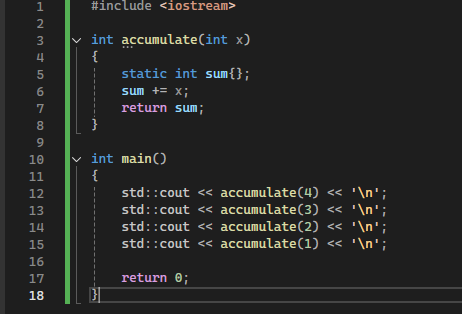
 14 Кб, 480x360
14 Кб, 480x360 10 Кб, 283x141
10 Кб, 283x141Хочется узнать как всё примерно работает под капотом. И вроде бы сейчас многие с Юнити уходят?
>И вроде бы сейчас многие с Юнити уходят?
Вот тут не подскажу. Имхо, С++ это ААА проекты в геймдеве, туда сложнее попасть. Часто эмбеддед разработка. Ещё какой-нибудь HFT, но туда даже сложнее чем в AAA gamedev.
Unity как будто проще для освоения и вката, да и можно будет выкатиться в бэкенд на c#.
Тут лучше самому помониторить рынок вакансий.
Но если не торопишься, есть свободное время, то почему бы не начать с плюсов. Правда, говорят, что даже те, кто годами на них пишут, до конца их не освоили. Но какую-нибудь БАЗУ по тому, как работает память (указатели), ООП и всё такое, можно получить.
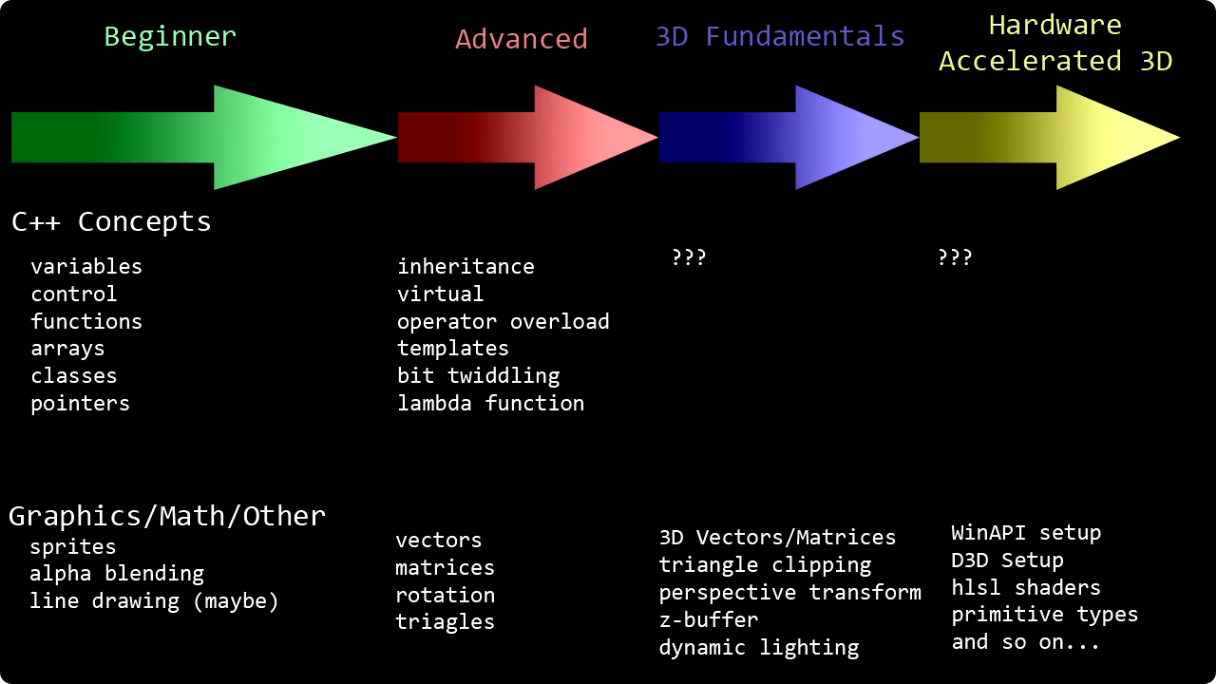
Есть же анрил, его много кто использует вроде. И мне интересно, как без чего-то готового можно было бы что-то сделать, хотя бы 2д игру уровня Марио. Я видео на ютубе нашел, оттуда картинка с оп-поста, и там сказали выбирать C++.
Я уже начал их учить, не буду менять. Думаю если будет необходимость, то перейти с одного на другое не будет особых проблем.
Насчёт работы у меня не особо горит, хотя хотелось бы конечно, как минимум из-за разницы в зп. Но я уже привык к своей, и если не получится найти другую, то и пусть.
>Есть же анрил, его много кто использует вроде.
Да, но это как правило более крупные проекты соответственно, кажется, что в них выше требования и сложнее попасть/найти работу, особенно, если ты в рф. Условно, анрил - фортнайт, ведьмак 4, Star Wars Jedi.
Хотя многие вообще используют свой движок - GTA, атсасин крид, ведьмак 3 и т.д. Там тоже скорее всего C++, взять тот же RAGE
https://rockstargames.fandom.com/wiki/Rockstar_Advanced_Game_Engine
А юнити - куча инди игр, но и не толькo. Капхед, сабнатика, амонг ас, и т.д.
В общем-то, если не к спеху, то стоит скорее ориентироваться на то, в какой геймдев ты хочешь попасть. Если делать что-то в соло или в целом что-то относительно небольшое, то юнити.
А если метишься в звёзды и особо не спешишь, то конечно плюсы.
Ну а поскольку у тебя не горят сроки, точно ничего не мешает заниматься плюсами.
>>791147
>Думаю если будет необходимость, то перейти с одного на другое не будет особых проблем.
Тут ты прав.
Будет интересно посмотреть на прогресс конкретно в геймдеве, скрины того же марио и процесса создания, если возьмёшься. Или игру про кубических коров, которые могут перемещаться во времени и между параллельными мирами... >>784686 →
 112 Кб, 724x696
112 Кб, 724x696Посмотрел на ХХ вакансии. 90 и 180 в пользу Юнити. На анриле вроде бы небольшие игры есть. Стрей например. Сабнатика новая тоже на анриле будет.
Пока не хочу особо думать куда. Дочитаю сайт и потом осмотрюсь.
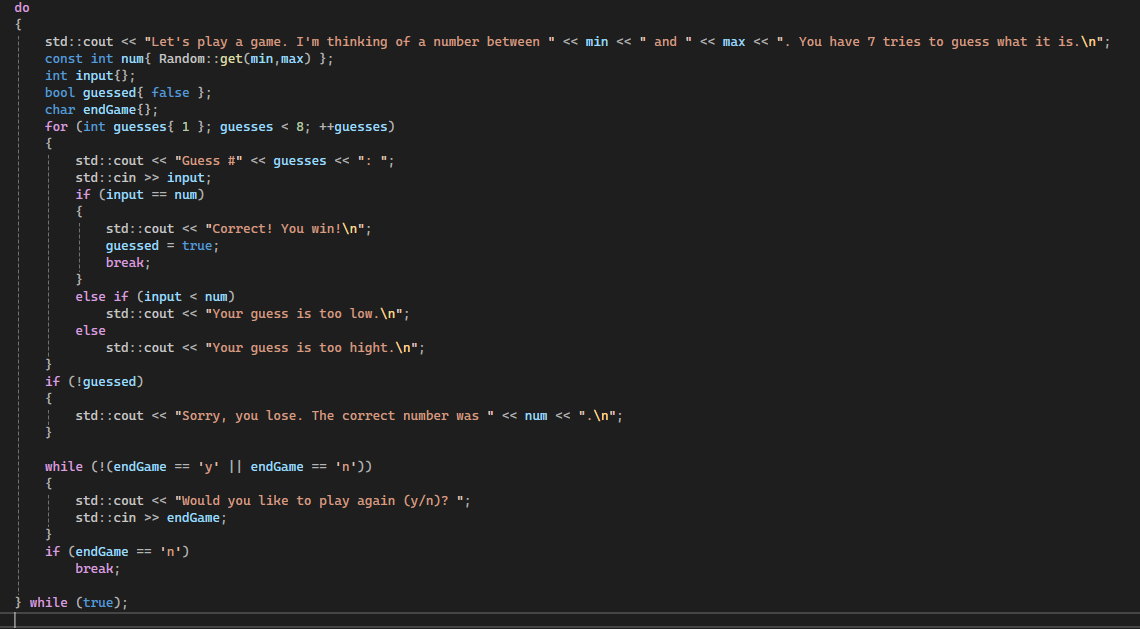
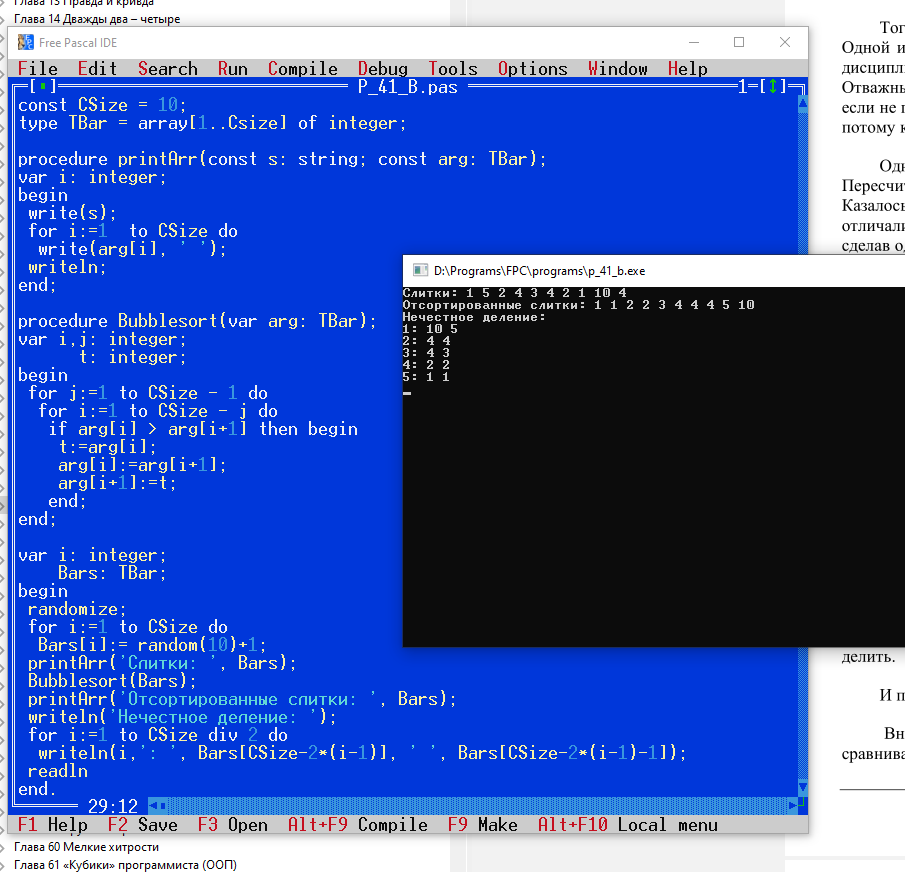
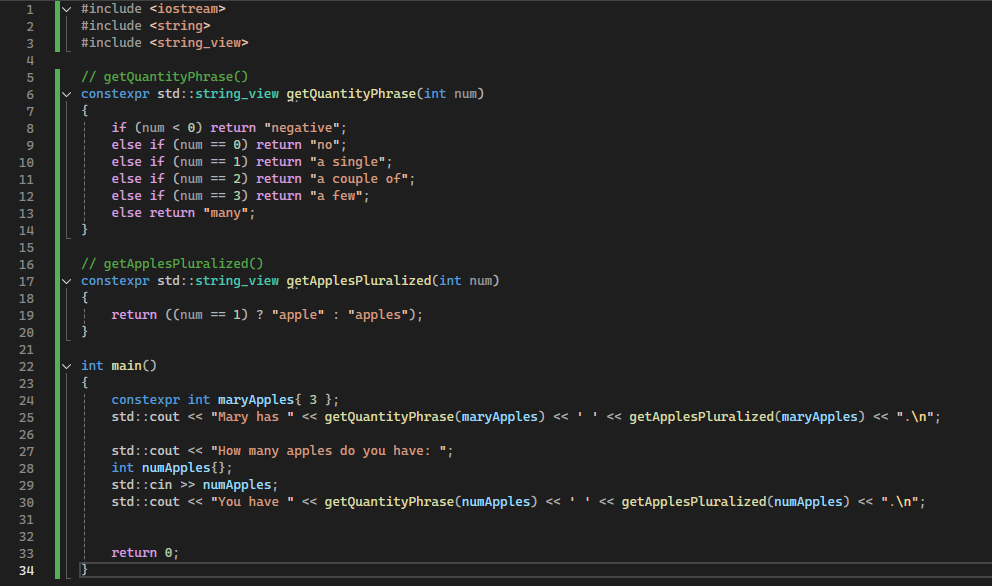 115 Кб, 992x586
115 Кб, 992x586Автор в первой функции не использовал else if, а просто ifы. Его решение наверное лучше.
Пока много текста и мало упражнений. Что самому написать идей нет.
Так же Алекс почему-то законы де Моргана описал табличкой. Хотя они довольно интуитивны. не(А и В) значит, что не должно соблюдаться и А, и В одновременно. Нас устроит, что либо опа не выполняются, либо хотя бы одно из них. Значит (неА или неВ).
 57 Кб, 800x526
57 Кб, 800x526Через 1 главу расскажут.
>>791737
>Пока много текста и мало упражнений. Что самому написать идей нет.
Можешь тут посмотреть список идей, например https://github.com/turborium/TurboTasks
Я понял constexpr просто заменяет выражения, которые можно заранее просчитать, их результатом, чтобы не тратить на это время во время работы программы. Компьютер исплняет не std::cout << 2+3, 2+3 считается заранее, и компьютер будто исполняет другой код std::cout << 5
Если я правильно понял, то вроде бы ничего сложного.
Да, опыт есть, но очень давний. Готовился к ЕГЭ по информатике, знал Паскаль. Но сдавал по итогу другие предметы. Ещё джаву пытался учить, чтобы моды для майнкрафта делать, но очень быстро, через день-два, бросил.
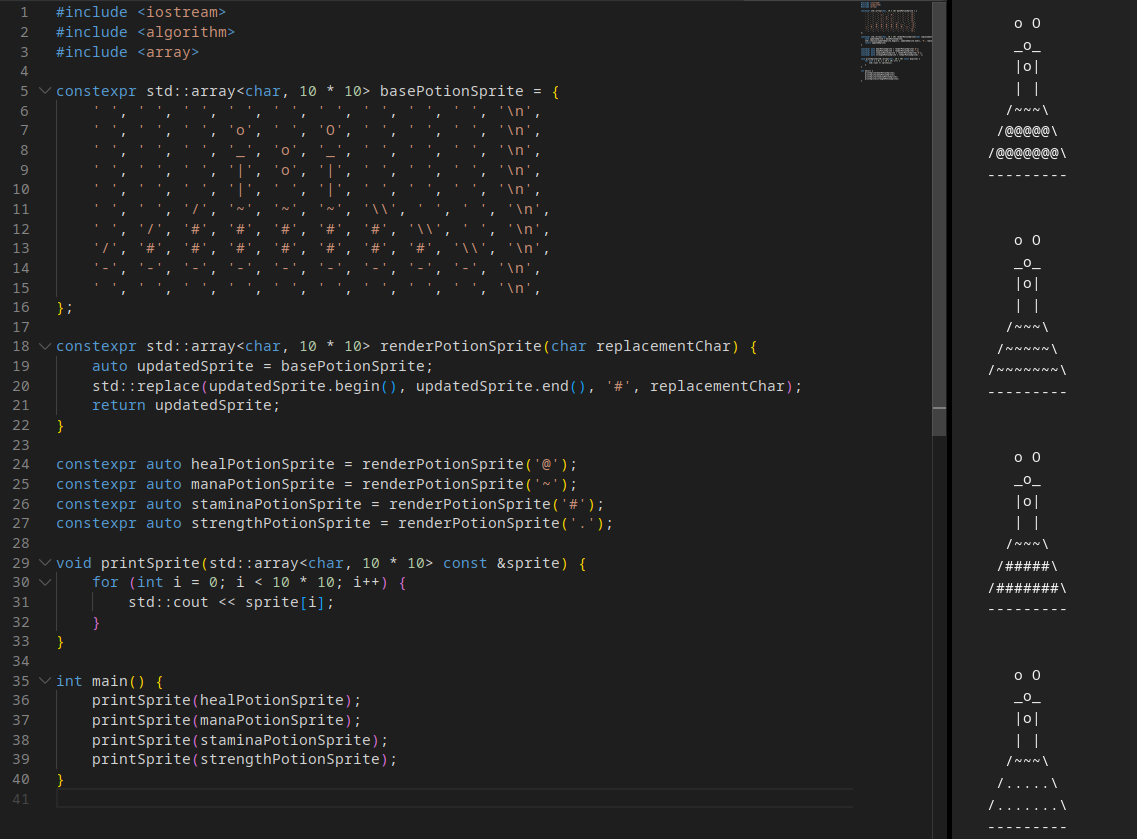 112 Кб, 1137x839
112 Кб, 1137x839>Компьютер исплняет не std::cout << 2+3, 2+3 считается заранее, и компьютер будто исполняет другой код std::cout << 5
То, что ты описываешь, называется свёрткой констант, это оптимизация в компиляторе, которая работает независимо от constexpr. Мне всё же кажется, constexpr не столько про подобные оптимизации, сколько про то, чтобы сделать какие-то вычисления заранее на этапе компиляции и потом использовать результаты этих вычислений во время работы программы.
Например, ты пишешь игру в стиле ascii арта, в которой есть много разных зелий, но спрайты зелий отличаются только тем, как выглядит содержимое колбочек. Вместо того, чтобы вручную рисовать все спрайты, можно написать код, который их генерирует. Причём логичнее было бы, чтобы спрайты генерировались единожды, только во время сборки экзешника игры, вместо того, чтобы генерировать их по новой при каждом запуске игры.
Это как раз можно через constexpr сделать. Если посмотришь в примере https://godbolt.org/z/TWW4vqY1P справа на асемблер, то увидишь там длинные последовательности из .byte - это сгенерированные на этапе компиляции спрайты, которые запишутся прямо внутрь экзешника. При запуске программы эти массивы байтов просто считываются и выводятся в консоль. А если уберёшь отовсюду в коде constexpr, то тогда спрайты будут генерироваться не во время компиляции, а при каждом запуске программы.
С constexpr много нюансов связано, которые зависят в том числе от версии стандарта плюсов, там не всё так просто. И я не знаю, зачем этим забивать голову. Для меня это выглядит как гейткиперство кодинга: как будто нарочно ебут голову какой-то си плюс плюсовой хуйнёй, чтобы ты в итоге ничего не понял. С википедией то же самое: в 90% случаев статьи написаны таким языком, что если заранее с темой не знаком, то ты вообще ничего не поймёшь. Я уже не верю в то, что это всё ненарочно.
 318 Кб, 833x294
318 Кб, 833x294Листал /pr, наткнулся на книги Стоялрова. Прочитал введение и ещё посмотрел видео автора этой темы, что ты скинул, ПетраТурбо.
Решил скорректировать планы. Начать с Паскаля, а затем Плюсы. Но учиться буду не по Столярову, он льёт много воды, и почему-то предлагает учить потом С?
Нашёл книгу "Песни о Паскале", в ней очень много задач. Буду налегать на неё, learncpp буду почитывать и дальше, чтобы не забыть и не пришлось перечитывать, но в более медленном темпе.
Как писать в тред прогресс не знаю. Темы в книге небольшие и постить решение задач после каждой главы слишком мелко. Наверное буду писать пару раз в неделю, а не каждый(е) 2 дня.
Зачем начинать с Паскаля? Это лишнее и только время отнимет. Ты же не будешь писать на Паскуале.
 301 Кб, 1062x229
301 Кб, 1062x229>он льёт много воды
Да ладно, он смешной... Временами. Мне чем-то Гоблина напоминает, не удивлюсь, если он в своё время на тупичке сидел.
>и почему-то предлагает учить потом С
Потому что Столик я теперь буду его так называть, по-моему звучит мило шиз. Он сторонник того, что, если ты начал учить программирование не с паскаля, то ты уже обречён, и тебя ничто не спасёт (пикрил как пример; честно говоря, я хотел другой его пост прикрепить, но мне лень искать). На взрослый язык для солидных дядь (Си) по Столику можно переходить только после того как написал пару тысяч строк кода на паскале. А дальше... А что дальше? Языков других больше нет. Ну, плюсы есть, но с НЕБОЛЬШИМ нюансом — это плюсы достандартизационного образца. За один твой constexpr он тебя, вероятно, пидорнул бы подальше со своего сайта. У него есть книжка по плюсам, её даже можно прочитать, она очень тонкая и там только базовые вещи написаны, но он люто ненавидит STL, поэтому её придётся изучать отдельно. Ещё, если решишься читать, к некоторым тезисам нужно относиться с осторожностью, как например к идее о том, что лесенка из if'ов лучше, чем исключения.
Чё ещё хотел сказать... Не помню. В общем, если интересно, подробно с творчеством можно ознакомиться здесь:
https://stolyarov.info
https://linux.org.ru (здесь нужно зайти в поиск и вбить имя пользователя Croco, именно Croco, с большой буквы, там регистрозависимые ники)
http://thalassa.croco.net/doc/cpp_subset.html#cplusplus
 727 Кб, 888x1500
727 Кб, 888x1500Это самый лучший язык на самом деле, просто про это никто не знает и у него нет нормальных компиляторов (как и у других языков... я джва года назад пробовал расписать ряд стандартных функций на ассемблере, сначала не знал ассемблера и делал это через C++, и очень сильно разочаровался в компиляторах C++, они то удивительно тупые, то СЛИШКОМ умные и ПОЭТОМУ делают ЕЩЁ хуже, чем если бы были тупыми), и туториалов. Эти туториалы для оБуЧеНиЯ заведомо не будут хватать звёзд с неба, но кроме них я ничего и не видел (впрочем, и не искал), кроме вот этой страницы: https://castle-engine.io/modern_pascal, и то, 3/4 тех возможностей, что на ней расписаны, я ненавижу — всё, что связано с классами, ввиду того, что экземпляры классов нельзя разместить статически, а про ещё столько же автор не рассказал. В первую очередь про это: https://wiki.freepascal.org/management_operators, возможность создавать пользовательские управляемые типы, то есть недо-аналог конструктора по умолчанию, конструктора копирования, и (авто)деструктора в C++, не такие полезные, как в C++, потому что в Паскале (пока) нет скоупов как в C++, чтобы автовызвать деструктор раньше конца функции, но хоть что-то.
Какой прекрасный пост. Ну почему меня увлек мир ебаного гламура в свое время, и не было никого рядом (и интернета толком тоже не было), кто бы подтолкнул в волшебный мир инженерии. Я ведь учился в шараге на погромиста (в 2002 поступил), куда пошел аж в 14 лет, так раньше можно было умудриться, да. Когда я узнал про демосцену очень хотел приобрести толстенную книгу по ОпенГл (да, не совсем то, но другого про программирование непосредственно графики в магазинах не было), но чёт денег так и не нашел, а потом полез в веб и купил книгу по пхп ебаному. Впрочем даже на него забил после сдачи диплома на много лет. А когда опомнился и вкатился, все сделал неправильно. Сделал штук 30 сайтов в общей сложности, самый дорогой за 150, но обычно по 20-40 были. И все на этом. Оп, ты молодец.
>Это самый лучший язык на самом деле
Ну да, если ты НЕ хочешь делать игры и НЕ хочешь найти работу, то язык охуенный. Хотя про игры ещё можно поспорить. Примерно в 2011 я недолго ходил в кружок по программированию, в котором мы рисовали всякое на паскале (ABC.net). Несколькими годами позже он появился в школе, естественно, детский уровень. И я буквально дрочил на это видео:
https://youtu.be/kDVJexd_tpY
>Ну да, если ты НЕ хочешь делать игры и НЕ хочешь найти работу
Не стоит вскрывать эту тему. . .
Учил его в школе. Большую часть мне придется просто вспомнить. К концу упомянутый книги интересные задачи, поиск, сортировки. Буду вкатываться, если не брошу, условно 1г1м вместо 1г, разница? Learn cpp я не бросаю, просто пока что буду меньше времени уделять. Меня напрягает малое кол-во задач там.
>>792094
Не понимаю, для чего учить С, зная Паскаль? Это ведь языки одного и того же уровня, из одного и того же времени.
Другие его книги, сети, парадигмы, мне не интересны. Возможно прочту у него про ассемблер в первой, там небольшая глава.
 241 Кб, 433x390
241 Кб, 433x390https://www.youtube.com/@SimpleCodeIT/playlists
Главное сначала плейлист "основы", потом - "ооп". И домашки там есть, можно делать.
Спасибо за совет. Но мне намного проще воспринимать текст, чем звук, даже в школе на уроках я ничего не понимал, только после того как учебник дома читал.
По тексту ещё и поиск проще, если что-то захочу перечитать. Плюс хочу потренироваться в чтении английского. Я почти без проблем могу читать что-то не художественное, но очень быстро устаю.
вот странно вроде прям оче этот ресурс люди рекоммендуют, но я глянул и не ахти. Там автопроверка заданий есть?
Флорентина.

