








 6,2 Мб, webm,
6,2 Мб, webm,1080x1080, 0:06
 737 Кб, webm,
737 Кб, webm,480x480, 0:05
 45 Кб, 749x396
45 Кб, 749x396 101 Кб, 480x640
101 Кб, 480x640Вообще в идеале твой парсер должен уметь работать, не имея всю строку в памяти, а читая куски по мере необходимости. Я себе сделал гибридный вариант:
— У парсера есть поля s: StringView (текущий буфер) + sp: SizeUint (позиция в буфере), через которые ты можешь удобно работать с куском текста в памяти. 99,8% времени этого достаточно; типичная ситуация — это тебе нужно прочитать число из 4 цифр, при этом sp = 1000, а s.n (размер буфера) = 65536, то есть всё число присутствует в памяти, и для осуществления желаемого можно так же, как с единственной строкой, натравить стандартную функцию преобразования строки в число на 4 символа в буфере, s.chars[sp..sp+3].
— Если ты достигаешь конца буфера (нужно прочитать число, но sp = 65534 и s.n = 65536 — доступны только 2 символа, и все они являются цифрами, так что неизвестно, это всё число или нет), ты вызываешь функцию ReadMore, которая читает новый блок — и, если нужно (если sp < s.n), переносит хвост старого блока, начиная с sp, в начало нового. Так что после неё s.chars[sp] продолжает указывать на начало числа, и в конце концов ты всё-таки заимеешь всё число в памяти, сведя случай к предыдущему.
Например, при разборе текста «someNumber = 1234; someOtherNumber = 5678» до ReadMore ситуация может быть
>s = "someNumber = |12"
(где | — позиция sp.)
После ReadMore она станет
>s= "|1234; someOthe"
— s[sp] продолжает указывать на начало числа, а части перед sp полагаются больше никого не интересующими и разрешёнными для отбрасывания.
 108 Кб, 1022x960
108 Кб, 1022x960

Я не знаю, у меня проблемы с мозгом. Ну точнее знаю. Что они есть.
Я вообще не понима, неужели нет никакого нормального способа перестать быть лоу айкью дауном.
 8 Кб, 1120x1120
8 Кб, 1120x1120 22 Кб, 549x408
22 Кб, 549x408Я не знаю, я постоянно на подобное напарываюсь, и можно было бы списать на то, что софт слишком сложный, чтобы избегать даже таких очевидных проблем, что это и не проблемы вовсе, а я просто придираюсь, но я сейчас задумался, что я так-то сам часть проблемы, потому что я в жизни своей никогда не создавал никаких баг репортов после того, как напарывался на подобные вещи. Ну я на английском просто плохо говорю ещё, умереть хочется, короче.
Я не знаю, что делать с таким критическим падением айкью, мне плохо, постоянно какие-то нечитаемые ошибки с борров чекером, я устал, я хочу подохнуть. Я не чувствую, что пишу то, что хочу, я чувствую, что пишу то, что хочет rustc. Вот, небольшой кусок мусорного кода https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=d997d44761f61669b3546aa13ee3c7bf я хотел сделать, чтобы advance мог скипать байты, если он выходит за границы того, что уже прочитано. Я не понимаю, как это сделать без чтения ненужных байтов в буфер и без io::Seek. Окей, есть io::copy и io::sink(), попробовал переписать https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=d6593f809fcc6f260a0d6f0e39db994c всё у меня слишком маленький айкью, чтобы понять, а что не так, зачем take мувает внутрь себя источник, откуда он читает, что вообще происходит.
Что вот мне делать, переписать, чтобы он не сам читал, а у него спрашивали, что он хочет сделать: скипнуть байты, прочесть сколько-то байтов, и потом пушили в него байты что ли, но это же бред, а может лучше просто выпилиться, потому что жить с таким маленьким айкью это просто уже невозможно.
Если прописать use std::io::Read, то всё будет работать. Или если вместо
> self.source.by_ref().take(...)
писать
> io::Read::take(self.source.by_ref(), ...)
то тоже будет работать.
Я понятия не имею, почему так. Проблема, видимо, в том, что в трейте Read есть только take(self, ...). Но в этом файле std::io::impls https://github.com/rust-lang/rust/blob/9fa6b3c15758e85657d5be051cfa57022a8bbe57/library/std/src/io/impls.rs#L17 есть отдельно реализация трейта Read для &mut Read. Но почему он сам не может разобраться, что можно использовать реализацию из impls, я не понимаю.
Минимальный пример как-то так выглядит:
https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=46d6d0474f2dd91d1b0bc33de05225b5
>>668693
Проблема не столько в расте, сколько в слишком низком айкью, который ещё и продолжает уменьшаться.
У меня появилось в мыслях, что можно было бы маркерами сделать два отдельных типа и в них сделать две отдельных реализации одного и того же метода. Но там всё равно без макросов в итоге не обойтись для реализации остальных методов, которые не зависят от того, какие трейты реализованы, но хотят вызывать методы, которые от реализованных трейтов зависят https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=52707488453b2530ddf0d268a505c477. Ну либо так https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=52707488453b2530ddf0d268a505c477 и я даже не знаю, что из этого хуже.
Но это даже не решение проблемы, что два отдельных типа приходится делать — это так-то бред.
Вообще ещё одна шизо-идея — это заставить самого пользователя реализовывать трейт Skippable. Сделать просто два макроса с двумя реализациями. Ну как, просто, там нужно будет как минимум заморочиться, если у структуры, для которой трейт реализуется, есть дженерик параметры, например. И вроде как вместе с min_specialization, которая вроде как по крайней мере не unsound, можно сделать одну дефолтную реализацию и пользователь может через макрос уточнить её https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=b878b49b9ef2210b03a6163e1c887f27. То есть в худшем случае используется дефолтная реализация.
>переписать, чтобы он не сам читал
Ну в смысле, что он не будет вызывать read, не будет владеть буфером, куда читает, а будет только по указателю, который ему дают. Наверное, это лучше, не знаю, потому что более гранулярное апи получится, которое проще переиспользовать и бла-бла-бла https://youtu.be/ZQ5_u8Lgvyk, но важнее, что мне тогда не приходится использовать трейты.
Ещё в предыдущем >>650387 варианте у меня в голове была какая-то стрёмная идея, что токенизатор должен по очереди пытаться распарсить токены, про которые он знает, и, наверное, я думал, что это сделает реализацию довольно прямолинейной и будет легко добавлять новые типы токенов, но по факту получился довольно нечитабельный код.
Во-первых, жсон токенизатор всё не должен беспокоится о валидности строк, чисел и ключевых слов по типу true или false, он просто должен проглатывать все эти вещи до следующей кавычки или до следующего разделительного символа. То есть опять же, более гранулярное апи, пусть пользователь сам разбирается с валидацией utf-16 булшита в жсон строках, что там с числами и так далее.
Ещё же тут дело в том, что если я читаю жсон, чтобы извлечь из него какую-то информацию, я, скорее всего, знаю, какая у него схема и поэтому мне необязательно нужно полностью его структуру в память сохранять. Возможно, я просто хочу получить только значения по какому-то конкретному ключу.
Во-вторых, у токенизатора должен быть контекст: находится он просто жсоне, внутри строки, числа и тд. И в зависимости от контекста он должен по-разному интерпретировать прочитанные символы. И менять контекст по ходу токенизации — это тоже ответственность пользователя: что после открывающей кавычки надо поменять контекст на строку, например.
В общем, токенизатор становится просто функцией от указателя на байты и текущего контекста.
https://godbolt.org/z/88Kfaj9os
Ну это в первом приближении, я просто хотел проверить, смогу ли я хотя бы прожевать тот же жсон.
Но что я так и не придумал, как решить — это как быть с бэктрекгингом. Предыдущий вариант состоял из него целиком и полностью, тут его гораздо меньше, но я не могу придумать, как его избежать полностью. Конкретно многострочные комментарии: когда встречаю звёздочку мне нужно либо сразу прочесть следующий символ, чтобы понять, это конец комментария или нет, либо запомнить, что я прочитал звёздочку и если после неё потом прочитаю слеш, то это конец комментария, либо читать многострочные комментарии кусками и придумывать какой-то дополнительный контекст для токенизатора, в котором он останавливается, если читает слеш, либо не хранить никакого дополнительного состояния параноидально при виде каждого слеша читать, что было перед ним.
Но это всё кривые решения, которые реализованы как какие-то исключения из правил, я хочу умереть.
>переписать, чтобы он не сам читал
Ну в смысле, что он не будет вызывать read, не будет владеть буфером, куда читает, а будет только по указателю, который ему дают. Наверное, это лучше, не знаю, потому что более гранулярное апи получится, которое проще переиспользовать и бла-бла-бла https://youtu.be/ZQ5_u8Lgvyk, но важнее, что мне тогда не приходится использовать трейты.
Ещё в предыдущем >>650387 варианте у меня в голове была какая-то стрёмная идея, что токенизатор должен по очереди пытаться распарсить токены, про которые он знает, и, наверное, я думал, что это сделает реализацию довольно прямолинейной и будет легко добавлять новые типы токенов, но по факту получился довольно нечитабельный код.
Во-первых, жсон токенизатор всё не должен беспокоится о валидности строк, чисел и ключевых слов по типу true или false, он просто должен проглатывать все эти вещи до следующей кавычки или до следующего разделительного символа. То есть опять же, более гранулярное апи, пусть пользователь сам разбирается с валидацией utf-16 булшита в жсон строках, что там с числами и так далее.
Ещё же тут дело в том, что если я читаю жсон, чтобы извлечь из него какую-то информацию, я, скорее всего, знаю, какая у него схема и поэтому мне необязательно нужно полностью его структуру в память сохранять. Возможно, я просто хочу получить только значения по какому-то конкретному ключу.
Во-вторых, у токенизатора должен быть контекст: находится он просто жсоне, внутри строки, числа и тд. И в зависимости от контекста он должен по-разному интерпретировать прочитанные символы. И менять контекст по ходу токенизации — это тоже ответственность пользователя: что после открывающей кавычки надо поменять контекст на строку, например.
В общем, токенизатор становится просто функцией от указателя на байты и текущего контекста.
https://godbolt.org/z/88Kfaj9os
Ну это в первом приближении, я просто хотел проверить, смогу ли я хотя бы прожевать тот же жсон.
Но что я так и не придумал, как решить — это как быть с бэктрекгингом. Предыдущий вариант состоял из него целиком и полностью, тут его гораздо меньше, но я не могу придумать, как его избежать полностью. Конкретно многострочные комментарии: когда встречаю звёздочку мне нужно либо сразу прочесть следующий символ, чтобы понять, это конец комментария или нет, либо запомнить, что я прочитал звёздочку и если после неё потом прочитаю слеш, то это конец комментария, либо читать многострочные комментарии кусками и придумывать какой-то дополнительный контекст для токенизатора, в котором он останавливается, если читает слеш, либо не хранить никакого дополнительного состояния параноидально при виде каждого слеша читать, что было перед ним.
Но это всё кривые решения, которые реализованы как какие-то исключения из правил, я хочу умереть.
Это типо эвристическая оптимизация, из предположения, что рядом с ASCII символами будут с большой вероятностью другие ASCII символы?
Ещё я как-то, мне надо было хотя бы немного пролистнуть RFC у UTF-8, потому что всё же, например, не любые три байта вида
> 1110xxxx 10xxxxxx 10xxxxxx
являются валидным код поинтом. Правда, я чего-то не знаю, почему так сделали.
https://www.rfc-editor.org/rfc/rfc3629#section-4
Например, E0 80 80 — это невалидный код поинт.
Я ещё заметил, что from_utf8 возвращает в ошибке то, до какого момента байты валидны, и там есть ещё unchecked версия, которая просто каст делает. Короче, наверное, лучше этим пользоваться, если использовать std в принципе, чем городить ту кривую ерунду, которую я написал выше.
Нашёл очень доступное для лоу айкью даунов объяснение про LR(0), SLR(1) и LR(1) парсеры:
https://web.stanford.edu/class/archive/cs/cs143/cs143.1128/handouts/100%20Bottom-Up%20Parsing.pdf
https://web.stanford.edu/class/archive/cs/cs143/cs143.1128/handouts/110%20LR%20and%20SLR%20Parsing.pdf
Но я не знаю, хватит ли у меня айкью, чтобы реализовать генерацию action/goto таблиц хотя бы для LR(0) грамматик, а LR(0)-парсинг, если что, это когда ты применяешь правило из грамматики к последовательности символов только лишь основываясь на том, какие символы ты успел прочитать, без учёта того, что за ними идёт. То есть, например, в такой грамматике, как я понимаю, невозможно нормально реализовать оператор постинкремента или operator[].
>>672094
Нет, короче, это бред, в этом JsonTokenizerMode нет никакого смысла, усложнение кода ради ничего, в итоге получается одна жирная функция, которая обрабатывает все ситуации, вместо нескольких небольших на каждую отдельную ситуацию, да, очень ГРАНУЛЯРНО, какой же я тупорылый даун. Так, всё, я перепишу нормально, как было с самого начала, только, возможно, без шизомакросов и всё же с фиксированным буфером, куда читается входная строка.
Это типо эвристическая оптимизация, из предположения, что рядом с ASCII символами будут с большой вероятностью другие ASCII символы?
Ещё я как-то, мне надо было хотя бы немного пролистнуть RFC у UTF-8, потому что всё же, например, не любые три байта вида
> 1110xxxx 10xxxxxx 10xxxxxx
являются валидным код поинтом. Правда, я чего-то не знаю, почему так сделали.
https://www.rfc-editor.org/rfc/rfc3629#section-4
Например, E0 80 80 — это невалидный код поинт.
Я ещё заметил, что from_utf8 возвращает в ошибке то, до какого момента байты валидны, и там есть ещё unchecked версия, которая просто каст делает. Короче, наверное, лучше этим пользоваться, если использовать std в принципе, чем городить ту кривую ерунду, которую я написал выше.
Нашёл очень доступное для лоу айкью даунов объяснение про LR(0), SLR(1) и LR(1) парсеры:
https://web.stanford.edu/class/archive/cs/cs143/cs143.1128/handouts/100%20Bottom-Up%20Parsing.pdf
https://web.stanford.edu/class/archive/cs/cs143/cs143.1128/handouts/110%20LR%20and%20SLR%20Parsing.pdf
Но я не знаю, хватит ли у меня айкью, чтобы реализовать генерацию action/goto таблиц хотя бы для LR(0) грамматик, а LR(0)-парсинг, если что, это когда ты применяешь правило из грамматики к последовательности символов только лишь основываясь на том, какие символы ты успел прочитать, без учёта того, что за ними идёт. То есть, например, в такой грамматике, как я понимаю, невозможно нормально реализовать оператор постинкремента или operator[].
>>672094
Нет, короче, это бред, в этом JsonTokenizerMode нет никакого смысла, усложнение кода ради ничего, в итоге получается одна жирная функция, которая обрабатывает все ситуации, вместо нескольких небольших на каждую отдельную ситуацию, да, очень ГРАНУЛЯРНО, какой же я тупорылый даун. Так, всё, я перепишу нормально, как было с самого начала, только, возможно, без шизомакросов и всё же с фиксированным буфером, куда читается входная строка.
 506 Кб, 1787x2048
506 Кб, 1787x2048И со вторым тут две идеи: наивная - все кадры одинакового размера, прозрачный цвет на местах уже закрашенных пикселей, и вторая - попытаться разбить картинку на как можно больше непересекающихся прямоугольников, чтобы не хранить избыточные прозрачные пиксели. Как это сделать - не знаю, наверное, резать пополам пока не найдёшь прямоугольник, где мало цветов, и потом так же, разрезанием пополам пытаться присоединить к нему ещё прямоугольник, чтобы по возможности максимизировать количество цветов. Но я не уверен, что это будет работать лучше, чем наивная идея.
Вариация идеи с прямоугольниками - в глобальной таблице цветов сохранить все самые часто встречающиеся цвета и в первую очередь искать прямоугольники, где много цветов из глобальной таблицы, для которых использовать глобальную таблицу вместо локальных. Ну то есть попытаться сократить повторные цвета среди локальных таблиц. Но тут, мне кажется, это совсем переусложнённый вариант и он точно будет в реальности хуже наивного.
Я начал сегодня писать читалку гифок, но пока что не успел написать даже прогу, которая бы просто проглатывала гифку без разбора. Я постараюсь найти завтра время, чтобы хотя бы просто проглотить гифку.
 642 Кб, 1378x2039
642 Кб, 1378x2039 2,1 Мб, 3541x2508
2,1 Мб, 3541x2508С возвращением тебя.
>нужно, чтобы кто-то спас меня от такой жизни.
Однажды я курил с обычным пацаном с района, мы стояли и был обычный диалог гоп-стиль ни о чём. Я вижу как к нам идёт один казах, я думаю что он такой же как другой чувак, дескать типичный пацанчик с района и он так себя и вёл, пока я что-то не сказанул про античную философию...
Я люблю поговорить, но глубоких познаний у меня нëт ни в чём, этот казах меня раскатал как ребёнка. У него даже тон изменился, он стал настоящий когда мы начали говорить про философию. А выглядел как обычный "четкий пацан". Я тогда особого внимания не это не обратил.
Сейчас когда начал менять свою жизнь понял, что очень многие люди завидуют мне из-за моего интеллекта, чуствуют себя ниже и это задевает их самолюбие. Поэтому они пытаются меня клюнуть. Вот вчера выряс это с с силой из своей подружки. Я сам считал себя самым последним глупцом на свете, даже совсем не верил своему мнению. Но это потому, что меня всю жизнь подавляла мать, а отца не было, а на самом деле я как Никола Тесла, чуствую это.
А тот парнишка просто скрывал силу, ведь иначе люди не примут. Всегда появляются проблемы когда ты выше в обществе на порядок. Но говорить стоит не со всеми. Ты можешь просто не говорить с людьми или говорить с ними на их языке, как тот казах. Тогда они тебя примут, но главное внутри остаться собой. Поверь в себя.
Бог тебе в помощь.
 18,4 Мб, mp4,
18,4 Мб, mp4,854x480, 3:09
Константные функции в трейтах в принципе нельзя использовать. Вызывать константные методы на не-константах нельзя. Передавать не-константы в константные функции (чтобы вывелся const дженерик с размером массива) нельзя даже, если эти не-константы в самой функции никак не используются. Доступ к константам, определённым, в трейте, есть только через типы, которые имплементируют трейт, но не через переменную этого типа.
В итоге я не знаю, как достать на этапе компиляции размер массива, мне кажется, это невозможно. В плюсах это можно сделать просто через constexpr метод, а здесь результат выполнения const функции считается константным только, если все аргументы у неё константные. Нужен хотя бы аналог decltype.
Вообще с массивами невозможно нормально работать из-за того, что слайсы теряют свой размер даже, если он известен: если array - это [T; N], то array[..] - это всё равно просто &[T]. Можно сделать .get(...).as_ptr().cast::<[T; N]>(), но проверки на то, что слайс не выходит за границы, похоже невозможно сделать в компайл-тайме из-за проблем выше.
Да, клиппи предупреждает, если слайс выходит за границы массива, но клиппи - это не компилятор, что там случилось с if it compiles, it works, это типо всё приколы и несерьёзно что ли. Причём просто доставание элемента по индексу, который выходит за границы - это rustc считает ошибкой, но если слайс выходит за границы - то уже нет.
И что, и какой смысл во всём этом тогда.
 519 Кб, 2152x4082
519 Кб, 2152x4082Позавчера вчера сегодня написал всё же что-то короче декодирование, но у меня нет сейчас доделывать, как есть в общем https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=fa66d48c734dcceb560a79a232760999 это какая-то дефолтная гифка с википедии, я не знаю, зачем я храню lzw коды в хештаблице, ну и бред, вот это эффекты низкого iq, но я не могу уже сейчас доделывать, я рандомно раскрасил, там даже яркость пикселей не вычисляется, я даун тупой
Я не понимаю, почему Rc<[u8]> не хочет становиться владеющим итератором, разве он не владеет данными, постоянно ошибки какие-то, что я ссылку на временное значение делаю. Я просто хотел из impl Iterator<Item = Rc<[u8]>> сделать impl Iterator<Item = u8>, но не выходит, не знаю. С вектором вместо Rc работает, а в чём принципиальная разница между ними - я не понимаю. Наверняка снова какой-то кринж раст момент, который где-то мельком упоминается, что ты какой-то трейт не импортировал или что-то в этом духе, и максимально бесполезное сообщение об ошибке, я бесполезное хочу подохнуть, мне испортили жизнь, руки чешутся что-нибудь разбить + сломать
Винда мусор, всё, она взяла сама по себе ночью всё позакрывала и ребутнулась, чтобы установить апдейт, если у меня будет новая видеокарта, то это будет амд, и я больше не хочу на винде сидеть, просто бред, неюзабельно. Гит тоже помойка неюзабельная, stash push по умолчанию туда пихает и не staged изменения, и staged, и потом после stash pop они объединённые, спасибо огромное, как же тяжело в гите потерять данные, ага, да вообще не понятно что какие команды делают со стейджем
Да всё, ничего хорошего, я хочу подохнуть, потому что слишком низкий iq + мне испортили жизнь + я тупой даун + я тупой даун, я не знаю, что мне делать, я никак не могу дождаться, когда все сдохнут и я тоже, очень нужно уничтожение всех людей, пожалуйста
 436 Кб, 1603x2048
436 Кб, 1603x2048во-первых, их не отличить от вызова обычных функций, то есть если ты увидел что-то вроде "do_something()", то, не прочитав весь код (все дефайны) до этого момента, ты не можешь знать, это макрос или вызов функции, и нужно ли его раскрывать
во-вторых, у функциональных макросов сначала полностью раскрываются аргументы и потом они подставляются в функциональный макрос, то есть ты не сможешь просто по очереди всё раскрывать, придётся вперёд смотреть, например, в "a(b(c(d)))" нужно будет сначала раскрыть d, потом c(раскрытое d), в раскрытии которого тоже могут быть макросы, которые придётся раскрыть
И я не знаю, как хранить всё это в процессе раскрытия макросов, я думал, может быть, в связном списке хранить токены, среди которых могут быть нераскрытые макросы, и понемногу их раскрывать, вставляя на место макросов последовательность других, но это вряд ли сработает как минимум из-за того, что в случае с функциональными макросами придётся как-то запоминать, каким образом изначально было разбиение на аргументы, ну типа
> #define first a, b
> #define second c, d
> #define test(a, b, c, d) (a) (b) (c) (d)
>
> test(first, second)
это при раскрытии не должно выдать (a), (b), (c), (d), нужно запомнить, что "a, b" - это первый аргумент у test, а "c, d" - второй. Придётся как-то это учитывать, короче, макросы это не просто search and replace как в текстовых редакторах
И ещё в расте в std нет нормального связного списка, там нет способа вставить в середину за O(1): нельзя разбить связный список на два по позиции курсора, пришлось бы писать свой.
Наверное, придётся делать что-то древовидное и постепенно его раскрывать, типа, если есть такое:
> #define add(a, b) a + b
> #define f3(f, a, b, c) f(f(a, b), c)
> #if f3(add, 1 + 1, 2, 3) == 7
> idk
> #endif
Ну, наверное, читаешь все определения и сохраняешь их в каком-то виде, например
название макроса, названия параметров, определение макроса для function-like макросов:
> (String, Vec<String>, Vec<Token>)
или название макроса + определение для object-like макросов:
> (String, Vec<Token>)
а токены в определении макроса сохраняются так:
> enum Token {
> Obj(String),
> Func(Obj(String), Vec<Vec<Token>>),
> Seq(Vec<Token>),
> Other(...),
> }
И тут Func - это просто что угодно, что выглядит как f(x, y, z), но мы не знаем, это вызов функции или макрос. А Obj - это какой-то идентификатор, за которым нет круглых скобок. И название Func хранится как Obj, потому что оно в теории тоже может раскрыться:
> #define add(a, b) a + b
> #define test(a, b) f(a, b)
> #define f add
> test(1, 2)
Типа, add сохранился бы как (add, [a, b], [Obj(a), +, Obj(b)]) и потом, когда надо будет делать подстановку, просто меняем Obj(a) на аргументы-последовательности-токенов внутри первого аргумента.
Ну, допустим, пришло время развернуть "f3(add, 1 + 1, 2, 3) == 7". Ты сначала парсишь это как Vec<Token>, ничего не раскрывая:
> [Func(Obj(f3), [Obj(add), Seq([1, +, 1]), 2, 3]), ==, 7]
Потом идёшь и раскрываешь все аргументы у Func, раскрываешь Obj в названиях Func, и просто все Obj макросы тоже раскрываешь. И если попадаются названия макросов у Func, то раскрываешь это всё как function-like макрос:
> [Func(Obj(f3), [Obj(add), Seq([1, +, 1]), 2, 3]), ==, 7]
> [Seq([Func(Obj(add), [Func(Obj(add), [Seq([1, +, 1]), 2]), 3])]), ==, 7]
> [Seq([Func(Obj(add), [Seq([Seq([1, +, 1]), +, 2]), 3])]), ==, 7]
> [Seq([Seq([Seq([Seq([1, +, 1]), +, 2]), +, 3])]), ==, 7]
И, наверное, так придётся утюжить раскрытие каждого макроса до тех пор, пока там не останется нераскрываемых символов, потому что может быть
> #define z 42
> #define y z
> #define x y
> x
Выглядит тупо, но я не знаю, как нормально сделать без этого древовидного бреда и вообще даже так, я не представляю, как это написать более-менее нормально и не совсем длинно
436 Кб, 1603x2048во-первых, их не отличить от вызова обычных функций, то есть если ты увидел что-то вроде "do_something()", то, не прочитав весь код (все дефайны) до этого момента, ты не можешь знать, это макрос или вызов функции, и нужно ли его раскрывать
во-вторых, у функциональных макросов сначала полностью раскрываются аргументы и потом они подставляются в функциональный макрос, то есть ты не сможешь просто по очереди всё раскрывать, придётся вперёд смотреть, например, в "a(b(c(d)))" нужно будет сначала раскрыть d, потом c(раскрытое d), в раскрытии которого тоже могут быть макросы, которые придётся раскрыть
И я не знаю, как хранить всё это в процессе раскрытия макросов, я думал, может быть, в связном списке хранить токены, среди которых могут быть нераскрытые макросы, и понемногу их раскрывать, вставляя на место макросов последовательность других, но это вряд ли сработает как минимум из-за того, что в случае с функциональными макросами придётся как-то запоминать, каким образом изначально было разбиение на аргументы, ну типа
> #define first a, b
> #define second c, d
> #define test(a, b, c, d) (a) (b) (c) (d)
>
> test(first, second)
это при раскрытии не должно выдать (a), (b), (c), (d), нужно запомнить, что "a, b" - это первый аргумент у test, а "c, d" - второй. Придётся как-то это учитывать, короче, макросы это не просто search and replace как в текстовых редакторах
И ещё в расте в std нет нормального связного списка, там нет способа вставить в середину за O(1): нельзя разбить связный список на два по позиции курсора, пришлось бы писать свой.
Наверное, придётся делать что-то древовидное и постепенно его раскрывать, типа, если есть такое:
> #define add(a, b) a + b
> #define f3(f, a, b, c) f(f(a, b), c)
> #if f3(add, 1 + 1, 2, 3) == 7
> idk
> #endif
Ну, наверное, читаешь все определения и сохраняешь их в каком-то виде, например
название макроса, названия параметров, определение макроса для function-like макросов:
> (String, Vec<String>, Vec<Token>)
или название макроса + определение для object-like макросов:
> (String, Vec<Token>)
а токены в определении макроса сохраняются так:
> enum Token {
> Obj(String),
> Func(Obj(String), Vec<Vec<Token>>),
> Seq(Vec<Token>),
> Other(...),
> }
И тут Func - это просто что угодно, что выглядит как f(x, y, z), но мы не знаем, это вызов функции или макрос. А Obj - это какой-то идентификатор, за которым нет круглых скобок. И название Func хранится как Obj, потому что оно в теории тоже может раскрыться:
> #define add(a, b) a + b
> #define test(a, b) f(a, b)
> #define f add
> test(1, 2)
Типа, add сохранился бы как (add, [a, b], [Obj(a), +, Obj(b)]) и потом, когда надо будет делать подстановку, просто меняем Obj(a) на аргументы-последовательности-токенов внутри первого аргумента.
Ну, допустим, пришло время развернуть "f3(add, 1 + 1, 2, 3) == 7". Ты сначала парсишь это как Vec<Token>, ничего не раскрывая:
> [Func(Obj(f3), [Obj(add), Seq([1, +, 1]), 2, 3]), ==, 7]
Потом идёшь и раскрываешь все аргументы у Func, раскрываешь Obj в названиях Func, и просто все Obj макросы тоже раскрываешь. И если попадаются названия макросов у Func, то раскрываешь это всё как function-like макрос:
> [Func(Obj(f3), [Obj(add), Seq([1, +, 1]), 2, 3]), ==, 7]
> [Seq([Func(Obj(add), [Func(Obj(add), [Seq([1, +, 1]), 2]), 3])]), ==, 7]
> [Seq([Func(Obj(add), [Seq([Seq([1, +, 1]), +, 2]), 3])]), ==, 7]
> [Seq([Seq([Seq([Seq([1, +, 1]), +, 2]), +, 3])]), ==, 7]
И, наверное, так придётся утюжить раскрытие каждого макроса до тех пор, пока там не останется нераскрываемых символов, потому что может быть
> #define z 42
> #define y z
> #define x y
> x
Выглядит тупо, но я не знаю, как нормально сделать без этого древовидного бреда и вообще даже так, я не представляю, как это написать более-менее нормально и не совсем длинно
 641 Кб, 1119x800
641 Кб, 1119x800Во Free Pascal макросы (там нет функциональных, но функциональные должны делаться несложной модификацией, заключающейся в том, что на время их непосредственного раскрытия их аргументы тоже считаются специальными макросами; лет через 10 сам сделаю... ... ...) сделаны следующим образом: штука, которая читает токены (на самом деле символы, но, наверное, это естественно делать на уровне токенов, чтобы проще обрабатывать пустые макросы, конкатенации и т. п.), может быть переключена на новый файл, а по его завершении возвращается к предыдущему. Само по себе это реализует инклюды, но и макросы реализованы как псевдо-файлы, на которые сканер переключается и затем возвращается к предыдущему (настоящему файлу или внешнему макросу). То есть мы работаем не со связным списком токенов, в середине которого периодически устраиваем разворачивания, а со стеком файлов и единственным токеном, читаемым в данный момент.
Это позволяет результату разворачивания макроса быть сколь угодно большим, его существование в памяти целиком не требуется. Конечно, в зависимости от того, в какие конструкции он разворачивается и что с ними происходит дальше, это может не помочь, но, во всяком случае, даже тогда препроцессору делает честь, что с нехваткой памяти упал не он.
 373 Кб, 1448x2048
373 Кб, 1448x2048+++
 61 Кб, 675x911
61 Кб, 675x911Мега кринж https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=d4e5b586dbb2f40abf1f7f2df303ed60 Я перестаю понимать зачем вообще жить хочется уже подохнуть поскорее, потому что вообще ничего хорошего не вижу уже, никакого смысла нету и ничего хорошего не будет
 648 Кб, 629x880
648 Кб, 629x880Ещё этот непонятный wWinMain, но вроде можно ориентироваться на то, как сделано в вайне https://github.com/wine-mirror/wine/blob/master/dlls/winecrt0/exe_wmain.c
 376 Кб, 1761x1761
376 Кб, 1761x1761https://godbolt.org/z/7n15qWd3E
Я вообще не знал, что у std::span есть второй шаблонный параметр и по дефолту он максимальный size_t и по дефолту std::span - жирный указатель, но если его размер известен в компайл тайме, то он просто указатель
Ну как бы понятно, что надо просто использовать метод .size(), но просто
Но даже с такими возможностями выстрелить себе в голову мне это больше нравится, чем
чем раст с его трейтами >>668663 и с его const функциями >>687871
 407 Кб, 2000x3000
407 Кб, 2000x3000- посмотреть строку в буфере
- откусить сколько-то байтов (предполагается, что ты сам знаешь, сколько надо откусить, иначе всё сломается)
- прочитать в буфер больше - это все функции ниже делают автоматически при необходимости, я думал сделать этот шаг явным, но, мне кажется, если, например, тебе надо прочесть следующий символ, но он в буфере есть только наполовину, то ну типо, ты в любом случае захочешь прочитать в буфер больше байтов и тут больше вроде ничего умного в общем случае не придумать, поэтому я просто запихнул это в сами функции, из-за этого они мутируют читалку даже, если это просто peek_char
- посмотреть/откусить следующий символ (просто вообще минимум, что от читалки требуется)
- откусить строку от начала буфера, пока выполняется предикат по символу и его номеру (то есть через неё можно, например, откусить первые несколько символов или откусить до следующего пробела)
- откусить от начала буфера до подстроки-разделителя (например, можно откусить до конца многострочного коммента)
- посмотреть, начинается ли буфер с какой-то строки (например, посмотреть, начался ли многострочный коммент)
И для трёх последних функций есть по два варианта, один кусает более уверенно, чем другой. Типо, например, если предикат нигде не выдал false, то один вариант просто откусит строку полностью, а другой выдаст ошибку. Или, если кусаем до какой-то подстроки-разделителя и в конце есть начальный кусок подстроки-разделителя, но ещё непонятно, это реально она или нет, то один вариант молча кусает до этого непонятного кусочка, надеясь разобраться потом, дочитав его в буфер полностью, а другой выдаст ошибку, что типо буфер слишком маленький или источник, откуда читаем, закончился.
Я думал добавить ещё вариант предиката не по отдельным символам, а по окну из нескольких символов, но, во-первых, я пока что не вижу, где такое могло бы мне пригодиться, а, во-вторых, такая функция слишком сложная, чтобы использовать её в простых ситуациях, но недостаточно сложная, чтобы применять её в сложных ситуациях. Типо, если тебе что-то такое нужно, то, скорее всего, тебе этого не хватит и нужны уже будут полноценные паттерны какие-то или регекспы.
https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=4ddd00c02b50063955816444b441ee70
Там жсон типо просто для примера использования, мне сейчас лень переписывать свой жсон парсер так, чтобы он не держал полностью строку в памяти, мне вообще для другого, наверное, даже гораздо более простого, оно нужно. И я сейчас смотрю на это и снова получилось полнейшее говно, которым почти невозможно пользоваться, лайк если хочешь нахуй сдохнуть блять
Я знаю про существование BufReader в std раста, но его проблема в том, что у него какой-то не очень интерфейс: там fill_buf читает больше байтов только, если ты буфер полностью законсюмил. То есть нельзя чуть-чуть законсюмить байтов и чуть-чуть дочитать, если что-то не влезло в буфер.
Ещё я чёто, листая код std, понял, что read в трейте Read так-то требует того, чтобы ему давали инициализированную память, куда он будет писать то, что прочёл. Потому что в теории реализацию read ничего не останавливает просто вернуть Ok(42), ничего не записать, и ты потом прочтёшь мусор в буфере, который так и остался незаполненным, и в расте подобные вещи называют unsound, типо, что можно либу каким-то неправильным образом использовать и получить какую-то уязвимость. Но там сделали вот это https://rust-lang.github.io/rfcs/2930-read-buf.html, частично, пока до не доделали.
Там и до этого в рамках std был костыль, чтобы избегать излишних инициализаций буферов https://github.com/rust-lang/rust/pull/81156/files#r766012221, но теперь типо заменили на костыль, который может использовать кто угодно. Но проблема в том, что теперь им, видимо, придётся везде добавлять эти функции, которые принимают https://doc.rust-lang.org/nightly/std/io/struct.BorrowedCursor.html, чтобы явно показать, что сюда можно передавать неинициализированную память. Тут например https://doc.rust-lang.org/stable/std/net/struct.UdpSocket.html#method.recv_from.
Не знаю, правда, действительно ли стоит с этим заморачиваться, это ещё к тому же чисто типичные растопроблемы, какой ужас, я прочитаю мусор. Ну хотя это может вызвать даже UB вроде, но я не понимаю, почему https://rust.godbolt.org/z/Y9rL-5
Очень много unsafe, но я поэтому написал тесты. Единственное нужно с алиасингом осторожнее быть, например, вот это вроде как UB:
> use std::ptr;
>
> let mut test: [u8; 3] = [0, 1, 2];
> unsafe {
> ptr::copy(
> test.as_ptr().add(1),
> test.as_mut_ptr(),
> 2,
> );
> }
А так вроде как нормально, потому что не создаются промежуточные ссылки, когда ты берёшь второй указатель, после того, как ты взял первый указатель. Типо получается, что у тебя есть, например, одновременно константный указатель и мутабельная ссылка. Что-то такое, короче, я не до конца понимаю https://doc.rust-lang.org/stable/std/ptr/macro.addr_of.html:
> use std::ptr;
>
> let mut test: [u8; 3] = [0, 1, 2];
> unsafe {
> ptr::copy(
> ptr::addr_of!(test).cast::<u8>().add(1),
> ptr::addr_of_mut!(test).cast(),
> 2,
> );
> }
Вот можно ли так кастить указатель на слайс я тоже не уверен.
Либо просто только один раз мутабельный указатель взять можно, а не отдельно один мутабельный и один константный.
И это всё компилятор не отлавливает никак. Если у тебя где-то есть указатели, то сам ломай голову с этим, раст сложнее плюсов в разы. Есть miri, но он медленный, не умеет интерпретировать произвольные программы (вроде, например, в FFI он не умеет совсем сейчас) и выдаёт сообщения об ошибках нечитаемые для low iq дебила типа меня.
407 Кб, 2000x3000- посмотреть строку в буфере
- откусить сколько-то байтов (предполагается, что ты сам знаешь, сколько надо откусить, иначе всё сломается)
- прочитать в буфер больше - это все функции ниже делают автоматически при необходимости, я думал сделать этот шаг явным, но, мне кажется, если, например, тебе надо прочесть следующий символ, но он в буфере есть только наполовину, то ну типо, ты в любом случае захочешь прочитать в буфер больше байтов и тут больше вроде ничего умного в общем случае не придумать, поэтому я просто запихнул это в сами функции, из-за этого они мутируют читалку даже, если это просто peek_char
- посмотреть/откусить следующий символ (просто вообще минимум, что от читалки требуется)
- откусить строку от начала буфера, пока выполняется предикат по символу и его номеру (то есть через неё можно, например, откусить первые несколько символов или откусить до следующего пробела)
- откусить от начала буфера до подстроки-разделителя (например, можно откусить до конца многострочного коммента)
- посмотреть, начинается ли буфер с какой-то строки (например, посмотреть, начался ли многострочный коммент)
И для трёх последних функций есть по два варианта, один кусает более уверенно, чем другой. Типо, например, если предикат нигде не выдал false, то один вариант просто откусит строку полностью, а другой выдаст ошибку. Или, если кусаем до какой-то подстроки-разделителя и в конце есть начальный кусок подстроки-разделителя, но ещё непонятно, это реально она или нет, то один вариант молча кусает до этого непонятного кусочка, надеясь разобраться потом, дочитав его в буфер полностью, а другой выдаст ошибку, что типо буфер слишком маленький или источник, откуда читаем, закончился.
Я думал добавить ещё вариант предиката не по отдельным символам, а по окну из нескольких символов, но, во-первых, я пока что не вижу, где такое могло бы мне пригодиться, а, во-вторых, такая функция слишком сложная, чтобы использовать её в простых ситуациях, но недостаточно сложная, чтобы применять её в сложных ситуациях. Типо, если тебе что-то такое нужно, то, скорее всего, тебе этого не хватит и нужны уже будут полноценные паттерны какие-то или регекспы.
https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=4ddd00c02b50063955816444b441ee70
Там жсон типо просто для примера использования, мне сейчас лень переписывать свой жсон парсер так, чтобы он не держал полностью строку в памяти, мне вообще для другого, наверное, даже гораздо более простого, оно нужно. И я сейчас смотрю на это и снова получилось полнейшее говно, которым почти невозможно пользоваться, лайк если хочешь нахуй сдохнуть блять
Я знаю про существование BufReader в std раста, но его проблема в том, что у него какой-то не очень интерфейс: там fill_buf читает больше байтов только, если ты буфер полностью законсюмил. То есть нельзя чуть-чуть законсюмить байтов и чуть-чуть дочитать, если что-то не влезло в буфер.
Ещё я чёто, листая код std, понял, что read в трейте Read так-то требует того, чтобы ему давали инициализированную память, куда он будет писать то, что прочёл. Потому что в теории реализацию read ничего не останавливает просто вернуть Ok(42), ничего не записать, и ты потом прочтёшь мусор в буфере, который так и остался незаполненным, и в расте подобные вещи называют unsound, типо, что можно либу каким-то неправильным образом использовать и получить какую-то уязвимость. Но там сделали вот это https://rust-lang.github.io/rfcs/2930-read-buf.html, частично, пока до не доделали.
Там и до этого в рамках std был костыль, чтобы избегать излишних инициализаций буферов https://github.com/rust-lang/rust/pull/81156/files#r766012221, но теперь типо заменили на костыль, который может использовать кто угодно. Но проблема в том, что теперь им, видимо, придётся везде добавлять эти функции, которые принимают https://doc.rust-lang.org/nightly/std/io/struct.BorrowedCursor.html, чтобы явно показать, что сюда можно передавать неинициализированную память. Тут например https://doc.rust-lang.org/stable/std/net/struct.UdpSocket.html#method.recv_from.
Не знаю, правда, действительно ли стоит с этим заморачиваться, это ещё к тому же чисто типичные растопроблемы, какой ужас, я прочитаю мусор. Ну хотя это может вызвать даже UB вроде, но я не понимаю, почему https://rust.godbolt.org/z/Y9rL-5
Очень много unsafe, но я поэтому написал тесты. Единственное нужно с алиасингом осторожнее быть, например, вот это вроде как UB:
> use std::ptr;
>
> let mut test: [u8; 3] = [0, 1, 2];
> unsafe {
> ptr::copy(
> test.as_ptr().add(1),
> test.as_mut_ptr(),
> 2,
> );
> }
А так вроде как нормально, потому что не создаются промежуточные ссылки, когда ты берёшь второй указатель, после того, как ты взял первый указатель. Типо получается, что у тебя есть, например, одновременно константный указатель и мутабельная ссылка. Что-то такое, короче, я не до конца понимаю https://doc.rust-lang.org/stable/std/ptr/macro.addr_of.html:
> use std::ptr;
>
> let mut test: [u8; 3] = [0, 1, 2];
> unsafe {
> ptr::copy(
> ptr::addr_of!(test).cast::<u8>().add(1),
> ptr::addr_of_mut!(test).cast(),
> 2,
> );
> }
Вот можно ли так кастить указатель на слайс я тоже не уверен.
Либо просто только один раз мутабельный указатель взять можно, а не отдельно один мутабельный и один константный.
И это всё компилятор не отлавливает никак. Если у тебя где-то есть указатели, то сам ломай голову с этим, раст сложнее плюсов в разы. Есть miri, но он медленный, не умеет интерпретировать произвольные программы (вроде, например, в FFI он не умеет совсем сейчас) и выдаёт сообщения об ошибках нечитаемые для low iq дебила типа меня.


У меня снова началась эта шиза, потому что мне хуёво блять и я либо сижу и нихуя не делаю, либо занимаюсь хуйнёй, заново переписал конфиг, не глядя на старый-старый, который я даже не использовал в пользу старого более минималистичного. Но получил в итоге примерно то же самое, но на этот раз более-менее разобрался с ленивой загрузкой плагинов, благодаря чему оно хотя бы стартовый экран с меню относительно быстро почти мгновенно открывает, тупо потому что почти ничего не грузит. Корову не я нарисовал, я её украл
Стартовый экран почти бесполезный, там полезное только это перейти в папку с конфигами за одно нажатие кнопки
https://github.com/stevearc/oil.nvim вот это вот прикольно, можно редактировать дерево файлов так же, как текстовые буферы в виме, не надо разбираться со всякими непонятными биндингами
https://github.com/andymass/vim-matchup и это, но только из-за того, что % из дефолтного вима не работает нормально в некоторых ситуациях
https://github.com/debugloop/telescope-undo.nvim и это, но это по сути просто более удобный интерфейс для взаимодействия со встроенной фичей в виме undolist. Типа у меня постоянно проблема в том, что я что-то пишу, потом делаю несколько раз undo, потому что написал кринж, пишу снова, а потом вспоминаю, что я хочу скопировать что-то из текста, который я убрал через undo, и в любом нормальном текстовом редакторе этот текст безвозвратно пропадает
Дерево файлов как дерево и дерево символов не нужны, я обычно просто поиском по названиям по файлам и функциям перемещаюсь
Но я не знаю, стоит ли оно вообще того, есть ли смысл в более сложном автодополнении, чем просто по словам в текущем файле. Я до сегодняшнего сколько-то месяцев использовал максимально минималистичный конфиг неовима, где из плагинов были только vim-surround и цветовая схема, и не то чтобы чувствовал себя сильно обделённым. И то, я думаю, не должно быть сложно написать свой примитивный кеймап для того, чтобы поставить скобки или кавычки вокруг выделения. Типа в виме просто автоматом есть маркеры < и > вокруг последнего выделения, просто на них прыгаешь, вставляешь символы, прыгаешь на изначальную позицию и всё.
С использованием netrw тоже, наверное, можно смириться.
В виме даже греп есть встроенный. Поиск и замену на несколько файлов немного неудобно делать (нужно сначала через vimgrep добавить файлы в quickfix, а потом cdof сделать), но тоже терпимо
https://neovim.io/doc/user/digraph.html#digraphs-use и про это тоже не знал, полезно для меня, потому что я слишком тупой, чтобы запомнить даже несколько юникодовых кодов для часто исопльзуемых символов, которых нет на клаве
Для дебаггинга есть просто gdb, там, оказывается, тупо есть графический режим, где показывается исходный код и для того же раста можно даже настроить сорсмапы для стд. И оно даже на винде почти работает (старая 12 версия работает нормально, а 13 версия и актуальный на сегодня trunk - нет, ну это вот типичный виндовс экспириенс, что ничего не работает). В виме даже есть встроенный плагин для gdb (termdebug), но он как-то не очень работает. Этот получше https://github.com/sakhnik/nvim-gdb и поддерживает lldb ещё
Мне, наверное, надо просто сделать опцию в конфиге, чтобы можно было либо выключить все плагины, либо оставить только минимальный набор (точно без LSP).
После того, как меня заставили пойти в рабство, моя жизнь испортилась окончательно и я хочу нахуй сдохнуть, мне не хочется заниматься этой хуйнёй, я не хочу говнокодить на говноязыке какую-то непонятную хуйню, на которую мне максимально похуй, и мне физически тяжело делать то, что мне не хочется. А в последние несколько недель я и перестал делать, и по сути жду, когда меня пошлют уже нахуй и уволят, потому что так жить невозможно, это буквально рабство, я ничего взамен не получаю, мне нахуй не нужны деньги, точнее, нахуй не нужны такие копейки, какие мне дают, их в жизни моей не скопится в разумные сроки (максимум за год) столько, чтобы хватило на свой дом и жить в нём до конца жизни. А больше нахуй не нужно ничего, ты такие маленькие деньги можешь потратить только на всякую бесполезную хуйню.
Ну разъебал я телефон окончательно об стену, купил новый, но мне телефон так-то не очень-то нужен. Болезни в большинстве случаев сами проходят, зубы, да похуй на зубы: их просто год не чистишь, они обрастают защитой из зубного камня и всё. Что блять на них покупать, шоколадки? да в рот я ебал шоколадки, они все на вкус говно и меня тошнит от них, я не хочу нихуя, я ебал всё и всех в рот, ненавижу. Охуенная трата сил и часов своей жизни в никуда
https://github.com/PowerShell/PowerShell/issues/1908 на это наткнулся, в cmd это просто работало. Я не буду больше пользоваться павершелом, это невозможно. И вингетом тоже, потому что он легко может рандомно заруинить установленную прогу при обновлении. Или установить что-то без нужных зависимостей, но это вообще на винде всегда так, что устанавливаешь что-то, а потом разбираешься, каких dll не хватает. И вскодом, потому что обычно это ещё более худший опыт настройки плагинов, чем в неовиме: куча каких-то жсонов, в которые иногда можно встраивать ${переменные}, нельзя прописать в жсоне просто список плагинов, чтобы вскод сам их установил, нужно обязательно мышкой прокликивать установку.
Микрософт портит мне жизнь. И скриптовые языки тоже, я ненавижу питон, я не понимаю, зачем он существует, ты пробуешь что угодно установить, написанное на нём, и выясняется, что у него есть какие-то платформозависимые зависимости, колёса какие-то, что они то ли компилируются, то ли там бинарники скачиваются, что тебе нужен мейк, сишный компилятор и что в итоге оно всё равно не компилится и выдаёт километр ошибок. Это просто типичный опыт вызова pip install, на винде так точно. На линуксе наверняка иногда тоже, потому что у тебя необязательно установлены все зависимости и естественно pip install не может их подтянуть, это же всего лишь пакетный менеджер для кроссплатформенного языка
Да и другие скриптовые языки, для них у тебя на компе обязательно должен быть установлен интерпретатор и, скорее всего, ещё и пакетный менеджер к нему, потому что миллион зависимостей является данностью для любой проги на скриптовом языке. Нельзя просто запустить прогу, потому что проги никакой нет, у тебя есть только куча бесполезных текстовых файлов
У меня типа просто есть скрипт, который скачивает всякую ерунду, но из-за того, что он написан на жс, я не могу его запустить, мне придётся устанавливать ноду и я так думаю, что ну это слишком сложно, обойдусь
У меня снова началась эта шиза, потому что мне хуёво блять и я либо сижу и нихуя не делаю, либо занимаюсь хуйнёй, заново переписал конфиг, не глядя на старый-старый, который я даже не использовал в пользу старого более минималистичного. Но получил в итоге примерно то же самое, но на этот раз более-менее разобрался с ленивой загрузкой плагинов, благодаря чему оно хотя бы стартовый экран с меню относительно быстро почти мгновенно открывает, тупо потому что почти ничего не грузит. Корову не я нарисовал, я её украл
Стартовый экран почти бесполезный, там полезное только это перейти в папку с конфигами за одно нажатие кнопки
https://github.com/stevearc/oil.nvim вот это вот прикольно, можно редактировать дерево файлов так же, как текстовые буферы в виме, не надо разбираться со всякими непонятными биндингами
https://github.com/andymass/vim-matchup и это, но только из-за того, что % из дефолтного вима не работает нормально в некоторых ситуациях
https://github.com/debugloop/telescope-undo.nvim и это, но это по сути просто более удобный интерфейс для взаимодействия со встроенной фичей в виме undolist. Типа у меня постоянно проблема в том, что я что-то пишу, потом делаю несколько раз undo, потому что написал кринж, пишу снова, а потом вспоминаю, что я хочу скопировать что-то из текста, который я убрал через undo, и в любом нормальном текстовом редакторе этот текст безвозвратно пропадает
Дерево файлов как дерево и дерево символов не нужны, я обычно просто поиском по названиям по файлам и функциям перемещаюсь
Но я не знаю, стоит ли оно вообще того, есть ли смысл в более сложном автодополнении, чем просто по словам в текущем файле. Я до сегодняшнего сколько-то месяцев использовал максимально минималистичный конфиг неовима, где из плагинов были только vim-surround и цветовая схема, и не то чтобы чувствовал себя сильно обделённым. И то, я думаю, не должно быть сложно написать свой примитивный кеймап для того, чтобы поставить скобки или кавычки вокруг выделения. Типа в виме просто автоматом есть маркеры < и > вокруг последнего выделения, просто на них прыгаешь, вставляешь символы, прыгаешь на изначальную позицию и всё.
С использованием netrw тоже, наверное, можно смириться.
В виме даже греп есть встроенный. Поиск и замену на несколько файлов немного неудобно делать (нужно сначала через vimgrep добавить файлы в quickfix, а потом cdof сделать), но тоже терпимо
https://neovim.io/doc/user/digraph.html#digraphs-use и про это тоже не знал, полезно для меня, потому что я слишком тупой, чтобы запомнить даже несколько юникодовых кодов для часто исопльзуемых символов, которых нет на клаве
Для дебаггинга есть просто gdb, там, оказывается, тупо есть графический режим, где показывается исходный код и для того же раста можно даже настроить сорсмапы для стд. И оно даже на винде почти работает (старая 12 версия работает нормально, а 13 версия и актуальный на сегодня trunk - нет, ну это вот типичный виндовс экспириенс, что ничего не работает). В виме даже есть встроенный плагин для gdb (termdebug), но он как-то не очень работает. Этот получше https://github.com/sakhnik/nvim-gdb и поддерживает lldb ещё
Мне, наверное, надо просто сделать опцию в конфиге, чтобы можно было либо выключить все плагины, либо оставить только минимальный набор (точно без LSP).
После того, как меня заставили пойти в рабство, моя жизнь испортилась окончательно и я хочу нахуй сдохнуть, мне не хочется заниматься этой хуйнёй, я не хочу говнокодить на говноязыке какую-то непонятную хуйню, на которую мне максимально похуй, и мне физически тяжело делать то, что мне не хочется. А в последние несколько недель я и перестал делать, и по сути жду, когда меня пошлют уже нахуй и уволят, потому что так жить невозможно, это буквально рабство, я ничего взамен не получаю, мне нахуй не нужны деньги, точнее, нахуй не нужны такие копейки, какие мне дают, их в жизни моей не скопится в разумные сроки (максимум за год) столько, чтобы хватило на свой дом и жить в нём до конца жизни. А больше нахуй не нужно ничего, ты такие маленькие деньги можешь потратить только на всякую бесполезную хуйню.
Ну разъебал я телефон окончательно об стену, купил новый, но мне телефон так-то не очень-то нужен. Болезни в большинстве случаев сами проходят, зубы, да похуй на зубы: их просто год не чистишь, они обрастают защитой из зубного камня и всё. Что блять на них покупать, шоколадки? да в рот я ебал шоколадки, они все на вкус говно и меня тошнит от них, я не хочу нихуя, я ебал всё и всех в рот, ненавижу. Охуенная трата сил и часов своей жизни в никуда
https://github.com/PowerShell/PowerShell/issues/1908 на это наткнулся, в cmd это просто работало. Я не буду больше пользоваться павершелом, это невозможно. И вингетом тоже, потому что он легко может рандомно заруинить установленную прогу при обновлении. Или установить что-то без нужных зависимостей, но это вообще на винде всегда так, что устанавливаешь что-то, а потом разбираешься, каких dll не хватает. И вскодом, потому что обычно это ещё более худший опыт настройки плагинов, чем в неовиме: куча каких-то жсонов, в которые иногда можно встраивать ${переменные}, нельзя прописать в жсоне просто список плагинов, чтобы вскод сам их установил, нужно обязательно мышкой прокликивать установку.
Микрософт портит мне жизнь. И скриптовые языки тоже, я ненавижу питон, я не понимаю, зачем он существует, ты пробуешь что угодно установить, написанное на нём, и выясняется, что у него есть какие-то платформозависимые зависимости, колёса какие-то, что они то ли компилируются, то ли там бинарники скачиваются, что тебе нужен мейк, сишный компилятор и что в итоге оно всё равно не компилится и выдаёт километр ошибок. Это просто типичный опыт вызова pip install, на винде так точно. На линуксе наверняка иногда тоже, потому что у тебя необязательно установлены все зависимости и естественно pip install не может их подтянуть, это же всего лишь пакетный менеджер для кроссплатформенного языка
Да и другие скриптовые языки, для них у тебя на компе обязательно должен быть установлен интерпретатор и, скорее всего, ещё и пакетный менеджер к нему, потому что миллион зависимостей является данностью для любой проги на скриптовом языке. Нельзя просто запустить прогу, потому что проги никакой нет, у тебя есть только куча бесполезных текстовых файлов
У меня типа просто есть скрипт, который скачивает всякую ерунду, но из-за того, что он написан на жс, я не могу его запустить, мне придётся устанавливать ноду и я так думаю, что ну это слишком сложно, обойдусь
 1,9 Мб, 4080x3072
1,9 Мб, 4080x3072 14,5 Мб, webm,
14,5 Мб, webm,1280x1024, 4:15
 19,5 Мб, webm,
19,5 Мб, webm,1280x1024, 6:17
 15,1 Мб, webm,
15,1 Мб, webm,1280x1024, 5:34
 17,3 Мб, webm,
17,3 Мб, webm,1280x1024, 5:59

 19,8 Мб, webm,
19,8 Мб, webm,1280x1024, 8:36
То ли мне показалось, что ли у тебя расхождение с тем, что ты пишешь и тем, как ты говоришь. У тебя вполне спокойный нормальный голос, не подавленный какой-то, рассказываешь интересно.
Ты это просто так пишешь, про сдохнуть, типа прикол такой?
 19,4 Мб, webm,
19,4 Мб, webm,1280x1024, 8:37
 17,4 Мб, webm,
17,4 Мб, webm,1280x1024, 7:44
 9,3 Мб, webm,
9,3 Мб, webm,1280x1024, 3:32
 9,6 Мб, mp4,
9,6 Мб, mp4,640x360, 2:03
Я не могу учиться, я не могу работать, я ненавижу это всё, мои родители эффективно заставили меня пойти на работу, потому что я просто уже не вывозил морально их постоянное нытьё о том, что вот ты какая мразь бросил учиться. И всё, у меня подошла точка, когда меня так сильно выворачивает наизнанку, что я не могу ни на минуту сесть за комп и что-то начать делать, я слишком сильно ебал в рот этот говнокодинг какой-то хуйни, которую я ебал в рот, я ни минуты не хочу больше разбираться в этой куче хуйни
Проблема в том, что мне теперь жить спокойно не дадут, зная что я блять нихуя себе сижу дома давлю кнопки и мне за это платят какие-то обоссанные копейки, и будут ебать мне мозг точно так же, как ебали мне мозг с учёбой, только ещё сильнее, мол, давай иди, иди снова всирай свою жизнь на какую-то очередную долбоёбскую парашу
Я могу уехать от них месяца на 4 максимум, а потом, видимо, лечь на пол, сдохнуть от голода и мумифицироваться, потому что абсолютно все работы доступные человеку с низким айкью - это подобное дегроидное говно, от которого мне хочется залезть на потолок. Либо притворяться, что работаю, блять, подделывать скрины из бансковского приложения
 18,7 Мб, webm,
18,7 Мб, webm,1280x1024, 8:19
 19,5 Мб, webm,
19,5 Мб, webm,1280x1024, 14:12
 14,3 Мб, webm,
14,3 Мб, webm,1280x1024, 5:54
 18,5 Мб, webm,
18,5 Мб, webm,1280x1024, 9:40
 19,6 Мб, webm,
19,6 Мб, webm,1280x1024, 13:35

 462 Кб, 2028x2048
462 Кб, 2028x2048 15,5 Мб, webm,
15,5 Мб, webm,1920x1440, 0:31
 2,5 Мб, 2383x2157
2,5 Мб, 2383x2157 1,3 Мб, 4080x3072
1,3 Мб, 4080x3072


 134 Кб, mp4,
134 Кб, mp4,844x426, 0:02
Не могу даже делать минимум спустя рукава, чтобы меня не трогали. И на фоне этого ничем для себя я толком тоже не могу заниматься, из-за ощущения, что вот-вот произойдёт что-то неприятное, из-за того, что в это время мне якобы нужно делать что-то другое, из-за того, что вне зависимости ни от чего будет кто-то, кто будет постоянно трахать мне мозг какой-то хуйнёй для долбоёбов.
У тебя просто нет возможности в течение, например, недели делать только что-то одно, без переключения на другие вещи. А как-то пытаться совмещать - это бесполезно, я пытался, у меня не хватает сил ни физических, ни моральных. Получалось так, что я ничего не успевал, тот треугольник рисовал почти два месяца, например.
Я в итоге сейчас просто целыми днями сижу и ничего не делаю, в состоянии ступора какого-то, я не знаю. Я всегда хотел только одного - чтобы я мог проснуться, осознавая, что никому от меня ничего не надо, что я могу потратить своё время так, как мне вздумается. Но этого просто никогда не будет, потому что, видимо, абсолютное большинство людей всё устраивает, возможно, им даже нравится, когда им нон-стоп ебут мозг.
 697 Кб, 3090x4096
697 Кб, 3090x4096Если я так и не начну сегодня ничего делать, то возможно меня уволят, потому что я ничего не делаю уже достаточно времени, чтобы это вызвало недовольство. Но проблема в том, что мне как-то всё равно, я хочу, чтобы всё как-нибудь просто закончилось, но мне никто не поможет, просто проблема в том, что меня потом снова погонят в рабство в стойло, либо у меня просто деньги закончатся, если я съеду от них, чтобы они меня не трогали. А откуда брать деньги, не прикладывая никаких усилий, или как жить без потребности в деньгах, при этом пользуясь интернетом и электричеством и не имея своего дома, я не знаю, я слишком тупой и бесполезный для этого
Почему я просто не родился красивой женщиной, всё было бы настолько проще, вот вообще тупо всё, а так это просто бесполезно жить так нет смысла никакого, не на что надеяться, ничего из более-менее вероятного в теории не может произойти, что могло бы исправить моё положение, и я сам ничего сделать не могу, ничего хорошего не будет

 14,1 Мб, mp4,
14,1 Мб, mp4,1280x1024, 0:46
Я бы не додумался сам потому что я тупорылый долбоёб
Фликеринг жёсткий
Похуй
блять мне
Какая зп, какой потолок в конторе, скока получают топманагеры, главхуй, скока оборот, какая продукция производится, куда сбывается?
Сори за такие интимные вопросы, но ответь хоть на что-то, раз ты дневниковод.
 29 Кб, 546x546
29 Кб, 546x546>Какая зп
Недостаточно большая, чтобы можно было за год рабства ХОТЯ БЫ накопить на покупку своего участка с домом, то есть обоссанные копейки. Как и на большинстве работ: хватает только на то, чтобы покупать всякую потреблядскую парашу, но не на нормальные вещи.
>какая продукция производится, куда сбывается
Это всё не имеет значения. Если у тебя IQ <130, то тебе доступны только бесполезные бессмысленные говноработы, от которых течёт мозг и на которых ты деградируешь, просто впустую всираешь часы своей жизни, свои силы.
И мне похуй на то, что там другие люди считают "полезным" трудом, я, например, в рот ебал центральное водоснабжение. Наверняка дохуя сложно поддерживать в нормальном состоянии всю эту ебаную систему, наверняка нужны какие-то специальные знания и далеко ненулевой интеллект, наверняка большинство людей считают её даже не просто полезной, а жизненно необходимой, но в моих глазах она не нужна, потому что Я НЕ МОЮСЬ БЛЯТЬ.
И что ещё хуже, все эти говноработы порождают потребность только в ещё большем количестве говноработ. Мы построили большой город - теперь нам нужны магазины на каждом углу. Мы нахуярили магазинов на каждом углу - теперь нам нужно развозить в них свежую еду каждый день, теперь нам нужно нанять дохуя людей расставлять товары и разгружать грузовики, теперь нам нужно разрабатывать говнософт для касс самообслуживания, потому что кассиров не хватает. И так далее.
Я ебал всё в рот, мне похуй, ему похуй, похуй похуй похуй
 171 Кб, 1000x1000
171 Кб, 1000x1000Я скорее всего, съеду от родителей в январе и тогда же стану безРАБотным с 90% вероятностью. И не знаю, что буду делать дальше, не знаю, на сколько месяцев хватит денег. Пытаться снова лезть в говнокодинг за деньги нет никакого желания, не хочу работать, работа - это рабство, мне внутри всё внутри грудной клетки прогрызли крысы
 149 Кб, mp4,
149 Кб, mp4,500x374, 0:01


Мельтешение при ресайзе невозможно убрать неважно с двумя скринбуферами или без них в любом случае вроде, не знаю
Единственное, что стоило сделать - это заменить растовый print! на WriteConsoleW, потому что раст похоже делает какую-то буферизацию и непонятно как преобразовывает utf8 строки в utf16 для винды, а я использую юникодовые символы, мне лень разбираться, проще самому сделать, вроде немного лучше (ну точнее в conhost.exe print вообще адекватно не работал, а виндовс терминалу было болееменее нормально с самого начала), но тоже вырвиглазно, короче бесполезно
А я просто что-то подумл зачем нужны все эти графические апи, если есть консоль, в которой можно рисовать квадратики и к тому же ещё и рендеринг текста есть, но не знаю короче
 9,6 Мб, mp4,
9,6 Мб, mp4,1280x1024, 0:27
 296 Кб, 1378x2039
296 Кб, 1378x2039

 335 Кб, 1943x2048
335 Кб, 1943x2048 905 Кб, 1834x1021
905 Кб, 1834x1021
Неплохо. Текстурки порельефнее сделать, (типо "запечь" но без запекания, а вручную всё отрисовав) как в старых играх типо варкрафта.
вот бы поюлозить своим хреном у тебя между сисек

блина, такой голос милый..
>выделение памяти для структуры через VirtualAlloc
хм, а разве в винде нет malloc? я мало под неё писал, вернее вообще не писал, так что не знаю
>PeekMessage
какое же winapi все таки странное, капетс
даже как-то сказать нечего, графика как была для меня темным лесом, так наверно и останется
 461 Кб, 1358x2048
461 Кб, 1358x2048В чём проблема? Тебе сколько годиков? Родители нашли заявление на увольнение... ХОСПАДЕ ИСУСИ
 476 Кб, 1378x2039
476 Кб, 1378x2039Проблема в том, что я не могу больше притворяться, что всё ещё работаю и эти хуесосы теперь снова будут трахать мне мозг тем, чтобы я снова шёл работать каким-нибудь долбоёбом
Стань мужиком и выйди на работу делов-то, все хватит ныть возьми себя в руки !!!
 504 Кб, 1665x1665
504 Кб, 1665x1665Работа - это рабство и деградация, если у тебя iq < 115, то не существует интересных работ, существует только унылое бессмысленное дерьмо, которым я не хочу заниматься и мне хуёво
Зачем ты привязываешь свой пессимизм к IQ? Боишься чего-то и пытаешься защититься?
Братан ну еду готовить и мусор выносить так-то тоже уныло.

