

Пожалуйста, пользуйтесь https://pastebin.com/ для вставки кода, если он длиной больше нескольких строк или содержит или ∗.
Что читать:
- Stephen Prata "C Primer Plus, 6th Edition" (2014) (в русском переводе: Стивен Прата "Язык программирования C. Лекции и упражнения (6-е издание)" ): относительно свежая, знает про C89/C99/C11, описывает различия, объемная (около тысячи страниц), годная, с вопросами, упражнениями и ответами. Идеально для начинающих.
- Brian Kernighan, Dennis Ritchie "The C Programming Language".
- Стандарт ISO/IEC 9899:1999 (C99): http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1256.pdf (драфт)
- Стандарт ISO/IEC 9899:2011 (C11): http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1570.pdf (драфт)
- Черновик стандарта ISO/IEC 9899:202x (C2x): http://www.open-std.org/jtc1/sc22/wg14/www/docs/n2479.pdf (февраль, с диффами)
- Последний черновик ISO/IEC 9899:202x (C2x): http://www.open-std.org/jtc1/sc22/wg14/www/docs/n2583.pdf (октябрь)
Прошлый тред: https://2ch.hk/pr/res/3386488.html (
typedef struct foo {
int bar;
int baz;
} foo_t, ⚹pfoo_t;
Если надо обозначить указатель на структуру, то нахуя перед этим писать foo_t?
Ну типо, тут две дефениции:
foo_t обозначает псевдоним для struct foo
А pfoo_t означает псевдоним для struct foo⚹ т.е. тип указатель на эту структуру.
Зачем нужен указатель на структуру? Хз, наверное чтобы компилятор не ругался, и чтобы лишний раз преобразования типов не делать. Ясно что все указатели хранят адрес, т.е. один и тот же тип, поэтому никаких проблем нет чтобы присвоить к обычному void ⚹ наш struct foo⚹. Однако после такого присвоения мы уже не можем корректно обратиться к значению по адресу, потому что непонятно что за тип там лежит. Нужно этот воид привести к структфуу и тогда обратится. Может автор кода решил избежать этих преобразований и заранее слелал тип "указатель на структуру". Яхз
>Ну типо, тут две дефениции
Точняк. Я привык, что
struct foo {
int bar;
int baz;
} fooi;
где fooi - обычный экземпляр. А тут через typedef сразу несколько алиасов повесили. Можно там еще через запятую добавить указатель на указатель ⚹⚹ppfoo_t и т.д. Пиздец, ну и синтаксис.
Но это разные вещи. Тут ты:
struct foo {
int bar;
int baz;
} fooi;
Создаешь тип "struct foo" и обьявляешь, получается что, глобальную переменную fooi.
А с директивой typedef ты переменных не создаёшь, ты создаёшь синонимы для типов. Т.е.
typedef struct foo {
int bar;
int baz;
} fooi;
после этого у тебя нет доступа к fooi, потому что fooi - это тип. Нужно ещё создать переменную типа fooi.
Например:
fooi a = {1,0};
Вопрос только, нахуя ему тип ⚹pfoo_t? он ведь может просто ⚹foo_t написать.
 77 Кб, 850x989
77 Кб, 850x9891. Только на сишке и плюсах можно писать софт, убивающий людей. Никакая другая "платформа", "экосистема" - не позволяет этого делать.
2. Отсутствие безопасности памяти - несомненная фича, и любой язык устранивший это является проблемным в самой своей глубине.
> Только на сишке и плюсах можно писать софт, убивающий людей. Никакая другая "платформа", "экосистема" - не позволяет этого делать.
Товарищ-си, здравствуйте! Вы имеете в виду компьютерное зрение на дронах? Всякие numpy безусловно содержат в себе под капот дизассемблированные плюсы для вычислений перемножения матриц и другой математики, но это всё ещё Питон.
Или Вы про то, что уча "низкроуровневое" программирование хочется вздёрнуться и убить себя? Тогда я с Вами согласен, у меня депрессия и апатия.
> 2. Отсутствие безопасности памяти - несомненная фича, и любой язык устранивший это является проблемным в самой своей глубине.
Сейчас очень сложно обычному программисту набедакурить с памятью, ибо ОСь сразу тебе стукнет по носу, так сказать.
 48 Кб, 774x1014
48 Кб, 774x1014>Товарищ-си, здравствуйте! Вы имеете в виду компьютерное зрение на дронах? Всякие numpy безусловно содержат в себе под капот дизассемблированные плюсы для вычислений перемножения матриц и другой математики, но это всё ещё Питон.
Я знал, что кто-то прибежит рассказывать про машинное зрение, но:
1. Как ты верно заметил, самая ответственная часть обыкновенно реализована на сишечке. Питон - это для рисёрча и прототипирования. И даже при рисёрче, конечный обработчик вводных в виде картиночек и модели по итогу будет являться сишным...
2. Можно взять OpenCV, который в целом почти полностью плюсы. И на его основе общаться с полётником.
3. Большая часть существующего софта, убивающего людей, про машинное зрение даже не слышало. А это - наши любимые микрушечки в MQ-9 Reaper, системах ПВО вроде S-300, ПТУРах, самонаводящихся патронах в .50 BMG которые пилит американское DoD, системы наведения в бомбах, микроконтроллеры для теплочувствительных матриц, fly by wire в самолётах, и наконец, обыкновенный софт для полётных контроллеров. Бжж-бжж, motherfucker. Я даже не буду говорить про возможность бабахнуть чего-нибудь тремя или пятью вольтами. Ну, ладно, здесь можно и интерфейс накалякать на реакте, и css-префиксов понакидать на кнопочку, таких, чтобы я её хотел сначала лизнуть, а потом нажать. А потом ещё раз лизнуть.
> Сейчас очень сложно обычному программисту набедакурить с памятью, ибо ОСь сразу тебе стукнет по носу, так сказать.
Я надеюсь, ты не про сегфолты.
Типы, указатели, контейнера. Преобразования из структур в байты и обратно. Если мы не можем уследить за данными, и это приводит к багам, может и пишем-то мы не слишком сознательно?
Исходя из моих знаний о рассеянности человеческого сознания, пока растфаги разберутся, как написать что-либо, они забудут, что они вообще хотят написать - и сделают ошибку в самой логике работы программы.
> Сложно
Нет. Большинство каличей не итт оп пикрл как бы намекает , на в ей борде да и вообще везде сдабо понимают что такое память и указатели. Да ось не даст тебе убить себя, но логику программы это никак не защитит.
Про пик мимо. Думал это плюсотред, там пик рилейтед.
 343 Кб, 471x477
343 Кб, 471x477>сегфолт - это благо хорошо
это ты так своему барину обьясняешь, когда он тебя отчитывает за говнокод?
-Сычёв, какого хуя у тебя код рандомно сегфолится, хули ты там настрочил, ищи ошибку мудень
-Кабан кабаныч, вы не понимаете, сегфол - это хорошо а не плохо! Это означает можно экстренно завершить программу, а не ждать 30 минут, пока мой говнокод завершится.
А я поддержу товарища-Си выше и скажу, что мне тоже нравятся сегфолты, они значат, что ты набедакурил что-то в памяти и куда-то не туда залез, а значит область кода сужается и легче найти ошибку с указателями.
Но сегфол это не ошибка компилятора С. Это ошибка операционной системы. Ты и на асме можешь наговнокодить и получить сегфол. Это получается плюс в репку разработчикам ОС и mmu что не допустили багов в виртуальной памяти.
И искать причину сегфола не так то и просто, особенно на параллельных программах. Надо изначально знать что пишешь.
Эх, до параллелизма я так и не дорос, слишком быдло, товарищ-Си, признаю Ваше превосходство.
Малолетний долбоёб, если сегфолта нет, то это ещё не означает, что всё заебись, а если случился эксепшон, то это очень хорошая новость.
Да кто тебя из твоей шараги отчислит, фантазер. На первом курсе что ли?
>>433837
>а если случился эксепшон
Долбоеб это ты. Исключение обраьатывает ОС. Если твоя долбоебская ОС не способна защитить тебя от нарушения целостности памяти - значит ставь нормальную ОС, не знаю на что за хуйне ты сидишь. При чём тут С вообще? Это ОС и нужно отслеживать сегфоллы, а С тут не причем. При утечки памяти, например, твоя ОС начнёт вырубать все процессы подряд. Это тоже "Очень хорошо и продкмано" по твоему? Нет, это называется "я долбоеб написал кал, а операционная система от этого кала рыгает". Хорошие ошибки - это только ошибки и предупреждения компилятора, потому что они позволяют устранить неполадку до запуска, ещё и с указанием проблемного места.
Тупорылое дерьмо, нахуй ты вообще пишешь, если не понимаешь о чём вообще говоришь?
Ну расскажи что ты думаешь, раз считаешь что прав.
Скидывай свои варианты, мы только рады будем.
 409 Кб, 669x603
409 Кб, 669x603Я точно не хочу покупать и паять ардуинки? У меня есть если что, но я её один раз запрогал и забил. Разбираться что не так двадцать часов а потом узнать что просто диод пробило или кондёр, не, я это уже проходил на работе сотни раз, меня тошнит от хардварных проблем, в большинстве случаев они вызываны хуёвой закупкой компонентов или если в нашем чипе RTL нахуевертили неудачно.
Можно ли себя развлекать на C и получать нормальные знания владея только лишь компьютером и виртуалкой (мне в линуксе удобнее вести разработку, но на домашний комп ставить не хочу).
Ну научусь я сортировать эффективно массивы, обрезать строки, формировать, структуры, эмбедить asm вставки, жонглировать поинтерами и теребить алоки малоки. Делать-то что? На чём набивать руку чтобы стать неебаться эмбедед? Только интститут и вкат через практику?
raylib
А где в России топ специальности для низкого уровня? Я думаю, что только топовое ИБ направление, где на парах анализируют исполняемые файлы, да и то только курс, а может только семестр.
Эмбеддед хрен знает, но для фана сижу пишу на raylib и Dear IMGUI всякие поделки для себя, очень интересно.




Я в душе не ебу, что у тебя там за версия компилятора, но на 14.2 всё без говна.
 12 Кб, 951x662
12 Кб, 951x662У меня предположение только в том, что старый printf обрабатывал переменные по адресу так, что он видел модификатор для long long и обрабатывал сразу переменную a, b. Скинул загруженные в стэк переменные для примера.
А вот теперь хз, даже мой самопальный _print_hex_ нормально обрабатывает данные https://pastebin.com/upmduS3c.
Во-первых, какая разрядность системы? Во-вторых, какая версия компилятора? В-третьих, надо копать в сторону stdarg, походу переменные неправильно обрабатываются для функций с переменным количеством параметров. В-четвёртых, введи другие значения для a и b в своей программе.
 40 Кб, 1618x539
40 Кб, 1618x539Как-то так, а дальше уже только в ассемблере копаться и смотреть какое соглашение о вызове функции стоит, stdcall или cdecl. В общем надо думать, а думать я больше не могу, прости, товарищ Си, я пошёл думать о том, что моя вайфу меня никогда не полюбит.

 51 Кб, 1849x527
51 Кб, 1849x527У меня сложная тема диплома, я не могу вывезти, товарищ Си... Зачем я её выбрал, довыёбывался...
Товарищ Си, а если Вы уже получили диплом, то почему не догадались в чём проблема кода? Или это была проверка на адекватов в треде?
Или в результате проверки Вы поняли, что я долбаёб, пиздец. ПОЧЕМУ ПОСТОЯННО ТАКИЕ ВОПРОСЫ, НА КОТОРЫЕ НЕТ ОТВЕТА, Я НЕ МОГУ ТАК ЖИТЬ!
Товарищ Си, здравствуйте, сайт сделал диззассемблер Си кода https://godbolt.org/z/GzhfsKWso
Я скомпилировал и слинковал код с использованием MASM32 https://pastebin.com/NEKE4BDF
И судя по всему это не вина ОСи Виндоус, и даже не вина компилятора, ибо он предупреждения делает, это Ваша вина, товарищ Си.
Товарищ Си, мне очень грустно, я бы хотел, чтобы моя вайфу меня любила, но она не любит меня, мне очень-очень грустно...
 50 Кб, 500x500
50 Кб, 500x500>Товарищ Си, а если Вы уже получили диплом, то почему не догадались в чём проблема кода?
Во-первых потому что я получил диплом на инжинера АСУ ТП. Программировать нас не учили. Разве что ПЛК на языке релейных схем. А во вторых, я своим дипломом жопу подтираю. Лучше бы на работу пошел. Вроде столько времени в лабораторные всрал - в итоге на рынке труда я ниже школьника без знаний.
Пока ты тут спамишь кринжевыми товарищами си, ты ещё не знаешь что тебя ждет голод и всеобщее обомсывание и обхаркивание таоего диплома как бесполезной корочки.
>ибо он предупреждения делает, это Ваша вина, товарищ Си.
Он не делает предупреждений. В глаза что ли долбишься. Причём тот же код на фрибсд работает нормально!!! Ану сьеби уроки учить школота блиядь.
К слову причем тут дизассемблер ДЕБИЛ. Ты не сможешь за дизассеблить код с виднды, потому что на Винде нет полноценной библиотеки Си. На Винде твой printf вызывает ConsoleWriteA, а тот в свою очередь вызывает NtDeviceIoControl. Давай назуй, задисассемблируй мне эту хуйню из kernelbase.dll.

> инжинера АСУ ТП
Да тут программирование + физика + схемотехника, вы должны быть умнее всех!
>спамишь кринжевыми товарищами си,
Я уважаю всех товарищей по Си, вы мне братья!
> тебя ждет голод и всеобщее обомсывание и обхаркивание
Я знаю, товарищ Си, я знаю.
>>436094
> Он не делает предупреждений.
Потому что надо -Wall -Wextra -Wpedantic прописывать, товарищ Си.
> нет полноценной библиотеки Си
Я не знаю, что вызывает WinAPI, но выглядит максимально прохладно и кажется, что Вы меня обманываете.
> Давай назуй, задисассемблируй мне эту хуйню из kernelbase.dll.
А вот это зря, данный компилятор диззассемблирует код на основе UNIX систем, Вы точно уверены, что он нормально отработал на BSD?
>>436095
Эх, товарищ Си, как же я ненавижу НСов, пиздец.
Я к Вам с добротой отнёсся, пытался искренне Вам помочь, а Вы меня последними бранными словами наградили. Теперь мне очень сильно грустно, я ушёл плакать, Вы плохой человек, товарищ Си.
данный диззасембер *godbolt.
>Да тут программирование + физика + схемотехника, вы должны быть умнее всех!
Умный, по горшкам дежурный, нах. Я денег бы хотел, а не чтобы анон на двачах назвал меня умным.
>я ненавижу НСов, пиздец.
Я не НС. Я гитлер.
>Вы точно уверены, что он нормально отработал на BSD?
Да. Сто процентов. Могу показать даже. То что я под виндой компилю - это виртуалка.
>Вам помочь, а Вы меня последними бранными
Ну соре все дела. Пынямать надо. День рождение Гитлера как ни как.
Ебать, на моего одного знакомого похожи, правда он себя открыто НС называл, но с Гитлером себя тож сравнивал, Вы идеалист или материалист?
Давайте скидывайте.
>Вы идеалист или материалист?
Это тебя в университете этой хуйне учат? Все эти "измы" - это придуманное в совке словоблудие. Советский человек настолько контуженный на голову, что он не может обходится без формальностей, и не нагружать всё каким-то словесным поносом. Не "нож" а "острый предмет угловатой формы, для нарезания продуктов питания, не боевой", не "я ебал твою мать" а "вы осознанно вступили в половой акт, с соверешннолетней гражданкой, находясь в трезвом состоянии". Нигде в мире так не говорят.
Если бы ты был реально умным, то давно бы чего да добился, а ты просто хуесос с огромным ЧСВ, который думает, что за факт его существования ему все должны.
>Если бы ты был реально умным, то давно бы чего да добился, а ты просто хуесос с огромным ЧСВ, который думает, что за факт его существования ему все должны.
Чё сказать хотел, долбоёб?
Например, нужно найти количество вхождений подстроки в строке. Я беру указатель и присваиваю ему значение strstr(строка, подстрока) и засовываю его в цикл while, проверяя чтобы он не был равен NULL. После нахождения вхождения я увеличиваю указатель на 1 (сдвигаю на следующую ячейку памяти), после чего цикл повторяется.
Эту задачу можно решить без указателей? Вообще это не считается болезнью, что теперь при решении любых задач я думаю про ячейки памяти и указатели?
 217 Кб, 512x451
217 Кб, 512x451попкукал что-то обиженка и сдрыснул
>>436546
код неси, не понятно. Но вообще вот
>вхождения я увеличиваю указатель на 1 (сдвигаю на следующую ячейку памяти)
так типо часто делают на с. Я бы предпочёл всё же скобочкаими это оформалять [] потому что это понятнее. Но разницы особо нет.
> Вообще это не считается болезнью, что теперь при решении любых задач я думаю про ячейки памяти и указатели?
Нет. Это как раз так сказать "парадигма" языка С, то что тут именно что байтоёбство и размышление в контексте байтов. Это как раз правильный подход. Вот мыслить категорями высокоуровневых яп это как раз вредно, например структуры пихать в качестве аргументов функций итд.