Паскаль мне нравится своей словесностью, begin end выглядят приятней скобочек. Но есть один жирный минус: это секция объявлений переменных. В С++ гораздо удобней их объявлять прямо в программе. Возможно это сделано ради того чтобы мотивировать заранее продумывать что пишешь. Я и так это делаю, но продумывать до таких мелочей, сколько переменных понадобится, уже перебор.
Думал 7 главу на learncpp прочитаю быстро за пару заходов. Но ушло гораздо больше времени, и ощущение что мало что запомнил оттуда. Слишком много информации "на потом". Возможно стоит перечитать и собственноручно повбивать примеры, я же просто читал и лишь отвечал на вопросы и писал программы, заданные в упражнениях вконце главы.
Нашёл, кстати, отзыв Столярова на "Песни". Почему-то он негативный. А мне пока книжка нравится. Жаль ничего в таком стиле для С++ нет. Стиль письма "для детей" может кого-то и отталкивает, но learn cpp Алекс иногда расписывает настолько подробно, будто для людей с проблемами развития, что это становится невероятно тяжело читать. И это может соседствовать с инфой, которую уже тяжело с первого раза уловить и приходиться перечитывать, смотреть примеры.
>>792396
То что мне нравилось уже давно нет в меню. Из того что есть сейчас, наверное Диабло.
>То что мне нравилось уже давно нет в меню. Из того что есть сейчас, наверное Диабло.
Эх. Столько воспоминаний с этой пиццей. А её, оказывается, из меню убрали. Теперь ни пиццы, ни друзей, с которыми я раньше её ел, да и воспоминания уже улетучиваются.
Ты путаешь наверное. Раньше вместо Диабло была Мексиканская. Вторую на первую заменили. Сейчас Диабло всё ещё есть.
Да я жопой прочитал. Подумал, что диабло убрали из меню.