Я не сразу понял, в чём вообще проблема, вот в более понятной для меня форме https://play.rust-lang.org/?version=stable&mode=release&edition=2021&gist=0449b79fa65e5d294f220a4d58dfb95e
Если попробовать на 12 строке вызвать function, то это не скомпилируется, потому что в теле функции попытка вернуть ссылку с более маленьким лайфтаймом, чем 'static, очевидно.
Если попробовать на 12 строке вызвать f1, то тоже не сработает, потому что хоть f1 и указатель на функцию и мы не знаем, что там на самом деле конкретно внутри возвращается с каким лайфтаймом, но из того, что в самой сигнатуре есть параметр типа "&'a &'b ()", следует, что 'b должен пережить 'a. Но у нас 'a = 'static, а 'b - нет, поэтому тоже скомпилируется.
Проблемы начинаются на 9 строке из-за того, что контравариантность типов параметров функции позволяет переход от "&'a &'b" к "&'a &'static". Тут с самой контравариантностью всё в порядке: если в функцию можно передать ссылку с лайфтаймом 'b, то туда тем более можно передать ссылку со 'static лайфтаймом. Но проблема в том, что при этом теряется информация о том, что 'b должен пережить 'a.
Не знаю, почему ещё не поправили это всё, лень читать тред, там непонятно ничего и слишком сложно для понимания
Ещё такой пример есть https://github.com/rust-lang/rust/issues/25860#issuecomment-1680007800 там как будто используется ковариантность типов возвращаемых значений, но я вообще не понимаю этот пример, слишком запутанный
что не работали плагины, зависящие от триситтера (matchup, например), если грузить их лениво,
и что когда открываешь файл напрямую командой через консоль так `nvim file` (а не внутри самого нвима через :e), то почему-то все лениво загружаемые плагины (триситтер, лсп, например) не давали сразу вывести на экран содержимое файла до того, как они все полностью загрузятся. Видимо, это из-за того, что BufReadPost, который триггерит загрузку большинства моих плагинов, триггерится до загрузки UI, из-за чего ждёшь лишние десятки миллисекунд смотря на чёрный экран, пока грузятся плагины.
Только сейчас попробовал посмотреть подробнее код LazyVim (который готовый конфиг, который я сам по себе не использую, только частично смотрел в нём, как настроить некоторые плагины), в общем,
первая проблема решается тем, чтобы предварительно добавить плагин триситтера в runtimepath https://github.com/LazyVim/LazyVim/blob/78e6405f90eeb76fdf8f1a51f9b8a81d2647a698/lua/lazyvim/plugins/treesitter.lua#L11 Чтобы для других плагинов стали по крайней мере видны все скомпилированные парсеры, и этого вроде достаточно, потому что триситтер частично встроен в нвим, но плагин всё равно нужен, чтобы делать через него подсветку кода, но этим другим плагинам, которые используют триситтер, сам плагин не очень нужен? Там вообще какая-то странная двухсторонняя зависимость между ними бывает.
вторая проблема решается тем, чтобы создать кастомный ивент, который при условии триггера BufReadPost триггерится уже только после загрузки UI https://github.com/LazyVim/LazyVim/blob/78e6405f90eeb76fdf8f1a51f9b8a81d2647a698/lua/lazyvim/util/plugin.lua#L114 и грузить большинство плагинов по этому кастомному ивенту, а не по BufReadPost/BufNewFile/BufWritePre.
Из этого выводы, что
дерево зависимостей глубже одного уровня - это зло,
UI, построенный на колбэках/ивентах с непонятно каким порядком выполнения кода - это зло,
скриптовые языки - это зло, потому что люди неизбежно начинают с их помощью надстраивать что-то гигантское, сложное и непонятное,
единственный правильный способ поддержки расширений - это менять исходный код через гит патчи, добавляющие нужный функционал, и самому пересобирать программу?
Или что мне нужно начать пользоваться блокнотом вместо нвима?
что не работали плагины, зависящие от триситтера (matchup, например), если грузить их лениво,
и что когда открываешь файл напрямую командой через консоль так `nvim file` (а не внутри самого нвима через :e), то почему-то все лениво загружаемые плагины (триситтер, лсп, например) не давали сразу вывести на экран содержимое файла до того, как они все полностью загрузятся. Видимо, это из-за того, что BufReadPost, который триггерит загрузку большинства моих плагинов, триггерится до загрузки UI, из-за чего ждёшь лишние десятки миллисекунд смотря на чёрный экран, пока грузятся плагины.
Только сейчас попробовал посмотреть подробнее код LazyVim (который готовый конфиг, который я сам по себе не использую, только частично смотрел в нём, как настроить некоторые плагины), в общем,
первая проблема решается тем, чтобы предварительно добавить плагин триситтера в runtimepath https://github.com/LazyVim/LazyVim/blob/78e6405f90eeb76fdf8f1a51f9b8a81d2647a698/lua/lazyvim/plugins/treesitter.lua#L11 Чтобы для других плагинов стали по крайней мере видны все скомпилированные парсеры, и этого вроде достаточно, потому что триситтер частично встроен в нвим, но плагин всё равно нужен, чтобы делать через него подсветку кода, но этим другим плагинам, которые используют триситтер, сам плагин не очень нужен? Там вообще какая-то странная двухсторонняя зависимость между ними бывает.
вторая проблема решается тем, чтобы создать кастомный ивент, который при условии триггера BufReadPost триггерится уже только после загрузки UI https://github.com/LazyVim/LazyVim/blob/78e6405f90eeb76fdf8f1a51f9b8a81d2647a698/lua/lazyvim/util/plugin.lua#L114 и грузить большинство плагинов по этому кастомному ивенту, а не по BufReadPost/BufNewFile/BufWritePre.
Из этого выводы, что
дерево зависимостей глубже одного уровня - это зло,
UI, построенный на колбэках/ивентах с непонятно каким порядком выполнения кода - это зло,
скриптовые языки - это зло, потому что люди неизбежно начинают с их помощью надстраивать что-то гигантское, сложное и непонятное,
единственный правильный способ поддержки расширений - это менять исходный код через гит патчи, добавляющие нужный функционал, и самому пересобирать программу?
Или что мне нужно начать пользоваться блокнотом вместо нвима?
 13,1 Мб, webm,
13,1 Мб, webm,960x1034, 9:33
 905 Кб, 1834x1021
905 Кб, 1834x1021Зачем бросил? Хуевит с него?
Я вообще просто хотел понять, что такое машинный эпсилон, потому что когда увидел его случайно в std раста, то подумалось, что а вдруг это то самое, что нужно использовать когда сравниваешь флоаты, но, короче, нет, это вообще дебильное предположение. Он связан с относительной погрешностью, но я так и не понял, какой смысл у того, чтобы взять абсолютную погрешность (например, выраженную в ULP) и поделить её на "настоящее" значение. Видимо, для того, чтобы сделать результат независимым от экспоненты?
Допустим, есть "настоящее" значение 1.0 × 10^{-42} и "вычисленное" значение 1.1 × 10^{-42}. Абсолютная погрешность равна 0.1 × 10^{-42}, что, наверное, ни о чём не говорит, потому что ну типа погрешность выглядит маленькой, но проблема в том, что сами числа тоже маленькие. А относительная погрешность будет равна просто 0.1, наверное, это даёт лучшее представление о точности, не знаю. И если мы работаем с флоатами (β = 10, p = 2), то можно сказать, что ε = 0.05 и оценить количество потенциально неверных знаков с конца через log_β{относительная погрешность / ε}? (p - это размер мантиссы, причём он в том числе включает единицу, которая в IEEE 754 неявная.)
Как я понял, в целом связь машинного эпсилона и относительной погрешности в том, что вот абсолютная погрешность представления флоата максимум равна 1/2 ULP = ((β / 2) · β^{-p}) × β^{e} для какой-то экспоненты e. И эта погрешность верна для всех флоатов в промежутке [β^{e} .. β^{e + 1}) . Но относительная погрешность зависит от "настоящего" вещественного значения, поэтому на этом промежутке она находится где-то в промежутке ((1 / 2) · β^{-p} .. (β / 2) · β^{-p}] - от экспоненты, получается, не зависит. И типо вот как раз верхняя граница этой оценки относительной погрешности определяется как машинный эпсилон. Ну и типо тогда, видимо, имеет смысл измерять погрешность вычислений во флоатах как n × ε, потому что ε - это максимальная точность, которую можно достичь, представляя результат во флоате?
Непонятно, почему-то иногда машинный эпсилон определяется как расстояние от 1.0 до следующего флоата, а иногда как половина от этого расстояния, причём в википедии тоже написано, что это либо то, либо это. Не понимаю.
Ещё один момент, о котором не думал: что во флоатах так-то всякие базовые операции (плюс, минус, умножить, поделить и как минимум вроде ещё квадратный корень) выполняются с максимальной точностью: то есть как если бы флоаты перевели в вещественные числа, сделали вычисления, а потом округлили бы обратно к флоатам. И, как я понял, для этого во внутренней реализации для таких точных вычислений не хватает использования только лишь p цифр мантиссы, нужна хотя бы одна дополнительная цифра (guard digit), чтобы, например, выполнять вычитание двух флоатов с точностью < 2ε (теорема 2 из статьи).
Вроде как эта дополнительная цифра играет роль, когда, например, вычитаешь два числа с разными экспонентами и сдвигаешь мантиссу числа с меньшей экспонентой, чтобы их выровнять.
Допустим, вычисляем 1.01 × 10^{1} - 9.93 × 10^{0}, (β = 10, p = 3)
1.01 × 10^{1} - 0.99 × 10^{1} = 0.02 × 10^{1} = 0.2 × 10^{0}, если не использовать guard digit.
1.010 × 10^{1} - 0.993 × 10^{1} = 0.017 × 10^{1} = 0.17 × 10^{0}, если добавить guard digit.
Но вроде как только одной дополнительной цифры недостаточно для максимальной точности, нужна как минимум ещё вторая дополнительная цифра round digit (видимо, чтобы округление было всегда в правильную сторону, судя по названию? возможно, нужен, потому что когда складываешь или умножаешь нормализованные флоаты, то целая часть может перевалить за 2 цифры?) Sticky bit не знаю, как определяется для произвольного β, в случае с β = 2 вроде как это просто OR всех битов, которые не уместились при сдвиге мантиссы, видимо, чтобы их тоже хотя бы как-то учесть?. Немного более подробно про это я нашёл только тут https://pages.cs.wisc.edu/~markhill/cs354/Fall2008/notes/flpt.apprec.html не знаю, короче.
И, как я понял, этих трёх дополнительных битов должно быть достаточно как для сингловых флоатов, так и для даблов? По крайней мере во всех теоремах про точность вычислений в статье погрешность указывается в машинных эпсилонах, то есть оно не должно зависеть от того, насколько большой сам машинный эпсилон? Вот не знаю, это, наверное, самый непонятный момент для меня.
Я вообще просто хотел понять, что такое машинный эпсилон, потому что когда увидел его случайно в std раста, то подумалось, что а вдруг это то самое, что нужно использовать когда сравниваешь флоаты, но, короче, нет, это вообще дебильное предположение. Он связан с относительной погрешностью, но я так и не понял, какой смысл у того, чтобы взять абсолютную погрешность (например, выраженную в ULP) и поделить её на "настоящее" значение. Видимо, для того, чтобы сделать результат независимым от экспоненты?
Допустим, есть "настоящее" значение 1.0 × 10^{-42} и "вычисленное" значение 1.1 × 10^{-42}. Абсолютная погрешность равна 0.1 × 10^{-42}, что, наверное, ни о чём не говорит, потому что ну типа погрешность выглядит маленькой, но проблема в том, что сами числа тоже маленькие. А относительная погрешность будет равна просто 0.1, наверное, это даёт лучшее представление о точности, не знаю. И если мы работаем с флоатами (β = 10, p = 2), то можно сказать, что ε = 0.05 и оценить количество потенциально неверных знаков с конца через log_β{относительная погрешность / ε}? (p - это размер мантиссы, причём он в том числе включает единицу, которая в IEEE 754 неявная.)
Как я понял, в целом связь машинного эпсилона и относительной погрешности в том, что вот абсолютная погрешность представления флоата максимум равна 1/2 ULP = ((β / 2) · β^{-p}) × β^{e} для какой-то экспоненты e. И эта погрешность верна для всех флоатов в промежутке [β^{e} .. β^{e + 1}) . Но относительная погрешность зависит от "настоящего" вещественного значения, поэтому на этом промежутке она находится где-то в промежутке ((1 / 2) · β^{-p} .. (β / 2) · β^{-p}] - от экспоненты, получается, не зависит. И типо вот как раз верхняя граница этой оценки относительной погрешности определяется как машинный эпсилон. Ну и типо тогда, видимо, имеет смысл измерять погрешность вычислений во флоатах как n × ε, потому что ε - это максимальная точность, которую можно достичь, представляя результат во флоате?
Непонятно, почему-то иногда машинный эпсилон определяется как расстояние от 1.0 до следующего флоата, а иногда как половина от этого расстояния, причём в википедии тоже написано, что это либо то, либо это. Не понимаю.
Ещё один момент, о котором не думал: что во флоатах так-то всякие базовые операции (плюс, минус, умножить, поделить и как минимум вроде ещё квадратный корень) выполняются с максимальной точностью: то есть как если бы флоаты перевели в вещественные числа, сделали вычисления, а потом округлили бы обратно к флоатам. И, как я понял, для этого во внутренней реализации для таких точных вычислений не хватает использования только лишь p цифр мантиссы, нужна хотя бы одна дополнительная цифра (guard digit), чтобы, например, выполнять вычитание двух флоатов с точностью < 2ε (теорема 2 из статьи).
Вроде как эта дополнительная цифра играет роль, когда, например, вычитаешь два числа с разными экспонентами и сдвигаешь мантиссу числа с меньшей экспонентой, чтобы их выровнять.
Допустим, вычисляем 1.01 × 10^{1} - 9.93 × 10^{0}, (β = 10, p = 3)
1.01 × 10^{1} - 0.99 × 10^{1} = 0.02 × 10^{1} = 0.2 × 10^{0}, если не использовать guard digit.
1.010 × 10^{1} - 0.993 × 10^{1} = 0.017 × 10^{1} = 0.17 × 10^{0}, если добавить guard digit.
Но вроде как только одной дополнительной цифры недостаточно для максимальной точности, нужна как минимум ещё вторая дополнительная цифра round digit (видимо, чтобы округление было всегда в правильную сторону, судя по названию? возможно, нужен, потому что когда складываешь или умножаешь нормализованные флоаты, то целая часть может перевалить за 2 цифры?) Sticky bit не знаю, как определяется для произвольного β, в случае с β = 2 вроде как это просто OR всех битов, которые не уместились при сдвиге мантиссы, видимо, чтобы их тоже хотя бы как-то учесть?. Немного более подробно про это я нашёл только тут https://pages.cs.wisc.edu/~markhill/cs354/Fall2008/notes/flpt.apprec.html не знаю, короче.
И, как я понял, этих трёх дополнительных битов должно быть достаточно как для сингловых флоатов, так и для даблов? По крайней мере во всех теоремах про точность вычислений в статье погрешность указывается в машинных эпсилонах, то есть оно не должно зависеть от того, насколько большой сам машинный эпсилон? Вот не знаю, это, наверное, самый непонятный момент для меня.
- Когда вычитаешь друг из друга два близких значения, вычисленных с погрешностью, то получаешь маленькое значение с потенциально очень большой погрешностью (что, наверное, верно не только для флоатов, а в целом в жизни, типо когда измеряешь что-то).
- Даже если финальный результат вычисления умещается во флоат, не факт, что уместятся промежуточные результаты вычислений, из-за чего можно получить вообще неправильный результат (что, наверное, верно не только для флоатов, но и для интов). И ещё, промежуточные результаты могут поместиться во флоат, но быть слишком большими, из-за чего слишком неточными. Чтобы предотвратить это при умножении, можно, например, сделать так (теорема 6): x · y = (x_h + x_l) · (y_h + y_l) = расписать как сумму из чётырёх чисел. В x_h - верхняя половина цифр из мантиссы, в x_l - нижняя. И типо после этого результат не сразу складывать, а попытаться что-нибудь ещё так разложить и сложить члены с одинаковыми экспонентами? Вроде что-то похожее можно сделать, чтобы эмулировать большие инты через маленькие?
- У флоатов нет ассоциативности. И деление не всегда обратимо даже для целых чисел, записанных во флоаты 1002.0F / 100.0F * 100.0F != 1002.0F. Но, что интересно, деление целого числа, записанного во флоате, например, на 10, вроде как почти всегда обратимо умножением на 10 (теорема 7, верно для деления на что угодно вида 2^{i} + 2^{j}, непонятно, правда, в чём смысл и как это хотя бы в теории можно использовать).
- Чем больше флоатовых операций делаешь, тем больше накапливается погрешность, из-за чего, например, вычислять (1 / x)^{n} лучше как 1 / x^{n} (потому что тогда в промежуточных вычислениях степени будет использоваться точный x, а не 1 / x, вычисленный с погрешностью). И эта проблема есть даже с вычислением суммы массива флоатов. Мне это немного ломает мозг с учётом предыдущего утверждения о том, что сумма двух флоатов вычисляется точно, но тут проблема в том, что суммируются не 2, а много флоатов, и на каждом шаге делается округление вместо того, чтобы сложить всё как вещественные числа и потом округлить к флоату. Вроде как есть такой алгоритм, который компенсирует эту погрешность https://en.wikipedia.org/wiki/Kahan_summation_algorithm я не сильно разбирался.
- Флоаты округляются к ближайшему чётному, типо смысл в том, что тогда в 50% случаев в спорной ситуации будет округление вниз, в остальных случаях - вверх. В статье есть вырожденный пример того, что может случиться, если вместо этого округлять всегда вверх (теорема 5), там итеративно прибавляется и вычитается флоат и в итоге результат постепенно смещается, а если округлять к чётным, то остаётся на месте. Интересно, можно ли подобрать такой же вырожденный пример, где бы округление к ближайшему чётному так фейлилось.
И ещё один момент, все эти разговоры о погрешностях имеют смысл только, если входные данные для вычислений - точные. Если они сами по себе вычислены с погрешностью, то не имеет смысла, например, переписывать x^{2} - y^{2} как (x - y) · (x + y), потому что сама разность x - y уже страдает от того, что в статье называется catastrophic cancellation (при условии близости x и y друг к другу), если x и y сами по себе вычислены с погрешностью.
Поэтому, наверное, все вот эти трюки имеют смысл только во всяких библиотечных функциях? В тригонометрических там, например.
Ещё там совсем немного о переводе флоатов в десятичный вид, но не даётся конкретного алгоритма. Только говорится о том, что типа 9 десятичных знаков для сингловых флоатов и 17 для даблов достаточно для того, чтобы перевести флоат в десятичный вид и обратно без потерь. Но это верхняя оценка, на практике может понадобится меньше знаков. Обоснование типо такое, что флоаты вида β = 10, p = 9 на одном и том же промежутке, что флоаты β = 2, p = 24 расположены плотнее, благодаря чему не будет ситуации, когда несколько бинарных флоатов отобразятся в один и тот же десятичный, но при этом может быть наоборот, что два разных десятичных флоата отображаются в один и тот же бинарный - отсюда потенциальная возможность выбрать более короткий вариант десятичного представления, чем 9 знаков.
А как, собственно, переводить флоат в десятичный вид я так особо и не понял. Я пытался читать эту статью https://www.cs.tufts.edu/~nr/cs257/archive/florian-loitsch/printf.pdf но я не осилил, я просто в какой-то момент перестаю понимать, что происходит, я слишком тупой. Ещё такой вариант https://blog.benoitblanchon.fr/lightweight-float-to-string но не знаю, насколько он точный. Там идея в том, чтобы отрубить у флоата экспоненту и потом дробную часть умножить на 10^{9}, привести к инту и привести к десятичному виду. А целая часть после обрубания экспоненты уже должна быть достаточно маленькой, чтобы поместиться в обычный инт. Вроде такая идея.
Тут https://randomascii.wordpress.com/2012/03/08/float-precisionfrom-zero-to-100-digits-2 вроде бы описывается способ точно перевести флоат в десятичный. Там идея в том, чтобы представить флоат как гигантское число с фиксированной точкой (128 бит на целую часть, 149 бит на дробную), чтобы в него записать флоат (по сути достаточно на нужное в соответствии с экспонентой смещение скопировать мантиссу). И потом вроде целую часть итеративно делишь на 10, записывая остатки в целую часть результата. А дробную умножаешь на 10 с переполнением, записывая это переполнение. Типо вроде когда умножаешь в столбик, то обрубаешь всё, что вылезло слева за пределы 149 бит. Я, если честно, ни разу вроде не писал ни деление, ни умножение в столбик.
Ещё у этого же чела в комментариях нашёл про генерацию рандомных флоатов от 0 до 1 https://randomascii.wordpress.com/2012/01/11/tricks-with-the-floating-point-format/#comment-573 В общем, проблема в том, что между 0 и 0.5 флоатов больше, чем между 0.5 и 1 (только лишь между 0.25 и 0.5 их столько же, сколько между 0.5 и 1), из-за чего, если просто взять рандомный u32 и поделить его на u32_max, то на второй половине промежутка некоторые рандомные u32 будут отображаться в одни и те же флоаты, потому что там просто мантиссы не хватает, и это несимметрично с первой половиной промежутка, где флоатов больше. Ну и короче решение просто в том, чтобы обрезать u32 до 23 битов.
Я просто бы, наверное, просто изначально не подумал, что тут есть какая-то проблема, потому что я ебаный даун.
И последнее, вроде как IEEE 754 ничего не говорит о порядке байтов в записи флоатов. По крайней мере в википедии так написано https://en.wikipedia.org/wiki/Endianness#Floating_point Из-за чего в теории порядок байтов у флоатов и интов может отличаться и старший бит инта необязательно соответствует знаковому биту флоата, из-за чего мой abs может в теории не работать. Но, по-моему, всё же на большинстве компов у них порядок байтов совпадает.
- Когда вычитаешь друг из друга два близких значения, вычисленных с погрешностью, то получаешь маленькое значение с потенциально очень большой погрешностью (что, наверное, верно не только для флоатов, а в целом в жизни, типо когда измеряешь что-то).
- Даже если финальный результат вычисления умещается во флоат, не факт, что уместятся промежуточные результаты вычислений, из-за чего можно получить вообще неправильный результат (что, наверное, верно не только для флоатов, но и для интов). И ещё, промежуточные результаты могут поместиться во флоат, но быть слишком большими, из-за чего слишком неточными. Чтобы предотвратить это при умножении, можно, например, сделать так (теорема 6): x · y = (x_h + x_l) · (y_h + y_l) = расписать как сумму из чётырёх чисел. В x_h - верхняя половина цифр из мантиссы, в x_l - нижняя. И типо после этого результат не сразу складывать, а попытаться что-нибудь ещё так разложить и сложить члены с одинаковыми экспонентами? Вроде что-то похожее можно сделать, чтобы эмулировать большие инты через маленькие?
- У флоатов нет ассоциативности. И деление не всегда обратимо даже для целых чисел, записанных во флоаты 1002.0F / 100.0F * 100.0F != 1002.0F. Но, что интересно, деление целого числа, записанного во флоате, например, на 10, вроде как почти всегда обратимо умножением на 10 (теорема 7, верно для деления на что угодно вида 2^{i} + 2^{j}, непонятно, правда, в чём смысл и как это хотя бы в теории можно использовать).
- Чем больше флоатовых операций делаешь, тем больше накапливается погрешность, из-за чего, например, вычислять (1 / x)^{n} лучше как 1 / x^{n} (потому что тогда в промежуточных вычислениях степени будет использоваться точный x, а не 1 / x, вычисленный с погрешностью). И эта проблема есть даже с вычислением суммы массива флоатов. Мне это немного ломает мозг с учётом предыдущего утверждения о том, что сумма двух флоатов вычисляется точно, но тут проблема в том, что суммируются не 2, а много флоатов, и на каждом шаге делается округление вместо того, чтобы сложить всё как вещественные числа и потом округлить к флоату. Вроде как есть такой алгоритм, который компенсирует эту погрешность https://en.wikipedia.org/wiki/Kahan_summation_algorithm я не сильно разбирался.
- Флоаты округляются к ближайшему чётному, типо смысл в том, что тогда в 50% случаев в спорной ситуации будет округление вниз, в остальных случаях - вверх. В статье есть вырожденный пример того, что может случиться, если вместо этого округлять всегда вверх (теорема 5), там итеративно прибавляется и вычитается флоат и в итоге результат постепенно смещается, а если округлять к чётным, то остаётся на месте. Интересно, можно ли подобрать такой же вырожденный пример, где бы округление к ближайшему чётному так фейлилось.
И ещё один момент, все эти разговоры о погрешностях имеют смысл только, если входные данные для вычислений - точные. Если они сами по себе вычислены с погрешностью, то не имеет смысла, например, переписывать x^{2} - y^{2} как (x - y) · (x + y), потому что сама разность x - y уже страдает от того, что в статье называется catastrophic cancellation (при условии близости x и y друг к другу), если x и y сами по себе вычислены с погрешностью.
Поэтому, наверное, все вот эти трюки имеют смысл только во всяких библиотечных функциях? В тригонометрических там, например.
Ещё там совсем немного о переводе флоатов в десятичный вид, но не даётся конкретного алгоритма. Только говорится о том, что типа 9 десятичных знаков для сингловых флоатов и 17 для даблов достаточно для того, чтобы перевести флоат в десятичный вид и обратно без потерь. Но это верхняя оценка, на практике может понадобится меньше знаков. Обоснование типо такое, что флоаты вида β = 10, p = 9 на одном и том же промежутке, что флоаты β = 2, p = 24 расположены плотнее, благодаря чему не будет ситуации, когда несколько бинарных флоатов отобразятся в один и тот же десятичный, но при этом может быть наоборот, что два разных десятичных флоата отображаются в один и тот же бинарный - отсюда потенциальная возможность выбрать более короткий вариант десятичного представления, чем 9 знаков.
А как, собственно, переводить флоат в десятичный вид я так особо и не понял. Я пытался читать эту статью https://www.cs.tufts.edu/~nr/cs257/archive/florian-loitsch/printf.pdf но я не осилил, я просто в какой-то момент перестаю понимать, что происходит, я слишком тупой. Ещё такой вариант https://blog.benoitblanchon.fr/lightweight-float-to-string но не знаю, насколько он точный. Там идея в том, чтобы отрубить у флоата экспоненту и потом дробную часть умножить на 10^{9}, привести к инту и привести к десятичному виду. А целая часть после обрубания экспоненты уже должна быть достаточно маленькой, чтобы поместиться в обычный инт. Вроде такая идея.
Тут https://randomascii.wordpress.com/2012/03/08/float-precisionfrom-zero-to-100-digits-2 вроде бы описывается способ точно перевести флоат в десятичный. Там идея в том, чтобы представить флоат как гигантское число с фиксированной точкой (128 бит на целую часть, 149 бит на дробную), чтобы в него записать флоат (по сути достаточно на нужное в соответствии с экспонентой смещение скопировать мантиссу). И потом вроде целую часть итеративно делишь на 10, записывая остатки в целую часть результата. А дробную умножаешь на 10 с переполнением, записывая это переполнение. Типо вроде когда умножаешь в столбик, то обрубаешь всё, что вылезло слева за пределы 149 бит. Я, если честно, ни разу вроде не писал ни деление, ни умножение в столбик.
Ещё у этого же чела в комментариях нашёл про генерацию рандомных флоатов от 0 до 1 https://randomascii.wordpress.com/2012/01/11/tricks-with-the-floating-point-format/#comment-573 В общем, проблема в том, что между 0 и 0.5 флоатов больше, чем между 0.5 и 1 (только лишь между 0.25 и 0.5 их столько же, сколько между 0.5 и 1), из-за чего, если просто взять рандомный u32 и поделить его на u32_max, то на второй половине промежутка некоторые рандомные u32 будут отображаться в одни и те же флоаты, потому что там просто мантиссы не хватает, и это несимметрично с первой половиной промежутка, где флоатов больше. Ну и короче решение просто в том, чтобы обрезать u32 до 23 битов.
Я просто бы, наверное, просто изначально не подумал, что тут есть какая-то проблема, потому что я ебаный даун.
И последнее, вроде как IEEE 754 ничего не говорит о порядке байтов в записи флоатов. По крайней мере в википедии так написано https://en.wikipedia.org/wiki/Endianness#Floating_point Из-за чего в теории порядок байтов у флоатов и интов может отличаться и старший бит инта необязательно соответствует знаковому биту флоата, из-за чего мой abs может в теории не работать. Но, по-моему, всё же на большинстве компов у них порядок байтов совпадает.
А симейк по дефолту линкует весь этот код динамически + использует ucrt через параметр `-Xclang --dependent-lib=msvcrt`. Тут по размеру получается совсем немного больше, чем с -nostdlib. Мне не то чтобы есть дело до того, что экзешник на 100 килобайтов больше или меньше, но типо я просто не понимал, почему у симейка получается меньше размер. Но, с другой стороны, такой экзешник, наверное, не будет работать на винде, где нету ucrt, плюс типичные дебильные ошибки с тем, что не найден vcruntime какой-то версии.
Я, наверное, разучился пользоваться гуглом, но я не понимаю, откуда я вообще должен узнать, что мне надо добавить этот магический параметр и что он означает. Особенно с учётом того, что как будто более очевидное решение передать в линкер `/defaultlib:ucrt.lib` тупо не работает и выдаёт какие-то стрёмные duplicate symbol ошибки.
Если полностью отказываться от линкования с сишной библиотекой на винде, то достаточно просто определить memcpy и memset и поменять main на mainCRTStartup (если subsystem console). Вызовы memset и memcpy компилятор (по крайней мере кланг точно) может сам вставлять в сгенерированный код, поэтому они нужны. Такое есть в том числе в расте, там есть даже отдельная библиотека со всеми подобными функциями https://github.com/rust-lang/compiler-builtins Для x86 ещё какие-то детали с выравниванием стека есть https://nullprogram.com/blog/2023/02/15/#stack-alignment-on-32-bit-x86
Ещё на винде может понадобиться функция chkstk https://stackoverflow.com/questions/8400118/what-is-the-purpose-of-the-chkstk-function но вроде кланг сам что-то делает с троганьем стека и не нужно её определять.
Меня ещё просто бесит симейк и я его использую только из-за того, что он генерирует compile_commands.json (там просто описание как компилировать все юниты), который использует clangd в основном, чтобы знать дефайны, где хедеры лежат и другие параметры компилятора. Может быть, можно его и вручную попробовать генерировать. А так я бы, может быть, просто одной командой все файлы каждый раз бы компилировал.
А симейк по дефолту линкует весь этот код динамически + использует ucrt через параметр `-Xclang --dependent-lib=msvcrt`. Тут по размеру получается совсем немного больше, чем с -nostdlib. Мне не то чтобы есть дело до того, что экзешник на 100 килобайтов больше или меньше, но типо я просто не понимал, почему у симейка получается меньше размер. Но, с другой стороны, такой экзешник, наверное, не будет работать на винде, где нету ucrt, плюс типичные дебильные ошибки с тем, что не найден vcruntime какой-то версии.
Я, наверное, разучился пользоваться гуглом, но я не понимаю, откуда я вообще должен узнать, что мне надо добавить этот магический параметр и что он означает. Особенно с учётом того, что как будто более очевидное решение передать в линкер `/defaultlib:ucrt.lib` тупо не работает и выдаёт какие-то стрёмные duplicate symbol ошибки.
Если полностью отказываться от линкования с сишной библиотекой на винде, то достаточно просто определить memcpy и memset и поменять main на mainCRTStartup (если subsystem console). Вызовы memset и memcpy компилятор (по крайней мере кланг точно) может сам вставлять в сгенерированный код, поэтому они нужны. Такое есть в том числе в расте, там есть даже отдельная библиотека со всеми подобными функциями https://github.com/rust-lang/compiler-builtins Для x86 ещё какие-то детали с выравниванием стека есть https://nullprogram.com/blog/2023/02/15/#stack-alignment-on-32-bit-x86
Ещё на винде может понадобиться функция chkstk https://stackoverflow.com/questions/8400118/what-is-the-purpose-of-the-chkstk-function но вроде кланг сам что-то делает с троганьем стека и не нужно её определять.
Меня ещё просто бесит симейк и я его использую только из-за того, что он генерирует compile_commands.json (там просто описание как компилировать все юниты), который использует clangd в основном, чтобы знать дефайны, где хедеры лежат и другие параметры компилятора. Может быть, можно его и вручную попробовать генерировать. А так я бы, может быть, просто одной командой все файлы каждый раз бы компилировал.
 158 Кб, 828x892
158 Кб, 828x892Но там всего лишь штук 10 ягод на пакет в 100 граммов и у ароматизатора слишком приторный запах какой-то. У меня изначально сложилось неоправданно положительное впечатление от ароматизированных чаёв из-за того, что первым попался очень вкусно пахнущий. А все последующие, что пробовал, были в лучшем случае терпимыми. Может быть, лучше пить без ароматизаторов и купить каких-нибудь сублимированных ягод. Не знаю, будут ли они сами по себе хотя бы запах давать в чае, не пробовал ни разу.
 6,4 Мб, webm,
6,4 Мб, webm,960x1034, 1:37
Недостаточно просто после клиппинга нарисовать с нуля линию между клипнутыми точками, нужно сохранить наклон старой линии + инициализировать брезенхама в состояние такое, как будто он сам дошёл до пикселя, с которого начинаешь рисовать. Иначе клипнутая линия не будет совпадать с оригинальной
https://en.wikipedia.org/wiki/Cohen–Sutherland_algorithm это типа самый тупой вариант, вроде можно умнее, но я не смотрел и сам не придумаю потому что я ебаный даун
https://git.musl-libc.org/cgit/musl/tree/src/math/floorf.c избегают того, чтобы просто взять и сделать каст к инту и обратно, вместо этого находят, где запятая и вручную делают -1 для отрицательных нецелых, вручную зануляют биты мантиссы
Я не знаю, как должен выглядеть ui код, пока что бред какой-то получается
Я как-то не задумывался, что можно сделать round просто через целочисленное деление, если просто (делимое + делитель / 2) / делитель, но если учитывать отрицательные числа, то получится слишком громоздко, тогда неинтересно
Из CMAKE_C_FLAGS_DEBUG и CMAKE_C_FLAGS_RELEASE убрать все дефолтные флаги и прописывать все флаги вручную. Для мультиконфиг билдов нужно это https://cmake.org/cmake/help/latest/manual/cmake-generator-expressions.7.html потому что на момент конфигурации ты не знаешь, билдишь релиз или дебаг и не можешь просто сделать if(CMAKE_BUILD_TYPE ...). add_compile_options и add_link_options зачем-то выпиливают дубликаты флагов. Нужно делать, например, add_compile_options("SHELL:-Xlinker ..." "SHELL:-Xlinker ..."), иначе он выпилит второй -Xlinker.
Пытаться настроить симейк - ещё более бесполезное занятие, чем сидеть писать конфиги к текстовому редактору
 11 Кб, 400x300
11 Кб, 400x300 1,1 Мб, webm,
1,1 Мб, webm,960x1034, 0:08
Ничего не понимаю, что я делаю. Типа совсем, я не понимал, почему mov из памяти в регистр не работает (нету версии mov из 8-байтового immediate адреса и, видимо, нужно либо относительный адрес делать, либо в регистр абсолютный адрес класть).
И что некоторые операции над младшими кусками регистров зануляют верхние, в том числе у xmm. Но только некоторые, mov al, например, остальные байты не трогает. Поэтому, видимо, если функция, возвращает bool, то проверять нужно именно al, а не rax целиком
И что на винде перед вызовом функций нужно на стеке выделить как минимум 32 байта, но я не понял, зачем. И что стек должен быть выровнен на 16 байт перед вызовом функций, но в начале функции он сдвинут на 8 байт из-за того, что call запушил адрес, куда возвращаться
Квадраты рисую не я, и даже нахождение внутри квадрата не я проверяю, это вот это https://www.raylib.com/cheatsheet/cheatsheet.html Виндовое ABI вроде более-менее простое
 1,7 Мб, mp4,
1,7 Мб, mp4,824x574, 0:06
 285 Кб, 1080x1350
285 Кб, 1080x1350И прикольная идея с тем, что можно несколько раз применить DDA. Типо, что если вычисляем функцию f(x, y) для последовательных точек, прибавляя постепенно D(x, y) = f(x + 1, y) - f(x, y), то эту D(x, y) можно тоже вычислять так последовательно что-нибудь прибавляя.
Я не знаю, как сделать клиппинг для окружностей. Я нагуглил только это https://theswissbay.ch/pdf/Gentoomen%20Library/Game%20Development/Programming/Graphics%20Gems%203.pdf (IV.3 A fast circle clipping algorithm), но это как будто бред какой-то бессодержательный, арккосинусы ещё зачем-то
Типо просто наивно найти точки пересечения прямоугольника и окружности, наверное, и нарисовать видимые куски. Для нахождения точек пересечения с точностью до пикселя нужен квадратный корень с округлением к ближайшему целому. Тут https://en.wikipedia.org/wiki/Integer_square_root#Algorithm_using_Newton's_method пишут, что для округления вниз метод Ньютона для квадратного корня достаточно остановить в момент, когда |x_{k+1} - x_k| < 1 и вернуть floor(x_{k+1}) как результат.
Для округления до ближайшего целого вроде как достаточно остановиться в момент |x_{k+1} - x_k| < 0.5 и вернуть round(x_{k+1}), но я не понимаю, как это формально доказать. Я не понимаю, как с погрешностью связана эта разность предыдущего и следующего приближений
У меня чувство, что по крайней мере залитые одним цветом круги проще рисовать просто проходясь по всем пикселям внутри квадрата
 1,3 Мб, mp4,
1,3 Мб, mp4,960x1032, 0:09
Но в самом triangle fan в контексте рейлиба смысла мало, потому что DrawTriangleFan на самом деле в любом случае там куда-то внутри себя собирает вершины треугольников, чтобы когда-то потом в одном батче их все нарисовать. И там внутри нигде не используется GL_TRIANGLE_FAN, не делается ничего через рестарт индекс.
Я не ожидал, что в xmm похоже вообще нельзя загружать immediate значения, только из памяти или из других регистров. То есть приходится придумывать названия для каждой константы. И что пользоваться fpu сложнее, чем другими инструкциями: там какой-то свой отдельный стек, в который ты пушишь аргументы, делаешь операции и потом достаёшь результат. И похоже, что доставать/класть аргументы можно только промежуточно положив их в память, нельзя из обычного регистра положить что-то на fpu стек или наоборот перенести из fpu стека в регистр.
И я всё ещё не понимаю, как прочитать в регистр что-то по абсолютному 64-битному адресу, nasm обрезает адрес до 32 бит и sign экстендит эту половину до 64 бит, когда я пишу "mov r, [abs qword label]". При этом как будто бы оно существует "Move r/m64 to r64" https://www.felixcloutier.com/x86/mov но почему у меня ничего не получается. И не получается даже через lea положить в регистр абсолютный адрес, там то же самое.
И адресовать массив, расположенный в data секции, я тоже не понимаю как (ну типа label + регистр умножить на размер элемента), у меня тоже ничего не работает
 738 Кб, 909x1400
738 Кб, 909x1400Не нужно читать по абсолютным 64-битным адресам, доступ к глобальным переменным в x64 почти всегда (когда их меньше 2 Гб; PE EXE в Windows >2 Гб принципиально не поддерживает, и нормально) делается как RIP-relative. Если нужно больше 2 Гб (не нужно, такое нужно динамически выделять и из внешнего файла загружать), есть модели с «абсолютными» адресами: https://wiki.osdev.org/X86-64#Text_Segment_Types, https://eli.thegreenplace.net/2012/01/03/understanding-the-x64-code-models, я не знаю, как они работают, но по логике ты кладёшь адреса в регистр через mov r64, imm64, И — это важно — добавляешь эту инструкцию в relocations, чтобы загрузчик в условиях ASLR и прочего поменял адрес в этой инструкции на настоящий. В “FPC-flavored GNU assembler” это каким-то таким заклинанием делается: https://gitlab.com/freepascal.org/fpc/source/-/blob/139f2dfe84cf07d03e461e50097a426cd88a0797/rtl/x86_64/x86_64.inc#L341 (помещаем адрес переменной fast_large_repmovstosb: boolean в r9 через mov r64, imm64 с добавлением этой инструкции в список релокаций, затем работаем по адресу в r9), в NASM тоже гуглится что-то на тему got / gotpcrel. Короче говоря, лучше не вскрывать эту тему, смысл RIP-relative как раз в том, что фишка напрямую поддерживается набором инструкций, позиционно-независимый код без необходимости вписывать правильные адреса получается автоматически, а 2 (4?) Гб хватит всем.
Чтобы «адресовать массив, расположенный в data-секции», ты сначала помещаешь его адрес в регистр соответствующим способом (RIP-relative — lea reg, [rel arr]; это отдельный способ адресации, несовместимый с base + index × scale в рамках одной и той же инструкции, размечтался), и уже потом используешь его как base в base + index × scale.
 305 Кб, 638x765
305 Кб, 638x765 807 Кб, 1564x2048
807 Кб, 1564x2048Ну да, понятно вообщем спасибо, у меня как-то не зарегистрировалось в голове, что абсолютные адреса же ещё будут на каждом запуске разными и непредопределёнными (несмотря на то, что, запуская код в дебаггере, видел, что адреса каждый раз разные)
>сначала помещаешь его адрес в регистр соответствующим способом (RIP-relative — lea reg, [rel arr]; это отдельный способ адресации, несовместимый с base + index × scale в рамках одной и той же инструкции
Ну да, я догадался сделать так и до того, что оно не будет работать с относительными адресами, поэтому снова вспомнил, что у меня не получалось mov использовать с абсолютными в более простом варианте адресации
 281 Кб, 1411x1852
281 Кб, 1411x1852Если делаешь subsystem windows, то приложение сразу же отсоединяется от консоли и шелл уже показывает промпт для ввода следующей команды, не дожидаясь закрытия гуишного окна. AttachConsole(ATTACH_PARENT_PROCESS) позволяет что-то писать в оторванную консоль из приложения, но это всё ещё конфликтует с шеллом, который рисует следующий промпт, затирает то, что пишет приложение, и обрабатывает инпут из консоли.
Если делаешь subsystem console, то вместе с гуишным окном неизбежно создастся консольное окно, когда запускаешь экзешник из эксплорера. Можно закрыть через FreeConsole, но оно всё равно на мгновение появится. Нужно понять, запустили ли тебя из эксплорера или консоли, чтобы делать FreeConsole только в первом случае. Я видел, люди предлагают смотреть на возвращаемые значения GetConsoleTitle, GetConsoleScreenBufferInfo, AttachConsole(ATTACH_PARENT_PROCESS), но для меня они все не работают вместе с subsystem console. Это https://devblogs.microsoft.com/oldnewthing/20160125-00/?p=92922 вроде работает.
Как это обходят другие люди - делают два экзешника: один - гуишное приложение, второй - консольный враппер. Например, у mpv есть "mpv.com" для консоли - он запускает основное приложение "mpv.exe", передавая информацию о том, что юзер запустил приложение из консоли через переменную среды https://github.com/mpv-player/mpv/blob/e42a8d537f575cf61747e9f67c5a9e34f511cb2b/osdep/win32-console-wrapper.c#L95
"mpv.exe" - полностью отдельный экзешник со своей отдельной точкой входа https://github.com/mpv-player/mpv/blob/e42a8d537f575cf61747e9f67c5a9e34f511cb2b/osdep/main-fn-win.c#L60
"mpv.exe" по дефолту запускается в гуишном режиме, но, если задана та переменная среды внутри консольного враппера, то он аттачит консоль родительского процесса "mpv.com" и использует его хэндлы на stdout, stdin, stderr. И тут избегается проблема subsystem windows с тем, что шелл не дожидается закрытия гуишного окна, потому что "mpv.com" висит и ждёт завершения дочернего процесса.
И ещё "mpv.com" почему-то имеет больший приоритет, чем "mpv.exe", когда пишешь "mpv" что в павершелле, что в cmd (алфавитный порядок?) А когда в поиске пишешь mpv, то приоритет у "mpv.exe". То есть оно работает бесшовно, если ты везде пишешь "mpv" без расширения.
Вообще я не знаю, что такое COM, https://devblogs.microsoft.com/oldnewthing/20080324-00/?p=23033 вроде какой-то старый формат экзешников, который просто содержит машинный код с первого же байта. Но в случае с mpv всё же "mpv.com" - это не COM, а PE экзешник с переименованным расширением, но винда умеет такое корректно такое загружать, поэтому всё в порядке, кроме того, что мне очень хочется уже умереть
281 Кб, 1411x1852Если делаешь subsystem windows, то приложение сразу же отсоединяется от консоли и шелл уже показывает промпт для ввода следующей команды, не дожидаясь закрытия гуишного окна. AttachConsole(ATTACH_PARENT_PROCESS) позволяет что-то писать в оторванную консоль из приложения, но это всё ещё конфликтует с шеллом, который рисует следующий промпт, затирает то, что пишет приложение, и обрабатывает инпут из консоли.
Если делаешь subsystem console, то вместе с гуишным окном неизбежно создастся консольное окно, когда запускаешь экзешник из эксплорера. Можно закрыть через FreeConsole, но оно всё равно на мгновение появится. Нужно понять, запустили ли тебя из эксплорера или консоли, чтобы делать FreeConsole только в первом случае. Я видел, люди предлагают смотреть на возвращаемые значения GetConsoleTitle, GetConsoleScreenBufferInfo, AttachConsole(ATTACH_PARENT_PROCESS), но для меня они все не работают вместе с subsystem console. Это https://devblogs.microsoft.com/oldnewthing/20160125-00/?p=92922 вроде работает.
Как это обходят другие люди - делают два экзешника: один - гуишное приложение, второй - консольный враппер. Например, у mpv есть "mpv.com" для консоли - он запускает основное приложение "mpv.exe", передавая информацию о том, что юзер запустил приложение из консоли через переменную среды https://github.com/mpv-player/mpv/blob/e42a8d537f575cf61747e9f67c5a9e34f511cb2b/osdep/win32-console-wrapper.c#L95
"mpv.exe" - полностью отдельный экзешник со своей отдельной точкой входа https://github.com/mpv-player/mpv/blob/e42a8d537f575cf61747e9f67c5a9e34f511cb2b/osdep/main-fn-win.c#L60
"mpv.exe" по дефолту запускается в гуишном режиме, но, если задана та переменная среды внутри консольного враппера, то он аттачит консоль родительского процесса "mpv.com" и использует его хэндлы на stdout, stdin, stderr. И тут избегается проблема subsystem windows с тем, что шелл не дожидается закрытия гуишного окна, потому что "mpv.com" висит и ждёт завершения дочернего процесса.
И ещё "mpv.com" почему-то имеет больший приоритет, чем "mpv.exe", когда пишешь "mpv" что в павершелле, что в cmd (алфавитный порядок?) А когда в поиске пишешь mpv, то приоритет у "mpv.exe". То есть оно работает бесшовно, если ты везде пишешь "mpv" без расширения.
Вообще я не знаю, что такое COM, https://devblogs.microsoft.com/oldnewthing/20080324-00/?p=23033 вроде какой-то старый формат экзешников, который просто содержит машинный код с первого же байта. Но в случае с mpv всё же "mpv.com" - это не COM, а PE экзешник с переименованным расширением, но винда умеет такое корректно такое загружать, поэтому всё в порядке, кроме того, что мне очень хочется уже умереть


Типа контекст - структура со всякой ерундой, которую обычно через глобальные переменные делают, например, аллокатор, логгер и прочее такое
Я не придумал, как через такое обобщённое апи сделать так, чтобы динамический массив с линейным аллокатором не тратил впустую память. Добавить функцию реаллок и сделать, чтобы линейный аллокатор мог по возможности расширить последнюю аллокацию, а не выделять новый кусок?
Я хотел бы попробовать написать решение этого https://adventofcode.com/2023/day/1 на саммсебреле, но я слишком тупой и мне страшно. Я так понимаю, когда я буду искать цифры, после сравнения, чтобы достать первую или последнюю цифру в строке, мне нужно будет перевести маску в более удобный вид https://www.felixcloutier.com/x86/pmovmskb и понять, какой по счёту байт мне нужен (через инструкции LZCNT или TZCNT)? Я думал, может быть, есть инструкция, которая бы позволила по маске извлечь один байт из SIMD регистра и положить этот один единственный байт куда-то в память, но не могу найти такое. Самое близкое это https://www.felixcloutier.com/x86/maskmovdqu но это вроде не то, оно сохранит замаскированные байты сохраняя смещения. Shuffle инструкции вроде работают только с immediate, blend - тоже что-то не то, наверное, нет такого, не знаю.
Не хочется жить
А, ссылкиhttps://play.rust-lang.org/?version=stable&mode=debug&edition=&gist=e спойлерземля тебе пухом, кста а в каком моменте он был во втором сезоне? я просто дропнул сезон с первом серии мне не в катила эта тема с рабами bdebafbfaedacaadだ。.
 1,1 Мб, 1000x1414
1,1 Мб, 1000x1414Если ты прочитал вектор по адресу A, что-то насравнивал, и из результата сравнения получил смещение через pmovmskb + bsf/tzcnt (положим i), то для извлечения значения по этому смещению ты перечитываешь его с адреса A + i. :) Я так делал в CompareByte (memcmp), вот здесь https://gitlab.com/freepascal.org/fpc/source/-/blob/b3c1f294ba4b69f2d3bee53730c86af204e456b9/rtl/x86_64/x86_64.inc#L856 перечитываются и вычитаются два байта по смещению, полученному из pmovmskb + bsf.
 288 Кб, 1377x2048
288 Кб, 1377x2048 67 Кб, 1171x840
67 Кб, 1171x840Теперь попробовал это:
>An aromatic blend of premium Ceylon black tea, raisins and soursop infused with the fruity flavour of white grape wine. With Nuwara Eliya tea, you are offered a fruity taste of grape and soursop with a hint of floral taste. Enjoy every sip.
Он просто невкусный. Меня от него не передёргивает, как от эрл грея после каждого глотка, но он просто пахнет как будто грязной половой тряпкой, а на вкус почти никакой, как будто его и нет почти.
Где-то две недели назад сломал очередные проводные наушники (случайно погнул штекер, я не осилю заменить его: единственный раз, когда пробовал чинить наушники - очень быстро снова их сломал, я слишком тупой для этого). Подумал, может быть, стоит купить беспроводные, короче, теперь кринжовая реальность - что иногда нужно снять наушники, чтобы их зарядить + ощутимая небольшая задержка, когда играешь в игры. А из плюсов от того, что они беспроводные - только, что я теперь не могу сломать провод.
Единственный сценарий, когда они удобнее проводных - когда делаешь что-то на кухне руками, ходишь туда-сюда, и одновременно что-то смотришь на телефоне. Можно телефон в одно место положить, не быть привязанным к нему наушниками и иметь возможность поглядывать на экран.
Про всякие дополнительные вещи, которые обычно пихают в беспроводные наушники, вроде микрофона, шумодава, режима прозрачности, жестов для управления, с моей стороны было бы говорить нечестно с учётом того, что я купил дешёвые наушники. Может быть, в каких-нибудь более дорогих есть, например, волшебный шумодав, который реально все звуки извне блокирует, а не просто давит шипением на барабанные перепонки, как мой китайский кусок мусора хуавей 5i. Но я тут и не рассчитывал ни на что с самого начала.
Короче, беспроводные устройства - это похоже просто очередной гиммик




В общем, если кейсов мало, то if-else.
Если кейсов много, но значения в них последовательные, то генерируется массив из адресов кейсов, куда прыгать, который индексируется значением, по которому делается свитч. Если есть небольшие дыры, то их можно заделать вставкой адреса, куда переходить, если значение не подошло ни под один кейс.
Если кейсов много и между значениями слишком большие дыры, то делается бинарный поиск с захардкоженными всеми возможными ветками и сравнениями. И это может комбинироваться с таблицей адресов для прыжков, если в какой-то ветке бинарного поиска остаётся кусок значений, которые (почти) последовательные внутри этого куска. Вроде бы он ещё умеет видеть кластеры близких друг к другу значений кейсов и делать под каждый из них отдельную таблицу, то есть не просто пополам делить бинарным поиском.
Не знаю, есть ли какой-то предел по количеству кейсов, после которого компиляторы перестают генерировать таблицу прыжков, как будто бы не должно быть, потому что если каждому кейсу соответствует какой-то отдельный уникальный немного осмысленный кусок кода, то эта таблица вроде не должна слишком уж сильно раздуть экзешник по сравнению с вариантом с if-else.
Вроде как кланг в случае со свитчем на 100к кейсов генерирует (очень долго, я не замерял, но минут 5-10) табличку (в коде на 4 картинке видно, что он что-то читает из памяти, там адрес из .rdata секции, и там дальше ниже уже идут разные кейсы почему-то в рандомном порядке). Кстати, сейчас подумал, что может быть, тут можно было бы обойтись и без таблички с учётом того, что размер кода во всех кейсах одинаковый и кейсы идут от 0 до 100к без дырок? Может быть, можно было бы вычислять нужный адрес напрямую, а не индексировать сначала таблицу.
Макросы в виме с навешанными на него плагинами как-то совсем дико медленно работают (я ими генерировал файл со свитчем на много кейсов) и я не уверен, какой конкретно плагин является причиной, было лень разбираться, просто все отключил, когда это делал.
Странно слышать после этого, что вим с плагинами какой-то по-особенному крутой по сравнению с другими редакторами, когда плагины убивают одну из самых прикольных фич вима. Я сомневаюсь даже, что за счёт отсутствия нормального GUI он работает быстрее других редакторов, которые зачастую внутри используют те же самые лсп, что и вим. То есть это уже даже не вим по своей сути, а очередной унылый редактор, у которого единственная отличительная бесполезная особенность - что его внутри терминала можно запустить.
Я какое-то время назад добавил в вим команду, чтобы переключаться между разными шеллами (cmd, pwsh, msys2, wsl) и заметил, что почему-то в как будто рандомные моменты меня начало переключать в wsl-ный шелл. До меня очень не сразу дошло, что я иногда случайно пишу :W вместо :w для сохранения файла, и эта :W выполняет мою кастомную команду :WSL. Потому что виме, если ты пишешь неполное уникальное начало команды, то он её без вопросов выполняет, и так получилось, что единственная команда, начинающаяся на W - это моя кастомная для переключения шелла на wsl-левский.
Короче, я решил это так, что просто назначил на :W тоже сохранение файла
В общем, если кейсов мало, то if-else.
Если кейсов много, но значения в них последовательные, то генерируется массив из адресов кейсов, куда прыгать, который индексируется значением, по которому делается свитч. Если есть небольшие дыры, то их можно заделать вставкой адреса, куда переходить, если значение не подошло ни под один кейс.
Если кейсов много и между значениями слишком большие дыры, то делается бинарный поиск с захардкоженными всеми возможными ветками и сравнениями. И это может комбинироваться с таблицей адресов для прыжков, если в какой-то ветке бинарного поиска остаётся кусок значений, которые (почти) последовательные внутри этого куска. Вроде бы он ещё умеет видеть кластеры близких друг к другу значений кейсов и делать под каждый из них отдельную таблицу, то есть не просто пополам делить бинарным поиском.
Не знаю, есть ли какой-то предел по количеству кейсов, после которого компиляторы перестают генерировать таблицу прыжков, как будто бы не должно быть, потому что если каждому кейсу соответствует какой-то отдельный уникальный немного осмысленный кусок кода, то эта таблица вроде не должна слишком уж сильно раздуть экзешник по сравнению с вариантом с if-else.
Вроде как кланг в случае со свитчем на 100к кейсов генерирует (очень долго, я не замерял, но минут 5-10) табличку (в коде на 4 картинке видно, что он что-то читает из памяти, там адрес из .rdata секции, и там дальше ниже уже идут разные кейсы почему-то в рандомном порядке). Кстати, сейчас подумал, что может быть, тут можно было бы обойтись и без таблички с учётом того, что размер кода во всех кейсах одинаковый и кейсы идут от 0 до 100к без дырок? Может быть, можно было бы вычислять нужный адрес напрямую, а не индексировать сначала таблицу.
Макросы в виме с навешанными на него плагинами как-то совсем дико медленно работают (я ими генерировал файл со свитчем на много кейсов) и я не уверен, какой конкретно плагин является причиной, было лень разбираться, просто все отключил, когда это делал.
Странно слышать после этого, что вим с плагинами какой-то по-особенному крутой по сравнению с другими редакторами, когда плагины убивают одну из самых прикольных фич вима. Я сомневаюсь даже, что за счёт отсутствия нормального GUI он работает быстрее других редакторов, которые зачастую внутри используют те же самые лсп, что и вим. То есть это уже даже не вим по своей сути, а очередной унылый редактор, у которого единственная отличительная бесполезная особенность - что его внутри терминала можно запустить.
Я какое-то время назад добавил в вим команду, чтобы переключаться между разными шеллами (cmd, pwsh, msys2, wsl) и заметил, что почему-то в как будто рандомные моменты меня начало переключать в wsl-ный шелл. До меня очень не сразу дошло, что я иногда случайно пишу :W вместо :w для сохранения файла, и эта :W выполняет мою кастомную команду :WSL. Потому что виме, если ты пишешь неполное уникальное начало команды, то он её без вопросов выполняет, и так получилось, что единственная команда, начинающаяся на W - это моя кастомная для переключения шелла на wsl-левский.
Короче, я решил это так, что просто назначил на :W тоже сохранение файла
 15,4 Мб, webm,
15,4 Мб, webm,960x1032, 10:31
 421 Кб, 1884x388
421 Кб, 1884x388Как я понял, на чёрных клетках рисуешь рандомные вертикальные, на белых - рандомные горизонтальные, потом дорисовываешь недостающие
 30 Кб, 818x312
30 Кб, 818x312Как я понял, это так ни в какой стандарт и не приняли
https://www.open-std.org/jtc1/sc22/wg14/www/docs/n2083.htm
А в плюсах их вроде по-хорошему вообще не существует как таковых
Понятно, что существующим компиляторам наверняка всё равно на такие моменты в стандартах и они съедят многое, но всё равно как-то неприятно. Неприятно не из-за того, что ой, а вдруг код сломается в новой версии компилятора из-за того, что я использую что-то нестандартизированное - это не проблема, просто можно продолжить использовать конкретную старую версию компилятора, в которой всё нормально было.
А из-за того, что кто-то, реализовав компилятор следуя только стандарту, не сможет компилировать код со всякими упоротыми расширениями (вроде такого https://clang.llvm.org/docs/BlockLanguageSpec.html - это похоже кложуры в си?) И ему придётся повторять путь существующих или существовавших компиляторов (когда весь код перепишут на раст и си и плюсы будут не нужны), чтобы что?
 19,6 Мб, webm,
19,6 Мб, webm,1280x720, 1:35
Я так до сих пор и не прошёл элдер ринг ни разу из-за своей шизы с удалением сейвов. Айзека, кстати, только относительно недавно прошёл спустя почти 3 года после выхода репы, и первый раз все ачивки закрыты с 2014. Там как будто новое обновление будет когда-то, а у меня закрытого сейва своего уже нету, ну тут не по моей вине, его каким-то образом скорраптила стим помойка
 19,6 Мб, webm,
19,6 Мб, webm,1280x720, 1:14
 19,7 Мб, webm,
19,7 Мб, webm,1280x720, 1:10
Днём пробовал ходить ногами немного больше 20 километров, короче, это просто дикое уныние и бессмысленная трата времени и я теперь хочу умереть только ещё сильнее
 19,7 Мб, webm,
19,7 Мб, webm,1280x720, 1:13
 19,6 Мб, webm,
19,6 Мб, webm,1280x720, 1:28
 19,7 Мб, webm,
19,7 Мб, webm,1280x720, 1:42
 19,8 Мб, webm,
19,8 Мб, webm,1280x720, 0:54
 18,9 Мб, webm,
18,9 Мб, webm,1280x720, 0:26
 19,7 Мб, webm,
19,7 Мб, webm,1280x720, 1:17
 19,7 Мб, webm,
19,7 Мб, webm,1280x720, 1:17
 19,9 Мб, webm,
19,9 Мб, webm,1280x720, 0:55


Парные боссы - это рнг бред. Это, понятно, что даже не босс по сути, но они будут позже и я, скорее всего, не вывезу их, если не начну прокачивать лвл. Меня с моим хп скоро будет вообще любой бомж ваншотать. Но, с другой стороны, я ненавижу прокачку в играх, какое-то дикое уныние для любителей сидеть и высчитывать, как бы заминмаксить статы
Лучше бы начальный класс полностью определял траекторию прокачки, а прокачка была бы линейной, например, по ходу прогресса тебе бы давали предметы, которые увеличивают статы. По-моему, в секире примерно так и было сделано для прокачки хп и урона, но зато было дебильное дерево прокачки протеза






Мне снова каждый день ебут мозг и я хочу умереть








Как же мощно амдшный хардварный ав1 энкодер периодически не вывозит: просто в рандомные моменты начинает лагать, причём это с speed пресетом





Я два дня не могу сесть и доделать это, там нужно сделать ещё хотя бы объединение чанков с соседними при освобождении и отдельные списки свободных чанков для заранее определённых мелких размеров, но я не знаю, мне не хочется, мне хочется нахуй повеситься уже, зачем жить


Моей видеокарте тоже как-то нехорошо стало, почему-то запись ещё сильнее лагать стала


>если у меня будет новая видеокарта, то это будет амд
Никогда больше не буду покупать этот мусор


H.265 тоже точно так же в рандомные моменты начинает лагать, непонятно, в среднем меньше, чем ав1, или так же. А амдшный H.264 вообще выдаёт слишком мусорное качество, чтобы им можно было пользоваться. Я не знаю, может быть, она перегревается, но почему тогда перегревается только энкодер, а всей остальной видеокарте нормально
Может быть, она просто уже подыхает, потому что вроде же недавно эта проблема не была так сильно выражена, ну, реже случалось. Либо ничего не изменилось и мне просто сейчас не повезло, что это произошло в неудачный момент, не знаю, короче. Мне просто от любой такой даже мелкой вещи сейчас хочется умереть только ещё сильнее, завтра ещё что-нибудь случится, ну типо чай пролью, и, наверное, повешусь нахуй блять


 1,3 Мб, 1893x1734
1,3 Мб, 1893x1734



Ещё один неоправданно жирный моб с миллионом хп и пойза, с которого не падает ничего уникального


















Тебе сколько, ОП? Сам живу в таком же состоянии, ни жив ни мёртв.