> Ты не сможешь за дизассеблить код с виднды, потому что на Винде нет полноценной библиотеки Си
Что? Я вообще нихуя не понял, это как? А .exe из-за святого духа работают? А компилятор объектники как делает?
> На Винде твой printf вызывает ConsoleWriteA, а тот в свою очередь вызывает NtDeviceIoControl
А это интересно уже. Лучше бы про это рассказал, а не про хуйню какую-то, про системные вызовы, что printf под капотом вызывает в винде, что в юниксах.
Только это всё ещё ты виноват, что код не работает, ты если бы нормально с компилятором умел работать, то увидел бы, что он предупреждения делает. Да и под винду у новых компиляторов такой проблемы нет.
Ленивый выблядок, которого турнули из магистратуры, а он сюда пришёл ныться, пошёл в жопу, хуесос, ты мразь и гандон.
>Нормально ли использовать указатели для решения любой задачи на C?
Да.
>Эту задачу можно решить без указателей?
Да.
>это не считается болезнью, что теперь при решении любых задач я думаю про ячейки памяти и указатели?
Нет.
>Что? Я вообще нихуя не понял, это как? А .exe из-за святого духа работают? А компилятор объектники как делает?
Нихуя не понимаешь, да? Вот и молчи
>>436579
Эти все предупреждения роли не играют, дятел. Число "с" там longlong, что соотвествует llx (long long hex).
К слову, на FreeBSD всё исправно работает. Пиздец долбоёб, увидел предупреждение и молится на него. Читать ты конечно же это предупреждение не читал.
>>436580
утютю
Ты долбаёб или что? Ты же про CRT слышал и ещё пиздишь, что на винде нельзя дизассмеблировать Си код, ты буквально это и написал, скотина слепая.
> llx (long long hex)
Покажи мне такой тип hex, хуесосина, это флаг для форматного вывода, который работает с переменной как с безнаковой, пидор ты ебанный.
> К слову, на FreeBSD всё исправно работает.
на винде тоже можно написать код так, чтобы он исправно раюотал и даже компилятор с cppcheck ошибок не выдавал, это всё твоя вина, криворукая залупа.
>Ты долбаёб или что? Ты же про CRT слышал и ещё пиздишь, что на винде нельзя дизассмеблировать Си код, ты буквально это и написал, скотина слепая.
У тебя на винде код целиком и полностью на dll-ках работает. Даже с ключами -static. Если ты это не понимаешь - ну ты идиот.
>Покажи мне такой тип hex, хуесосина, это флаг для форматного вывода, который работает с переменной как с безнаковой, пидор ты ебанный.
Вай вай вай, какой умный малыш. И тебя не волнует что я long long hex нигде даже типом не назвал. Это расшифровка.
>всё твоя вина, криворукая залупа.
Соре, я не разработчик GCC, ты ошибся
Блять, а какой процесс на любой ОСи может работать без использования dll/so, если тебе в любом случае придётся взаимодействовать с железом через ОСь, даже если ты просто программу напишешь, в которой не будут подключаться библиотеки, ты про что говоришь, блять, сука ебанная.
>Блять, а какой процесс на любой ОСи может работать без использования dll/so, если тебе в любом случае придётся взаимодействовать с железом через ОСь
Через системные вызовы, порридж!!! Напрямую, через програмные прерывания, таблицу системных вызовов можно работать с обьектами ядра. И на windows это работает точнно так же. Если ты дизасемблируешь ntdll, то ты там не найдёшь ссылок на другие библиотеки. Ого, эво как да? А вот так, там чистые сисколы используются.
Напиши мне прогу которая в регистр EAX записывает 0xffff и делает возврат и, чтобы не было библиотек от ОСи.
 47 Кб, 160x160
47 Кб, 160x160>Напиши мне прогу которая в регистр EAX записывает 0xffff и делает возврат и, чтобы не было библиотек от ОСи.
mov eax, 0xffff
ret
та-дааам.
 3 Кб, 232x110
3 Кб, 232x110Угу, и по твоему ОСь не прилинкует сюда либы? Ну, ладно...
Я тебя не понимаю, ты на что опираешься? По моим подозрениям на том Танненбаума по ОСям.
>Угу, и по твоему ОСь не прилинкует сюда либы?
Какие либы? ret, mov - это всё мнемоники команд процессора, для них не нужны никакие либы.
Мы не говорим о BIOS и прошивках сейчас, мы говорим о коде в контексте ОСи.
А как ОСь должна понимать с каким ядром ты работаешь?
Я тебя не понимаю, вообще, блять, не понимаю.
Какую книгу мне надо прочитать, чтобы я тебя понял?
 441 Кб, 1280x593
441 Кб, 1280x593>Блять, ну, невозможно даже код на ассемблере написать, чтобы он не использовал kernel32 на винде, ибо там как раз эти ебучие сисколы.
Теоретически - возможно. Практически - все эти сисколы не задокументированы, и непонятно как они работают. Даже разработчики wine и ReactOS не всё знают. Поэтому, на винде можно пользоваться только kernel32.dll, потому что это последнее на что есть инфа.
Вот на скрине функция которая в конце концов использует сискол. Но что он делает - я так и не смог догадаться. Нужно знать как устроена windows чтобы понять как правильно использовать этот сискол. Я только PEB смог правильно интерпритировать. И то на угад.
>А как ОСь должна понимать с каким ядром ты работаешь?
Она и не должна понимать. Ядро находится на 0 уровне. Когда ты совершаешь сискол, ты буквально даёшь процессору команду оторваться от юзермода и выполнить что-то из режима ядра. В режиме ядра по-идее всё архаично как на MS DOS, поэтому там всё работает по протоколу ядра - т.е. если ты что-то сделаешь неправильно, никто тебя об этом не предупредит. Протокол типо вот регистр eax нужен для того чтобы номер системного вызова передать - соглашение такое.
>>436618
я хз.
Какая книга Столярова или цикл книг? Про ОСи? Почему так сложно дать название? В какой программе код учился дизассемблировать?
учился код дизассемблированный читать*
>В какой программе код учился дизассемблировать?
Ghidra, бесплатная, кросплатформенная и довольно неплохо дизассемблирует
>Какая книга Столярова или цикл книг? Про ОСи?
Там просто "введение в профессию". Помоему у него других книг и нет (а те что есть - старьё ненужное). Второй том, помоему, после изучения С, идёт более подробный обзор устройства unix.
>учился код дизассемблированный читать
Не учился специально, просто смотрю чё там написано. Если адреса есть - значит это код дизассемблированный, если нет - значит это полезная информация всякая от гидры. Покопался немного, посмотрел как форматы PE .exe выглядят как система загружает программу. Вроде ничего больше не читал особо. Работу надо искать, а не байтоёбствовать.
Понял, спасибо, ладно, сорри, что бугуртил. Спасибо, что расписал, но мне кажется, что ты меня троллишь.
А у него реально в книге про Си о кольцах защиты расписано? Что-то не верится, если честно.
 41 Кб, 640x480
41 Кб, 640x480>А у него реально в книге про Си о кольцах защиты расписано? Что-то не верится, если честно.
Нет, там только общая информация. Но да, там обьяснено что такое "защита памяти" "юзерспейс" и зачем оно вообще нужно. Про кольца я слышал задолго до прочтения этой книги, но во всяких роликах мне затирали, что якобы "юзерспейс" нужен для "безопасности", что вот злые хакеры хотят попасть в ядро и похитить память, а защита памяти якобы защищает от этих хаккеров. У меня всегда это вызывало критику, потому что это звучит как бред. Ну и не только звучит, это и есть бред. Вот у столярова пояснено, что "защита памяти", по сути защищает компьютер от самого себя, а не от кого-то другого. Ведь на нулевом уровне всё просто и логично, до тех пор, пока не возникают парралельные процессы. Все же ОС сейчас многозадачные, никто не сидит на MS-DOS, поэтому появляются такие сущности как "параллелньые процессы", ну и их всех надо умело размещать в памяти, с учётом того, что каждый из них может в любой момент завершится. И ведь если всё складывать просто в "плоскую" абсолютную память, то появляется "фрагментация". т.е. процессы просто могут в шахматном порядке встать и заполонить всю память. Более того, процессы могут "разростаться" и аллоцировать больше памяти". Поэтому в реальности, абсолютная память забивается в случайном порядке, а процессы, видят сконвертированную на "страницы" память из mmu. Таким образом. получается сделать абстракцию в виде "гибкой" памяти, которую можно в любой момент выделить и освободить. И всё это само собой накладывает ограничения в виде необходимости не допустить ошибок. Поэтому и появляются разные кольца "защиты". Вприципе, можно сделать многозадачную ОС и на нулевом кольце защиты вон TempleOS, например. Но это не то, чтобы что-то работоспособное.
Я имел ввиду, следующее: вот есть так называемая "стандартная библиотека С", откомпилированная статично libc.a и динамично libc.so. Функции в ней для ввода вывода типо printf используют системный вызов write (0x4), который собственно пишет информацию в стандартный поток вывода (stdio). Ты можешь откомпилировать unix-программу с флагом -static, и получить полностью самостоятельный машинный код, не содержащий в себе никаких зависимостей от динамических библиотек. То есть, если версия libc изменится, или вовсе если перекинуть эту программу на ОС без libc, то она запустится и будет работать. Собственно, при декомпиляции этой программы, ты можешь отследить какие системные вызовы она использует, и как этот код детально работает через дебаггер.
Вот только в винде ситуация другая. На винде нет таких элементов ядра как "стандартный поток вывода", на винде потоки устроены иначе. Более того, то как винда устроена - не задокументированно. Никто кроме разработчиков microsoft не знает как использовать системные вызовы. Следовательно, как работает printf на винде? Он на самом деле иммитирует работу printf, средствами winapi. То есть, стандартная библиотека под windows представляет собой Trunk-функции для windows-api и не более того. Как я уже говорил, printf вызывает WriteConsoleA, а та в свою очередь вызывает NtDeviceIoControl. Поэтому, даже когда ты с ключем --static компилируешь программу под винду, статично зашиваются все библиотеки кроме стандартной. На винде нет статичных версий библиотек ntdll (она даже называется dll лол). Поэтмоу, когда ты дизасемблируешь виндоусовскую программу - ты не видишь в ней ничего, кроме основного её функционала и ссылки на winapi. То есть, таким образом, портирование программы лишено смысла, потому что её релальный функционал проще изобрести самому - он находится на поверхности, его не сложно разработать с нуля, а остальной функционал отсутствует - он находится в динамических библиотеках.
Ну и тогда, само собой, могут появляться ошибки в выводе, потому что ничего не известно о том как винда обрабатывает буферы для вывода информации.
Я имел ввиду, следующее: вот есть так называемая "стандартная библиотека С", откомпилированная статично libc.a и динамично libc.so. Функции в ней для ввода вывода типо printf используют системный вызов write (0x4), который собственно пишет информацию в стандартный поток вывода (stdio). Ты можешь откомпилировать unix-программу с флагом -static, и получить полностью самостоятельный машинный код, не содержащий в себе никаких зависимостей от динамических библиотек. То есть, если версия libc изменится, или вовсе если перекинуть эту программу на ОС без libc, то она запустится и будет работать. Собственно, при декомпиляции этой программы, ты можешь отследить какие системные вызовы она использует, и как этот код детально работает через дебаггер.
Вот только в винде ситуация другая. На винде нет таких элементов ядра как "стандартный поток вывода", на винде потоки устроены иначе. Более того, то как винда устроена - не задокументированно. Никто кроме разработчиков microsoft не знает как использовать системные вызовы. Следовательно, как работает printf на винде? Он на самом деле иммитирует работу printf, средствами winapi. То есть, стандартная библиотека под windows представляет собой Trunk-функции для windows-api и не более того. Как я уже говорил, printf вызывает WriteConsoleA, а та в свою очередь вызывает NtDeviceIoControl. Поэтому, даже когда ты с ключем --static компилируешь программу под винду, статично зашиваются все библиотеки кроме стандартной. На винде нет статичных версий библиотек ntdll (она даже называется dll лол). Поэтмоу, когда ты дизасемблируешь виндоусовскую программу - ты не видишь в ней ничего, кроме основного её функционала и ссылки на winapi. То есть, таким образом, портирование программы лишено смысла, потому что её релальный функционал проще изобрести самому - он находится на поверхности, его не сложно разработать с нуля, а остальной функционал отсутствует - он находится в динамических библиотеках.
Ну и тогда, само собой, могут появляться ошибки в выводе, потому что ничего не известно о том как винда обрабатывает буферы для вывода информации.
> в русском переводе
^ Ничего не изменилось, Если вам нужен русский перевод - вы идете нахуй
>На винде нет статичных версий библиотек ntdll (она даже называется dll лол).
ntdll это ядро, ты собрался ядро статически вкомпилировать в приложения, чтобы они работали мимо ядра, ебанат?
Если в линуксе так делают, значит там ядро говно, нихуя не реализовано, вот и костыляют функционал внешними библиотеками. Естественно такое говно ни с чем не совместимо, приходится компилировать отдельно на каждое ведро со своими костылями.
>Ну и тогда, само собой, могут появляться ошибки в выводе, потому что ничего не известно о том как винда обрабатывает буферы для вывода информации.
Винда - графическая ОС, консоль там для совместимости с DOS только, то есть не нужна, для обмена данными существуют другие механизмы, всё документировано. Лезешь в винду не понимая что это такое кукарекая зашоренные предрассудки.
Товарищ Си, а что Вы посоветуете почитать, чтобы понять и осознать Вами написанное в полной мере? Таненбаум про ОСи подойдёт?
 98 Кб, 230x219
98 Кб, 230x219>ntdll это ядро
Нет. Ядро работает на 0 кольце до загрузки системы. Ядро ты не видишь и не можешь увидеть, потому что это голый код. NtDll это user-mode библиотека, она по-умолчанию не может быть ядром. Чё несешь. ntdll ближе всех к ядру, потому что как раз она представляет собой обёртки системных вызовов.
>чтобы они работали мимо ядра, ебанат?
Ебанат это ты. Хотя бы википедию почитай перед тем как такой бред нести.>>437086
>Если в линуксе так делают, значит там ядро говно, нихуя не реализовано, вот и костыляют функционал внешними библиотеками. Естественно такое говно ни с чем не совместимо, приходится компилировать отдельно на каждое ведро со своими костылями.
Ахаха что ты несёшь контуженный. Никто не собирается вкомпилировать ядро, это блядь вообще не так устроено. Ты хоть что-то собирал на голом железе, на микроконтрллерах?
Вот такие безграмотные олухи затируют что линукс - говно
>Винда - графическая ОС, консоль там для совместимости с DOS только, то есть не нужна, для обмена данными существуют другие механизмы, всё документировано.
"графическая ос" пиздец ты посмешище. Какая впизду "графическая ОС". Ты видел хоть одного человека с реальным терминалом в 2025 году?? Да при наличие настоящего vt100 ты можешь разбогатеть сдав его в антикварный магазин! У всех компьютеров всё выводится через монитор. На выводе монитора что написано? Правильно VGA - что тут значит буквока "А" - это означает "аналоговый". Это значит, скотина ты тупорылая, что у тебя вывод идёт через видеокарточку. И чтобы тебе консольку открыть - тебе приходится использовать драйвера видеокарточки для отрисовки знакосимволов. ОППА! получается Unix что тоже ГРАФИЧЕСКАЯ ОПЕРАЦИОННАЯ СИСТЕМА???? А что если я тебе скажу что на Unix ты тоже kldload'ом подгружаешь графическое ядро, и у тебя также вся графика xorg работает в kernelspace? Да да, прямо как на виндоус. Обтекай короче. Ты меня насмешил.
>>437087
Он олух тупой. Столярова лучше прочитай. Столяров шиз - но вприципе неплохие книги пишет.
У тебя был бы шанс иронично сманяврировать, если бы не предыдущий твой пост, исходя из котрого ты помоему даже 9 классов ещё пока не окончил.
Ntdll у него ядро! представте себе, файловой системы ещё нет никакой, а уже есть полноценная dll-ка! В следующий раз начинай сразу с оскорблений, не пытайся блеснуть знаниями которые у тебя отсутсвуют.
Я так-то без негатива, ты человек шарящий, просто у тебя подача порой странная и ты суть вопроса не раскрываешь, чтобы тебя мог понять другой человек, или хотя бы по запросу в поисковом фиде что-то найти.
Но у тебя крайне глубокие познания для человека, которые на АСУ ТП учился.
Но при этом ты скомпилировал код без ключа на все предупреждения, да и вообще вопрос нахуя ты на 32битной виртуалке запускал код, если бы тебе было интересно как 32битная система работает с 64 битными значениями, то скорее всего бы под родной линухой скомпилил код с ключом -m32.
Короче, это всё максимально странно и подозрительно.
>да и вообще вопрос нахуя ты на 32битной виртуалке запускал код, если бы тебе было интересно как 32битная система работает с 64 битными значениями,
да ты в глаза что ли долбишься? Там буквально на том же скришоте вывод назад всё нормально интерпритируется. Система 64 бит. Я сайзофом всё проверил. Очевидно, ошибка в gcc
 442 Кб, 996x907
442 Кб, 996x907Вот специально для тебя выделил. Код абсолютно одинаковый.
Эти выражения выводятся в рамках одной программы.
llx -> c
llx -> c
И в третий раз, какого-то хуя он выводит непонятную крокозябру.
И заметь.. c - это у нас long long, т.е. llx.