Паскаль прочёл до 20 главы. Пока там ничего нового, я это когда-то знал. В нём, кстати, switch реализован лучше. В нём нельзя провалиться в метки ниже, не нужно писать break/return, после исполнения кода относящийся к метке он автоматически выйдет из case of(паскалевский аналог switch).
Следующая 9 глава выглядит скучноватой. Но благо она коротенькая.
 728 Кб, 575x727
728 Кб, 575x727Столяров - полный долбоеб и хуесос. Вообще, обращайте внимание на либертарианские взгляды - за типичным лишертариашкой скрытается обыкновенный проткнутый левак-коммиглист. В случае столярыча это работает в полной мере. Де факто, Анька Столярова выступает за ограничению свободы слова, за концентрационные лагеря, за довольно примитивное рабство.
Кстати, кодить этот долбоеб при седых мудях тоже нихуя не умеет. На linux.org, его "фалассу" оценили как дикий говнокод нулевого похлеба.
Однако, не смотря на всё это, книги у Столярова действительно не плохие. Столяров умеет преподавать. И это напрямую связано с тем что он ТУПОЙ как пробка. Я заметил, что тупые люди, как правило не понимают довольно простые вещи с первого раза, и поэтому им приходится извиваться в мысленной гимнастике, ходить бессмысленными умозаключениями, чтобы прийти к конечному факту. Поэтому тупые люди способны более развернуто и подробно объяснять некоторый материал. То что умному просто лень рассказывать - тупой человек будет разжёвывать часами. Поэтому, книги Столярова пожалуй могу посоветовать. Но сам столяров - вырожденец недоразвитый. Ну, кстати это не особо страшно, детей то у него нет, этот долбоеб ведь чайлдфри. А вот недавно врачи обнаружили у него рак.. часики то тикают, а пиписька больше не стоит. Так и здохнет он плешивым душеым шизопреподом, который всю жизнь затирал студентам пол Unix-way сидя на убунту.
>Не понимаю, для чего учить С, зная Паскаль? Это ведь языки одного и того же уровня, из одного и того же времени.
Да не, абсолютно разные языки из разных эпох. Паскаль - это высокоуровневый язык, с поддержкой ООП, с полноценными юнитами и раздутым рантаймом. Паскаль ближе к, С++ чем к С.
Сишка - низкоуровневый язык, в идеале с нулевым рантаймом (хотя на практике это чаще всего не так). В С нет ни классов, ни конструкторов, и даже отдельных модулей нет - модули компилируются сразу в байткод и линкуются. А вот в Паскале на уровне языка можно подключить "модуль".
 89 Кб, 1280x720
89 Кб, 1280x720>НЕ хочешь найти работу
Ага, сейчас бы в 2к25 работу искать разрабом на С++. Вообще забей.
Начнем с того что "программист" - это никакой не интеллектуальный труд. Интеллектуальный труд - это псиоп. На рынке не особо нужны люди типо Рируру, рынок более заинтересован в формальном подходе и формошлёпстве. Кодишь на известных фреймворках по форме -> стабильность -> прибыль. Поэтому любой наёмный труд - это всегда рутина.
Рынок сейчас перенасыщен разного рода лодырями-кнопкодавами. Желающих плевать в потолок и получать 999ккк в секунду много, а товар сбывать некуда. Если в 2018, можно было смело пойти в любую компанию - тебя бы взяли даже без опыта, то сейчас с опытом в 3 года работы не так то просто трудоустроится.
И это я про вакансии разработчика на Java, на Python, на PHP. Если брать во внимание C++ то он никому не всрался даже с опытом работы в 6 лет. Так что чтение книг Столярова - дело не прибыльное, в чем сам Столярчик и признаётся. Можешь почитать гостевуху, там периодически появляются вкатуны, которые прочитав все его книги не могут найти работу, на что столяров им предъявляет мол: "А сколько ты полезных программ продал, сынок". Очевидно, торговля программами сейчас уже звучит как пережиток прошлого. Новоиспечённый вкатун отвечает что ничего он не продавал - и получает ответ, что стало быть он не настоящий программист, и книгу он читал зря. Чистосердечное признание Столярова, что его книга - полная хуйня бесполезная, которая не учит никаким профессиональным навыкам.
Однако, если для тебя сама цель - не заработок денег, а создание игр, то в целом создать игру можно на чем угодно. И тут Столяров оказывается как никогда прав, когда говорит что аналогов С и С++ в настоящем мире нет, какими бы кривыми и уродливыми эти два языка не были. Никакие Javы не дают столько контроля над процессом разработки, чтобы сделать игру производительнее. Так что для разработки игр вполне себе и плюсы, и си, и паскаль подходят. Гта ре3 на плюсах чисто сделана. Doom вообще на чистом С написан.
89 Кб, 1280x720>НЕ хочешь найти работу
Ага, сейчас бы в 2к25 работу искать разрабом на С++. Вообще забей.
Начнем с того что "программист" - это никакой не интеллектуальный труд. Интеллектуальный труд - это псиоп. На рынке не особо нужны люди типо Рируру, рынок более заинтересован в формальном подходе и формошлёпстве. Кодишь на известных фреймворках по форме -> стабильность -> прибыль. Поэтому любой наёмный труд - это всегда рутина.
Рынок сейчас перенасыщен разного рода лодырями-кнопкодавами. Желающих плевать в потолок и получать 999ккк в секунду много, а товар сбывать некуда. Если в 2018, можно было смело пойти в любую компанию - тебя бы взяли даже без опыта, то сейчас с опытом в 3 года работы не так то просто трудоустроится.
И это я про вакансии разработчика на Java, на Python, на PHP. Если брать во внимание C++ то он никому не всрался даже с опытом работы в 6 лет. Так что чтение книг Столярова - дело не прибыльное, в чем сам Столярчик и признаётся. Можешь почитать гостевуху, там периодически появляются вкатуны, которые прочитав все его книги не могут найти работу, на что столяров им предъявляет мол: "А сколько ты полезных программ продал, сынок". Очевидно, торговля программами сейчас уже звучит как пережиток прошлого. Новоиспечённый вкатун отвечает что ничего он не продавал - и получает ответ, что стало быть он не настоящий программист, и книгу он читал зря. Чистосердечное признание Столярова, что его книга - полная хуйня бесполезная, которая не учит никаким профессиональным навыкам.
Однако, если для тебя сама цель - не заработок денег, а создание игр, то в целом создать игру можно на чем угодно. И тут Столяров оказывается как никогда прав, когда говорит что аналогов С и С++ в настоящем мире нет, какими бы кривыми и уродливыми эти два языка не были. Никакие Javы не дают столько контроля над процессом разработки, чтобы сделать игру производительнее. Так что для разработки игр вполне себе и плюсы, и си, и паскаль подходят. Гта ре3 на плюсах чисто сделана. Doom вообще на чистом С написан.
>Если в 2018, можно было смело пойти в любую компанию - тебя бы взяли даже без опыта, то сейчас с опытом в 3 года работы не так то просто трудоустроится.
Напомню, что в 2018 так же говорили, даже в 2012 так же говорили лол. Количество дерьма просто надо побольше знать, но так всегда и было, в 2007 я вот книжки покупал, в 2012 уже много текстовой инфы в интернетах было, но приходилось, прям сильно в коде фреймворка сидеть и смотреть че как работает, ну и т.д. инфу получать все проще и проще, поэтому и надо ее знать больше.
Насчёт байтоебства, ну кто-то же микроконтроллеры все ещё программирует... В любой профессии найти классное место сложно, и погромирование к этому приходит.
>Насчёт байтоебства, ну кто-то же микроконтроллеры все ещё программирует...
Кто-то да программирует. Пара embedded разработчиков, которых препод по блату пристроил, например. А для остальных вход закрыт. Хз, я контроллеры ковырял, прогал, на собесах на все общие вопросы по С по сетям и устройстве контроллеров ответил - всё равно не взяли. Да даже бы и если взяли, в embedded разработке денег особо много нет, там 150к потолок. Я туда чисто ради интереса пытался трудоустроиться. Если уж выкатываться в IT ради денег, то лучше в ML время потратить.
>Ага, сейчас бы в 2к25 работу искать разрабом на С++. Вообще забей.
Сложнее, чем на других языках, но легче, чем на паскале. Возможно. У меня несколько знакомых в 2023-2024 находили. Правда, там не backend, а embedded. С Нулевым опытом. В резюме указывали два года.
Но вообще ты прав, особенно насчёт Столярова.

 191 Кб, 736x736
191 Кб, 736x736А почему нет? На чистом ассемблере - идея такая себе. Но с вкраплениями ассемблера, почему бы и нет. Особенно что, вопреки тому что говорит столяров, С довольно не идеален на практике. С изначально был разработан под компьютер PDP и оптимизирован под его инструкции. Перенос языка на компилятор для x86-64 вносит некоторый хаос. Возьмём следующий фрагмент кода на языке С:
int x = 1;
x = x << sizeof(int) ⚹ 8;
Попробуем предположить, какой результат у нас получится. Допустим, мы скомпилировали этот код для процессоров архитектуры ARM. Инструкция битового сдвига в рамках этой аппаратной платформы определена так, что итоговым значением переменной "x" должен быть "0". С другой стороны, мы можем транслировать нашу программу в машинный код архитектуры x86. И уже там битовый сдвиг реализован таким образом, что значение "x" не изменится и останется равным "1". Т.е. один и тот же код, на разных системах будет выдавать разный результат. Кроме того, компилятор под x86-64 терят довольно много производительности, так как в каком то смысле является костылем. Для решения проблем начали делать оптимизаторы, и тут отпитизаторы оказались довольно опасной штукой - создатель каждого оптимизатора сам решает каким путем оптимизировать. Т.е. в некоторых случаях, а твоей программе компилятор мог бы взять и заменить код на уязвимый, а порой может быть и вовсе работающий некорректно. Получается что программируя на С, ты не можешь гарантировать, что твоя программа будет работать вообще.
Также сам по себе С испольщует стеклвый фрейм, так что частое выполнение функций и trunk-функций даёт о себе знать в узких горлышках программы. Пока фрейм подготовится, пока процессор распердиться - на всё это уходит довольно много тактов процессора. И если ты делаешь графический рендер для своей игры, то на момент интерполяции текстур по треугольнику, для тебя важна каждая миллисекунда. Ассемблер, мне кажется мог бы помочь, именно вот в таких узких местах.
Интересный тред. Надеюсь ОП создаст что-то прикольное.
191 Кб, 736x736А почему нет? На чистом ассемблере - идея такая себе. Но с вкраплениями ассемблера, почему бы и нет. Особенно что, вопреки тому что говорит столяров, С довольно не идеален на практике. С изначально был разработан под компьютер PDP и оптимизирован под его инструкции. Перенос языка на компилятор для x86-64 вносит некоторый хаос. Возьмём следующий фрагмент кода на языке С:
int x = 1;
x = x << sizeof(int) ⚹ 8;
Попробуем предположить, какой результат у нас получится. Допустим, мы скомпилировали этот код для процессоров архитектуры ARM. Инструкция битового сдвига в рамках этой аппаратной платформы определена так, что итоговым значением переменной "x" должен быть "0". С другой стороны, мы можем транслировать нашу программу в машинный код архитектуры x86. И уже там битовый сдвиг реализован таким образом, что значение "x" не изменится и останется равным "1". Т.е. один и тот же код, на разных системах будет выдавать разный результат. Кроме того, компилятор под x86-64 терят довольно много производительности, так как в каком то смысле является костылем. Для решения проблем начали делать оптимизаторы, и тут отпитизаторы оказались довольно опасной штукой - создатель каждого оптимизатора сам решает каким путем оптимизировать. Т.е. в некоторых случаях, а твоей программе компилятор мог бы взять и заменить код на уязвимый, а порой может быть и вовсе работающий некорректно. Получается что программируя на С, ты не можешь гарантировать, что твоя программа будет работать вообще.
Также сам по себе С испольщует стеклвый фрейм, так что частое выполнение функций и trunk-функций даёт о себе знать в узких горлышках программы. Пока фрейм подготовится, пока процессор распердиться - на всё это уходит довольно много тактов процессора. И если ты делаешь графический рендер для своей игры, то на момент интерполяции текстур по треугольнику, для тебя важна каждая миллисекунда. Ассемблер, мне кажется мог бы помочь, именно вот в таких узких местах.
Интересный тред. Надеюсь ОП создаст что-то прикольное.
 80 Кб, 673x800
80 Кб, 673x800> trunk-функций
Что такое trunk-функция? Не гуглится вообще никак.
> Также сам по себе С испольщует стеклвый фрейм
А ты уверен, что это написано в стандарте? На x64 есть всякие fastcall-конвенции, которые кучу аргументов кидают через регистры.
Хотя, конечно, иногда вызовы функций могут быть дорогими. Константин Владимиров, например, любит показывать, как Сишный qsort сосёт у std::sort приплюснутого, потому что компиляторы C++ имеют доступ к типу объекта переданного в качестве функтора, и вследствие могут заинлайнить вызов. А компиляторы Си не могут, потому что информация о типе затирается тут, кстати, забавно вышло — я как будто говорю о компиляторах C++ и C как о разных программах, лол.
Но тут, надо понимать, имеется в виду косвенный вызов функции. А на явных, наверное, особо нет смысла экономить.
> И если ты делаешь графический рендер для своей игры, то на момент интерполяции текстур по треугольнику, для тебя важна каждая миллисекунда
Интерполяция текстур по треугольнику на процессоре? Софтвейр рендер делаешь что-ли? Тут, наверное, уже мало что поможет...
>Что такое trunk-функция? Не гуглится вообще никак.
Ну, типо варпер функция, которая вызвает другую функцию, чисто для инкапсуляции. Просто в дизассемблере она почему-то thunk называется, я поэтому так привык называть.
>А ты уверен, что это написано в стандарте?
Насколько я понял, в стандарте вроде бы не написано ничего вообще. Т.е. стандарт компилятора С специально оставляет "пустые места" для того чтобы разработчики сами могли решить как им реализовать ту или иную конструкцию. Из-за этого код и становится нестабильным, потому что на олной платформе он использует одни решения, а на другом - другие.
>Софтвейр рендер делаешь что-ли? Тут, наверное, уже мало что поможет...
Да)) Но мне просто интересно, вот в half-life был же вариант "software render". И всё нормально работало, не тормозило. Получается програмные рендеры всё таки в теории можно как-то оптимизировать, мб распараллелить. Почему то у меня только тормознутое говно получилось, сколько бы я не старался.
Ещё нужно изучить drm-kmod драйвера, чтобы можно было напрямую с видеокартой работать. Тогда можно аппаратный рендер добавить. Типо софтверный - общий для всех, а аппаратный - если повезёт.