Всё же нашёл более-менее нормальную одежду




Опенинги обычно бывают после того, как он две каких-то атаки сделал: два раза укусил, махнул лапой и ударил в землю, укусил и махнул лапой и тд, но во второй фазе это не всегда работает: у него появляются более длинные комбо. Перекатываться от его атак назад, два раза подряд, но, если видишь, что случайно сблизился с ним, то наоборот: вперёд под него, потому что иначе не успеваешь выкатиться из-под аое
В остальных случаях просто доджить все остальные атаки и ждать, из-за чего всё растягивается на минуты 4. Можно пытаться бегать у него под ногами и бить по ним, но он постоянно будет на тебя вешать электрический заряд, из-за чего не получится даже два раза нормально ударить подряд, будешь как мышь туда-сюда бегать, тяжело, хоть и будет быстрее, я думаю
Круговая атака во второй фазе доджится перекатом влево вроде довольно стабильно. Сквозь волны на земле можно перекатываться.
Текстовый туториал на босса, потому что ну правда неочевидно, что с ним делать, особенно, когда он почти всеми своими атаками меня ваншотит


Ладно, она легко проходится на моём низком лвле и даже без оверлвл оружия, просто это долго




Проблема в том, что получилось говно и я ебаный отсталый даун, потому что
Во-первых, в консоли нет дабл буферинга, из-за чего в миллисекундах будет выводиться мусор с большой вероятностью, плюс я зачем-то трачу время на перерисовку вообще всего кода, хотя меняются только цифры, но это ладно, оно толерантно к мусору в цифрах.
Во-вторых, оно просто адово жирное и даже не убирается нормально на экран. Много места занимает шрифт, закодированный в инты, может быть, стоило бы кодировать в base64, сам блоб был бы компактнее, но тогда бы пришлось ещё впихнуть base64 декодер в код, неясно, было ли бы лучше. И/или добавить сжатие одинаковых подряд идущих символов с теми же издержками.
Плюс ещё аргументы принтфов раздувают код а их нужно использовать по той причине, что ты не можешь ни в каком виде в строковые литералы с кодом программы включить символы из набора: " % \. Эскейпить не выйдет, потому что тогда придётся эскейпить символы, КОТОРЫМИ ты эскейпишь, и в итоге тебе нужно бесконечно эскейпов. По этой же причине нельзя использовать \n. Поэтому нужно либо использовать %c + аски код символа в аргументах, либо нормальный вариант - это писать свой принтф, который будет автоматом эскейпить всё сам при выводе (это то, как сделал этот чел с первого видео, как я понял). Ну и всё нужно было делать более широким, чтобы уменьшить высоту.
В-третьих, я пытался код сделать выровненным, но вот в середине кусок строкового литерала обрывается в начале строки. Я бы мог забить оставшееся место просто ;;;;;;;;;; но проблема в том, что тогда эти точки с запятой нужно также добавить внутрь строкового литерала с кодом программы, то есть на самом деле нужно добавить количество символов равное половине оставшегося места, НО оно не делится на 2 и всё равно не будет выровнено. То есть придётся внизу менять код, чтобы добавить один символ где-то, но тогда сам код внизу съедет. И я не понимаю, как это всё выровнять, видимо, наоборот, пытаться сжать код, но как будто те же проблемы вылезут.
Кроме того, куча кринжа связанного с тем, чтобы выровнять код: опять же, бесполезные точки с запятой и кудрявые скобки, неоправданно длинные идентификаторы, шестнадцатеричные и восьмеричные интовые литералы, интовые литералы, переписанные как сумма маленького и большого, забивание комментов и строк бесполезными символами (надпись "time's up" в конце даже не успевает вывестись на экран, она моментально затирается, она там чисто для выравнивания). Единственное правило, которое пытался соблюдать - отсутствие лишних пробелов, но мог что-то пропустить случайно. Можно было бы эксплоитить всякую си шизу с тем, что, например, у переменных по дефолту тип инт и тп, но я в ней не особо разбираюсь и я не хочу. Плюс инклюд можно было бы добавить как аргумент компилятора, но тогда придётся добавлять в коммент инструкции по компиляции, а я хотел, чтобы оно компилилось просто как "cc quimer.c", по этой же причине использую какую-то непонятную c11 timespec_get ерунду: потому что она доступна на всех компиляторах и платформах вроде.
В-четвёртых, САМОЕ ГЛАВНОЕ ЭТО БЛЯТЬ ДАЖЕ НЕ КВАЙН, Я ДАУН И НЕ ОСИЛИЛ, я слишком поздно понял, что то, как я отформатировал литералы с кодом прораммы - это никак не отразится на том, что напечатается на экране. По этой причине на видео видно, что литералы печатаются просто в одну строку. У чела в видео - настоящий квайн, то есть его прога сама себя печатает (он чёто не показал дифф), у меня печатает только в лучшем случае наполовину такую же программу.
Как исправить, оставив выравнивание - я не знаю. С принтф это точно невозможно, потому что ты обязан переносить литерал именно только там, где есть перенос в коде, и вставлять туда %c для новой строки. И код в строковом литерале будет длиннее самого кода, то есть по крайней мере они не могут быть выровнены на одну ширину. У чела в видео с кастомным принтфом тоже так, если посмотреть: каждый кусок литерала заканчивается на \n и он вручную при выводе после переносов строк добавляет двойные кавычки (код в конце p('\\');p('n');p('"');p('\n');p('"')).
Решается это, скорее всего, тем, что опять же, делать кастомный принтф, который по ходу вывода в консоль считает символы в строке и в нужные моменты сам делает перенос, без необходимости добавлять в сам литерал индикаторы того, где нужно делать переносы. Плюс иметь удачу или большой мозг, чтобы в итоге всё красиво вручную выровнять, либо ещё более большой мозг, чтобы написать прогу, которая выравнивает всё сама, применяя всякие ухищрения. И эта прога - это всё ещё, к сожалению, не чат джипити инб4 ты неправильно объясняешь, что нужно сделать, к тому же слепить всё в одну строку, убрав пробелы даже там, где нельзя - это тоже валидный вариант выровнять код, ты ведь не указал максимальную длину строки А я же реально жду, когда смогу попросить его сгенерировать аски арт и получить в ответ что-то отличное от рандомного набора символов, ну и в целом, момента, когда оно будет способно на что-то реально интересное само по себе, и искренне надеюсь, что это когда-нибудь случится, но пока что это просто сплошное разочарование какое-то.
Ну и ещё одна причина, по которой это даже в теории не может быть квайном - это то, что это более-менее честный таймер и "запускается" он как можно быстрее после запуска программы, после чего перед выводом цифр тратится немного времени по крайней мере на то, чтобы распарсить шрифт из массива интов, из-за чего на момент вывода цифр в консоль там уже останется меньше времени, чем написано в коде программы.
Единственный более-менее прикольный момент этой проги - это то, что вот эти большие цифры посередине - это именно то, что определяет, на сколько минут/секунд запустится таймер, и типо видно на видео, что пока таймер крутится, то кроме самих цифр в коде ничего больше не меняется, ну и я вручную именно цифры поменял и тем самым задал время. (Если честно, я настолько блять тупой, что только когда начал это всё делать, понял, что я же могу просто в коде переменным присвоить количество минут, секунд и миллисекунд, и вся эта идея имеет ОЧЕНЬ МАЛО СМЫСЛА.) Чтобы это реализовать, я считаю что-то типо хэша: взвешенную сумму всех символов, составляющих глиф. Веса зависят от типов символов (ну, пробел, вертикальная черта, нижнее подчёркивание, иначе сумма всех символов одинакова у всех глифов, потому что шрифт моноширинный) + от игрек координаты (потому что иначе у 6 и 9 и у 5 и 2 получаются всегда попарно одинаковые хэши). Ну и дальше просто типо очень упрощённая хэш таблица без коллизий, но кринжовая, потому что на 12 элементов требуется целых 35 ячеек. И все неактивные ячейки забиты нулями и это то, благодаря чему оно не особо сходит с ума от мусорных символов, но, наверное, всё ещё может сделать что-то странное, если хэш попадёт в ячейку с точкой или точкой с запятой. Ну и ещё неприятно то, что вероятно даже мелкие изменения в символах, визуально ничего не меняющие, возможно, будут кардинально менять то, как они интерпретируются.
Короче, это моя вторая попытка сделать квайн, в первый раз получился вообще полный мусор, но то был хотя бы действительно квайн (я там просто код программы внутри строки закодировал в base64, типа чтобы было не совсем очевидно, что это квайн, и тоже просто принтф использовал). А тут я не осилил даже квайн сделать в итоге.
Проблема в том, что получилось говно и я ебаный отсталый даун, потому что
Во-первых, в консоли нет дабл буферинга, из-за чего в миллисекундах будет выводиться мусор с большой вероятностью, плюс я зачем-то трачу время на перерисовку вообще всего кода, хотя меняются только цифры, но это ладно, оно толерантно к мусору в цифрах.
Во-вторых, оно просто адово жирное и даже не убирается нормально на экран. Много места занимает шрифт, закодированный в инты, может быть, стоило бы кодировать в base64, сам блоб был бы компактнее, но тогда бы пришлось ещё впихнуть base64 декодер в код, неясно, было ли бы лучше. И/или добавить сжатие одинаковых подряд идущих символов с теми же издержками.
Плюс ещё аргументы принтфов раздувают код а их нужно использовать по той причине, что ты не можешь ни в каком виде в строковые литералы с кодом программы включить символы из набора: " % \. Эскейпить не выйдет, потому что тогда придётся эскейпить символы, КОТОРЫМИ ты эскейпишь, и в итоге тебе нужно бесконечно эскейпов. По этой же причине нельзя использовать \n. Поэтому нужно либо использовать %c + аски код символа в аргументах, либо нормальный вариант - это писать свой принтф, который будет автоматом эскейпить всё сам при выводе (это то, как сделал этот чел с первого видео, как я понял). Ну и всё нужно было делать более широким, чтобы уменьшить высоту.
В-третьих, я пытался код сделать выровненным, но вот в середине кусок строкового литерала обрывается в начале строки. Я бы мог забить оставшееся место просто ;;;;;;;;;; но проблема в том, что тогда эти точки с запятой нужно также добавить внутрь строкового литерала с кодом программы, то есть на самом деле нужно добавить количество символов равное половине оставшегося места, НО оно не делится на 2 и всё равно не будет выровнено. То есть придётся внизу менять код, чтобы добавить один символ где-то, но тогда сам код внизу съедет. И я не понимаю, как это всё выровнять, видимо, наоборот, пытаться сжать код, но как будто те же проблемы вылезут.
Кроме того, куча кринжа связанного с тем, чтобы выровнять код: опять же, бесполезные точки с запятой и кудрявые скобки, неоправданно длинные идентификаторы, шестнадцатеричные и восьмеричные интовые литералы, интовые литералы, переписанные как сумма маленького и большого, забивание комментов и строк бесполезными символами (надпись "time's up" в конце даже не успевает вывестись на экран, она моментально затирается, она там чисто для выравнивания). Единственное правило, которое пытался соблюдать - отсутствие лишних пробелов, но мог что-то пропустить случайно. Можно было бы эксплоитить всякую си шизу с тем, что, например, у переменных по дефолту тип инт и тп, но я в ней не особо разбираюсь и я не хочу. Плюс инклюд можно было бы добавить как аргумент компилятора, но тогда придётся добавлять в коммент инструкции по компиляции, а я хотел, чтобы оно компилилось просто как "cc quimer.c", по этой же причине использую какую-то непонятную c11 timespec_get ерунду: потому что она доступна на всех компиляторах и платформах вроде.
В-четвёртых, САМОЕ ГЛАВНОЕ ЭТО БЛЯТЬ ДАЖЕ НЕ КВАЙН, Я ДАУН И НЕ ОСИЛИЛ, я слишком поздно понял, что то, как я отформатировал литералы с кодом прораммы - это никак не отразится на том, что напечатается на экране. По этой причине на видео видно, что литералы печатаются просто в одну строку. У чела в видео - настоящий квайн, то есть его прога сама себя печатает (он чёто не показал дифф), у меня печатает только в лучшем случае наполовину такую же программу.
Как исправить, оставив выравнивание - я не знаю. С принтф это точно невозможно, потому что ты обязан переносить литерал именно только там, где есть перенос в коде, и вставлять туда %c для новой строки. И код в строковом литерале будет длиннее самого кода, то есть по крайней мере они не могут быть выровнены на одну ширину. У чела в видео с кастомным принтфом тоже так, если посмотреть: каждый кусок литерала заканчивается на \n и он вручную при выводе после переносов строк добавляет двойные кавычки (код в конце p('\\');p('n');p('"');p('\n');p('"')).
Решается это, скорее всего, тем, что опять же, делать кастомный принтф, который по ходу вывода в консоль считает символы в строке и в нужные моменты сам делает перенос, без необходимости добавлять в сам литерал индикаторы того, где нужно делать переносы. Плюс иметь удачу или большой мозг, чтобы в итоге всё красиво вручную выровнять, либо ещё более большой мозг, чтобы написать прогу, которая выравнивает всё сама, применяя всякие ухищрения. И эта прога - это всё ещё, к сожалению, не чат джипити инб4 ты неправильно объясняешь, что нужно сделать, к тому же слепить всё в одну строку, убрав пробелы даже там, где нельзя - это тоже валидный вариант выровнять код, ты ведь не указал максимальную длину строки А я же реально жду, когда смогу попросить его сгенерировать аски арт и получить в ответ что-то отличное от рандомного набора символов, ну и в целом, момента, когда оно будет способно на что-то реально интересное само по себе, и искренне надеюсь, что это когда-нибудь случится, но пока что это просто сплошное разочарование какое-то.
Ну и ещё одна причина, по которой это даже в теории не может быть квайном - это то, что это более-менее честный таймер и "запускается" он как можно быстрее после запуска программы, после чего перед выводом цифр тратится немного времени по крайней мере на то, чтобы распарсить шрифт из массива интов, из-за чего на момент вывода цифр в консоль там уже останется меньше времени, чем написано в коде программы.
Единственный более-менее прикольный момент этой проги - это то, что вот эти большие цифры посередине - это именно то, что определяет, на сколько минут/секунд запустится таймер, и типо видно на видео, что пока таймер крутится, то кроме самих цифр в коде ничего больше не меняется, ну и я вручную именно цифры поменял и тем самым задал время. (Если честно, я настолько блять тупой, что только когда начал это всё делать, понял, что я же могу просто в коде переменным присвоить количество минут, секунд и миллисекунд, и вся эта идея имеет ОЧЕНЬ МАЛО СМЫСЛА.) Чтобы это реализовать, я считаю что-то типо хэша: взвешенную сумму всех символов, составляющих глиф. Веса зависят от типов символов (ну, пробел, вертикальная черта, нижнее подчёркивание, иначе сумма всех символов одинакова у всех глифов, потому что шрифт моноширинный) + от игрек координаты (потому что иначе у 6 и 9 и у 5 и 2 получаются всегда попарно одинаковые хэши). Ну и дальше просто типо очень упрощённая хэш таблица без коллизий, но кринжовая, потому что на 12 элементов требуется целых 35 ячеек. И все неактивные ячейки забиты нулями и это то, благодаря чему оно не особо сходит с ума от мусорных символов, но, наверное, всё ещё может сделать что-то странное, если хэш попадёт в ячейку с точкой или точкой с запятой. Ну и ещё неприятно то, что вероятно даже мелкие изменения в символах, визуально ничего не меняющие, возможно, будут кардинально менять то, как они интерпретируются.
Короче, это моя вторая попытка сделать квайн, в первый раз получился вообще полный мусор, но то был хотя бы действительно квайн (я там просто код программы внутри строки закодировал в base64, типа чтобы было не совсем очевидно, что это квайн, и тоже просто принтф использовал). А тут я не осилил даже квайн сделать в итоге.







>>747408
>делать кастомный принтф, который по ходу вывода в консоль считает символы в строке и в нужные моменты сам делает перенос, без необходимости добавлять в сам литерал индикаторы того, где нужно делать переносы
Получился пикрил 2 он просто печатает сам себя если что https://godbolt.org/z/odWGK7K13 и даже, после некоторых мучений в попытках скукожить код "23 умножить на 3" вместо 69 - это попытка скукожить, а не раздуть, потому что это сокращает таблицу символов, случайно получился ровный прямоугольник.
Индексы, идущие в таблицу символов (переменная t), записал в строку (переменная s) через печатаемые аски символы, получается, тут есть оверхед в записи кода программы из-за того, что индексы 6-битные, но каждый записан символом, который кодирует 8 бит, и я не знаю, как можно эффективно в код впихнуть последовательность 6-битных чисел. То есть я тупой еблан и буквально ничего не выигрываю этим и только раздуваю код необходимостью хранить таблицу.




Эта шиза снова прогрессирует, добавил в типо контекст в дополнение к основному аллокатору дополнительный для всякого временного мусора, который бы не замусоривал основной и который можно было бы периодически чистить полностью. И проблема в том, что это именно должен быть отдельный второй аллокатор, потому что иногда функция может одновременно захотеть и выделить что-то с долгим лайфтаймом, и выделить что-то для использования чисто внутри неё самой (например, utf-16 строку, чтобы передать в виндовое апи). Из-за чего приходится раздваивать некоторые функции на обычную версию, которая создаёт что-то, используя основной аллокатор, и "временную", которая использует временный аллокатор и не мусорит в основной. Переделал динамические массивы на отдельные функции вместо макросов, которые инлайнят реализации функций на месте. Не знаю, зачем, потому что теперь невозможно использовать sizeof, чтобы узнать размер элемента, и нельзя пушить литералы, потому что тут, оказывается, нельзя брать указатели на rvalue, которые являются литералами? В итоге бред какой-то получается и сам массив какой-то жирный теперь. В итоге не уверен, что мне это всё нравится, но, неважно, я слишком тупой в любом случае ничего неважно
Я думал ещё про то, хочу ли я какие-нибудь шизоидные проверки на переполнение интов, когда выделяю память, но первая проблема в том, что это скользкая дорожка к тому, чтобы делать бесполезные проверки вообще любой степени шизовости вообще везде, а вторая - а какой вообще реалистичный сценарий того, что кто-то захочет выделить что-то вроде, например, 20000 элементов каждый из которых размером 1000 терабайтов? Или даже что-то отдалённо близкое к этому, где не было бы переполнения при перемножении. Если это происходит при чтении какого-то пользовательского ввода, например, читаешь в память битмаповый шрифт из файла и типо, допустим, там прописано, что размер какого-то глифа = миллиард миллиардов пикселей, то все эти проверки, наверное, должны быть именно там, где ты парсишь этот файл, и там у этих проверок к тому же есть шанс быть более разумными. Например, сделать лимит на размер одного глифа условно 100x100 пикселей. Если это какой-то алгоритм, которому нужна дополнительная память, то он вряд ли сразу захочет так много памяти выделить, скорее постепенно будет съедать больше и больше, и более вероятно отвалится на моменте, когда попытается выделить даже пару десятков гигабайт, гораздо раньше, чем там что-то переполнится. Короче, наверное, в этом нет смысла.
>>747408
Кстати, вроде можно было бы немного сократить строку, если заменить в ней длинные числа из массива с шрифтом (переменная ef) на %llu и в принтф аргументы передать через ef[0], ef[1] и тд, хотя, скорее всего, в итоге в лучшем случае никакой разницы не будет из-за того, что эти ef[0], ef[1] придётся в строку тоже добавить. Вообще, наверное, лучше в строку кодировать шрифт
Эта шиза снова прогрессирует, добавил в типо контекст в дополнение к основному аллокатору дополнительный для всякого временного мусора, который бы не замусоривал основной и который можно было бы периодически чистить полностью. И проблема в том, что это именно должен быть отдельный второй аллокатор, потому что иногда функция может одновременно захотеть и выделить что-то с долгим лайфтаймом, и выделить что-то для использования чисто внутри неё самой (например, utf-16 строку, чтобы передать в виндовое апи). Из-за чего приходится раздваивать некоторые функции на обычную версию, которая создаёт что-то, используя основной аллокатор, и "временную", которая использует временный аллокатор и не мусорит в основной. Переделал динамические массивы на отдельные функции вместо макросов, которые инлайнят реализации функций на месте. Не знаю, зачем, потому что теперь невозможно использовать sizeof, чтобы узнать размер элемента, и нельзя пушить литералы, потому что тут, оказывается, нельзя брать указатели на rvalue, которые являются литералами? В итоге бред какой-то получается и сам массив какой-то жирный теперь. В итоге не уверен, что мне это всё нравится, но, неважно, я слишком тупой в любом случае ничего неважно
Я думал ещё про то, хочу ли я какие-нибудь шизоидные проверки на переполнение интов, когда выделяю память, но первая проблема в том, что это скользкая дорожка к тому, чтобы делать бесполезные проверки вообще любой степени шизовости вообще везде, а вторая - а какой вообще реалистичный сценарий того, что кто-то захочет выделить что-то вроде, например, 20000 элементов каждый из которых размером 1000 терабайтов? Или даже что-то отдалённо близкое к этому, где не было бы переполнения при перемножении. Если это происходит при чтении какого-то пользовательского ввода, например, читаешь в память битмаповый шрифт из файла и типо, допустим, там прописано, что размер какого-то глифа = миллиард миллиардов пикселей, то все эти проверки, наверное, должны быть именно там, где ты парсишь этот файл, и там у этих проверок к тому же есть шанс быть более разумными. Например, сделать лимит на размер одного глифа условно 100x100 пикселей. Если это какой-то алгоритм, которому нужна дополнительная память, то он вряд ли сразу захочет так много памяти выделить, скорее постепенно будет съедать больше и больше, и более вероятно отвалится на моменте, когда попытается выделить даже пару десятков гигабайт, гораздо раньше, чем там что-то переполнится. Короче, наверное, в этом нет смысла.
>>747408
Кстати, вроде можно было бы немного сократить строку, если заменить в ней длинные числа из массива с шрифтом (переменная ef) на %llu и в принтф аргументы передать через ef[0], ef[1] и тд, хотя, скорее всего, в итоге в лучшем случае никакой разницы не будет из-за того, что эти ef[0], ef[1] придётся в строку тоже добавить. Вообще, наверное, лучше в строку кодировать шрифт








https://www.songho.ca/opengl/gl_projectionmatrix.html такое нашёл, но в итоге, наверное, можно было бы здравым смыслом вывести её без учёта того, что фрустум может быть зачем-то несимметричным. Кроме момента с тем, что почему Z нелинейная? Я понимаю, что если пытаешься впихнуть перспективное преобразование в матрицу, то оно по-другому быть не может, но вообще в целом, зачем? http://www.humus.name/index.php?ID=255 на эту тему нашёл только это, он говорит, что типо Z, оказывается, линеен на экране, я типо верю, но интуитивно не понимаю совсем, попытался найти производную dZ/dX для чего-то типо похожего на перспективное преобразование (X/Z, Y/Z, 1/Z), как будто действительно выходит константа, но не знаю, я мог написать бред. Пытался проверить, что оно прямые в прямые переводит, ну как будто да, вот очередная вещь, которая наверняка очевидна людям с высоким iq, а я реально не вижу, из чего следует сохранение прямых. Идея того, чтобы использовать повороты на 360 градусов вместо радиан, в том числе внутри тригонометрических функций, показалось забавной? 0.25 вместо π/2, например, выглядит красивее или нет, не знаю
https://www.songho.ca/opengl/gl_projectionmatrix.html такое нашёл, но в итоге, наверное, можно было бы здравым смыслом вывести её без учёта того, что фрустум может быть зачем-то несимметричным. Кроме момента с тем, что почему Z нелинейная? Я понимаю, что если пытаешься впихнуть перспективное преобразование в матрицу, то оно по-другому быть не может, но вообще в целом, зачем? http://www.humus.name/index.php?ID=255 на эту тему нашёл только это, он говорит, что типо Z, оказывается, линеен на экране, я типо верю, но интуитивно не понимаю совсем, попытался найти производную dZ/dX для чего-то типо похожего на перспективное преобразование (X/Z, Y/Z, 1/Z), как будто действительно выходит константа, но не знаю, я мог написать бред. Пытался проверить, что оно прямые в прямые переводит, ну как будто да, вот очередная вещь, которая наверняка очевидна людям с высоким iq, а я реально не вижу, из чего следует сохранение прямых. Идея того, чтобы использовать повороты на 360 градусов вместо радиан, в том числе внутри тригонометрических функций, показалось забавной? 0.25 вместо π/2, например, выглядит красивее или нет, не знаю


Не хочется в это играть, там с самого начала первая локация - какой-то очередной гигантский пустырь и непонятно куда идти, мне гораздо больше нравился коридорный левел дизайн дарк солсов, где чётко понятно, куда идти, а бегать по пустырям и выискивать данжи, мини боссов и нпс мне приносит только уныние. И первый встретившийся мини босс - дракон скелет с душными атаками, которые нельзя задоджить, пока ты сидишь на коне, но если слезешь с коня, то он может поймать тебя своей аое, от которой не убежишь на ногах. Вместо того, чтобы сделать хотя бы один нормальный файт с драконом в этой игре, они похоже решили наоборот сделать самый худший из всех. В итоге забил в тот же день, что длц вышло.
Да и в основную игру не хочется играть, короче, я никогда не пройду эту игру. Играть на сейве, где у меня базовый RL5 бандит, стало слишком депрессивно: боссы начали слишком часто ваншотать, нужно прямо очень осторожно играть и бить только в безопасные окна, а это не очень весело. Играть в основную игру на сейве, где я по-быстрому добирался до длц, тоже не хочется, я там уже слишком оверлвл для основной игры, ну, можно перераспределить статы во что-то бесполезное, но уже нету настроения.
Короче, в итоге я забил на игру и, раз уж у меня есть стим версия игры, решил побегать немного в пвп на RL1+0 и это было довольно забавно: вторгаться в начальных локациях и мешать людям играть в коопе, в худшем случае людям, которые полчаса назад игру в первый раз запустили и даже играть толком не умеют, короче, как раз уровень моего скилла. Веселее всего офк убивать людей, прикрываясь за спинами толпы мобов или за наземным боссом. Но особо нет ощущения, что ты серьёзно руинишь кому-то игру, они по сути теряют только немного времени и аналог человечности, как в дс1, но тут он имеет нулевую ценность, потому что растёт на земле. Самый максимум неудобств, что можно принести, это вторгнуться около полудохлого дракона с гигантским хп баром, к которому некоторые люди приходят в начале игры, чтобы получить много рун забесплатно, и по-быстрому убить хоста, обнулив его прогресс по убийству дракона. Или когда вторгаешься посреди того, как кто-то кому-то передаёт предметы, и крадёшь их с пола, но это редко случается и мне ни разу не везло подобрать что-то интересное: только консервы и какие-то мусорные талисманы.
Проблема в том, что, оказывается, чуть ли не половина людей, играющих в коопе, играют вместе с высокоуровневыми фантомами, призванными по паролю. По всей видимости, это челы, которые уже прошли игру, играют с друзьями, которые только начали играть, не знаю. И, хоть вроде как их дамаг по мне скейлится вниз, я слишком анскилл, чтобы доджить их спам какими-то непонятными вепон артами и заклинаниями, которые в первый раз вижу, и продираться через их пойз и гигантскую полоску здоровья. Иногда получается их убить или быстро прикончить хоста, но зачастую нет.
Не знаю, могу ли я сам получить доступ хотя бы к каким-нибудь опшным оружиям или вепон артам, чтобы ещё более эффективно убивать людей, запустивших игру в первый раз. По-честному это придётся играть пве на RL1+0, а это раз в 10 сложнее обычного RL1. Ну, в начале убить годрика, чтобы получить реюзабельный палец для вторжений, было не очень сложно, а вот даже файт с раданом уже занял три с половиной минуты душения меня, и дальше только хуже. Чем дольше файт, тем более вероятно, что ты ошибёшься и тебя ваншотнут, либо ошибёшься достаточно раз, что у тебя закончатся фляги с хп.
А кооп в игре прямо дико унылый, даже вдвоём боссы по кд выбиваются из равновесия и в целом просто уничтожаются. В коопе весело, наверное, только стоять где-нибудь, ждать вторжений и втроём ганкать красных фантомов, особенно, если призвать кого-нибудь высоколвльного по паролю. А в пве играть с какими-то рандомами - не знаю.
Не хочется в это играть, там с самого начала первая локация - какой-то очередной гигантский пустырь и непонятно куда идти, мне гораздо больше нравился коридорный левел дизайн дарк солсов, где чётко понятно, куда идти, а бегать по пустырям и выискивать данжи, мини боссов и нпс мне приносит только уныние. И первый встретившийся мини босс - дракон скелет с душными атаками, которые нельзя задоджить, пока ты сидишь на коне, но если слезешь с коня, то он может поймать тебя своей аое, от которой не убежишь на ногах. Вместо того, чтобы сделать хотя бы один нормальный файт с драконом в этой игре, они похоже решили наоборот сделать самый худший из всех. В итоге забил в тот же день, что длц вышло.
Да и в основную игру не хочется играть, короче, я никогда не пройду эту игру. Играть на сейве, где у меня базовый RL5 бандит, стало слишком депрессивно: боссы начали слишком часто ваншотать, нужно прямо очень осторожно играть и бить только в безопасные окна, а это не очень весело. Играть в основную игру на сейве, где я по-быстрому добирался до длц, тоже не хочется, я там уже слишком оверлвл для основной игры, ну, можно перераспределить статы во что-то бесполезное, но уже нету настроения.
Короче, в итоге я забил на игру и, раз уж у меня есть стим версия игры, решил побегать немного в пвп на RL1+0 и это было довольно забавно: вторгаться в начальных локациях и мешать людям играть в коопе, в худшем случае людям, которые полчаса назад игру в первый раз запустили и даже играть толком не умеют, короче, как раз уровень моего скилла. Веселее всего офк убивать людей, прикрываясь за спинами толпы мобов или за наземным боссом. Но особо нет ощущения, что ты серьёзно руинишь кому-то игру, они по сути теряют только немного времени и аналог человечности, как в дс1, но тут он имеет нулевую ценность, потому что растёт на земле. Самый максимум неудобств, что можно принести, это вторгнуться около полудохлого дракона с гигантским хп баром, к которому некоторые люди приходят в начале игры, чтобы получить много рун забесплатно, и по-быстрому убить хоста, обнулив его прогресс по убийству дракона. Или когда вторгаешься посреди того, как кто-то кому-то передаёт предметы, и крадёшь их с пола, но это редко случается и мне ни разу не везло подобрать что-то интересное: только консервы и какие-то мусорные талисманы.
Проблема в том, что, оказывается, чуть ли не половина людей, играющих в коопе, играют вместе с высокоуровневыми фантомами, призванными по паролю. По всей видимости, это челы, которые уже прошли игру, играют с друзьями, которые только начали играть, не знаю. И, хоть вроде как их дамаг по мне скейлится вниз, я слишком анскилл, чтобы доджить их спам какими-то непонятными вепон артами и заклинаниями, которые в первый раз вижу, и продираться через их пойз и гигантскую полоску здоровья. Иногда получается их убить или быстро прикончить хоста, но зачастую нет.
Не знаю, могу ли я сам получить доступ хотя бы к каким-нибудь опшным оружиям или вепон артам, чтобы ещё более эффективно убивать людей, запустивших игру в первый раз. По-честному это придётся играть пве на RL1+0, а это раз в 10 сложнее обычного RL1. Ну, в начале убить годрика, чтобы получить реюзабельный палец для вторжений, было не очень сложно, а вот даже файт с раданом уже занял три с половиной минуты душения меня, и дальше только хуже. Чем дольше файт, тем более вероятно, что ты ошибёшься и тебя ваншотнут, либо ошибёшься достаточно раз, что у тебя закончатся фляги с хп.
А кооп в игре прямо дико унылый, даже вдвоём боссы по кд выбиваются из равновесия и в целом просто уничтожаются. В коопе весело, наверное, только стоять где-нибудь, ждать вторжений и втроём ганкать красных фантомов, особенно, если призвать кого-нибудь высоколвльного по паролю. А в пве играть с какими-то рандомами - не знаю.


В общем, если вторгаться где-нибудь подальше от начальных локаций, где конкретно сейчас много людей, которые в первый раз запустили игру из-за хайпа по длц, то меня самого зачастую начинают довольно эффективно давить как таракана, которым я и являюсь. И я перепробовал много разного оружия: когда меня убивали чем-то, то пробовал его сам использовать, и ничего не менялось, когда встречались люди, немного умеющие играть. А всякое дно вроде меня можно чем угодно забить.
 171 Кб, 279x388
171 Кб, 279x388

Плюс прикольно можно менять на ходу оружие в зависимости от ситуации, типо сменить по-быстрому на оружие, где повешен пробивающий щит выпад, или на оружие с более быстрым мувсетом, ну и в целом прикольно так делать, даже если практической пользы немного. Но в идеале это нужно запоминать расположение всего, чтобы не глядя менять.
А играть на мета пвп лвле на арене не очень хочется даже пробовать, там всё как-то совсем всё выглядит сложно со стороны, там файты выглядят так, что два чела сначала минуту бегают друг перед другом, а потом один резко стрейфит атаку другого и убивает бэкстабом
Пробовал на RL1+0 продолжить убивать боссов, конкретно тощего попробовал https://youtu.be/yNnJOCg9WwI но для такого, мне кажется, я уже не только анскилл, но ещё и мозг слишком дерьмовый, типо, например, я физически не могу отпарировать его атаку острым концом слева и когда пытаюсь, каждый раз опаздываю из-за того, что мозг не успевает распознать конкретно эту атаку и решить вместо переката прожать парирование. Из-за плохого мозга хочется умереть, это не только плохая реакция, но и плохая память, плохо и медленно соображаешь, иногда когда в чём-то разбираешься, то чувствуешь, что мозг плавится и всё


В новом сейве я просто почти мимо всех данжей пробегаю мимо в отличие от RL5 сейва, где я всё подряд проходил, все итемы скупал и пылесосил лут в локациях, тут только квесты делаю и всё.
Я более-менее далеко прошёл, дальше, чем в первом сейве, но не до конца
Его, на самом деле, парировать тяжелее, чем по-нормальному убивать, хотя выглядит наоборот. Но просто забавно так


В итоге просто кринж файт получился, где я постояно стою как можно дальше от неё и постоянно отбегаю, чтобы успеть потенциально убежать от этой атаки. И парирую ровно один вид атаки, другие не научился, слишком плохой мозг, слишком анскилл
Для этой атаки её клонами я тоже слишком анскилл, каждый раз я просто стою и не понимаю, что происходит. Вроде как можно отбежать подальше и задоджить только последнего клона, который атакует выпадом в тебя слева, и потом её саму, но не знаю, насколько это стабильно работает, я только один раз так сделал в успешном трае
Она ещё бьёт как-то совсем очень больно, хотя у меня 60 уровней в хп и это вроде кап, ну, с другой стороны, я просто в одном платье бегаю без нормальной брони, но, с третьей стороны, сомневаюсь, что это сыграло бы особую роль.





Я сначала смотрел это видео 3b1b https://youtu.be/d4EgbgTm0Bg и это https://eater.net/quaternions но, по-моему, это просто бред какой-то: ну я вижу, что да, стереографическая проекция кусков 4д сферы в трёхмерное пространство, да, умножение на кватернион растягивает и крутит проекцию, да, если умножить слева на единичный кватернион и справа на сопряжённый, то растягивания типа компенсируют друг друга и проекция крутится, ну и чё дальше, это что-то на уровне того мультика про выворачивание сферы наизнанку, вот тоже сидишь смотришь и киваешь пустой башкой.
По-моему, в плане геометрических преобразований комплексные числа и кватернионы слишком разные, несмотря на то, что одно является расширением другого. Умножение на комплексное число делает произвольный поворот + скейлинг 2д векторов, а умножение на кватернион вроде бы не может сделать даже произвольный поворот 4д вектора: слишком мало компонентов, нужно хотя бы 6. Короче, я не вижу пользы в том, чтобы проводить параллели между ними.
Я не особо понимаю, сколько нужно чисел для представления произвольного поворота в N-мерном пространстве. Вроде бы один вариант, как об этом можно думать, это, что мы хотим выбрать все различные пары осей координат, которые будут представлять плоскости поворота, и это количество равно числу сочетаний из N по 2, то есть N! / ((N-2)! 2!) = N (N - 1) / 2. В 3д обычно говорят об осях вращения, но просто можно взять нормали к плоскостям в качестве осей. В 2д вообще плоскость только одна, поэтому и поворот представляется только одним числом.
Другой вариант - это представить, что у нас есть куб с рёбрами, выровненными по осям координат, и мы хотим его повернуть в какую-то ориентацию. Сначала хватаемся за ребро, смотрящее в направлении оси X, и у нас есть N - 1 степеней свободы (по количеству оставшихся осей координат), чтобы ориентировать его, как нам надо. После хватаемся за ось Y, тоже ставим её в нужное положение, но только у нас осталось уже N - 2 степеней свободы, так как X мы зафиксировали. (N - 1) + (N - 2) + ... + 1 = N (N - 1) / 2.
Ещё из попыток объяснить кватернионы такое есть https://marctenbosch.com/quaternions что-то что-то бивекторы, внешнее произведение, роторы, ничего не понял особо в итоге и сложилось впечатление, что магические формулы кватернионов просто подменили на другие магические формулы.
Короче, в итоге, если ты тупой, то похоже нет смысла пытаться понять, что было в голове у того чела, который придумал кватернионы, почему 4д кватернионы используются для 3д поворотов и какой глубинный смысл формулы p' = qpq∗. И просто последовательно всё вывести из формулы i2 = j2 = k2 = ijk = -1, которую, допустим, я увидел, проходя мимо моста.
https://www.youtube.com/playlist?list=PLpzmRsG7u_gr0FO12cBWj-15_e0yqQQ1U вот эти видео нормальные, ну вот только представление операции умножения на кватернион в виде матрицы оказалось каким-то бесполезным. Я думал его можно было бы использовать для вывода матричной формы p' = qpq∗, но не вижу, как. Ну просто интересно получается, что матрицы эти, выходит изоморфны кватернионам? И тут реально наделяется смысл тому, что значит, например, возвести i в квадрат и получить -1.
Представление кватерниона в виде скаляра + вектора очень удобное и вроде как раз исторически именно отсюда пошли векторное и скалярное произведения векторов: они вылезают в формуле умножения кватернионов. Отсюда становится понятно, почему они выглядят такими искусственными и взявшимися из ниоткуда (ну у них есть геометрический смысл, но, по-моему, не самый очевидный, чтобы взять просто на ровном месте придумать эти операции для векторов).
Формулу поворота он сначала выводит через векторное и скалярное произведения, а потом показывает, как переписать её через кватернионы, используя типа аналог формулы эйлера для кватернионов, выходит так: v' = eθn/2 v e-θn/2. Почему половинный угол? Я не знаю, да и какая разница, ну просто получилось так. И я видел все эти картинки с книжками, к которым прицеплена ленточка, и там она перекручивается, если перевернуть книжку на 360 градусов, но если перевернуть на 720, то её можно размотать без переворачивания книжки и бла-бла-бла, это не имеет никакого смысла в моих глазах.
По-моему, это просто означает, что ну ок, получается, при повороте через кватернионы, можно выбрать то, по какой дуге делать поворот: по короткой или по длинной. Ну, типо, например, поворот от 120 градусов либо к 240 градусам, либо к -120 градусам. Финальная ориентация одна и та же, но поворот сделан либо против, либо по часовой стрелке.
Матричную запись поворота через кватернионы можно вывести так http://www.songho.ca/opengl/gl_quaternion.html но это какое-то безумие, нашёл вариант попроще https://en.wikipedia.org/wiki/Quaternions_and_spatial_rotation#Quaternion-derived_rotation_matrix немного подробнее расписал.
Я так понял, что между кватернионами можно просто брать и делать линейную интерполяцию и в отличие от матриц, с которыми если так сделать, то объект будет искажаться и вроде может быть shearing? Я не уверен, есть ли искажения в случае с кватернионами, сам не пробовал ещё, а, ну, наверное, их нужно будет нормализовывать после лерпа, потому что он величину вектора не сохраняет. Но, если просто лерпать, то в любом случае оно крутиться будет как минимум с неравномерной скоростью, для постоянной скорости нужен слерп. Вывод формулы слерпа отсюда http://allenchou.net/2018/05/game-math-deriving-the-slerp-formula
Но, в итоге, если честно, я не особо понимаю, почему слерп кватернионов как 4д векторов результирует именно в плавный поворот вроде как по кратчайшей дуге в 3д, что означает угол между кватернионами как 4д векторами в этом контексте... Это, наверное, можно проверить, если взять два произвольных кватерниона p и q, подставить их в формулу слерпа, чтобы получить промежуточный кватернион slerp(p, q, t). Потом взять произвольный вектор v и проверить, что промежуточно повёрнутый "slerp(p, q, t) v slerp(p, q, t)∗" лежит в плоскости, которую образуют qvq∗ и pvp∗, и что он повёрнут на правильный угол относительно них? Я это всё сойду с ума считать, у меня нет сейчас сил на такое. В общем, я просто не вижу интуицию, почему это работает, я слишком тупой, я реально отсталый.
Про дуальные кватернионы (именно дуальные, октонионы - это что-то другое, хотя и у тех, и у других по 8 компонентов) немного посмотрел, в основном отсюда https://cs.gmu.edu/~jmlien/teaching/cs451/uploads/Main/dual-quaternion.pdf но там много опечаток и мало информации. Это видео https://youtu.be/ichOiuBoBoQ выглядело многообещающим, но там пошла какая-то проективная геометрия? и я ничего не понял.
Ну, короче, если кратко, то идея такая, что в два кватерниона определённым образом записываются поворот + смещение, а сами два кватерниона объединяются в один "дуальный". И определяются операции над этими дуальными кватернионами, которые основаны на дуальных числах (что-то вроде комплексных), где компонентами выбрали кватернионы. И так выходит, что если вписать обычный 3д вектор в дуальный кватернион (единица в вещественной части и сам вектор в дуальной https://en.wikipedia.org/wiki/Dual_quaternion#Dual_quaternions_and_4%C3%974_homogeneous_transforms), и домножить его слева на дуальный кватернион, а справа на его сопряжённое (как в смысле дуальных чисел, так и в смысле кватернионов), то типо получается сначала повёрнутый, а потом смещённый вектор. И вроде как смысл в том, что эти дуальные кватернионы тоже можно интерполировать, как обычные кватернионы. Вроде ещё для чего-то используются в анимации этот чел рассказывал https://youtu.be/en2QcehKJd8 про какой-то candy-wrapper эффект, но я его презентацию аболютно не понял от начала и до конца.
Гораздо больше магических формул, взявшихся из ниоткуда, я максимум просто проверил, что формула действительно делает с вектором поворот + смещение. Я не стал пытаться самостоятельно пройти аналогичный путь, как с обычными кватернионами: от формулы, записанной в форме векторов, к формуле через дуальные кватернионы p' = qpq∗, я не вывезу и запутаюсь.
В конце немного про отражения, выраженные через кватернионы. Я не задумывался о том, что два последовательных отражения - это поворот (или задумывался, я забыл), но с формулами отражения/поворота через кватернионы это легко выводится. Это всё немного перекликается с той статьёй про роторы, только там вроде наоборот: сначала шли отражения, а потом повороты через них выражались. Ну и формулы выглядят там визуально похоже.
Я сначала смотрел это видео 3b1b https://youtu.be/d4EgbgTm0Bg и это https://eater.net/quaternions но, по-моему, это просто бред какой-то: ну я вижу, что да, стереографическая проекция кусков 4д сферы в трёхмерное пространство, да, умножение на кватернион растягивает и крутит проекцию, да, если умножить слева на единичный кватернион и справа на сопряжённый, то растягивания типа компенсируют друг друга и проекция крутится, ну и чё дальше, это что-то на уровне того мультика про выворачивание сферы наизнанку, вот тоже сидишь смотришь и киваешь пустой башкой.
По-моему, в плане геометрических преобразований комплексные числа и кватернионы слишком разные, несмотря на то, что одно является расширением другого. Умножение на комплексное число делает произвольный поворот + скейлинг 2д векторов, а умножение на кватернион вроде бы не может сделать даже произвольный поворот 4д вектора: слишком мало компонентов, нужно хотя бы 6. Короче, я не вижу пользы в том, чтобы проводить параллели между ними.
Я не особо понимаю, сколько нужно чисел для представления произвольного поворота в N-мерном пространстве. Вроде бы один вариант, как об этом можно думать, это, что мы хотим выбрать все различные пары осей координат, которые будут представлять плоскости поворота, и это количество равно числу сочетаний из N по 2, то есть N! / ((N-2)! 2!) = N (N - 1) / 2. В 3д обычно говорят об осях вращения, но просто можно взять нормали к плоскостям в качестве осей. В 2д вообще плоскость только одна, поэтому и поворот представляется только одним числом.
Другой вариант - это представить, что у нас есть куб с рёбрами, выровненными по осям координат, и мы хотим его повернуть в какую-то ориентацию. Сначала хватаемся за ребро, смотрящее в направлении оси X, и у нас есть N - 1 степеней свободы (по количеству оставшихся осей координат), чтобы ориентировать его, как нам надо. После хватаемся за ось Y, тоже ставим её в нужное положение, но только у нас осталось уже N - 2 степеней свободы, так как X мы зафиксировали. (N - 1) + (N - 2) + ... + 1 = N (N - 1) / 2.
Ещё из попыток объяснить кватернионы такое есть https://marctenbosch.com/quaternions что-то что-то бивекторы, внешнее произведение, роторы, ничего не понял особо в итоге и сложилось впечатление, что магические формулы кватернионов просто подменили на другие магические формулы.
Короче, в итоге, если ты тупой, то похоже нет смысла пытаться понять, что было в голове у того чела, который придумал кватернионы, почему 4д кватернионы используются для 3д поворотов и какой глубинный смысл формулы p' = qpq∗. И просто последовательно всё вывести из формулы i2 = j2 = k2 = ijk = -1, которую, допустим, я увидел, проходя мимо моста.
https://www.youtube.com/playlist?list=PLpzmRsG7u_gr0FO12cBWj-15_e0yqQQ1U вот эти видео нормальные, ну вот только представление операции умножения на кватернион в виде матрицы оказалось каким-то бесполезным. Я думал его можно было бы использовать для вывода матричной формы p' = qpq∗, но не вижу, как. Ну просто интересно получается, что матрицы эти, выходит изоморфны кватернионам? И тут реально наделяется смысл тому, что значит, например, возвести i в квадрат и получить -1.
Представление кватерниона в виде скаляра + вектора очень удобное и вроде как раз исторически именно отсюда пошли векторное и скалярное произведения векторов: они вылезают в формуле умножения кватернионов. Отсюда становится понятно, почему они выглядят такими искусственными и взявшимися из ниоткуда (ну у них есть геометрический смысл, но, по-моему, не самый очевидный, чтобы взять просто на ровном месте придумать эти операции для векторов).
Формулу поворота он сначала выводит через векторное и скалярное произведения, а потом показывает, как переписать её через кватернионы, используя типа аналог формулы эйлера для кватернионов, выходит так: v' = eθn/2 v e-θn/2. Почему половинный угол? Я не знаю, да и какая разница, ну просто получилось так. И я видел все эти картинки с книжками, к которым прицеплена ленточка, и там она перекручивается, если перевернуть книжку на 360 градусов, но если перевернуть на 720, то её можно размотать без переворачивания книжки и бла-бла-бла, это не имеет никакого смысла в моих глазах.
По-моему, это просто означает, что ну ок, получается, при повороте через кватернионы, можно выбрать то, по какой дуге делать поворот: по короткой или по длинной. Ну, типо, например, поворот от 120 градусов либо к 240 градусам, либо к -120 градусам. Финальная ориентация одна и та же, но поворот сделан либо против, либо по часовой стрелке.
Матричную запись поворота через кватернионы можно вывести так http://www.songho.ca/opengl/gl_quaternion.html но это какое-то безумие, нашёл вариант попроще https://en.wikipedia.org/wiki/Quaternions_and_spatial_rotation#Quaternion-derived_rotation_matrix немного подробнее расписал.
Я так понял, что между кватернионами можно просто брать и делать линейную интерполяцию и в отличие от матриц, с которыми если так сделать, то объект будет искажаться и вроде может быть shearing? Я не уверен, есть ли искажения в случае с кватернионами, сам не пробовал ещё, а, ну, наверное, их нужно будет нормализовывать после лерпа, потому что он величину вектора не сохраняет. Но, если просто лерпать, то в любом случае оно крутиться будет как минимум с неравномерной скоростью, для постоянной скорости нужен слерп. Вывод формулы слерпа отсюда http://allenchou.net/2018/05/game-math-deriving-the-slerp-formula
Но, в итоге, если честно, я не особо понимаю, почему слерп кватернионов как 4д векторов результирует именно в плавный поворот вроде как по кратчайшей дуге в 3д, что означает угол между кватернионами как 4д векторами в этом контексте... Это, наверное, можно проверить, если взять два произвольных кватерниона p и q, подставить их в формулу слерпа, чтобы получить промежуточный кватернион slerp(p, q, t). Потом взять произвольный вектор v и проверить, что промежуточно повёрнутый "slerp(p, q, t) v slerp(p, q, t)∗" лежит в плоскости, которую образуют qvq∗ и pvp∗, и что он повёрнут на правильный угол относительно них? Я это всё сойду с ума считать, у меня нет сейчас сил на такое. В общем, я просто не вижу интуицию, почему это работает, я слишком тупой, я реально отсталый.
Про дуальные кватернионы (именно дуальные, октонионы - это что-то другое, хотя и у тех, и у других по 8 компонентов) немного посмотрел, в основном отсюда https://cs.gmu.edu/~jmlien/teaching/cs451/uploads/Main/dual-quaternion.pdf но там много опечаток и мало информации. Это видео https://youtu.be/ichOiuBoBoQ выглядело многообещающим, но там пошла какая-то проективная геометрия? и я ничего не понял.
Ну, короче, если кратко, то идея такая, что в два кватерниона определённым образом записываются поворот + смещение, а сами два кватерниона объединяются в один "дуальный". И определяются операции над этими дуальными кватернионами, которые основаны на дуальных числах (что-то вроде комплексных), где компонентами выбрали кватернионы. И так выходит, что если вписать обычный 3д вектор в дуальный кватернион (единица в вещественной части и сам вектор в дуальной https://en.wikipedia.org/wiki/Dual_quaternion#Dual_quaternions_and_4%C3%974_homogeneous_transforms), и домножить его слева на дуальный кватернион, а справа на его сопряжённое (как в смысле дуальных чисел, так и в смысле кватернионов), то типо получается сначала повёрнутый, а потом смещённый вектор. И вроде как смысл в том, что эти дуальные кватернионы тоже можно интерполировать, как обычные кватернионы. Вроде ещё для чего-то используются в анимации этот чел рассказывал https://youtu.be/en2QcehKJd8 про какой-то candy-wrapper эффект, но я его презентацию аболютно не понял от начала и до конца.
Гораздо больше магических формул, взявшихся из ниоткуда, я максимум просто проверил, что формула действительно делает с вектором поворот + смещение. Я не стал пытаться самостоятельно пройти аналогичный путь, как с обычными кватернионами: от формулы, записанной в форме векторов, к формуле через дуальные кватернионы p' = qpq∗, я не вывезу и запутаюсь.
В конце немного про отражения, выраженные через кватернионы. Я не задумывался о том, что два последовательных отражения - это поворот (или задумывался, я забыл), но с формулами отражения/поворота через кватернионы это легко выводится. Это всё немного перекликается с той статьёй про роторы, только там вроде наоборот: сначала шли отражения, а потом повороты через них выражались. Ну и формулы выглядят там визуально похоже.
 725 Кб, 1448x2048
725 Кб, 1448x2048Основная идея в том, чтобы распаковать флоат в бинарное число с фиксированной точкой с гигантской точностью, чтобы в него уместился любой флоат без потери точности, а потом скопировать биты после первой старшей единицы в мантиссу + посчитать экспоненту так, чтобы она сдвигала точку в нужное место. Примерно то же самое, что описывал тот чел https://randomascii.wordpress.com/2012/03/08/float-precisionfrom-zero-to-100-digits-2 для обратной операции (перевод из флоата в строку с десятичной дробью), но нет заморочек с тем, чтобы вывести самое короткое представление в десятичном виде, потому что тут результат фиксированного размера.
Проблема в том, что десятичную дробь в бинарную не всегда можно записать конечным количеством цифр, поэтому придётся округлять. Я сделал вроде примерно, как в той >>735955 статье рассказывалось: что беру дополнительно два следующих бита (guard и round) после того, как заканчивается точность мантиссы, и ещё третий бит равный OR-у всех оставшихся битов (sticky). Ну и типо, если биты равны 0xx, то округляешь вниз, если 100, то к чётному, иначе вверх. Округление делается просто через +1 к почти готовому флоату, проинтерпретированному как u32.
Непонятно, сколько нужно вперёд битов брать, чтобы вычислить sticky бит. У меня на целую часть выделено 5 u32-ых (типо самый длинный флоат 2^127 + ещё сверху нужно хотя бы 2 бита на guard и round), и на дробную тоже 5 u32-ых (самый маленький положительный флоат 2^-149 + тоже биты для округления). Ну и как будто хватает.
Чтобы перевести десятичную целую часть в бинарную, можно просто взять это число, состоящее из 5 u32-ых, изначально равное нулю, и последовательно умножать его на 10 и прибавлять следующую и следующую цифру из входной строки слева от точки. Умножение столбиком (long multiplication) и о нём тут можно думать как об умножении числа из 5 цифр на число из одной цифры в 2^32-ричной системе счисления, то есть просто напрямую перемножаешь два u32, прибавляешь перенос, записываешь результат в u64, после чего одна половина идёт в результат произведения, а вторая - в перенос к умножению на следующий разряд. Со сложением в столбик примерно то же самое.
А дробную часть не знаю, как нормально переводить в бинарный вид. Я думал, можно обойтись так же, как с целой, и что-нибудь с экспонентой сделать, но проблема в том, что в изначальной форме число десятичное, а приводится к двоичному и непонятно, как сконвертировать умножение на 10^n в умножение на 2^n. Я в итоге сделал через последовательное умножение десятичной дробной части на 2, ну то есть буквально записываешь все цифры из входной строки после точки в массив, оставив в начале один ноль для целой части, и столбиком умножаешь их на 2. Умножил один раз, если в целой части вылезла единица, то значит в числе есть одна 1/2-ая, иначе ноль, единицу зануляешь, и потом умножаешь ещё раз на 2 - получил количество 1/4-ых в числе, ещё раз - количество 1/8-ых, и так далее, по ходу записываешь результат в бинарном виде.
И к этому ещё нужно было как-то прикрутить парсинг такой записи 1e-2, и тут та же проблема, короче, я просто как-то криво сделал, что при переводе целой/дробной части в бинарную я, в зависимости от десятичной экспоненты, например, читаю цифры из целой десятичной части в дробную бинарную, если экспонента отрицательная, либо читаю из дробной десятичной в целую бинарную, если положительная, либо забиваю нулями, короче, такой бред.
Для парсинга десятичной экспоненты нужен парсинг интов + понимать, умещается ли последовательность цифр в инт, и я почему-то написал какой-то бред, что для этого я просто сравниваю входную строку лексикографически с максимальным / минимальным интом, записанным в строку. Другой вариант был бы, наверное, попробовать упихнуть последовательность цифр в инт и на каждой следующей цифре проверять сложение / умножение на переполнение, не знаю, что хуже.
А с денормализованными как будто всё легко получилось, потому что просто, когда целая часть нулевая и идёшь по бинарной дробной в поисках первой единицы, постепенно уменьшая бинарную экспоненту, то останавливаешься в момент, когда бинарная экспонента андерфловится, и дальше уже пишешь все следующие биты в мантиссу, какими бы они ни были.
И вот весь этот бред он вроде работает, но как-то медленно, по крайней мере достаточно, чтобы мне лень ждать, чтобы проверить его хотя бы на всех сингловых флоатах, отформатированных через sprintf, и то это не будет избыточной проверкой, потому что это будут только некоторые из возможных входных десятичных дробей.
Скорее всего, основная проблема в том, что я делаю всякий побитовый бред вручную вместо того, чтобы использовать интринсики, ну которые там количество единиц считают или находят бит со старшей единицей. Ну и сам подход в корне какой-то дебильный: что мне приходится сначала всё разворачивать в гигантский десимал, а потом сворачивать в крошечный флоат.
725 Кб, 1448x2048Основная идея в том, чтобы распаковать флоат в бинарное число с фиксированной точкой с гигантской точностью, чтобы в него уместился любой флоат без потери точности, а потом скопировать биты после первой старшей единицы в мантиссу + посчитать экспоненту так, чтобы она сдвигала точку в нужное место. Примерно то же самое, что описывал тот чел https://randomascii.wordpress.com/2012/03/08/float-precisionfrom-zero-to-100-digits-2 для обратной операции (перевод из флоата в строку с десятичной дробью), но нет заморочек с тем, чтобы вывести самое короткое представление в десятичном виде, потому что тут результат фиксированного размера.
Проблема в том, что десятичную дробь в бинарную не всегда можно записать конечным количеством цифр, поэтому придётся округлять. Я сделал вроде примерно, как в той >>735955 статье рассказывалось: что беру дополнительно два следующих бита (guard и round) после того, как заканчивается точность мантиссы, и ещё третий бит равный OR-у всех оставшихся битов (sticky). Ну и типо, если биты равны 0xx, то округляешь вниз, если 100, то к чётному, иначе вверх. Округление делается просто через +1 к почти готовому флоату, проинтерпретированному как u32.
Непонятно, сколько нужно вперёд битов брать, чтобы вычислить sticky бит. У меня на целую часть выделено 5 u32-ых (типо самый длинный флоат 2^127 + ещё сверху нужно хотя бы 2 бита на guard и round), и на дробную тоже 5 u32-ых (самый маленький положительный флоат 2^-149 + тоже биты для округления). Ну и как будто хватает.
Чтобы перевести десятичную целую часть в бинарную, можно просто взять это число, состоящее из 5 u32-ых, изначально равное нулю, и последовательно умножать его на 10 и прибавлять следующую и следующую цифру из входной строки слева от точки. Умножение столбиком (long multiplication) и о нём тут можно думать как об умножении числа из 5 цифр на число из одной цифры в 2^32-ричной системе счисления, то есть просто напрямую перемножаешь два u32, прибавляешь перенос, записываешь результат в u64, после чего одна половина идёт в результат произведения, а вторая - в перенос к умножению на следующий разряд. Со сложением в столбик примерно то же самое.
А дробную часть не знаю, как нормально переводить в бинарный вид. Я думал, можно обойтись так же, как с целой, и что-нибудь с экспонентой сделать, но проблема в том, что в изначальной форме число десятичное, а приводится к двоичному и непонятно, как сконвертировать умножение на 10^n в умножение на 2^n. Я в итоге сделал через последовательное умножение десятичной дробной части на 2, ну то есть буквально записываешь все цифры из входной строки после точки в массив, оставив в начале один ноль для целой части, и столбиком умножаешь их на 2. Умножил один раз, если в целой части вылезла единица, то значит в числе есть одна 1/2-ая, иначе ноль, единицу зануляешь, и потом умножаешь ещё раз на 2 - получил количество 1/4-ых в числе, ещё раз - количество 1/8-ых, и так далее, по ходу записываешь результат в бинарном виде.
И к этому ещё нужно было как-то прикрутить парсинг такой записи 1e-2, и тут та же проблема, короче, я просто как-то криво сделал, что при переводе целой/дробной части в бинарную я, в зависимости от десятичной экспоненты, например, читаю цифры из целой десятичной части в дробную бинарную, если экспонента отрицательная, либо читаю из дробной десятичной в целую бинарную, если положительная, либо забиваю нулями, короче, такой бред.
Для парсинга десятичной экспоненты нужен парсинг интов + понимать, умещается ли последовательность цифр в инт, и я почему-то написал какой-то бред, что для этого я просто сравниваю входную строку лексикографически с максимальным / минимальным интом, записанным в строку. Другой вариант был бы, наверное, попробовать упихнуть последовательность цифр в инт и на каждой следующей цифре проверять сложение / умножение на переполнение, не знаю, что хуже.
А с денормализованными как будто всё легко получилось, потому что просто, когда целая часть нулевая и идёшь по бинарной дробной в поисках первой единицы, постепенно уменьшая бинарную экспоненту, то останавливаешься в момент, когда бинарная экспонента андерфловится, и дальше уже пишешь все следующие биты в мантиссу, какими бы они ни были.
И вот весь этот бред он вроде работает, но как-то медленно, по крайней мере достаточно, чтобы мне лень ждать, чтобы проверить его хотя бы на всех сингловых флоатах, отформатированных через sprintf, и то это не будет избыточной проверкой, потому что это будут только некоторые из возможных входных десятичных дробей.
Скорее всего, основная проблема в том, что я делаю всякий побитовый бред вручную вместо того, чтобы использовать интринсики, ну которые там количество единиц считают или находят бит со старшей единицей. Ну и сам подход в корне какой-то дебильный: что мне приходится сначала всё разворачивать в гигантский десимал, а потом сворачивать в крошечный флоат.