Ну конечно... виноват я что какое-то предупреждение не посмотрел. А схуя ли я его смотреть должен?
У нас a и b - это int по 32 бита. Можем ли мы в 64 бита поместить 32? можем. Что мешает. Мы не можем в меньшее складывать большее. А в большее меньшее - можем. И портится при этом никак не связанная с этим переменная "с", которая соотвествует своему типу.
Ну конечно же виноват анон который -wall не поставил. Ни разу не разрабы gcc.
 25 Кб, 632x552
25 Кб, 632x552Вот ещё пруф. Откопилировал при помощи tcc на этой же системе - Всё почему-то правильно работает. А вот gcc нет. Что же опять не так??? Может мне флаг -O0 сделать.. а нет не помогает ничерта.
 29 Кб, 632x552
29 Кб, 632x552проклятье. ну и чёрт с ним
Ну, это относительно интуитивна реально понятно, ты прописал модификатор для 8 байт и оно 8байт из стэка и обработало, что не так? Это проблемы со stdarg скорее, чем с printf.
> В ембедед сишка не является тут предметной областью.
Еще как является лол. На собесах теорию по сишке еще как спрашивают.
Знал о том, что при флагах компиляции можно проверки на SEGV отключить? Нет? Так нахуй ты пришел блять сюда? Хуйню несёшь всякую
Меня в свое время из-за физры чуть не отчислили
Я вбил в поисковик asan и так понял, что он отключается при оптимизации O2, а gcc же по дефолту с этим ключом объектники делает, разве нет?
Почитал статью и это больше критика компилятора gcc, чем языка Си, но заголовок безусловно кликбейтный. Хотя и с большей частью проблем оптимизирующих флагов я, к счастью, не сталкивался.
Эхх, а раньше этот аффффтар дрочил на столярова и критиковал раст
https://veresov.pro/rustmustdie/
А теперь ушёл в оппозицию и ругает власть.
Так-то хуйню написал, кроме одного момента, пидораст, конечно, говно язык, но челик вообще не рубит.
Ну и по сайту какой-то он мастер на все руки, но на деле обычная институтка.
Я сходил на одно собеседование - С вообще не спрашивали. Не приняли. На собес в другую компанию отказали, на собес в третью - даже не позвали, тупо проигнорили. Ну хз. Пока что как-то всрато выходит.
>>3401714 →
>Насколько сложно реализовать компилятор, это же пиздец.
Нет. Это легко. Все сложности написания комплияторов это не перевод, а оптимизации. Если на них глаза закрыть, то компилятор это не особо сложная программа. Можно даже без АСТ реализовать.
Можешь старый туториал от Джека Креншоу(Jack Crenshaw) навернуть.
>Нет. Это легко
Именно поэтому МЦСТ ищет ценных кадров и с руками-ногами их отрывает? Очень легко, да...с какими же дегенератами тут сижу блядь.
Ты дальше первых двух предложений читал? Или это слишком сложно для тебя?
Любой, кто умеет в тот же лисп или хаскель, может свой мини-язычок сделать за неделю без проблем. Как я сказал и как упомянул анон выше ещё раз, основная сложность это оптимизации, все сложности связаны только с этим, проблему перевода решили ещё в 50-х.
По твоему стилю ты кстати похож на местного дегенарата, что по всей доске бегает и на виндузятников плюется. Это ты? То есть я был прав ты далбаеб-вкатун, который ничего не умеет и кукарекает лозунгами, подхваченному от всяких "гуру".
Вкатун говорит вкатуну что он вкатун
>- ЯРЯЯЯ СИ ДОЛЖИН УМИРИТЬ
>- -fwrapv -fno-strict-aliasing
>- о норм язык
Чёт проиграл с этого додика, да блядь, си сложный язык, всю хуйню надо знать.
Что хорошего в знании? Бошка не резиновая, знания тоже нужно оптимизировать.
Твой вопрос эквивалентен вопросу: "А какая погода сегодня на марсе?"
>Что хорошего в знании?
Расширяет кругозор и этим помогает в работе.
>Бошка не резиновая
Мозг как раз таки очень резиновый, так что нужно изучать как можно больше всего.
Это те дибилы которые уже и не знают на чем бы еще распилить.
А для копиляторов есть ллвм, больше не надо колеса изобретать.
В работе помогает убедительно и вежливо послать всех пытающихся навесить на тебя работу, а когда нельзя послать, ту работу свалить на других. Оставшуюся работу от которой нельзя откосить или свалить на других сделать за пять минут и остальное время капчировать двач, играть в игры и т.д.
>убедительно и вежливо послать всех пытающихся навесить на тебя работу
>сделать за пять минут и остальное время капчировать двач, играть в игры
Дык это и есть знание и широкий кругозор.
У эльбруса хуевинький встроенный планировщик, им надо миллион человеко-часов вложить в оптимизирующий конпелятор.
>А для копиляторов есть ллвм, больше не надо колеса изобретать.
Ты - тупая хуйня просто.
Кланг работает. На ллвме новые кипиляторы для чего только не сделали уже, а
> Ты - тупая хуйня просто.
все копроьивляется.
Какой кланг, уёбок, я тебе про оптимизирующий компилятор под систему без планировщика, учитывающий микроархитектуру поделия от мцст, никто за них его не напишет, для подобных систем это не попильная прихоть, а тупо необходимость, они его будут улучшать до бесконечности.
Идиот анон спросил про написание компилятора, по нити пройдись.
А про ворье это даже писать больше не хочу.
>систему без планировщика
А изобрести велосипед транзистор аналоговнетные еще не придумали? Слышал, стоящая вещь.
Знания и кругозор за тебя работу не сделают. Меньше работы только у того, кто от работы откосил. Получается, знания нужны для тунеядства, чтобы ничего не делать, но зарплату получать, воровство.
>знания нужны для тунеядства, чтобы ничего не делать
Именно. Чем больше ты знаешь, тем быстрее ты можешь сделать РАБоту и проёбываться оставшееся время.
Только платят тебе не за работу, а за время. Чем быстрее ты сделал задачу, тем быстрее метнулся делать следующую.
Тебя никто не заставляет сразу по завершению всё коммитить и орать "сматрите какой я быстрый".
>>для тунеядства, чтобы ничего не делать
>Именно.
>сделать РАБоту
Одебилевшее животное, посмотри значение тунеядства в словаре.
Делать работу это трудолюбие, а не тунеядство. Тунеядец потому и тунеядец, что НЕ делает работу, он косит от работы, а делает только хуйню для вида чтобы не выгнали, то есть на практике нихуя не делает, только штаны протирает изображая важную нужную персону.
Там и не должно быть планировщика, команды просто либо распихиваются по вычислительным блокам, либо все ждут, пока какой-то из них не освободится. Архитектура VLIW подразумевает, что блоки процессора выставлены наружу явно, и в момент генерации инструкций будет выполняться поиск оптимального их набора. Сэкономленные на отказе от сложного устройства транзисторы в теории можно перевести в работу за меньшее количество тактов, или большую синхронность, или повышение частоты, или более простой техпроцесс, и так далее.
Другое дело, что по факту это процессоры для каких-то радаров противоракетной обороны, следящих за целями, и их устройство (перевес вычислительных блоков для обработки данных) было определено исторически этой задачей (или же просто в оригинале несколько ящиков, набитых платами, заменили на один микропроцессор с точно такой же системой команд и внутренней схемой). То, что их представляют публике в качестве универсальных, — старый советский анекдот «только ребёнка через башню неудобно доставать». А у основного применения набор программ и требуемые характеристики производительности заданы заранее, там можно карьеру построить на оптимизации конкретно этих задач и до пенсии сидеть их вылизывать. Можно даже догадаться, что процессор модели такой-то заранее спроектирован так, чтобы выполнять известный код достаточно быстро.
Но что мы прицепились к конкретному примеру, можно ведь обсудить, что C при кажущейся универсальности ориентирован на вполне определённый класс систем времён своего появления и развития, а к остальному его прикручивали как получится.
в Мсис2 установишь через пакеты
как си может умереть если на нем написан весь интернет, вся инфраструктура, все операционки, все языки, даже небо, даже аллах?
На коболе и ассемблере тоже много чего написано.
>все языки
Нет. Многие были написаны сами на себе. Та же джава.
Стыдоба, в растотреде тебе бы сразу ответили.
Можно. Придумываешь язык, пишешь на нем компилятор, дальше вручную компилируешь его, переводя в машинный, и у тебя есть компилятор. Дальше уже пишешь улучшенный компилятор и компилируешь готовым, получая новый компилятор и тд.
>Джава на с++ написана изначально.
Жвм да. Но компилятор джавы написан на джаве, открой их доки и посмотри.
>>450440
https://web.archive.org/web/20080222200518/http://java.sun.com/docs/overviews/java/java-overview-1.html
> The Java system itself is quite portable. The compiler is written in Java and the runtime is written in ANSI C with a clean portability boundary. The portability boundary is essentially a POSIX subset.
Так найди гайды, как это сделать. Можешь nand2tetris навернуть. Книгу на либгене скачаешь.
>Не понимаю как из головы можно написать драйвер или операционку.
Это и не берется из головы. Это годы нахуй, просто годы написания кода, чтения документации, чужих примеров и так далее. Если ты видишь как кто-то написал пиздатый драйвер или что-то из той же оперы, то ты просто не видишь что за этим стояло: бессонные ночи, тонны прочитаных талмудов, дебаггинга, переписываний и тд и тп
а можно подробнее? допустим я хочу написать холиПитон, в мире нет ничего кроме ассемблера. как мне написать интерпритатор/компилятор для холиПитона, если компьюетры базарят только на ассембере?
Там не на ассемблере, не труъ.
Научись в циклы и условия на асме. Затем пишешь компилятор своего холиПитона на чём угодно, хоть на нём самом в тетрадку. Твоя программа будет состоять из циклов и условий, а ты умеешь их руками реализовывать на асме. Вручную компилируешь свой код и получаешь компилятор.
Естественно проще сделать урезанную версию языка для начала, и постепенно улучшать, но делая это на своем языке, а не на асме.
Я не знаю книг, где был бы реализован этот план.
>>451972
Я бы начал с Let's Build a Compiler, оригинал на Паскале, но есть версии и С и Форта. Там оч. примитивный компилятор без AST и прочего, отчего можно хотя бы представление поиметь, что перевести эт овсё вручную в машинный код реально.
>Но компилятор джавы написан на джаве,
Нет, изначально он был написан на плюсах.
И только потому же переписали.
Невозможно написать компилятор или интерпретатор языка на нем самом в первый раз. Потому что язык это буквально просто набор слов.
Вообще хуею с уровня современных айтишников.
Дурачек, я уже написал, как это сделать. Буквально ручками.
Как по-твоему первый компилятор был сделан? Слетали в будущее, написали его на Хаскеле, а потом вернулись?
Представь что ты сделал первый компьютер. Ты программируешь в машинных кодах. Дальше ты понимаешь, что это нечитабельно и придумываешь мнемоники. Пишешь гайд, как мнемоники перевести в коды, нанимаешь сотрудников и они вручную твои программы переводят. В этом ничего сложного нет, любой человек с улицы справится.
Дальше ты пишешь свой ассемблер на... языке ассемблера и отдаешь сотрудникам, они его переводят и вот у тебя есть перфокарточка с ассемблером и отдел перевода больше не нужен.
Дальше ты можешь выдумать что-то получше. Выдумываешь улсовный С. Дальше пишешь гайд, как его конструкции перевести в асм. Как пример я уже указал - можешь попробовать реализовать цикл на асме. Пишешь компилятор уже на С, находишь опять же людей, готовых ручками его перевести, и всё, у тебя есть компилятор написанный на самом себе!
Ты можешь сейчас спиздануть, что в примере выше он написан на асме. Но ты можешь заставить переводить в машинные коды напрямую.
Вуаля ты написал компилятор языка на самом языке, без использования промежуточных языков.
>Как по-твоему первый компилятор был сделан?
В машкодах пишешь ассемблер, на ассемблере пишешь компилятор. Можно сразу в машкодах писать, если программа маленькая, и все вручную слинковать можно.
Шаг с бумажным компилятором и компилированием в голове - откровенная шиза, тупо потому, что ты без ошибок программу сходу не напишешь, а без рабочего компилятора ее не отладишь. Ну и, например, функциональные языки на ассемблер очень плохо ложаться, в голове их компилировать будет очень сложно.
Тебя вроде никто и не заставляет сходу писать без ошибок. Функциональные точно так же пишутся, как анон выше описал:
https://www-formal.stanford.edu/jmc/history/lisp/node3.html
>we started by hand-compiling various functions into assembly language and writing subroutines to provide a LISP "environment"
Конечно в 2025 это шиза. Но в 1955 нет.
Но если представить, что весь софт как-то уничтожится, то скорее всего всё восстановят по схеме типа: - асм - форт - лисп - с
Ну и я, конечно, подтраливал. Конечно бутстрапинг джавы начинали с другого языка, а не вручную.
>Функциональные точно так же пишутся
Лисп - такой же функциональный, как js или питон. То, что там лямбды есть, не делает его функциональным.
Хорошо, пусть будет так.


Есть динамическая библиотека libzalupa.so. Она линкуется с моей программой обычным путём.
В моей программе есть pthreads, в библиотеке тоже есть. У себя я использую Global dynamic TLS model, что использовано внутри библиотеки - непонятно, никаких торчащих наружу секций или инфы нету, но треды она там плодит и убивает.
В какой-то момент, после вызова пары-тройки функций из этой библиотеки, оказывается что malloc начинает выделять для меня память там, где он раньше уже выделял её мне, и там мои живые данные лежат, и я их не освобождал.
Что происходит?! malloc же тредобезопасный, да? При загрузке библиотеки через LD автоматически при старте программы оно же не копирует какое-нибудь состояние malloc и оно потом не может же расходиться?
Пиздец, я третий день мозги этим ебу, помогите!
Нахуй ты делаешь маллоки во время работы программы? У тебя какие-то генеративные данные приходят, в огромных размерах? Парсишь половину интернета?
Нахуя в принципе выделять память вне инициализации?
>>malloc же тредобезопасный, да?
>Нет
Есть же стандарт, давно тредобезопасным его сделали. Он не реентерабельный, но там мьютекс на входе
>Пиздец, я третий день мозги этим ебу, помогите!
Нужна какая-нибудь софтина, которая запишет историю выделяемых и освобождаемых диапазонов. В логе увидишь тот диапазон который затирается и кто его затирает.
Только лог нужен с backtrace на каждый вызов malloc/free
Мимо
>Есть же стандарт, давно тредобезопасным его сделали.
Я конечно за стандартами не слежу, но ты там тогда настройки конпелятора и либ посмотри на соответсвие стандартам.
void moving(char str)
{
str += 1;
// do something with s
str += 1;
// do something with s
return some_value
}
int main()
{
char *s = "ABC";
moving(&s);
// do something
// и тут у меня вопрос. указатель уже стоит где-то, но не в начале строки, как мне теперь пользоваться этим указателем, если он хуй знает где? Норм практика? Или создовать доп. указатель, который можно двигать внутри другой функции, а оригинальный, что бы оставался только для использования в данной функции?
return 0;
}
Блять, две звёздочки - это же жирный текст. Надеюсь, понятно в чём вопрос.
>Или создовать доп. указатель, который можно двигать внутри другой функции, а оригинальный, что бы оставался только для использования в данной функции?
А зачем ты указатель увеличиваешь? Указатель указывает на начало, а ты увеличивай переменную и прибавляй ее к указателю для обхода
str + i++
Функции moving ты зачем-то передаёшь указатель на указатель, s - это уже указатель на строку "ABC". Ну то есть так можно сделать, а в функции moving разыименовывать str, но так ты изменишь значение указателя s. Тогра придётся сохранить значение указателя перед вызовом moving, а потом вернуть его:
char ⚹s = "ABC";
char ⚹sBackup = s;
moving(&s);
s = sBackup;
Проще сделать так:
void moving(char ⚹str)
{
str += 1;
// do something with s
str += 1;
// do something with s
return some_value
}
int main()
{
char ⚹s = "ABC";
moving(s);
return 0;
}
Тогда изменение str не повлияет на s, т.к. str - это локальная переменная функции moving, которой присвоится значение s, в данном случае адрес строки в памяти.
И ещё взорву тебе мозг:
char ⚹my_func()
{
char ⚹str1 = "ABC"; //str1 указывает на строку, которая храниться в секции text и изменять её нельзя.
//str2,str3,str4 - одинаковые массивы, в них строки хранится в стэке функции и их можно изменять.
char str2[] = "ABC";
char str3[] = {'A','B','C','\0'};
char str4[] = {65,66,67,0};
str1[0]='a'; //тут будет ошибка, нельзя изменять строку в секции text
//str2,str3,str4 - можно изменять, т.к. строки находятся в стэки функции
str2[0]='a';
str3[0]='a';
str4[0]='a';
return str1; //можно возвращать указатель на строку в секции text, т.к. она останется в памяти до конца работы программы. str2,str3,str4 возвращать нельзя, т.к. они указывают на строки в стэке функции, который затрётся после выхода из функции.