>Также сам по себе С испольщует стеклвый фрейм
Да ты ёбу дал, это понятие не C, а платформы и её соглашений, тебе никто не запрещает придумать свою платформу, на которой вместо стекового фрейма будет (...кхм... ну, что-нибудь...), и написать под неё компилятор C. Более того, компилятору под «нормальные» платформы тоже не запрещено вместо стекового фрейма реализовать вызовы и локальные переменные как-то по другому; банально функция, заинлайненная в другую функцию, или функция, «вызванная» из другой функции последним действием через jmp вместо call — примеры таких «вызовов» без фрейма. Если под trunk-функциями имелись в виду leaf-функции, то это ТОЖЕ чисто понятие платформы. (А, ок.)
>в half-life был же вариант "software render". И всё нормально работало, не тормозило.
Играл я в неё недавно, и софтварный рендер выставлял... На высоких разрешениях он тормозит именно так, как от него можно ожидать. Старые ЭЛТ-мониторы умели нормально отображать низкие разрешения на весь экран.
>>794943
>fastcall-конвенции
...И даже соглашения платформы можно не соблюдать, если не хочется: https://devblogs.microsoft.com/oldnewthing/20150128-00/?p=44813, они нужны только для взаимодействия с остальным миром. Другое дело, что остальным миром может являться ОС и от неё может требоваться работоспособность механизма, которым Access Violation можно поймать и обработать как исключение, так что с внешним миром потенциально взаимодействует любая точка программы и в такой ситуации совсем борзеть всё же не стоит, но на практике вот автор https://github.com/synopse/mORMot2/blob/master/src/core/mormot.core.fpcx64mm.pas, который явно считает это промышленным решением, хладнокровно выебал в рот все эти соглашения Win64, что «пролог и эпилог функции должны выглядеть так-то и так-то, никаких push посередине, а то система её корректно раскрутить не сможет» (https://learn.microsoft.com/en-us/cpp/build/prolog-and-epilog), в теории достаточно охуевший компилятор C (GCC с достаточно охуевшими флагами, я не разбираюсь) тоже мог бы это сделать.
>Также сам по себе С испольщует стеклвый фрейм
Да ты ёбу дал, это понятие не C, а платформы и её соглашений, тебе никто не запрещает придумать свою платформу, на которой вместо стекового фрейма будет (...кхм... ну, что-нибудь...), и написать под неё компилятор C. Более того, компилятору под «нормальные» платформы тоже не запрещено вместо стекового фрейма реализовать вызовы и локальные переменные как-то по другому; банально функция, заинлайненная в другую функцию, или функция, «вызванная» из другой функции последним действием через jmp вместо call — примеры таких «вызовов» без фрейма. Если под trunk-функциями имелись в виду leaf-функции, то это ТОЖЕ чисто понятие платформы. (А, ок.)
>в half-life был же вариант "software render". И всё нормально работало, не тормозило.
Играл я в неё недавно, и софтварный рендер выставлял... На высоких разрешениях он тормозит именно так, как от него можно ожидать. Старые ЭЛТ-мониторы умели нормально отображать низкие разрешения на весь экран.
>>794943
>fastcall-конвенции
...И даже соглашения платформы можно не соблюдать, если не хочется: https://devblogs.microsoft.com/oldnewthing/20150128-00/?p=44813, они нужны только для взаимодействия с остальным миром. Другое дело, что остальным миром может являться ОС и от неё может требоваться работоспособность механизма, которым Access Violation можно поймать и обработать как исключение, так что с внешним миром потенциально взаимодействует любая точка программы и в такой ситуации совсем борзеть всё же не стоит, но на практике вот автор https://github.com/synopse/mORMot2/blob/master/src/core/mormot.core.fpcx64mm.pas, который явно считает это промышленным решением, хладнокровно выебал в рот все эти соглашения Win64, что «пролог и эпилог функции должны выглядеть так-то и так-то, никаких push посередине, а то система её корректно раскрутить не сможет» (https://learn.microsoft.com/en-us/cpp/build/prolog-and-epilog), в теории достаточно охуевший компилятор C (GCC с достаточно охуевшими флагами, я не разбираюсь) тоже мог бы это сделать.
>Да ты ёбу дал, это понятие не C, а платформы и её соглашений, тебе никто не запрещает придумать свою платформу, на которой вместо стекового фрейма будет
Так тогда и получается, что на одной платформе, допустим битовый сдвиг будет спамит 11 в новые биты, а на другой 00. Т.е. если мы битовые сдвиги используем для расчета света, то на одной платформе текстура может оказаться белой, а на другой зелёной. В чём я не прав?
Или вот по-лучше есть пример как раз в учебнике сторярыча. Там он демонстрирует пример остаточной рекурсии. Так вот, если программу написать не используя остаточную рекурсию, т.е. чтобе стек рос по мере вызова функций, то получается, на некоторых платформах где стек не используется, программа может отработать стабильно и даже пройти все юнит тесты. Но стоит эту программу портировать на другую платформу - она рухнет со "стек оверфлоу". Насколько я знаю высокоуровневые языки типо Java эти вопросы решают при помощи собственной среды выполнения jvm, именно поэтому ими в энтерпрайсе и пользуются. А С - нет, не обязан. Т.е. имея ввиду как раз специфику и минималистичность языка, мы получаем на выходе неоднозначные компиляторы.
 269 Кб, 1448x2048
269 Кб, 1448x2048Во-первых, «а вы так не делайте». GIGO — это нормально, если функция не имеет какого-то однозначного результата в каком-то случае, то ему нормально быть неопределённым. В платформозависимом коде можно положиться на конкретное поведение (так-то то, что на x86 сдвиг автоматически берёт %, часто удобно), в универсальном — «не делайте так», зато не полностью определённые функции проще реализовать на всех уровнях вплоть до цены в транзисторах.
О, придумал иллюстрацию: радиус сходимости рядов для вычисления трансцендентных функций. Если тебе нужно реализовать функцию тангенса, то ты можешь использовать ряд Тейлора (или другого мужика), но у него будет радиус сходимости — π/2 (на практике радиус «быстрой сходимости» может быть ещё меньше), и если функция tan(x) нужна для произвольного x, то тебе понадобится предварительный этап argument reduction, приводящий x к нужному диапазону. Этот этап сильно сложнее, чем вычисление самого ряда (поверь) (ладно, вот здесь сравни основную функцию синуса с вспомогательной функцией k_rem_pio2, до которой доходит argument reduction в «очень плохих случаях»: https://gitlab.com/freepascal.org/fpc/source/-/blob/cb4bcaa068c86564249be6f58c28458c8fa839d0/rtl/inc/genmath.inc#L1453), так что если функция всё-таки НЕ нужна для произвольного x, то ты можешь не делать argument reduction, а вместо этого сказать, что при x > π/2 функция возвращает фигню. Это оставит тебе пространство для манёвра; ты сможешь даже поменять мужика; у нового мужика будет другой размер ч радиус или другие значения вне радиуса, но это неважно, ведь ты оставил за собой право вернуть фигню.
Метафорично, ты / Столик предлагаете мне пожертвовать возможностью прыгать по хуям ради штабильности того, что меня и ебать-то не должно.
 67 Кб, 665x475
67 Кб, 665x475>платформозависимом коде можно положиться на конкретное поведение
Да, при том что я вот не понимаю в чём фишка якобы "платформо-независимой" java если ошибка StakOverflow таки возникает. Т.е. вот коллеги мне мимо делом нарассказывал, что С++ - фигня, байтоёбство для дрочеров памяти, а вот в java смазка выделяется сама! ни о какой памяти думать не нужно. Но стоит сделать while(1) { new.. так сразу программа вылетает с ошибкой Out of memory. А що таке?! Почему сборщик мусора не спас? Вернее.. зачем нужен сборщик мусора, если он спасает не от всего. Получается, что вот вы сделали "высокоуровневый язык" для быстрой корпоративной разработки... казалось бы, значит нам не обязательно знать "что там под капотом". Но фактически то это не так, всё равно приходится знать что там под капотом, понимать концепции стека pop, push чтобы хоть что-то написать. Так тогда бы почему не выкинуть эту жаву и не начать байтоёбствовать. Ведь если понимать все нюансы работы с памятью, то ошибок утечки памяти избежать легко.
>так что если функция всё-таки НЕ нужна для произвольного x, то ты можешь не делать argument reduction, а вместо этого сказать, что при x > π/2 функция возвращает фигню. Это оставит тебе пространство для манёвра; ты сможешь даже поменять мужика
Ну так то мне кажется что гибкость программы идёт в разрез с её производительностью. Т.е. чем более программа примитивна, тем более она производительна. Так что каждый раз надо бы задуматься "а нужна ли универсальность в конкретно этом случае". И если функция известна заранее, почему бы не использовать готовый результат в виде таблицы, а промежуточные варианты просто с интерполировать. Даже если взять банально вычисление квадратного корня - програмно его фиг высчитаешь.
>Метафорично, ты / Столик предлагаете мне пожертвовать возможностью прыгать по хуям ради штабильности того, что меня и ебать-то не должно.
А я чё, я даже не программист. Просто сижу тут уши грею.
Столярову вообще ничего помоему не нравиться - на всё ворчит, все у него гниды и предатели, всех пристрелить "маленькими и в кроватках".
67 Кб, 665x475>платформозависимом коде можно положиться на конкретное поведение
Да, при том что я вот не понимаю в чём фишка якобы "платформо-независимой" java если ошибка StakOverflow таки возникает. Т.е. вот коллеги мне мимо делом нарассказывал, что С++ - фигня, байтоёбство для дрочеров памяти, а вот в java смазка выделяется сама! ни о какой памяти думать не нужно. Но стоит сделать while(1) { new.. так сразу программа вылетает с ошибкой Out of memory. А що таке?! Почему сборщик мусора не спас? Вернее.. зачем нужен сборщик мусора, если он спасает не от всего. Получается, что вот вы сделали "высокоуровневый язык" для быстрой корпоративной разработки... казалось бы, значит нам не обязательно знать "что там под капотом". Но фактически то это не так, всё равно приходится знать что там под капотом, понимать концепции стека pop, push чтобы хоть что-то написать. Так тогда бы почему не выкинуть эту жаву и не начать байтоёбствовать. Ведь если понимать все нюансы работы с памятью, то ошибок утечки памяти избежать легко.
>так что если функция всё-таки НЕ нужна для произвольного x, то ты можешь не делать argument reduction, а вместо этого сказать, что при x > π/2 функция возвращает фигню. Это оставит тебе пространство для манёвра; ты сможешь даже поменять мужика
Ну так то мне кажется что гибкость программы идёт в разрез с её производительностью. Т.е. чем более программа примитивна, тем более она производительна. Так что каждый раз надо бы задуматься "а нужна ли универсальность в конкретно этом случае". И если функция известна заранее, почему бы не использовать готовый результат в виде таблицы, а промежуточные варианты просто с интерполировать. Даже если взять банально вычисление квадратного корня - програмно его фиг высчитаешь.
>Метафорично, ты / Столик предлагаете мне пожертвовать возможностью прыгать по хуям ради штабильности того, что меня и ебать-то не должно.
А я чё, я даже не программист. Просто сижу тут уши грею.
Столярову вообще ничего помоему не нравиться - на всё ворчит, все у него гниды и предатели, всех пристрелить "маленькими и в кроватках".
 698 Кб, 692x845
698 Кб, 692x845Скачал вместо этого книгу Страуструпа. Она есть во всех топах, а так же в ней много заданий. Надеюсь пойдёт так же легко, как и Паскалик.
А чё столярова не читануть. У него глава про С++ довольно урезана, т.е. там объясняются только самые базовые конструкции C++, не написано ничего ни про STL, ни про паттерны какие-нибудь. Но по сути, то что объясняется это и есть сам чистый С++. Потом, если охота можно и чего другого навернуть.
Не, не пойдёт. Страуструп ещё хуже.
Из того, что я видел, рекомендуют книгу Харви Дейтел, Пол Дейтел «Как программировать на C++».
Ещё лекции Константина Владимирова крутые и книжка Скотта Майерса «Эффективный и современный C++», но это для тех, кто уже смешарик.
Почти дочитал Песни, осталось глав 10-15. Страуструп меня задушил. Перешел на видеоуроки от ChiliTomato с ютуба, дошёл до урока со Змейкой. Думаю за пару дней осилю и запощу результат.
Огоя, я думал ты все
Ничесе, я думал ты все
 11,1 Мб, mp4,
11,1 Мб, mp4,800x600, 0:34
Думал смотреть все туториалы заново, вдруг забыл что. Но пробежал глазами по вики, по уже пройденным, вроде все темы помнил. Вернулся к змейке, где и остановился. Сделал "рабочую" версию за день, но без домашки. Но решил отполировать сверх того, на что ушло ещё два дня, так же сделал домашку.
Полировка заключалась в следующем: добавил прохождение сквозь стены, что повлекло за собой следующие проблемы
1) нужно было модернизировать алгоритм перемещения
2) если на краю области есть препятствие, то при перемещении через стену змейка проходила сквозь него
Так же сделал не совсем тупую систему спавна цели и препятствий. Препятствия появляются случайно, но они НЕ могут появиться прямо перед головой змейки, внутри неё, поверх другого препятствия и поверх цели. Цель появляется случайно, и так же не может появиться внутри препятствия и змейки. Ещё, когда змейка кусает саму себя, голова не заезжает в тело, а так же она не может укусить себя за хвост.
У меня в детстве на телефоне была именно такая версия, об края не убивалась, и кусала себя без наезда поверх. Хотел добавить ещё систему жизней и очков. Но устал. Хочу двигаться дальше по туториалам.
"Песни о паскале" мало желания читать, из-за перерыва пыл поубавился, хотя книга хорошая, но консольные приложения делать скучно. Но я её почти прочел, и как раз дошел до глав с сортировками, а дальше графы. Может в будущем понадобится. Потому хочется добить, а не бросать почти в самом конце.
 45 Кб, 799x168
45 Кб, 799x168На паскале решаю только задания из книги "песни о паскале".
Змейка на с++. Учу его по видеоурокам от пика - ChiliTomatoNoodle

 3,8 Мб, 3000x4244
3,8 Мб, 3000x4244Автор не круто сделал, он этот подход с отдельными типами для массивов, просто чтобы их передавать в функции, по старой памяти из Turbo Pascal тянет (ну или формально примеры из книжки рассчитаны на компилируемость в нём... но смысл, когда всё равно все будут использовать актуальный ❤️FPC❤️).
Вот так круто: https://godbolt.org/z/Gj37han3Y. Этой фиче 27 лет, и она «базовая» в том смысле, что тупо исправляет ошибку изначального дизайна языка без каких-то сложных подкапотных механизмов (логика, по которой можно не хотеть давать ученикам, например, динамические массивы).
Автор выпустил книгу в 2010. Тогда, наверное, в учебных учреждения Турбо был всё ещё актуален. Я примерно в то время ходил в кружок по программированию. Там стояла винХП и ТурбоПаскаль.
Не знаю, зачем я туда ходил, кружок был платным. Я очень быстро перестал что-либо понимать и просто списывал у гораздо более умного друга, с кем туда и пошёл изначально.
Почему тебе нравится FPC?
Понял про себя, что мне неприятно делать несколько дел. Я из-за этого начинаю прокрастинировать. Если сфокусироваться на одном, то могу потратить много времени занимаясь этим. Потому зря, наверное, начал Паскаль параллельно. С играми в прошлом так же было, кстати. Никогда не играл в несколько игр параллельно, а выбирал одну и играл пока не пройду/надоест.
Но осталось совсем немного, учитывая что две последние главы филлерные, надеюсь за две недели точно добью и полностью сосредоточусь на курсе от Чили.
Книга в целом отличная, но лично мне она не подходит. В книге много мелких простых заданий, мне же больше по душе делать что-то одно и большое. Как выше змейку например. Или можно делить на мелкие подзадачи, но чтобы они были ступеньками к чему-то большому, а не независимыми.
Ну и автор очевидно по послесловию метил в школьников стремящихся к олимпиадами. Я уже 10+ лет не школьник и олимпиадные задачи не вызывают интереса.
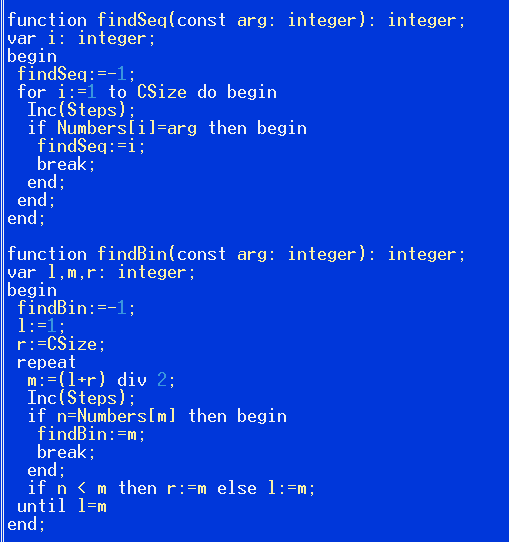
Написал двоичный поиск. Почему-то очень долго тупил, как его написать, минут 20 размышлений потребовалось, чтобы дойти до введения переменных для левой/правой границы.
Существует корреляция между копать глубоко в любимый стак и "мне не важна зп, работа, ирл".
1 месяц c#
2 месяца unity
3 первая игра для вебплощадок.
Итого полгода.
пчел додомастер
Не хочу
Нет, чувак. Ты хоть работал когда нибудь? На работе нужно быть по сути удобным инструментом. Но собеседование смотрят сколько лично ты полезных проектов сделал на каком-то конкретном языке. Ключевое слово "полезных". Если ты сделал змейку, и хорошо знаешь синтаксис языка - полетишь пинком под зад.
 161 Кб, 1234x754
161 Кб, 1234x754Я бы возможно так поступил, будь у меня идея для игры. Она есть, но очень мутная и трудноосуществимая.
Если бы я хотел работать, то я бы хотел, скорее, создавать инструменты для создания игр, а не сами игры.
Я получаю менее половины от 100к. На жизнь хватает, но впритык, и у меня есть своё жилье.
>>817032
Я её делал просто как задание из уроков. Причём тут инкам?
https://wiki.planetchili.net/index.php/Beginner_C%2B%2B_Game_Programming_Tutorial_14