Идею для видео украл откуда-то (гифку увидел в интернете), круги, расположенные по сетке, на точках пересечения цвет меняется на противоположный, радиус меняют по синусоиде со сдвигом в зависимости от расстояния от центра. Каждый раз не могу понять, правильно ли я сделал закольцовывание или нет.
Через сохранение в файлы не пробовал, там основная сложность, в каком формате сохранять файлы, ну, наверное, лучше всего в пнг, но ффмпег также понимает это https://netpbm.sourceforge.net/doc/ppm.html (никакого сжатия) и это https://qoiformat.org (какое-то сжатие, вроде несложно написать свой энкодер). Плюс в том, что промежуточные результаты рендера сохраняются на диск: в теории можно поставить на паузу и продолжить позже или сохранить видео в нескольких форматах без траты времени на то, чтобы перерендеривать кадры. Минус в том, что наверное, много место занимает, даже с учётом сжатия?
Я сам сделал через stdin, ффмпег запускается примерно такой командой:
> ffmpeg -y -f rawvideo -pix_fmt argb -s 1920x1080 -r 60 -i - -an out.mp4
И просто в него скармливаешь подряд байты в формате, какой указал в -pix_fmt, в конце закрываешь stdin и ждёшь завершения работы процесса.
Под виндой это делается через то, чтобы создать пайп, один его конец (read) прицепить к дочернему процессу с ффмпегом при его создании, а во второй (write) писать из родительского, который потом в конце закрыть просто как обычный файл через CloseHandle. https://learn.microsoft.com/en-us/windows/win32/procthread/creating-a-child-process-with-redirected-input-and-output
CreateProcess - какая-то странная функция, куча параметров и я не понимаю, что передавать в параметры application name и что в command line. Если в application name положить путь до экзешника ffmpeg, а в command line команду полностью, включая "ffmpeg" в начале, то работает. Другие комбинации по типу "NULL в application name, полностью команду в command line" или "путь до ффмпега в application name, пропустить ffmpeg в command line" либо работают как-то странно, либо падают с ошибкой.
Под линуксом, вроде я слышал, это делается через fork+exec и что-то ещё для пайпов, но я не пробовал, у меня сейчас нет линукса и не очень хочется.
С линуксом я недавно мучился, когда пытался установить его на qemu виртуалку с UEFI, потому что я хотел попробовать установить так, чтобы оно грузилось без бутлодера (efistub). И я, во-первых, не сразу понял, что если ты редактируешь efivars, то недостаточно просто делать -bios OVMF.fd, нужно отдельно подключать драйв с кодом UEFI и драйв, где хранятся efivars
> -drive if=pflash,format=raw,unit=0,file=OVMF_CODE.fd,readonly=on -drive if=pflash,format=raw,unit=1,file=OVMF_VARS.fd
А, во-вторых, начались проблемы с qemu под виндой, что ускоритель whpx не дружит с тем, чтобы вот так отдельно code и vars подключать. Обходится через то, чтобы один раз запуститься без whpx, отредактировать efivars, склеить vars и code в один файл и потом подключать его через -bios одновременно уже с whpx.
И я как-то очень поздно нагуглил ридми https://github.com/msys2/MINGW-packages/blob/master/mingw-w64-qemu/msys2.readme.txt где решения всех этих проблем описываются прямым текстом.
UEFI биос, кстати, отсюда можно скачать https://retrage.github.io/edk2-nightly и я помню, что когда делал хелловорлд на уефи и тестил его в виртуалке, то я его сам собирал этот биос из-за того, что тупо не мог нагуглить, где скачать готовый билд. Мне кажется, у меня упал iq ещё сильнее и я перестал уметь пользоваться гуглом.
Ну и, на самом деле, под виндой во всех этих заморочках с qemu не особо есть смысл, потому что тут, оказывается, есть hyper-v manager - что-то похожее на virt-manager из линукса, и в нём также есть какая-то своя встроенная реализация UEFI.
Идею для видео украл откуда-то (гифку увидел в интернете), круги, расположенные по сетке, на точках пересечения цвет меняется на противоположный, радиус меняют по синусоиде со сдвигом в зависимости от расстояния от центра. Каждый раз не могу понять, правильно ли я сделал закольцовывание или нет.
Через сохранение в файлы не пробовал, там основная сложность, в каком формате сохранять файлы, ну, наверное, лучше всего в пнг, но ффмпег также понимает это https://netpbm.sourceforge.net/doc/ppm.html (никакого сжатия) и это https://qoiformat.org (какое-то сжатие, вроде несложно написать свой энкодер). Плюс в том, что промежуточные результаты рендера сохраняются на диск: в теории можно поставить на паузу и продолжить позже или сохранить видео в нескольких форматах без траты времени на то, чтобы перерендеривать кадры. Минус в том, что наверное, много место занимает, даже с учётом сжатия?
Я сам сделал через stdin, ффмпег запускается примерно такой командой:
> ffmpeg -y -f rawvideo -pix_fmt argb -s 1920x1080 -r 60 -i - -an out.mp4
И просто в него скармливаешь подряд байты в формате, какой указал в -pix_fmt, в конце закрываешь stdin и ждёшь завершения работы процесса.
Под виндой это делается через то, чтобы создать пайп, один его конец (read) прицепить к дочернему процессу с ффмпегом при его создании, а во второй (write) писать из родительского, который потом в конце закрыть просто как обычный файл через CloseHandle. https://learn.microsoft.com/en-us/windows/win32/procthread/creating-a-child-process-with-redirected-input-and-output
CreateProcess - какая-то странная функция, куча параметров и я не понимаю, что передавать в параметры application name и что в command line. Если в application name положить путь до экзешника ffmpeg, а в command line команду полностью, включая "ffmpeg" в начале, то работает. Другие комбинации по типу "NULL в application name, полностью команду в command line" или "путь до ффмпега в application name, пропустить ffmpeg в command line" либо работают как-то странно, либо падают с ошибкой.
Под линуксом, вроде я слышал, это делается через fork+exec и что-то ещё для пайпов, но я не пробовал, у меня сейчас нет линукса и не очень хочется.
С линуксом я недавно мучился, когда пытался установить его на qemu виртуалку с UEFI, потому что я хотел попробовать установить так, чтобы оно грузилось без бутлодера (efistub). И я, во-первых, не сразу понял, что если ты редактируешь efivars, то недостаточно просто делать -bios OVMF.fd, нужно отдельно подключать драйв с кодом UEFI и драйв, где хранятся efivars
> -drive if=pflash,format=raw,unit=0,file=OVMF_CODE.fd,readonly=on -drive if=pflash,format=raw,unit=1,file=OVMF_VARS.fd
А, во-вторых, начались проблемы с qemu под виндой, что ускоритель whpx не дружит с тем, чтобы вот так отдельно code и vars подключать. Обходится через то, чтобы один раз запуститься без whpx, отредактировать efivars, склеить vars и code в один файл и потом подключать его через -bios одновременно уже с whpx.
И я как-то очень поздно нагуглил ридми https://github.com/msys2/MINGW-packages/blob/master/mingw-w64-qemu/msys2.readme.txt где решения всех этих проблем описываются прямым текстом.
UEFI биос, кстати, отсюда можно скачать https://retrage.github.io/edk2-nightly и я помню, что когда делал хелловорлд на уефи и тестил его в виртуалке, то я его сам собирал этот биос из-за того, что тупо не мог нагуглить, где скачать готовый билд. Мне кажется, у меня упал iq ещё сильнее и я перестал уметь пользоваться гуглом.
Ну и, на самом деле, под виндой во всех этих заморочках с qemu не особо есть смысл, потому что тут, оказывается, есть hyper-v manager - что-то похожее на virt-manager из линукса, и в нём также есть какая-то своя встроенная реализация UEFI.


Изначально я хотел сделать алгоритм FPP из этой древней статьи https://lists.nongnu.org/archive/html/gcl-devel/2012-10/pdfkieTlklRzN.pdf но я интуитивно не особо понимаю смысла алгоритмов оттуда и постоянно путаюсь в однобуквенных переменных. Ну, типа, я понимаю, что вроде как там сначала флоат представляется в виде рациональной дроби R / S. Потом процедура simple-fixup, видимо, определяет то, начиная с какого разряда в десятичном представлении мы начнём генерировать цифры (через умножение числителя / знаменателя на 10, пока не нормализуем дробь). Плюс там что-то делается, чтобы учесть потенциально неравные расстояния между текущим флоатом и следующим / предыдущим. После чего генерируем цифры для десятичного представления с каким-то непонятным условием выхода из цикла. Но это всё равно всё дико запутанно.
Ещё есть такая статья https://arxiv.org/pdf/1310.8121 с очень привлекательно коротким алгоритмом на джаве, но я его тоже не понял, к тому же проблема в том, что он требует реализации полноценного длинного деления одного многоциферного числа на другое многоциферное, а я слишком тупой для этого, я не понимаю, как в делении в столбик угадывать цифры из частного без того, чтобы итеративно вычитать делитель из куска делимого (что, наверное, не вариант, когда "цифры" - это 4-байтовые инты).
Что я имею в виду, вот, допустим, делим 3142 на 53, как понять, что первая цифра частного - это 5 без того, чтобы долго и нудно вычитать 314 - 53 - 53 - 53 - 53 - 53 = 49? Ну, короче, оказывается, что есть способ почти точно оценить значение следующей цифры из частного, про это у кнута есть (вторая книжка, глава 4.3.1, алгоритм D) и в хакерс делайт глава с реализацией на си, но я особо не разбирался.
В итоге я взял алгоритм из вступления к этой статье https://dl.acm.org/doi/pdf/10.1145/3192366.3192369 Там в начале описывается медленный алгоритм, как преобразовывать флоаты в строку, а потом показывается, как его можно ускорить, но я дальше не читал. Основная идея медленного алгоритма в том, что берём флоат, а также два числа, которые находятся посередине между входным флоатом и предыдущим и следующим флоатами. Преобразовываем все три числа в десятичную форму с максимальной точностью и отбрасываем у них десятичные цифры в мантиссах до тех пор, пока не выполнятся какие-то там магические условия выхода из цикла.
Перед преобразованием в десятичную форму смещаем бинарную экспоненту так, чтобы бинарная мантисса стала интом, дальше работаем только с интами. После, хотим в этом уравнении:
> bin_mantissa · 2^bin_exp = dec_mantissa · 10^dec_exp
узнать dec_mantissa и dec_exp, при этом мы вольны выбирать любую десятичную экспоненту, какая нам была бы удобна, но чтобы dec_mantissa был интом.
Если бинарная экспонента положительная, то можно взять dec_exp = 0 и вычислить десятичную интовую мантиссу, перемножив bin_mantissa · 2^bin_exp.
Если бинарная экспонента отрицательная, то берём dec_exp = bin_exp, сокращаем 2^bin_exp с обеих сторон, переносим 5^bin_exp влево и получаем dec_mantissa = bin_mantissa · 5^(-bin_exp). Вот это умножение на степень 5 было и в том алгоритме на джаве выше, но я всё равно не понял тот алгоритм.
Алгоритм очень простой в реализации, я тупо переписал псевдокод в обычный код + сделал несколько несложных бигинтовых операций: умножение бигинтов, сравнение бигинтов, деление бигинта на u32, прибавление u32 к бигинту, вычитание u32 из бигинта, возведение 5 в большую степень. По итогу выполнения алгоритма получаешь десятичную интовую мантиссу и экспоненту к ней. Чтобы напечатать это в виде дроби, я написал 50 строк какой-то кринжовой хуеты, лишь бы как-то работало, по-любому там где-то есть ошибка. Не складываются слова в предложения, потому что я нахуй хочу умереть
Изначально я хотел сделать алгоритм FPP из этой древней статьи https://lists.nongnu.org/archive/html/gcl-devel/2012-10/pdfkieTlklRzN.pdf но я интуитивно не особо понимаю смысла алгоритмов оттуда и постоянно путаюсь в однобуквенных переменных. Ну, типа, я понимаю, что вроде как там сначала флоат представляется в виде рациональной дроби R / S. Потом процедура simple-fixup, видимо, определяет то, начиная с какого разряда в десятичном представлении мы начнём генерировать цифры (через умножение числителя / знаменателя на 10, пока не нормализуем дробь). Плюс там что-то делается, чтобы учесть потенциально неравные расстояния между текущим флоатом и следующим / предыдущим. После чего генерируем цифры для десятичного представления с каким-то непонятным условием выхода из цикла. Но это всё равно всё дико запутанно.
Ещё есть такая статья https://arxiv.org/pdf/1310.8121 с очень привлекательно коротким алгоритмом на джаве, но я его тоже не понял, к тому же проблема в том, что он требует реализации полноценного длинного деления одного многоциферного числа на другое многоциферное, а я слишком тупой для этого, я не понимаю, как в делении в столбик угадывать цифры из частного без того, чтобы итеративно вычитать делитель из куска делимого (что, наверное, не вариант, когда "цифры" - это 4-байтовые инты).
Что я имею в виду, вот, допустим, делим 3142 на 53, как понять, что первая цифра частного - это 5 без того, чтобы долго и нудно вычитать 314 - 53 - 53 - 53 - 53 - 53 = 49? Ну, короче, оказывается, что есть способ почти точно оценить значение следующей цифры из частного, про это у кнута есть (вторая книжка, глава 4.3.1, алгоритм D) и в хакерс делайт глава с реализацией на си, но я особо не разбирался.
В итоге я взял алгоритм из вступления к этой статье https://dl.acm.org/doi/pdf/10.1145/3192366.3192369 Там в начале описывается медленный алгоритм, как преобразовывать флоаты в строку, а потом показывается, как его можно ускорить, но я дальше не читал. Основная идея медленного алгоритма в том, что берём флоат, а также два числа, которые находятся посередине между входным флоатом и предыдущим и следующим флоатами. Преобразовываем все три числа в десятичную форму с максимальной точностью и отбрасываем у них десятичные цифры в мантиссах до тех пор, пока не выполнятся какие-то там магические условия выхода из цикла.
Перед преобразованием в десятичную форму смещаем бинарную экспоненту так, чтобы бинарная мантисса стала интом, дальше работаем только с интами. После, хотим в этом уравнении:
> bin_mantissa · 2^bin_exp = dec_mantissa · 10^dec_exp
узнать dec_mantissa и dec_exp, при этом мы вольны выбирать любую десятичную экспоненту, какая нам была бы удобна, но чтобы dec_mantissa был интом.
Если бинарная экспонента положительная, то можно взять dec_exp = 0 и вычислить десятичную интовую мантиссу, перемножив bin_mantissa · 2^bin_exp.
Если бинарная экспонента отрицательная, то берём dec_exp = bin_exp, сокращаем 2^bin_exp с обеих сторон, переносим 5^bin_exp влево и получаем dec_mantissa = bin_mantissa · 5^(-bin_exp). Вот это умножение на степень 5 было и в том алгоритме на джаве выше, но я всё равно не понял тот алгоритм.
Алгоритм очень простой в реализации, я тупо переписал псевдокод в обычный код + сделал несколько несложных бигинтовых операций: умножение бигинтов, сравнение бигинтов, деление бигинта на u32, прибавление u32 к бигинту, вычитание u32 из бигинта, возведение 5 в большую степень. По итогу выполнения алгоритма получаешь десятичную интовую мантиссу и экспоненту к ней. Чтобы напечатать это в виде дроби, я написал 50 строк какой-то кринжовой хуеты, лишь бы как-то работало, по-любому там где-то есть ошибка. Не складываются слова в предложения, потому что я нахуй хочу умереть
Твой конфиг для Neovim выглядит неплохо. Плагины, которые ты используешь, действительно полезны. Однако, если ты чувствуешь, что твой конфиг слишком сложный, ты можешь попробовать использовать более минималистичный подход. Это может помочь тебе сосредоточиться на написании кода, а не на настройке редактора
 413 Кб, 1080x1350
413 Кб, 1080x1350https://godbolt.org/z/fTa4W15cM
Там два способа, один через какой-то VirtualAlloc2, который в 10 винде появился, и там в него просто можно параметром выравнивание передать. Другой - зарезервировать достаточно большой кусок памяти, чтобы в нём точно нашёлся выровненный адрес, и коммитнуть кусочек памяти по выровненному адресу. В худшем случае резервируются 2N мегабайтов и коммитится N. Как я понял, через VirtualFree нельзя частично освободить зарезервированный интервал адресов (в документации прямо написано), частично можно только декоммитнуть память. Что интересно, оба способа зачастую один и тот же адрес возвращают, если их последовательно запустить.
Ещё есть третий шизоидный вариант - перебирать выровненные адреса, подсовывая их как параметр в VirtualAlloc, пока не найдётся доступный, но, как будто это совсем бред.
Заметил, что даже если коммитишь много памяти, но на деле используешь её только частично, то как будто таск менеджер пишет, что процесс использует только ту память, которую ты реально потрогал, а не столько, сколько закоммитил. И что можно вообще коммитить больше памяти, чем у тебя есть физически. И показалось, что может быть, нет смысла резервировать и коммитить отдельно, но всё же нет https://learn.microsoft.com/en-us/archive/blogs/markrussinovich/pushing-the-limits-of-windows-virtual-memory#committed-memory и суммарно закоммиченная память там в отдельной вкладке отображается.
Оно следит за тем, чтобы в теории была возможность одновременно всю коммитнутую память где-то держать: будь то в оперативке или в файле подкачки, поэтому есть предел, даже если ты эту память никак не используешь. И ещё по мере приближения к этому пределу VirtualAlloc работает всё медленнее и медленнее, пока не сдыхает, у меня - ближе к 128 гигабайтам закоммиченной памяти (ну вот, видимо, 32Гб физической + какой-то там большой файл подкачки).
А если в цикле кусками резервировать адреса, то те же 128 гигабайтов гораздо быстрее резервируются и полностью, и вроде всё в порядке. Виртуальные адреса тоже вроде не совсем бесконечные https://learn.microsoft.com/en-us/windows-hardware/drivers/gettingstarted/virtual-address-spaces написано, что доступны только адреса от 0 до 128 терабайтов.
Не особо понятно, что под линуксом, там в mmap как будто нет разделения на reserve и commit. Вроде бы достаточно указать PROT_NONE (pages may not be accessed) в mmap и потом сделать mprotect для нужного диапазона адресов. И у munmap как будто нет ограничения, что мол нужно передавать туда только то, что mmap вернул, поэтому, видимо, можно даже виртуальные адреса ненужные обратно отдать? Я не проверял ничего из этого
413 Кб, 1080x1350https://godbolt.org/z/fTa4W15cM
Там два способа, один через какой-то VirtualAlloc2, который в 10 винде появился, и там в него просто можно параметром выравнивание передать. Другой - зарезервировать достаточно большой кусок памяти, чтобы в нём точно нашёлся выровненный адрес, и коммитнуть кусочек памяти по выровненному адресу. В худшем случае резервируются 2N мегабайтов и коммитится N. Как я понял, через VirtualFree нельзя частично освободить зарезервированный интервал адресов (в документации прямо написано), частично можно только декоммитнуть память. Что интересно, оба способа зачастую один и тот же адрес возвращают, если их последовательно запустить.
Ещё есть третий шизоидный вариант - перебирать выровненные адреса, подсовывая их как параметр в VirtualAlloc, пока не найдётся доступный, но, как будто это совсем бред.
Заметил, что даже если коммитишь много памяти, но на деле используешь её только частично, то как будто таск менеджер пишет, что процесс использует только ту память, которую ты реально потрогал, а не столько, сколько закоммитил. И что можно вообще коммитить больше памяти, чем у тебя есть физически. И показалось, что может быть, нет смысла резервировать и коммитить отдельно, но всё же нет https://learn.microsoft.com/en-us/archive/blogs/markrussinovich/pushing-the-limits-of-windows-virtual-memory#committed-memory и суммарно закоммиченная память там в отдельной вкладке отображается.
Оно следит за тем, чтобы в теории была возможность одновременно всю коммитнутую память где-то держать: будь то в оперативке или в файле подкачки, поэтому есть предел, даже если ты эту память никак не используешь. И ещё по мере приближения к этому пределу VirtualAlloc работает всё медленнее и медленнее, пока не сдыхает, у меня - ближе к 128 гигабайтам закоммиченной памяти (ну вот, видимо, 32Гб физической + какой-то там большой файл подкачки).
А если в цикле кусками резервировать адреса, то те же 128 гигабайтов гораздо быстрее резервируются и полностью, и вроде всё в порядке. Виртуальные адреса тоже вроде не совсем бесконечные https://learn.microsoft.com/en-us/windows-hardware/drivers/gettingstarted/virtual-address-spaces написано, что доступны только адреса от 0 до 128 терабайтов.
Не особо понятно, что под линуксом, там в mmap как будто нет разделения на reserve и commit. Вроде бы достаточно указать PROT_NONE (pages may not be accessed) в mmap и потом сделать mprotect для нужного диапазона адресов. И у munmap как будто нет ограничения, что мол нужно передавать туда только то, что mmap вернул, поэтому, видимо, можно даже виртуальные адреса ненужные обратно отдать? Я не проверял ничего из этого


>перебирать выровненные адреса
Можно перебирать диапазоны адресов функцией VirtualQuery. Красиво? Красиво??? :3
Ещё для сценариев, похожих на твой вариант 2, есть плейсхолдеры (https://devblogs.microsoft.com/oldnewthing/20240201-00/?p=109346), но они, видимо, поддерживаются (только) той же этой твоей VirtualAlloc2, что и прямое задание выравнивания. Выделяешь один плейсхолдер, делишь его на два в нужном месте, одну часть материализуешь, другую освобождаешь.
В принципе, можно то же самое делать без плейсхолдеров, просто в таком же цикле на случай гонки, что в статье. То есть, чтобы выделить кусок памяти, выровненный на 1 Мб, делаешь
>do {
>— p = VirtualAlloc(null, 2 Мб, ...)
>— if (!p) throw;
>— p_aligned = (p + 1 Мб − 1) & −1 Мб
>— VirtualFree(p)
>— p = VirtualAlloc(p_aligned, 1 Мб, ...)
>} while (!p)
Честно говоря, с учётом всегда существовавшей возможности сделать вот так и доли случаев, когда это нужно, все эти явные плейсхолдеры и выравнивания выглядят решениями никогда ни у кого не стоявших проблем. Аллокации и так всегда выровнены МИНИМУМ на 64 Кб, НУ КУДА ЕЩЁ БОЛЬШЕ. Опуская городские легенды про волшебные менеджеры памяти, использующие это вместо заголовков (идея на первый взгляд понятна, но чем больше об этом думаю, тем больше вопросов...), худшее, про что я слышал — это выравнивание буферов для асинхронного I/O (https://learn.microsoft.com/en-us/windows/win32/fileio/file-buffering) на размер физического сектора диска (https://en.wikipedia.org/wiki/Disk_sector), но, э-э, см. числа.


У меня в голове крутится шизоидная идея проги, которая берёт репозиторий с кодом и конвертирует его в картинку, на которой содержимое всех файлов выводится текстом с мелким пиксельным шрифтом, текст каждого файла пишется внутри отдельного прямоугольника вместе с названием файла и, возможно, другими метаданными. Может быть, даже конвертирует в гифку и в прямоугольниках с текстами файлов содержимое скроллится, а не сразу целиком выводится, чтобы удобнее было читать и потому что просмоторщикам картинок может стать плохо от картинок большого размера (в ширину и высоту). А также нужно, чтобы была возможность в обратную сторону прокрутить - из такой картинки воссоздать всю структуру папок и файлов и их содержимое. Короче, такой формат для архивирования репозитория в один файл, но при этом визуально читаемый.
Также можно добавить возможность делать патчи и точно так же их запаковывать в картинки, чтобы можно было запостить, например, на имиджборду, картинку с начальным состоянием репозитория, а потом самому себе реплаить по цепочке картинками-патчами с изменениями. Не знаю, как быть с мердж реквестами. Отдельную ветку в чужом картиночном репозитории создать легко, просто начинаешь сам реплаить по цепочке на какой-нибудь пост оригинального автора, но как потом объединить две параллельные цепочки: свою и авторскую - непонятно. Самый простой вариант, наверное, это чтобы автор для слияния вместо очередного патча запостил бы полноценный снапшот репозитория, в котором аккумулированы все авторские патчи и все патчи из мердж реквестовой ветки с вручную разрешёнными возможными конфликтами. Либо другой вариант, автор может вручную перепостить все твои картинки себе в цепочку, типа такой ребейз, не надо постить полноценный снапшот репозитория целиком, но это как-то муторно
 228 Кб, 1075x1442
228 Кб, 1075x1442Возьмём объявление переменной, идея в том, что у неё есть один "базовый" тип и к нему по очереди, наслаиваясь друг на друга, применяются типа "операторы", которые модифицируют его. Конкретно это:
- оператор "указатель на ..." (записывается звёздочкой)
- оператор "массив из ..." (записывается парой квадратных скобок с размерностью внутри)
- оператор "функция, возвращающая ..." (записывается парой круглых скобок со списком параметров внутри)
Если бы в си был нормальный синтаксис, то объявление переменной типа "массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char" могло бы выглядеть как-то так:
> array<8, ptr<fn(int, int) -> ptr<char>>> variable;
Здесь "базовый" тип - это char и к нему по очереди применяются операторы-модификаторы через обёртывание в "ptr<...>", "array<N, ...>" или "fn() -> ...", а название переменной просто в сторонке стоит.
Можно пройтись от базового типа до финального, постепенно применяя к нему операторы. Изначально есть просто char, а на название переменной вообще всё равно, просто потом можно дописать в конец:
> char
Указатель на char:
> ptr<char>
Функция, которая принимает два инта в качестве параметров и возвращает указатель на char:
> fn(int, int) -> ptr<char>
Указатель на функцию, которая принимает два инта в качестве параметров и возвращает указатель на char:
> ptr<fn(int, int) -> ptr<char>>
Массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char:
> array<8, ptr<fn(int, int) -> ptr<char>>>
А как провести теперь параллель с сишным синтаксисом я даже не знаю, он просто не делает никакого смысла. Отличия такие:
- "базовый" тип стоит всегда слева в сторонке
- "операторы" выглядят так, как будто применяются к названию переменной, потому что стоят вокруг неё, хотя по логике они всё так же применяются к базовому типу
- но при этом операторы, которые находятся дальше от названия переменной, применяются первее, чем те, что ближе к ней
- и да, они стоят именно вокруг переменной, а не по порядку перед ней или после неё (то есть это и не префиксная форма записи, и не постфиксная): оператор "указатель на ..." всегда стоит слева, а остальные два - всегда справа, из-за чего возникает необходимость вводить приоритет для них (у "указателя на ..." он меньше), а также использовать скобки, чтобы при необходимости применить оператор с меньшим приоритетом в первую очередь
Можно попытаться пройтись точно так же, от базового типа к финальному производному, но уже в упоротом сишном синтаксисе. Изначально есть char, название переменной тоже придётся добавить, потому что наворачивать операторы мы будет именно вокруг него, причём, из-за дебильного обратного порядка на каждом шаге мы будем впихивать операторы прямо РЯДОМ с названием переменной:
> char variable
Указатель на char:
> char ∗variable
Функция, которая принимает два инта в качестве параметров и возвращает указатель на char:
> char ∗(variable(int, int))
На русском звучит просто как обычное объявление функции, но почему код так странно выглядит (кстати, он спокойно компилируется)? Эти лишние скобки можно убрать, потому что оператор "(int, int)" всё равно по приоритету применится первее звёздочки, и тогда получится привычное объявление функции:
> char ∗variable(int, int)
Указатель на функцию, которая принимает два инта в качестве параметров и возвращает указатель на char. Здесь ставим звёдочку рядом с названием переменной и заключаем её в скобки, потому что у рядом стоящего "(int, int)" больше приоритет, но нам нужно, чтобы только что добавленная звёздочка применилась первее, потому что у нас наркоманский обратный порядок:
> char ∗(∗variable)(int, int)
Массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char, тут снова скобки лишние, потому что у "[8]" более высокий приоритет, чем у звёдочки:
> char ∗(∗variable[8])(int, int)
Это полный бред, но это походу вот реально то, как оно работает, даже можно напихать лишних скобок и оно будет компилироваться и означать ровно то же самое:
> char (∗((∗((variable)[8]))(int, int)))
Независимо я какое-то время назад, ещё летом вроде, смотрел стрим одного чела и он случайно обнаружил, что названия функций можно оборачивать в бессмысленные скобки, я тогда не задумывался особо глубоко, зачем так и почему, просто можно и ладно, но, получается, это отсюда ноги растут.
В статье также расписан алгоритм, как читать такие объявления, ну, что от названия переменной ты идёшь сначала до упора направо, потом налево, раскрываешь скобки, когда больше не можешь продвинуться ни туда, ни туда. Одновременно с этим строишь предложение на естественном языке от начала и до конца, в прямом порядке. Это более-менее очевидный подход, который следует из того, что звёздочки пишутся слева и имеют меньший приоритет. Ещё видел алгоритм чтения по спирали вместо "иди направо, потом налево" https://c-faq.com/decl/spiral.anderson.html. Если честно, я уже слышал про эти алгоритмы, но тогда тупо не понял их, из-за того, что не видел никакой логики в сишных объявлениях.
Но если реализовывать парсинг этих объявлений программно, то, как мне кажется, проще было бы идти не изнутри наружу, а наоборот, снаружи вовнутрь, постепенно отбрасывая внешние слои, но тогда звёздочки бы имели наоборот больший приоритет в порядке раскрывания:
...
> char ∗(∗variable[8])(int, int)
... char
> ∗(∗variable[8])(int, int)
... указатель на char
> (∗variable[8])(int, int)
... функция, которая принимает два инта в качестве параметров и возвращает указатель на char
> (∗variable[8])
... функция, которая принимает два инта в качестве параметров и возвращает указатель на char
> ∗variable[8]
... указатель на функцию, которая принимает два инта в качестве параметров и возвращает указатель на char
> variable[8]
... массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char
> variable
variable - это массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char
>
К тому же этот способ не страдает от того, что при парсинге такого "int ∗(∗)())()" способом из статьи, непонятно, откуда изнутри начать разворачивать этот абстрактный декларатор (в статье пишет, что они встречаются в двух местах: в кастах и внутри sizeof, но так-то ещё в форвард-объявлениях функций, там же можно опустить названия параметров).
Можно типа сказать, что синтаксис с треугольными скобками ещё хуже и вообще он уродливый, ну ладно, но почему бы просто было не сделать так, например:
> char variable∗(int, int)∗[8]
Здесь не нужны дополнительные скобки, потому что все операторы пишутся с одной стороны от названия переменной. Если посмотреть на конец объявления, то сразу понятно, ЧТО ЭТО ВООБЩЕ, в отличие от сишного синтаксиса, например, тут сразу видно, что это массив из восьми каких-то элементов. Чтобы понять, из каких, просто читаешь операторы справа-налево. Да, оно тоже выглядит уродливо, очень непривычно, возможно, на практике там вылезает миллион проблем в духе https://en.wikipedia.org/wiki/Most_vexing_parse, но, блин, а нахуй я живу, блять, кстати. Я думал сделать парсер сишных хедеров, начал писать токенизатор, а потом почти сразу забил, потому что, а зачем он мне нужен. Кстати, в шланге вроде бы есть опция, чтобы он выплюнул AST входного файла, больше имело бы смысл брать это готовое и делать что-то с ним.
А тайпдефы это, кстати, просто объявления переменных, к которым дописали слева typedef, и тогда название переменной становится названием алиаса для типа, который был типом переменной.
Ещё из странных вещей, я случайно обнаружил, что строковые и символьные литералы поддерживают восьмеричные коды для записи байтов, а синтаксис у них - "обратный слеш + от 1 до 3 цифр". Ну, то есть, например, 'J' == '\112' == 74. И, получается, в нуль-терминаторе '\0' - это не какой-то отдельный эскейп для нуля, как я думал, а восьмеричный код. Ну, понятно, что это не играет роли для нуля, но просто забавно
228 Кб, 1075x1442Возьмём объявление переменной, идея в том, что у неё есть один "базовый" тип и к нему по очереди, наслаиваясь друг на друга, применяются типа "операторы", которые модифицируют его. Конкретно это:
- оператор "указатель на ..." (записывается звёздочкой)
- оператор "массив из ..." (записывается парой квадратных скобок с размерностью внутри)
- оператор "функция, возвращающая ..." (записывается парой круглых скобок со списком параметров внутри)
Если бы в си был нормальный синтаксис, то объявление переменной типа "массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char" могло бы выглядеть как-то так:
> array<8, ptr<fn(int, int) -> ptr<char>>> variable;
Здесь "базовый" тип - это char и к нему по очереди применяются операторы-модификаторы через обёртывание в "ptr<...>", "array<N, ...>" или "fn() -> ...", а название переменной просто в сторонке стоит.
Можно пройтись от базового типа до финального, постепенно применяя к нему операторы. Изначально есть просто char, а на название переменной вообще всё равно, просто потом можно дописать в конец:
> char
Указатель на char:
> ptr<char>
Функция, которая принимает два инта в качестве параметров и возвращает указатель на char:
> fn(int, int) -> ptr<char>
Указатель на функцию, которая принимает два инта в качестве параметров и возвращает указатель на char:
> ptr<fn(int, int) -> ptr<char>>
Массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char:
> array<8, ptr<fn(int, int) -> ptr<char>>>
А как провести теперь параллель с сишным синтаксисом я даже не знаю, он просто не делает никакого смысла. Отличия такие:
- "базовый" тип стоит всегда слева в сторонке
- "операторы" выглядят так, как будто применяются к названию переменной, потому что стоят вокруг неё, хотя по логике они всё так же применяются к базовому типу
- но при этом операторы, которые находятся дальше от названия переменной, применяются первее, чем те, что ближе к ней
- и да, они стоят именно вокруг переменной, а не по порядку перед ней или после неё (то есть это и не префиксная форма записи, и не постфиксная): оператор "указатель на ..." всегда стоит слева, а остальные два - всегда справа, из-за чего возникает необходимость вводить приоритет для них (у "указателя на ..." он меньше), а также использовать скобки, чтобы при необходимости применить оператор с меньшим приоритетом в первую очередь
Можно попытаться пройтись точно так же, от базового типа к финальному производному, но уже в упоротом сишном синтаксисе. Изначально есть char, название переменной тоже придётся добавить, потому что наворачивать операторы мы будет именно вокруг него, причём, из-за дебильного обратного порядка на каждом шаге мы будем впихивать операторы прямо РЯДОМ с названием переменной:
> char variable
Указатель на char:
> char ∗variable
Функция, которая принимает два инта в качестве параметров и возвращает указатель на char:
> char ∗(variable(int, int))
На русском звучит просто как обычное объявление функции, но почему код так странно выглядит (кстати, он спокойно компилируется)? Эти лишние скобки можно убрать, потому что оператор "(int, int)" всё равно по приоритету применится первее звёздочки, и тогда получится привычное объявление функции:
> char ∗variable(int, int)
Указатель на функцию, которая принимает два инта в качестве параметров и возвращает указатель на char. Здесь ставим звёдочку рядом с названием переменной и заключаем её в скобки, потому что у рядом стоящего "(int, int)" больше приоритет, но нам нужно, чтобы только что добавленная звёздочка применилась первее, потому что у нас наркоманский обратный порядок:
> char ∗(∗variable)(int, int)
Массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char, тут снова скобки лишние, потому что у "[8]" более высокий приоритет, чем у звёдочки:
> char ∗(∗variable[8])(int, int)
Это полный бред, но это походу вот реально то, как оно работает, даже можно напихать лишних скобок и оно будет компилироваться и означать ровно то же самое:
> char (∗((∗((variable)[8]))(int, int)))
Независимо я какое-то время назад, ещё летом вроде, смотрел стрим одного чела и он случайно обнаружил, что названия функций можно оборачивать в бессмысленные скобки, я тогда не задумывался особо глубоко, зачем так и почему, просто можно и ладно, но, получается, это отсюда ноги растут.
В статье также расписан алгоритм, как читать такие объявления, ну, что от названия переменной ты идёшь сначала до упора направо, потом налево, раскрываешь скобки, когда больше не можешь продвинуться ни туда, ни туда. Одновременно с этим строишь предложение на естественном языке от начала и до конца, в прямом порядке. Это более-менее очевидный подход, который следует из того, что звёздочки пишутся слева и имеют меньший приоритет. Ещё видел алгоритм чтения по спирали вместо "иди направо, потом налево" https://c-faq.com/decl/spiral.anderson.html. Если честно, я уже слышал про эти алгоритмы, но тогда тупо не понял их, из-за того, что не видел никакой логики в сишных объявлениях.
Но если реализовывать парсинг этих объявлений программно, то, как мне кажется, проще было бы идти не изнутри наружу, а наоборот, снаружи вовнутрь, постепенно отбрасывая внешние слои, но тогда звёздочки бы имели наоборот больший приоритет в порядке раскрывания:
...
> char ∗(∗variable[8])(int, int)
... char
> ∗(∗variable[8])(int, int)
... указатель на char
> (∗variable[8])(int, int)
... функция, которая принимает два инта в качестве параметров и возвращает указатель на char
> (∗variable[8])
... функция, которая принимает два инта в качестве параметров и возвращает указатель на char
> ∗variable[8]
... указатель на функцию, которая принимает два инта в качестве параметров и возвращает указатель на char
> variable[8]
... массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char
> variable
variable - это массив из восьми указателей на функции, которые принимают два инта в качестве параметров и возвращают указатель на char
>
К тому же этот способ не страдает от того, что при парсинге такого "int ∗(∗)())()" способом из статьи, непонятно, откуда изнутри начать разворачивать этот абстрактный декларатор (в статье пишет, что они встречаются в двух местах: в кастах и внутри sizeof, но так-то ещё в форвард-объявлениях функций, там же можно опустить названия параметров).
Можно типа сказать, что синтаксис с треугольными скобками ещё хуже и вообще он уродливый, ну ладно, но почему бы просто было не сделать так, например:
> char variable∗(int, int)∗[8]
Здесь не нужны дополнительные скобки, потому что все операторы пишутся с одной стороны от названия переменной. Если посмотреть на конец объявления, то сразу понятно, ЧТО ЭТО ВООБЩЕ, в отличие от сишного синтаксиса, например, тут сразу видно, что это массив из восьми каких-то элементов. Чтобы понять, из каких, просто читаешь операторы справа-налево. Да, оно тоже выглядит уродливо, очень непривычно, возможно, на практике там вылезает миллион проблем в духе https://en.wikipedia.org/wiki/Most_vexing_parse, но, блин, а нахуй я живу, блять, кстати. Я думал сделать парсер сишных хедеров, начал писать токенизатор, а потом почти сразу забил, потому что, а зачем он мне нужен. Кстати, в шланге вроде бы есть опция, чтобы он выплюнул AST входного файла, больше имело бы смысл брать это готовое и делать что-то с ним.
А тайпдефы это, кстати, просто объявления переменных, к которым дописали слева typedef, и тогда название переменной становится названием алиаса для типа, который был типом переменной.
Ещё из странных вещей, я случайно обнаружил, что строковые и символьные литералы поддерживают восьмеричные коды для записи байтов, а синтаксис у них - "обратный слеш + от 1 до 3 цифр". Ну, то есть, например, 'J' == '\112' == 74. И, получается, в нуль-терминаторе '\0' - это не какой-то отдельный эскейп для нуля, как я думал, а восьмеричный код. Ну, понятно, что это не играет роли для нуля, но просто забавно


Оладьи на молоке, просто обычные на вкус. В рецепте зачем-то были сода и лимонная кислота как отдельные ингредиенты, хотя, как я понимаю, вместе это то же самое, что разрыхлитель. Это для какого-то кастомного соотношения соды к лимонной кислоте что ли, ну я попробовал так, вроде тесто поднялось немного. Лимонная кислота у меня была случайно, потому что я пробовал её добавлять в рис, якобы он тогда с большей вероятностью получается рассыпчатым (на деле не помогает).
Я еду никогда в жизни до этого себе не готовил и начал это делать только месяца два назад, но с тех пор не появилось ощущения, что это что-то хотя бы немного важное в жизни. Вообще, если бы существовал просто условный "человеческий корм", безвкусный и спресованный в порционные сухие брикеты, я бы лучше его использовал как основную еду, запивая чаем или кофе


Попробовал из спины, моркови и луковицы сделать куриный бульон и сварить на нём суп, ну бульон вроде получился на вкус как куриный бульон. Отделение ошмётков мяса от сваренного куриного остова - это какой-то аутизм, а результат - всего лишь небольшая горка этих самых ошмётков. Подобным, наверное, стоит заниматься только, если у тебя изначально не куриная тушка, а какие-нибудь петушиные шеи, и тогда у тебя выбор: либо сидишь копаешься в костях, либо у тебя нет мяса вообще.
Я зачем-то решил сделать гороховый суп и в итоге это убило какой-либо смысл приготовления бульона перед этим, теперь не понять, сварен горох на бульоне или просто на воде, оно просто на вкус как горох. Больше было бы смысла сварить в нём что-то нейтральное по вкусу вроде лапши. Либо варить на этом бульоне суп из каких-нибудь трав, крапивы, лебеды, щавеля, и в идеале кость на бульон у бродячей собаки отобрать, чтобы все ингредиенты были околобесплатными


 82 Кб, 1231x1556
82 Кб, 1231x1556У меня ощущение, что внутри что-то окончательно переломилось и я теперь уже совсем больше ничего не могу делать, и я не знаю, как это исправить. Скорее всего, никак, у меня в жизни в целом никогда не было так, что мои осознанные действия приводили бы к каким-либо улучшениям, со временем в среднем просто всё становится хуже и хуже. Я бы хотел уже подохнуть, чтобы это прекратилось, потому что это путь в никуда, беспомощность, безысходность