}
Функции moving ты зачем-то передаёшь указатель на указатель, s - это уже указатель на строку "ABC". Ну то есть так можно сделать, а в функции moving разыименовывать str, но так ты изменишь значение указателя s. Тогра придётся сохранить значение указателя перед вызовом moving, а потом вернуть его:
char ⚹s = "ABC";
char ⚹sBackup = s;
moving(&s);
s = sBackup;
Проще сделать так:
void moving(char ⚹str)
{
str += 1;
// do something with s
str += 1;
// do something with s
return some_value
}
int main()
{
char ⚹s = "ABC";
moving(s);
return 0;
}
Тогда изменение str не повлияет на s, т.к. str - это локальная переменная функции moving, которой присвоится значение s, в данном случае адрес строки в памяти.
И ещё взорву тебе мозг:
char ⚹my_func()
{
char ⚹str1 = "ABC"; //str1 указывает на строку, которая храниться в секции text и изменять её нельзя.
//str2,str3,str4 - одинаковые массивы, в них строки хранится в стэке функции и их можно изменять.
char str2[] = "ABC";
char str3[] = {'A','B','C','\0'};
char str4[] = {65,66,67,0};
str1[0]='a'; //тут будет ошибка, нельзя изменять строку в секции text
//str2,str3,str4 - можно изменять, т.к. строки находятся в стэки функции
str2[0]='a';
str3[0]='a';
str4[0]='a';
return str1; //можно возвращать указатель на строку в секции text, т.к. она останется в памяти до конца работы программы. str2,str3,str4 возвращать нельзя, т.к. они указывают на строки в стэке функции, который затрётся после выхода из функции.
}
 28 Кб, 309x846
28 Кб, 309x846>А зачем ты указатель увеличиваешь?
Ну у чувака на кодварс увидел такое использование и решил узнать, это ж ведь хуёво, что он двигает указатель в другой функции, просто что бы перебрать строку.
>>466384
Мне интуитивно кажется, что лучше по максимуму пользоваться указателями, для манипуляции нелокальными переменными.
Скрин части решения чувака, которое я привёл в пример, может я что-то не так понял.
>это ж ведь хуёво
Нет, он там строку парсит, поэтому двигает указатель на следующий терм, что бы скормить его другой функции. Это норма для парсинга.
Так если я дальше буду использовать этот же указатель внутри функции main дальше где-то в коде, например, а он будет перемещён другой функцией?
ну да, зависит зачем он тебе нужен, если нужен сделай копию
 131 Кб, 1502x745
131 Кб, 1502x745Блять, и в правду, а как это работает?
Ведь по идее, что str1 это статический массив, что str2, мы же не выделяли память. При этом под строку "ABC" аж память в секции данных выделили.
 82 Кб, 850x833
82 Кб, 850x833В теории казалось не так сложно, а потом я засучил рукава...
Раздражает, что даже при присутствии некоторой модульности (нечто похожее на интерфейс в виде VTables, а часть функционала вынесена в отдельные исходники), всё всё равно взаимосвязано, и мне нужно либо выдирать, либо реализовывать взаимосвязи. И все их нужно учесть...
Твёрдое чувство хаоса испытываю я, глядя на этот сишный код. И если обычно с ним можно смириться, то тут я по факту обязан рефакторить всю эту хуйню.
Мне кажется, нормальные люди не стали бы делать то, что делаю я.
Но при этом мне кажется, что я должен уметь так делать, если хочу право называть себя опытным огурцом и вообще сеньором (а я хуй знает кто).
держу в курсе
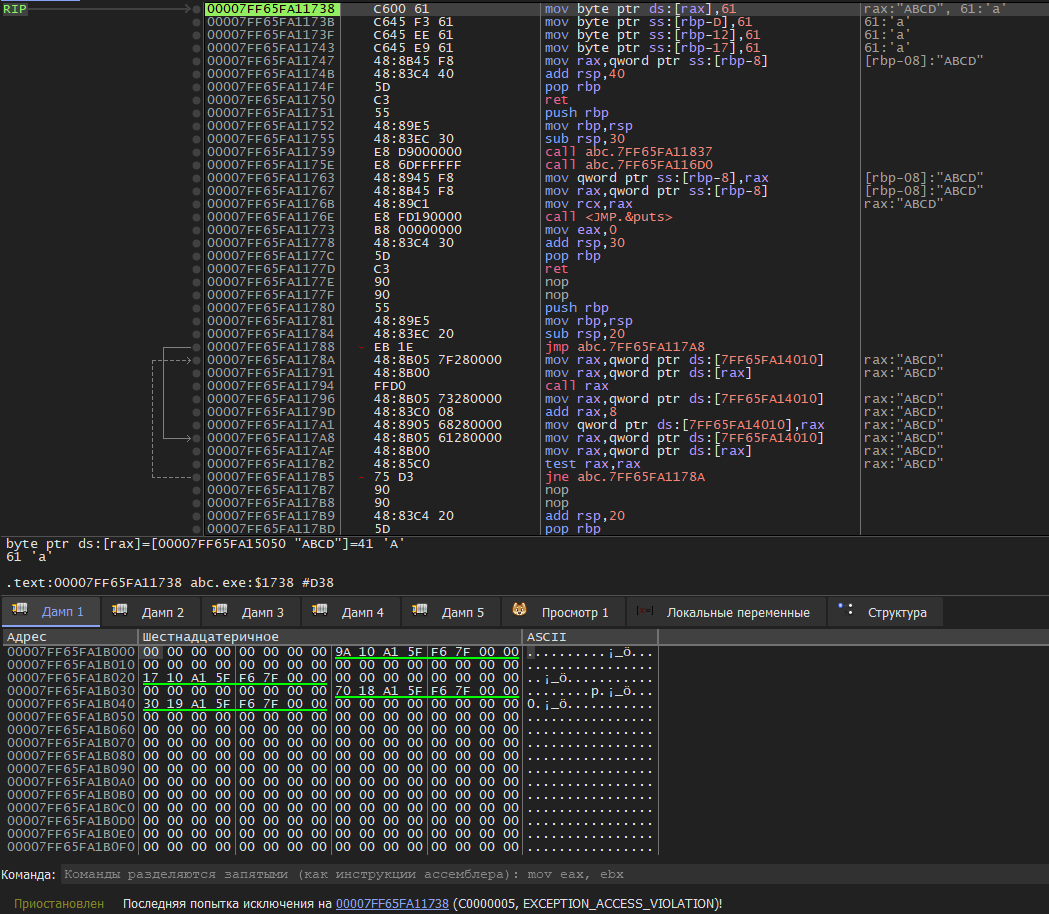
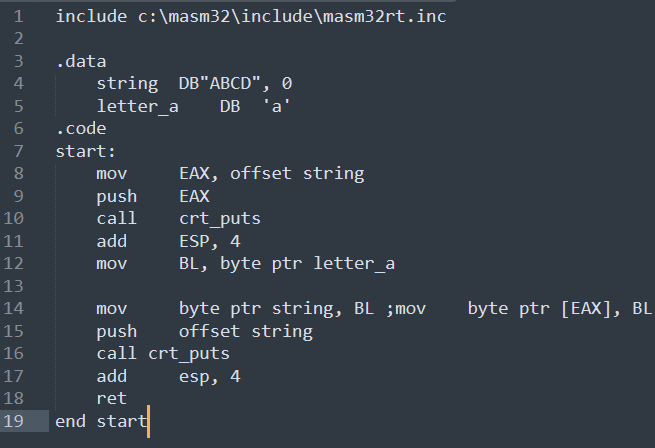
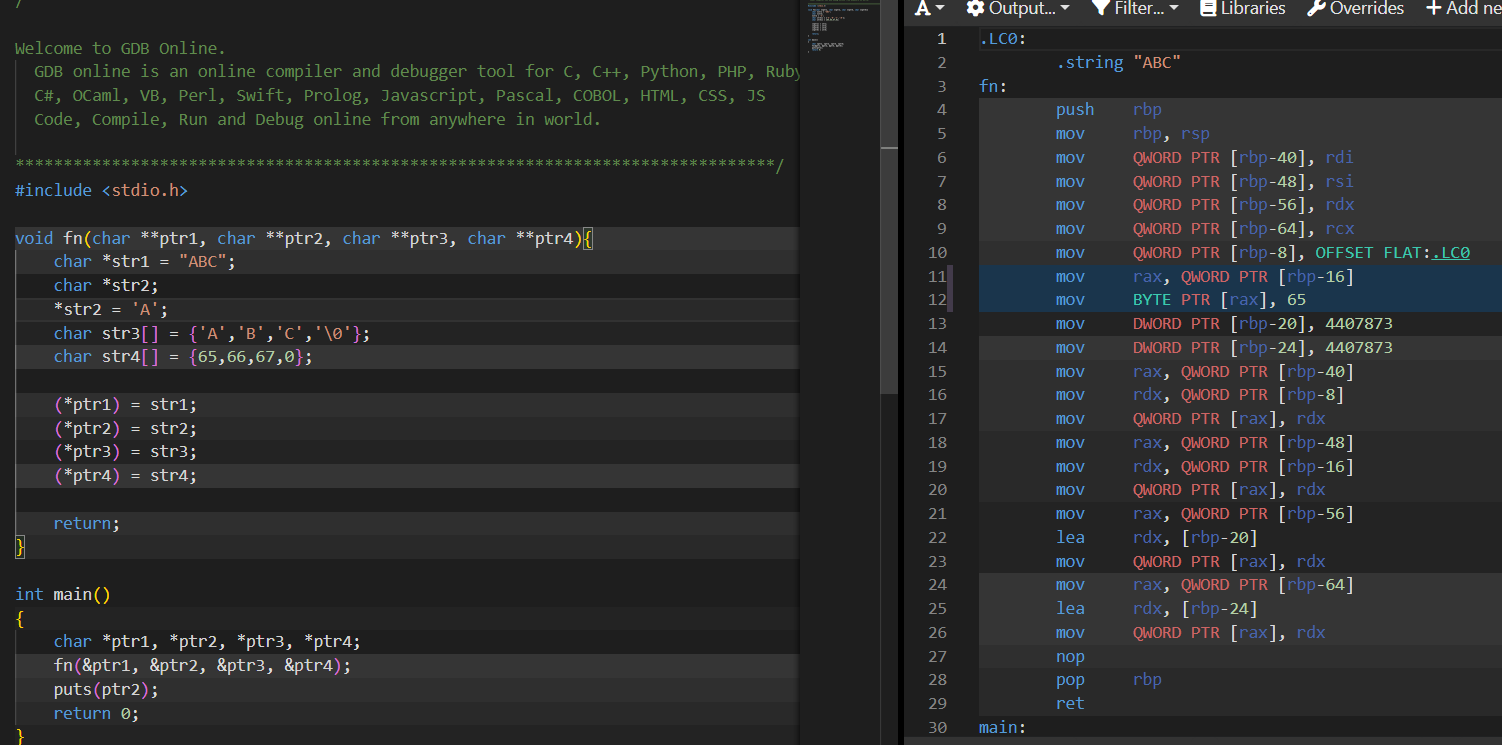
Спасибо, анон. Не знал...
Но теперь я понял, что ассемблер вовсе не понимаю, см. 14 строчка - почему я не могу записать по адресу string, который хранится в регистре EAX, один байт. Но могу записать если пропишу "mov byte ptr string, BL", потому что сегмент данных можно и читать, и модифицировать.
Пиздец.

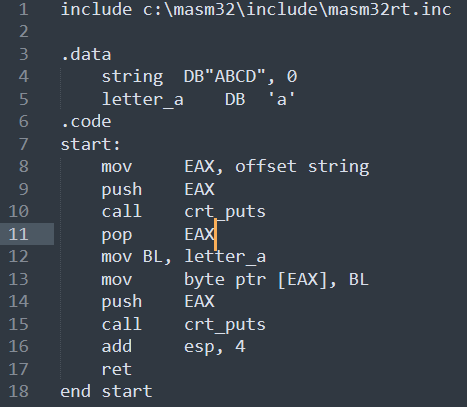
А, нет. Всё нормально, я забыл, что в процессе вызова puts значения регистров EAX, ECX, EBX и ещё каких-то могут поменяться, согласно cdecl.
Тогда не понятно почему Си код ругается. Не уж то у пользователя нет доступа к сегменту данных программы, которую он же и запустил?
У тебя ошибка:
char ⚹str2;
⚹str2 = 'A';
Ты объявил указатель str2 и не инициализировал его, его значение может быть каким угодно.
Потом ты по этому неинициализированному указателю записываешь ASCII код буквы A.
Т.е. ты в непонятно какой адрес памяти записываешь значение 65.
И ещё, строки, на которые указывают str3 и str4, пропадут после выхода из функции fn т.к. они расположены в её стэке. Поэтому нельзя их использовать за пределами этой функции, а ты присваиваешь указатели на эти строки указателям ptr3 и ptr4, которые будут использоваться вне функции fn.
>str1 указывает на строку, которая храниться в секции text и изменять её нельзя.
В любую секцию можно и писать и читать и выполнять (все зависит от флагов, компилятор за тебя решит или сам явно укажешь), да и к тому же секция .text обычно не имеет констант, хех. Тогда уж лучше было бы написать const char. Хотя конечно стоит уточнить что и не всегда строки пишутся в секцию, компилятор может и решить, что лучше прямо посимвольно нахуярить, или числом.
>char str2[] = "ABC";
Здесь тоже самое что и с str1, но шанс оказаться в секции данных выше.
>char str3[] = {'A','B','C','\0'};
Здесь да, компилятор скорее всего посимвольно грузанет все в стек.
>можно возвращать указатель на строку в секции text
Лучше не стоит
Итог: переходите на плюсы и не ебите себе мозги
>str1 указывает на строку, которая храниться в секции text и изменять её нельзя.
>В любую секцию можно и писать и читать и выполнять (все зависит от флагов, компилятор за тебя решит или сам явно укажешь), да и к тому же секция .text обычно не имеет констант, хех.
Строковый литерал хранится в read-only секции с кодом. Может быть, в каком-то конкретном компиляторе в неё и можно писать, но в общем случае нельзя.
>char str2[] = "ABC";
>Здесь тоже самое что и с str1, но шанс оказаться в секции данных выше.
Здесь создаётся массив в стэке функции и инициализируется строкой. Строка находится в стэке.
>можно возвращать указатель на строку в секции text
>Лучше не стоит
Строка никуда не пропадёт до конца работы программы, указатель на неё можно передавать куда угодно.
>Итог: переходите на плюсы и не ебите себе мозги
Иди к Линусу Торвальдсу со своим C++.
> Строка находится в стэке.
Там анон про другое наверно говорил, что в str2 будет так: memcpy(stack_str2, offset_blabla, 4)".
А в str3 так:
stack_str3[0] = 'A';
stack_str3[1] = 'B';
stack_str3[2] = 'C';
stack_str3[3] = 0;
>Практически - все эти сисколы не задокументированы
Все уже давно задокументировано, просто источники не всегда очевидные.
>непонятно как они работают
10 минут на дебаг потрать и все станет ясно как день.
>Поэтому, на винде можно пользоваться только kernel32.dll
В корне неверное заявление, используя сисколы иногда можно добиться 40% увеличения производительности, посмотри хотя бы в сторону файловой системы, удивишься.
>Но что он делает - я так и не смог догадаться.
Скрин посмотреть не смог. Покажи что у тебя за сисколл, если в виде номера, то тогда еще и версию винды.
Защиты имели смысл до Windows XP включительно, дальше пошла анализация блокированием доступа пользователя к его собственному компьютеру, то есть отжимание собственности пользователя в пользу корпорации. Ну а визги про стабильность/безопасность шаблонная методичка которой сто лет в обед.
> Строка никуда не пропадёт до конца работы программы, указатель на неё можно передавать куда угодно.
Куда угодно нельзя, только внутри своего приложения.
Для наноядерных ос, которые не подразумевают наличия сложной логики в ядре, все уже давно придумано - обращение к памяти только через дескрипторы. Это было реализовано в последней symbian os которая так и не вышла, ее выкинули на гитхаб.
Самая главная проблема это то что в такой системе придется все ПО переделывать, Эльбрус у которого есть аппаратная адресация в дескрипторы доказывает что практически весь код придется если не переписывать то как минимум править. Весь.
>Куда угодно нельзя
Можно куда угодно, даже вывести на экран и показать твоей мамаше шлюхе, а она передаст соседкам, указатель остается валидным.
Нейро-макака ты? Узнал тебя по шизойдным высерам.
 147 Кб, 612x684
147 Кб, 612x684https://www.programiz.com/online-compiler/18tvXjO00DmBv
 15 Кб, 422x303
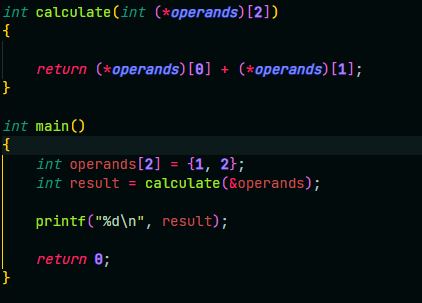
15 Кб, 422x303> это я правильно передал по ссылке указатель на массив или копией
Нет operand[] это ★operand, а ты еще его адрес берешь
Зачем в delete_list указатель на указатель в х?