Здесь на скрине у меня была логическая ошибка. Первое это условие выхода l=m. Если n > Arr[m], то l:=m, и досрочный выход.
Можно поставить условие l=r. Допустим мы пришли к виду [][]LR[][], тогда m = L, и если n < Arr[m], то R:=L и выходим из цикла. Но если n > Arr[m], то L=m, бесконечный цикл.
Выход не дать ползункам застрять на месте, объявить l:=m+1 или r:=m-1; И условие выхода если ползунки разойдутся, l>r;
Книгу песни о Паскале я дочитал. В общем книга хорошая, но довольно объемная, много тривиальных заданий. Я изначально начал решать все, не пропуская ни одного, но к концу это надоело, но тк я до этого решал все, то и дальше хотелось решать все, что замедляло. Если её сократить, то была бы прям очень хорошая. Не знаю, почему она не понравилась Столярову.
В целом аноны выше были правы. Не стоило распыляться на Паскаль. Хотя, может, опыт из него и из решения заданий позволит быстрее осваивать С++, чем если бы его не было. Песни оканчивались адресами, динамическими переменными, графами и поиском кратчайшего пути на них. Потратил на всю книгу где-то 60-70 дней. Это дни когда я открывал и что-то делал, между ними были пропуски. Но мог сделать 1-2 заданий за 20 минут и закрыть. И следующие сделать в другой день, потратив так же не много времени.
Продолжаю проходить beginner плейлист от Chili. Почти закончил, осталось несколько уроков. На клон арконойда потратил дня 3, делал после работы. Приветствующей картинки и в случае проигрыша нету, тк инструмент для конвертации картинок не скачать, ссылки мертвые. Дольше всего думал как заставить мерцать в случае упадка мяча, и как сделать отскок зависящим от расстояния.
Кстати сменил работу. Но оказалось на более худшую, тяжелее и меньше свободного времени. Месяца 3 проработаю и буду искать другую.
>Не знаю, почему она не понравилась Столярову.
А что вообще когда либо нравилось столярову? Старый перд, ничего не любит, сидит в своём сербском щитхоле, от рака дохнет.
>Хотя, может, опыт из него и из решения заданий позволит быстрее осваивать С++
Бля, уже несколько месяцев прошло, ты до сих пор учебник не выбрал. Бери второй том столярова по С, и третий по С++, потом досыпь STL и норм будет. Учебники у него нормальные.

>ты до сих пор учебник не выбрал
Почему? Учебник нет, но я по плейлисту, видеоурокам учусь. Почти beginner плейлист закончил, осталось 3 урока, я сейчас на 22, сегодня его закончу и останутся лишь два.
https://www.youtube.com/@ChiliTomatoNoodle/courses
Ну ладно.
Но пикрил выглядит дебильтно. Во-первых обучение програмиированию не связано с векторной алгеброй. Хз зачем там насыпали матрицы и векторы - это всё на первом курсе в университете объясняют, понять как работает С++ это вообще не даёт. Камон, урок называется "С++", а обучают векторной алгебре - что за ебланство. Векторы можно хоть на С, хоть на Паскале, хоть на ассемблере реализовать. У столярова как раз плюс в том что акцент сделан именно на самом языке. То есть вот что такое С, и почему С - не паскаль? Потому что С - низкоуровневых язык, с околонулевым рантаймом, там каждая операция производит некоторые действия с памятью. Там даже есть глава "программа на С без стандартной библиотеки" которая демонстрирует чем по своей сути является С, и почему нововведения из gcc выглядят довольно нелепо. В следующий книге уже идёт повествование о С++, и там уже наглядно поясняется разница между низким байтоёбским уровнем, и высоким. То есть что такого делает компилятор С++, что позволяет сократить труд по программированию. Например вот пишешь ты void func(int a) - на обычном С под функцию строго выделяются байты. А в С++, на самом деле выделяются байты под функцию _int_func, чтобы её можно было перегрузить и сделать такую же но _float_func допустим. И компилятор в зависимости от аргумента выберет необходимую.
Чем это полезно вообще? С++ довольно топорный и низкоуровневый. Если не понимать как он устроен то можно подумать что он не работает как нужно. На самом деле он просто странный - создатели и добавили в него "высокоуровневые фишки" при этом байтоёбство оставили. В итоге получилось что-то всратое, но говорят что полезное, так как производительность он всяко больше выдаёт.
Во-вторых, если ты чисто хочешь разрабатывать игры, то зачем тебе разрабатывать графику, и зачем тебе С++? Разработка игр сводится к написанию скриптовухи, и разработке моделек. Это довольно душное занятие. Если начать писать свою графику, в какой-то момент поймёшь что нахуй эти видеоигры вообще нужны.
Ну ладно.
Но пикрил выглядит дебильтно. Во-первых обучение програмиированию не связано с векторной алгеброй. Хз зачем там насыпали матрицы и векторы - это всё на первом курсе в университете объясняют, понять как работает С++ это вообще не даёт. Камон, урок называется "С++", а обучают векторной алгебре - что за ебланство. Векторы можно хоть на С, хоть на Паскале, хоть на ассемблере реализовать. У столярова как раз плюс в том что акцент сделан именно на самом языке. То есть вот что такое С, и почему С - не паскаль? Потому что С - низкоуровневых язык, с околонулевым рантаймом, там каждая операция производит некоторые действия с памятью. Там даже есть глава "программа на С без стандартной библиотеки" которая демонстрирует чем по своей сути является С, и почему нововведения из gcc выглядят довольно нелепо. В следующий книге уже идёт повествование о С++, и там уже наглядно поясняется разница между низким байтоёбским уровнем, и высоким. То есть что такого делает компилятор С++, что позволяет сократить труд по программированию. Например вот пишешь ты void func(int a) - на обычном С под функцию строго выделяются байты. А в С++, на самом деле выделяются байты под функцию _int_func, чтобы её можно было перегрузить и сделать такую же но _float_func допустим. И компилятор в зависимости от аргумента выберет необходимую.
Чем это полезно вообще? С++ довольно топорный и низкоуровневый. Если не понимать как он устроен то можно подумать что он не работает как нужно. На самом деле он просто странный - создатели и добавили в него "высокоуровневые фишки" при этом байтоёбство оставили. В итоге получилось что-то всратое, но говорят что полезное, так как производительность он всяко больше выдаёт.
Во-вторых, если ты чисто хочешь разрабатывать игры, то зачем тебе разрабатывать графику, и зачем тебе С++? Разработка игр сводится к написанию скриптовухи, и разработке моделек. Это довольно душное занятие. Если начать писать свою графику, в какой-то момент поймёшь что нахуй эти видеоигры вообще нужны.
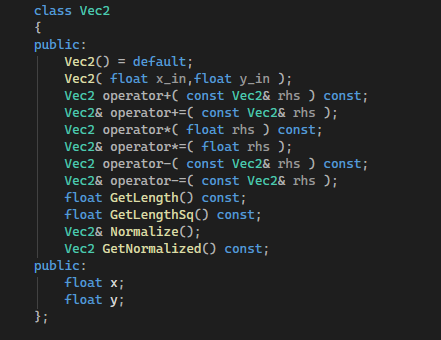
У Chili цель с 0, без опыта в программировании, обучить C++ и потом directX11. У него несколько плейлистов.
Начинающий: самые основы, переменные, их типы, операции, функции, циклы и условия. Так же классы, массивы, перегрузка операторов.
Опытный: там уже разные низкоуровневые и не очень вещи. Указатели например.
3д основы: графика без использования готовых инструментов. Там уже про векторы и матрицы.
directX: графика с использованием directX
Выше копии игр - это домашние задания из этого курса. Изначально он дал лишь функцию, закрашивающую пиксели по координатам.
Первые 2 плейлиста они именно про C++. Да, в уроках используются векторы, но просто для удобства, чтобы не писать int x, int y, а писать Vec2 point. Матрицы и нетривиальные операции над векторами у него уже после Intermediate плейлиста, я не скоро до них дойду.
Я проскользил по диагонали Столярова, часть про С. Интересно было, что в С нет главной программы, как в Паскале, и что можно без библиотек что-то делать. Я потом, наверное, всё это прочту чуть немного поподробней. Вкладывать много времени в С не хочу. Да и у меня сейчас времени не особо много, после работы часа 3 остается.
Про игры. И я изначально писал, что мне интересно сделать что-то, пусть и примитивное, не используя что-то готовое. И в каком-то видео, что на ютубе наткнулся, говорилось что вот учи C++.
У меня нет в голове идей игры, которую мне бы горело сделать. В этом случае я бы начал с Юнити или Анрила.


 33 Кб, 511x383
33 Кб, 511x383>Опытный
>там уже разные низкоуровневые и не очень вещи. Указатели например
Указатели - это уровень новичков. Они и в паскале и в С есть. Из твоего описания я всё больше убеждаюсь что видеокурс - полное говно, раз там указатели ставят на уровень "опытный". А if-else это уровень "Эксперт" в рамках данного видеокурса?
При том что нелепость С++ заключается ни в указателях, и не в конструкциях. Нелепость заключается в том что компилятор берёт на себя только рутинную часть некоторых действий, и в итоге получается "ни вашим ни нашим" - т.е. с одной стороны там можно писать классы, с другой стороны, их всё равно приходится колхозно инициализировать как на С, получается каша. Я и сам если честно когда пишу на С++ постоянно голову ломаю над реализацией тех или иных классов, и в итоге прихожу к тому что на С, это можно было бы сделать куда проще и быстрее, при этом удобство использования не сильно ухудшается - один хуй и там и там одинаковые количество кода. Но иногда С++ действительно быстрее, вот тот же TCP сервер намного более гибким получается на С++, нежели чем на С. На сишке выходит всратая портянка функций, что в любом случае переделывать нужно, на С++ достаточно поменять начледников базовой функции - считай переоборудовал сервер под всё что хочешь.
>3д основы: графика без использования готовых инструментов. Там уже про векторы и матрицы.
directX: графика с использованием directX
Нахуя вно нужно? Ну я под opengl прогал и свой рендер сделал. И как это помогло игры создать? Да никак. Мне лень писать игры. А было бы не лень - писал бы на годоте.
>Матрицы и нетривиальные операции над векторами у него уже после Intermediate плейлиста
Опять же, это уроки программирования? А какого хуя они объясняют математику за первый курс? Очевидно тупорылые индусы без образования впервые увидели матрицы и поэтому решили в свой говновидеоурок их впихнуть.
>я изначально писал, что мне интересно сделать что-то, пусть и примитивное, не используя что-то готовое. И в каком-то видео, что на ютубе наткнулся, говорилось что вот учи C++.
Он пиздабол. Язык не так важен, хоть на паскале пиши. Ну да ладно, пофиг, ебош. Может что-то весёлое закодишь!
33 Кб, 511x383>Опытный
>там уже разные низкоуровневые и не очень вещи. Указатели например
Указатели - это уровень новичков. Они и в паскале и в С есть. Из твоего описания я всё больше убеждаюсь что видеокурс - полное говно, раз там указатели ставят на уровень "опытный". А if-else это уровень "Эксперт" в рамках данного видеокурса?
При том что нелепость С++ заключается ни в указателях, и не в конструкциях. Нелепость заключается в том что компилятор берёт на себя только рутинную часть некоторых действий, и в итоге получается "ни вашим ни нашим" - т.е. с одной стороны там можно писать классы, с другой стороны, их всё равно приходится колхозно инициализировать как на С, получается каша. Я и сам если честно когда пишу на С++ постоянно голову ломаю над реализацией тех или иных классов, и в итоге прихожу к тому что на С, это можно было бы сделать куда проще и быстрее, при этом удобство использования не сильно ухудшается - один хуй и там и там одинаковые количество кода. Но иногда С++ действительно быстрее, вот тот же TCP сервер намного более гибким получается на С++, нежели чем на С. На сишке выходит всратая портянка функций, что в любом случае переделывать нужно, на С++ достаточно поменять начледников базовой функции - считай переоборудовал сервер под всё что хочешь.
>3д основы: графика без использования готовых инструментов. Там уже про векторы и матрицы.
directX: графика с использованием directX
Нахуя вно нужно? Ну я под opengl прогал и свой рендер сделал. И как это помогло игры создать? Да никак. Мне лень писать игры. А было бы не лень - писал бы на годоте.
>Матрицы и нетривиальные операции над векторами у него уже после Intermediate плейлиста
Опять же, это уроки программирования? А какого хуя они объясняют математику за первый курс? Очевидно тупорылые индусы без образования впервые увидели матрицы и поэтому решили в свой говновидеоурок их впихнуть.
>я изначально писал, что мне интересно сделать что-то, пусть и примитивное, не используя что-то готовое. И в каком-то видео, что на ютубе наткнулся, говорилось что вот учи C++.
Он пиздабол. Язык не так важен, хоть на паскале пиши. Ну да ладно, пофиг, ебош. Может что-то весёлое закодишь!
А чего нетривиального?
 124 Кб, 1137x861
124 Кб, 1137x861Там не только про указатели. Но и про другие вещи. Вот кусок оглавления.
В общем не хочу тратить время на защиту, но не понимаю твою предвзятость.
>Heap new delete
Это тоже уровень новичка.
>Destructors
Это у столярова есть, буквально в первых главах срр. Тоже уровень новичка
>std:string
Это STL. Полезная штука, у столярова этого нет. Это лучше отдельно от С++ учить, потому что шаблоны не являются частью с++.
>Всё остальное
Ну и мусор. А зачем это вообще изучать? Я когда свой трехмерных рендер писал, я максимум референс мануал по xlib прочитал. Всё. Зачем нужны уроки по клиппингу? Если ты не конченный долбоеб, то теле сложно будет не заметить что твоя программа тратит такты процессора на отрисовку мусора. Более того, тебе не сложно будет заметить, что если мусора больше чем полезного (а такую ситуацию запросто представить если ты например смотришь в близком приближении) то очевидно у тебя программа зависнет впизду обрабатывая мусор. Любому абсолютно придёт на ум вопрос: "как мне вычислить что фигура попадает в область". Собственно, самому думать сложно - заходим в Википедию. А там что? Там псевдокод:
https://en.wikipedia.org/wiki/Sutherland%E2%80%93Hodgman_algorithm
Реализуем данный алгоритм хоть на паскале хоть на С, хоть на С++ разницы вообще не имеет.
Ты можешь прямого сейчас всю 3D графику реализовать на GraphABC паскаль
Вот, попробуй прочитать эти статьи и реализовать графику на паскале
https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%91%D1%80%D0%B5%D0%B7%D0%B5%D0%BD%D1%85%D1%8D%D0%BC%D0%B0
https://en.wikipedia.org/wiki/Wavefront_.obj_file
https://en.wikipedia.org/wiki/Rasterisation#triangle
https://en.wikipedia.org/wiki/Z-buffering
https://en.wikipedia.org/wiki/3D_projection
https://en.wikipedia.org/wiki/Shading
https://en.wikipedia.org/wiki/Gouraud_shading
https://en.wikipedia.org/wiki/Barycentric_coordinate_system
>Heap new delete
Это тоже уровень новичка.
>Destructors
Это у столярова есть, буквально в первых главах срр. Тоже уровень новичка
>std:string
Это STL. Полезная штука, у столярова этого нет. Это лучше отдельно от С++ учить, потому что шаблоны не являются частью с++.
>Всё остальное
Ну и мусор. А зачем это вообще изучать? Я когда свой трехмерных рендер писал, я максимум референс мануал по xlib прочитал. Всё. Зачем нужны уроки по клиппингу? Если ты не конченный долбоеб, то теле сложно будет не заметить что твоя программа тратит такты процессора на отрисовку мусора. Более того, тебе не сложно будет заметить, что если мусора больше чем полезного (а такую ситуацию запросто представить если ты например смотришь в близком приближении) то очевидно у тебя программа зависнет впизду обрабатывая мусор. Любому абсолютно придёт на ум вопрос: "как мне вычислить что фигура попадает в область". Собственно, самому думать сложно - заходим в Википедию. А там что? Там псевдокод:
https://en.wikipedia.org/wiki/Sutherland%E2%80%93Hodgman_algorithm
Реализуем данный алгоритм хоть на паскале хоть на С, хоть на С++ разницы вообще не имеет.
Ты можешь прямого сейчас всю 3D графику реализовать на GraphABC паскаль
Вот, попробуй прочитать эти статьи и реализовать графику на паскале
https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%91%D1%80%D0%B5%D0%B7%D0%B5%D0%BD%D1%85%D1%8D%D0%BC%D0%B0
https://en.wikipedia.org/wiki/Wavefront_.obj_file
https://en.wikipedia.org/wiki/Rasterisation#triangle
https://en.wikipedia.org/wiki/Z-buffering
https://en.wikipedia.org/wiki/3D_projection
https://en.wikipedia.org/wiki/Shading
https://en.wikipedia.org/wiki/Gouraud_shading
https://en.wikipedia.org/wiki/Barycentric_coordinate_system
>А какого хуя они объясняют математику за первый курс? Очевидно тупорылые индусы без образования впервые увидели матрицы и поэтому решили в свой говновидеоурок их впихнуть.
Я их не знаю. Я не учился в университете. У меня только 11 классов.
>Вот, попробуй прочитать эти статьи и реализовать графику на паскале
Я работаю 6/1, после работы часа 3 остается свободных. Потому уроки выше для меня просто удобнее, чем копаться по всему интернету. У меня нет кучи свободного времени сейчас.
Пару тройку сообщений выше, писал, что сменил работу. Не совсем по своему желанию. Получаю около 45-50.