 1,3 Мб, 1667x1881
1,3 Мб, 1667x1881Туториал, как раздуть объём исходного кода в два раза, не изменив функционально абсолютно ничего:
https://godbolt.org/z/KnKWhMvoz
Единственное, наверное, только, сделал поддержку паддинга для кастомных форматтеров, потому что внезапно понял, что могу им подсовывать реализацию writerа, которая ничего никуда не пишет, а просто символы считает. Это, чтобы понять, сколько нужно паддинговых символов добавить слева и справа. И, раз теперь паддинг поддерживается всеми форматируемыми значениями, то паддинговые параметры можно было бы сделать общими для всех видов значений и немного упростить код, но их там не получится вытащить на уровень вверх из структур внутри юниона, потому что тогда сломаются шизомакросы, имитирующие именованные аргументы функции. Поэтому сделал просто, чтобы все структуры в юнионе начинались с этих общих параметров, чтобы их можно было доставать, не обращая внимание на реальное содержимое юниона. И, я так понял, что это внезапно даже не будет УБ: https://stackoverflow.com/a/20752261. Типа исключение из всех этих дебильных правил сделали, из-за которых, например, чисто формально через юнион нельзя даже взять флоат и проинтерпретировать его как uint32_t, потому что типа в юнионе хранится именно флоат, а не что-то другое.
Ну и там ещё по мелочи возможность автослива после переносов строк, отделённый слой ОС и поддержка линукс-помойки, правда, через <unistd.h>, то есть она всё равно завязана на сишную библиотеку, но тут похоже иначе никак, дальше только свои врапперы для системных вызовов писать на асемблере https://gist.github.com/tcoppex/443d1dd45f873d96260195d6431b0989.
И новый виток шизы с абстрагированными аллокаторами, чтобы через них writerы создавать, ну потому что, когда начинается полиморфизм, то часто вылезает необходимость выделить объект динамически. Но на стеке тоже можно создать, причём за один стейтмент, без того, чтобы в отдельных переменных создавать буфер и структуру с данными writerа, потому что, как оказалось, в си у компаунд литералов которые "(Struct) {...}" или "(Type[]) {...}" лайфтайм растянут на весь внешний скоуп, то есть можно на них сразу брать указатели и они не протухнут в следующем же стейтменте. https//x.com/mono_morphic/status/1869303586502397994
Была ещё мысль на тему шизомакросов, которые имитируют variadic функции: вместо того, чтобы вычислять размер массива с аргументами через sizeof, сделать его терминированным специальным значением. Просто, если через sizeof делать, то препроцессор, получается, в код дважды вставляет массив, и у меня такое ощущение, что именно из-за вот таких шизомакросов, которые превращаются в кучу кода, у меня clangd периодически тупо отваливается. Плюс некоторым компиляторам становится плохо от пустых массивов-компаунд-литералов, а так эта проблема бы автоматически решилась. Но там, короче, не получится нормально сделать, нужен __VA_OPT__, чтобы убирать лишнюю запятую, когда добавляешь значение-терминал к пустому списку аргументов. Можно было бы ещё положить массив в локальную переменную и потом брать sizeof по её названию, но тогда из макроса нельзя будет ничего вернуть, потому что он раскроется в больше, чем один стейтмент. Вот тут реально была бы полезна фича с возвратом значения из блока кода, как в расте.
Ну, короче, охуеть спасибо за 2к строк говнокода, которые не делают примерно ничего, даже не могут распечатать флоат в консоль, уёбище, блять. А ещё эта срань, оказывается, всё же крашит msvcшный компилятор, если попытаться вывести просто формат строку без аргументов. Ему вроде становится плохо из-за пустого массива в виде компаунд литерала, но как будто оно до этого работало даже с пустыми массивами, просто warning был в одном месте, я как-то пропустил конкретный момент, когда мой код начал ронять компилятор.
Надо, получается, заменить это
(FormatArg[]) {__VA_ARGS__}
на это что ли
(FormatArg[]) {(FormatArg) {}, __VA_ARGS__} + 1
какой же бред, мне лень пересоздавать ссылку на годболт.
1,3 Мб, 1667x1881Туториал, как раздуть объём исходного кода в два раза, не изменив функционально абсолютно ничего:
https://godbolt.org/z/KnKWhMvoz
Единственное, наверное, только, сделал поддержку паддинга для кастомных форматтеров, потому что внезапно понял, что могу им подсовывать реализацию writerа, которая ничего никуда не пишет, а просто символы считает. Это, чтобы понять, сколько нужно паддинговых символов добавить слева и справа. И, раз теперь паддинг поддерживается всеми форматируемыми значениями, то паддинговые параметры можно было бы сделать общими для всех видов значений и немного упростить код, но их там не получится вытащить на уровень вверх из структур внутри юниона, потому что тогда сломаются шизомакросы, имитирующие именованные аргументы функции. Поэтому сделал просто, чтобы все структуры в юнионе начинались с этих общих параметров, чтобы их можно было доставать, не обращая внимание на реальное содержимое юниона. И, я так понял, что это внезапно даже не будет УБ: https://stackoverflow.com/a/20752261. Типа исключение из всех этих дебильных правил сделали, из-за которых, например, чисто формально через юнион нельзя даже взять флоат и проинтерпретировать его как uint32_t, потому что типа в юнионе хранится именно флоат, а не что-то другое.
Ну и там ещё по мелочи возможность автослива после переносов строк, отделённый слой ОС и поддержка линукс-помойки, правда, через <unistd.h>, то есть она всё равно завязана на сишную библиотеку, но тут похоже иначе никак, дальше только свои врапперы для системных вызовов писать на асемблере https://gist.github.com/tcoppex/443d1dd45f873d96260195d6431b0989.
И новый виток шизы с абстрагированными аллокаторами, чтобы через них writerы создавать, ну потому что, когда начинается полиморфизм, то часто вылезает необходимость выделить объект динамически. Но на стеке тоже можно создать, причём за один стейтмент, без того, чтобы в отдельных переменных создавать буфер и структуру с данными writerа, потому что, как оказалось, в си у компаунд литералов которые "(Struct) {...}" или "(Type[]) {...}" лайфтайм растянут на весь внешний скоуп, то есть можно на них сразу брать указатели и они не протухнут в следующем же стейтменте. https//x.com/mono_morphic/status/1869303586502397994
Была ещё мысль на тему шизомакросов, которые имитируют variadic функции: вместо того, чтобы вычислять размер массива с аргументами через sizeof, сделать его терминированным специальным значением. Просто, если через sizeof делать, то препроцессор, получается, в код дважды вставляет массив, и у меня такое ощущение, что именно из-за вот таких шизомакросов, которые превращаются в кучу кода, у меня clangd периодически тупо отваливается. Плюс некоторым компиляторам становится плохо от пустых массивов-компаунд-литералов, а так эта проблема бы автоматически решилась. Но там, короче, не получится нормально сделать, нужен __VA_OPT__, чтобы убирать лишнюю запятую, когда добавляешь значение-терминал к пустому списку аргументов. Можно было бы ещё положить массив в локальную переменную и потом брать sizeof по её названию, но тогда из макроса нельзя будет ничего вернуть, потому что он раскроется в больше, чем один стейтмент. Вот тут реально была бы полезна фича с возвратом значения из блока кода, как в расте.
Ну, короче, охуеть спасибо за 2к строк говнокода, которые не делают примерно ничего, даже не могут распечатать флоат в консоль, уёбище, блять. А ещё эта срань, оказывается, всё же крашит msvcшный компилятор, если попытаться вывести просто формат строку без аргументов. Ему вроде становится плохо из-за пустого массива в виде компаунд литерала, но как будто оно до этого работало даже с пустыми массивами, просто warning был в одном месте, я как-то пропустил конкретный момент, когда мой код начал ронять компилятор.
Надо, получается, заменить это
(FormatArg[]) {__VA_ARGS__}
на это что ли
(FormatArg[]) {(FormatArg) {}, __VA_ARGS__} + 1
какой же бред, мне лень пересоздавать ссылку на годболт.
 1,2 Мб, 2508x3185
1,2 Мб, 2508x3185Я всё же почитал чужой код https://github.com/ennorehling/dlmalloc/blob/master/malloc.c, потому что в прошлый раз не додумался, как нормально реализовать некоторые детали, только исходя из написанного здесь https://sourceware.org/glibc/wiki/MallocInternals, ну и, короче, начал писать примерно ровно то же самое.
Конкретно, например, я не додумался до того, чтобы при разделении куска памяти, полученного от ОС, на чанки всегда иметь в конце два маленьких чанка (которые никогда ни для чего не используются), чтобы было безопасно смотреть на два чанка вперёд. Смотреть вперёд нужно при освобождении чанка, чтобы проверить, можно ли объединиться со следующим. А на два вперёд, потому что в хедере чанка хранится не то, является ли он сам занятым или свободным, а то, свободен ли чанк перед ним. А это, в свою очередь, нужно, чтобы проверять, можно ли объединиться с предыдущим чанком. И если всё так организовать, то boundary теги с размером предыдущего чанка можно хранить в самом предыдущем чанке только, когда он свободен, потому что иначе нам не надо в него лезть.
Вот, а я вроде бы изначально в чанках хранил то, являются ли они сами свободными, из-за чего приходилось также хранить размер предыдущего чанка в хедерах, чтобы можно было перейти к хедеру предыдущего чанка и там посмотреть, свободен он или занят. А это в два раза больший оверхед.
В маллоке есть бины - это связные списки из свободных чанков примерно одинакового размера нужные, чтобы быстрее находить best-fit чанк при выделении памяти. Они обязательно должны быть двусвязными, чтобы мы могли удалять из них элементы, имея на руках только лишь указатель на удаляемый элемент. Хаки вроде такого https://en.wikipedia.org/wiki/XOR_linked_list максимум позволяют итерироваться в обе стороны, и то, только начиная с конца или начала списка. Короче, всё же придётся хранить оба указателя отдельно, это понятно.
Но ещё одна проблема в том, что когда удаляешь чанк из бина, то ты не знаешь точно, из какого конкретно бина тебе нужно его убрать. А если ты сами бины хранишь как "указатель на первый и указатель последний элементы", то тебе это знать необходимо, чтобы обновить эти указатели, когда удаляется первый или последний элемент. Можно определить конкретный бин по размеру чанка, но это немного криво получается, потому что есть особый unsorted бин, в котором хранятся чанки каких угодно размеров, и приходится проверять, является ли удаляемый чанк первым/последним как в этом unsorted бине, так и в бине под размер удаляемого чанка.
Более общее решение, до которого я бы не додумался - это хранить в голове связного списка головной dummy элемент, а сам список сделать циклическим. И этот головной элемент сам будет представлять весь список. Изначально пустой список - это головной элемент, зацикленный сам на себя. Если список непустой, то первый элемент - это head->next, а последний - это head->prev. И в таком списке получается, что удаление первого или последнего элементов никак не отличается от удаления элемента из середины списка. Наверное, это какой-то дефолтный трюк, но я его в первый раз только тут увидел.
Конкретно в контексте бинов из dlmalloc тут ещё проблема, что указатели prev/next указывают на хедеры у чанков, а не на то, где начинается payload чанка, где и хранятся указатели prev/next. Из-за чего, выходит, головные элементы в бинах должны хранить в себе бесполезный хедер, чтобы не отличаться от остальных элементов списка. Можно было бы, наверное, сделать, чтобы prev/next всё же ссылались на payload после хедера. В dlmalloc же сделано так, что головные элементы бинов упакованы так, что по сути накладываются друг на друга, чтобы не тратить память на бесполезные хедеры.
Что я ещё хотел посмотреть - это то, как dlmalloc менеджит куски памяти, полученные от ОС, но, короче, никак. Под линуксом он выделяет память из кучи - это один вроде бы непрерывный кусок памяти, который есть у каждого процесса, который можно растягивать или сжимать вызовами sbrk. И dlmalloc просто кладёт один специальный чанк в конец кучи и при необходимости его растягивает, если надо запросить больше памяти у ОС, и откусывает память из его начала, если не нашлось ни одного более подходящего чанка. Проблема в том, что в винде, например, нет аналога sbrk, поэтому его приходится эмулировать через VirtualQuery, но полноценно повторить поведение sbrk не получится, потому что при попытке расширения куска памяти мы можем наткнуться на уже занятый кем-то регион. Ну, хотя, наверное, можно было бы изначально найти адрес, с которого начинается незанятый регион на достаточно много гигабайтов, не знаю, но, в общем, в dlmalloc вместо этого сделано так, что он каждый раз проверяет, действительно ли sbrk возвращает непрерывный кусок памяти, и если нет, то он просто забивает на отслеживание памяти, которую навыделял до этого (в том плане, что он её ещё может переиспользовать, потому что он уже разделил её на чанки, но уже не сможет вернуть обратно системе).
Эта проблема с не-непрерывным sbrk может возникнуть в том числе и на линуксе, если кто-то другой одновременно с dlmalloc трогает sbrk (например, другой аллокатор, который тоже из кучи берёт память), и в том числе может не только расширить кучу, но и сжать её. И куча одна на весь процесс, поэтому в многопоточном сценарии мы не сможем создать по одному инстансу dlmalloc на каждый поток, придётся запихивать один инстанс под мутекс, иначе куча будет постепенно только увеличиваться и увеличиваться (из-за того, что с точки зрения каждого отдельного инстанса, sbrk будет возвращать не-непрерывные адреса). В современном маллоке сделали умнее, там куча всё ещё используется как источник памяти, но также используются mmap-нутые "кучи". В dlmalloc mmap тоже используется, но только, если мы просим у него достаточно большой кусок памяти, он в этом случае выделяет его напрямую через mmap и потом, когда мы возвращаем память обратно, он сразу же его отдаёт системе без попытки переиспользовать.
Не особо понимаю, если честно, всех эвристик, которые используются в маллоке. Это best-fit аллоктор, который как будто в большей мере озабочен уменьшением фрагментации памяти, чем кеш локальностью или скоростью работы. Обычно он пытается eagerly совмещать вместе соседние свободные чанки, исключение - совсем мелкие чанки, которые при особождении помещаются в "фаст" бины, ни с кем не объединяются и потом могут сразу снова пойти в использование. Но фаст бины долго не живут: если следующий запрос на выделение памяти большой, то все чанки из фаст бинов объединяются. Типа расчёт на то, что деаллокации мелких кусков памяти соседствуют с аллокацией таких же мелких кусочков.
Если при аллокации выбор из нескольких чанков одного размера, то берётся LRU, слышал, что это типа тоже для борьбы с фрагментацией: если достаточно долго маринуем чанк в свободном состоянии, то больше вероятность, что соседние с ним тоже освободятся и смогут объединиться с ним.
На тему кеш локальности вроде есть только то, что если нам при аллокации пришлось откусить кусок от чанка, то при следующей аллокации мы возможно попробуем сделать укус от этого же чанка. Иными словами, есть вероятность, что последовательные мелкие аллокации будут соседствовать друг с другом.
Да, короче, блять, похуй, в итоге я даже не дописал до конца, причём, ну, я пытался в этот раз, но я слишком тупой, это не проблема концентрации или лени, я просто умственно отсталое всратое уёбище, мне каждый раз хуёво становится, когда случайно смотрю в зеркало, а потом меня добивает осознание собственной тупости и хочется очень сильно повеситься нахуй. Там единственная неукраденная и хотя бы немного интересная идея - это хранить структуру с состоянием аллокатора внутри обычного чанка, а не выделять её как-то отдельно. Но это типа очевидно, наверное, примерно аналогичная по духу идея, как то, что в том принтф велосипеде репортинг ошибок сделан через сам принтф велосипед. Но там не получилось сделать прямо в полной мере через него, потому что я зачем-то хотел сделать реализацию компилируемой через плюсовый компилятор, а в плюсах нет компаунд литералов, через которые работают все шизомакросы для форматированного вывода.
1,2 Мб, 2508x3185Я всё же почитал чужой код https://github.com/ennorehling/dlmalloc/blob/master/malloc.c, потому что в прошлый раз не додумался, как нормально реализовать некоторые детали, только исходя из написанного здесь https://sourceware.org/glibc/wiki/MallocInternals, ну и, короче, начал писать примерно ровно то же самое.
Конкретно, например, я не додумался до того, чтобы при разделении куска памяти, полученного от ОС, на чанки всегда иметь в конце два маленьких чанка (которые никогда ни для чего не используются), чтобы было безопасно смотреть на два чанка вперёд. Смотреть вперёд нужно при освобождении чанка, чтобы проверить, можно ли объединиться со следующим. А на два вперёд, потому что в хедере чанка хранится не то, является ли он сам занятым или свободным, а то, свободен ли чанк перед ним. А это, в свою очередь, нужно, чтобы проверять, можно ли объединиться с предыдущим чанком. И если всё так организовать, то boundary теги с размером предыдущего чанка можно хранить в самом предыдущем чанке только, когда он свободен, потому что иначе нам не надо в него лезть.
Вот, а я вроде бы изначально в чанках хранил то, являются ли они сами свободными, из-за чего приходилось также хранить размер предыдущего чанка в хедерах, чтобы можно было перейти к хедеру предыдущего чанка и там посмотреть, свободен он или занят. А это в два раза больший оверхед.
В маллоке есть бины - это связные списки из свободных чанков примерно одинакового размера нужные, чтобы быстрее находить best-fit чанк при выделении памяти. Они обязательно должны быть двусвязными, чтобы мы могли удалять из них элементы, имея на руках только лишь указатель на удаляемый элемент. Хаки вроде такого https://en.wikipedia.org/wiki/XOR_linked_list максимум позволяют итерироваться в обе стороны, и то, только начиная с конца или начала списка. Короче, всё же придётся хранить оба указателя отдельно, это понятно.
Но ещё одна проблема в том, что когда удаляешь чанк из бина, то ты не знаешь точно, из какого конкретно бина тебе нужно его убрать. А если ты сами бины хранишь как "указатель на первый и указатель последний элементы", то тебе это знать необходимо, чтобы обновить эти указатели, когда удаляется первый или последний элемент. Можно определить конкретный бин по размеру чанка, но это немного криво получается, потому что есть особый unsorted бин, в котором хранятся чанки каких угодно размеров, и приходится проверять, является ли удаляемый чанк первым/последним как в этом unsorted бине, так и в бине под размер удаляемого чанка.
Более общее решение, до которого я бы не додумался - это хранить в голове связного списка головной dummy элемент, а сам список сделать циклическим. И этот головной элемент сам будет представлять весь список. Изначально пустой список - это головной элемент, зацикленный сам на себя. Если список непустой, то первый элемент - это head->next, а последний - это head->prev. И в таком списке получается, что удаление первого или последнего элементов никак не отличается от удаления элемента из середины списка. Наверное, это какой-то дефолтный трюк, но я его в первый раз только тут увидел.
Конкретно в контексте бинов из dlmalloc тут ещё проблема, что указатели prev/next указывают на хедеры у чанков, а не на то, где начинается payload чанка, где и хранятся указатели prev/next. Из-за чего, выходит, головные элементы в бинах должны хранить в себе бесполезный хедер, чтобы не отличаться от остальных элементов списка. Можно было бы, наверное, сделать, чтобы prev/next всё же ссылались на payload после хедера. В dlmalloc же сделано так, что головные элементы бинов упакованы так, что по сути накладываются друг на друга, чтобы не тратить память на бесполезные хедеры.
Что я ещё хотел посмотреть - это то, как dlmalloc менеджит куски памяти, полученные от ОС, но, короче, никак. Под линуксом он выделяет память из кучи - это один вроде бы непрерывный кусок памяти, который есть у каждого процесса, который можно растягивать или сжимать вызовами sbrk. И dlmalloc просто кладёт один специальный чанк в конец кучи и при необходимости его растягивает, если надо запросить больше памяти у ОС, и откусывает память из его начала, если не нашлось ни одного более подходящего чанка. Проблема в том, что в винде, например, нет аналога sbrk, поэтому его приходится эмулировать через VirtualQuery, но полноценно повторить поведение sbrk не получится, потому что при попытке расширения куска памяти мы можем наткнуться на уже занятый кем-то регион. Ну, хотя, наверное, можно было бы изначально найти адрес, с которого начинается незанятый регион на достаточно много гигабайтов, не знаю, но, в общем, в dlmalloc вместо этого сделано так, что он каждый раз проверяет, действительно ли sbrk возвращает непрерывный кусок памяти, и если нет, то он просто забивает на отслеживание памяти, которую навыделял до этого (в том плане, что он её ещё может переиспользовать, потому что он уже разделил её на чанки, но уже не сможет вернуть обратно системе).
Эта проблема с не-непрерывным sbrk может возникнуть в том числе и на линуксе, если кто-то другой одновременно с dlmalloc трогает sbrk (например, другой аллокатор, который тоже из кучи берёт память), и в том числе может не только расширить кучу, но и сжать её. И куча одна на весь процесс, поэтому в многопоточном сценарии мы не сможем создать по одному инстансу dlmalloc на каждый поток, придётся запихивать один инстанс под мутекс, иначе куча будет постепенно только увеличиваться и увеличиваться (из-за того, что с точки зрения каждого отдельного инстанса, sbrk будет возвращать не-непрерывные адреса). В современном маллоке сделали умнее, там куча всё ещё используется как источник памяти, но также используются mmap-нутые "кучи". В dlmalloc mmap тоже используется, но только, если мы просим у него достаточно большой кусок памяти, он в этом случае выделяет его напрямую через mmap и потом, когда мы возвращаем память обратно, он сразу же его отдаёт системе без попытки переиспользовать.
Не особо понимаю, если честно, всех эвристик, которые используются в маллоке. Это best-fit аллоктор, который как будто в большей мере озабочен уменьшением фрагментации памяти, чем кеш локальностью или скоростью работы. Обычно он пытается eagerly совмещать вместе соседние свободные чанки, исключение - совсем мелкие чанки, которые при особождении помещаются в "фаст" бины, ни с кем не объединяются и потом могут сразу снова пойти в использование. Но фаст бины долго не живут: если следующий запрос на выделение памяти большой, то все чанки из фаст бинов объединяются. Типа расчёт на то, что деаллокации мелких кусков памяти соседствуют с аллокацией таких же мелких кусочков.
Если при аллокации выбор из нескольких чанков одного размера, то берётся LRU, слышал, что это типа тоже для борьбы с фрагментацией: если достаточно долго маринуем чанк в свободном состоянии, то больше вероятность, что соседние с ним тоже освободятся и смогут объединиться с ним.
На тему кеш локальности вроде есть только то, что если нам при аллокации пришлось откусить кусок от чанка, то при следующей аллокации мы возможно попробуем сделать укус от этого же чанка. Иными словами, есть вероятность, что последовательные мелкие аллокации будут соседствовать друг с другом.
Да, короче, блять, похуй, в итоге я даже не дописал до конца, причём, ну, я пытался в этот раз, но я слишком тупой, это не проблема концентрации или лени, я просто умственно отсталое всратое уёбище, мне каждый раз хуёво становится, когда случайно смотрю в зеркало, а потом меня добивает осознание собственной тупости и хочется очень сильно повеситься нахуй. Там единственная неукраденная и хотя бы немного интересная идея - это хранить структуру с состоянием аллокатора внутри обычного чанка, а не выделять её как-то отдельно. Но это типа очевидно, наверное, примерно аналогичная по духу идея, как то, что в том принтф велосипеде репортинг ошибок сделан через сам принтф велосипед. Но там не получилось сделать прямо в полной мере через него, потому что я зачем-то хотел сделать реализацию компилируемой через плюсовый компилятор, а в плюсах нет компаунд литералов, через которые работают все шизомакросы для форматированного вывода.



Не уверен, что нормально написал, скорее всего, нет, потому что у меня вылезали рандомные ошибки при запуске, похожие на какую-то гонку:
X Error of failed request: BadAccess (attempt to access private resource denied)
Major opcode of failed request: 130 (MIT-SHM)
Minor opcode of failed request: 1 (X_ShmAttach)
Как будто они возникают из-за того, что тайловый оконный менеджер моментально сразу после создания окна и выделения картинки под него снапает окно на своё место в сетке, после чего размер окна меняется, что вызывает пересоздание картинки. Я не знаю, видимо, какие-то вызовы функций из Xlib отправляют асинхронные запросы и получается так, что иксы трогают пошаренную картинку одновременно с тем, как я её пересоздаю. Например, нельзя трогать память картинки сразу после вызова XShmPutImage, нужно дождаться, пока иксы её отрисуют, но я типа учитываю это (рисую в другую картинку, пока только что отправленная на отрисовку недоступна). А может ли подобное происходить с другими функциями, в документации не сказано.
Ошибка вроде исчезает, если изначально при создании окна не создавать под него картинку, или если поменять порядок действий: создание картинок и вывод окна на экран (XMapWindow), но я просто не вижу логики никакой в этих действиях, и не гуглится ничего, кроме советов вообще отключить это расширение. Да и в целом в иксах и этом расширении ничего не понятно, максимально непонятное апи, MIT-SHM прибит гвоздями к какому-то упоротому старому способу создания расшаренной между процессами памяти (shmget/shmctl/shmat/shmdt), может быть, я и его тоже как-то неправильно использую. Может быть, мне стоило использовать XCB - это по сути то же самое, что Xlib (сишное апи, чтобы низкоуровнево говорить с иксовым сервером), но вроде как там что-то что-то он лучше дружит с многопоточностью, но у меня моё приложение-то однопоточное, поэтому не уверен, что это помогло бы, потому что XInitThreads(), кстати, не помогает.
Ещё абсолютно не понял, в чём смысл этих каких-то кнопочных символов, зачем они, если есть кнопочные коды. Типа вроде символы учитывают раскладку клавиатуры, а коды - это физические кнопки на клавиатуре. При обработке событий ты получаешь коды, но для них нет констант как на винде (VK_KEY_UP, например), но есть константы для символов с обычной клавиатуры, поэтому типа надо установить соответствие между константами символов и кодами (через XKeysymToKeycode), чтобы понять, во что мапить коды? Из кода GLFW на эту тему https://github.com/glfw/glfw/blob/master/src/x11_init.c я не понял вообще ничего, сам написал какой-то бред. Я понимаю, что иксы не прошли проверку временем, но я тупо даже в теории не понимаю, зачем оно так запутанно сделано, в чём смысл этих абстракций над кнопками.
Ну типа такого, короче https://gist.github.com/poppyfanboy/8f81ca0fd36f1f4e7e74b069b8ffe5a1 И для винды код немного упростил, который у меня был, я изначально там зачем-то городил свою SPSC очередь, чтобы передавать события от потока, куда они приходят, к потоку, где делается рендер и обрабатываются события. Но как будто можно обработку событий впихнуть туда же, куда они приходят. И ещё не знаю, есть ли смысл на винде тоже делать две битмапы, я не особо понимаю, можно ли трогать память битмапы сразу после вызова BitBlt.
А шум этот - случайно нашёл, какой-то "ромбо-квадратный алгоритм". Он выглядит как фрактальный шум, где независимо друг от друга генерируются несколько октав и накладываются друг на друга, но тут все пиксели генерируются за один проход по каждому из них. Типа идея в том, что пиксели проходятся по сетке, которая со временем становится мельче и мельче. Значения генерируются из усреднения соседних пикселей на сетке + рандом. И чем мельче сетка, тем меньше рандома и больше играет роль интерполяция соседних пикселей, поэтому возникает вот этот эффект с локальной плюс-минус гладкостью, но с наличием более глобальных перепадов высот. Тайлится просто из-за того, как он генерируется: когда около-граничные пиксели генерируем, то семплим пиксели с противоположной стороны, а сами граничные пиксели делаем одинаковыми с противоположных сторон.
https://learn.64bitdragon.com/articles/computer-science/procedural-generation/the-diamond-square-algorithm
И потом на сгенерированный шум наложен сдвиг по палитре.
Не уверен, что нормально написал, скорее всего, нет, потому что у меня вылезали рандомные ошибки при запуске, похожие на какую-то гонку:
X Error of failed request: BadAccess (attempt to access private resource denied)
Major opcode of failed request: 130 (MIT-SHM)
Minor opcode of failed request: 1 (X_ShmAttach)
Как будто они возникают из-за того, что тайловый оконный менеджер моментально сразу после создания окна и выделения картинки под него снапает окно на своё место в сетке, после чего размер окна меняется, что вызывает пересоздание картинки. Я не знаю, видимо, какие-то вызовы функций из Xlib отправляют асинхронные запросы и получается так, что иксы трогают пошаренную картинку одновременно с тем, как я её пересоздаю. Например, нельзя трогать память картинки сразу после вызова XShmPutImage, нужно дождаться, пока иксы её отрисуют, но я типа учитываю это (рисую в другую картинку, пока только что отправленная на отрисовку недоступна). А может ли подобное происходить с другими функциями, в документации не сказано.
Ошибка вроде исчезает, если изначально при создании окна не создавать под него картинку, или если поменять порядок действий: создание картинок и вывод окна на экран (XMapWindow), но я просто не вижу логики никакой в этих действиях, и не гуглится ничего, кроме советов вообще отключить это расширение. Да и в целом в иксах и этом расширении ничего не понятно, максимально непонятное апи, MIT-SHM прибит гвоздями к какому-то упоротому старому способу создания расшаренной между процессами памяти (shmget/shmctl/shmat/shmdt), может быть, я и его тоже как-то неправильно использую. Может быть, мне стоило использовать XCB - это по сути то же самое, что Xlib (сишное апи, чтобы низкоуровнево говорить с иксовым сервером), но вроде как там что-то что-то он лучше дружит с многопоточностью, но у меня моё приложение-то однопоточное, поэтому не уверен, что это помогло бы, потому что XInitThreads(), кстати, не помогает.
Ещё абсолютно не понял, в чём смысл этих каких-то кнопочных символов, зачем они, если есть кнопочные коды. Типа вроде символы учитывают раскладку клавиатуры, а коды - это физические кнопки на клавиатуре. При обработке событий ты получаешь коды, но для них нет констант как на винде (VK_KEY_UP, например), но есть константы для символов с обычной клавиатуры, поэтому типа надо установить соответствие между константами символов и кодами (через XKeysymToKeycode), чтобы понять, во что мапить коды? Из кода GLFW на эту тему https://github.com/glfw/glfw/blob/master/src/x11_init.c я не понял вообще ничего, сам написал какой-то бред. Я понимаю, что иксы не прошли проверку временем, но я тупо даже в теории не понимаю, зачем оно так запутанно сделано, в чём смысл этих абстракций над кнопками.
Ну типа такого, короче https://gist.github.com/poppyfanboy/8f81ca0fd36f1f4e7e74b069b8ffe5a1 И для винды код немного упростил, который у меня был, я изначально там зачем-то городил свою SPSC очередь, чтобы передавать события от потока, куда они приходят, к потоку, где делается рендер и обрабатываются события. Но как будто можно обработку событий впихнуть туда же, куда они приходят. И ещё не знаю, есть ли смысл на винде тоже делать две битмапы, я не особо понимаю, можно ли трогать память битмапы сразу после вызова BitBlt.
А шум этот - случайно нашёл, какой-то "ромбо-квадратный алгоритм". Он выглядит как фрактальный шум, где независимо друг от друга генерируются несколько октав и накладываются друг на друга, но тут все пиксели генерируются за один проход по каждому из них. Типа идея в том, что пиксели проходятся по сетке, которая со временем становится мельче и мельче. Значения генерируются из усреднения соседних пикселей на сетке + рандом. И чем мельче сетка, тем меньше рандома и больше играет роль интерполяция соседних пикселей, поэтому возникает вот этот эффект с локальной плюс-минус гладкостью, но с наличием более глобальных перепадов высот. Тайлится просто из-за того, как он генерируется: когда около-граничные пиксели генерируем, то семплим пиксели с противоположной стороны, а сами граничные пиксели делаем одинаковыми с противоположных сторон.
https://learn.64bitdragon.com/articles/computer-science/procedural-generation/the-diamond-square-algorithm
И потом на сгенерированный шум наложен сдвиг по палитре.


- Это слишком сильно переусложнит апи: чтобы им пользоваться, придётся специально определять функцию, которая берёт байты от энкодера и куда-то их пишет. А если, предположим, у тебя используются несколько независимых энкодеров, сделанных в стиле такого апи, то тебе придётся делать отдельные такие функции под каждый из них.
- Вылезает вызов функции по указателю, который ничем не оправдан. В нашем одном конкретном применении энкодера мы вряд ли захотим выводить байты гифки в овер девять тыщ различных мест, скорее всего, мы хотим сделать только что-то одно.
- Если мы пишем гифку в буфер в памяти через эту Write прослойку, то, вероятно, получится, что мы будем заниматься бессмысленным перекладыванием байтов: сначала в какой-то внутренний буфер энкодера и только потом в целевой буфер, вместо того, чтобы сразу писать, куда надо.
То есть как будто нельзя адекватно сделать, чтобы энкодер сам куда-то пушил байты, приходится вручную их из него доставать. И это требование как-то очень плохо синергирует с тем, что я бы также не хотел, чтобы у энкодера сразу был доступ ко всем кадрам, которые надо закодировать. То есть нельзя просто загрузить всю информацию для генерации гифки в энкодер за один вызов функции и потом тупо прочитать все байты гифки из него. Приходится делать вперемешку добавление новых кадров и вытягивание закодированных байтов, и всё превращается в какую-то стейт машиновую жижу, где тебе надо в каком-то чётко определённом порядке делать операции над энкодером, а иначе всё сломается. И либо делать рантаймовые проверки корректности внутреннего состояния энкодера и выводить ошибки при включённом дебаг режиме, либо вообще, видимо, лучше просто забить на какую-либо валидацию, потому что это бессмысленная духота и ты сам виноват, если неправильно используешь энкодер.
Ну просто банально можно по ошибке неполностью прочитать все закодированные байты (решив, что можно сначала вызвать gif_encoder_next_frame для всех кадров, а потом вытащить все закодированные байты для них) или в неправильный момент вызвать какую-то функцию, которая передаёт какие-то опциональные данные, вроде локальной для кадра таблицы цветов.
В расте я видел бредовый вариант решения этой проблемы - наплодить отдельных типов на каждое состояние структуры (через генерик параметр, в который записывается какой-то маркерный тип, обозначающий состояние) и под каждый тип-состояние имплементить только те методы-действия, которые можно сделать в текущем состоянии. Ну вроде такого:
> impl Encoder<Start> {
> ・・fn set_size(self, width: isize, height: isize) -> Encoder<HeaderDataRead> { ... }
> }
>
> impl Encoder<HeaderDataRead> {
> ・・fn pull_header(self, buffer: &mut [u8]) -> Encoder<ReadyForFrames> { ... }
> }
>
> impl Encoder<ReadyForFrames> {
> ・・fn add_frame(self, frame: &[u32]) -> Encoder<FrameDataRead> { ... }
> ・・fn finish_adding_frames(self) -> Encoder<AllFramesPulled> { ... }
> }
>
> impl Encoder<FrameDataRead> {
> ・・fn pull_frame(self, buffer: &mut [u8]) -> Encoder<ReadyForFrames> { ... }
> }
>
> impl Encoder<AllFramesPulled> {
> ・・fn pull_trailer(self, buffer: &mut [u8]) -> Encoder<Finish> { ... }
> }
https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=fa12a467aeb2cf50d44845ad462fc20a
То есть тут нельзя сразу попытаться вытащить байты трейлера гифки из Encoder<Start> или попытаться несколько раз подряд вызвать add_frame, оно тупо не скомпилится.
Но это работает кое-как только, если мы знаем в компайл-тайме, где происходят переходы между состояниями, ну то есть, если у нас реально конечный автомат, а в случае с энкодером гифок, например, переход от состояния "читаю переданный мне кадр, отдаю закодированные байты" к состоянию "готов начать принять следующий кадр" происходит непонятно когда, если мы читаем закодированные байты не за один раз, а в несколько подходов.
И этот подход ещё ограничивает то, в какой последовательности можно делать действия: тут не получится вызвать методы в такой последовательности: set_size, add_frame, pull_header, pull_frame, хотя по логике в этом нет проблем. Ну либо удачи добавить миллиард дополнительных возможных состояний, чтобы так всё же можно было делать.
Ну и плюс оно даже в расте адски уродливо выглядит: там придётся постоянно копировать данные внутри энкодера между этими разными типами-состояниями, то есть их придётся в Box запихать. И постоянное переобъявление переменной encoder выглядит шизово (а оно тут необходимо, потому что тип переменной encoder меняется каждый раз) и очень плохо сочетается с циклом for, например. Короче, это только на каких-то игрушечных примерах выглядит как что-то работающее.
У меня есть в голове ещё другая идея, как можно было бы сделать ещё: типа в каком-то смысле инвертировать контроль, чтобы энкодер просил от тебя совершить какие-то действия, например, "дай мне размер гифки", "дай мне глобальную таблицу цветов", "дай мне следующий кадр", "читай из меня закодированные байты", и чтобы у тебя была возможность ответить "ок, вот тебе следующий кадр" или там "нет, не буду давать тебе таблицу цветов, сам разбирайся". Типа код, пользующийся энкодером, будет выглядеть примерно как window procedure из win32, но это окончательно просто шизофрения.
Ну, короче, в итоге я ничего не сделал по сути за сегодня, кроме этой ментальной мастурбации.
- Это слишком сильно переусложнит апи: чтобы им пользоваться, придётся специально определять функцию, которая берёт байты от энкодера и куда-то их пишет. А если, предположим, у тебя используются несколько независимых энкодеров, сделанных в стиле такого апи, то тебе придётся делать отдельные такие функции под каждый из них.
- Вылезает вызов функции по указателю, который ничем не оправдан. В нашем одном конкретном применении энкодера мы вряд ли захотим выводить байты гифки в овер девять тыщ различных мест, скорее всего, мы хотим сделать только что-то одно.
- Если мы пишем гифку в буфер в памяти через эту Write прослойку, то, вероятно, получится, что мы будем заниматься бессмысленным перекладыванием байтов: сначала в какой-то внутренний буфер энкодера и только потом в целевой буфер, вместо того, чтобы сразу писать, куда надо.
То есть как будто нельзя адекватно сделать, чтобы энкодер сам куда-то пушил байты, приходится вручную их из него доставать. И это требование как-то очень плохо синергирует с тем, что я бы также не хотел, чтобы у энкодера сразу был доступ ко всем кадрам, которые надо закодировать. То есть нельзя просто загрузить всю информацию для генерации гифки в энкодер за один вызов функции и потом тупо прочитать все байты гифки из него. Приходится делать вперемешку добавление новых кадров и вытягивание закодированных байтов, и всё превращается в какую-то стейт машиновую жижу, где тебе надо в каком-то чётко определённом порядке делать операции над энкодером, а иначе всё сломается. И либо делать рантаймовые проверки корректности внутреннего состояния энкодера и выводить ошибки при включённом дебаг режиме, либо вообще, видимо, лучше просто забить на какую-либо валидацию, потому что это бессмысленная духота и ты сам виноват, если неправильно используешь энкодер.
Ну просто банально можно по ошибке неполностью прочитать все закодированные байты (решив, что можно сначала вызвать gif_encoder_next_frame для всех кадров, а потом вытащить все закодированные байты для них) или в неправильный момент вызвать какую-то функцию, которая передаёт какие-то опциональные данные, вроде локальной для кадра таблицы цветов.
В расте я видел бредовый вариант решения этой проблемы - наплодить отдельных типов на каждое состояние структуры (через генерик параметр, в который записывается какой-то маркерный тип, обозначающий состояние) и под каждый тип-состояние имплементить только те методы-действия, которые можно сделать в текущем состоянии. Ну вроде такого:
> impl Encoder<Start> {
> ・・fn set_size(self, width: isize, height: isize) -> Encoder<HeaderDataRead> { ... }
> }
>
> impl Encoder<HeaderDataRead> {
> ・・fn pull_header(self, buffer: &mut [u8]) -> Encoder<ReadyForFrames> { ... }
> }
>
> impl Encoder<ReadyForFrames> {
> ・・fn add_frame(self, frame: &[u32]) -> Encoder<FrameDataRead> { ... }
> ・・fn finish_adding_frames(self) -> Encoder<AllFramesPulled> { ... }
> }
>
> impl Encoder<FrameDataRead> {
> ・・fn pull_frame(self, buffer: &mut [u8]) -> Encoder<ReadyForFrames> { ... }
> }
>
> impl Encoder<AllFramesPulled> {
> ・・fn pull_trailer(self, buffer: &mut [u8]) -> Encoder<Finish> { ... }
> }
https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=fa12a467aeb2cf50d44845ad462fc20a
То есть тут нельзя сразу попытаться вытащить байты трейлера гифки из Encoder<Start> или попытаться несколько раз подряд вызвать add_frame, оно тупо не скомпилится.
Но это работает кое-как только, если мы знаем в компайл-тайме, где происходят переходы между состояниями, ну то есть, если у нас реально конечный автомат, а в случае с энкодером гифок, например, переход от состояния "читаю переданный мне кадр, отдаю закодированные байты" к состоянию "готов начать принять следующий кадр" происходит непонятно когда, если мы читаем закодированные байты не за один раз, а в несколько подходов.
И этот подход ещё ограничивает то, в какой последовательности можно делать действия: тут не получится вызвать методы в такой последовательности: set_size, add_frame, pull_header, pull_frame, хотя по логике в этом нет проблем. Ну либо удачи добавить миллиард дополнительных возможных состояний, чтобы так всё же можно было делать.
Ну и плюс оно даже в расте адски уродливо выглядит: там придётся постоянно копировать данные внутри энкодера между этими разными типами-состояниями, то есть их придётся в Box запихать. И постоянное переобъявление переменной encoder выглядит шизово (а оно тут необходимо, потому что тип переменной encoder меняется каждый раз) и очень плохо сочетается с циклом for, например. Короче, это только на каких-то игрушечных примерах выглядит как что-то работающее.
У меня есть в голове ещё другая идея, как можно было бы сделать ещё: типа в каком-то смысле инвертировать контроль, чтобы энкодер просил от тебя совершить какие-то действия, например, "дай мне размер гифки", "дай мне глобальную таблицу цветов", "дай мне следующий кадр", "читай из меня закодированные байты", и чтобы у тебя была возможность ответить "ок, вот тебе следующий кадр" или там "нет, не буду давать тебе таблицу цветов, сам разбирайся". Типа код, пользующийся энкодером, будет выглядеть примерно как window procedure из win32, но это окончательно просто шизофрения.
Ну, короче, в итоге я ничего не сделал по сути за сегодня, кроме этой ментальной мастурбации.


Первый раз попробовал гццшный санитайзер, потому что в один момент оказался слишком сильно фрустрирован тем, что ничего не получается, и он помог найти банальный баг с умножением вместительности массива в два раза, при том, что она изначально ноль, и обругать меня за утечки памяти, на которые мне всё равно, но на деле основная ошибка оказалась логической: в гифках закодированные данные картинки подразделяются на более мелкие блоки с максимальным размером 255 байт и я почему-то подумал, что LZW коды НЕ могут быть размазаны между двумя блоками данных, а оказалось, что могут, и надо наполнять блоки битами прямо до краёв указанных размеров.
Санитайзер, кстати, оказался не супер какой-то панацеей, не знаю, как он работает, но даже за это непродолжительное использование попалась ситуация, где он не отследил выход за границы массива. Вроде бы там массив был на стеке аллоцирован внутри структуры и я случайно залез в другие поля этой же структуры, получается, вряд ли такое можно нормально отследить подобными автоматическими инструментами.



Сейчас снова попробовал просто сесть и наблевать говнокодом, лишь бы что-то получилось, потратил где-то 4 часа, чтобы заставить работать энкодинг с фиксированной таблицей цветов для произвольной картинки, результат - пикрил 3, который, надеюсь, всё же загрузится сюда. Но, во-первых, получается, очевидно, говнокод, а, во-вторых, всё равно в итоге мозг расплавлен даже от 4 часов попыток его применять, всё, я ничего не могу, я реально уже смысла жить не вижу никакого, ну, серьёзно, я не могу перестать думать о том, что мне надо нахуй уже умереть, ну вот, например, я вчера услышал случайно "деление через умножение", загуглил, я бы в жизни до такого не додумался https://board.flatassembler.net/topic.php?t=20938 какие-то п-адические числа, про которые я так никогда и не почитал, при этом я уверен, что каждый человек знает всё это, и это то, что происходит на регулярной основе.
Как оказалось, необязательно сбрасывать LZW таблицу, когда она переполняется, энкодер может просто продолжить выдавать коды максимальной длины (которая всего лишь 12 бит). Непонятно, короче, когда лучше таблицу сбрасывать, но если вообще этого не делать, то пикрил 3 получается раз в 7 более жирным, чем если сбрасывать каждый раз при переполнении, ну тут потому что таблица, заполненная паттернами, полученными в небе, вообще не актуальна, когда доходим до травы, там с ней околонулевое сжатие будет.
Первый раз попробовал gdb из консоли, короче, этим примерно невозможно пользоваться, постоянно глючит этот tui режим, шизовый синтаксис команд (p/x - вывести значение в хексе, 🞰array@length - вывести по указателю несколько значений, кто это выдумал), сидишь, пальцы ломаешь об клавиатуру, чтобы просто брейкпоинт поставить и убрать его вместо того, чтобы просто мышкой нажать рядом со строкой кода.
>>777426
>банальный баг с умножением вместительности массива в два раза, при том, что она изначально ноль
Кстати, спасибо большое glibc за то, что malloc(0) зачем-то выделяет память и возвращает валидный указатель, по которому я могу ошибочно начать спокойно что-то писать, вместо того, чтобы просто вернуть 0, чтобы всё упало с сегфолтом, реально тупо компилируемый джаваскрипт
>>773703
>Если мы пишем гифку в буфер в памяти через эту Write прослойку, то, вероятно, получится, что мы будем заниматься бессмысленным перекладыванием байтов
Ну, кстати, я не додумался, но этот момент всё же можно обойти, как этот чел: https://lists.sr.ht/~skeeto/public-inbox/%3Cane2ee7fpnyn3qxslygprmjw2yrvzppxuim25jvf7e6f5jgxbd@p7y6own2j3it%3E
То есть не делать в этом полиморфном интерфейсе в принципе никакого write, только flush. Вместо вызовов write писать в свой внутренний буфер. Если пишем в файл, то flush делает запись в файл и очищает буфер, если пишем в память, то flush расширяет буфер.
Сейчас снова попробовал просто сесть и наблевать говнокодом, лишь бы что-то получилось, потратил где-то 4 часа, чтобы заставить работать энкодинг с фиксированной таблицей цветов для произвольной картинки, результат - пикрил 3, который, надеюсь, всё же загрузится сюда. Но, во-первых, получается, очевидно, говнокод, а, во-вторых, всё равно в итоге мозг расплавлен даже от 4 часов попыток его применять, всё, я ничего не могу, я реально уже смысла жить не вижу никакого, ну, серьёзно, я не могу перестать думать о том, что мне надо нахуй уже умереть, ну вот, например, я вчера услышал случайно "деление через умножение", загуглил, я бы в жизни до такого не додумался https://board.flatassembler.net/topic.php?t=20938 какие-то п-адические числа, про которые я так никогда и не почитал, при этом я уверен, что каждый человек знает всё это, и это то, что происходит на регулярной основе.
Как оказалось, необязательно сбрасывать LZW таблицу, когда она переполняется, энкодер может просто продолжить выдавать коды максимальной длины (которая всего лишь 12 бит). Непонятно, короче, когда лучше таблицу сбрасывать, но если вообще этого не делать, то пикрил 3 получается раз в 7 более жирным, чем если сбрасывать каждый раз при переполнении, ну тут потому что таблица, заполненная паттернами, полученными в небе, вообще не актуальна, когда доходим до травы, там с ней околонулевое сжатие будет.
Первый раз попробовал gdb из консоли, короче, этим примерно невозможно пользоваться, постоянно глючит этот tui режим, шизовый синтаксис команд (p/x - вывести значение в хексе, 🞰array@length - вывести по указателю несколько значений, кто это выдумал), сидишь, пальцы ломаешь об клавиатуру, чтобы просто брейкпоинт поставить и убрать его вместо того, чтобы просто мышкой нажать рядом со строкой кода.
>>777426
>банальный баг с умножением вместительности массива в два раза, при том, что она изначально ноль
Кстати, спасибо большое glibc за то, что malloc(0) зачем-то выделяет память и возвращает валидный указатель, по которому я могу ошибочно начать спокойно что-то писать, вместо того, чтобы просто вернуть 0, чтобы всё упало с сегфолтом, реально тупо компилируемый джаваскрипт
>>773703
>Если мы пишем гифку в буфер в памяти через эту Write прослойку, то, вероятно, получится, что мы будем заниматься бессмысленным перекладыванием байтов
Ну, кстати, я не додумался, но этот момент всё же можно обойти, как этот чел: https://lists.sr.ht/~skeeto/public-inbox/%3Cane2ee7fpnyn3qxslygprmjw2yrvzppxuim25jvf7e6f5jgxbd@p7y6own2j3it%3E
То есть не делать в этом полиморфном интерфейсе в принципе никакого write, только flush. Вместо вызовов write писать в свой внутренний буфер. Если пишем в файл, то flush делает запись в файл и очищает буфер, если пишем в память, то flush расширяет буфер.



Результат - пикрил два, 256 цветов, вроде не сильно плохо выглядит даже без дизеринга, но это, возможно, из-за того, что джипеговые артефакты входной картинки выступают в этой роли, поэтому бэндинг не сильно бросается в глаза. Использовал этот алгоритм https://en.wikipedia.org/wiki/Median_cut суть его просто в том, что берём все цвета оригинальной картинки, сортируем их по той компоненте цвета, где больше всего разброс значений, после чего разделяем цвета пополам на два куска, дальше повторяем эти действия на более мелких группах цветов, пока у нас не получится количество групп, равное желаемому количеству цветов в картинке. После чего усредняем цвета в каждой группе и используем усреднённые цвета в палитре. Можно сделать совсем мало цветов, пикрил три - это только 4 цвета. Вроде бы ещё для квантизации можно использовать k-means clustering, но я не читал про него.
В коде получился какой-то полный бред. Вхардкоженный опен адресинг хешсет для составления массива цветов из картинки. Потом куски массива цветов сортируются и разбиваются на сегменты, которые я в очереди на циклическом массиве просто храню: в цикле из начала берётся новый сегмент, разбивается на два, которые добавляются в конец. И так до тех пор либо, пока не разобъём на 256 групп, либо, пока размер всех групп не достигнет единицы (что означает, что во входной картинке меньше 256 цветов).
Этот фронтенд для gdb вроде бы неплохой https://github.com/nakst/gf не для всего есть кнопки, к сожалению, некоторые вещи вроде условных брейкпоинтов и текущей рабочей директории приходится вводить командами в gdb, нет возможности навести мышкой на переменную и посмотреть её значение, иногда глючит, но в целом лучше, чем пользоваться gdb из консоли. (И ещё его нет под виндой, но там есть варианты получше типа remedybg или RAD debugger, которые к тому же не просто фронтенды, а самостоятельные дебаггеры.)
Под конец у меня снова не было никаких сил уже любых и я еле-еле смог выискать все тупейшие ошибки в коде и доделать до минимально рабочего состояния. Работает оно, кстати, дико медленно из-за линейных лукапов последовательностей из LZW таблицы в цикле, всё ещё не заменил на хештаблицу. Самый тупой момент был, когда не мог найти ошибку из-за того, что случайно вместо изменения переменной в цикле переобъявил её внутри, и дебаггер тоже не помогал, потому что в watch окне просто показывал значение локальной для цикла переменной, короче, виноват во всём этот gf, в котором нельзя по ховеру смотреть значения переменных. А я тупо не заметил, видимо, придётся теперь всегда включать ворнинги для шедоувинга переменных, раз я напоролся на это.
Я каким-то образом сидел с этим почти 7 часов подряд, у меня снова напрочь выжжен мозг, я не знаю, что с собой сделать, я моментально устаю буквально от любых попыток приложить куда-то усилия, моя проблема 100% в том, что я генетическое уёбище, которое может только лежать в кровати и обниматься с одеялом и больше ничего не хочется, мне ничего не поможет, я хочу нахуй умереть
Результат - пикрил два, 256 цветов, вроде не сильно плохо выглядит даже без дизеринга, но это, возможно, из-за того, что джипеговые артефакты входной картинки выступают в этой роли, поэтому бэндинг не сильно бросается в глаза. Использовал этот алгоритм https://en.wikipedia.org/wiki/Median_cut суть его просто в том, что берём все цвета оригинальной картинки, сортируем их по той компоненте цвета, где больше всего разброс значений, после чего разделяем цвета пополам на два куска, дальше повторяем эти действия на более мелких группах цветов, пока у нас не получится количество групп, равное желаемому количеству цветов в картинке. После чего усредняем цвета в каждой группе и используем усреднённые цвета в палитре. Можно сделать совсем мало цветов, пикрил три - это только 4 цвета. Вроде бы ещё для квантизации можно использовать k-means clustering, но я не читал про него.
В коде получился какой-то полный бред. Вхардкоженный опен адресинг хешсет для составления массива цветов из картинки. Потом куски массива цветов сортируются и разбиваются на сегменты, которые я в очереди на циклическом массиве просто храню: в цикле из начала берётся новый сегмент, разбивается на два, которые добавляются в конец. И так до тех пор либо, пока не разобъём на 256 групп, либо, пока размер всех групп не достигнет единицы (что означает, что во входной картинке меньше 256 цветов).
Этот фронтенд для gdb вроде бы неплохой https://github.com/nakst/gf не для всего есть кнопки, к сожалению, некоторые вещи вроде условных брейкпоинтов и текущей рабочей директории приходится вводить командами в gdb, нет возможности навести мышкой на переменную и посмотреть её значение, иногда глючит, но в целом лучше, чем пользоваться gdb из консоли. (И ещё его нет под виндой, но там есть варианты получше типа remedybg или RAD debugger, которые к тому же не просто фронтенды, а самостоятельные дебаггеры.)
Под конец у меня снова не было никаких сил уже любых и я еле-еле смог выискать все тупейшие ошибки в коде и доделать до минимально рабочего состояния. Работает оно, кстати, дико медленно из-за линейных лукапов последовательностей из LZW таблицы в цикле, всё ещё не заменил на хештаблицу. Самый тупой момент был, когда не мог найти ошибку из-за того, что случайно вместо изменения переменной в цикле переобъявил её внутри, и дебаггер тоже не помогал, потому что в watch окне просто показывал значение локальной для цикла переменной, короче, виноват во всём этот gf, в котором нельзя по ховеру смотреть значения переменных. А я тупо не заметил, видимо, придётся теперь всегда включать ворнинги для шедоувинга переменных, раз я напоролся на это.
Я каким-то образом сидел с этим почти 7 часов подряд, у меня снова напрочь выжжен мозг, я не знаю, что с собой сделать, я моментально устаю буквально от любых попыток приложить куда-то усилия, моя проблема 100% в том, что я генетическое уёбище, которое может только лежать в кровати и обниматься с одеялом и больше ничего не хочется, мне ничего не поможет, я хочу нахуй умереть
 1,2 Мб, 1576x2594
1,2 Мб, 1576x2594> typedef union {
> ・・f32 data[3];
> ・・struct { f32 x, y, z; };
> ・・struct { f32 red, green, blue; };
> } f32x3;
Но, во-первых, для анонимных структур нужен C11, в C99 придётся назвать все структуры и обращаться к ним как "vector.coord.y" или "vector.color.green". А во-вторых, тут вылезает UB из-за массива: если ты создал f32x3 и изначально инициализировал его через поля x, y, z, то ты не можешь пытаться читать их через массив data, потому что чисто формально в юнионе не лежит массив (читать red, green, blue при этом, кстати, можно, потому что одни и те же типы полей в двух структурах под юнионом).
Ладно, можно попробовать убрать массив и сделать индексированный доступ через функцию, например (под MSVC __assume(0) - эквивалент __builtin_unreachable()):
> f32 f32x3_get(f32x3 vector, int index) {
> ・・switch (index) {
> ・・・・case 0: return vector.coord.x;
> ・・・・case 1: return vector.coord.y;
> ・・・・case 2: return vector.coord.z;
> ・・・・default: __builtin_unreachable();
> ・・}
> }
Компилятор же сможет такое оптимизировать и убрать ветвление? Ну типа и да, и нет? https://godbolt.org/z/js9fvGMv7 Если он инлайнит вызов этой функции, то убирает джампы, но в коде самой функции почему-то всё равно есть ветвление.
А если сделать так:
> f32 f32x3_get_branchless(f32x3 vector, int index) {
> ・・return ((f32 🞰) &vector)[index];
> }
то опять же, чисто формально это будет UB.
Ну ок, можно подумать, что хотя бы такое сработает:
> #define RED 0
> #define GREEN 1
> #define BLUE 2
> #define X 0
> #define Y 1
> #define Z 2
> typedef f32 f32x3[3];
Но это ещё хуже, удачи попытаться вернуть массив из функции, удачи попытаться просто присвоить другое значение переменной с таким вектором:
> f32x3 vector = {1.0F, 2.0F, 3.0F};
> vector = (f32x3) {4.0F, 5.0F, 6.0F};
Это не сработает, потому что на второй строке компаунд литерал справа имеет тип "f32 🞰". То есть придётся запихивать массив внутрь структуры и обращение к элементам начинает выглядеть совсем стрёмно: vector.data[Y] или vector.data[GREEN]. Про то, что мы мы дефайнами заняли названия цветов и осей координат, я вообще молчу.
Да, короче, просто похуй на это UB, это всё бред, компилятор либо генерирует нужный тебе код, либо нет, программа просто либо работает, либо нет, эти рассуждения - бессмысленная хуета, а я ёбаный дегенерат. Я просто попытался сесть продолжить что-то писать, но выебал сам себе мозг какой-то хуйнёй, не имеющей ничего общего с реальностью, я тупое животное, я нахуй ненавижу себя
1,2 Мб, 1576x2594> typedef union {
> ・・f32 data[3];
> ・・struct { f32 x, y, z; };
> ・・struct { f32 red, green, blue; };
> } f32x3;
Но, во-первых, для анонимных структур нужен C11, в C99 придётся назвать все структуры и обращаться к ним как "vector.coord.y" или "vector.color.green". А во-вторых, тут вылезает UB из-за массива: если ты создал f32x3 и изначально инициализировал его через поля x, y, z, то ты не можешь пытаться читать их через массив data, потому что чисто формально в юнионе не лежит массив (читать red, green, blue при этом, кстати, можно, потому что одни и те же типы полей в двух структурах под юнионом).
Ладно, можно попробовать убрать массив и сделать индексированный доступ через функцию, например (под MSVC __assume(0) - эквивалент __builtin_unreachable()):
> f32 f32x3_get(f32x3 vector, int index) {
> ・・switch (index) {
> ・・・・case 0: return vector.coord.x;
> ・・・・case 1: return vector.coord.y;
> ・・・・case 2: return vector.coord.z;
> ・・・・default: __builtin_unreachable();
> ・・}
> }
Компилятор же сможет такое оптимизировать и убрать ветвление? Ну типа и да, и нет? https://godbolt.org/z/js9fvGMv7 Если он инлайнит вызов этой функции, то убирает джампы, но в коде самой функции почему-то всё равно есть ветвление.
А если сделать так:
> f32 f32x3_get_branchless(f32x3 vector, int index) {
> ・・return ((f32 🞰) &vector)[index];
> }
то опять же, чисто формально это будет UB.
Ну ок, можно подумать, что хотя бы такое сработает:
> #define RED 0
> #define GREEN 1
> #define BLUE 2
> #define X 0
> #define Y 1
> #define Z 2
> typedef f32 f32x3[3];
Но это ещё хуже, удачи попытаться вернуть массив из функции, удачи попытаться просто присвоить другое значение переменной с таким вектором:
> f32x3 vector = {1.0F, 2.0F, 3.0F};
> vector = (f32x3) {4.0F, 5.0F, 6.0F};
Это не сработает, потому что на второй строке компаунд литерал справа имеет тип "f32 🞰". То есть придётся запихивать массив внутрь структуры и обращение к элементам начинает выглядеть совсем стрёмно: vector.data[Y] или vector.data[GREEN]. Про то, что мы мы дефайнами заняли названия цветов и осей координат, я вообще молчу.
Да, короче, просто похуй на это UB, это всё бред, компилятор либо генерирует нужный тебе код, либо нет, программа просто либо работает, либо нет, эти рассуждения - бессмысленная хуета, а я ёбаный дегенерат. Я просто попытался сесть продолжить что-то писать, но выебал сам себе мозг какой-то хуйнёй, не имеющей ничего общего с реальностью, я тупое животное, я нахуй ненавижу себя



Ну, на самом деле, там можно было вместо каста структуры к указателю на f32 просто в массив все компоненты сложить и по индексу достать значение из него, не знаю, почему я не подумал об этом, но меня в любом случае просто как-то расстроило, что оно зачем-то ветвление делает.
Я уже несколько дней назад типо как-то улучшил (в гигантских кавычках) скорость работы просто банально за счёт того, что убрал тысячи бесполезных переводов в цикле из sRGB в линейное пространство для табличных цветов (которые нужны, чтобы найти табличный цвет ближайший к цветам пикселей из картинки). Ну типа все эти переводы можно один раз сделать в начале для всех табличных цветов и дальше переиспользовать. Вообще я почти уверен, что там сейчас неправильно всё с квантизацией цветов, потому что как будто при генерации палитры под картинку тоже нужно учитывать гамму (когда выбираешь компонент цвета, по которому делишь цвета на каждой итерации median cut quantization, когда вычисляешь среднее для группы похожих цветов), а я сейчас этого не делаю. Я подозреваю, что если сделать картинку с градиентом от чёрного до белого и урезать её до небольшого количества цветов, например, до восьми, то там будет хорошо видно, что градиент съедет по сравнению с оригинальной картинкой. Но у меня сейчас не было сил это проверять.
У меня сейчас лукапы ближайших цветов к табличным сделаны через k-d дерево и вроде бы на них тратится подавляющее количество времени, если верить gprof. Из-за этого мне мозг сверлила мысль, что может быть можно выпилить рекурсию, явные указатели на поддеревья и запихать дерево в массив, типа как когда бинарную кучу запихивают в массив? Мне почему-то казалось, что там благодаря этому можно было бы сделать как-то так, что не нужен будет бэктрекинг, ну или что как-то дерево можно было бы одним циклом обойти или уменьшить бэктрекинг, но, короче, я не придумал ничего и пикрил два код работает ровно так же, как версия с рекурсией и явным деревом. Бессмысленно, наверное, вот так разворачивать рекурсию, если приходится всё равно свой стек велосипедить. А если не k-d дерево, то я не знаю, что использовать, может быть, лучше было бы во время генерации палитры все цвета картинки впихнуть в хешмапу, которая бы маппила их в цвет из палитры, чтобы во время итерации по пикселям делать лукап по хештаблице, а не по дереву. Я не знаю, почему я так не сделал изначально, это более очевидный вариант вроде бы.
Почему-то захотелось попробовать посмотреть, что из себя представляют локально запущенные ллм, потому что как будто даже есть некий свой вайб у того, что "разговаривает" с тобой именно твой комп, который у тебя под ногами шумит и греется, автономно, без того, чтобы слать запросы в какие-то непонятные датацентры. Ну и плюс в голову лезут какие-то выдуманные сценарии про то, что человечество отупело, пришло в упадок, вся инфраструктура порушилась, электричества нет, всё взорвано атомными бомбами, но есть надежда, что можно найти мифические уцелевшие жёсткие диски с ллм, как-то их запустить и, короче, чтобы оно дало туториал как восстановить человечество. А типа у тебя прямо сейчас в настоящем на жёстком диске лежит этот мега артефакт.
Но, короче, проблема в том, что мне с 8 Гб видеопамяти, как оказалось, примерно бесполезно пытаться что-то запускать. Максимум с разумной производительностью можно запустить только модели на 7B параметров, которые, если они не зафайнтюнены на что-то конкретное вроде кодинга, то они довольно тупые. Либо на 14B параметров, но с весами урезанными до 3 бит как минимум, они менее тупые, но не особо качественные. А если на видеокарту полностью не удаётся выгрузить все слои, то скорость работы падает практически до скорости работы просто на проце. Reasoning ллмы запускать бесполезно, на 7B они как будто ещё тупее, чем обычные, а если более жирные, то с моей видеокартой не дождёшься момента, когда они завершат этот шизоидный диалог с самой собой и перейдут к ответу. Модели на 32B ещё кое-как хотя бы запускаются на процессоре с 32 Гб оперативки, на 70B - уже нет.
Кокретно, что я хотел попробовать - это вариант использования ллм как бэкситтера во время кодинга, потому что я на эту тему только один раз давно, год назад, попробовал копилот, но меня тогда почти сразу выбесило, что он посоветовал мне что-то очевидно ошибочное, и я забил. Показалось, что самое более-менее адекватное из доступного мне - это Qwen 2.5 coder 7B instruct (Q6_K) с 16к токенами контекста (больше не уместилось в VRAM). Ну, короче, вывод за пару часов использования, сейчас, пока я пытался переписать поиск по k-d дереву - оно иногда может угадать концовки комментариев, которые я пишу к коду. В остальном либо генерирует бред (из-за тупости / слишком маленького контекста), либо как будто нарочно пытается внести баги в код, но чтобы я не заметил, как на пикрил три.
И даже такая мелкая и тупая модель работает довольно медленно и периодически уходит в себя на минуту и всё это время оно что-то долго генерит, судя по нагрузке на видеокарту, но в итоге может выдать не какой-то длинный ответ, а просто короткий и тупой. Вообще я так понял, они не отвечают на твои вопросы, они тупо непрерывно генерят текст, но натренированы иногда вставлять специальные токены по типу <|im_start|>assistant, <|im_start|>user, <|im_end|>, обозначающие границы реплик себя и тебя. Но в целом ей всё равно, если её не останавливать, то она начнёт ролеплеить за юзера, задавать вопросы сама себе, сама же себе отвечать и так бесконечно, некоторые модели, которые запускал, тупо так и делали почему-то. Из-за этого создалось впечатление, что в такие моменты затупов у него не получается вовремя выдать завершающий токен, а вскодовое расширение (continue.dev) пытается заново и заново сгенерировать автокомплит, пока наконец-то не получает рандомно что-то завершённое и не сильно длинное, поэтому оно может долго тупить и потом выдать что-то короткое. По крайней мере таких затупов стало меньше после того, как выставил completionOptions.maxTokens на 128 токенов, всё равно чем больше генерит за раз, тем с большей вероятностью код оказывается полнейшим бредом.
Я пользовался ей через llama.cpp с вулкановым бэкендом, как будто бы ROCm бэкенд должен работать немного получше, но я не могу его скомпилировать, слишком много гигабайтов зависимостей, а у меня линукс помойка, на которой я зачем-то сейчас в основном сижу, сейчас находится в изгнании на довольно небольшой флешке.
Неважно, короче, у меня после этого окончательно угас любой интерес ко всему этому нейрослопу, ничего никогда не происходит
Ну, на самом деле, там можно было вместо каста структуры к указателю на f32 просто в массив все компоненты сложить и по индексу достать значение из него, не знаю, почему я не подумал об этом, но меня в любом случае просто как-то расстроило, что оно зачем-то ветвление делает.
Я уже несколько дней назад типо как-то улучшил (в гигантских кавычках) скорость работы просто банально за счёт того, что убрал тысячи бесполезных переводов в цикле из sRGB в линейное пространство для табличных цветов (которые нужны, чтобы найти табличный цвет ближайший к цветам пикселей из картинки). Ну типа все эти переводы можно один раз сделать в начале для всех табличных цветов и дальше переиспользовать. Вообще я почти уверен, что там сейчас неправильно всё с квантизацией цветов, потому что как будто при генерации палитры под картинку тоже нужно учитывать гамму (когда выбираешь компонент цвета, по которому делишь цвета на каждой итерации median cut quantization, когда вычисляешь среднее для группы похожих цветов), а я сейчас этого не делаю. Я подозреваю, что если сделать картинку с градиентом от чёрного до белого и урезать её до небольшого количества цветов, например, до восьми, то там будет хорошо видно, что градиент съедет по сравнению с оригинальной картинкой. Но у меня сейчас не было сил это проверять.
У меня сейчас лукапы ближайших цветов к табличным сделаны через k-d дерево и вроде бы на них тратится подавляющее количество времени, если верить gprof. Из-за этого мне мозг сверлила мысль, что может быть можно выпилить рекурсию, явные указатели на поддеревья и запихать дерево в массив, типа как когда бинарную кучу запихивают в массив? Мне почему-то казалось, что там благодаря этому можно было бы сделать как-то так, что не нужен будет бэктрекинг, ну или что как-то дерево можно было бы одним циклом обойти или уменьшить бэктрекинг, но, короче, я не придумал ничего и пикрил два код работает ровно так же, как версия с рекурсией и явным деревом. Бессмысленно, наверное, вот так разворачивать рекурсию, если приходится всё равно свой стек велосипедить. А если не k-d дерево, то я не знаю, что использовать, может быть, лучше было бы во время генерации палитры все цвета картинки впихнуть в хешмапу, которая бы маппила их в цвет из палитры, чтобы во время итерации по пикселям делать лукап по хештаблице, а не по дереву. Я не знаю, почему я так не сделал изначально, это более очевидный вариант вроде бы.
Почему-то захотелось попробовать посмотреть, что из себя представляют локально запущенные ллм, потому что как будто даже есть некий свой вайб у того, что "разговаривает" с тобой именно твой комп, который у тебя под ногами шумит и греется, автономно, без того, чтобы слать запросы в какие-то непонятные датацентры. Ну и плюс в голову лезут какие-то выдуманные сценарии про то, что человечество отупело, пришло в упадок, вся инфраструктура порушилась, электричества нет, всё взорвано атомными бомбами, но есть надежда, что можно найти мифические уцелевшие жёсткие диски с ллм, как-то их запустить и, короче, чтобы оно дало туториал как восстановить человечество. А типа у тебя прямо сейчас в настоящем на жёстком диске лежит этот мега артефакт.
Но, короче, проблема в том, что мне с 8 Гб видеопамяти, как оказалось, примерно бесполезно пытаться что-то запускать. Максимум с разумной производительностью можно запустить только модели на 7B параметров, которые, если они не зафайнтюнены на что-то конкретное вроде кодинга, то они довольно тупые. Либо на 14B параметров, но с весами урезанными до 3 бит как минимум, они менее тупые, но не особо качественные. А если на видеокарту полностью не удаётся выгрузить все слои, то скорость работы падает практически до скорости работы просто на проце. Reasoning ллмы запускать бесполезно, на 7B они как будто ещё тупее, чем обычные, а если более жирные, то с моей видеокартой не дождёшься момента, когда они завершат этот шизоидный диалог с самой собой и перейдут к ответу. Модели на 32B ещё кое-как хотя бы запускаются на процессоре с 32 Гб оперативки, на 70B - уже нет.
Кокретно, что я хотел попробовать - это вариант использования ллм как бэкситтера во время кодинга, потому что я на эту тему только один раз давно, год назад, попробовал копилот, но меня тогда почти сразу выбесило, что он посоветовал мне что-то очевидно ошибочное, и я забил. Показалось, что самое более-менее адекватное из доступного мне - это Qwen 2.5 coder 7B instruct (Q6_K) с 16к токенами контекста (больше не уместилось в VRAM). Ну, короче, вывод за пару часов использования, сейчас, пока я пытался переписать поиск по k-d дереву - оно иногда может угадать концовки комментариев, которые я пишу к коду. В остальном либо генерирует бред (из-за тупости / слишком маленького контекста), либо как будто нарочно пытается внести баги в код, но чтобы я не заметил, как на пикрил три.
И даже такая мелкая и тупая модель работает довольно медленно и периодически уходит в себя на минуту и всё это время оно что-то долго генерит, судя по нагрузке на видеокарту, но в итоге может выдать не какой-то длинный ответ, а просто короткий и тупой. Вообще я так понял, они не отвечают на твои вопросы, они тупо непрерывно генерят текст, но натренированы иногда вставлять специальные токены по типу <|im_start|>assistant, <|im_start|>user, <|im_end|>, обозначающие границы реплик себя и тебя. Но в целом ей всё равно, если её не останавливать, то она начнёт ролеплеить за юзера, задавать вопросы сама себе, сама же себе отвечать и так бесконечно, некоторые модели, которые запускал, тупо так и делали почему-то. Из-за этого создалось впечатление, что в такие моменты затупов у него не получается вовремя выдать завершающий токен, а вскодовое расширение (continue.dev) пытается заново и заново сгенерировать автокомплит, пока наконец-то не получает рандомно что-то завершённое и не сильно длинное, поэтому оно может долго тупить и потом выдать что-то короткое. По крайней мере таких затупов стало меньше после того, как выставил completionOptions.maxTokens на 128 токенов, всё равно чем больше генерит за раз, тем с большей вероятностью код оказывается полнейшим бредом.
Я пользовался ей через llama.cpp с вулкановым бэкендом, как будто бы ROCm бэкенд должен работать немного получше, но я не могу его скомпилировать, слишком много гигабайтов зависимостей, а у меня линукс помойка, на которой я зачем-то сейчас в основном сижу, сейчас находится в изгнании на довольно небольшой флешке.
Неважно, короче, у меня после этого окончательно угас любой интерес ко всему этому нейрослопу, ничего никогда не происходит





А) Не знаю, знаешь ты про это или нет, может, ты это уже делаешь и просто оставил названия RGB, но в качестве дальнейшего углубления в кроличью нору (https://en.wikipedia.org/wiki/Color_difference) можешь преобразовывать цвета в XYZ, а из неё в L*a*b*. Эти модели специально сделаны в стремлении создать такое пространство, в котором ощущаемая homo sapiens разница между цветами будет соответствовать евклидовому расстоянию между векторами. Линеаризованная sRGB выражает (буквально) количество фотонов, откуда естественным образом подходит для расчёта освещения, но менее естественна для поиска ближайшего цвета в палитре через расстояние. (На этом примере результат #5 с L*a*b* очень близок к результату #2 с √(2ΔR²+4ΔG²+3ΔB²)...)
Б) abs(x) < distance эквивалентно sqr(x) < sqr_distance. :>
В) Мо... можешь разбить пространство на сетку кубиков и связать с каждым список точек, которые могут оказаться ближайшими к точке внутри кубика. У каждой известно минимальное и максимальное расстояние до кубика (например, у точек внутри кубика минимальное = 0 и максимальное = расстоянию до самой дальней вершины), точки, у которых минимальное больше, чем «минимальное из максимальных», заведомо не могут быть ближайшими.
В.2) Ещё вариант (он пересекается с предыдущим aka пространственным хэшированием, потому что иногда за хэш берут эту проекцию — у неё есть ценное свойство локальности): выбираешь одну-две-три оси, сортируешь точки вдоль каждой по проекции (скалярному произведению), и для поиска проецируешь точку и ищешь по каждой оси в обе стороны, предположительно, поочерёдно (именно поочерёдно, а не выбирая минимальную из следующих, т. к. по одной из осей может быть некрасивый ложный кластер, которого под другим углом не будет видно). То есть изначально у тебя есть 2×(число осей) «курсоров», и по мере того, как ты находишь более близкие цвета, ты прерываешь поиск по тем, по которым ушёл дальше.
 239 Кб, 1310x1513
239 Кб, 1310x1513проклятье рнн-господина


![ᴜᴘᴀ=宇羽☽ 🎮配信中! - [創作] AKAGE | meme [1905100174491607040].mp4](https://2ch.life/dr/thumb/644092/17448370520110s.jpg)


Я изначально думал, может быть, сделать так, чтобы энкодер сам пытался расширить буфер под гифку, но решил, что раз выделение памяти через арену, то лучше пусть все аллокации будут максимально явными, потому что иначе можно попасть в какую-нибудь дебильную ситуацию, когда пушишь элементы в два разных динамических массива и пытаешься выделять под них память из одной арены. Короче, если честно, лучше бы сделал через колбэк write и всё, выглядит слишком всрато.
Сейчас попробовал что-нибудь анимированное закодировать через этот энкодер (потому что до этого это было невозможно, потому что половина кода была в мэйне), рандомно решил сделать шестиугольную жизнь: шесть соседей, клетка продолжает жить, если есть ровно два живых соседа, новая клетка рождается там, где есть ровно два живых соседа. Ничего интересного не получилось, а может быть, я заруинил реализацию, не знаю. Попробовал идею, которую давно на ютубе видел: скармливать rule 110 внутрь жизни, чтобы был постоянный поток живых клеток, получилась какая-то хуета, в процессе пару раз напарывался на то, что энкодер генерил невалидные гифки, но не знаю, в чём проблема пока что, всё, больше ничего не делал, хочу повеситься в пизду, блять.
Я изначально думал, может быть, сделать так, чтобы энкодер сам пытался расширить буфер под гифку, но решил, что раз выделение памяти через арену, то лучше пусть все аллокации будут максимально явными, потому что иначе можно попасть в какую-нибудь дебильную ситуацию, когда пушишь элементы в два разных динамических массива и пытаешься выделять под них память из одной арены. Короче, если честно, лучше бы сделал через колбэк write и всё, выглядит слишком всрато.
Сейчас попробовал что-нибудь анимированное закодировать через этот энкодер (потому что до этого это было невозможно, потому что половина кода была в мэйне), рандомно решил сделать шестиугольную жизнь: шесть соседей, клетка продолжает жить, если есть ровно два живых соседа, новая клетка рождается там, где есть ровно два живых соседа. Ничего интересного не получилось, а может быть, я заруинил реализацию, не знаю. Попробовал идею, которую давно на ютубе видел: скармливать rule 110 внутрь жизни, чтобы был постоянный поток живых клеток, получилась какая-то хуета, в процессе пару раз напарывался на то, что энкодер генерил невалидные гифки, но не знаю, в чём проблема пока что, всё, больше ничего не делал, хочу повеситься в пизду, блять.