 17 Кб, 371x372
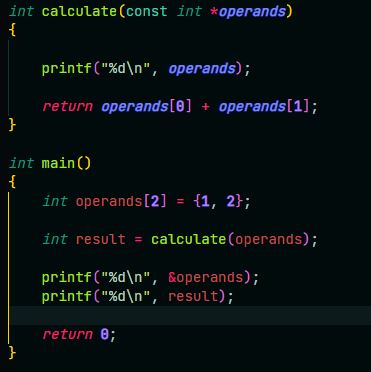
17 Кб, 371x372Спасибо. Вроде начал понимать слегка.
operands из calculate == &operands из main. Значит по ссылку передал. Ну и только что прочитал полезную вещь, что бы указать, можно или нельзя мутировать массив, лучше аргумент обозначать констом.
Как работает маппинг устройств в память? Я понимаю, что с точки зрения программиста это удобный способ работы с устройствами (я даже не знаю не гугля какие еще способы можно придумать) - берешь мануал по железке и пишешь в память. Но как оно на уровне железа работает? В памятью +- понятно - есть шина, проц физически через свои ножки и мат плату по ней команды памяти отправляет, а память их уже как нибудь да распознает. Я примерно представляю как память хранит данные, видел 100500 видов защёлок и в целом верю, что можно сделать железку которая будет согласно какой нибудь спецификации давать читать/писать себя. Но вот как мать понимает, что когда на шине идет обращение к какому то определенному региону, то нужно это каким то образом (например у меня по usb что то подключено) в другую железку отправить?
P.S я вот вижу в доке к плате, что у нее память статически размечена и некоторые части не executable. А что будет, если всё таки попробовать? Illegal instruction проц выкинет или че? Как проц должен понять, что ему нельзя оттуда читать? Или ошбку доступа к памяти? А какая вообще для проца разница executable память или нет, если он только читает/пишет в нёё? Как это ограничение реализуцется?
>Но как оно на уровне железа работает?
>Но вот как мать понимает, что когда на шине идет обращение к какому то определенному региону, то нужно это каким то образом
Да просто там декодер стоит, который бивасом настраивается и контрольными регистрами.
>Как проц должен понять, что ему нельзя оттуда читать? Или ошбку доступа к памяти? А какая вообще для проца разница executable память или нет, если он только читает/пишет в нёё? Как это ограничение реализуцется?
Конкретно про штеуд, в даташите к алдерлейку vol1:
>The Intel Execute Disable Bit (EDB), also known as No eXecute (NX) bit, is a hardware-based security feature that helps protect against certain types of malware attacks, particularly those exploiting buffer overflow vulnerabilities
Гугли детали.
Если ты про mmap system call (https://man7.org/linux/man-pages/man2/mmap.2.html), то так как это системный вызов, то предположу что работает через ядро, ядро хранит соответствие между между адресом у тебя в памяти и адресом в памями устройства и соответственно транслирует адреса туда и обратно тоже ядро.
Моё предположение.
Я бы предположил что память по указателю уже освобождена, возможно автоматически, например если ты туда передал указатель на стековую переменную, которая к этому моменту уже зачистилась
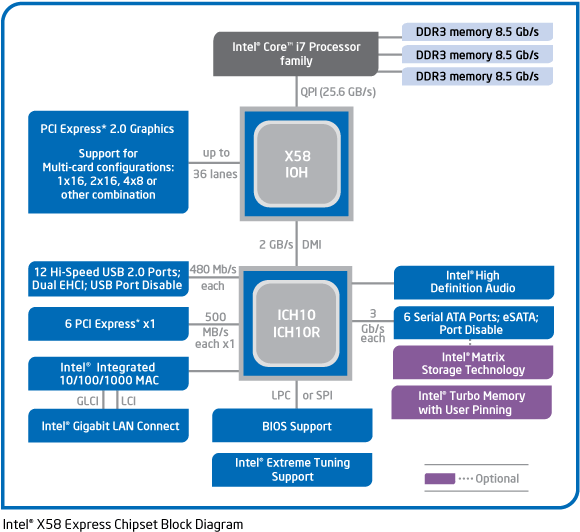
В процессоре реализована некая логика, которая определяет, на какие ножки какой адрес выставить в зависимости от того, по какому физическому адресу обратилась программа.
Например, в процессоре есть встроенный PCI и есть диапазон адресов для работы с PCI. Если программа запишет в этот диапазон адресов, процессор выставит на ножки PCI адрес, по которому записала программа минус адрес начала диапазона адресов PCI. Т.е., например, если в процессоре адреса PCI начинаются с 0xb0000000 и программа записала по 0xb0001000, то процессор выставит на PCI адрес 0x1000.
Поддержка разных интерфейсов и устройств может быть реализована во внешних контроллерах, процессор соединён с ними через какую-либо шину.
Тогда, при обращении по адресам, соответствующим этим устройствам, процессор выставит обращение на эту шину, а дальше с устройством будет работать уже внешний контроллер. В контроллере может быть сложная логика работы с устройством, а со стороны процессора это выглядит как простая запись по адресу.
Реально. Погуглил сокеты, там оказывается прям в процессоре должна быть поддержка usb, pcie
Насколько я понял не обязательно, к этому просто пришли, раньше это управлялось специальным набором чипов для периферии, назыаемым Южный мост
https://en.wikipedia.org/wiki/Southbridge_(computing)
>>471276
Ну да, как я ответил выше, чтобы в устройства можно было читать/писать простым обращением к адресу, устройства должны быть либо реализованы в процессоре (SoC или система на кристалле по-русски), либо вынесены во внешний контроллер, но процессор должен знать, как работать с этим контроллером.
Тогда логику работы с устройством можно реализовать аппаратно. Т.е. грубо говоря функцию драйвера устройства выполняет процессор или чип и программа может работать с устройством простым обращением по адресам.
Насколько я понимаю за это драйвер устройства отвечает, он знает по каким адресам писать для какого устройства
Разработчик железа знает какие он чипы куда припаял и соответственно у кого какие адреса будут, он же и пишет драйвер
Припаивает к процу производитель матери, а дрова пишет производитель видеокарты, например
Нет, так у тебя в данном случае мать абстрагирует обмен данными через интерфейсы. Например проц знает что нужно послать данные на PCI-E, мать знает что это значит послать сигнал на такие-то ноги, уже внутри этого сообщения есть команда видеокарте, в её собственном формате, с её адресами, которое формируется драйвером этой конкретной видеокарты.
Насколько я понимаю это так примерно работает.
>Например проц знает что нужно послать данные на PCI-E
Для этого нужно знать на какой адрес оно замаплено. В этом и вопрос. Куда эта инфа вшита?
OSTEP
В целом логично, наврное, если мать при запуске сначала выполняет программу в ROM, которая уже куда то сохраняет инфу о адресах, а потом проц уже использует это. Спасибо
Я уже на таком уровне совсем мало знаю, но если ты возьмёшь свой процессор и вставишь в другую материнку с таким же сокетом и он будет работать, значит как-то разводка от сокета до чипсета материнки адресует запросы?
Строго говоря наврядли сам PCI-E замаплен на адрес, скорее всего там адрес в памяти процессора замаплен на определенные ноги, запись по адресу выставляет напряжение на ногах, этот сигнал идёт к материнке, а материнка знает что с этих ног идёт сигнал на определенный интерфейс.
Но это всё неточно.
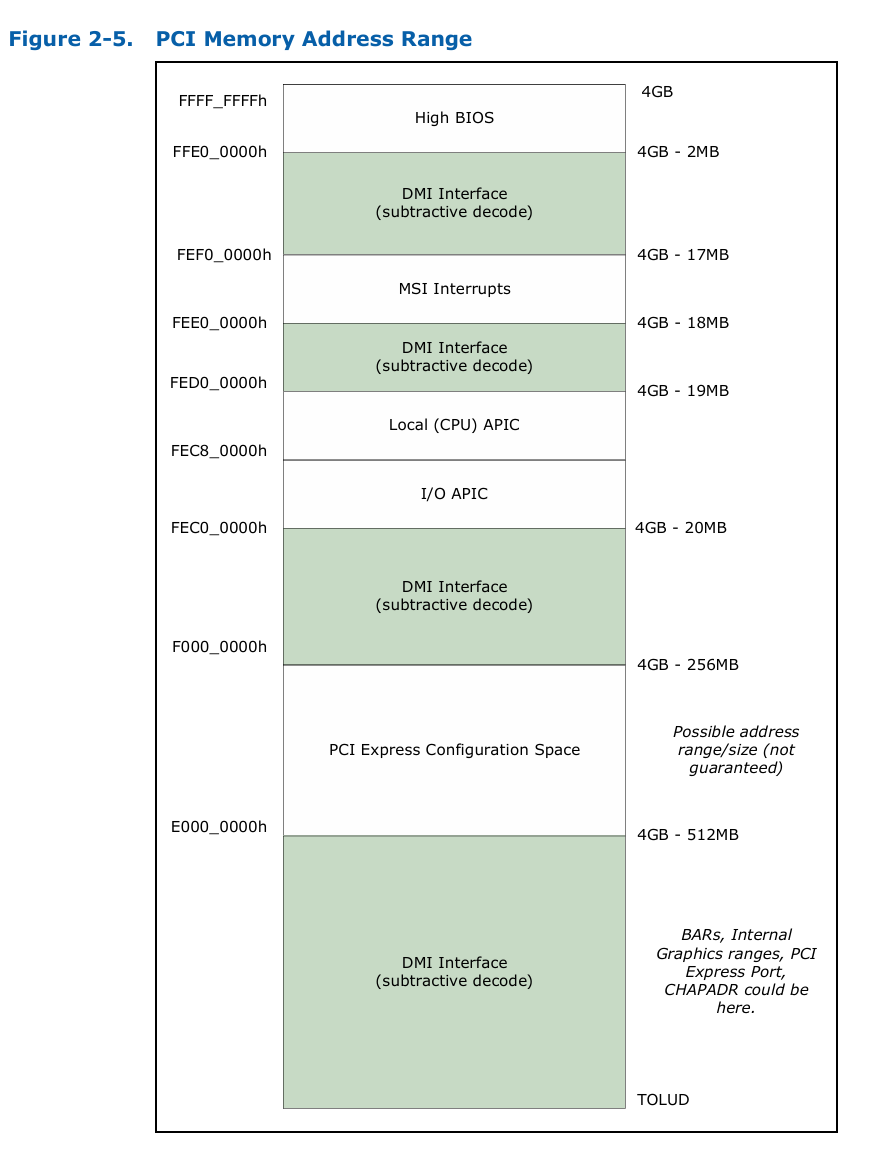
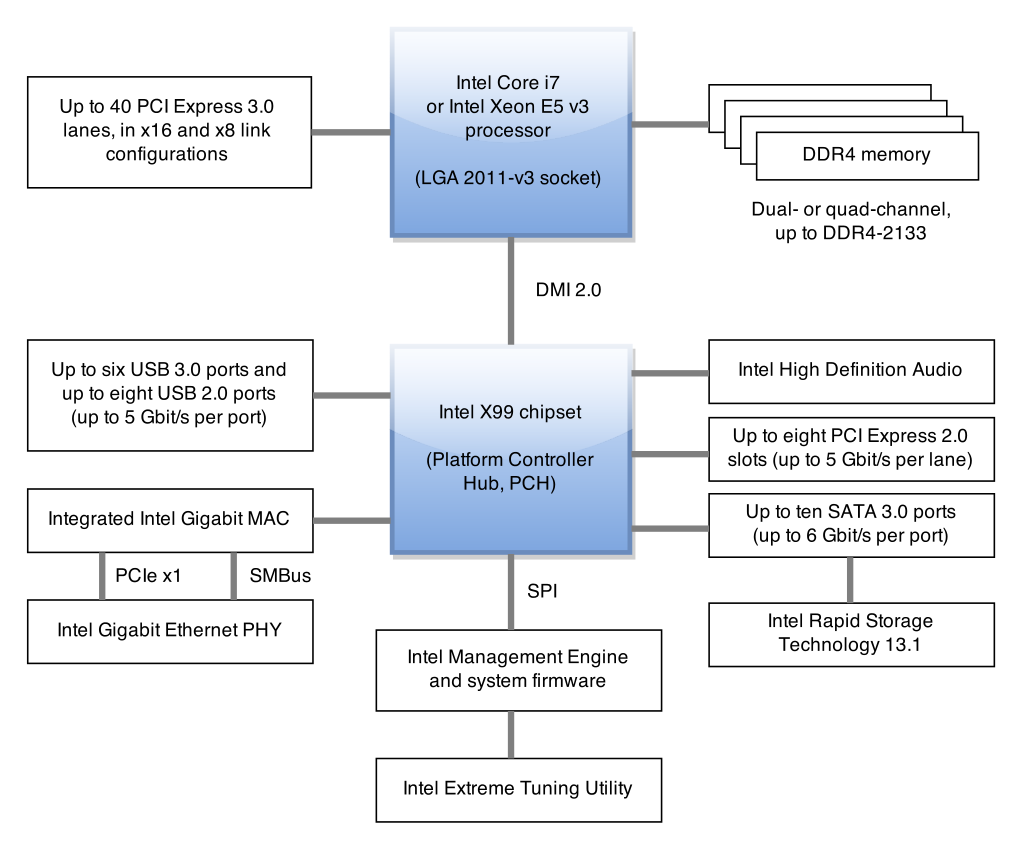
У процессора есть выделенный диапазон адресов для PCI, см. пикрил 1. Взял его отсюда (качать под VPN) https://www.intel.com/content/dam/www/public/us/en/documents/datasheets/10th-gen-core-families-datasheet-vol-2-datasheet.pdf
Смысл в том, что каждому устройству назначается диапазон адресов на шине PCI. Т.е. говорим устройству, чтобы оно отвечало только на назначенные ему адреса на шине PCI, а остальные игнорировало.
Потом драйвер обращается по какому-либо адресу из пространства PCI, процессор выставляет его на шину PCI, отвечает только то устройство, которому этот адрес был назначен.
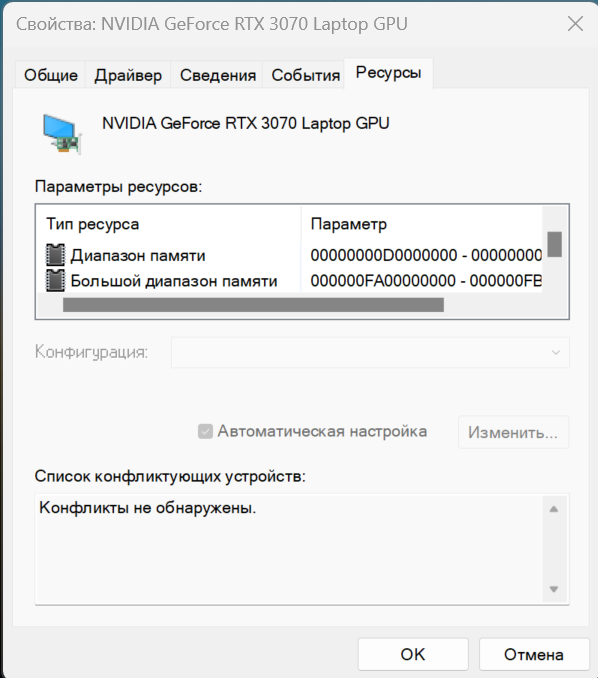
В Windows назначенный устройству диапазон адресов можно посмотреть в диспетчере устройств, см. прикрил 2.
Чтобы назначить устройству адрес PCI, используются конфигурационные транзакции.
На шине PCI для выбора устройства в конфигурационной транзакции есть отдельная линия IDSEL для каждого устройства. На материнской плате к каждому разъёму PCI идёт отдельная линяя IDSEL.
На шине PCIe в конфигурационной транзакции устройство адресуется идентификатором виде bus:dev:function, устройство отвечает только на свой идентификатор.
В конфигурационной транзакции идёт чтение/запись конфигурационного пространства PCI, его начало стандартизировано https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D1%84%D0%B8%D0%B3%D1%83%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D1%81%D1%82%D0%B2%D0%BE_PCI
Общение с устройством происходит через регистры Base Address Register, мы должны записать в них адрес на шине PCI, который хотим назначить устройству.
Например, чтобы записать в Base Address Register 0 адрес, мы в конфигурационной транзакции по смещению 0x10 записываем адрес на шине PCI, который хотим назначить устройству. Теперь устройство будет знать, что этот адрес на шине PCI относится к нему, и будет отвечать на него.
Не обязательно записывать адреса во все Base Address Register, это зависит от конкретного устройства.
Можно узнать нужный устройству размер памяти на шине PCI, нужно записать в соответствующий Base Address Register 0xffffffff, устройство ответит нужным ему размером.
Дальше общение с устройством будут происходить через адреса PCI, которые мы указали в Base Address Register, и конфигурационные транзакции больше не нужны, как и линия DEVSEL на PCI.
В x86 адреса PCI устройствам автоматически назначает Биос, поэтому операционной системе нет необходимости их назначать.
Советую почитать книгу Гук М. Ю. Шины PCI, USB и FireWire. Энциклопедия. 2005г., там описан PCI.
У процессора есть выделенный диапазон адресов для PCI, см. пикрил 1. Взял его отсюда (качать под VPN) https://www.intel.com/content/dam/www/public/us/en/documents/datasheets/10th-gen-core-families-datasheet-vol-2-datasheet.pdf
Смысл в том, что каждому устройству назначается диапазон адресов на шине PCI. Т.е. говорим устройству, чтобы оно отвечало только на назначенные ему адреса на шине PCI, а остальные игнорировало.
Потом драйвер обращается по какому-либо адресу из пространства PCI, процессор выставляет его на шину PCI, отвечает только то устройство, которому этот адрес был назначен.