 535 Кб, 2048x1362
535 Кб, 2048x1362>Если ты не конченный долбоеб, то теле сложно будет не заметить что твоя программа тратит такты процессора на отрисовку мусора.
Чел, ты серьёзно, это нереально заметить без специального расследования, вспомни ту историю с O(N²) разбором JSON в GTA V, или миллион таких же историй. Даже если твоя программа очевидно критически тормозит и ты досконально помнишь, как ты её писал и что конкретно сделал плохо, ты в общем случае не можешь взять и сказать, что из этого, и из этого ли вообще, послужило причиной. Моя личная ИСТОРИЯ ИЗ ЖИЗНИ, от которой я охуел больше всего (&9evelANUS
И вот немного смежная и уже совсем недавняя история из жизни; ищется пост Торвальдса про это (https://www.reddit.com/r/programming/comments/24gr79/linus_on_the_cost_of_page_fault_handling/). Вот есть низкоуровневые функции запроса памяти у операционной системы, либо занулённой (в kernel-colored glasses это называется «спроецированной в своп»), либо спроецированной в файл, типа VirtualAlloc/MapViewOfFile или линуксовой mmap, ну классные функции, ещё и бесплатно зануляют или автоматически обмениваются информацией с диском, круто же? Оказывается, по умолчанию каждые 4096 байт памяти, выделенной этими функциями, при твоём первом их трогании невидимо приводят к пейдж фолту, который заполняет эту страницу нужными данными (ну, задним числом это очевидно; но всё равно я бы на месте системы фолтил побольше 1 страницы за раз, по крайней мере при очевидно последовательном паттерне доступа). По моим подсчётам, такой пейдж фолт стоит порядка 4'500 тактов, то есть порядка 1 такта/байт просто как едино- (или даже не едино-)временная цена в пересчёте на каждый потроганный байт. Это может быть не так много на общем фоне (Торвальдс упоминает 5% времени реальной работы, проводимого в таких фолтах, что всё ещё неприятно), но всё равно, до того, как я заметил, что хотя сами по себе эти функции быстрее, но если брать всю работу в целом, то за счёт фолтов VirtualAlloc внезапно проигрывает, в терминологии Pascal, FillChar, а MapViewOfFile внезапно проигрывает ReadFile/WriteFile, моё отношение к этим функциям было таким же, как у среднего человека из интернета: «О-ОО, ЗАЕБИСЬ, БЕСПЛАТНЫЕ НУЛИ / БЕСПЛАТНОЕ ОТОБРАЖЕНИЕ ПРЯМО НА ФАЙЛОВЫЙ КЭШ ОС».
535 Кб, 2048x1362>Если ты не конченный долбоеб, то теле сложно будет не заметить что твоя программа тратит такты процессора на отрисовку мусора.
Чел, ты серьёзно, это нереально заметить без специального расследования, вспомни ту историю с O(N²) разбором JSON в GTA V, или миллион таких же историй. Даже если твоя программа очевидно критически тормозит и ты досконально помнишь, как ты её писал и что конкретно сделал плохо, ты в общем случае не можешь взять и сказать, что из этого, и из этого ли вообще, послужило причиной. Моя личная ИСТОРИЯ ИЗ ЖИЗНИ, от которой я охуел больше всего (&9evelANUS
И вот немного смежная и уже совсем недавняя история из жизни; ищется пост Торвальдса про это (https://www.reddit.com/r/programming/comments/24gr79/linus_on_the_cost_of_page_fault_handling/). Вот есть низкоуровневые функции запроса памяти у операционной системы, либо занулённой (в kernel-colored glasses это называется «спроецированной в своп»), либо спроецированной в файл, типа VirtualAlloc/MapViewOfFile или линуксовой mmap, ну классные функции, ещё и бесплатно зануляют или автоматически обмениваются информацией с диском, круто же? Оказывается, по умолчанию каждые 4096 байт памяти, выделенной этими функциями, при твоём первом их трогании невидимо приводят к пейдж фолту, который заполняет эту страницу нужными данными (ну, задним числом это очевидно; но всё равно я бы на месте системы фолтил побольше 1 страницы за раз, по крайней мере при очевидно последовательном паттерне доступа). По моим подсчётам, такой пейдж фолт стоит порядка 4'500 тактов, то есть порядка 1 такта/байт просто как едино- (или даже не едино-)временная цена в пересчёте на каждый потроганный байт. Это может быть не так много на общем фоне (Торвальдс упоминает 5% времени реальной работы, проводимого в таких фолтах, что всё ещё неприятно), но всё равно, до того, как я заметил, что хотя сами по себе эти функции быстрее, но если брать всю работу в целом, то за счёт фолтов VirtualAlloc внезапно проигрывает, в терминологии Pascal, FillChar, а MapViewOfFile внезапно проигрывает ReadFile/WriteFile, моё отношение к этим функциям было таким же, как у среднего человека из интернета: «О-ОО, ЗАЕБИСЬ, БЕСПЛАТНЫЕ НУЛИ / БЕСПЛАТНОЕ ОТОБРАЖЕНИЕ ПРЯМО НА ФАЙЛОВЫЙ КЭШ ОС».
 108 Кб, 800x800
108 Кб, 800x800>Чел, ты серьёзно, это нереально заметить без специального расследования, вспомни ту историю с O(N²) разбором JSON в GTA V
Ну мы же говорим про задачки школьного уровня. Тут достаточно просто посмотреть какой набор данных ты отправляешь в программу и какой в итоге на выходе получаешь. Это ещё и всё визуально. Стандартная программа создающая перспективную проекцию, в частности способна масштабировать треугольник. Очевидно же, что значения могут принимать хоть до миллиарда. Если вспомнить о том что переменные ещё и переполнятся, то само собой это коллапс. Нельзя так программу написать. Когда пишешь на С первым же делом думаешь, а что вообще в эти переменные будет записано, знаем ли мы диапазон, хватит ли его. В первых же главах книги Столярова как раз продемонстрирована уязвимость переполнения буфера - когда никто не подумал о том сколько байт вообще может быть записано, в итоге можно в стек коды возврата написать. Так что клиппинг всего подряд - это всё равно что обработка ввода. Когда ты вводим данные с потока, мы же всегда рассматриваем вообще все ситуации, что там могут ввести. Иначе тупо получается. Плюс в однопоточных программах профайлер всегда под рукой - запилил посмотрел что у тебя такты крадёт.
>это когда расследуя такой случай, я совершенно неожиданно выяснил, что Windows
Ну это ж получается ошибка винды, а не твоя. В зависимости от компилятора С результат тоже может быть довольно разный, С же для pdp создан, а не для x86. Чё мне за ошибки компилятора отдуваться?
>Оказывается, по умолчанию каждые 4096 байт памяти, выделенной этими функциями, при твоём первом их трогании невидимо приводят к пейдж фолту
Проблемы Пинуса Тормоза. Не я же этот mmap кодил. Нормально делай - нормально будет. В чем смысл оправдывать ошибки программистов тем что это "не очевидно" - они ж спецы своего дела, для них должно быть очевидно. За что им деньги платят?
Смотря каких собесах. Если в Яндекс или Тинькофф, то там не только литкод, там вообще заставят пазлы собирать. Бигтех хуле. А в среднеконторах пох.
 76 Кб, 706x976
76 Кб, 706x976Не, бигкеки могут пройти нахуй, особенно яндых, лучше уж дворником.
Не, а чё ради престижа можно было бы поработать. Но в бигтехи сто проц не возьмут. Хз вообще как туда устраиваются.
 41 Кб, 608x1080
41 Кб, 608x1080>ради престижа
Наёбка для видешов.
 31 Кб, 288x346
31 Кб, 288x346 194 Кб, 1079x1340
194 Кб, 1079x1340Но таким можно заниматься когда у тебя уже закрыты все базовые потребности и на счёт капают деньги с ренты и ты можешь себе позволить тратить своё время на проекты от которых не будет никакого выхлопа.
 24 Кб, 534x401
24 Кб, 534x401>сколько усилий придётся вложить что бы запилить каэску на асме
Каеска посложнее будет. Там клиент-серверная архитектура с Quake 3, где события предсказываются заранее.
 1,6 Мб, 1430x2000
1,6 Мб, 1430x2000Это не ошибки и так надо (по крайней мере иногда), в частности, этот прикол с пейджфолтами идентичен в Windows и Linux и следует из идеи виртуальной памяти и паттернов её использования, это просто НЕОЧЕВИДНЫЕ примеры того, куда может улететь твоё время CPU без того, чтобы ты как программист предварительно пошёл нахуй по причине конченый долбоёб и сам виноват. Никто не виноват и всё работает как задумано, но знать, как именно работает, полезно для здоровья.


Уроки нравятся, потому что в них не консольные проекты. Надеюсь допройду все плейлисты до конца не забросив. Перехожу к intermediate.
Ну давай рассказывай, что такое остаточная рекурсия, и как не засрать стек.
>что такое остаточная рекурсия
Не знаю.
>и как не засрать стек
Ну, нужно что бы было какое-то условие, которое не даст бесконечно проваливаться в вызов функции.
Всё что я могу сейчас ответить.
> и как не засрать стек.
А на C++, по-моему, никак. Там хвостовая рекурсия по стандарту не схлопывается в цикл, если ничего не поменялось за последнее время.
Более того, инстанциацией шаблонов можно уронить стек во время компиляция. Метастековерфлоу... Господи, наконец-то мы в будущем.
А в С можно. Вот и думайте!
 33 Кб, 604x879
33 Кб, 604x879Да по сути незачем. Я пару раз пытался выебнуться что-то рекурсивное закодить, в итоге пришёл к выводу что это неудобно, любая неостаточная рекурсия забъет стек, а остаточной по сути только изредка пару раз ей можно выебнуться. В остальном while всё заменяет. А если ограничивать количество итераций, то вообще не понятно зачем рекурсия нужна.
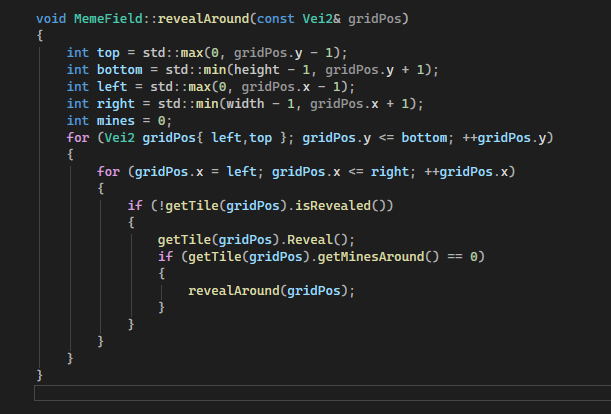
Как бы ты все пустые клеточки раскрыл? Ты ведь не знаешь заранее, сколько шагов придется делать, в случае цикла. Легко придумать такой алгоритм
раскрыть клеточку
если в клеточке записан 0, то
@раскрыть соседа
@@если в клеточке-соседа записан 0, то //иначе перейти к следующему
@@@раскрыть эту клеточку...
Я об рекурсии думаю как о простой подстановке текста. Сам ты не знаешь, сколько раз его придется подставлять, но компьютер может проверять условие и на основе него делать выбор.
[раскрыть соседа
если в клеточке-соседа записан 0, то A] = A
Я пытался через do-while, но там тоже получается, что нужно один и тот же текст подставлять друг за другом, и заранее неизвестно, сколько раз это придется сделать.
 575 Кб, 1040x585
575 Кб, 1040x585>Ты ведь не знаешь заранее, сколько шагов придется делать, в случае цикла.
Для этого есть цикл while. Рекурсивную функцию можно развернуть через while. А стек можно сделать вручную, выделив в куче заранее оптимальные количество места - при необходимости расширить.
>Я пытался через do-while, но там тоже получается, что нужно один и тот же текст подставлять друг за другом, и заранее неизвестно, сколько раз это придется сделать.
Скидывай. Го оценим. Рекурсивные функции в ряде случаев получаются короче и универсальнее. Вот только они жрут стек, а он ограничен. Если у тебя программа имеет возможность свалиться в stack overflow то это ж говнокод. Вот у меня была функция которая прошаривает каталоги в поисках файлов браузера. А что если там кто-то запихнет сотню каталогов - бах, программа вылетела. Ну это кал. А остаточной рекусией тут не сделать, потому что чтобы освободить стек нужно вернуться из функции, а пока мы прошариваем граф нам нельзя возвращаться из функции.
 1,3 Мб, 1500x1123
1,3 Мб, 1500x1123Бывают такие штуки, называемые деревьями, рассмотрим https://ru.wikipedia.org/wiki/Двоичное_дерево_поиска — специальные деревья, у которых в каждом узле есть ссылки на два поддерева, одно с меньшими элементами, другое — с большими.
Эта структура по своей природе рекурсивна: поддеревья каждого узла сами по себе являются такими же деревьями, и к ним применимы те же функции. Например, обход такого дерева по возрастанию проще, очевиднее, да, в принципе, и эффективнее всего сделать как https://godbolt.org/z/3vKrxWjnM.