Ну, хотя я ещё мог заруинить реализацию LAB, потому что если взять ту же фиксированную палитру, что здесь >>779354, у меня получается другой результат (четвёртый пик). Подумал, что, может быть, из-за того, что формула перевода между XYZ и LAB зависит от выбранного референсного белого цвета или чего-то такого (D50 или D65, я использую второй), но вроде бы нет.
Хотя, если взять D50 и не возводить цвета в степень перед преобразованием в XYZ и потом в LAB, то получается что-то более похожее, но тоже не совсем то же самое. Но тут:
http://www.brucelindbloom.com/index.html?Eqn_RGB_XYZ_Matrix.html
написано вроде, что:
>In order to properly use this matrix, the RGB values must be linear and in the nominal range [0.0, 1.0]. In many cases, RGB values may first need conversion (for example, dividing by 255 and then raising them to a power).
Не знаю, короче.
>>784620
Как оказалось, чтобы браузеры зацикливали гифку, нужно добавить дополнительно блок, где указано, что гифка повторяется бесконечно:
https://web.archive.org/web/20180620143135/https://www.vurdalakov.net/misc/gif/netscape-looping-application-extension Из-за этого там гифка в конце просто останавливается.
А ещё браузеры не умеют в 100 фпс гифки из-за какого-то дебильного легаси, тянущегося 20 лет https://learn.microsoft.com/en-us/archive/blogs/ieinternals/trivia-animated-gif-timing (ну, точнее не тянущегося, а сейчас уже просто всем слишком всё равно на какой-то тупой древний формат картинок).



Пример:
┏┓
┗┛
У меня получилось так (не факт, что нормально отображается везде):
┏━┯┭┬┰┲┳┱┮┓
┗╍╈╅╁╊╋╉╂╆┛
┌┈┦┡┩┣┫┠┨┞┄╌┒
┕┉┿┽┼╄╇╃╀┾┅┑╏
┎─┤┝┥┟┧┢┪├┐└┚
┃┍┷┵┴┸┺┻┹┶┙
┖┘
Я думаю, что из-за того, что я на протяжении где-то года или около того испытывал сильный стресс, мне это нанесло непоправимый дамаг по мозгу. Стресс ускоряет старение и деградацию организма, в том числе мозга. Это очевидное наблюдение, достаточно просто посмотреть на работодебилов, которые годами находятся в стрессе. Надеяться на то, что негативные эффекты со временем ревёртятся - ни на чём не основанный коупинг. Нахождение в состоянии стресса никак не закаляет тебя от его воздействия в дальнейшем, а если у тебя нет контроля над его источником, то это дополнительно вырабатывает выученную беспомощность. Когда я что-то делаю, я постоянно сталкиваюсь с ощущением того, что мозг начинает работать на 100% даже, когда я не делаю ничего сложного, это именно физически ощущается, это не боль, но если в таком состоянии просидеть несколько часов, то потом гарантированно голова начинает трескаться от боли. Я хочу нахуй сдохнуть


Заманчивые иероглифы конечно, недавно запомнил их коды 185~220, но получилось что-то непонятное.
Надо смотреть в будущее, не брезговать штучьками всякими компенсаторными, нивелирующими эффекты некогда работавшего снадобья. У тех кто духом молод, а смотрит в прошлое - голова неминуемо трескается от боли - сама собою.. просто наблюдение.


Я тут типо специально сделал все буквы по возможности одной максимальной ширины, чтобы не сильно бросалось в глаза, что шрифт моноширинный и внутри слов в тексте есть какие-то визуальные пробелы непонятные, но мне не очень нравится, что они получились слишком жирными какими-то. Мелкие буквы в латинице и кириллице более угловатые специально, типо, чтобы их было легче отличить от заглавных, не знаю, в итоге такое себе.
Сейчас думал, что по-быстрому напишу немного кода, чтобы распарсить его из картинки + файла со списком символов, чтобы потом экспортировать во что-то более удобное для использования (ну там в сишный файл с массивом из структур с символами, в BDF/PCF, чтобы можно было впихнуть этот файл в какой-нибудь существующий конвертер между разными форматами шрифтов если что). В итоге я просидел 4 часа и нихуя не сделал, потому что я ебаный тупорылый долбоёб, который делал тупейшие ошибки, а потом по полчаса пытался их найти и исправить, плюс возился с какой-то дебильной дичью вроде того, что gdb фронтенд, которым я пользовался, внезапно перестал нормально работать и я пытался найти, что другое можно использовать. Я за это время буквально осилил только прочитать входные данные в память, ну то есть просто распарсить UTF-8 и квадраты с символами из картинки, это всё бессмысленно, я деградировал в пизду, я хочу повеситься, мой мозг протух.
>>773148
>Не уверен, что нормально написал, скорее всего, нет, потому что у меня вылезали рандомные ошибки при запуске, похожие на какую-то гонку
>Ошибка вроде исчезает, если изначально при создании окна не создавать под него картинку, или если поменять порядок действий: создание картинок и вывод окна на экран (XMapWindow), но я просто не вижу логики никакой в этих действиях
Потому что я даун, наверняка там как раз в порядке и была проблема, надо сначала создать картинку и только потом окно показывать. И/или ещё не хватало вызова XSync после вызова XShmDetach и перед удалением куска памяти, чтобы удостовериться, что иксы реально отпустили кусок памяти прежде, чем ты его удалишь, там же все функции из Xlib - это асинхронные запросы к иксам.
А ещё настраивать эту штуку с WM_DELETE_WINDOW нужно тоже ПЕРЕД тем, как выводишь окно на экран, иначе можно успеть закрыть окно прежде, чем ты её настроишь, и у тебя тоже всё крашнется вместо грейсфул шатдауна через получение события о закрытии.
А краши тут нежелательны, потому что, как оказалось, в линуксе пошаренная память остаётся жить даже после завершения всех процессов, которые были к ней приаттачены, и суммарное количество таких кусков памяти ограничено ~4к штуками, что не особо много, чтобы ими разбрасываться (ipcs -m команда, чтобы посмотреть существующие куски).
>рисую в другую картинку, пока только что отправленная на отрисовку недоступна
Это шизофрения, с двумя картинками в очереди оно тормозит сильнее, чем если используется ровно одна и каждый раз перед отрисовкой следующего кадра мы ждём события о завершении отрисовки предыдущего. Видимо, подряд идущие XShmPutImage воюют друг с другом, не знаю, но в любом случае, было глупо велосипедить какое-то подобие свопчейна из вулкана. Вообще я даже не уверен, что есть смысл ждать получения ShmCompletion события этого, но ладно.
Плюс там в виндовом коде память течёт, когда окно ресайзишь: недостаточно вызвать DeleteObject для указателя на пиксели DIB section, нужно DeleteObject для хенлда на сам DIB section тоже вызывать. Ну, по крайней мере под вайном память точно течёт, на винде вроде не текла.
А ещё под вайном этот говнокод тупо тормозит, из-за того, что я нагородил эту шизу с отдельным потоком, где создаётся окно и обрабатываются события, чтобы не тормозить рендер во время ресайза и перемещения окна. По крайней мере без этого отдельного потока никаких тормозов нет. Это вроде бы фиксится тем, чтобы НЕ диспатчить WM_PAINT события, причём как будто тормоза именно из-за вызова DispatchMessage, а не из-за обработки этих событий внутри процедуры окна через DefWindowProc. Но это всё странно, потому что проблема возникает именно, если события диспатчатся в отдельном потоке.
Альтернативно отдельному потоку, я ещё нашёл такое https://github.com/glfw/glfw/pull/1426 но там совсем какая-то шиза. Диспатчинг событий делается в отдельном файбере (это штука в винапи для кооперативной многозадачности, как я понял, симметричные стекфул корутины) и суть примерно в том, что если мы задерживаемся в процедуре окна дольше, чем на 1 миллисекунду, то мы свитчаемся обратно на основной файбер. Сделать так же без файбера вроде бы нельзя, потому что после диспатча WM_ENTERSIZEMOVE, мы тупо не можем выбраться наружу из процедуры окна (из модального цикла), нужно именно приостановить её выполнение, чтобы вернуться, перерендерить картинку и потом снова зайти в приостановленную процедуру окна, чтобы дообработать WM_SIZE и WM_MOVE события до конца, что подразумевает сохранение стека куда-то.
Я тут типо специально сделал все буквы по возможности одной максимальной ширины, чтобы не сильно бросалось в глаза, что шрифт моноширинный и внутри слов в тексте есть какие-то визуальные пробелы непонятные, но мне не очень нравится, что они получились слишком жирными какими-то. Мелкие буквы в латинице и кириллице более угловатые специально, типо, чтобы их было легче отличить от заглавных, не знаю, в итоге такое себе.
Сейчас думал, что по-быстрому напишу немного кода, чтобы распарсить его из картинки + файла со списком символов, чтобы потом экспортировать во что-то более удобное для использования (ну там в сишный файл с массивом из структур с символами, в BDF/PCF, чтобы можно было впихнуть этот файл в какой-нибудь существующий конвертер между разными форматами шрифтов если что). В итоге я просидел 4 часа и нихуя не сделал, потому что я ебаный тупорылый долбоёб, который делал тупейшие ошибки, а потом по полчаса пытался их найти и исправить, плюс возился с какой-то дебильной дичью вроде того, что gdb фронтенд, которым я пользовался, внезапно перестал нормально работать и я пытался найти, что другое можно использовать. Я за это время буквально осилил только прочитать входные данные в память, ну то есть просто распарсить UTF-8 и квадраты с символами из картинки, это всё бессмысленно, я деградировал в пизду, я хочу повеситься, мой мозг протух.
>>773148
>Не уверен, что нормально написал, скорее всего, нет, потому что у меня вылезали рандомные ошибки при запуске, похожие на какую-то гонку
>Ошибка вроде исчезает, если изначально при создании окна не создавать под него картинку, или если поменять порядок действий: создание картинок и вывод окна на экран (XMapWindow), но я просто не вижу логики никакой в этих действиях
Потому что я даун, наверняка там как раз в порядке и была проблема, надо сначала создать картинку и только потом окно показывать. И/или ещё не хватало вызова XSync после вызова XShmDetach и перед удалением куска памяти, чтобы удостовериться, что иксы реально отпустили кусок памяти прежде, чем ты его удалишь, там же все функции из Xlib - это асинхронные запросы к иксам.
А ещё настраивать эту штуку с WM_DELETE_WINDOW нужно тоже ПЕРЕД тем, как выводишь окно на экран, иначе можно успеть закрыть окно прежде, чем ты её настроишь, и у тебя тоже всё крашнется вместо грейсфул шатдауна через получение события о закрытии.
А краши тут нежелательны, потому что, как оказалось, в линуксе пошаренная память остаётся жить даже после завершения всех процессов, которые были к ней приаттачены, и суммарное количество таких кусков памяти ограничено ~4к штуками, что не особо много, чтобы ими разбрасываться (ipcs -m команда, чтобы посмотреть существующие куски).
>рисую в другую картинку, пока только что отправленная на отрисовку недоступна
Это шизофрения, с двумя картинками в очереди оно тормозит сильнее, чем если используется ровно одна и каждый раз перед отрисовкой следующего кадра мы ждём события о завершении отрисовки предыдущего. Видимо, подряд идущие XShmPutImage воюют друг с другом, не знаю, но в любом случае, было глупо велосипедить какое-то подобие свопчейна из вулкана. Вообще я даже не уверен, что есть смысл ждать получения ShmCompletion события этого, но ладно.
Плюс там в виндовом коде память течёт, когда окно ресайзишь: недостаточно вызвать DeleteObject для указателя на пиксели DIB section, нужно DeleteObject для хенлда на сам DIB section тоже вызывать. Ну, по крайней мере под вайном память точно течёт, на винде вроде не текла.
А ещё под вайном этот говнокод тупо тормозит, из-за того, что я нагородил эту шизу с отдельным потоком, где создаётся окно и обрабатываются события, чтобы не тормозить рендер во время ресайза и перемещения окна. По крайней мере без этого отдельного потока никаких тормозов нет. Это вроде бы фиксится тем, чтобы НЕ диспатчить WM_PAINT события, причём как будто тормоза именно из-за вызова DispatchMessage, а не из-за обработки этих событий внутри процедуры окна через DefWindowProc. Но это всё странно, потому что проблема возникает именно, если события диспатчатся в отдельном потоке.
Альтернативно отдельному потоку, я ещё нашёл такое https://github.com/glfw/glfw/pull/1426 но там совсем какая-то шиза. Диспатчинг событий делается в отдельном файбере (это штука в винапи для кооперативной многозадачности, как я понял, симметричные стекфул корутины) и суть примерно в том, что если мы задерживаемся в процедуре окна дольше, чем на 1 миллисекунду, то мы свитчаемся обратно на основной файбер. Сделать так же без файбера вроде бы нельзя, потому что после диспатча WM_ENTERSIZEMOVE, мы тупо не можем выбраться наружу из процедуры окна (из модального цикла), нужно именно приостановить её выполнение, чтобы вернуться, перерендерить картинку и потом снова зайти в приостановленную процедуру окна, чтобы дообработать WM_SIZE и WM_MOVE события до конца, что подразумевает сохранение стека куда-то.

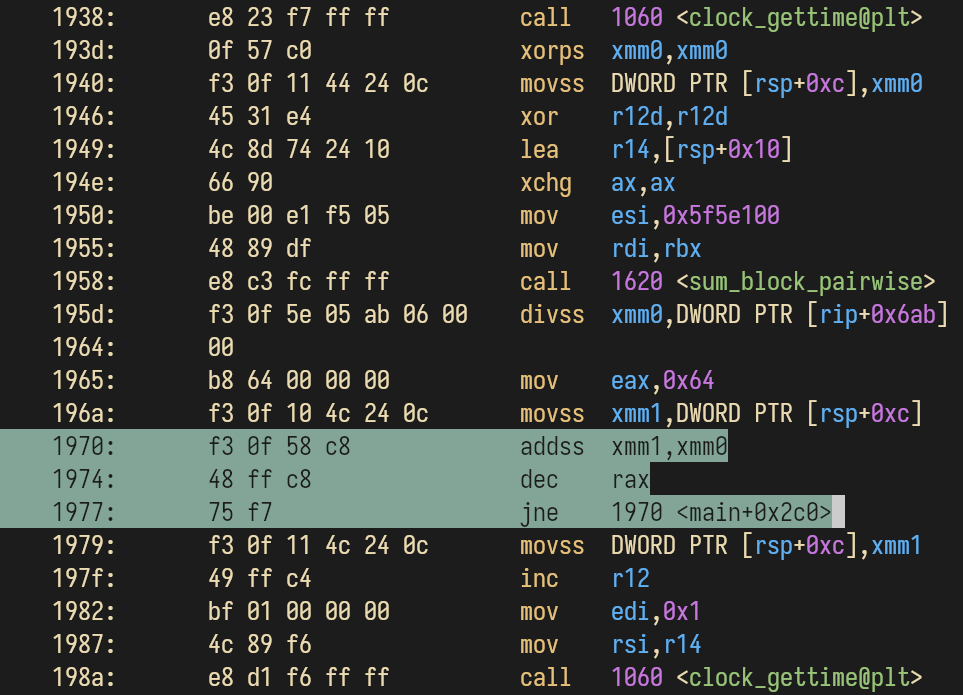
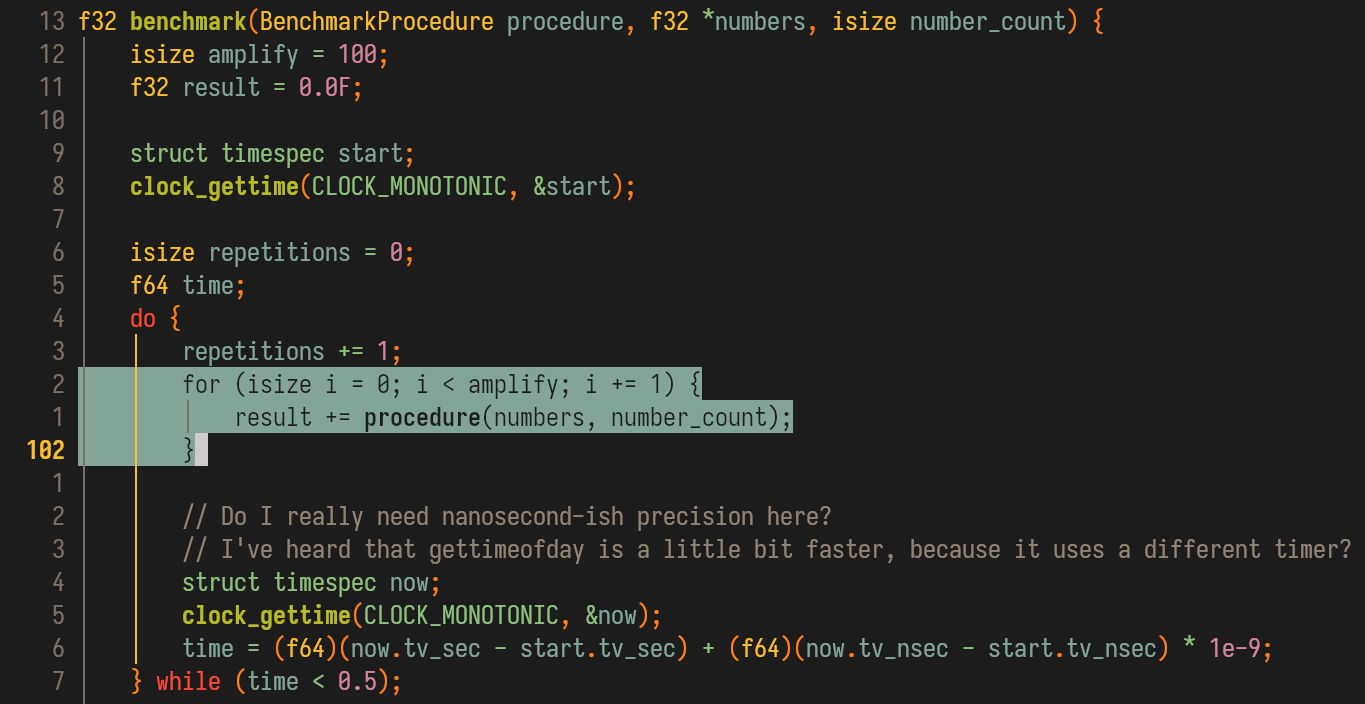
А ещё моя жизнь - бессмысленная хуйня и я хочу повеситься. А ещё моя жизнь - бессмысленная хуйня и я хочу повеситься. А ещё я украл этот код.
 65 Кб, 1161x630
65 Кб, 1161x630Как-то ты обитаешь здесь одиноко - ведь не думаешь ты, что увлечение этими хм-хм-программами мешает тебе общаться с остальными?

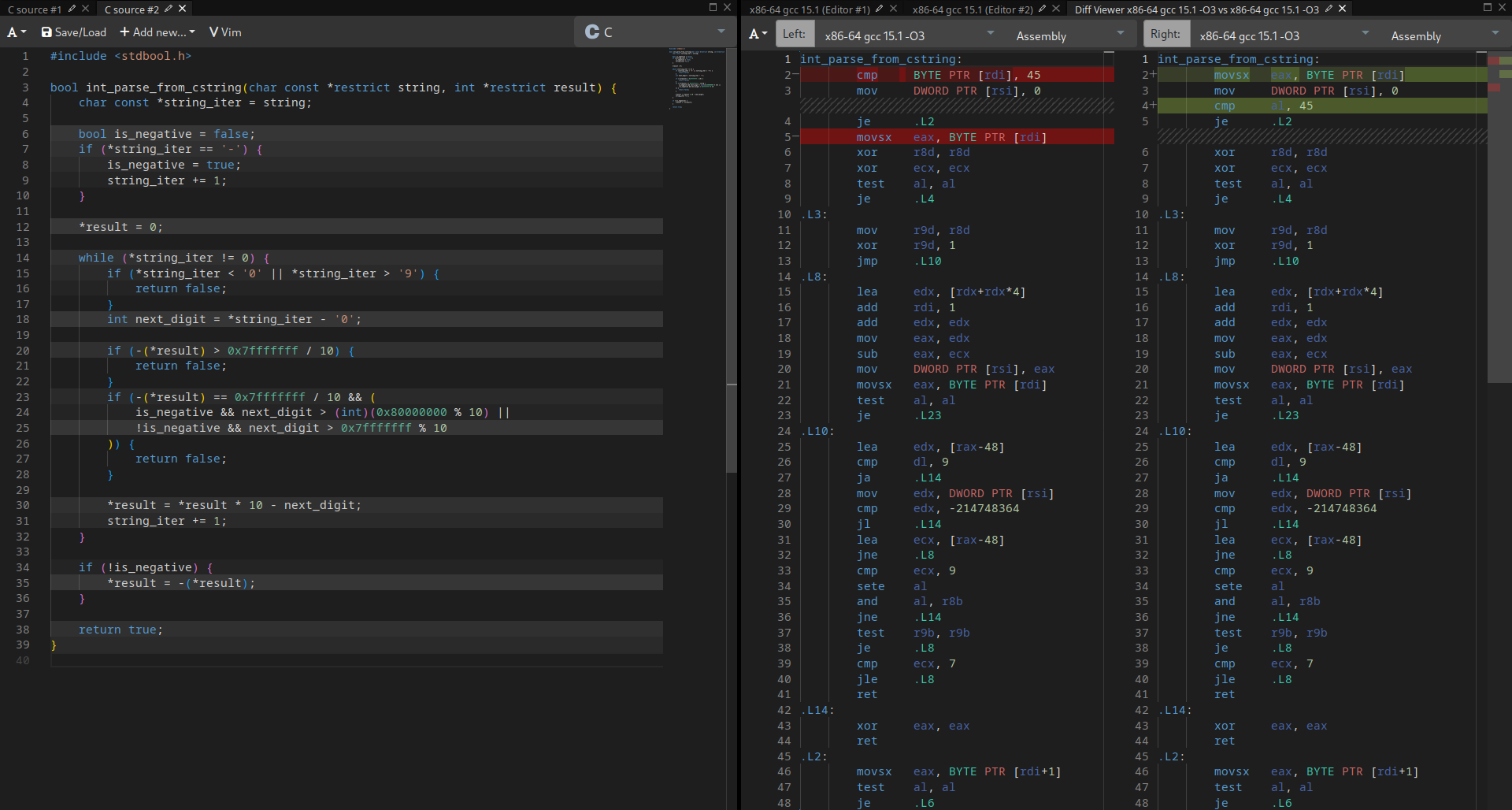
Но, короче, на деле тут оказалось, что в сгенерированном коде буквально ноль разницы, что есть restrict, что его нету: все записи по указателю остались mov-ами в память. В начале функции код немного отличается только из-за того, что походу gcc побоялся переставить местами первые два mov-а и это оказалось единственным местом, где он додумался применить знание о restrict.
Ну, это как бы нормально и адекватно, что оно так компилируется, просто хотя бы от кланга я ожидал какую-то мега-шизо-оптимизацию, но там restrict вообще ни на что не повлиял. Короче, как будто restrict существует только для функции memcpy и на этом его полезность заканчивается. И теперь мне ещё менее понятно, существуют ли вообще на практике эти мифические гига-оптимизации, ломающие код из-за того, что ты, например, скастил указатель на флоат к указателю на инт.
Довольно очевидную идею с тем, чтобы собирать сумму в отрицательное число вместо положительного украл отсюда, кстати https://ptspts.blogspot.com/2014/04/how-to-parse-integer-in-c-and-c-with.html Я бы не додумался до такого и просто бы в начале проверял строку на равенство "-2147483648".
Были мысли ещё использовать беззнаковые инты для накопления результата, а на переполнение проверять тупо через N × 10 < N, потому что типо засомневался, может быть, всё гораздо проще можно было бы делать. Но тут это не сработает, например, для 32-битных интов: (500млн × 10) % 2^32 > 500млн, но 500млн × 10 > 2^32 - 1. Короче, не обойтись без checked_add и checked_mul подобных вещей.
Но, короче, на деле тут оказалось, что в сгенерированном коде буквально ноль разницы, что есть restrict, что его нету: все записи по указателю остались mov-ами в память. В начале функции код немного отличается только из-за того, что походу gcc побоялся переставить местами первые два mov-а и это оказалось единственным местом, где он додумался применить знание о restrict.
Ну, это как бы нормально и адекватно, что оно так компилируется, просто хотя бы от кланга я ожидал какую-то мега-шизо-оптимизацию, но там restrict вообще ни на что не повлиял. Короче, как будто restrict существует только для функции memcpy и на этом его полезность заканчивается. И теперь мне ещё менее понятно, существуют ли вообще на практике эти мифические гига-оптимизации, ломающие код из-за того, что ты, например, скастил указатель на флоат к указателю на инт.
Довольно очевидную идею с тем, чтобы собирать сумму в отрицательное число вместо положительного украл отсюда, кстати https://ptspts.blogspot.com/2014/04/how-to-parse-integer-in-c-and-c-with.html Я бы не додумался до такого и просто бы в начале проверял строку на равенство "-2147483648".
Были мысли ещё использовать беззнаковые инты для накопления результата, а на переполнение проверять тупо через N × 10 < N, потому что типо засомневался, может быть, всё гораздо проще можно было бы делать. Но тут это не сработает, например, для 32-битных интов: (500млн × 10) % 2^32 > 500млн, но 500млн × 10 > 2^32 - 1. Короче, не обойтись без checked_add и checked_mul подобных вещей.

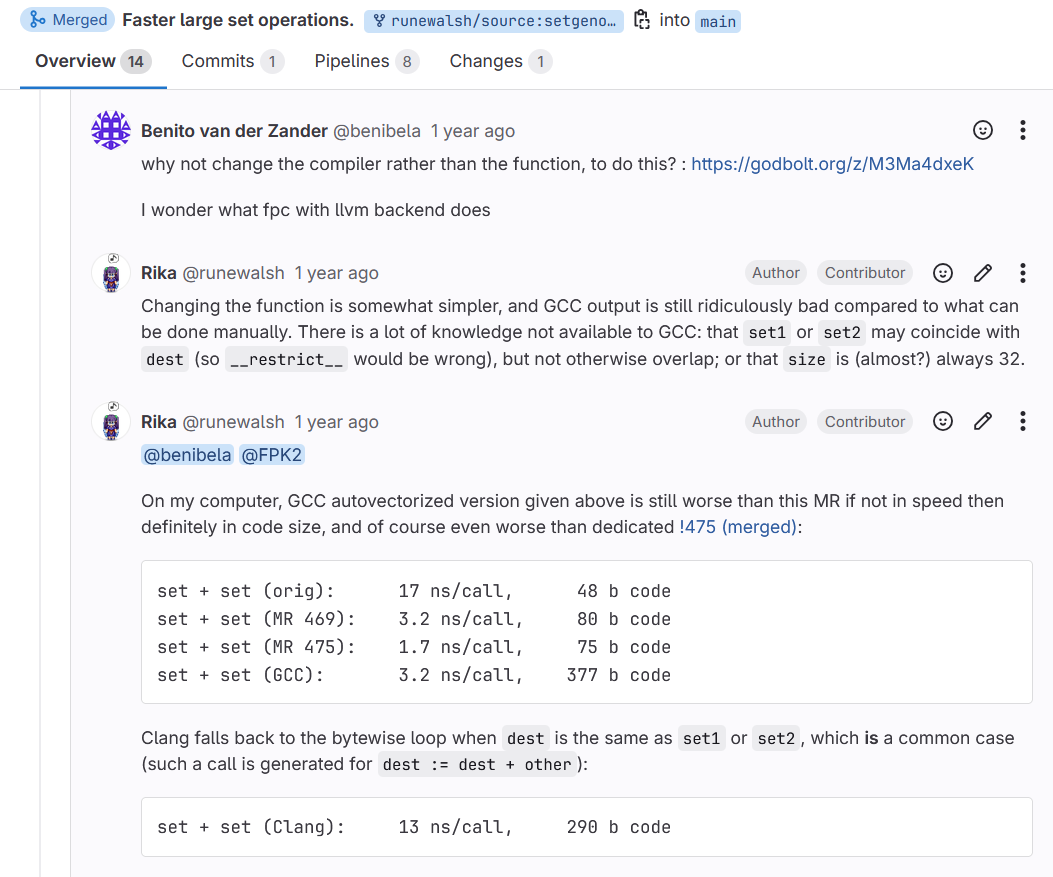
Я в https://gitlab.com/freepascal.org/fpc/source/-/merge_requests/942 придумал следующее. Заранее известно, какой длины максимальное значение (без лидирующих нулей), помещающееся в целевой тип — оно зависит от основания системы счисления, целевого типа, и отрицательности числа, все варианты можно собрать в небольшую лукап-таблицу (ну или в данном случае это вообще константа времени компиляции). Например, десятичное число, читаемое в int32, не может насчитывать больше 10 цифр.
Если число превысило эту длину — оно точно переполнилось, если не превысило — точно не переполнилось, если оно ровно этой длины — оно, может, переполнилось, а может, и нет, и можно это проверить любым способом, включая этот. Для этого в цикле достаточно делать всего лишь
>digits_left--, prev_n = n;
(даже брейкаться по digits_left < 0 не обязательно), чтобы после цикла было возможно сделать
>if (digits_left > 0) { точно нет переполнения } else if (digits_left == 0) { проверка переполнения на основании prev_n и оставшегося с цикла последнего разряда } else { точно переполнение }.
>существуют ли вообще на практике эти мифические гига-оптимизации, ломающие код
Да, существуют, я забыл (хорошие) примеры из интернета и слишком никогда не пишу на чём-либо кроме Free Pascal, чтобы иметь свои, но (плохой) легко искусственно построить: https://godbolt.org/z/qhMozx3ba. Этот код меняет поведение, если убрать -fno-strict-aliasing, потому что компилятор начинает полагать возможным не перечитывать *i.
Тоже считаю restrict бесполезным, на следующем примере такого крайне частого и полностью им игнорируемого случая перекрытий, как полные совпадения, на который я на этот раз сам натыкался на пике 2. Рассмотрим функцию:
>void batch_add(float *a, float *b, size_t n, float *r),
выполняющую покомпонентное r[n] = a[n] + b[n]. То, что выходные буферы не должны перекрываться с входными, если это явно не разрешено — неписаное правило программирования (https://devblogs.microsoft.com/oldnewthing/20060320-13/?p=31853), но как раз для таких простых и поэлементно независимых функций, где это точно не будет конфликтовать с какими бы то ни было оптимизациями и позволит переиспользовать тот же код для in-place операций вида a[] += b[], естественно и удобно явно разрешать, чтобы r совпадало с a/b — и только совпадало, т. е. частичные перекрытия всё ещё запрещены. Restrict здесь неверен и разрешит компилятору, например, записать в вычисляемую ячейку r промежуточный результат, то есть реализовать r[і] = a[і] + b[і] как r[і] = a[і]; r[і] += b[і] (ну мало ли).
Я в https://gitlab.com/freepascal.org/fpc/source/-/merge_requests/942 придумал следующее. Заранее известно, какой длины максимальное значение (без лидирующих нулей), помещающееся в целевой тип — оно зависит от основания системы счисления, целевого типа, и отрицательности числа, все варианты можно собрать в небольшую лукап-таблицу (ну или в данном случае это вообще константа времени компиляции). Например, десятичное число, читаемое в int32, не может насчитывать больше 10 цифр.
Если число превысило эту длину — оно точно переполнилось, если не превысило — точно не переполнилось, если оно ровно этой длины — оно, может, переполнилось, а может, и нет, и можно это проверить любым способом, включая этот. Для этого в цикле достаточно делать всего лишь
>digits_left--, prev_n = n;
(даже брейкаться по digits_left < 0 не обязательно), чтобы после цикла было возможно сделать
>if (digits_left > 0) { точно нет переполнения } else if (digits_left == 0) { проверка переполнения на основании prev_n и оставшегося с цикла последнего разряда } else { точно переполнение }.
>существуют ли вообще на практике эти мифические гига-оптимизации, ломающие код
Да, существуют, я забыл (хорошие) примеры из интернета и слишком никогда не пишу на чём-либо кроме Free Pascal, чтобы иметь свои, но (плохой) легко искусственно построить: https://godbolt.org/z/qhMozx3ba. Этот код меняет поведение, если убрать -fno-strict-aliasing, потому что компилятор начинает полагать возможным не перечитывать *i.
Тоже считаю restrict бесполезным, на следующем примере такого крайне частого и полностью им игнорируемого случая перекрытий, как полные совпадения, на который я на этот раз сам натыкался на пике 2. Рассмотрим функцию:
>void batch_add(float *a, float *b, size_t n, float *r),
выполняющую покомпонентное r[n] = a[n] + b[n]. То, что выходные буферы не должны перекрываться с входными, если это явно не разрешено — неписаное правило программирования (https://devblogs.microsoft.com/oldnewthing/20060320-13/?p=31853), но как раз для таких простых и поэлементно независимых функций, где это точно не будет конфликтовать с какими бы то ни было оптимизациями и позволит переиспользовать тот же код для in-place операций вида a[] += b[], естественно и удобно явно разрешать, чтобы r совпадало с a/b — и только совпадало, т. е. частичные перекрытия всё ещё запрещены. Restrict здесь неверен и разрешит компилятору, например, записать в вычисляемую ячейку r промежуточный результат, то есть реализовать r[і] = a[і] + b[і] как r[і] = a[і]; r[і] += b[і] (ну мало ли).


>Да и вообще в целом я ничего не хочу, всё бессмысленно, я не могу сделать ничего, чтобы произошло что-то хорошее, потому что не может ничего хорошего произойти даже в теории
Всё так и есть.


Это всё какой-то бред, я просто хотел, чтобы у поля были максимальные высота и ширина и чтобы клетки при этом оставались квадратными. Каждый раз как будто какую-то загадку решаешь, пытаясь перевести изначально императивные требования в эту шизоидную декларативную парадигму, в которой миллиард каких-то дебильных исключений, которые ещё и зависят от конкретного браузера.


Полностью пропало желание к этому прикасаться. Хотел попробовать переписать всё под какой-нибудь MVC или MVP, но в процессе понял, что я не понимаю, в чём смысл.
Если что, MVC - это когда фарш прокручивается по кругу:
- контроллер получает события от вью (клики по кнопкам, например)
- контроллер меняет модель, выполняя какую-то логику на ней
- вью подписан на изменения в модели и реагирует на них
А MVP - это когда модель и вью никак не связаны напрямую друг с другом и между ними есть связующая сущность в виде презентера, который подписан на изменения и в модели, и во вью. И он же сам руководит, что делать в разных ситуациях и модели, и вью.
Общее между ними и вообще смысл и того, и другого - это разделение кода на отдельные куски:
- кусок с обработкой действий юзера
- кусок с представлением данных
- кусок с логикой обработки данных и с самими данными
Но я пришёл к выводу, что не понимаю, а зачем это нужно. Всё, чего ты добиваешься, разделяя так код - что тебе из-за слабой связности приходится продумывать взаимодействие между компонентами и, возможно, писать дополнительный код для реализации этого взаимодействия. Всё из-за того, что находясь в одном компоненте, у тебя больше нету доступа напрямую к кишкам другого компонента. И ладно, это бы имело смысл, если бы была необходимость свопнуть реализацию одного компонента на другую, но в 80% случаев такой необходимости даже нету. И что хуже, наворачивая подобные абстракции, ты только усложняешь код и превращаешь его в большее спагетти, чем он был до этого.
Я всю дорогу выберу читать прямолинейное "спагетти", где перемешаны логика и представление, чем разбираться в реальном энтерпрайз-грейд спагетти из сотен классов и интерфейсов, которые друг в друга инжектятся, и читая код, ты толком не знаешь, какая конкретно реализация куда инжектится. И к тому же ещё, каждый отдельный класс выполняет только какую-то небольшую часть логики, не имеющую смысла в изоляции, и вот сидишь, пытаешься удержать в голове код, размазанный по десятку файлов и написанный суммарно несколькими разными людьми, и понять, почему он не делает того, что от него ожидается в одном конкретном эдж кейсе.
Попробовал сейчас добавить анимацию раскрытия клеток, не знаю. Ещё, до этого, я не говорил, мне пришлось заменить эмоджи и цифры на свг картинки, потому что их тупо проще ресайзить и центрировать внутри клеток, чем текст.
Если что, если указать font-size в процентах, то будут браться проценты не от ширины родителя, а от размера шрифта на родительском элементе (это к слову о том, насколько CSS анти-интуитивный кусок мусора), короче, то же самое, что em юниты. Альтернативно можно было бы использовать container queries (которые, как оказалось, уже работают во всех браузерах): там просто можно использовать cqw юниты.
У меня возникла необходимость сделать реверс прокси для одного апи и, короче, нужно было, чтобы оно работало по хттпс, чтобы браузер с ума не сходил. Но я не хотел покупать домен ради хттпс, плюс домены - это кринж примерно на уровне нфт.
Нашёл такое
https://duckdns.org
просто можно бесплатно создать поддомен и выставить там нужный IP, есть ещё похожие сайты, но этот вроде сейчас самый популярный.
Альтернативно есть ещё сайты по типу https://sslip.io, где IP вписывается прямо в поддомен, например: http://127-0-0-1.sslip.io, даже не надо регистрироваться. Но в этом также и минус, что домен завязан на айпи и если он изменится, то все существующие ссылки на сайт протухнут. Но, если у тебя просто веб страница, а не хттп апи, то можно создать страницу на любом сайте, который позволяет хостить хтмл страницы (гитхаб/тамблер/неоситис) с одним единственным <iframe>, в который вписан sslip поддомен, и, получается, быть самим себе днсом.
Полностью пропало желание к этому прикасаться. Хотел попробовать переписать всё под какой-нибудь MVC или MVP, но в процессе понял, что я не понимаю, в чём смысл.
Если что, MVC - это когда фарш прокручивается по кругу:
- контроллер получает события от вью (клики по кнопкам, например)
- контроллер меняет модель, выполняя какую-то логику на ней
- вью подписан на изменения в модели и реагирует на них
А MVP - это когда модель и вью никак не связаны напрямую друг с другом и между ними есть связующая сущность в виде презентера, который подписан на изменения и в модели, и во вью. И он же сам руководит, что делать в разных ситуациях и модели, и вью.
Общее между ними и вообще смысл и того, и другого - это разделение кода на отдельные куски:
- кусок с обработкой действий юзера
- кусок с представлением данных
- кусок с логикой обработки данных и с самими данными
Но я пришёл к выводу, что не понимаю, а зачем это нужно. Всё, чего ты добиваешься, разделяя так код - что тебе из-за слабой связности приходится продумывать взаимодействие между компонентами и, возможно, писать дополнительный код для реализации этого взаимодействия. Всё из-за того, что находясь в одном компоненте, у тебя больше нету доступа напрямую к кишкам другого компонента. И ладно, это бы имело смысл, если бы была необходимость свопнуть реализацию одного компонента на другую, но в 80% случаев такой необходимости даже нету. И что хуже, наворачивая подобные абстракции, ты только усложняешь код и превращаешь его в большее спагетти, чем он был до этого.
Я всю дорогу выберу читать прямолинейное "спагетти", где перемешаны логика и представление, чем разбираться в реальном энтерпрайз-грейд спагетти из сотен классов и интерфейсов, которые друг в друга инжектятся, и читая код, ты толком не знаешь, какая конкретно реализация куда инжектится. И к тому же ещё, каждый отдельный класс выполняет только какую-то небольшую часть логики, не имеющую смысла в изоляции, и вот сидишь, пытаешься удержать в голове код, размазанный по десятку файлов и написанный суммарно несколькими разными людьми, и понять, почему он не делает того, что от него ожидается в одном конкретном эдж кейсе.
Попробовал сейчас добавить анимацию раскрытия клеток, не знаю. Ещё, до этого, я не говорил, мне пришлось заменить эмоджи и цифры на свг картинки, потому что их тупо проще ресайзить и центрировать внутри клеток, чем текст.
Если что, если указать font-size в процентах, то будут браться проценты не от ширины родителя, а от размера шрифта на родительском элементе (это к слову о том, насколько CSS анти-интуитивный кусок мусора), короче, то же самое, что em юниты. Альтернативно можно было бы использовать container queries (которые, как оказалось, уже работают во всех браузерах): там просто можно использовать cqw юниты.
У меня возникла необходимость сделать реверс прокси для одного апи и, короче, нужно было, чтобы оно работало по хттпс, чтобы браузер с ума не сходил. Но я не хотел покупать домен ради хттпс, плюс домены - это кринж примерно на уровне нфт.
Нашёл такое
https://duckdns.org
просто можно бесплатно создать поддомен и выставить там нужный IP, есть ещё похожие сайты, но этот вроде сейчас самый популярный.
Альтернативно есть ещё сайты по типу https://sslip.io, где IP вписывается прямо в поддомен, например: http://127-0-0-1.sslip.io, даже не надо регистрироваться. Но в этом также и минус, что домен завязан на айпи и если он изменится, то все существующие ссылки на сайт протухнут. Но, если у тебя просто веб страница, а не хттп апи, то можно создать страницу на любом сайте, который позволяет хостить хтмл страницы (гитхаб/тамблер/неоситис) с одним единственным <iframe>, в который вписан sslip поддомен, и, получается, быть самим себе днсом.


Я на такой как будто более нормальный подход наткнулся:
https://www.exploringbinary.com/correct-decimal-to-floating-point-using-big-integers/
Здесь входное число представляется рациональным вида d / 10^D. Оно скейлится умножениями на 2 так, чтобы в его целой части было количество бит, соответствующее точности мантиссы, после чего делается длинное целочисленное деление, по остатку от которого можно понять, в какую сторону округлять, а само частное будет мантиссой распаршенного флоата.
Длинное деление одного многоциферного числа на другое сводится к нескольким делениям (N+1)-циферных чисел на N-циферное, причём таких, что частное - это всегда одна единственная цифра, но непонятно какая. У Кнута (том 2: 4.3.1) описывается хорошая верхняя оценка для этого частного - взять два старших разряда делимого и поделить на старший разряд делителя, но она работает только, если первая цифра у делимого >= floor(b / 2), где b - основание системы счисления. Такая оценка сама по себе будет максимум на 2 больше, чем настоящее частное, причём вне зависимости от системы счисления, то есть чем больше b, тем выгоднее использовать эту оценку. Любую пару делимое-делитель можно подогнать под условия оценки просто домножив их оба на что-нибудь.
Дополнительно он ещё выдумал быстрый способ чекнуть, является ли оценка частного однозначно слишком большой: взять первые два разряда от делителя, умножить их на оценку частного и если результат строго больше, чем первые три разряда от делимого, то настоящее частное строго меньше, чем такая оценка.
Доказательства оценки и этой дополнительной проверки, кстати, плюс-минус простые, но ощущаются немного, как будто они (доказательства) придуманы задним числом, особенно те, что от противного, но у меня почти всегда такие ощущения, когда читаю доказательства, потому что я тупой.
Например, при делении 528702984 на 76623621 оценка частного будет 52 / 7 = 7. То есть настоящее частное равно либо 5, либо 6, либо 7. Используем дополнительную проверку: 76 × 7 = 532 > 528, значит, 7 точно не подходит. Угадывание цифры сводится к угадыванию между 5 и 6.
Тот факт, что 76 × 6 = 456 <= 528 нам не говорит, что 6 - это частное, но в большинстве случаев - это так, причём чем больше b, тем меньше пар чисел, для которых первые три цифры делимого, поделенные на первые две цифры делителя будут отличаться от полноценного частного этих чисел. Но опять же, вот пример, когда это не работает: 536 357 684 / 76 623 621 = 6, несмотря на то, что 53 / 7 = 7 и 536 / 76 = 7.
Альтернативно, наверное, можно было бы делить в двоичной системе счисления, там не надо ничего угадывать, потому что на каждом шаге при вычислении следующей цифры частного у тебя выбор всего лишь между цифрами 0 и 1, но минус в том, что придётся обработать больше разрядов.
Ну, я, короче, захотел это сделать, но зачем-то начал с более простого варианта, с целых чисел, и подумал, что а тут так-то и длинное деление не нужно, можно просто сконвертировать в двоичную систему счисления, взять нужное количество старших битов оттуда, положить их в мантиссу, а по оставшимся младшим битам понять, куда округлять. Это я сделал конкретно для f32, а потом я подумал, что хочу абстрагировать этот код от конкретной битности мантиссы, ну, чтобы не повторять код парсинга f32 и f64. Начал писать функцию, которая в конечном счёте должна была бы по сути перекопировать N старших что-то значащих бит числа внутри массива из u32 (из входного инта в двоичной системе счисления) внутрь другого массива из u32 (в мантиссу) на нужное смещение, и я, короче, просто не смог написать её, потому что я запутался и я слишком тупой. Понятно, что эта функция не нужна, понятно, что надо было просто расписать копирование конкретного захардкоженного количества бит (под f32 и под f64) и не в какой-то абстрактный массив, а в одно u64 число, и это было бы лучше, проще и более производительно и так далее, но это не важно, просто я понял, что не уверен, что мой мозг вообще физически способен выдать код для этой функции. Я час сидел и в итоге просто всё стёр, даже не пытался запустить. Я хочу умереть, ну, буквально, я не вижу смысла так жить, я сначала весь день до этого разгребал какие-то джаваскрипты за копейки (потому что да, теперь я разгребаю джаваскрипты за копейки, потому что если я ещё раз услышу очередные душевыворачивающие издевательские докапывания родителей до себя, то я сразу же выйду в окно, лишь бы это дерьмо не слышать), чтобы потом сесть и в оставшиеся сколько-то часов времени ничего не сделать из-за того, что я слишком тупой, чтобы скопировать биты из одного места в другое.
Я уже не знаю, кем я себя ощущаю, это не рабство, а нахождение в бетонно-арматурной пыточной камере внутри гигантской тюрьмы в виде всего этого помойного города / страны / планеты. Уроды, которым нравится заниматься каким-то бессмысленным говном, построили общество, где тебя толкают к тому, чтобы ты тоже занимался бессмысленным говном. Я не верю в то, что в этом есть смысл, это просто статистически невозможно, чтобы даже половина людей занималась на работах чем-то осмысленным или полезным. Средний наркоман рэпер производит на порядок больше пользы выпуская один альбом, чем средний программист на зарплате за всю свою жизнь, работая в каких-то говноконторах по продаже какого-то говна каким-то дебилам. Завтра 80% людей не выйдут работать, у этого окей, наверняка будут последствия, не знаю, возможно, например, куча людей передохнут из-за того, что некому будет производить и завозить килотонны еды в крупные города, ну и дальше что, получается, это просто изначально гиблая затея была, раз для её поддержания нужно было расплодиться на сотни тысяч людей и чтобы абсолютное большинство из них по сути посвятило свои жизни поддержанию жизнеспособности крупных городов?
Печатанье флоатов я до этого тоже заново переписывал, но немного более успешно, я не стал там тот >>753616 подход использовать и пробовать печатать кратчайшее представление, отчасти потому что мне тогда вообще не понравилось втупую без понимания транслировать псевдокод в обычный код, хоть и как будто какой-то результат получился. Я, в общем, просто сделал тупой подход отсюда https://randomascii.wordpress.com/2012/03/08/float-precisionfrom-zero-to-100-digits-2/ и тупо сделал для него округление до заданной точности (округление сделал тоже тупо, уже после перевода в десятичную систему счисления, после полного "раскрытия" флоата в число с фиксированной точкой). Может быть, можно было бы попробовать похожий подход, как с парсингом и длинным делением, но звучит как переусложнение, обходились ведь без деления.
Вообще для печати ещё можно походу использовать double-double арифметику, по крайней мере так вроде бы делает stb_sprintf и в комментах автор пишет, что точности хватает для обратных преобразований во в точности изначальный флоат. Double-double арифметика - это, как я понял, такой хак, который позволяет числа с четверной точностью (но с тем же ренжем значений, как у даблов) реализовать через пару даблов, я не смотрел, как, но там вроде используется вот это: https://en.wikipedia.org/wiki/2Sum Через этот же приём можно уменьшить ошибку при сложении большого количества флоатов (Kahan summation), либо полностью устранить её (fsum из питона, но ему нужна дополнительная память).
Кстати, формула и таблица того, сколько цифр надо для преобразований без потерь для флоатов в разных системах счисления https://www.exploringbinary.com/number-of-digits-required-for-round-trip-conversions/
Я на такой как будто более нормальный подход наткнулся:
https://www.exploringbinary.com/correct-decimal-to-floating-point-using-big-integers/
Здесь входное число представляется рациональным вида d / 10^D. Оно скейлится умножениями на 2 так, чтобы в его целой части было количество бит, соответствующее точности мантиссы, после чего делается длинное целочисленное деление, по остатку от которого можно понять, в какую сторону округлять, а само частное будет мантиссой распаршенного флоата.
Длинное деление одного многоциферного числа на другое сводится к нескольким делениям (N+1)-циферных чисел на N-циферное, причём таких, что частное - это всегда одна единственная цифра, но непонятно какая. У Кнута (том 2: 4.3.1) описывается хорошая верхняя оценка для этого частного - взять два старших разряда делимого и поделить на старший разряд делителя, но она работает только, если первая цифра у делимого >= floor(b / 2), где b - основание системы счисления. Такая оценка сама по себе будет максимум на 2 больше, чем настоящее частное, причём вне зависимости от системы счисления, то есть чем больше b, тем выгоднее использовать эту оценку. Любую пару делимое-делитель можно подогнать под условия оценки просто домножив их оба на что-нибудь.
Дополнительно он ещё выдумал быстрый способ чекнуть, является ли оценка частного однозначно слишком большой: взять первые два разряда от делителя, умножить их на оценку частного и если результат строго больше, чем первые три разряда от делимого, то настоящее частное строго меньше, чем такая оценка.
Доказательства оценки и этой дополнительной проверки, кстати, плюс-минус простые, но ощущаются немного, как будто они (доказательства) придуманы задним числом, особенно те, что от противного, но у меня почти всегда такие ощущения, когда читаю доказательства, потому что я тупой.
Например, при делении 528702984 на 76623621 оценка частного будет 52 / 7 = 7. То есть настоящее частное равно либо 5, либо 6, либо 7. Используем дополнительную проверку: 76 × 7 = 532 > 528, значит, 7 точно не подходит. Угадывание цифры сводится к угадыванию между 5 и 6.
Тот факт, что 76 × 6 = 456 <= 528 нам не говорит, что 6 - это частное, но в большинстве случаев - это так, причём чем больше b, тем меньше пар чисел, для которых первые три цифры делимого, поделенные на первые две цифры делителя будут отличаться от полноценного частного этих чисел. Но опять же, вот пример, когда это не работает: 536 357 684 / 76 623 621 = 6, несмотря на то, что 53 / 7 = 7 и 536 / 76 = 7.
Альтернативно, наверное, можно было бы делить в двоичной системе счисления, там не надо ничего угадывать, потому что на каждом шаге при вычислении следующей цифры частного у тебя выбор всего лишь между цифрами 0 и 1, но минус в том, что придётся обработать больше разрядов.
Ну, я, короче, захотел это сделать, но зачем-то начал с более простого варианта, с целых чисел, и подумал, что а тут так-то и длинное деление не нужно, можно просто сконвертировать в двоичную систему счисления, взять нужное количество старших битов оттуда, положить их в мантиссу, а по оставшимся младшим битам понять, куда округлять. Это я сделал конкретно для f32, а потом я подумал, что хочу абстрагировать этот код от конкретной битности мантиссы, ну, чтобы не повторять код парсинга f32 и f64. Начал писать функцию, которая в конечном счёте должна была бы по сути перекопировать N старших что-то значащих бит числа внутри массива из u32 (из входного инта в двоичной системе счисления) внутрь другого массива из u32 (в мантиссу) на нужное смещение, и я, короче, просто не смог написать её, потому что я запутался и я слишком тупой. Понятно, что эта функция не нужна, понятно, что надо было просто расписать копирование конкретного захардкоженного количества бит (под f32 и под f64) и не в какой-то абстрактный массив, а в одно u64 число, и это было бы лучше, проще и более производительно и так далее, но это не важно, просто я понял, что не уверен, что мой мозг вообще физически способен выдать код для этой функции. Я час сидел и в итоге просто всё стёр, даже не пытался запустить. Я хочу умереть, ну, буквально, я не вижу смысла так жить, я сначала весь день до этого разгребал какие-то джаваскрипты за копейки (потому что да, теперь я разгребаю джаваскрипты за копейки, потому что если я ещё раз услышу очередные душевыворачивающие издевательские докапывания родителей до себя, то я сразу же выйду в окно, лишь бы это дерьмо не слышать), чтобы потом сесть и в оставшиеся сколько-то часов времени ничего не сделать из-за того, что я слишком тупой, чтобы скопировать биты из одного места в другое.
Я уже не знаю, кем я себя ощущаю, это не рабство, а нахождение в бетонно-арматурной пыточной камере внутри гигантской тюрьмы в виде всего этого помойного города / страны / планеты. Уроды, которым нравится заниматься каким-то бессмысленным говном, построили общество, где тебя толкают к тому, чтобы ты тоже занимался бессмысленным говном. Я не верю в то, что в этом есть смысл, это просто статистически невозможно, чтобы даже половина людей занималась на работах чем-то осмысленным или полезным. Средний наркоман рэпер производит на порядок больше пользы выпуская один альбом, чем средний программист на зарплате за всю свою жизнь, работая в каких-то говноконторах по продаже какого-то говна каким-то дебилам. Завтра 80% людей не выйдут работать, у этого окей, наверняка будут последствия, не знаю, возможно, например, куча людей передохнут из-за того, что некому будет производить и завозить килотонны еды в крупные города, ну и дальше что, получается, это просто изначально гиблая затея была, раз для её поддержания нужно было расплодиться на сотни тысяч людей и чтобы абсолютное большинство из них по сути посвятило свои жизни поддержанию жизнеспособности крупных городов?
Печатанье флоатов я до этого тоже заново переписывал, но немного более успешно, я не стал там тот >>753616 подход использовать и пробовать печатать кратчайшее представление, отчасти потому что мне тогда вообще не понравилось втупую без понимания транслировать псевдокод в обычный код, хоть и как будто какой-то результат получился. Я, в общем, просто сделал тупой подход отсюда https://randomascii.wordpress.com/2012/03/08/float-precisionfrom-zero-to-100-digits-2/ и тупо сделал для него округление до заданной точности (округление сделал тоже тупо, уже после перевода в десятичную систему счисления, после полного "раскрытия" флоата в число с фиксированной точкой). Может быть, можно было бы попробовать похожий подход, как с парсингом и длинным делением, но звучит как переусложнение, обходились ведь без деления.
Вообще для печати ещё можно походу использовать double-double арифметику, по крайней мере так вроде бы делает stb_sprintf и в комментах автор пишет, что точности хватает для обратных преобразований во в точности изначальный флоат. Double-double арифметика - это, как я понял, такой хак, который позволяет числа с четверной точностью (но с тем же ренжем значений, как у даблов) реализовать через пару даблов, я не смотрел, как, но там вроде используется вот это: https://en.wikipedia.org/wiki/2Sum Через этот же приём можно уменьшить ошибку при сложении большого количества флоатов (Kahan summation), либо полностью устранить её (fsum из питона, но ему нужна дополнительная память).
Кстати, формула и таблица того, сколько цифр надо для преобразований без потерь для флоатов в разных системах счисления https://www.exploringbinary.com/number-of-digits-required-for-round-trip-conversions/

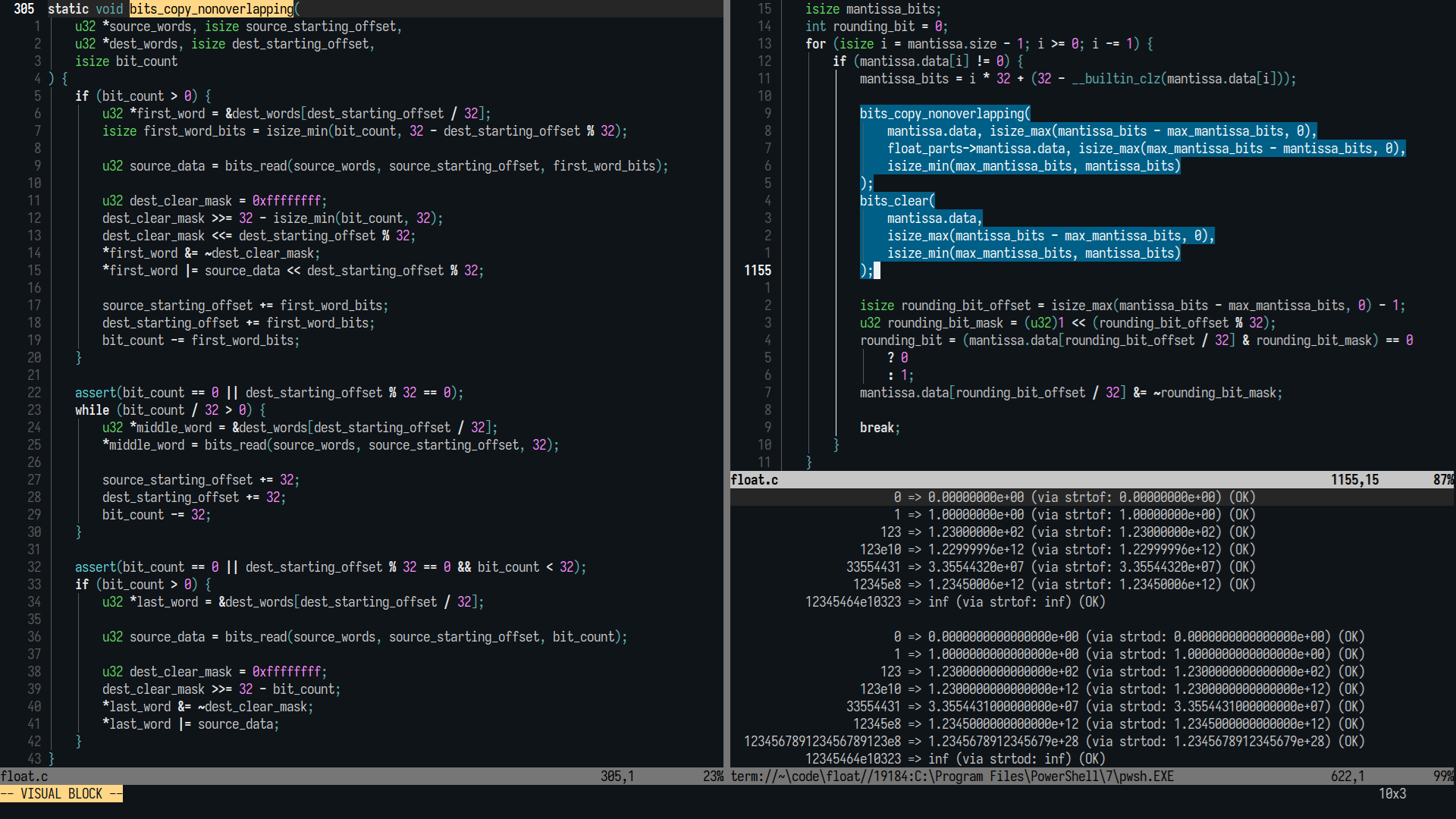

>Начал писать функцию, которая в конечном счёте должна была бы по сути перекопировать N старших что-то значащих бит числа внутри массива из u32 (из входного инта в двоичной системе счисления) внутрь другого массива из u32 (в мантиссу) на нужное смещение, и я, короче, просто не смог написать её, потому что я запутался и я слишком тупой.
Типа я мог бы написать что-то такое наивное, но, во-первых, это какое-то говно и тем не менее, даже для написания такого мне пришлось обложиться тестами, потому что я постоянно ошибался в процессе и путался, во-вторых, является говном сама эта идея с тем, чтобы настолько обобщать код для парсинга флоатов различной точности из строки (там безумно ужасный код и это при том, что я всё ещё только лишь делаю парсинг целых чисел), а в третьих, я хочу, чтобы все люди взяли и убили себя, пожалуйста?