В Windows назначенный устройству диапазон адресов можно посмотреть в диспетчере устройств, см. прикрил 2.
Чтобы назначить устройству адрес PCI, используются конфигурационные транзакции.
На шине PCI для выбора устройства в конфигурационной транзакции есть отдельная линия IDSEL для каждого устройства. На материнской плате к каждому разъёму PCI идёт отдельная линяя IDSEL.
На шине PCIe в конфигурационной транзакции устройство адресуется идентификатором виде bus:dev:function, устройство отвечает только на свой идентификатор.
В конфигурационной транзакции идёт чтение/запись конфигурационного пространства PCI, его начало стандартизировано https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D1%84%D0%B8%D0%B3%D1%83%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D1%81%D1%82%D0%B2%D0%BE_PCI
Общение с устройством происходит через регистры Base Address Register, мы должны записать в них адрес на шине PCI, который хотим назначить устройству.
Например, чтобы записать в Base Address Register 0 адрес, мы в конфигурационной транзакции по смещению 0x10 записываем адрес на шине PCI, который хотим назначить устройству. Теперь устройство будет знать, что этот адрес на шине PCI относится к нему, и будет отвечать на него.
Не обязательно записывать адреса во все Base Address Register, это зависит от конкретного устройства.
Можно узнать нужный устройству размер памяти на шине PCI, нужно записать в соответствующий Base Address Register 0xffffffff, устройство ответит нужным ему размером.
Дальше общение с устройством будут происходить через адреса PCI, которые мы указали в Base Address Register, и конфигурационные транзакции больше не нужны, как и линия DEVSEL на PCI.
В x86 адреса PCI устройствам автоматически назначает Биос, поэтому операционной системе нет необходимости их назначать.
Советую почитать книгу Гук М. Ю. Шины PCI, USB и FireWire. Энциклопедия. 2005г., там описан PCI.
TLB тут не при чём. Он нужен для быстрого преобразования логического адреса в физический. Т.е. чтобы процессор быстро узнал без обхода таблиц страниц, какой логический адрес в программе какому физическому адресу в ОЗУ соответствует
Может писать какие-нибудь сишные либы для питона? Ну Си наверное нигде кроме эмбеда массово не используется. Деньги в джава-крудах.
Опенсорс - маст ноу си. Полно кода на си, как коммерческого, так н коммерческого. Я например не сишник и вообще веб макака. На днях столкнулся с необходимостью писать кастомный сканер для три ситтера. Другого способа решить проблему просто нет.
Было бы желание, а задачи найдутся. Другое дело что без экспертных знаний ты врядли в сишке заработаешь на кусок хлеба, как например на питухоне.
>В крик, примерно 99.99% системного софта - это Си.
А вот и буквоед подъехал. Ну ок, крикун, раз так то думаю тогда ни у кого не составит труда грести деньги лопатой на Си, раз на нём столько софта.
Ой вей, а ведь тот софт весь поголовно в легаси моде и не развивается, а те крохи где развивается - там сидят вахтёры типа Торвальдса и туда никто не попадёт случайно. Вот ведь незадача.
Я не си фанатик, мне не нравится этот язык.
Что за дизассемблированый питон код? Питон интерпретируемый язык. Или ты из-под интерпретатора инструкции выхватываешь?
Есть IR, есть компиляторы питона. На самом деле нет строго интерпретируемых/компилирумых языков
Ну если ты не шипаешь питон программу в скомпилированном виде, то наверное он всё-таки не компилируемый.
int leaders = malloc(element_numbers sizeof(nums[0]));
У меня есть другой массив nums с количеством элементов element_numbers.
Я в массив leaders буду записывать числа и в конце, в нём будет (100%!) меньше элементов, чем в nums.
Как мне в конце уменьшить память, выделенную для leaders (malloc(element_numbers * sizeof(nums[0]));)?
free(leaders)?
Я правильно понимаю, что делает функция free?
realloc
Функция free освободит целиком память, выделенную malloc. Т.е. сообщит операционной системе, что этот участок памяти больше не используется и может быть затёрт.
Аааа, типа, я малоком себе в функции выделил памяти для локального массива, что-то с ним сделал и если я этот массив не буду возвращать из функции, то я просто очищаю через free память. Ок, спасибо.
>sizeof(nums[0])
Бля ну ты и ебанутый, ты в блокноте пишешь код что ли, нет там у тебя подсказок что это значит?
Как ты вообще в программировани на си то оказался, из какого стека/языка пришел?
Из джаваскрипт, решил попробовать ваше си. Ну и говно, как вы на этом пишете? Даже веб-фреймворков нормальных нет, кринж.
Ну вообще питон это высокоуровневое продолжение си ящитаю, а там размер строки/массива помоему вычисляется через len(str | array) но блять даже в питонологике len(nums[0]) было бы странно.

>Бля ну ты и ебанутый, ты в блокноте пишешь код что ли, нет там у тебя подсказок что это значит?
А что не так с определением размера элемента массива с помощью sizeof(nums[0])?
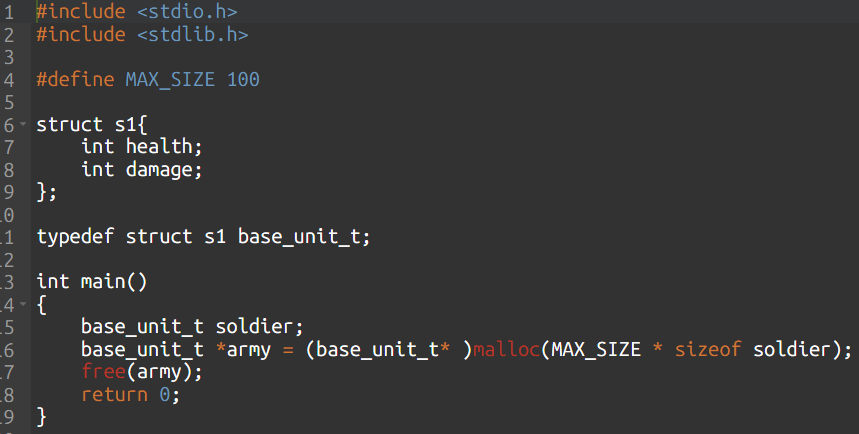
Нет ни единой ошибки на скрине, Вы просто не знаете синтаксис языка, которым оперируете.
Дебилина у тебя malloc не проверяет на переполнение либо сам проверяй либо вызывай calloc.
Со всеми паддингами структура займёт максимум байтов 12, давно ОСям стало трудно выделять 1200байт для процесса, ты из 90го капчуешь? Линукс наверное оптимизирует это настолько, что просто память в стэке выделит, ибо размер просто мизерный.
А, не заметил, что там константа.
>давно ОСям стало трудно выделять 1200байт для процесса
Не в хуилионах памяти дело, а в потенциальном переполнении буфера.
то, что ты:
1. выделяешь память для int leaders[] а в размере указываешь хуй знает что.
2. nums это просто указатель который можно переинтерпритировать как угодно в массив байтов.
3. sizeof съест препроцессор, а вот что делать с nums[0] компилятору придется решать, или убрать и сделать вид что никаких чтений перед вызовом небыло или въебать чтение которое потенциально может привести к падению (вдруг так задумано разработчиком).
Блять, у нас тут в треде кто-то включил LLM для кода, поздравляю.
Только ЛЛМ могла выдать такую хуйню, ибо ей не хватает контекста кода, хотя по факту тут можно спокойно додумать, да и вопрос юзер_нейма вообще не в этом заключался.
ВЫРУБИТЕ ЛЛМ, БЛЯТЬ, СУКИ!
Мозги себе вруби, шизойд, или отложи в сторону си и не подходи к нему на пушечный выстрел. На пистоне лабай, там есть защита от мартышкокодинга.
Какую хуйню, клован? Ты вместо того что бы написать int[] A = malloc(n × sizeof(int)) как нормальные люди, положил грабли, которые простоелят тебе ноги в любой непредвиденной ситуации, и ты будешь бегать с горящей жопой по коду кумекать что же не так и не найдешь. Ты высрал уродливый просто потому что ты так привык, потому что ты макака, которая не заботится о читаемости безопасности и производительности. Не пиши на си больше, от тебя гоVNой воняет.
Потому что ты не сделал приведение типа, ибо malloc возвращает void*.
Ты реально LLM какая-то, а не живой человек.
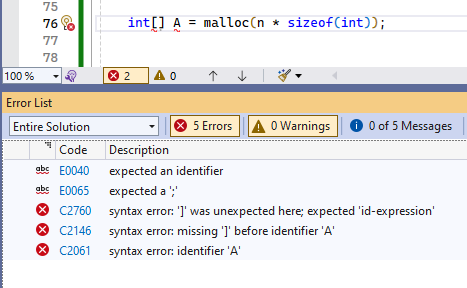
У тебя перед вызовом функции, идёт вычисление выражения, промоушен первого аргумента идёт до size_t типа, можно подобрать n, чтобы произошёл wrap around, в итоге в качесвте аргумента будет использовано меньшее значение, чем ожидаемо.
Вот это ты говна на вентилятор накинул. Согласен с тобой, что sizeof(num[0]) - не Сишный код, а больше к простым языкам, где думать надо меньше (типа жс), я просто ещё не выработал привычки к sizeof(TYPE), так как реально пришёл из жса в котором массивы типизировать не надо. (Хотя обожаю ТС, но привычки ещё не выработал, да). Ну и вопрос был действительно не в этом, но тем не менее спасибо.
>>473179-кун
Это ошибка синтаксиса тогда, а не баг
Если питон это высокоуровневый си, то жс это высокоуровневые плюсы, тебе лучше туда. Поймешь очень много о жс, например почему у него так все устроено что нет проверки типов , хотя у ts все по другом это уже всетаки другой язык ближе к сишарпу, если не сказать что просто с него срисованый.
Я нюхаю Си, что бы МК программировать. Всё остальное (ну кроме Си++ и асемблера) требует ещё свистоперделки, которые в МК память занимают, да и на Си больше примеров/либ и т.д, чем на условном микропайтоне, а жс вообще только специальные платы поддерживают пока что. Хотя программировать на ТСе микроконтроллеры было бы пиздато, но это не подходящий инструмент вообще.
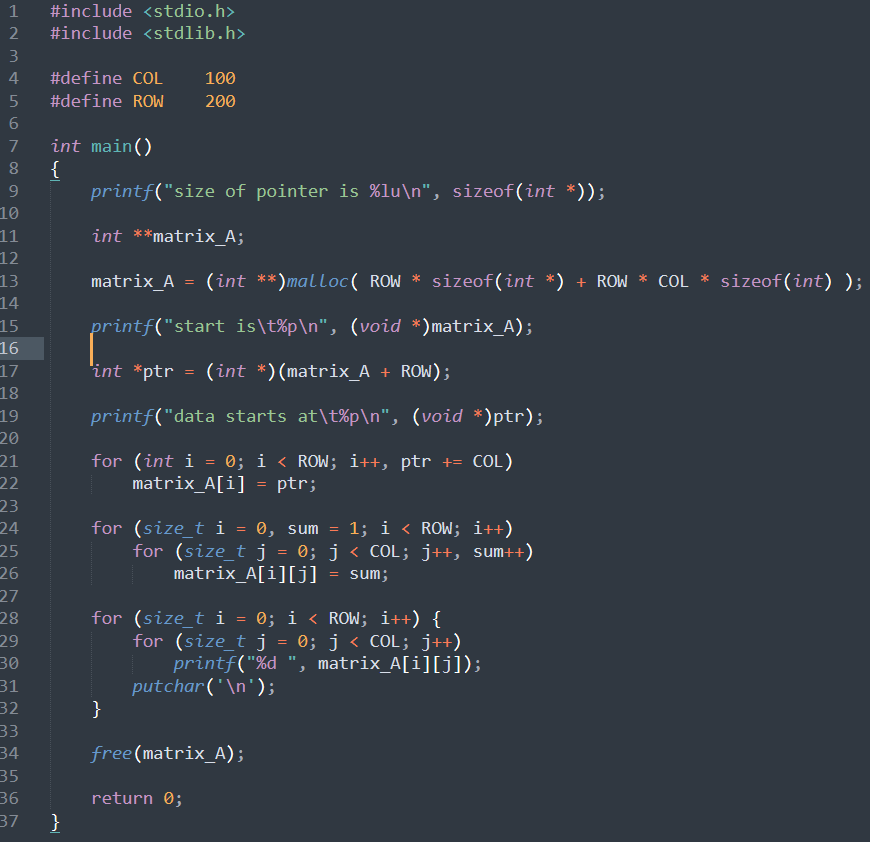 79 Кб, 870x842
79 Кб, 870x842Ну это да, плюсовые библиотеки не для контроллеров, хотя где то смотрел жалобы эмбедщиков что заебало с сишкой дрючится, напряглись они и написали патч или скрипт сборки собирающий минимальный набор получили libstdc++ в 500кб что все равно как бы много по сравнению с сишными либами 300-100kb, но им вроде как норм.
М-ля, ну, так-то факт, но, типо, его легко спутать с функцией, ибо обычно в попсовых источниках его использование описывают как size( [type] | [object] ), опуская, что можно писать sizeof object, и не говоря, что "результат" превращается в константы времени компиляции.
Ну, и это больше спор про синтаксис языка, что пиздецки сложно и требует изучения конечных автоматов и дохуя еболы, я с интересом такое читаю, но сам остановился на дискретной математике, поэтому мимо.
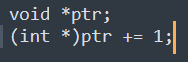
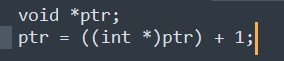
Для меня вообще обидно, что в Си
нельзя сделать пик1, только как пик2 можно.
Ты мошоночный сосатель, иди нахуй.
Типичный сишник?
(https://lloydrochester.com/post/c/list-directory/#:~:text=Use%20the%20glibc%20scandir%20function,alphasort()%20glibc%20standard%20function.)
(https://learn.microsoft.com/ru-ru/windows/win32/fileio/listing-the-files-in-a-directory)
Я походу не понял твоего вопроса, ибо гуглится всё достаточно легко.
Придётся использовать функции, специфичные для конкретной операционки.
Как для Windows не знаю, а для Unix вот https://firststeps.ru/linux/r.php?20
Потому что си не питон
Потому что, внезапно, это функции привязанные к определённым ОСям со своей спецификой работы. В Си даже работа с файлами нельзя назвать универсальной, ибо помню кодил функцию для открытия, чтения и записи, чтобы отлавливали все ошибки и писали в stderr/лог. файл. Так даже там возникла сложность в том, что под Windows приходилось после fwrite дополнительно делать fseek, ибо указатель упорно не хотел сдвигаться, самое смешное, что даже ftell показывал, что указатель на дескриптор файла сдвинулся, но а по факту нет, вот...
А ты хочешь, чтобы была универсальная функция для работы с каталогами! И так большинство функций в итоге оборачиваться либо в системные вызовы, либо в вызовы WinAPI, чтобы просто байты в эмулятор консоли вывести.


Всё так и есть, и чем дальше, тем хуже.
20 лет назад на компе с 1Гб оперативки я мог играть в Max Payne 2, Far Cry, Half-life 2, Doom 3, FEAR, Battlefield 2 и другие игры с передовой на тот момент графикой. Даже первый Crysis кое-как шёл.
А теперь такой комп нельзя использовать даже как печатную машинку, Windows 11 просто не заработает.
Для отображения web страниц в браузере без тормозов нужен комп по мощности, какими раньше были графические станции, на которых делали голливудские блокбастеры.
Хотя страницы не должны тормозить на Pentium 166MMX, т.к. это простая 2d графика.
Так если у тебя есть целый jar-файл, то в чём проблема декомпилировать его? Я помню как-то декомпилировал старые игрушки на кнопочные телефоны с помощью обычного онлайн-java-декомпилятора и всё было вполне читаемо.
А не легче на уровне роутера/сетевой карты перехватить пакеты через фильтр и уже что-то там делать с ними?
>А не легче на уровне роутера/сетевой карты перехватить пакеты через фильтр и уже что-то там делать с ними?
Я опишу ситуацию более подробно:
1) работаем с удаленным сервером
2) jar'ник может изменять другая группа людей, а я и ещё один человек можем лишь читать и исполнять(так настроены права)
3) так как все происходит на удаленном сервере, то делать финты с роутером тоже не могу - нет доступа к такому.
Проблему решили, но по-своему. За совет с роутера и спасибо.
> Здравствуйте.
Привет!
> Я новичок и только начал изучать си.
Удачи в этом нелёгком деле, Си очень коварный язык и чтобы на нём уметь писать БЕЗОПАСНО - надо потратить долгие и долгие годы.
> Можно ли тут задавать глупые вопросы
А почему нет? Только АИ ассистенты тебе и быстрее ответят, и понятнее объяснят.
> и не ебаться с переименовыванием переменных для более легкого чтения кода?
Искусство правильно оформления кода только в процессе работы и познаётся и лучше сразу приучаться оформлять его правильно, поскольку в дальнейшем будет трудно переучиться! Это, конечно, больше относится к своеобразной философии программирования, а не с языком Си, поэтому советую почитать совершенный код.
Ярик блять..