Не.. погоди... Падажжи ёмана. У нас же не чистый ассемблерный pop/push, у нас идёт операция вызова функции, там стековый фрейм целый нужно создать.
Если у нас рекурсивная программа обрабатывает произвольные пользовательские графы типо каталогов - то всё её использовать ни в коем случае нельзя. Пусть она хоть в тысячу раз быстрее - пользователь запросто может переполнить стек. Представь что ты программу на сервере запустил и какой-то подлец специально решил накидать в неё кала чтобы вызвать dos.
Если у нас данные ограничены, то почему бы не использовать while + локальные переменные? Думаешь операция вызова функции быстрее чем while? Чёто помниться через профайлер дороже выходило.
> там стековый фрейм целый нужно создать
Как будто что-то прям уж тяжёлое.
> Если у нас данные ограничены, то почему бы не использовать while + локальные переменные
Потому что для обхода того же дерева нужно будет использовать свой самодельный тяжёлый стек. Хотя, может можно и без стека. А может и не можно. Незнаю, чото лень мне думать сейчас.
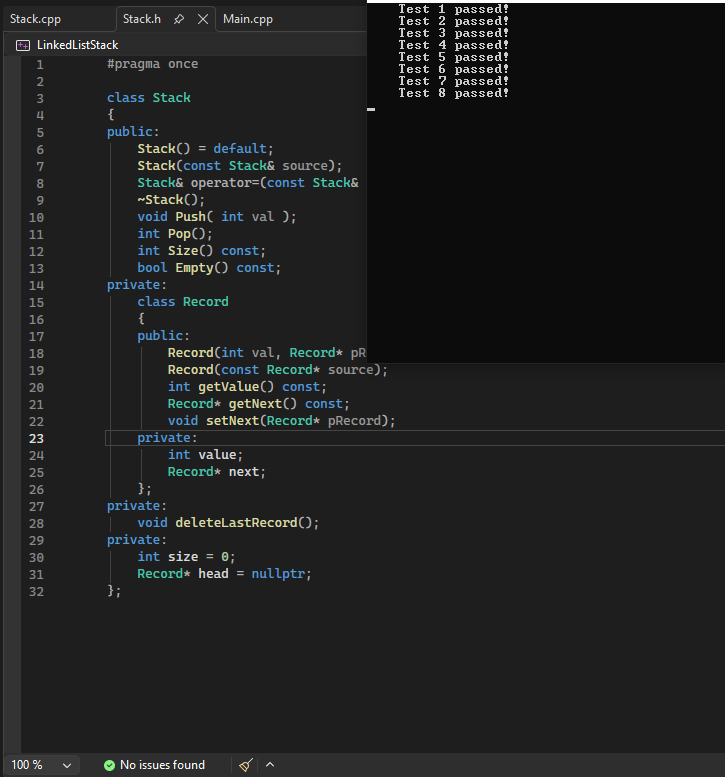
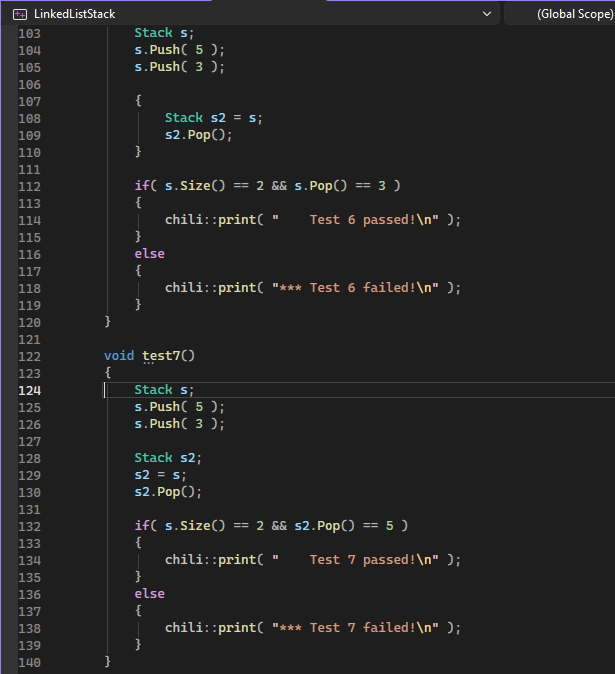
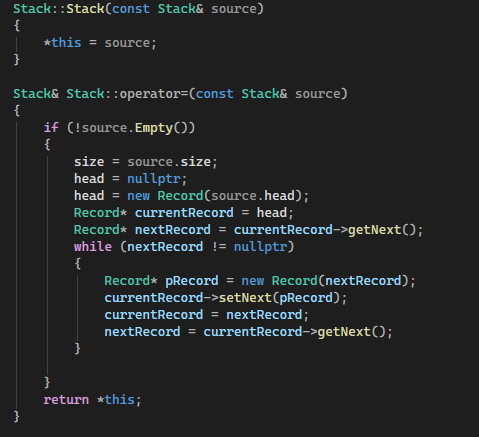
>When the Stack is fully implemented and the program is executed, there are 8 test routines that will be run. All test routines should output 'Passed' to the console for the homework to be considered solved. Furthermore, the heap memory will be monitored at the end of the program and any dynamic memory that has not been freed will trigger a diagnostic error message. It is required that no diagnostic error be output for the homework to be considered solved.
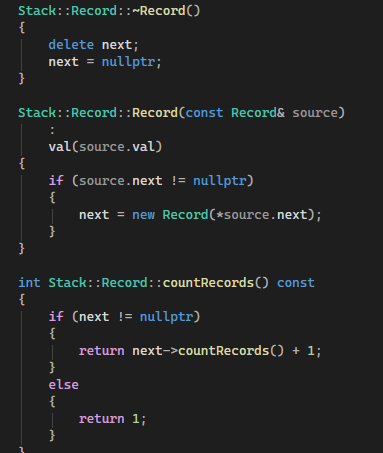
Так как я уже имел дело с связными списками в Паскале, и стэк и очереди делал, думал будет легко. Но копи-конструктор и оператор присваивания были незнакомы, и пришлось потратить намного больше времени, чем ожидал. Хотя код получился простой.
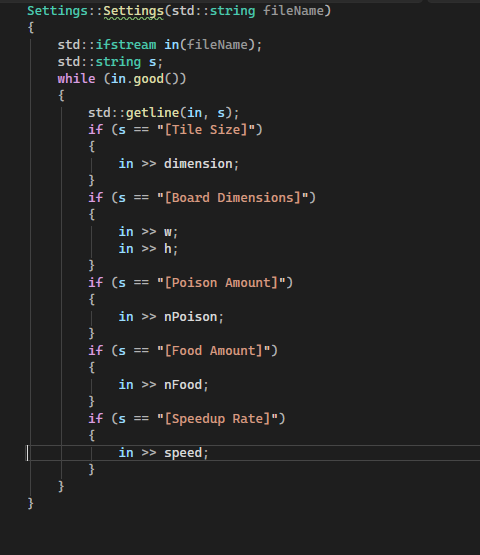
Сделал 7 урок. Модифицировал змейку, теперь она настройки достает из файла. Возможно не лучшим образом, сделал отдельный класс, его конструктор читает файл и заполняет данные в него. Затем уже другие конструкторы берут информацию из этого класса, данные сделал публичными. Сейчас буду смотреть решение автора.
С с++ потоками и строками чувствую себя неловко. С с-строками, о которых он рассказывал в первых уроках, чувствовал себя так же.
Может в будущем стоит потратить время на какие-нибудь задачи, на работу с вводом/выводом, файлами. В Паскале это всё ощущалось гораздо уверенней.
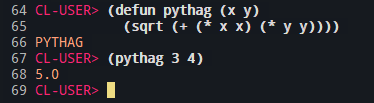 8 Кб, 374x103
8 Кб, 374x103На работе предновогодняя ёбка, потому С++ пока отложил, 1 урок занимает от часу до двух и более. После работы у меня есть всего часа 3.
В эти 3 часа делаю свои дела и немного читаю о Лиспе. Очень уж нравится синтаксис. К С++ вернусь где-то после нового года. Не знаю, когда буду приходить с работы не под вечер.

Живёт по кайфу парень, делает свою игру на cpp на стриме, курит, показывает её своему другальку. Короче круче всего двача судя по всему, мы все лохи на его фоне.
Планирую тем же самым заняться когда зп +100к подниму.
Просто на разработке игр денег то особо не сделаешь. А думать надо много, потому что клепать слоп на юнити довольно скучно, хочется именно самому сделать такую систему которая бы работала так как тебе необходимо. Либо, изучить какие-нибудь другие движки которые именно на С++ и opengl. Вот как пример RenderWare неплохой - множество игр на нём сделано от гта до шутеров. Проблема только в отсутствии документации. Сам Renderware вообще-то закрытый, но его реверс-инжинернули, сделав re3 - гта 3 который даже на freebsd откомпилировать и запустить можно. Но документацию, как и полагается не завезли.
Я бы забил хуй на эти идеи навсегда, если бы не нейросети. Мне кажется чатгпт способен снять с меня часть нагрузки по анализу кода и оформлению документации. Мне достаточно открыть код re3, и начать из main() смотреть что за функции что делают - нейросеть всё это дооформит. И если честно, то ли я лоускилыш, то ли что, но как люди вообще анализируют код на миллионы строк?! В этом же разобраться невозможно. А вот в нейронку загрузил целый файл в котором описан класс, и спрашиваешь "что в целом делает допустим метод CFileInit" - и он отвечает, что это класс-прослойка чтобы в разных файловых системах будь то ps2 или windows, файлы открывались одинаково. Впринцпе понятно, отметку посиавил, дальше в этот файл не не лезу, так как пока не хочу узнавать как он конкретно это реализует. А как люди это делали без нейросетей?! Они бы что CFile.cpp читали бы, тратили на это сутки, просто чтобы понять что это прослойка?! Такими темпами закончить читать код можно только когда дедом станешь.
А ещё нейронки могут сгенерировать сотню концептов, текстур и прочей рутинной работы, которая занимает 70% времени от разработки. Прикольно, можно было бы на движке gta3 сделать рогалик по данжам. Летом я это кстати начал делать. Но подзабил, так как это же типо хобби, денег не принесёт, а я нищий грустно и голодно.
 7 Кб, 235x221
7 Кб, 235x221>но как люди вообще анализируют код на миллионы строк?!
Да там чел какой-то iq140, мозг быстро работает. Но судя по демкам шиз угорающий по ультранасилию. Он ещё и музыкант, на пианине лабает, таких 1 на 100тыс наверное рождается.
>но как люди вообще анализируют код на миллионы строк?!
А вообще большие игры пилятся большими командами, и это не бомжи какие-то с улицы, это технари окончившие MIT. Меня этот факт остудил немного, лучше попытаться пробиться тестером/разрабом на галеру и попутно пилить свои проекты, чем гнаться за какой-то несбыточной и сомнительной мечтой, которая в итоге обернётся смертью в нищете.
 37 Кб, 736x736
37 Кб, 736x736>А как люди это делали без нейросетей?! Они бы что CFile.cpp читали бы, тратили на это сутки, просто чтобы понять что это прослойка?!
А вообще думаю всё дело в том, что в таких проектах продуманная архитектура с хорошей документацией, тебе не придётся всё анализировать, если код хорошо задокументирован. Чисто мои мысли. К тому же читать свою васянку намного легче, чем чужую.
>А вообще большие игры пилятся большими командами
Глупая какая-то идея "больше людей значит лучше". Достаточно и одного человека. Тем более какие впизду MIT, зачем это? Возьми и запрограммируй.
>тебе не придётся всё анализировать, если код хорошо задокументирован.
Когда такое бывает? Не видел ни одного кода который был бы хоть как-то задокументирован.
Я вообще к тому что нейросетеи сейчас могут добавить участников в команду. Нейронка может и концепт-арты сделать, и музыку написать и озвучку, и помочь код задокументировать. С учётом такой помощи мне кажется можно и в одиночку проект написать - времени на анализ кода нейрока срежет. Opengl только самому придётся выучить для начала, и openAL, чтобы нормально код читать можно было.
 61 Кб, 1080x1080
61 Кб, 1080x1080Я смотрю ты в любой области эксперт. Хули ты тогда такой бедный?(с)
Пффф, ты смороил какую-то бессвязнаю хуйню не в тему, теперь ещё и обижаешься. Пиздец ты девочка
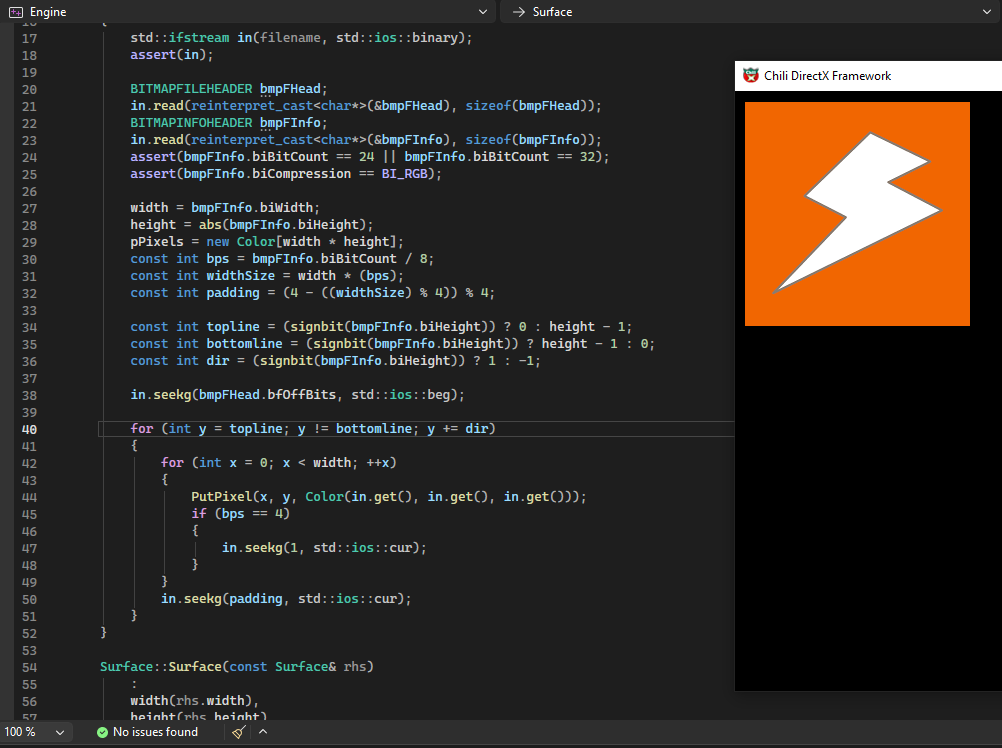 170 Кб, 1002x748
170 Кб, 1002x748Научился загружать .bmp, закончил 10 урок.