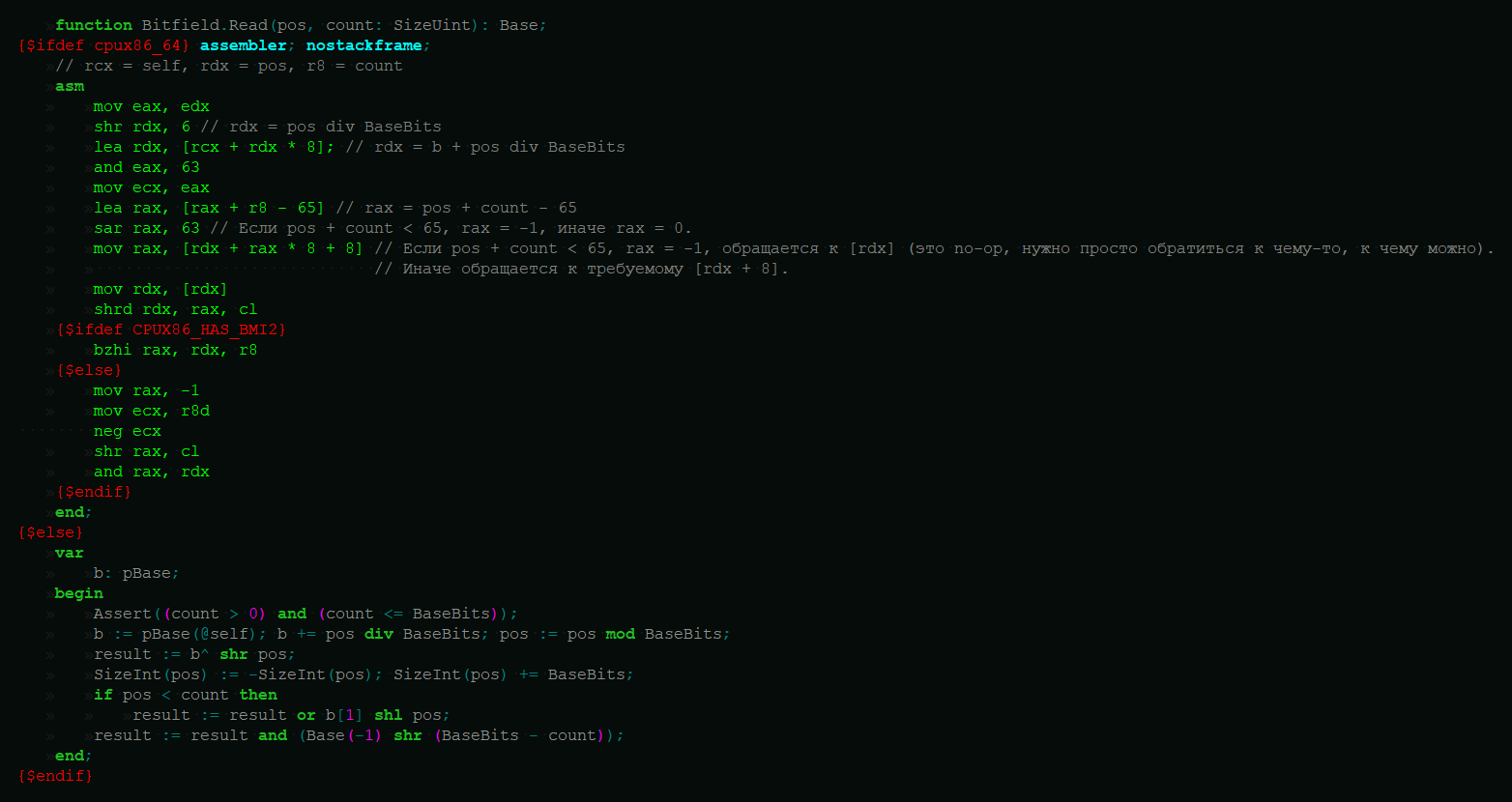
Я некоторое время назад в попытке сделать битовые поля более пригодными для массивов индексов сменного типа придумал клёвую реализацию того, что ты называешь bits_read. Для определённости положим, что базовый тип битового поля — 64 бита, и нужно читать значения от 1 до 64 бит. Для чтения COUNT бит с позиции POS:
— Выясняем, пересекает ли чтение границу ячейки, выставляем С1 = 0, если не пересекает, и C1 = 1, если пересекает. Автором предлагается нехитрая формула C1 = (POS % 64 + COUNT − 65) sar 7 + 1. (7 — сдвиг, достаточный, чтобы превратить все положительные числа в 0 и все отрицательные в −1. На скриншоте используется 63.)
— Составляем 128-битное число с младшей половинкой cells[POS / 64] и старшей cells[POS / 64 + C1].
— Сдвигаем это число вправо на POS % 64 и маскируем младшие COUNT бит.
То есть чтение старшей ячейки — безопасный (не залезающий в следующую ячейку) no-op, если она не нужна. Сейчас проверил, что GCC прекрасно работает с uint64/128 для шага 2 (в твоём случае достаточно 32/64, что упрощает задачу компилятору на x64 — не нужна инструкция SHRD).




Можешь, пожалуйста, съебать отсюда нахуй и чатиться в другом месте? Спасибо.
Недавно задумался о том, а будут ли считаться в плюсах константными мемберы класса, если пытаться их потрогать через константную ссылку на объект этого класса?
Просто в коде, который пишу, есть структура Number, внутри которой лежит указатель на цифры числа. И в сигнатурах функций, которые я пишу, иногда хотелось бы отражать то, что входные числа остаются неизменными. Отчасти для самодокументации, отчасти, чтобы совершать меньше тупых ошибок как на втором пике: изначально, видимо, хотел, чтобы разность писалась в result, но потом тупо забыл об этом и в итоге результат записал прямо в вычитаемое, а result даже не трогал.
В си, понятно, тут ничего не поделаешь, но в плюсах, как оказалось, константная ссылка почему-то не спасает и единственный способ добиться ошибки компиляции - это завернуть доступ к данным внутрь метода или перегруженного оператора. Не знаю, почему так сделали, не вижу буквально ни одной причины позволять компилироваться коду на 17 строке на третьем пике.
В расте, кстати, эквивалентный пример работает так, как я считаю было бы правильным.

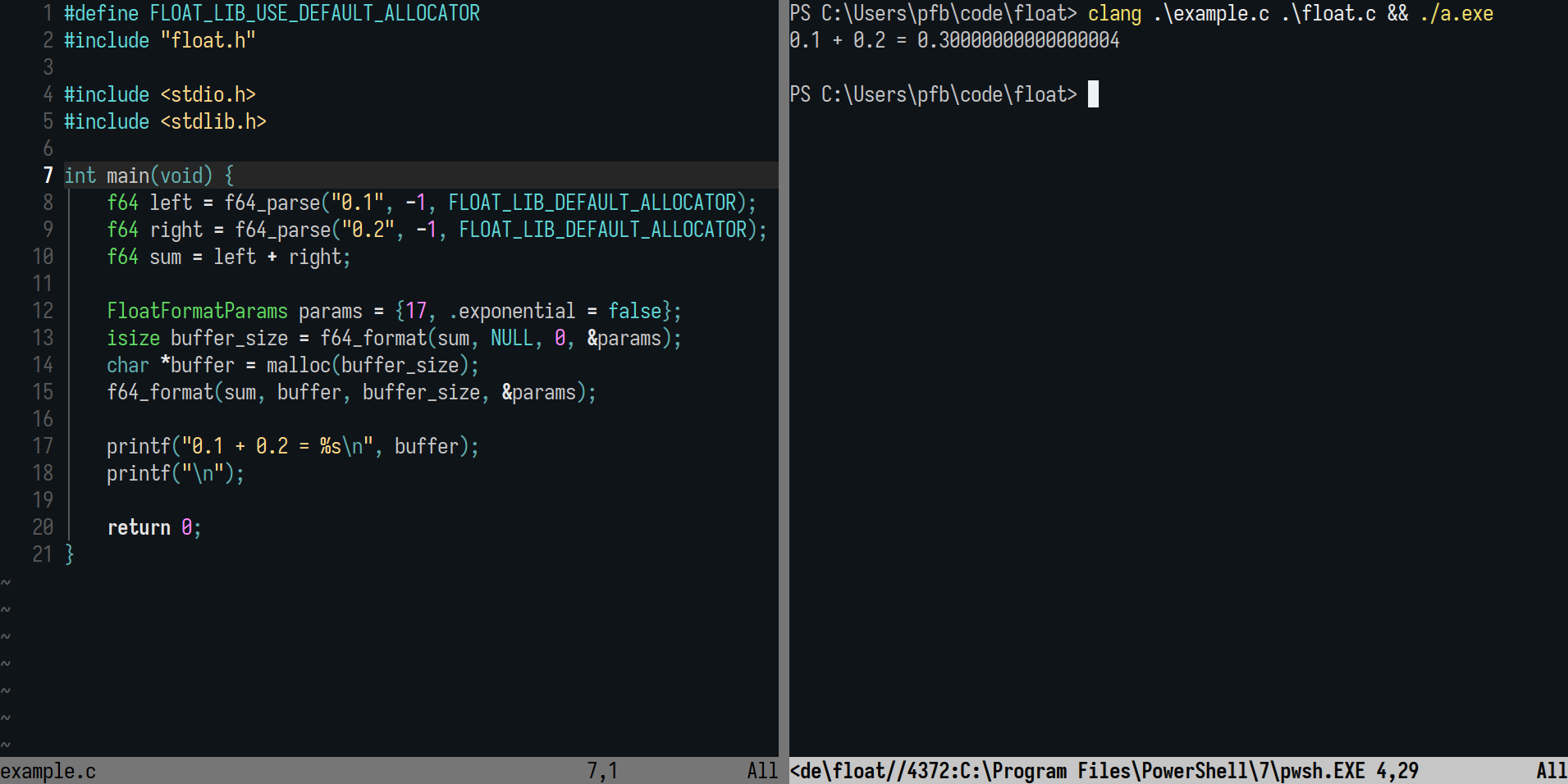
Как будто дописал парсинг в том числе для дробных чисел, не особо проверял, но вроде работает. Там основная сложность для меня была - это длинное деление написать, а код его использующий - более-менее короткий получается.
Единственное, я как-то поздно осознал, что для обобщёной функции float_parse (которая используется как для парсинга 32-битных, так и 64-битных флоатов) недостаточно знать только, сколько бит мантиссы ей нужно сгенерировать, ей нужно также знать минимальное значение экспоненты. Иначе, например, для даблов она всегда будет генерировать 53 бита, даже в случае денормализованных флоатов. То есть снаружи придётся округлять до меньшего количества битов, когда экспонента меньше минимальной, но это не получится корректно сделать, потому что выйдя из функции, ты уже потерял информацию о том, какие там были биты за пределами этих сгенерированных 53 бит мантиссы. Если что, под "сгенерировать N бит мантиссы" я имею в виду найти N-битное целое число с единицей в старшем бите, такое, что умножив его на 2^E, ты бы получил ~входное число.
Но вроде как это всё просто решается тем, чтобы прокинуть минимальную экспоненту и ограничить ею то, на какую степень двойки можно максимум заскейлить входную дробь d / 10^D, чтобы частное числителя и знаменателя в итоге содержало нужное количество бит. Там даже получается, что автоматически хендлится случай с андерфлоу в 0: когда минимальная экспонента не позволяет заскейлить дробь d / 10^D даже, чтобы она была больше единицы, то частное будет 0, но с помощью достаточно большого остатка всё ещё можно округлиться наверх.
Деление не стал полноценно как у кнута реализовывать, только использую его верхнюю оценку через две цифры делимого и одну цифру делителя, а дальше перебором вниз нахожу первое попавшееся число, которое после умножения на делитель даёт что-то меньшее, чем делимое. Этот момент - далеко даже не первый кандидат на улучшение, там в целом код ужасный, много аллокаций, которых можно было бы, наверное, если не избежать, то хотя бы заранее рассчитать их суммарный размер в пике и выделить одним куском? По возможности этот один кусок выделить на стеке, если он достаточно маленький?
Ну а ещё там возведение 10 в степень сделано тупым последовательным умножением, но это ещё отчасти потому что я не уверен, как сделать умный вариант без дополнительной памяти? Просто, умножая в столбик, тебе нужно несколько раз пройтись по верхнему числу, из-за чего ты не можешь в него же писать результат, выходит, как будто результат надо в отдельное место писать.
Как будто дописал парсинг в том числе для дробных чисел, не особо проверял, но вроде работает. Там основная сложность для меня была - это длинное деление написать, а код его использующий - более-менее короткий получается.
Единственное, я как-то поздно осознал, что для обобщёной функции float_parse (которая используется как для парсинга 32-битных, так и 64-битных флоатов) недостаточно знать только, сколько бит мантиссы ей нужно сгенерировать, ей нужно также знать минимальное значение экспоненты. Иначе, например, для даблов она всегда будет генерировать 53 бита, даже в случае денормализованных флоатов. То есть снаружи придётся округлять до меньшего количества битов, когда экспонента меньше минимальной, но это не получится корректно сделать, потому что выйдя из функции, ты уже потерял информацию о том, какие там были биты за пределами этих сгенерированных 53 бит мантиссы. Если что, под "сгенерировать N бит мантиссы" я имею в виду найти N-битное целое число с единицей в старшем бите, такое, что умножив его на 2^E, ты бы получил ~входное число.
Но вроде как это всё просто решается тем, чтобы прокинуть минимальную экспоненту и ограничить ею то, на какую степень двойки можно максимум заскейлить входную дробь d / 10^D, чтобы частное числителя и знаменателя в итоге содержало нужное количество бит. Там даже получается, что автоматически хендлится случай с андерфлоу в 0: когда минимальная экспонента не позволяет заскейлить дробь d / 10^D даже, чтобы она была больше единицы, то частное будет 0, но с помощью достаточно большого остатка всё ещё можно округлиться наверх.
Деление не стал полноценно как у кнута реализовывать, только использую его верхнюю оценку через две цифры делимого и одну цифру делителя, а дальше перебором вниз нахожу первое попавшееся число, которое после умножения на делитель даёт что-то меньшее, чем делимое. Этот момент - далеко даже не первый кандидат на улучшение, там в целом код ужасный, много аллокаций, которых можно было бы, наверное, если не избежать, то хотя бы заранее рассчитать их суммарный размер в пике и выделить одним куском? По возможности этот один кусок выделить на стеке, если он достаточно маленький?
Ну а ещё там возведение 10 в степень сделано тупым последовательным умножением, но это ещё отчасти потому что я не уверен, как сделать умный вариант без дополнительной памяти? Просто, умножая в столбик, тебе нужно несколько раз пройтись по верхнему числу, из-за чего ты не можешь в него же писать результат, выходит, как будто результат надо в отдельное место писать.



Отчасти вина на убогом шизоидном апи моего гиф энкодера (ну, то есть всё ещё на мне), которое, как оказалось, на практике использовать максимально неприятно, особенно, когда смотришь на него в первый раз спустя несколько месяцев. Я, наверное, пришёл к выводу, что самый нормальный способ абстрагироваться от IO - это просто делать коллбэки, как в stb_image и stb_image_write. А не вот этот бред с функцией, которая пишет в буфер, который ты ей даёшь, и ты дёргаешь её до тех пор, пока она не выплюнет из себя все байты.

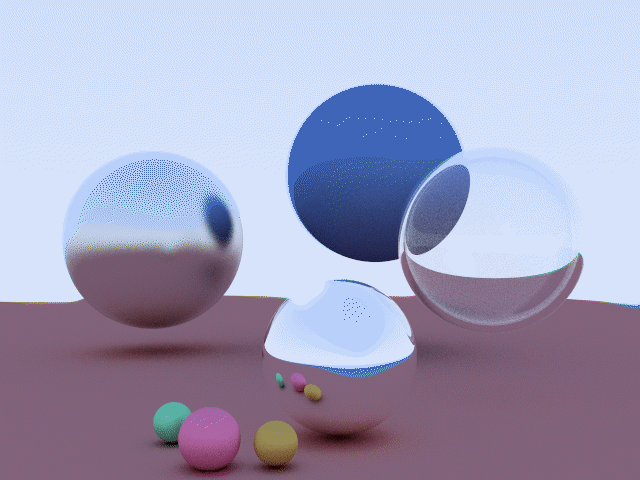

Обнаружил, что алгоритм, который я использовал для генерации палитры (median cut), генерирует довольно убогие палитры и это плохо синергирует с тем, что похоже error diffusion дизерингу не особо такое нравится и в итоге получается всратый результат как на втором пике. Я так понял, проблема в том, что палитра не накрывает все цвета в картинке? Потому что если палитра, например, чёрно-белая или как на третьем пике (все 216 комбинаций 0x00, 0x33, ..., 0xff), то всё в порядке.
Я не знаю, может быть, можно как-то растянуть сгенерированную палитру, либо наоборот: ужать или заклампить цвета в картинке, чтобы дизеринг мог нормально отработать, не пробовал.
Либо попробовать сам median cut улучшить, типа, я сейчас пополам делю, но вот тут:
http://www.leptonica.org/color-quantization.html
http://leptonica.org/papers/mediancut.pdf
как я понял, вместо этого предлагают посмотреть на два диапазона, которые получаются после разделения медианой, взять тот, где больше разброс минимальное/максимальное значение (по выбранной компоненте цвета), и в качестве разделения взять его середину. Таким образом разбиение будет смещаться в сторону к менее плотно наполненным различными цветами участкам.
Это должно контрить ситуацию, когда, например, в картинке много различных оттенков синего и есть одна большая, но одноцветная красная клякса. И если делить по медиане, то красный цвет перемешается с синими, потому что медиана будет смещена в сторону кластера синих цветов из-за того, насколько их много. Из-за чего красная клякса возможно поменяет свой цвет на синий.
Там не только этой идеей реализация отличается, там вообще полностью всё другое: компоненты цвета квантизируются до 5 бит во время разбиений боксов в цветовом пространстве и во время усреднения цветов в конце (но это, скорее всего, только для оптимизации). И приоритет выбора следующего бокса для разбиения может зависеть как от количества в нём различных цветов, так и от его объёма.
Попробовал ещё сейчас ordered дизеринг, он должен для любой палитры как будто работать, но как будто получается прикольнее фиксированные палитры делать. Не уверен, что правильно написал, просто посмотреть хотел.
Обнаружил, что алгоритм, который я использовал для генерации палитры (median cut), генерирует довольно убогие палитры и это плохо синергирует с тем, что похоже error diffusion дизерингу не особо такое нравится и в итоге получается всратый результат как на втором пике. Я так понял, проблема в том, что палитра не накрывает все цвета в картинке? Потому что если палитра, например, чёрно-белая или как на третьем пике (все 216 комбинаций 0x00, 0x33, ..., 0xff), то всё в порядке.
Я не знаю, может быть, можно как-то растянуть сгенерированную палитру, либо наоборот: ужать или заклампить цвета в картинке, чтобы дизеринг мог нормально отработать, не пробовал.
Либо попробовать сам median cut улучшить, типа, я сейчас пополам делю, но вот тут:
http://www.leptonica.org/color-quantization.html
http://leptonica.org/papers/mediancut.pdf
как я понял, вместо этого предлагают посмотреть на два диапазона, которые получаются после разделения медианой, взять тот, где больше разброс минимальное/максимальное значение (по выбранной компоненте цвета), и в качестве разделения взять его середину. Таким образом разбиение будет смещаться в сторону к менее плотно наполненным различными цветами участкам.
Это должно контрить ситуацию, когда, например, в картинке много различных оттенков синего и есть одна большая, но одноцветная красная клякса. И если делить по медиане, то красный цвет перемешается с синими, потому что медиана будет смещена в сторону кластера синих цветов из-за того, насколько их много. Из-за чего красная клякса возможно поменяет свой цвет на синий.
Там не только этой идеей реализация отличается, там вообще полностью всё другое: компоненты цвета квантизируются до 5 бит во время разбиений боксов в цветовом пространстве и во время усреднения цветов в конце (но это, скорее всего, только для оптимизации). И приоритет выбора следующего бокса для разбиения может зависеть как от количества в нём различных цветов, так и от его объёма.
Попробовал ещё сейчас ordered дизеринг, он должен для любой палитры как будто работать, но как будто получается прикольнее фиксированные палитры делать. Не уверен, что правильно написал, просто посмотреть хотел.




Немного думал над тем, как быть с рехешем хеш-сетов при условии, что память аллоцируется через арену. Конкретно в контексте того, чтобы выбрать уникальные цвета из картинки, чтобы алгоритму подбора палитры не надо было пережёвывать больше входных данных, чем нужно.
Неприятность в том, что массив бакетов нельзя просто расширить, нужно именно сначала создать новый, перенести все элементы из старого в новый, и это как-то плохо стакуется с идеей линейно аллоцировать память. Ну, вроде бы есть какое-то "линейное хеширование", но я не смотрел особо, что это.
Была в мыслях шизовая идея делать хеш-сет с бакетами на связных списках вместо открытой адресации, чтобы во время рехеша можно было собрать все бакеты в один большой связный список и потом перераспределить по ячейкам (то есть память под сами элементы, хранимые в хеш-сете, выделяется единожды). Ячейки были бы сущностями как бы отдельными от бакетов: это массив указателей на бакеты, которые ставят соответствие между хешкодом и бакетами. Массив ячеек можно было бы представить как массив, разбитый на куски с размерами 2^0, 2^1, 2^2, ..., 2^63, то есть расширение такого массива - это просто аллокация нового куска.
Но это всё не имеет смысла из-за того, что для реализации нужно как минимум +8 байтов на каждый элемент хеш-сета для хранения указателя next, а размер хранимых элементов в моём случае - это и так всего лишь 12 байтов (3 флоата для представления цвета). Короче, что толку, что мы можем всё сделать как бы in-place, если для этого нужно столько же дополнительной памяти, сколько выбрасывается в мусорку, когда мы просто выбрасываем старые хеш-сеты после рехеша. Может быть, можно было бы ужаться, если вместо указателей использовать 16/32-битные индексы, но я, короче, решил забить и единственное, что сделал - пытаюсь по возможности переиспользовать постепенно растущий кусок свободной памяти, образующийся после рехешей.
Ещё плюс открытой адресации в сочетании с тем, что твои бакеты - это просто сами значения, хранимые в таблице (пустые бакеты обозначаются каким-то специальным значением), это то, операция сбора элементов хеш-сета в один плотный массив просто in-place делается. Ну, тебе просто надо выпилить все "пустые" значения и всё. Я не знаю, почему я это в упор не заметил, когда ещё писал median-cut и там тоже надо было выбрать уникальные цвета.
Идею с кусочным массивом всё же использовал, для того, чтобы сохранять разбиение цветов на кластеры, потому что там получается ситуация, что мы одновременно пушим цвета в K различных динамических массивов (один под каждый кластер). Правда, сейчас я понял, что это тупая идея и здесь тоже: я мог бы просто рядом с цветом хранить то, какому кластеру он принадлежит сейчас, нет смысла хранить эту информацию в каком-то отдельном списке из списков. Когда вычисляешь новые центроиды, то вместо того, чтобы отдельно проходиться по цветам из каждого кластера, суммируешь цвета параллельно по всем кластерам.
Не особо понял, когда заканчивать итерации в k-means, я сейчас просто суммирую то, на сколько изменилось количество цветов в каждом кластере с предыдущей итерации и завершаю алгоритм, если это количество меньше скольки-то процентов от общего числа цветов. Не уверен, что это правильно.
Немного думал над тем, как быть с рехешем хеш-сетов при условии, что память аллоцируется через арену. Конкретно в контексте того, чтобы выбрать уникальные цвета из картинки, чтобы алгоритму подбора палитры не надо было пережёвывать больше входных данных, чем нужно.
Неприятность в том, что массив бакетов нельзя просто расширить, нужно именно сначала создать новый, перенести все элементы из старого в новый, и это как-то плохо стакуется с идеей линейно аллоцировать память. Ну, вроде бы есть какое-то "линейное хеширование", но я не смотрел особо, что это.
Была в мыслях шизовая идея делать хеш-сет с бакетами на связных списках вместо открытой адресации, чтобы во время рехеша можно было собрать все бакеты в один большой связный список и потом перераспределить по ячейкам (то есть память под сами элементы, хранимые в хеш-сете, выделяется единожды). Ячейки были бы сущностями как бы отдельными от бакетов: это массив указателей на бакеты, которые ставят соответствие между хешкодом и бакетами. Массив ячеек можно было бы представить как массив, разбитый на куски с размерами 2^0, 2^1, 2^2, ..., 2^63, то есть расширение такого массива - это просто аллокация нового куска.
Но это всё не имеет смысла из-за того, что для реализации нужно как минимум +8 байтов на каждый элемент хеш-сета для хранения указателя next, а размер хранимых элементов в моём случае - это и так всего лишь 12 байтов (3 флоата для представления цвета). Короче, что толку, что мы можем всё сделать как бы in-place, если для этого нужно столько же дополнительной памяти, сколько выбрасывается в мусорку, когда мы просто выбрасываем старые хеш-сеты после рехеша. Может быть, можно было бы ужаться, если вместо указателей использовать 16/32-битные индексы, но я, короче, решил забить и единственное, что сделал - пытаюсь по возможности переиспользовать постепенно растущий кусок свободной памяти, образующийся после рехешей.
Ещё плюс открытой адресации в сочетании с тем, что твои бакеты - это просто сами значения, хранимые в таблице (пустые бакеты обозначаются каким-то специальным значением), это то, операция сбора элементов хеш-сета в один плотный массив просто in-place делается. Ну, тебе просто надо выпилить все "пустые" значения и всё. Я не знаю, почему я это в упор не заметил, когда ещё писал median-cut и там тоже надо было выбрать уникальные цвета.
Идею с кусочным массивом всё же использовал, для того, чтобы сохранять разбиение цветов на кластеры, потому что там получается ситуация, что мы одновременно пушим цвета в K различных динамических массивов (один под каждый кластер). Правда, сейчас я понял, что это тупая идея и здесь тоже: я мог бы просто рядом с цветом хранить то, какому кластеру он принадлежит сейчас, нет смысла хранить эту информацию в каком-то отдельном списке из списков. Когда вычисляешь новые центроиды, то вместо того, чтобы отдельно проходиться по цветам из каждого кластера, суммируешь цвета параллельно по всем кластерам.
Не особо понял, когда заканчивать итерации в k-means, я сейчас просто суммирую то, на сколько изменилось количество цветов в каждом кластере с предыдущей итерации и завершаю алгоритм, если это количество меньше скольки-то процентов от общего числа цветов. Не уверен, что это правильно.
 5,1 Мб, 1835x2595
5,1 Мб, 1835x2595Подход из >>544995 → НЕ СЛОЖНЕЕ и строит (в отсутствие удалений) плотный массив с цветами СРАЗУ. Помимо этого, применительно к твоему случаю:
— Пустые элементы обозначаются специальным индексом (положим, −1; или 0 со сдвигом всех индексов на +1). Изначальный такой пустой массив индексов можно заполнить через memset (полагая битовым паттерном многобайтовых нулей очевидные «все нули», или многобайтовых минус единиц менее очевидные «все единицы»). Это эквивалент «невозможного» значения, как NaN является «невозможным» значением для цвета, но с этим не нужно полагаться на то, что у самих цветов вообще есть «невозможное» значение, тем более NaN.
— Только массив индексов должен быть овераллоцирован на множитель вроде 3/2, массив цветов может иметь и ровно требуемый размер. Хэш-таблица с максимальными 224 цветов в твоём случае займёт (4 × 3) × 224 × (3 / 2) = 288 Мб, с индексами, полагая int32 — 4 × 224 × (3 / 2) + (4 × 3) × 224 = тоже 288 Мб. (Если хранить цвета по-человечески в 4 байтах — 3 байта на цвет + дополнительный байт на представление пустой ячейки — индексы становятся хуже, но не очень сильно и см. следующий пункт.)
— Вариант с индексами позволяет сделать оба массива, индексов и цветов, «чанкнутыми», и рехэшировать на месте, благодаря тому, что массив индексов можно полностью восстановить из массива цветов. Для рехэша мы просто расширяем оба массива, стираем все индексы, и перестраиваем их.
Попробовал сделать сам: https://godbolt.org/z/fxnMdhrTr. В части построения «чанкнутого» массива со случайным доступом это использует мою крутую идею из https://gitlab.com/freepascal.org/fpc/source/-/blob/21fe99bfccf56bdb4c765b5d0dd5c4629c9eca92/rtl/inc/heap.inc#L229!!! :> (просто, согласно моему телепатическому модулю, ты посчитал это невозможным, Я ПРАВ?), и у меня это даже НЕ МЕДЛЕННЕЕ обычных массивов. (Ну, было вдвое медленнее, но потом я заменил код вида
>with ChunkedArray.DecomposeGlobalIndex(iIndex) do carr[chunkIndex][indexInChunk] := ...;
на
>dec := ChunkedArray.DecomposeGlobalIndex(iIndex);
>carr[dec.chunkIndex][dec.indexInChunk] := ...;
и стало прям ровно как с обычными массивами, так что, скорее всего, это причуды кодогенератора FPC в отношении никем не используемого оператора with.)
5,1 Мб, 1835x2595Подход из >>544995 → НЕ СЛОЖНЕЕ и строит (в отсутствие удалений) плотный массив с цветами СРАЗУ. Помимо этого, применительно к твоему случаю:
— Пустые элементы обозначаются специальным индексом (положим, −1; или 0 со сдвигом всех индексов на +1). Изначальный такой пустой массив индексов можно заполнить через memset (полагая битовым паттерном многобайтовых нулей очевидные «все нули», или многобайтовых минус единиц менее очевидные «все единицы»). Это эквивалент «невозможного» значения, как NaN является «невозможным» значением для цвета, но с этим не нужно полагаться на то, что у самих цветов вообще есть «невозможное» значение, тем более NaN.
— Только массив индексов должен быть овераллоцирован на множитель вроде 3/2, массив цветов может иметь и ровно требуемый размер. Хэш-таблица с максимальными 224 цветов в твоём случае займёт (4 × 3) × 224 × (3 / 2) = 288 Мб, с индексами, полагая int32 — 4 × 224 × (3 / 2) + (4 × 3) × 224 = тоже 288 Мб. (Если хранить цвета по-человечески в 4 байтах — 3 байта на цвет + дополнительный байт на представление пустой ячейки — индексы становятся хуже, но не очень сильно и см. следующий пункт.)
— Вариант с индексами позволяет сделать оба массива, индексов и цветов, «чанкнутыми», и рехэшировать на месте, благодаря тому, что массив индексов можно полностью восстановить из массива цветов. Для рехэша мы просто расширяем оба массива, стираем все индексы, и перестраиваем их.
Попробовал сделать сам: https://godbolt.org/z/fxnMdhrTr. В части построения «чанкнутого» массива со случайным доступом это использует мою крутую идею из https://gitlab.com/freepascal.org/fpc/source/-/blob/21fe99bfccf56bdb4c765b5d0dd5c4629c9eca92/rtl/inc/heap.inc#L229!!! :> (просто, согласно моему телепатическому модулю, ты посчитал это невозможным, Я ПРАВ?), и у меня это даже НЕ МЕДЛЕННЕЕ обычных массивов. (Ну, было вдвое медленнее, но потом я заменил код вида
>with ChunkedArray.DecomposeGlobalIndex(iIndex) do carr[chunkIndex][indexInChunk] := ...;
на
>dec := ChunkedArray.DecomposeGlobalIndex(iIndex);
>carr[dec.chunkIndex][dec.indexInChunk] := ...;
и стало прям ровно как с обычными массивами, так что, скорее всего, это причуды кодогенератора FPC в отношении никем не используемого оператора with.)



Я в флоатах цвета уникальные искал, потому что я думал, что типа раз я условно нагенерил пикселей в каком-нибудь линейном sRGB, то и палитру тоже лучше подбирать в этом самом же цветовом пространстве сразу, но, наверное, это мало смысла имеет, потому что в итоге же всё равно в нелинейный sRGB всё сохраняется. То есть просто сидишь зря перевариваешь мусорные чуть-чуть отличающиеся значения, которые после всех манипуляций в любом случае в одно и то же значение замаппятся в нелинейном sRGB, в общем, бред.
И ещё я не особо даже задумался о несостыковках с хешированием флоатов: должны ли отличаться хеши у 0.0 и -0.0, что делать с добавлением NaN-ов, которые сами себе не равны, но, правда, в моём случае это не особо было важно, я думаю.
В принципе прикольно, мне кажется, прикольно ещё, что таким подходом с индексами можно собирать уникальные значения прямо в тот же самый массив, откуда читаешь входные данные.
>>814644
Я не додумался, что можно было просто заклампить ошибку, которая распространяется на соседние пиксели, чтобы не возникали эти артефакты при дизеринге.
Попробовал немного изменённый вариант median cut сделать по описанию отсюда (MMCQ):
https://tpgit.github.io/Leptonica/colorquant2_8c.html
Он сам по себе от артефактов при дизеринге всё же не помогает, всё ещё нужно клампить ошибку. Но вроде бы чуть лучше палитру выдаёт, чем та версия median cut, которая у меня была до этого. В основном за счёт того, что деление коробок в цветовом пространстве делается не по медиане, а со смещением в часть коробки, где меньше плотность цветов, благодаря чему мелкие кластеры цветов меньше страдают от смешивания с цветами из более крупных кластеров. На пикриле три видно, что мелкие цветные шары стали более блеклыми, это из-за этого, я думаю. На пикриле четыре как будто получше.
Там ещё есть тема с тем, что поначалу при делении коробок на куски в приоритете выбираются коробки с наибольшим количеством цветов, а потом в определённый момент также дополнительно начинает учитываться объём коробок: большие коробки с большим количеством цветов выбираются для деления первее остальных. Но это как будто имеет окологомеопатический эффект.
Я тут обе версии median cut делаю в нелинейном sRGB. Для новой версии особо нет выбора, потому что там в реализации вместо сортировок я квантую цвета до 6 бит и сохраняю в массив из 2^18 элементов, сколько цветов в какой микрокубик попало. То есть для нахождения медианы у коробки вдоль какой-то оси нужно идти вдоль неё и суммировать количество цветов в поперечных сечениях коробки до тех пор, пока не наберёшь половину от всех цветов в коробке.
Это как будто местами быстрее, чем бесконечные qsort, местами наоборот внезапно медленнее, видимо, из-за необходимости изначально построить тот массив с записью количества цветов в каждом мелком кубике? Не знаю, возможно, я бред какой-то написал и можно было бы проще, я не читал код библиотеки, откуда я эту всю идею украл, но вроде бы по описаниям там плюс-минус так же сделано.
А дизеринг я делаю в oklab, в lab мне как-то меньше нравится результат. До 16 цветов ограничивается палитра на каждой из трёх картинок. Какая-то хуета, получилась, если честно.
Я в флоатах цвета уникальные искал, потому что я думал, что типа раз я условно нагенерил пикселей в каком-нибудь линейном sRGB, то и палитру тоже лучше подбирать в этом самом же цветовом пространстве сразу, но, наверное, это мало смысла имеет, потому что в итоге же всё равно в нелинейный sRGB всё сохраняется. То есть просто сидишь зря перевариваешь мусорные чуть-чуть отличающиеся значения, которые после всех манипуляций в любом случае в одно и то же значение замаппятся в нелинейном sRGB, в общем, бред.
И ещё я не особо даже задумался о несостыковках с хешированием флоатов: должны ли отличаться хеши у 0.0 и -0.0, что делать с добавлением NaN-ов, которые сами себе не равны, но, правда, в моём случае это не особо было важно, я думаю.
В принципе прикольно, мне кажется, прикольно ещё, что таким подходом с индексами можно собирать уникальные значения прямо в тот же самый массив, откуда читаешь входные данные.
>>814644
Я не додумался, что можно было просто заклампить ошибку, которая распространяется на соседние пиксели, чтобы не возникали эти артефакты при дизеринге.
Попробовал немного изменённый вариант median cut сделать по описанию отсюда (MMCQ):
https://tpgit.github.io/Leptonica/colorquant2_8c.html
Он сам по себе от артефактов при дизеринге всё же не помогает, всё ещё нужно клампить ошибку. Но вроде бы чуть лучше палитру выдаёт, чем та версия median cut, которая у меня была до этого. В основном за счёт того, что деление коробок в цветовом пространстве делается не по медиане, а со смещением в часть коробки, где меньше плотность цветов, благодаря чему мелкие кластеры цветов меньше страдают от смешивания с цветами из более крупных кластеров. На пикриле три видно, что мелкие цветные шары стали более блеклыми, это из-за этого, я думаю. На пикриле четыре как будто получше.
Там ещё есть тема с тем, что поначалу при делении коробок на куски в приоритете выбираются коробки с наибольшим количеством цветов, а потом в определённый момент также дополнительно начинает учитываться объём коробок: большие коробки с большим количеством цветов выбираются для деления первее остальных. Но это как будто имеет окологомеопатический эффект.
Я тут обе версии median cut делаю в нелинейном sRGB. Для новой версии особо нет выбора, потому что там в реализации вместо сортировок я квантую цвета до 6 бит и сохраняю в массив из 2^18 элементов, сколько цветов в какой микрокубик попало. То есть для нахождения медианы у коробки вдоль какой-то оси нужно идти вдоль неё и суммировать количество цветов в поперечных сечениях коробки до тех пор, пока не наберёшь половину от всех цветов в коробке.
Это как будто местами быстрее, чем бесконечные qsort, местами наоборот внезапно медленнее, видимо, из-за необходимости изначально построить тот массив с записью количества цветов в каждом мелком кубике? Не знаю, возможно, я бред какой-то написал и можно было бы проще, я не читал код библиотеки, откуда я эту всю идею украл, но вроде бы по описаниям там плюс-минус так же сделано.
А дизеринг я делаю в oklab, в lab мне как-то меньше нравится результат. До 16 цветов ограничивается палитра на каждой из трёх картинок. Какая-то хуета, получилась, если честно.

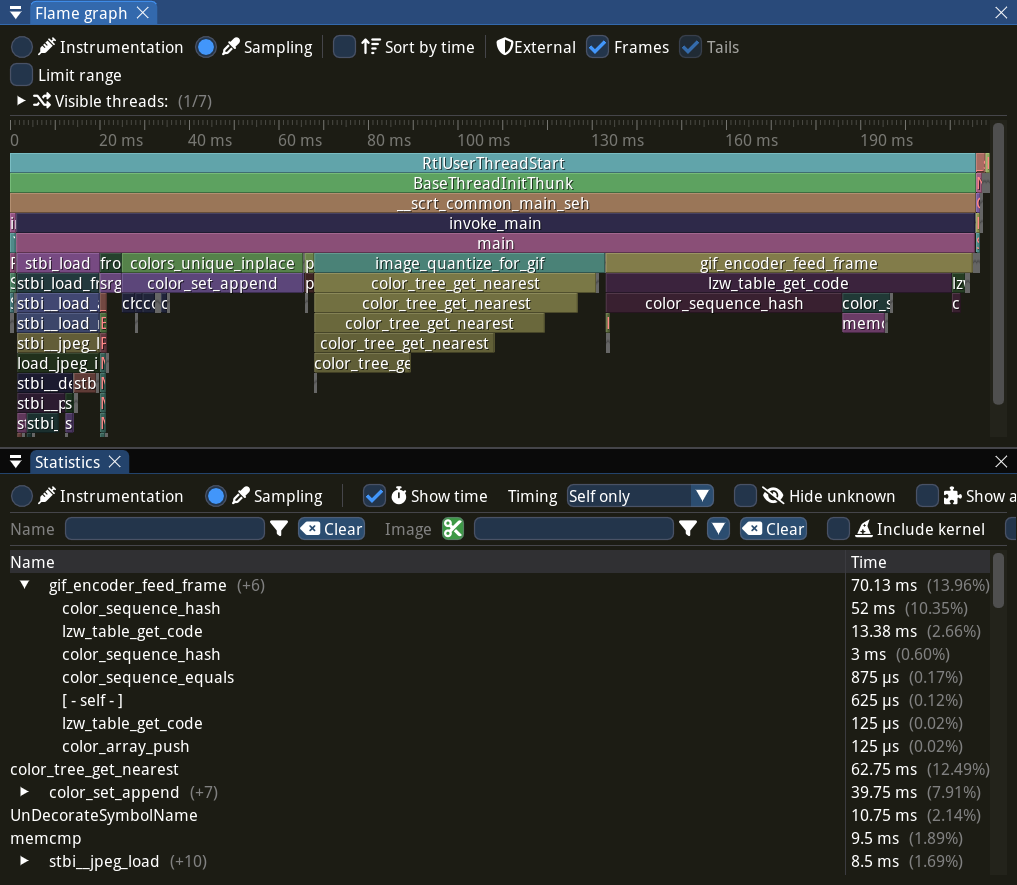
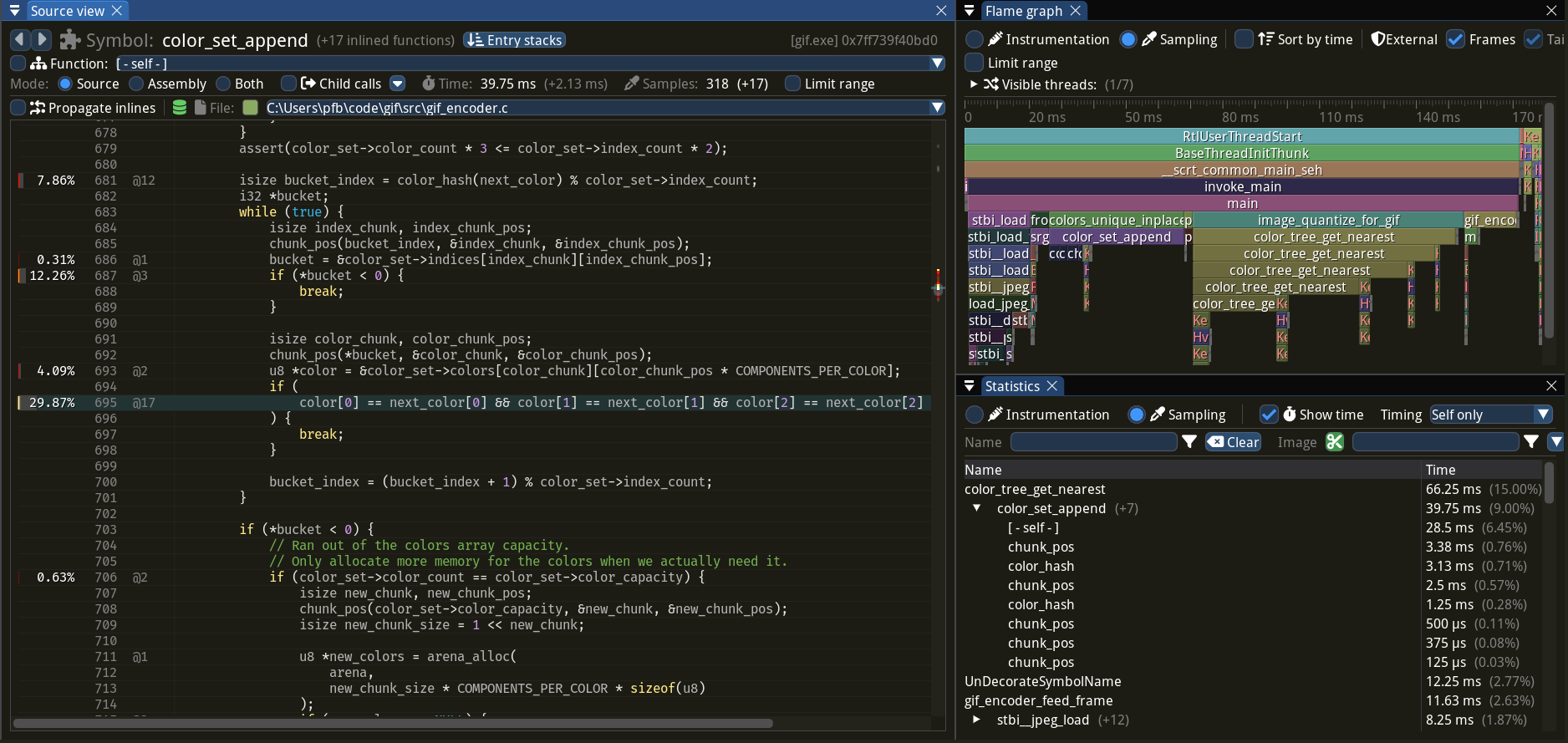
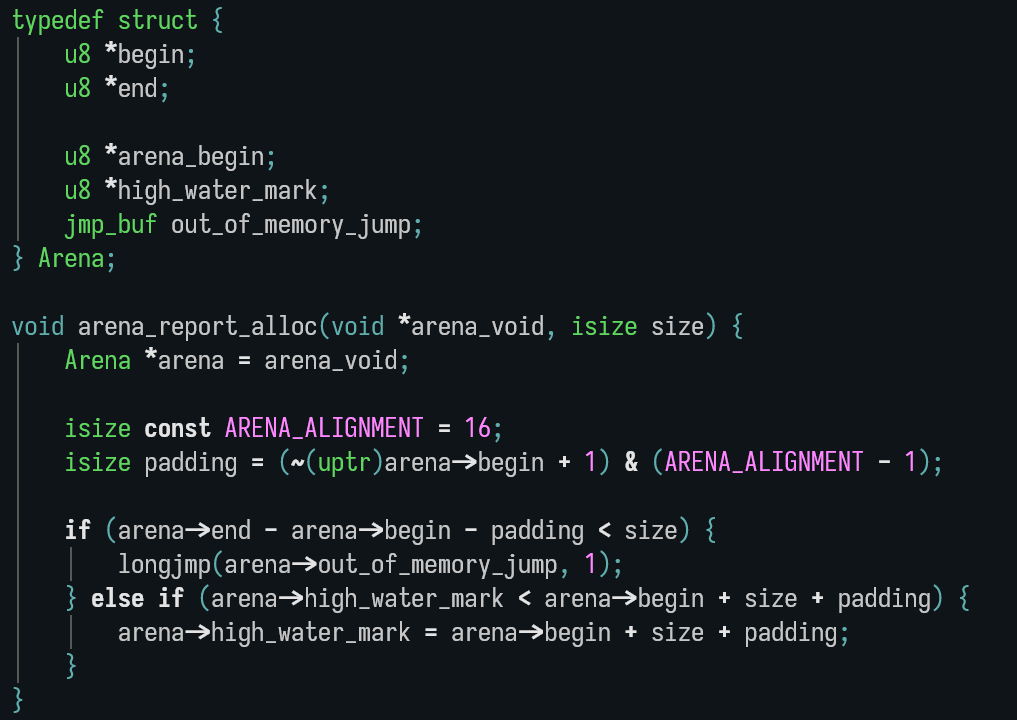
Программирование компьютера.
Попробовал заменить хеш-таблицу, в которой хранятся LZW коды для последовательностей цветов, на префиксное дерево. Потому что там с хеш таблицей возникала квадратичная сложность в каком-то смысле. На каждой итерации цикла LZW кодировщика он набирает пиксели картинки в последовательность до тех пор, пока не соберёт такую, которой ещё нет в таблице. Чтобы залукапить последовательность в таблице, нужно вычислить её хеш код и, короче, выходило, что сложность вытаскивания новой последовательности - это O(N^2), где N - это длина новой последовательности, иными словами, большую часть времени в кодировщике я сидел считал хеш коды постепенно увеличивающейся последовательности, потому что я тупой еблан и не додумался НЕ вычислять хеш код каждый раз заново с первого элемента последовательности? Да, я только сейчас понял, что возможно мог бы не переделывать всё на префиксное дерево.
С префиксным деревом там местами получился более простой код как будто бы, ну, по крайней мере точно меньше строк. Например, теперь не нужно в явном виде хранить аккумулированную последовательность, ты просто одновременно с итерацией по пикселям идёшь вниз по дереву, пока не упираешься в ноду, где по следующему пикселю нету линка дальше вниз. В случае с хеш-таблицей пришлось бы всё равно хранить последовательность для разрешения коллизий. И в моём шизокоде так устроено, что да, нужно именно сохранять набранную последовательность в отдельный массив, нельзя просто сохранить указатель на начало последовательности во входном массиве пикселей, потому что я типа разрешаю по кускам прогрессивно давать пиксели кодировщику.
Что интересно, даже с максимально тупой реализацией префиксного дерева с хранением 256 указателей в каждой ноде как будто бы по использованию памяти выходит так же, как и в предыдущем варианте с хеш-таблицей. Мне лень сейчас заниматься арифметикой, но вроде бы на тестовых картинках используется только чуть-чуть больше памяти. Да, я кстати, сделал подсчёт пикового использования памяти в арене через то, что при компиляции гиф энкодера теперь можно задефайнить кастомный хук, который будет вызываться перед аллокацией памяти в арене, в котором можно в том числе отслеживать использование памяти.
И ещё я выпилил определение структуры арены из хедера гиф энкодера и насрал воид звёздочками, чтобы пользователь (ну, то есть я сам) мог в своём коде определить структуру арены самостоятельно и при необходимости добавить в неё какие-то свои дополнительные поля. (Да, чисто технически это UB, но мне так всё равно.) Главное, чтобы в начале были указатели на конец и начало куска памяти. В этом же хуке можно ещё, например, решить, что делать, когда закончилась память: аборт, лонг джамп, либо, возможно, даже расширить память, передвинув end указатель вперёд? Ограничение состоит в том, что трогать begin никак нельзя, то есть, например, нельзя подсунуть новый кусок памяти, когда старый закончился. Чтобы можно было всё же совать новую память, пришлось бы, наверное, также определять аналогичные хуки перед arena_snapshot и перед arena_rewind, что уже звучит как переусложнение.
Ещё попробовал вот этот профилировщик https://github.com/wolfpld/tracy
Как будто бы даже что-то показывает, например, то, что хешсет с цветами из входной картинки сильно тормозит из-за сравнения цветов по отдельным компонентам, типа, лучше было бы сравнивать их как 32-битные инты. Но в целом мне от него сейчас больше всего полезно смотреть соотношение времени выполнения разных этапов преобразования картинки в гифку. Он, кстати, вроде не только под винду, но и под линукс, просто билды готовые только под винду, то есть можно, вероятно, забыть про gprof, которым я так и не понял, как пользоваться.
Программирование компьютера.
Попробовал заменить хеш-таблицу, в которой хранятся LZW коды для последовательностей цветов, на префиксное дерево. Потому что там с хеш таблицей возникала квадратичная сложность в каком-то смысле. На каждой итерации цикла LZW кодировщика он набирает пиксели картинки в последовательность до тех пор, пока не соберёт такую, которой ещё нет в таблице. Чтобы залукапить последовательность в таблице, нужно вычислить её хеш код и, короче, выходило, что сложность вытаскивания новой последовательности - это O(N^2), где N - это длина новой последовательности, иными словами, большую часть времени в кодировщике я сидел считал хеш коды постепенно увеличивающейся последовательности, потому что я тупой еблан и не додумался НЕ вычислять хеш код каждый раз заново с первого элемента последовательности? Да, я только сейчас понял, что возможно мог бы не переделывать всё на префиксное дерево.
С префиксным деревом там местами получился более простой код как будто бы, ну, по крайней мере точно меньше строк. Например, теперь не нужно в явном виде хранить аккумулированную последовательность, ты просто одновременно с итерацией по пикселям идёшь вниз по дереву, пока не упираешься в ноду, где по следующему пикселю нету линка дальше вниз. В случае с хеш-таблицей пришлось бы всё равно хранить последовательность для разрешения коллизий. И в моём шизокоде так устроено, что да, нужно именно сохранять набранную последовательность в отдельный массив, нельзя просто сохранить указатель на начало последовательности во входном массиве пикселей, потому что я типа разрешаю по кускам прогрессивно давать пиксели кодировщику.
Что интересно, даже с максимально тупой реализацией префиксного дерева с хранением 256 указателей в каждой ноде как будто бы по использованию памяти выходит так же, как и в предыдущем варианте с хеш-таблицей. Мне лень сейчас заниматься арифметикой, но вроде бы на тестовых картинках используется только чуть-чуть больше памяти. Да, я кстати, сделал подсчёт пикового использования памяти в арене через то, что при компиляции гиф энкодера теперь можно задефайнить кастомный хук, который будет вызываться перед аллокацией памяти в арене, в котором можно в том числе отслеживать использование памяти.
И ещё я выпилил определение структуры арены из хедера гиф энкодера и насрал воид звёздочками, чтобы пользователь (ну, то есть я сам) мог в своём коде определить структуру арены самостоятельно и при необходимости добавить в неё какие-то свои дополнительные поля. (Да, чисто технически это UB, но мне так всё равно.) Главное, чтобы в начале были указатели на конец и начало куска памяти. В этом же хуке можно ещё, например, решить, что делать, когда закончилась память: аборт, лонг джамп, либо, возможно, даже расширить память, передвинув end указатель вперёд? Ограничение состоит в том, что трогать begin никак нельзя, то есть, например, нельзя подсунуть новый кусок памяти, когда старый закончился. Чтобы можно было всё же совать новую память, пришлось бы, наверное, также определять аналогичные хуки перед arena_snapshot и перед arena_rewind, что уже звучит как переусложнение.
Ещё попробовал вот этот профилировщик https://github.com/wolfpld/tracy
Как будто бы даже что-то показывает, например, то, что хешсет с цветами из входной картинки сильно тормозит из-за сравнения цветов по отдельным компонентам, типа, лучше было бы сравнивать их как 32-битные инты. Но в целом мне от него сейчас больше всего полезно смотреть соотношение времени выполнения разных этапов преобразования картинки в гифку. Он, кстати, вроде не только под винду, но и под линукс, просто билды готовые только под винду, то есть можно, вероятно, забыть про gprof, которым я так и не понял, как пользоваться.