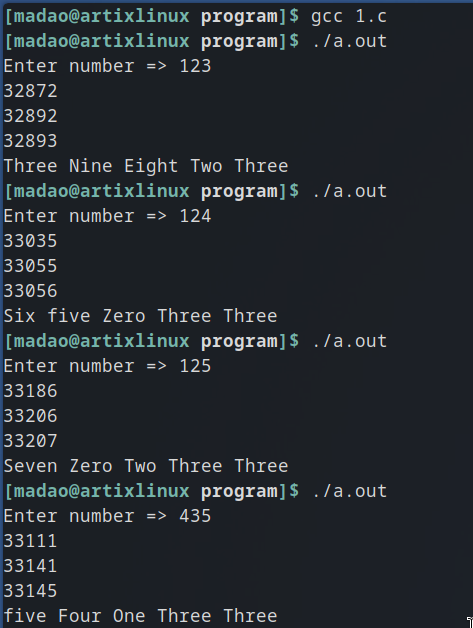
Отлично. Надеюсь смогу донести свою мысль.
В общем выполнял задание из учебника и обнаружил непонятную мне вещь, связанную с переменными.
Есть две программы.
Первая: https://pastebin.com/d7VuAM1f
Вторая: https://pastebin.com/EHmq5zFd
Первая программа это полностью законченное задание, а вот вторая это кусочек из первой программы, который я писал отдельно чтобы не путаться.
И вот у меня возникает проблема с переменной invertedNumber. Почему во второй программе можно не присваивать этой переменной никаких значений и она будет работать идеально, а первой нужно присвоить ноль, чтобы она работала корректно? Если этого не сделать и просто вставить код из второй программы в первую то результат будет отображаться как на второй картинке. В чем причина то? Это как то связанно с работой компилятора или есть более простой ответ?
Попробуй сразу после объявления этой переменной вывести её значение.
Скорее всего, там что-то уже записано.
C - работающий без всяких рантайм/vm штук. И такое может быть.
 29 Кб, 566x532
29 Кб, 566x532

Такое кековое задание на самом деле, scanf сам преобразовывает считанную строку в int значение, а мы ещё и делаем обратную операцию.
У меня в целом претензии к написанному тобой алгоритму.
Во-первых, скрин1, в Си так никто не пишет, я не пойму, ты хотел сделать И или ИЛИ, но в условиях у тебя выполнялось проверка только на b != 1.
Во-вторых, ты алгоритм плохо написал, его можно сделать в разы лучше и без переворота введённого числа.
#include <stdio.h>
int main()
{
long long unsigned number;
const char *digits[10] = {"zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"};
//size of string eq to lg(2^64 - 1) + 1
char number_as_a_string[20];
//read from terminal number
scanf("%llu", &number);
//get every digit of input number and save in array
unsigned string_length = 0;
do
{
number_as_a_string[string_length++] = number % 10;
number /= 10;
} while ( number );
for (unsigned i = string_length; i; i--)
printf("%s ", digits[ number_as_a_string[i - 1] ] );
return 0;
}
Такое кековое задание на самом деле, scanf сам преобразовывает считанную строку в int значение, а мы ещё и делаем обратную операцию.
У меня в целом претензии к написанному тобой алгоритму.
Во-первых, скрин1, в Си так никто не пишет, я не пойму, ты хотел сделать И или ИЛИ, но в условиях у тебя выполнялось проверка только на b != 1.
Во-вторых, ты алгоритм плохо написал, его можно сделать в разы лучше и без переворота введённого числа.
#include <stdio.h>
int main()
{
long long unsigned number;
const char *digits[10] = {"zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"};
//size of string eq to lg(2^64 - 1) + 1
char number_as_a_string[20];
//read from terminal number
scanf("%llu", &number);
//get every digit of input number and save in array
unsigned string_length = 0;
do
{
number_as_a_string[string_length++] = number % 10;
number /= 10;
} while ( number );
for (unsigned i = string_length; i; i--)
printf("%s ", digits[ number_as_a_string[i - 1] ] );
return 0;
}
А конкретно по твоему вопросу, тебе выше верно ответили. Когда будешь программировать на ассемблере, то даже сам будешь выделять память для переменных на стэке.
Может он на асме эльбруса будет писать а там ничего не надо выделять, даже команд таких нет что бы со стеком что то делать.
Нихуясе, а где они там хранят массивы маленькие, для которых грех вызывать выделение памяти?
>В чем причина то? Это как то связанно с работой компилятора или есть более простой ответ?
Есть. Называется undefined behaviour.
Не знаю, чесно говоря помоему и интеле/арме то это в русную не делается, все операционная система выделяет, еще и ловушки ставит чтоб за определенные границы ты не выскочил.
>так никто не пишет
Почему тогда это работает с компилятором?
В предыдущем треде кто-то показывал один финт, который поддерживается gcc, но ты крайне редко его встретишь. Это был финт с штуками вида ({...}).
А по поводу while(exp1,exp2) скажу, что gcc такое жуёт.
Так что... Или ты просто не знаешь спецификаций C для отдельных компиляторов, или просто тролль.
Мужик, ты делаешь буквально лишнее сравнее, которое умный оптимизирующий компилятор убирает, я поэтому вопрос и занял, ты нахуя это сравнение делаешь, если оно ни к чему не приведёт?
> Это был финт с штуками вида ({...}).
То синтаксический сахар удобный, а у тебя какой-то кал в коде.
> Или ты просто не знаешь спецификаций C для отдельных компиляторов, или просто тролль.
Лол, тролль походу тут только ты, буквально два сравнения делаешь, при котором одно ни на что не влияет в последующем, а ещё выёбываешься!
> своими глазами видел массив на стэке.
Как ты его видел?
> Сегфолты это не то же самое, что проверки выхода
Шизойд блять.
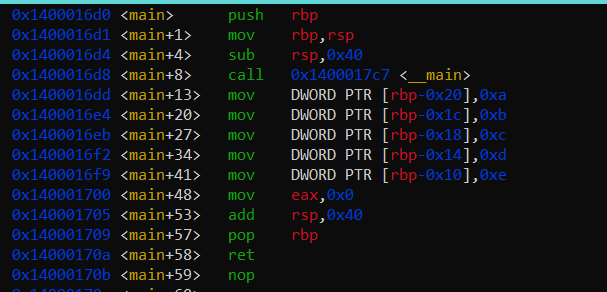
> Как ты его видел?
Видел его в стэке, лол. В x64dbg лень открывать.
> Шизойд блять.
Лол, поясняй давай.
 159 Кб, 646x1405
159 Кб, 646x1405>Во-первых, скрин1, в Си так никто не пишет, я не пойму, ты хотел сделать И или ИЛИ
Да, сглупил тут. Совсем забыл про закорючки && и ||. Как вернусь домой поправлю код.
>Во-вторых, ты алгоритм плохо написал, его можно сделать в разы лучше и без переворота введённого числа.
Массивы будут изучаться в следующей главе, так что их использовать нельзя. Применял только то что было изучено в предыдущих главах.
> Массивы будут изучаться в следующей главе
Об этом не знал...
Что ж, тогда рекурсивные функции!
#include <stdio.h>
void print_digit_as_a_string(long long unsigned number)
{
if ( number ){
print_digit_as_a_string(number / 10);
unsigned char digit = number % 10;
switch (digit) {
case 0:
printf("zero ");
break;
case 1:
printf("one ");
break;
case 2:
printf("two ");
break;
case 3:
printf("three ");
break;
case 4:
printf("four ");
break;
case 5:
printf("five ");
break;
case 6:
printf("six ");
break;
case 7:
printf("seven ");
break;
case 8:
printf("eight ");
break;
case 9:
printf("nine ");
break;
}
}
return;
}
int main()
{
long long unsigned number;
//read number from terminal
scanf("%llu", &number);
//print every digit of number
if ( number ) {
print_digit_as_a_string(number);
putchar('\n');
}
else
printf("zero\n");
return 0;
}
> Массивы будут изучаться в следующей главе
Об этом не знал...
Что ж, тогда рекурсивные функции!
#include <stdio.h>
void print_digit_as_a_string(long long unsigned number)
{
if ( number ){
print_digit_as_a_string(number / 10);
unsigned char digit = number % 10;
switch (digit) {
case 0:
printf("zero ");
break;
case 1:
printf("one ");
break;
case 2:
printf("two ");
break;
case 3:
printf("three ");
break;
case 4:
printf("four ");
break;
case 5:
printf("five ");
break;
case 6:
printf("six ");
break;
case 7:
printf("seven ");
break;
case 8:
printf("eight ");
break;
case 9:
printf("nine ");
break;
}
}
return;
}
int main()
{
long long unsigned number;
//read number from terminal
scanf("%llu", &number);
//print every digit of number
if ( number ) {
print_digit_as_a_string(number);
putchar('\n');
}
else
printf("zero\n");
return 0;
}
>ты делаешь
Не я.
>синтаксический сахар удобный
Тут тоже выходит некоторый синтаксический сахар, который позволяет сделать осуществление какой-то операции(к примеру, вызова процедуры) каждую итерацию, а уже потом какое-нибудь сравнение. Так что твоя претензия "синтаксический сахар удобный" и твоё "так никто не пишет" выглядят странно.
>тролль походу тут только ты
Ничуть.
>два сравнения делаешь, при котором одно ни на что не влияет в последующем
1) не я
2) прочти выше.
>а ещё
Да-да... Я выделываюсь, а не ты - человек "так никто не пишет".
 35 Кб, 1768x234
35 Кб, 1768x234Честно признаться, то я никогда не видел код, где использовался бы этот модификатор.
> load операции
Это что?
> sequence point
О, узнал новую подтему, спасибо.
P.S. проверил листинг ассемблера при ключе оптимизации -O2. проверки на то, что number больше нуля - нет, модификатор добавил. Но зато есть запись этого самого числа number в регистр EAX, это и есть load операция?
Всё, операцию присваивания не узнал, сразу в петухи попал, пиздос.
Кто в РФ и РБ вообще говорит load operation?
Там перед фразой про load которую ты бегаешь надрачиваешь была другая, очень важная часть предложения, которую ты или не понял или проигнорировал по причине рассеиного внимания.
Тебе с такими проблемами ни за си ни за руль нельзя, только за хуй браться можно.
min max обычно макросами реализуют типа:
#define _MIN(a, b) (a)<(b)? (a):(b)
#define _MAX(a, b) (a)>(b)? (a):(b)
Это если у тебя простые целочисленные типы.
Использовать функции мат библиотеки необходимо только в следующих случаях:
1. У тебя вещественные числа в которых могут быть всякие NaN и Infinite (если не предполагаются то смотри сам что удобнее, по идее в процессоре есть инструкции для вещественных min/max, библиотека скорее всего просто их модсунет вместо функций).
2. У тебя вектор из нескольких элементов (правда это уже наверное интринсики надо подтыкать а не мат библиотеку).
Собери всякую такую общую хуйню в зоголовочный фаил, например defines.h в нем обязательно пропиши
#ifndef _DEFS_H
#define _DEFS_H
// ... Тут все твои дефайны (точнее общие для всех исходников, типа MAX_INT итд, локальные сюда выписывать лучше не надо)
#endif
И да инклюдить в те файлы где что то из этого используется.
>Кто в РФ и РБ вообще говорит load operation?
Любой, кто программирует под load/store машины?
Бля, ебал я в рот ваше программирование.
Лишним знание C точно не будет, даже если использовать его не будешь в работе. У Столярова вроде хорошие книги, но сам их глубоко не читал.
Столяров это который в городке играет или который древнюю развитую цивилизацию ищет?
>Сап. Слышал, что C это "база" и его надо знать всем. Насколько правда
Ни на сколько. На 0%. Всем знать точно не нужно. Знание С никак не поможет "лучше освоить" python/java/php/c#/golang. Если тебе показать внутрянку какого-нибудь питона, ты нихуя не поймёшь. Там миллионы строк кода. Если так судить, то ассемблер ещё "базовее", потому что он ещё более низкоуровневый чем С. А машинные коды ещё "базовее" чем ассемблер. Так можно дойти вообще до проводов. Смотри - там нейтроны позитроны летают. Вот это надо изучать, а не это ваше программирование!
Ассемблер это уже ISA+API конкретной машины, а си это язык программирования, который можно компильнуть под что угодно, питон нельзя, его на микроконтроллерах, и голанга там нет. А си есть и поэтому он база, хотя я тоже против того чтоб его изучали первым (то есть с него начинали) и высирали на нем школокод.
Ни о чём не говорит. Проблемы с которыми сталкиваются программисты на С не имеют никакого отношения к высокоуровневым языкам - python/java/php/c#/golang. Высокоуровневый программист вообще не думает о таких вещах как управление строками или конкатенация строк. Или когда переполняется int. Или когда дважды освобождается память free() free(). Если ты сам не можешь объяснить зачем тебе си, то он тебе и не нужен. Приведу пример: я хочу сделать автономный дрон с функцией SLAM. Тогда имеет смысл изучать. А просто учить "на всякий случай" - тупо.
>как управление строками или конкатенация строк.
>Или когда дважды освобождается память free() free().
Как хорошо, что есть плюсы с удобными контейнерами в стандартной либе, которые всё это жуткое байтоёбское говно надёжно прячут у себя в кишках в 99% случаев.
>Высокоуровневый программист вообще не думает о таких вещах как управление строками или конкатенация строк.
Т.е. такими вещами никакой высокоуровневый программист не занимается? Даже в python никто так не делает?
>Или когда переполняется int.
На высокоуровневых языках тоже бывает переполнение типов. В java такое есть.
А вот как бывает при переполнении целого типа в php:
Если PHP обнаружил, что число превышает размер типа int, язык будет интерпретировать число как float.
>>490341
>Если ты сам не можешь объяснить зачем тебе си, то он тебе и не нужен.
Согласен с таким. При этом на всяких направлениях в вузах с началом кодировки на 01, 02 и 03 постоянно преподается C на первом курсе, а потом со второго и далее почему-то все задачи решаются python'ом и кучей библиотек или всякими специальными программами. При этом у всех какой-то культ C/C++.
Вот прямо знать знать - нахуй не нужно. Но какое-то поверхностное понимание иметь стоит, всё-таки большинство языков используют C-подобный синтаксис.
Давай рпределимся с терминами. Низкоуровневый стиль программирования можно применять везде, байтоебством можно и на джаваскипте заниматься, там даже есть объект DataView для чтения бинарных структур и компилятор glsl.
Да и сам js похож на си, я как то взял сишный исходник A-law декодера для wave audio поменял только оператор переменных и оно просто заработало, все побитовые операции совпадают, (ну кроме некоторых). На джаваскрипте вообще можно было бы многое но слабая динамическая типизация не позволяет (Например в джаваскрипте все отрицательные числа на самом деле флоаты, соответственно к ним уже битовые операции неприменимы и конвертация в uint тоже не работает). Ну и jit тоже накладывает ограничения.
А что касается переполнения инта и его относимости к низкому уровню, то типизация (любая) это как раз базовый атрибут ЯВУ. В машинном коде нету типизации как таковой, там есть регистры на 32бита каждый и операции над определенными типами данных, что на эти регистры положат ему откровенно похую. Можно на вещественный регистр положить инты и сделать вещественное умножение, можно вещественное число положить на целочисленный регистр и поменять ему знак например или сделать невалидным сохранив экспаненту. А можно f16 состряпать что все и делают для неиронок. Машине похуй на переполнение она его просто делает, а следит как раз высокоуровневая система типов напяленая на это все, и следящая что бы ты господин программист не обосрался. Она бывает строгая статическая, как вси, а бывает динамическая как в жс и пхп.
У каждой типизации свои задачи, если ты считаешь что байтики-хуяйтики и контроль за типами это сугубо низкоуровневая ебала для отсталых сишников, то получается на высокоуровневых языках в принципе ничего нельзя написать кроме веба и бизнес прикладух для бухгалтеров. Прикладные приложения требуют опускания в это все и нормальную типизацию.
1. Маллок не системный вызов.
2. На пике говнокод с перерасходом памяти и циклов на мойсив указателей. Деды писали макрос АT(i, j).
>культ C/C++
Они возможно приравнивают ето к фундаментальным знаниям, поэтому преподают. Я бы вообще не преподавал языки, чисто блоксхемами обошёлся бы, альзо, типовой выпускничок обычно не делает разницы между Си и плюсодерьмом, как так получается х3.
>Сап. Слышал, что C это "база" и его надо знать всем.
Хуяза. Всем надо знать, что существует альтернатива венде в виде линух. Дальнейшее - дроч на тяжелое наследие pdp-11.
Или так. Главное, чтобы твои min/max не ломали компиляцию тому, кто добавит твой library.h
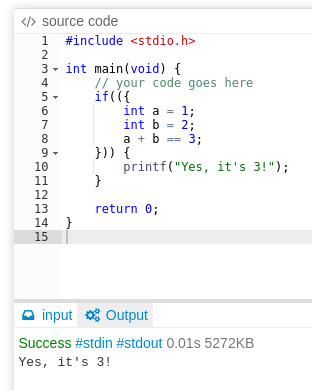 21 Кб, 312x390
21 Кб, 312x390https://ideone.com/kRDeRb
1. Но сводится то к API вызову и запросу у ОСи чуть-чуть памяти, который уже потом сводится к системному вызову.
2. Ну, тут да, можно убрать память под указатели на строки и обращаться с матрицей как с массивом через i * ROW + j, но с другой стороны тут появляется операция умножения, что не очень приятно тоже.
Вариант с массивом указателей может быть лучше. Там у тебя много выделений памяти маленькими блочками на каждую строку. В libpng такое используется. Памяти мало, и виртуальной вообще нахуй нет, например, в WASM под браузером. С маленькими кусочками оно у тебя на пределе может как-то прочихаться, а с большим сразу на всю матрицу (например, картинку) просто упадет.
А?
Если надо порционно обработать данные, то мы просто выделим кусочек нужный и будем в него всё грузить же.
А в чём разница между тем, чтобы выделить память несколькими запросами или одним?
Под один свободного куска такого размера в куче может не быть, если она сильно фрагментирована.
А... Теперь звучит действительно резонно. Но как работают страницы памяти я так и не понял, подскажите что для этого надо прочитать, пожалуйста.
>как работают страницы памяти
Если без деталей, то адресное пространство, которое видит твое программа или ты в отладчике, называется виртуальным, оно транслируется в физическое (адрес на пинах микросхем ОЗУ) блоками по 4 килобайта - страницами. Транслируется по таблице, то есть тупо через массив. Дает операционке всякие плюшки при работе с памятью, например, очень сильно и быстро увеличивать длину уже выделенных блоков (realloc) без полного копирования, или через метож "копирование при записи" быстро выделять огромные массивы, заполненные нулями, которые при этом в физической памяти ссылаются на одну единственную страницу из нулей. Полезная штука, но realloc, например, НЕ используется в крестовой стандартной либе. Разницу видно, когда пытаешься большие данные провернуть на питоне - он всю систему тормозит, или на крестах - работает помедленнее, но меньше затрагивает другие процессы. Но последнее это может быть мое субъективное.
 107 Кб, 1169x617
107 Кб, 1169x617Никогда не спрашивайте у женщины про ее возраст, у бизнесмена - про размер его доходов, у низкоуровневого кодера - про его код.
Тру-сишников один на 1кк. Тру-сишник всё с нуля пишет и дрочится с FPGA.
"Покажи мне свой хуй" - самая неудобная просьба для джаваскуфника.
Никогда не спрашивайте у женщины про ее возраст, у бизнесмена - про размер его доходов, у банкоуровневого кодера - что у него под пузом.
>Стивен Прата
Книга не полная. Не рассматривает многопоточка и многие сложные темы тоже пропускаются. Это скорей учебник для абсолютных новичков, кто не знает основ программирования. Автор учит не сколько языку Си, а сколько базовым алгоритмам: поиск, сортировка, связные списки и т.п. Для людей знакомым с программированием книга будет душной, т.к. 90% они уже знают.
Соглы лучше 99штандарт пусть читают заместо Праты.
Что перспективно ракать в 2к25?
Есть кхгм тенденция даже там использовать плюсы. Я долго был фонатом чистого си, но работа навела на мысоль, что классы и абстрактные коллекции (пусть неэффективные) лучше иметь из коробки, чем создавать их снова и снова из жвачки и спичек.
>Вот это надо изучать, а не это ваше программирование!
чел, буквально так и изучают
бмстушный курс на ИУ буквально такой как ты и написал.
физика квантовых эффектов p-n переходов, реализации транзисторов, технология производства кристаллов, литография, общая архитектура процессоров, их схемотехника (включая верилог и вхдл), общая архитекутра компьютеров на примере x86, асмы, программируемые чипы, си для армов, базовые алгоритмы на сишке, потом уже жава, питон, матлаб и все остальное
Фишка в том, что выражение вида ({...}) Будет возвращать результат последней "инструкции".
Т.е. в случае с примером будет возвращаться 1, если a+b равно 3, а иначе 0.
Такая штука не всюду работает, но gcc такое точно жует.
>>493803
Да мне уже подсказали в ньюфаг-треде. Это gnu-extension, которое работает в gcc, clang и visual studio, но не работает в intel. А мне нравится эта фигня, можно в макрос передавать функцию, сделать в макросе что-то до ее вызова, вызвать ее, сделать что-то еще, а ее результат все равно вернуть. Что-то типа декораторов в петухоне.
Дак они раз создал, а потом переиспользуешь. Это как бы должно стимилировать писать подобные вещи в виде библиотеки и самому же её использовать в своих программах. У опытного сишника уже всё это есть. А новичкам полезно написать, для лучшего понимания. Вроде даже на джаве некоторые преподы рекомендуют самим писать базовые коллекции, чтобы раз и навсегда понять как они работают в стандартной библиотеке. А если будешь пользоваться готовыми, то придётся учить 100500 исключений как нельзя их применять, не понимая при этом почему это так, а когда сам реализовал, то понимание будет.
там английский крайне простой, буквально для начальной школы. перевод будет сложнее даже, так как будешь во фрустрацию впадать от переведенных терминов
https://www.open-std.org/jtc1/sc22/wg14/www/docs/n3220.pdf
если уж совсем плохо то просто скорми пдф дипсику и попроси перевод
>У опытного сишника уже всё это есть.
ну это мем 30-летней давности, у каждого сишника есть своя собственная библиотека для работы со строками
Буквально слизали с раста. А ещё это выглядит несуразно, это как в питоне добавили присваивание переменных в условиях по типу if (var := expression): ...
Совершенно противоречит семантике языка
>Буквально слизали с раста
Есть и другие языки, в которых значение блока получается из последнего выражения в нем. Они появились на десятки лет раньше раста. А вообще я лично считаю этот момент довольно разумным. Не зря его в раст взяли.
>это выглядит несуразно
Зато дает дополнительные возможности в макросах, а они местами очень нужны, поскольку C сам по себе все же довольно беден как язык.
>в питоне добавили присваивание переменных в условиях по типу if (var := expression
Добавили потому, что это было нужно и можно. Они где-то многострочные лямбды обсуждали, Гвидо или кто-то другой написал, что там пиздец с индентами получается. Это тоже нужно, но нельзя.
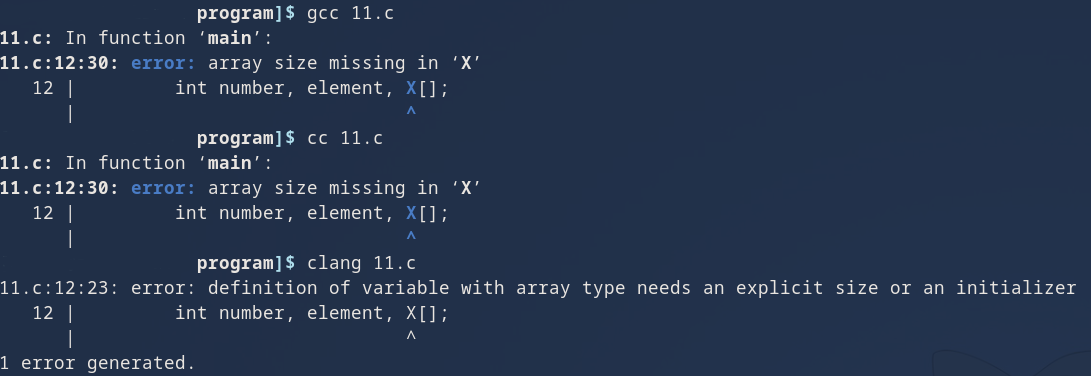 67 Кб, 1091x376
67 Кб, 1091x376Представь себя на месте компилятора, тебя юзер попросил выделить место под массив хуй какого размера, но ладно бы ещё перечислил ещё элементы этого самого массива, так юзер просто попросил выделить место в стэке хуй пойми под какой размер, вот и думай головой, что этому проклятому юзеру надо.
>технология производства кристаллов
>литография
>верилог и вхдл
>программируемые чипы
>си для армов
У нас такого не было.
мимо иушонок
>Слышал, что C это "база" и его надо знать всем
Это правда, если тебе 12 лет и ты учишься в школе. Тогда обязательно начинай с C. Если ты уже на первом курсе, то можешь посвятить 1 семестр. Если нет, то забей хуй.
физика квантовых эффектов p-n переходов, реализации транзисторов, технология производства кристаллов, литография, общая архитектура процессоров, их схемотехника (включая верилог и вхдл), общая архитекутра компьютеров на примере x86, асмы, программируемые чипы, си для армов, базовые алгоритмы на сишке, а потом уже диплом и выпускной
Поправил.
Что-то мне кажется, что под "базовостью" в этом случае понимается не близость к железу, а особенности синтаксиса. Зная C на поверхностном уровне (а то, как его изучают в начале вышки) будет куда проще учить как минимум 3 из перечисленных тобой языка.
на иу1-иу5 по идее низкоуровневая шняга должна быть обязательно, была по крайней мере 20 лет назад точно
>физика квантовых эффектов p-n переходов, реализации транзисторов, технология производства кристаллов, литография, общая архитектура процессоров, их схемотехника
На ИУ7 немного этого касаются, но только очень поверхностно, в основном все сводилось к изучению диодов, транзисторов и триггеров в схемотехнике. Про литографию и технологию производства кристаллов ничего не рассказывали, но оно и нахуй не надо программистам.
мимо иу7
Я бы больше в иу6 поверил, что там это трогают, чем на остальных кафедрах. Я тоже с 7ки, учился чуть больше 10 лет назад, у нас только физ. основы электроники были и архитектура эвм, где хоть как-то не программной части касаются. А так асм, ОС, дрова.
>Самое разумное, что это расширение, и его не тащат в стандарт
А потом код использующий это расширение, собирается только одним компилятором, классная переносимость
Какой? Как его написать? Как его потрогать? Как инициализировать его по полной? Хочу его
Это разрешается для последнего элемента структуры, но память ты должен будешь выделить сам.
Лучше свой динамический массив реализовать. Столяров кстати запретил использовать динамические массивы, которые добавили террористы-стандартизаторы.
А онлайн-переводчики не справляются? Хотя там с терминами наверняка косяки будут...
>Столяров кстати запретил использовать динамические массивы
Он сделал свой компилятор, который ругается на динамический массив?
Конвертируй pdfину в текст. И вообще, либо учи английский, либо сразу пиздуй к дегенератам в 1С тред.
>компилятор, который ругается на динамический массив
Компилятор C++.
Пишешь сишный код в .cpp и компилируешь соответственно как С++. Если что-то не компилируется, значит это неправильный С, исправляешь по стандарту С++. Заодно можешь воспользоваться например строками, которых в С нет и не будет никогда.
В С есть строки в формате массива байт, который заканчивается нулевым байтом. Это универсальный тип. Можно хранить какие угодно кодировки.
Так вот, наличие строчных литералов это опровергает. А встроенных операций над строками нет, потому что не было на pdp-11 команд типа rep movsb.
>В С есть строки в формате массива байт
Ассемблерное говно. Байты это тупо байты, ни больше, ни меньше, не являются ни чем кроме байтов, остальное пердолинг, источник жопоболи и багов из за говна костыляемого вручную бедным ущербным программистом. А я говорил про строки реализованные в языке. В Си не реализованы никакие строки и никогда не будут из за отсутствия поддержки объектов (классов).
>никогда не будут из за отсутствия поддержки объектов (классов)
Зачем нужны классы для строк?
Потому что строки не работают без кода. Чтобы сложить две строки требуется код, код в типе это классы, без классов сложные типы реализовать невозможно.
То же самое с массивами, строка это разновидность массива, в Си массивов не существует и не может существовать.
Массив это std::vector, а сишная хуета это лишь сахар над арифметикой указателя, вместо ∗(ptr+i) пишут ptr, ну и плюс делают указатель константным чтобы случайно не переписали, только толку-то хуй, всё равно запросто выходишь за пределы этого "хуйсива" который вовсе не массив. За пределы типа невозможно выйти по определению, сишная поебень это не массив, а костыль указателей, так же как ассемблерные строки не строки никакие.
>Массив это std::vector,
Жирно. Вот в Quake C или прологе действительно нет массевов. Улавливаешь разницу? Если нет, порешай задачи на одном из этих языков, потом возращайся.
>пук
Обтекай, тупое говно.
Указатели это указатели, сырая память, не типы никакие. Отсюда и проблемы дебилов лезущих в Си не понимая этого факта. Память это не шутки, "типы" через указатель это как обращение к файлам по секторам, любая ошибка и файловая система пошла по пизде вместе с данными и твоей порванной жопой, дебил. Потому что секторы это не файлы, и сишная поебень это сырая память - указатель, а вовсе не строки и массивы.
>код в типе это классы, без классов сложные типы реализовать невозможно
Почему? ФП языки же обходятся без классов, просто структуры и функции для работы с ними выделяют в модуль. В Go классов в чистом виде тоже нет.
Потому что это скрипты, а Си это язык программирования. У скрипта всё под капотом черного ящика, а программирование когда программист видит код. Разумеется можно засунуть код под капот, только это будет скриптинг, а не программирование. Программирование это дословно "программирование компьютера на некие действия", то есть "управление железом". Программист должен видеть что происходит от его действий, а вовсе сидеть как скрипто-баран и ждать результата от волшебного джина черного ящика.
>У скрипта всё под капотом черного ящика, а программирование когда программист видит код
Не понимаю. В C++ строки реализованы в стандартной библиотеке, ты её не "видишь" из своего кода, а просто вызываешь методы как чёрный ящик. В каком-нибудь функциональном языке будет точно такая же реализация в стандартной библиотеке, или вообще в самом языке. Разница только в том, что в одном языке используются классы, а в другом структуры.
>Дебич, напиши код с этой мокрописькой и собери его чем-то кроме gcc.
Блядь, уебите этого тупого мудака кто-нибудь.
>Указатели это указатели, сырая память, не типы никакие
При этом практически указатели на не совместимые типы (и не только) воспринимаются, как указатели на разные объекты.
Просто переполнение а[5] не обнаруживается. Ты еще скажи, что в Си нет чисел, потому что переполнение + не обнаруживается.
Операция а шире по возможностям, чем индексация КЛАСИЧИСКАГО массива, поэтому такие массивы есть как подмножество Си.
>в Си нет чисел
Мне в универе когда-то объясняли, что чисел там реально нет. Там скорее кольцо классов вычетов по 2^n, где n может быть равно 16/32/64.
Спешите видеть, обезьяна не понимает зачем нужны стандарты
В Си есть числа, потому что числа есть в инструкциях процессора, а вот массивов и строк в процессорах нет, вот и в Си нет. Поэтому сишка бесполезное говно без элементарных типов которые приходится костылять через жопу с охуительными багами:
> напечатал "hello"+"world"
> @
> коррупция стека с непредсказуемыми последствиями и возможностью инжектить на выполнение произвольный код
>В Си есть числа, потому что числа есть в инструкциях процессора, а вот массивов и строк в процессорах нет, вот и в Си нет.
Да, а что же тогда значат лиетралы " и [] в си?
>В Си есть числа, потому что числа есть в инструкциях процессора,
Это дебильный аргумент, потому что фичи языка могут не быть в цпу, и наоборот..
> массивов и строк в процессорах нет, вот и в Си нет.
В процессоре нет "hello\n", а в Си есть. Шах и мат!
>напечатал "hello"+"world"
Варнинг в лоб тобi.
subscript operator (это не литерал кстати) де-факто просто указывает на смещение от начала массива
В смысле что там pointer arithmetic под капотом
Для беззнаковых типов результат i+1 всегда определен, а для знаковых не всегда. Вот тебе и числа.
Ну если это просто указатели на адреса памяти, ты ты можешь написать int array[] = "string"; и всё прекрасно скомпилируется
CLion
 226 Кб, 640x640
226 Кб, 640x640Потому что компилятор откажется это компилить, а не потому что оно физически не могло бы работать, если бы скомпилилось (что ты подразумеваешь). Это какая-то непостижимая концепция для senior php.js девелопидора?
VS Code
Пробовал эти вимы-нано - жутко неудобно. Пока удобного консольного редактора не сделали.
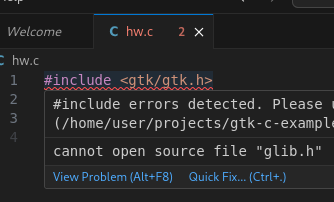
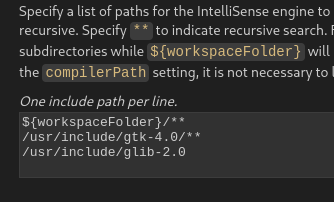
Расширение от МС? У меня почему-то ругается на #include <gtk/gtk.h>, хотя я указал где искать. Чего ему еще надо?
На голых TUI-редакторах никто не пишет, обычно берут nvim и обмазывают плагинами реально удобно реально под себя
Ну так а где у тебя сам "язык С"? Там где компилируется или там где физически работает? А, джуниор пхп девелопер?
Я тогда линупсом не пользовался, а была только винда хр, а в ней нормальные редакторы типа вижлы или борланд с++ 3.1
Представил, ну раз размер не указан, то пусть будет 0.
 7 Кб, 275x183
7 Кб, 275x183
Джаваскуф спокуха
>чем сейчас современные Си-синьёры пользуются, когда нужны стандартные структуры данных
https://github.com/nginx/nginx/blob/master/src/core/ngx_rbtree.c
Да я понял, принято велосипедить.
В nginx должен быть хороший код, чебы не спиздить от туда красно-черные деревья по Корману.

Stack is not a data structure.
В 89 же они написали второе издание по ANSI-стандарту.
ну, закрыта же, точно не сказать по публичной информации (DSL, что-то из ядра).
покрайней мере нанимают со знанием хаскеля для разработки ОС
Скидывай код, тут помогут разобраться! Но это неточно.