После инициализации у тебя получится, что в каждой листовой вершине хранится входной цвет. И теперь ты итеративно берёшь листовые вершины и объединяешь их вместе с сиблингами внутрь родителя, повторяешь до тех пор, пока листовых вершин не станет меньше, чем требуется цветов в палитре. В родителе сохраняешь сумму цветов и то, сколько дочерних вершин в него было объединено. Для объединения в первую очередь выбираешь те вершины, где в поддеревьях было суммарно меньше всего входных цветов, но как будто бы можно и просто по порядку объединять все вершины на самом нижнем уровне и результат особо не изменится.
Результат получился довольно паршивый, хуже, чем даже обычный median-cut. Единственный плюс в том, что он приблизительно близкие друг к другу цвета смешивает вместе, благодаря чему, например башня с фиолетовой подсветкой вдали остаётся фиолетовой. Обычный median-cut делает её синей, смешивая с какими-то другими цветами. Но MMCQ, который я выше пробовал, тоже имеет похожий эффект с сохранением редких цветов, да и результат в целом лучше получается, чем у октодерева.
В той же библиотеке, откуда я украл улучшенный median-cut (MMCQ), также есть и октодерево, тоже какое-то улучшенное https://tpgit.github.io/UnOfficialLeptDocs/leptonica/color-quantization.html#octree-implementation но я абсолютно не понял суть алгоритма. Там ещё вроде бы их алгоритм может сгенерировать больше цветов, чем у него просишь, что звучит довольно странно.
Ещё попробовал в k-means сделать выбор начальных центроидов через k-means++: центроиды выбираются рандомно из входных цветов и вероятность выбрать цвет в качестве центроида тем выше, чем он дальше от уже выбранных центроидов. Короче, иными словами, он пытается начально выбрать центроиды так, чтобы они находились далеко друг от друга. Само по себе это мало что дало, но потом попробовал это совместить с тем, чтобы оставлять дублирующиеся цвета во входных данных, и результат получился довольно неплохой (на обоих картинках 256 цветов), но работает дико медленно из-за того, что приходится переваривать гораздо больше входных данных.
А если оставлять дубликаты цветов при равномерно рандомной инициализации центроидов, то палитра тоже неплохая получается, часто лучше, чем с уникальными цветами, но немного хуже, чем с k-means++ инициализацией. Но в отдельных вырожденных случаях, когда в картинке достаточно много одинаковых пикселей, результат наоборот ухудшается по сравнению с уникальными входными цветами, видимо, из-за того, что в качестве начальных центроидов больше шансов выбрать несколько одинаковых цветов. Это как раз контрится через k-means++.
После инициализации у тебя получится, что в каждой листовой вершине хранится входной цвет. И теперь ты итеративно берёшь листовые вершины и объединяешь их вместе с сиблингами внутрь родителя, повторяешь до тех пор, пока листовых вершин не станет меньше, чем требуется цветов в палитре. В родителе сохраняешь сумму цветов и то, сколько дочерних вершин в него было объединено. Для объединения в первую очередь выбираешь те вершины, где в поддеревьях было суммарно меньше всего входных цветов, но как будто бы можно и просто по порядку объединять все вершины на самом нижнем уровне и результат особо не изменится.
Результат получился довольно паршивый, хуже, чем даже обычный median-cut. Единственный плюс в том, что он приблизительно близкие друг к другу цвета смешивает вместе, благодаря чему, например башня с фиолетовой подсветкой вдали остаётся фиолетовой. Обычный median-cut делает её синей, смешивая с какими-то другими цветами. Но MMCQ, который я выше пробовал, тоже имеет похожий эффект с сохранением редких цветов, да и результат в целом лучше получается, чем у октодерева.
В той же библиотеке, откуда я украл улучшенный median-cut (MMCQ), также есть и октодерево, тоже какое-то улучшенное https://tpgit.github.io/UnOfficialLeptDocs/leptonica/color-quantization.html#octree-implementation но я абсолютно не понял суть алгоритма. Там ещё вроде бы их алгоритм может сгенерировать больше цветов, чем у него просишь, что звучит довольно странно.
Ещё попробовал в k-means сделать выбор начальных центроидов через k-means++: центроиды выбираются рандомно из входных цветов и вероятность выбрать цвет в качестве центроида тем выше, чем он дальше от уже выбранных центроидов. Короче, иными словами, он пытается начально выбрать центроиды так, чтобы они находились далеко друг от друга. Само по себе это мало что дало, но потом попробовал это совместить с тем, чтобы оставлять дублирующиеся цвета во входных данных, и результат получился довольно неплохой (на обоих картинках 256 цветов), но работает дико медленно из-за того, что приходится переваривать гораздо больше входных данных.
А если оставлять дубликаты цветов при равномерно рандомной инициализации центроидов, то палитра тоже неплохая получается, часто лучше, чем с уникальными цветами, но немного хуже, чем с k-means++ инициализацией. Но в отдельных вырожденных случаях, когда в картинке достаточно много одинаковых пикселей, результат наоборот ухудшается по сравнению с уникальными входными цветами, видимо, из-за того, что в качестве начальных центроидов больше шансов выбрать несколько одинаковых цветов. Это как раз контрится через k-means++.

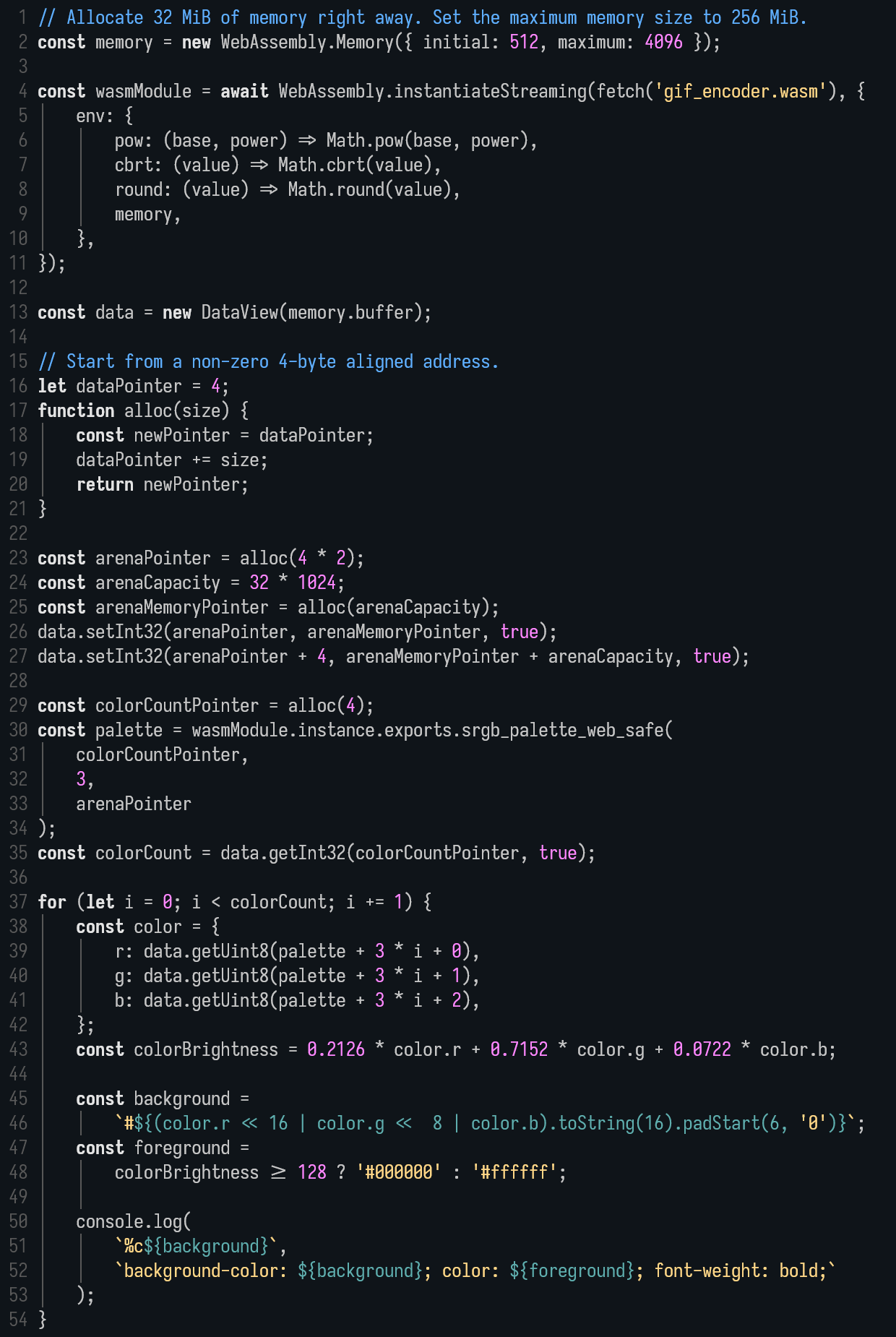
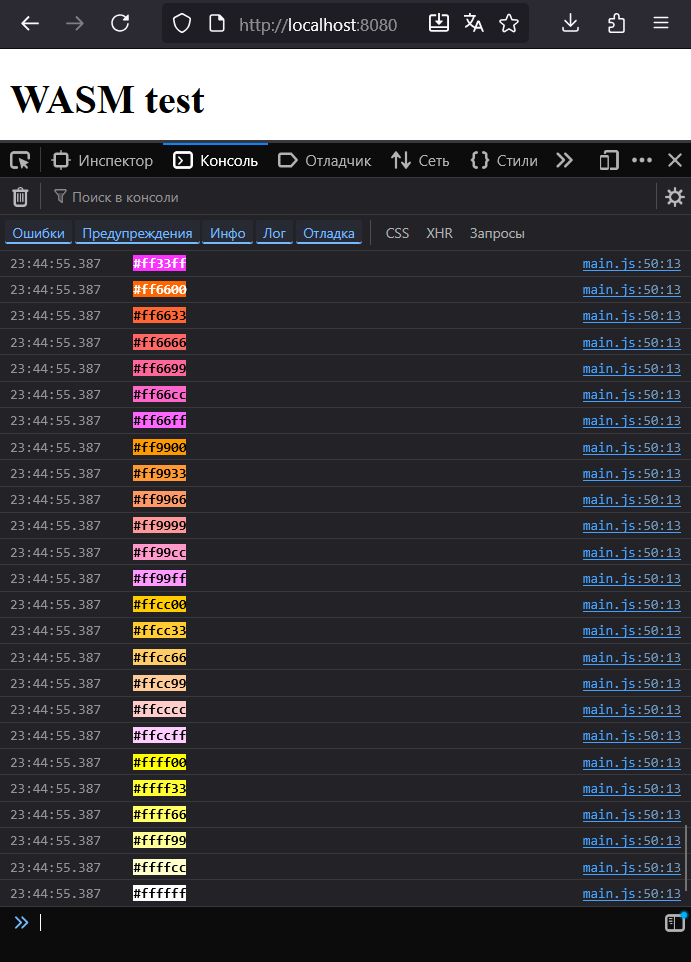
Компилируешь клангом с аргументами --target=wasm32 и --no-standard-libraries, то есть все используемые функции из стандартной библиотеки придётся написать самому, ну или взять откуда-то реализации (но желательно использовать другие имена функций, компилятор может затроллить). Дополнительно линковщику https://lld.llvm.org/WebAssembly.html через -Wl нужно прокинуть флаги --no-entry и --export-table.
Функции, экспортируемые из васма в жс, помечаешь атрибутом __attribute__((export_name("имя_функции"))). Объявления функций, импортируемых внутрь васма из жс, аналогичным образом помечаешь атрибутом import_name. Неймспейс, откуда по дефолту всё импортируется внутрь васма, называется "env". Чтобы узнать это, можно через wasm2wat https://webassembly.org/getting-started/advanced-tools перевести скомпилированный васм модуль в текстовый формат и посмотреть, откуда импортируются функции.
Куски памяти в васм модуле можно импортировать/экспортировать точно так же, как и функции. По дефолту память экспортируется из васма. То есть, если ты, например, со стороны жс хочешь прочесть что-то, что записал васм, тебе надо использовать объект "wasmModule.instance.exports.memory", который был создан автоматически. "memory" - это опять же, как и "env", не часть какого-то фиксированного апи, а просто дефолтный идентификатор, который кланг использует. Там так-то этих кусков памяти вообще в теории можно несколько сделать внутри одного модуля: https://github.com/WebAssembly/multi-memory/blob/main/proposals/multi-memory/Overview.md
То, насколько большим является экспортируемый кусок памяти и на сколько максимум его можно будет расширить, задаётся через --initial-memory и --max-memory флаги линковщика. Но, как мне кажется, проще наоборот импортировать память из жс внутрь васма, потому что можно тогда прямо в жс коде вручную создать кусок памяти и определить его начальный и максимальный размеры, как это сделано в самом верху на скрине. (Там, если что, размеры измеряются в количестве страниц размером 64Кб.)
Для работы с памятью со стороны жс можно использовать DataView, там есть методы, чтобы читать разные типы значений по байтовым оффсетам. Но тут неудобство в том, что его методы, например, setInt32, по дефолту используют big-endian порядок, в то время как васм использует little-endian порядок. Из-за этого приходится везде в методах DataView прокидывать true последним аргументом, чтобы переключить на little-endian. Может показаться, что Int32Array и аналогичные классы удобнее и как будто работают без этой мороки, но это всё чисто по совпадению: у них порядок байтов совпадает с порядком байтов на железе, где браузер запущен.
А в остальном там всё максимально плоско, всё передаётся по указателям ака байтовым оффсетам внутри используемого куска памяти. Получается, что на стороне джаваскрипта приходится возиться с указателями, прямо как в си, только ещё хуже, потому что нету никакой типизации для них, вручную прописываешь оффсеты. Например, на скрине, на 26 и 27 строках это я прописываю begin и end указатели для арены, которую позже передаю внутрь функции.
На скрине это я типо вызываю функцию генерации web-safe палитры из гиф энкодера и печатаю цвета в консоль.
К сожалению, ничего, связанного с васмом, невозможно тестить локально без хттп сервера: никак иначе не загрузить локальный файл с васм модулем. Единственная альтернатива - запихать содержимое файла в строку в base64. Но, с другой стороны, как оказалось, написать примитивный хттп сервер на winsock, который отдаёт захардкоженный список файлов - это вообще не сложно.
Компилируешь клангом с аргументами --target=wasm32 и --no-standard-libraries, то есть все используемые функции из стандартной библиотеки придётся написать самому, ну или взять откуда-то реализации (но желательно использовать другие имена функций, компилятор может затроллить). Дополнительно линковщику https://lld.llvm.org/WebAssembly.html через -Wl нужно прокинуть флаги --no-entry и --export-table.
Функции, экспортируемые из васма в жс, помечаешь атрибутом __attribute__((export_name("имя_функции"))). Объявления функций, импортируемых внутрь васма из жс, аналогичным образом помечаешь атрибутом import_name. Неймспейс, откуда по дефолту всё импортируется внутрь васма, называется "env". Чтобы узнать это, можно через wasm2wat https://webassembly.org/getting-started/advanced-tools перевести скомпилированный васм модуль в текстовый формат и посмотреть, откуда импортируются функции.
Куски памяти в васм модуле можно импортировать/экспортировать точно так же, как и функции. По дефолту память экспортируется из васма. То есть, если ты, например, со стороны жс хочешь прочесть что-то, что записал васм, тебе надо использовать объект "wasmModule.instance.exports.memory", который был создан автоматически. "memory" - это опять же, как и "env", не часть какого-то фиксированного апи, а просто дефолтный идентификатор, который кланг использует. Там так-то этих кусков памяти вообще в теории можно несколько сделать внутри одного модуля: https://github.com/WebAssembly/multi-memory/blob/main/proposals/multi-memory/Overview.md
То, насколько большим является экспортируемый кусок памяти и на сколько максимум его можно будет расширить, задаётся через --initial-memory и --max-memory флаги линковщика. Но, как мне кажется, проще наоборот импортировать память из жс внутрь васма, потому что можно тогда прямо в жс коде вручную создать кусок памяти и определить его начальный и максимальный размеры, как это сделано в самом верху на скрине. (Там, если что, размеры измеряются в количестве страниц размером 64Кб.)
Для работы с памятью со стороны жс можно использовать DataView, там есть методы, чтобы читать разные типы значений по байтовым оффсетам. Но тут неудобство в том, что его методы, например, setInt32, по дефолту используют big-endian порядок, в то время как васм использует little-endian порядок. Из-за этого приходится везде в методах DataView прокидывать true последним аргументом, чтобы переключить на little-endian. Может показаться, что Int32Array и аналогичные классы удобнее и как будто работают без этой мороки, но это всё чисто по совпадению: у них порядок байтов совпадает с порядком байтов на железе, где браузер запущен.
А в остальном там всё максимально плоско, всё передаётся по указателям ака байтовым оффсетам внутри используемого куска памяти. Получается, что на стороне джаваскрипта приходится возиться с указателями, прямо как в си, только ещё хуже, потому что нету никакой типизации для них, вручную прописываешь оффсеты. Например, на скрине, на 26 и 27 строках это я прописываю begin и end указатели для арены, которую позже передаю внутрь функции.
На скрине это я типо вызываю функцию генерации web-safe палитры из гиф энкодера и печатаю цвета в консоль.
К сожалению, ничего, связанного с васмом, невозможно тестить локально без хттп сервера: никак иначе не загрузить локальный файл с васм модулем. Единственная альтернатива - запихать содержимое файла в строку в base64. Но, с другой стороны, как оказалось, написать примитивный хттп сервер на winsock, который отдаёт захардкоженный список файлов - это вообще не сложно.


>как оказалось, написать примитивный хттп сервер на winsock, который отдаёт захардкоженный список файлов - это вообще не сложно
Попробовал доделать это до более полноценного хттп сервера с хот релоадом для более удобного програмирования хтмлей и жаваскриптов.
Чтобы сообщать браузеру, когда ему пора перезагружать страницу для отображения изменений, можно было бы использовать лонг-поллинг, но он мне всегда виделся каким-то убогим костылём, поэтому я сделал примитивную частичную реализацию вебсокет сервера. По сути всё, что требовалось - это определённым образом ответить на хендшейк, отосланный браузером, который выглядит как обычный хттп запрос с хедером "Upgrade: websocket". Конкретно, там нужно взять строку-ключ, приходящую в одном из хедеров, сконкатенировать с другой строкой, вычислить SHA-1 хеш, закодировать в base64 и отправить обратно. Это, видимо, просто челлендж-проверка на адекватность сервера, потому что этот ключ в дальнейшем нигде использоваться не будет, как я понял. Функцию хеширования просто навелосипедил по википедии и RFC. А дальше я в нужные моменты отсылаю захардкоженную последовательность байтов, скопипасченную из RFC вебсокетов, которая представляет собой один дата-фрейм с каким-то рандом текстом.
Сложнее было разобраться с тем, как следить за изменениями файлов внутри папки. В винде есть вариант через FindFirstChangeNotification/FindNextChangeNotification, но там нету способа узнать, какое конкретно изменение вызвало уведомление, а это хотелось бы знать, чтобы минимально отфильтровать мусорные апдейты. Я слежу за изменением последнего времени записи и это репортится не только для изменённого файла, но и для содержащей его папки. Причём папка репортится несколько раз из-за того, что вим создаёт внутри неё ещё какой-то временный файл: https://github.com/neovim/neovim/discussions/30613
Другой вариант, который я и выбрал - через ReadDirectoryChangesW, там можно вытащить пути до изменённых файлов/папок, но делается это через OVERLAPPED-хрень, короче, вот пример: https://gist.github.com/nickav/a57009d4fcc3b527ed0f5c9cf30618f8
Но это всё равно вроде бы не гарантирует отсутствие дополнительных мусорных апдейтов: https://devblogs.microsoft.com/oldnewthing/20140507-00/?p=1053 Или он всё же чисто про то, что если одновременно следишь за несколькими видами событий (например, последнее время изменения и размер файла), то будешь получать несколько апдейтов, а не ровно один на каждый файл или папку, не особо понял.
Код сервера пришлось переписать с select на WaitForMultipleObjects, потому что сервер однопоточный и мне нужно одновременно ждать либо изменений содержимого файлов, чтобы отправить сообщения по вебсокетам, либо событий по сокетам. Ну и, кстати, вынести отслеживание изменений файлов в отдельный поток вряд ли как-то помогло бы, потому что в любом случае нет способа прервать select, пришлось бы делать таймаут, чтобы периодически проверять, изменились ли файлы, что звучит так себе.
В общем, суть в том, что для каждого сокета делаешь объект события через WSACreateEvent, через WSAEventSelect выставляешь события, в которых заинтересован (FD_ACCEPT для listen сокета, FD_READ и FD_CLOSE для client сокетов), и ждёшь. При получении события сбрасываешь событие через WSAResetEvent и снова ждёшь. С этим работать даже немного более удобно, чем с select, потому что не надо каждый раз полностью проходиться по всему fd_set в поиске прокнувших сокетов. Но вроде как по производительности это всё равно не особо лучше, чем select, а типо самый лучший вариант - это какие-то I/O Completion Ports (IOCP), не разбирался, что это.
Для хттп ради интереса попытался сделать парсилку, которая умеет жрать данные постепенно кусочками произвольного размера, не придумал ничего лучше, чем насрать стейт машиной и сохранять поступающие данные в промежуточный буфер до тех пор, пока не набирается достаточно данных, чтобы продвинуть стейт вперёд (конкретно в случае с хттп - пока не встретится перенос строки). Но я, если что, не стал это никак использовать, чтобы конкурентно обрабатывать сразу несколько хттп запросов, это было бы совсем уж переусложнение здесь, я просто синхронно высасываю все байты, пока не встречаю "\r\n\r\n".
Вообще это первый раз, когда я что-то пробовал делать с сетью и наверняка много чего неправильно делаю, не понимаю или не знаю. Например, отсюда:
https://youtu.be/JRTLSxGf_6w
https://blog.netherlabs.nl/articles/2009/01/18/the-ultimate-so_linger-page-or-why-is-my-tcp-not-reliable
я какое-то время назад рандомно узнал, что байты, отправленные по TCP через send() могут тупо не дойти до получателя, если ты сразу после отправки закроешь сокет. И типо единственный способ удостовериться в том, что всё реально дошло - это после отправки вызвать shutdown() операций на запись и хотя бы дождаться, пока получатель сам не закроет сокет. А ещё лучше, если он явно отправит по этому же TCP соединению какое-то сообщение, типо, что ок, получил, и только после этого можно закрывать сокет со стороны отправителя.
Или, например, после того, как переписал с селекта на ивенты, внезапно стали падать какие-то EWOULDBLOCK ошибки. Я их просто заигнорил, но может быть, я должен был что-то по-другому сделать? Ну и куча нюансов, типо, я сейчас не разрешаю переиспользовать старые TCP соединения для новых хттп запросов и просто их закрываю, но в теории вроде лучше держать их открытыми (keep-alive).
И ещё я сейчас никак не обрабатываю вебсокет сообщения с клиента и просто закрываю сокет, если клиент что-то пытается написать, потому что вроде бы он сам по себе, автоматом, пишет только close фрейм при закрытии вебсокета, так что это почти корректно по совпадению. Но по-хорошему мне нужно детектить close фрейм, присланный клиентом, отвечать на него тоже close фреймом и только после этого закрывать соединение. И возможно ещё детектить пинг фреймы и отвечать на них понгами, не знаю, может ли браузер рандомно мне такое прислать.
Это звучит как мелочь, но, например, из-за казалось бы эквивалентной по важности мелочи когда я в очередной раз забыл, что snprintf возвращает размер строки без нуль-терминатора, из-за чего я эффективно недосылал один последний байт из серверной части вебсокет хендшейка браузер тупо бесконечно ждал, пока я не отошлю этот несчастный последний байт ответа, держал соединения открытыми даже после рефреша или закрытия вкладки, а при достижении какого-то количества открытых соединений вообще отказывался открывать новые.
А, да, список самих файлов, которые отдаются сервером, до сих пор так и остался захардкоженным, не успел доделать.
>как оказалось, написать примитивный хттп сервер на winsock, который отдаёт захардкоженный список файлов - это вообще не сложно
Попробовал доделать это до более полноценного хттп сервера с хот релоадом для более удобного програмирования хтмлей и жаваскриптов.
Чтобы сообщать браузеру, когда ему пора перезагружать страницу для отображения изменений, можно было бы использовать лонг-поллинг, но он мне всегда виделся каким-то убогим костылём, поэтому я сделал примитивную частичную реализацию вебсокет сервера. По сути всё, что требовалось - это определённым образом ответить на хендшейк, отосланный браузером, который выглядит как обычный хттп запрос с хедером "Upgrade: websocket". Конкретно, там нужно взять строку-ключ, приходящую в одном из хедеров, сконкатенировать с другой строкой, вычислить SHA-1 хеш, закодировать в base64 и отправить обратно. Это, видимо, просто челлендж-проверка на адекватность сервера, потому что этот ключ в дальнейшем нигде использоваться не будет, как я понял. Функцию хеширования просто навелосипедил по википедии и RFC. А дальше я в нужные моменты отсылаю захардкоженную последовательность байтов, скопипасченную из RFC вебсокетов, которая представляет собой один дата-фрейм с каким-то рандом текстом.
Сложнее было разобраться с тем, как следить за изменениями файлов внутри папки. В винде есть вариант через FindFirstChangeNotification/FindNextChangeNotification, но там нету способа узнать, какое конкретно изменение вызвало уведомление, а это хотелось бы знать, чтобы минимально отфильтровать мусорные апдейты. Я слежу за изменением последнего времени записи и это репортится не только для изменённого файла, но и для содержащей его папки. Причём папка репортится несколько раз из-за того, что вим создаёт внутри неё ещё какой-то временный файл: https://github.com/neovim/neovim/discussions/30613
Другой вариант, который я и выбрал - через ReadDirectoryChangesW, там можно вытащить пути до изменённых файлов/папок, но делается это через OVERLAPPED-хрень, короче, вот пример: https://gist.github.com/nickav/a57009d4fcc3b527ed0f5c9cf30618f8
Но это всё равно вроде бы не гарантирует отсутствие дополнительных мусорных апдейтов: https://devblogs.microsoft.com/oldnewthing/20140507-00/?p=1053 Или он всё же чисто про то, что если одновременно следишь за несколькими видами событий (например, последнее время изменения и размер файла), то будешь получать несколько апдейтов, а не ровно один на каждый файл или папку, не особо понял.
Код сервера пришлось переписать с select на WaitForMultipleObjects, потому что сервер однопоточный и мне нужно одновременно ждать либо изменений содержимого файлов, чтобы отправить сообщения по вебсокетам, либо событий по сокетам. Ну и, кстати, вынести отслеживание изменений файлов в отдельный поток вряд ли как-то помогло бы, потому что в любом случае нет способа прервать select, пришлось бы делать таймаут, чтобы периодически проверять, изменились ли файлы, что звучит так себе.
В общем, суть в том, что для каждого сокета делаешь объект события через WSACreateEvent, через WSAEventSelect выставляешь события, в которых заинтересован (FD_ACCEPT для listen сокета, FD_READ и FD_CLOSE для client сокетов), и ждёшь. При получении события сбрасываешь событие через WSAResetEvent и снова ждёшь. С этим работать даже немного более удобно, чем с select, потому что не надо каждый раз полностью проходиться по всему fd_set в поиске прокнувших сокетов. Но вроде как по производительности это всё равно не особо лучше, чем select, а типо самый лучший вариант - это какие-то I/O Completion Ports (IOCP), не разбирался, что это.
Для хттп ради интереса попытался сделать парсилку, которая умеет жрать данные постепенно кусочками произвольного размера, не придумал ничего лучше, чем насрать стейт машиной и сохранять поступающие данные в промежуточный буфер до тех пор, пока не набирается достаточно данных, чтобы продвинуть стейт вперёд (конкретно в случае с хттп - пока не встретится перенос строки). Но я, если что, не стал это никак использовать, чтобы конкурентно обрабатывать сразу несколько хттп запросов, это было бы совсем уж переусложнение здесь, я просто синхронно высасываю все байты, пока не встречаю "\r\n\r\n".
Вообще это первый раз, когда я что-то пробовал делать с сетью и наверняка много чего неправильно делаю, не понимаю или не знаю. Например, отсюда:
https://youtu.be/JRTLSxGf_6w
https://blog.netherlabs.nl/articles/2009/01/18/the-ultimate-so_linger-page-or-why-is-my-tcp-not-reliable
я какое-то время назад рандомно узнал, что байты, отправленные по TCP через send() могут тупо не дойти до получателя, если ты сразу после отправки закроешь сокет. И типо единственный способ удостовериться в том, что всё реально дошло - это после отправки вызвать shutdown() операций на запись и хотя бы дождаться, пока получатель сам не закроет сокет. А ещё лучше, если он явно отправит по этому же TCP соединению какое-то сообщение, типо, что ок, получил, и только после этого можно закрывать сокет со стороны отправителя.
Или, например, после того, как переписал с селекта на ивенты, внезапно стали падать какие-то EWOULDBLOCK ошибки. Я их просто заигнорил, но может быть, я должен был что-то по-другому сделать? Ну и куча нюансов, типо, я сейчас не разрешаю переиспользовать старые TCP соединения для новых хттп запросов и просто их закрываю, но в теории вроде лучше держать их открытыми (keep-alive).
И ещё я сейчас никак не обрабатываю вебсокет сообщения с клиента и просто закрываю сокет, если клиент что-то пытается написать, потому что вроде бы он сам по себе, автоматом, пишет только close фрейм при закрытии вебсокета, так что это почти корректно по совпадению. Но по-хорошему мне нужно детектить close фрейм, присланный клиентом, отвечать на него тоже close фреймом и только после этого закрывать соединение. И возможно ещё детектить пинг фреймы и отвечать на них понгами, не знаю, может ли браузер рандомно мне такое прислать.
Это звучит как мелочь, но, например, из-за казалось бы эквивалентной по важности мелочи когда я в очередной раз забыл, что snprintf возвращает размер строки без нуль-терминатора, из-за чего я эффективно недосылал один последний байт из серверной части вебсокет хендшейка браузер тупо бесконечно ждал, пока я не отошлю этот несчастный последний байт ответа, держал соединения открытыми даже после рефреша или закрытия вкладки, а при достижении какого-то количества открытых соединений вообще отказывался открывать новые.
А, да, список самих файлов, которые отдаются сервером, до сих пор так и остался захардкоженным, не успел доделать.


Ну, на деле я ещё пару дней разбирался со всякими багами, чтобы довести этот велосипед до минимально юзабельного состояния. Типо, например, я абсолютно не обратил внимание на то, что WSAEventSelect автоматически делает сокеты неблокирующими, но я при этом продолжал пользоваться сокетами так, как будто они блокирующие. Это и было причиной, почему внезапно посыпались EWOULDBLOCK ошибки. И ещё, как оказалось, необязательно создавать события для сокетов через WSACreateEvent, можно использовать обычный CreateEvent, в котором есть возможность включить авто-ресет, чтобы вручную не делать его.
И вот это
>Но по-хорошему мне нужно детектить close фрейм, присланный клиентом, отвечать на него тоже close фреймом и только после этого закрывать соединение.
действительно оказалось чем-то важным. Если не отправить в конце эти два несчастных байта, то после хот-релоада браузеры почему-то переоткрывают вебсокет соединение с ощутимой задержкой, причём чем больше вкладок было открыто одновременно, тем больше задержка. Я не знаю почему так происходит, типо браузер мне уже сказал, что он закрывает соединение, зачем ему ещё ждать какого-то подтверждения со стороны сервера? Сервер может максимум вместе с close фреймом ещё прислать причину закрытия соединения вроде бы, но тут она как бы очевидна.
Ну и добавил, чтобы можно было натравить сервер на папку, чтобы он отдавал все файлы из неё. Естественно без всяких предосторожностей от ".." в URL, потому что мне лень. Но я попытался хотя бы добавить поддержку юникодовых названий файлов, но, как оказалось, fopen() под виндой не умеет в UTF-8, и мне стало тоже лень доделывать это, всё меньше и меньше причин пользоваться помойной стандартной либой.
Я, кстати, не знаю, обязан ли хттп сервер корректно резолвить относительные пути, как будто бы и браузеры, и даже curl, делают это сами автоматически, может быть, можно просто игнорить сегменты с точками, да и всё.
Ещё случайно обнаружил гениальный способ сделать подобие сырых строк в си. Просто делаешь так:
> #define RAW(...) #__VA_ARGS__
и можешь писать строку прямо внутрь вот так: RAW(Hello world). Непарные кавычки, непаврные круглые скобки и символ решётки не работают, их придётся заменить на \x??, в остальном, вроде бы любые символы можно пихать.
Ещё недостаток в том, что оно игнорит повторные пробелы (снаружи кавычек) и переносы строк, но это как раз то, что не имеет значения, когда в строку нужно загнать какой-нибудь кусок кода. Например, код шейдера или кусок жаваскрипта для хот релоада, как в моём случае. Даже подсветка синтаксиса в редакторах работает.
Вот пример:
https://github.com/libretro/RetroArch/blob/4c7a1a5322965befed5d83f3ebb9607edbb229e0/gfx/drivers/d3d_shaders/opaque_sm5.hlsl.h
Попробовал эту хрень:
https://developer.mozilla.org/en-US/docs/Web/API/Web_components/Using_custom_elements
На видео для теста типо сделал элемент для драг н дропа картинок. Элемент можно просто в хтмл писать, ещё даже до того, как он был определён через жаваскрипт. И он позже просто автоматически проинициализируется сам, вызовется конструктор и колбеки жизненного цикла, и каждый инстанс компонента будет иметь своё отдельное состояние.
Там даже можно подписываться на изменение значений атрибутов. А изнутри наружу данные можно передавать через кастомные события обычные, только нужно к событию добавить параметр composed, чтобы оно пробилось наружу из shadow дома.
И удобно, что можно в <template> впихнуть рядом одновременно и стили, и разметку, а в конструкторе веб компонента всё содержимое <template> впихнуть в shadow дом, изолированный от внешнего мира (в том числе id тоже изолированные, так что это решает проблему указания уникального id для <label for="...">). Но, с другой стороны, это мешает, когда хочется определить какие-то глобальные стили, например, хотя бы reset.css или normalize.css, и непонятно, насколько адекватно будет просто взять и прописать @import внутри <style> тега, например. Будет ли это как-то серьёзно нагружать браузер, если на странице будет куча shadow домов и в каждом по импорту какого-то большого файла.
Я просто многого от браузеров не ожидаю после того, как я понял, что ту анимацию в сапёре >>795747 походу тупо невозможно нормально сделать, если ты рендеришь клетки поля через хтмл элементы. Браузер там пытается вынести каждую двигающуюся клетку в отдельный композит слой, что очевидно тут абсолютно избыточно. Всё особенно тормозит, когда браузер пытается на ходу разбить всё на слои как-то по умному, минимизируя их количество. И если изначально наивно зафорсить отдельный слой на каждую клетку через will-change, то всё начинает работать быстрее.
И я тупо не нашёл ни одного способа как-то сообщить браузеру, что мне всё равно на пересечения анимированных клеток между собой (которых там даже на деле нету, но браузер понятно этого не может знать) и они все могут быть в теории на одном слое. Единственная идея была - рендерить эти анимированные клетки на канвасе с прозрачным фоном, расположенным, поверх поля? И в этот момент задаёшься вопросом, почему бы тогда вообще всё не рендерить в канвас тогда?
Ну, на деле я ещё пару дней разбирался со всякими багами, чтобы довести этот велосипед до минимально юзабельного состояния. Типо, например, я абсолютно не обратил внимание на то, что WSAEventSelect автоматически делает сокеты неблокирующими, но я при этом продолжал пользоваться сокетами так, как будто они блокирующие. Это и было причиной, почему внезапно посыпались EWOULDBLOCK ошибки. И ещё, как оказалось, необязательно создавать события для сокетов через WSACreateEvent, можно использовать обычный CreateEvent, в котором есть возможность включить авто-ресет, чтобы вручную не делать его.
И вот это
>Но по-хорошему мне нужно детектить close фрейм, присланный клиентом, отвечать на него тоже close фреймом и только после этого закрывать соединение.
действительно оказалось чем-то важным. Если не отправить в конце эти два несчастных байта, то после хот-релоада браузеры почему-то переоткрывают вебсокет соединение с ощутимой задержкой, причём чем больше вкладок было открыто одновременно, тем больше задержка. Я не знаю почему так происходит, типо браузер мне уже сказал, что он закрывает соединение, зачем ему ещё ждать какого-то подтверждения со стороны сервера? Сервер может максимум вместе с close фреймом ещё прислать причину закрытия соединения вроде бы, но тут она как бы очевидна.
Ну и добавил, чтобы можно было натравить сервер на папку, чтобы он отдавал все файлы из неё. Естественно без всяких предосторожностей от ".." в URL, потому что мне лень. Но я попытался хотя бы добавить поддержку юникодовых названий файлов, но, как оказалось, fopen() под виндой не умеет в UTF-8, и мне стало тоже лень доделывать это, всё меньше и меньше причин пользоваться помойной стандартной либой.
Я, кстати, не знаю, обязан ли хттп сервер корректно резолвить относительные пути, как будто бы и браузеры, и даже curl, делают это сами автоматически, может быть, можно просто игнорить сегменты с точками, да и всё.
Ещё случайно обнаружил гениальный способ сделать подобие сырых строк в си. Просто делаешь так:
> #define RAW(...) #__VA_ARGS__
и можешь писать строку прямо внутрь вот так: RAW(Hello world). Непарные кавычки, непаврные круглые скобки и символ решётки не работают, их придётся заменить на \x??, в остальном, вроде бы любые символы можно пихать.
Ещё недостаток в том, что оно игнорит повторные пробелы (снаружи кавычек) и переносы строк, но это как раз то, что не имеет значения, когда в строку нужно загнать какой-нибудь кусок кода. Например, код шейдера или кусок жаваскрипта для хот релоада, как в моём случае. Даже подсветка синтаксиса в редакторах работает.
Вот пример:
https://github.com/libretro/RetroArch/blob/4c7a1a5322965befed5d83f3ebb9607edbb229e0/gfx/drivers/d3d_shaders/opaque_sm5.hlsl.h
Попробовал эту хрень:
https://developer.mozilla.org/en-US/docs/Web/API/Web_components/Using_custom_elements
На видео для теста типо сделал элемент для драг н дропа картинок. Элемент можно просто в хтмл писать, ещё даже до того, как он был определён через жаваскрипт. И он позже просто автоматически проинициализируется сам, вызовется конструктор и колбеки жизненного цикла, и каждый инстанс компонента будет иметь своё отдельное состояние.
Там даже можно подписываться на изменение значений атрибутов. А изнутри наружу данные можно передавать через кастомные события обычные, только нужно к событию добавить параметр composed, чтобы оно пробилось наружу из shadow дома.
И удобно, что можно в <template> впихнуть рядом одновременно и стили, и разметку, а в конструкторе веб компонента всё содержимое <template> впихнуть в shadow дом, изолированный от внешнего мира (в том числе id тоже изолированные, так что это решает проблему указания уникального id для <label for="...">). Но, с другой стороны, это мешает, когда хочется определить какие-то глобальные стили, например, хотя бы reset.css или normalize.css, и непонятно, насколько адекватно будет просто взять и прописать @import внутри <style> тега, например. Будет ли это как-то серьёзно нагружать браузер, если на странице будет куча shadow домов и в каждом по импорту какого-то большого файла.
Я просто многого от браузеров не ожидаю после того, как я понял, что ту анимацию в сапёре >>795747 походу тупо невозможно нормально сделать, если ты рендеришь клетки поля через хтмл элементы. Браузер там пытается вынести каждую двигающуюся клетку в отдельный композит слой, что очевидно тут абсолютно избыточно. Всё особенно тормозит, когда браузер пытается на ходу разбить всё на слои как-то по умному, минимизируя их количество. И если изначально наивно зафорсить отдельный слой на каждую клетку через will-change, то всё начинает работать быстрее.
И я тупо не нашёл ни одного способа как-то сообщить браузеру, что мне всё равно на пересечения анимированных клеток между собой (которых там даже на деле нету, но браузер понятно этого не может знать) и они все могут быть в теории на одном слое. Единственная идея была - рендерить эти анимированные клетки на канвасе с прозрачным фоном, расположенным, поверх поля? И в этот момент задаёшься вопросом, почему бы тогда вообще всё не рендерить в канвас тогда?


Узнать адрес, начиная с которого идёт память, отведённая под кучу, можно так: объявляешь глобальную переменную __heap_base:
> extern unsigned char __heap_base;
Тип вроде может быть любым, потому что адресом начала кучи будет не значение, хранимое внутри, а адрес этой глобальной переменной. А в жаваскрипт этот адрес можно протащить экспортировав функцию, которая просто возвращает &__heap_base.
Причём вроде бы лучше делать это именно функцией, а не, например, через другую глобальную переменную. Когда попробовал экспортировать глобальную переменную, куда положил значение &__heap_base (экспортировать переменные можно через линкер флаг --export-dynamic + атрибут visibility("default")), то там оказалось значение отличное от того, что из функции возвращается. Типо на момент компиляции ещё точно не известно, какой адрес будет у __heap_base, потому что она автоматически определяется линковщиком, или что-то такое? С другой стороны, разве линковщик не должен такое уметь разрешать? Я просто не понимаю, почему в интернете есть примеры кода, где делается и так, и так.
До того, что проблема именно в этом, я вообще не сразу додумался. Как и до того, что у меня в коде случилось переполнение из-за того, что в одном месте использовал тип isize для вычислений и его, как оказалось, не хватало на 32-битном васме. По очереди делал step over в нативном и васмовом дебагерах и сравнивал значения переменных. Дебаг васма, кстати походу только в хроме работает, и то, только с расширением https://chromewebstore.google.com/detail/pdcpmagijalfljmkmjngeonclgbbannb?utm_source=item-share-cb
И в хроме дебаг какой-то малость кривой: после выбрасывания исключений невозможно посмотреть значения локальных переменных из-за чего невозможно разобраться, например, в каких переменных на момент отвала лежали какие-то подозрительные значения. Приходится заниматься принт стейтмент дебаггингом в любом случае.
Ещё вынес кодирование картинки в web worker, чтобы долгая кодировка не вешала основной поток и можно было хотя бы показать спиннер. Общение с воркером асинхронное, через ивенты, обмениваться можно только сериализуемыми объектами.
Из неудобств в воркере нельзя делать await на самом верхнем уровне и ещё не работают некоторые браузерные апи, например, нет доступа к дому и в частности, например, нельзя даже создать объект Image, чтобы отрисовать его в offscreen канвасе. Мне это нужно было, чтобы получить сырые пиксели загруженной картинки: в основном потоке я бы просто взял URL файла, присвоил бы его в src объекта Image, подождал бы события onload, после чего картинку можно было бы уже рисовать в канвас. И из канваса можно уже вытаскивать ImageData. А в воркере нельзя ни Image создать, ни передать его ивентом из основного потока.
В общем, решение такое, что в воркер передаёшь URL картинки, внутри качаешь её через fetch, сохраняешь в Blob, который, в свою очередь, конвертируешь в ImageBitmap через глобальную функцию createImageBitmap(), которая доступна как в основном потоке, так и в воркерах. И вот эту ImageBitmap можно уже отрисовать в канвас.
Альтернативно вроде бы можно было бы вытащить сырые пиксели в основном потоке и передать их массивом в воркер, я просто не знал, что можно так, скорее всего, это даже лучше: https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Transferable_objects
Вообще, как оказалось, передавать в воркер можно даже сам этот offscreen канвас, как я понял, это чтобы какая-то тяжёлая отрисовка в 0.01 FPS не тормозила основной поток: https://developer.mozilla.org/en-US/docs/Web/API/HTMLCanvasElement/transferControlToOffscreen
Благодаря тому, что теперь можно смотреть на результат применения разных комбинаций опций, не вбивая миллиард параметров текстом в консоль, стало ещё лучше видно, насколько оно всё же зачастую уёбищный результат генерирует в плане палитр, и дизеринг часто странно выглядит, подозреваю, что, я так и не осилил нормально его написать. А ещё оно адски медленное, особенно обычный median-cut, но там это, скорее всего, из-за того, что я временно заменил библиотечный qsort на сортировку вставками, лишь бы оно скомпилировалось.
Узнать адрес, начиная с которого идёт память, отведённая под кучу, можно так: объявляешь глобальную переменную __heap_base:
> extern unsigned char __heap_base;
Тип вроде может быть любым, потому что адресом начала кучи будет не значение, хранимое внутри, а адрес этой глобальной переменной. А в жаваскрипт этот адрес можно протащить экспортировав функцию, которая просто возвращает &__heap_base.
Причём вроде бы лучше делать это именно функцией, а не, например, через другую глобальную переменную. Когда попробовал экспортировать глобальную переменную, куда положил значение &__heap_base (экспортировать переменные можно через линкер флаг --export-dynamic + атрибут visibility("default")), то там оказалось значение отличное от того, что из функции возвращается. Типо на момент компиляции ещё точно не известно, какой адрес будет у __heap_base, потому что она автоматически определяется линковщиком, или что-то такое? С другой стороны, разве линковщик не должен такое уметь разрешать? Я просто не понимаю, почему в интернете есть примеры кода, где делается и так, и так.
До того, что проблема именно в этом, я вообще не сразу додумался. Как и до того, что у меня в коде случилось переполнение из-за того, что в одном месте использовал тип isize для вычислений и его, как оказалось, не хватало на 32-битном васме. По очереди делал step over в нативном и васмовом дебагерах и сравнивал значения переменных. Дебаг васма, кстати походу только в хроме работает, и то, только с расширением https://chromewebstore.google.com/detail/pdcpmagijalfljmkmjngeonclgbbannb?utm_source=item-share-cb
И в хроме дебаг какой-то малость кривой: после выбрасывания исключений невозможно посмотреть значения локальных переменных из-за чего невозможно разобраться, например, в каких переменных на момент отвала лежали какие-то подозрительные значения. Приходится заниматься принт стейтмент дебаггингом в любом случае.
Ещё вынес кодирование картинки в web worker, чтобы долгая кодировка не вешала основной поток и можно было хотя бы показать спиннер. Общение с воркером асинхронное, через ивенты, обмениваться можно только сериализуемыми объектами.
Из неудобств в воркере нельзя делать await на самом верхнем уровне и ещё не работают некоторые браузерные апи, например, нет доступа к дому и в частности, например, нельзя даже создать объект Image, чтобы отрисовать его в offscreen канвасе. Мне это нужно было, чтобы получить сырые пиксели загруженной картинки: в основном потоке я бы просто взял URL файла, присвоил бы его в src объекта Image, подождал бы события onload, после чего картинку можно было бы уже рисовать в канвас. И из канваса можно уже вытаскивать ImageData. А в воркере нельзя ни Image создать, ни передать его ивентом из основного потока.
В общем, решение такое, что в воркер передаёшь URL картинки, внутри качаешь её через fetch, сохраняешь в Blob, который, в свою очередь, конвертируешь в ImageBitmap через глобальную функцию createImageBitmap(), которая доступна как в основном потоке, так и в воркерах. И вот эту ImageBitmap можно уже отрисовать в канвас.
Альтернативно вроде бы можно было бы вытащить сырые пиксели в основном потоке и передать их массивом в воркер, я просто не знал, что можно так, скорее всего, это даже лучше: https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Transferable_objects
Вообще, как оказалось, передавать в воркер можно даже сам этот offscreen канвас, как я понял, это чтобы какая-то тяжёлая отрисовка в 0.01 FPS не тормозила основной поток: https://developer.mozilla.org/en-US/docs/Web/API/HTMLCanvasElement/transferControlToOffscreen
Благодаря тому, что теперь можно смотреть на результат применения разных комбинаций опций, не вбивая миллиард параметров текстом в консоль, стало ещё лучше видно, насколько оно всё же зачастую уёбищный результат генерирует в плане палитр, и дизеринг часто странно выглядит, подозреваю, что, я так и не осилил нормально его написать. А ещё оно адски медленное, особенно обычный median-cut, но там это, скорее всего, из-за того, что я временно заменил библиотечный qsort на сортировку вставками, лишь бы оно скомпилировалось.

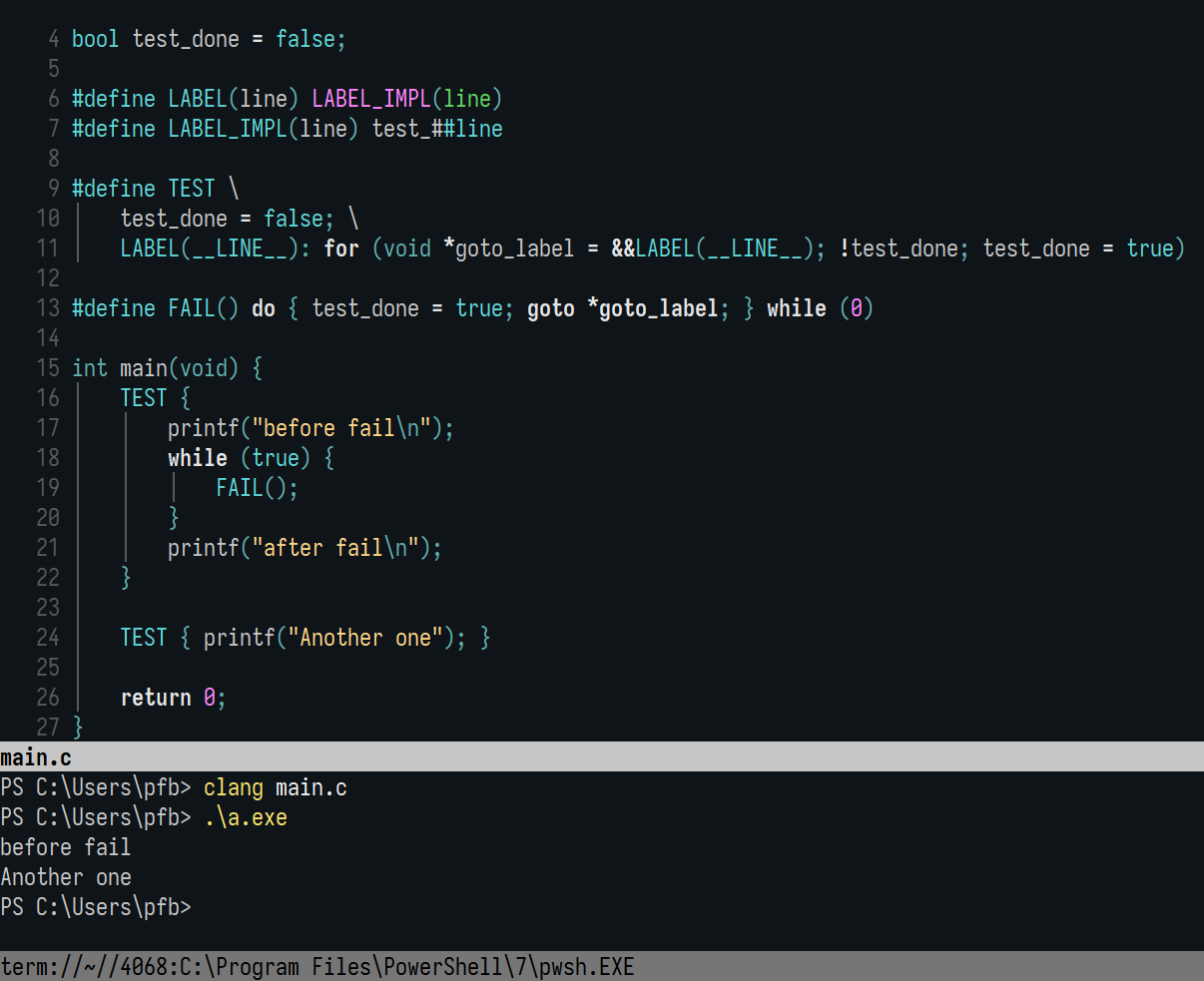
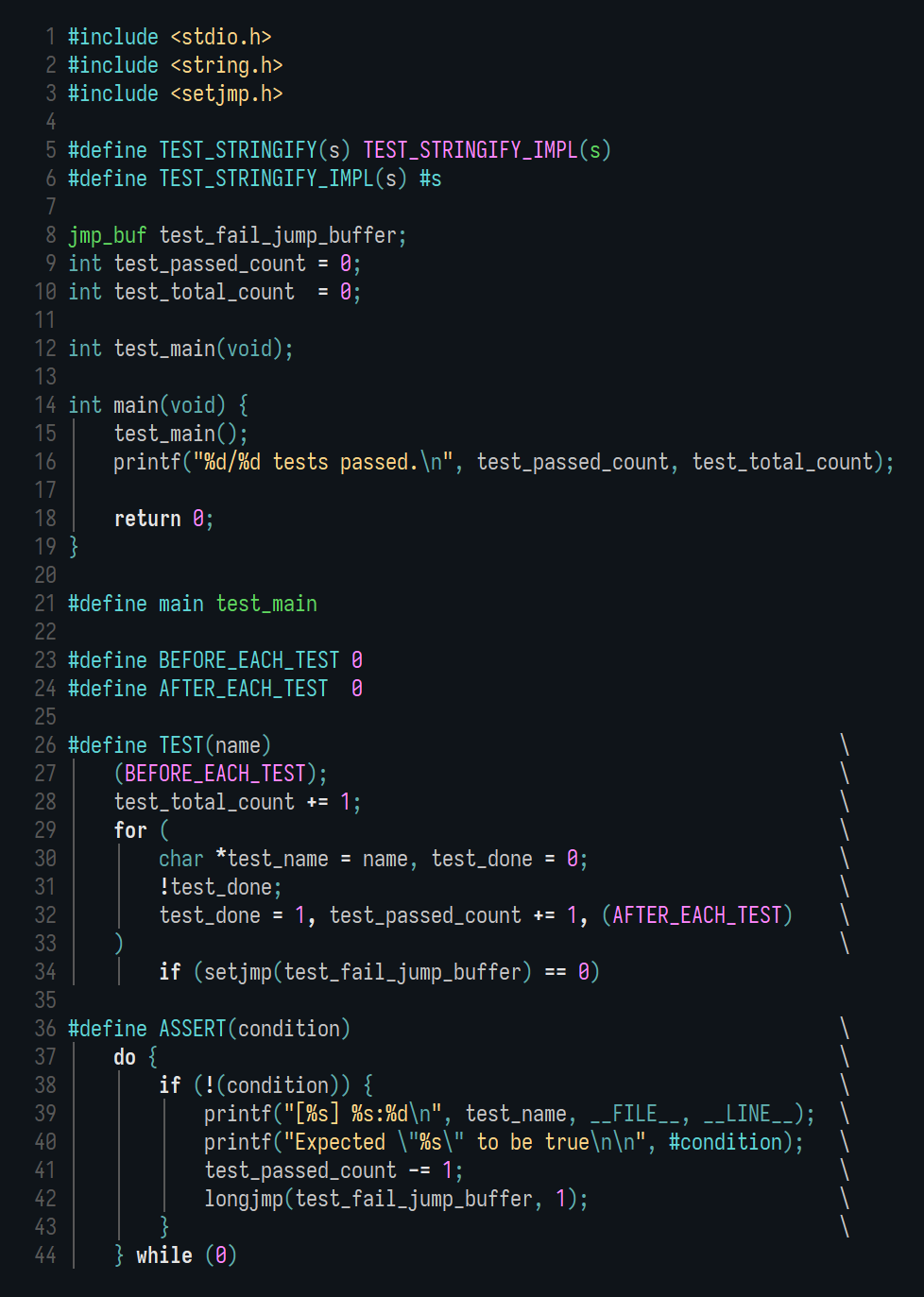
Поначалу думал, что в ассерте можно просто делать брейк, но потом вспомнил, что тогда не будут работать ассерты внутри циклов. В языке, к сожалению, нету меток для циклов, нельзя брейкнуться сразу на несколько уровней наружу. А метку для обычного goto никак не поставить: если рядом будут два теста, то они внутри одной функции создадут две метки с одним и тем же названием.
Можно было бы попробовать уникализировать название метки через __LINE__, но тогда непонятно, как обращаться к такой метке внутри ассерта. Один вариант, который пришёл на ум - это использовать computed goto: сохранить указатель на метку в переменную и потом сделать goto по адресу из переменной, но computed goto вроде бы не поддерживается в MSVC.
В коде библиотеки https://libcello.org/home которая как будто является самым страшным насилием над языком через макросы, которое я только видел, не нашёл ничего интересного.
Думал, что можно как-то заабузить довольно обскурную фичу с тем, что внутри свитч кейсов можно делать goto на метку, находящуюся прямо внутри тела свитч кейса:
https://jorenar.com/blog/gotophobia-harmful#common-code-in-switch-statement
И сделать что-то вроде:
> switch (1) {
> fail:
> case 0:
>・・char const *test_name = "Test name";
>・・break;
> case 1:
> ・・// Test code
> ・・goto fail;
> }
Но тут со скобками ничего не сходится и опять же, метка fail не может повторяться в функции более одного раза, я постоянно забываю, что вложенная область видимости тут никак не помогает.
В итоге ни до чего не додумался, кроме как до setjmp, чтобы вернуться наверх.
Нашёл ещё такое:
https://github.com/GunshipPenguin/attounit/blob/master/attounit.h
Тут тестовый код внешне похож на мой, но каждый тест - это отдельная функция. И он через какой-то атрибут __attribute__((constructor)) автоматически добавляет тестовые функции в глобальный список, по которому позже проходится внутри main.
> The constructor attribute causes the function to be called automatically before execution enters main().
Поначалу думал, что в ассерте можно просто делать брейк, но потом вспомнил, что тогда не будут работать ассерты внутри циклов. В языке, к сожалению, нету меток для циклов, нельзя брейкнуться сразу на несколько уровней наружу. А метку для обычного goto никак не поставить: если рядом будут два теста, то они внутри одной функции создадут две метки с одним и тем же названием.
Можно было бы попробовать уникализировать название метки через __LINE__, но тогда непонятно, как обращаться к такой метке внутри ассерта. Один вариант, который пришёл на ум - это использовать computed goto: сохранить указатель на метку в переменную и потом сделать goto по адресу из переменной, но computed goto вроде бы не поддерживается в MSVC.
В коде библиотеки https://libcello.org/home которая как будто является самым страшным насилием над языком через макросы, которое я только видел, не нашёл ничего интересного.
Думал, что можно как-то заабузить довольно обскурную фичу с тем, что внутри свитч кейсов можно делать goto на метку, находящуюся прямо внутри тела свитч кейса:
https://jorenar.com/blog/gotophobia-harmful#common-code-in-switch-statement
И сделать что-то вроде:
> switch (1) {
> fail:
> case 0:
>・・char const *test_name = "Test name";
>・・break;
> case 1:
> ・・// Test code
> ・・goto fail;
> }
Но тут со скобками ничего не сходится и опять же, метка fail не может повторяться в функции более одного раза, я постоянно забываю, что вложенная область видимости тут никак не помогает.
В итоге ни до чего не додумался, кроме как до setjmp, чтобы вернуться наверх.
Нашёл ещё такое:
https://github.com/GunshipPenguin/attounit/blob/master/attounit.h
Тут тестовый код внешне похож на мой, но каждый тест - это отдельная функция. И он через какой-то атрибут __attribute__((constructor)) автоматически добавляет тестовые функции в глобальный список, по которому позже проходится внутри main.
> The constructor attribute causes the function to be called automatically before execution enters main().