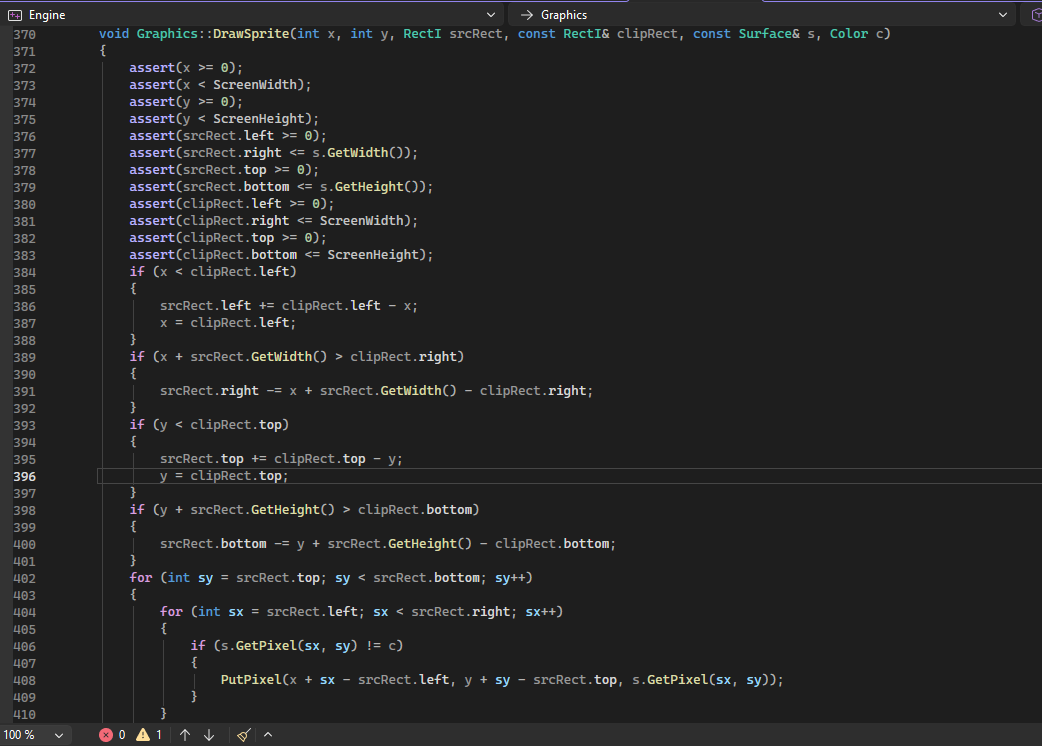

 184 Кб, 1223x577
184 Кб, 1223x577Потому, без твоего позволения - я набегу на 2 поста, отправлю этот и следующий, а после прогонишь, если я тут лишний.
Я просто даже не могу понять в чём дело и из-за чего эта нотка возникла от простого пролистывания треда.
У меня просто вот, пикрелейтед на компьютере открыт. Разница с тобой в год по возрасту, и что-то похожее в коде написано.

По теме поста, пока старая винда исправно работала было желание снести её и угореть по TUI, сейчас уже как будто не актуально, потому что винда всё таки слетела, а с ней и старые гугл-аккаунты с сформированной лентой ютуба, пинтереста и прочих развлекательных сервисов и теперь смотреть интересные превьюшки больше негде, а новые аккаунты формировать уже не хочется.
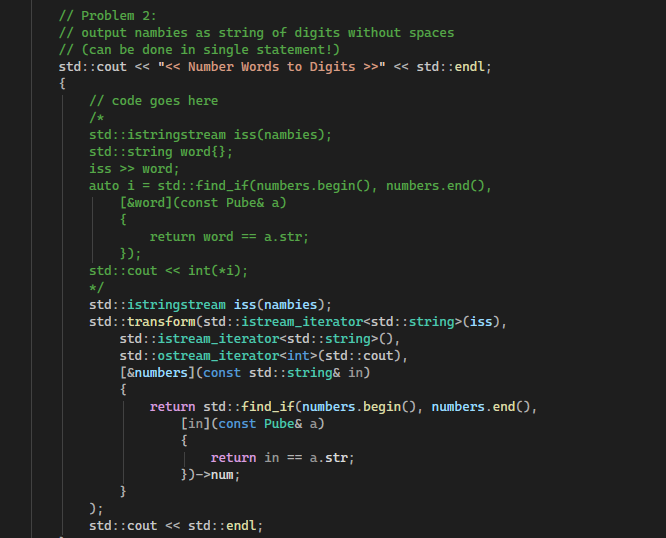


Закончил 16 урок. Довольно трудная была домашка, постоянно казалось что проще самому всё написать, а не разбираться как работать с готовыми алгоритмами.
Не знал что лямбда можешь захватывать объект [this], потому проявил смекалочку и в функции сделал копию хромокей-цвета.
Следующие уроки углубленно про ООП. Хочется поскорее закончить этот плейлист, тк следующие уже конкретно про графику, а не про программирование/язык.
>вкатывальшик по Столярову
Сейчас у меня мнение, что из-за него я зря потратил время на Паскаль. Хорошо хоть я не стал полностью следовать её советам и накатывать Линуксы, тратя время на то чтобы разобраться как работать с терминалом и пр.
Ещё заметил за собой, что мне трудно изучать две вещи параллельно. Приводит к тому что я начинаю прокрастинировать. Потому Лисп я отложил на когда-нибудь потом. Сейчас только плейлист Чили.
Работа отнимает слишком много времени. Ещё после неё не хочется ничего делать, а просто поваляться на кровати, сильно изматывает, а на выходном я просто отсыпаюсь целый день.
Доработаю этот месяц, а дальше буду искать другую, с меньшей нагрузкой.
 287 Кб, 500x464
287 Кб, 500x464Сейчас в отпуске, половина уже прошла. Надеюсь за эту неделю и следующую закончить Intermidiate плейлист наконец-то. Сейчас остановился на 18 туториале.
>>853757
>>855724
Я просто иду по курсу. Когда начинал, то идей игры у меня не было. Мне скорее интересно сейчас как, например, графика работает. И вообще, думаю, мне бы интереснее было делать инструменты, редакторы, чем сами игры. Курс мне нравится, что он с 0 доводит до д3д рендера, нравится конечная цель, только из-за неё я всё окончательно не забросил.
Но сейчас появилась идея. Причём игра, вроде, должна простая получиться. Не знаю, досмотреть ли курс по 3д и начать делать с 0, или скачать Юнити. Все разы, когда я пытался делать что-то параллельно, проваливались и я скатывался в ничегонеделанье. Потому склоняюсь больше к первому варианту.
Вообще без месяца год прошёл с начала треда. Чувствую себя невероятно неэффективным. То что я за год освоил, мог освоить за месяца 2-3. Если ещё на лишнее бы не отвлекался, например Паскаль, то месяц-полтора. Всё остальное время въебал на всякий слоп. И так все свои пост-школьные годы, 18-30 пролетели незаметно, ничему новому я не научился, вдобавок потерял здоровье. И я продолжаю наступать на те же грабли.

ДЗ не было. Потому просто посмотрел видео, а после повторил. Впервые зафейлился с поинтером. Есть бойцы, у них есть оружия. Если враг пал и у него оружие лучше, то победитель должен забрать его пуху. Оружие это просто указатель. И забывал у проигравшего поставить указатель в nullptr, отчего при вызове его деструктора программа пыталась удалить область, которую мог удалить перед этим победитель.
19 урок ничего особенного. Просто о возможности узнать тип объекта, на который ссылается базовый указатель. Особо ничего руками не писал.
Сегодня наверное смогу осилить и 20 урок.
Привет. Да я допрошел плейлист, только домашку для последнего видео не стал делать.
Мне стал сильно не нравится С++. Не нравятся исключения, не нравится всё обмазывать классами, геттерами-сеттерами. Пишешь кучу строчек, которые ничего не делают.
Сейчас ничем не занимаюсь. С прошлой работы уволился. Новую лениво ищу.
Мне тоже особенно не нравятся исключения, особенно то что они стали системой типов (функций) и то что ситуация с этим менялась в 11, 14 и 17 стандарте вроде бы. Там же ещё и у компилятора вопросы к этому возникают, то что у тебя возврат из функции может разные типы через исключения возвращать и другой бред. Это прям что-то очень стрёмное.
Я их просто не использовал, а потом узнал что у гугла ещё вот такое есть. Ну и до сих пор не использую, и всё у меня хорошо, лол, с++ любимый язык. Геттеры-сеттеры и в других будут - но это всё защита от выстрела в ногу, может быть через какой-то синтаксис параметров или ещё что-то, ну да суть не меняется.
Впрочем, с++ в отличие от многих других не принуждает тебя использовать всё это. ООП штука ситуативная, у меня почти все классы - это структуры из си, и методы там просто как синтаксический сахар, без наследований, геттеров и вот всего этого. Это С+ или даже си с половиной плюса. В сущности ты можешь вообще на си писать, где не будет ни одного автоматического действия, а происходить будет только то что ты явно напишешь.
Я всё понимаю, что минусов много и напрягает обилие чужого кода, который переписывать самому нецелесообразно или невозможно, а он написан с исключениями, с множественным десятиуровневым наследованием и так далее, но как будто бы и альтернатив нету внятных. Не знаю, может быть тебе моды на с++ понравятся вроде go и rust.
К слову про твою работу - пиццу первый раз в жизни попробовал вот дня четыре назад. У меня всегда отвращение было к блюдам, где смешано больше двух продуктов. Но там вроде ничего вышло. Тесто, сыр и колбаска. Ну хотя всё-равно такое, на 3/10. Просто тесто и сыр отдельно были бы вкуснее.
Забыл упомянуть ещё RAII. В общем мне не нравится, что многие вещи происходят автоматически и неявно.
Что мне нравится, по сравнению с Паскалем: объявление переменных на лету, блочные области видимости, перегрузка функций и операторов, шаблоны. Но без последних двух, думаю, можно жить. Не знаю, может и стоит ограничиться С и дальше что-то пытаться делать.
>Геттеры-сеттеры и в других будут - но это всё защита от выстрела в ногу, может быть через какой-то синтаксис параметров или ещё что-то, ну да суть не меняется.
Так это ведь и без классов можно релизовать защиту. В box2d например нет прямого доступа к структурам. Тебе дают номерок, и правильно работать с ним могут только функции автора. Для юзера же это просто айди, число. Ну, я так понял, проскользив по-диагонали по доке.
Так не используй RAII.
Ну, то есть в некоторой степени придётся использовать для взаимодействия с чужими либами - но это можно обернуть в классе (более того, задача достаточно шаблонная, ты можешь с удобным тебе синтаксисом сделать это для одного класса - а нейросеть по твоему шаблону сделать для всех остальных структур и функций либы).
Я примерно так делаю (RAII я не игнорирую, но использую очень ограничено):
У каждой структуре есть метод init. То есть после создания объект невалидный, и надо сделать init - и из-за того что это не конструктор, мне не надо использовать уродливые конструкции вида
class t_class{
A a;
B b;
tud_descriptor_string_cb usb_musor;
t_class(int x, int y):a{123,"s12313"},b(12312,643345), usb_musor{calculate_param_for_usb_musro()}{
... код конструктора.
}
}, я такое постоянно вижу в примерах, особенно в коде игр, и там таких вложенных штук просто на десять строк, больше чем конструктора.
Мне очень не нравится что в таком синтаксисе параметры для конструкторов я не могу в теле конструктора вычислить, а мне нужны вспомогательные функции вида calculate_param_for_usb_musro, чтобы прямо в скобках вычислить параметры - что не всегда эффективно (какая-то функция может высчитывать параметры сразу для двух вложенных классов), и выглядит отвратительно. Это та часть синтаксиса в с++, которая топ-1 по уродливости с моей точки зрения. Топ-2 это умные указатели, кстати.. Ну и ещё это странно, для примера я создаю структуру мира, в которую вложена, например, локация и объект. И получается, что несмотря на то что было бы логично сгенерировать мир, а потом туда в зависимости от свойств мира добавлять локацию и объекты - с raii выходит, что я сначала создаю объект, а уже потом локацию и мир. И так как объекту нужно что-то знать про мир, хотя бы просто иметь указатель на владельца, то всё-равно придётся что-то вроде ниже-описанной функции init делать.
С функцией init я могу в теле конструктора делать что хочу, удобным образом и в нужной мне последовательности, примерно так:
class t_class{
A a;
B b;
tud_descriptor_string_cb usb_musor;
void init(int x, int y){
a.init(123,"s12313");
auto r=calculate_param_for_();
b.init(r.first);
usb_musor.init(r.second);
... код конструктора.
}
}
Итого в конструкторе/деструкторе или ничего нет, или что-то супер простое типа выделения 20 мб памяти для массива, которую со стека я не возьму, а из кучи возьму, и которое в RAII логично ложится.
И аналогично я могу destroy вызывать когда мне хочется.
Есть конечно проблемы, что можно два раза вызвать init/destroy - но такую ошибку допустить достаточно сложно, как мне кажется, ну и к слову виртуальный метод (не статичный, а в таблице виртуальных методов когда есть что-то) даёт наклодных расходов больше (и по памяти, и по быстродействию), чем проверка bool-переменной в вызове статичного метода. Проверка проще, чем переход по чему-то там в таблице виртуальных методов, я тестировал это на разных компьютерах. Ну да это впрочем и логично, у проверки функционал проще. Да, надо иметь ввиду, что такая фигня сразу делает не особо совместимым тип с stl-контейнерами, и если unordered_map будет расширять свой внутренний буфер - он с большой вероятностью не слишком качественно скопирует твои объекты и нужно немного понимать что где происходит.
Конечно можно все объекты хранить как указатель, и вызывать для них new для инициализации в нужный момент - но это бьёт по производительности, и это не окей, что в угоду синтаксиса вместо монолитного расположения памяти объекты лежат в куче как попало, и разыменовываю постоянно указатели, хотя это нужно только для инициализации, лол. Или сделать пустой объект и move-оператор присваивания.
Да, move-симантика и вот эти мутные схемы, когда какая перегрузка перемещения или копирования вызывает, и почему у меня конструктор копирования и конструктор перемещения это не то же самое, что оператор = копирования и перемещения (при инициализациях вида A a={1,3}; и A a{1,3}; вроде какая-то разница в вызовах есть) тоже немного напрягает, потому не считаю зазорным написать явный метод вида move_unit(unit from, unit to). Это как есть офигительное копирование строк через while (dest++ = src++) и аналогичный фокус с абузом switch/case, но ведь всегда можно написать
int i = 0;
while (src != 0) {
dest = src;
i++;
}
dest = 0;
что скорее всего после компилятора будет байт в байт тем же кодом, что и вышерасположенная нечитаемая дичь.
>Что мне нравится, по сравнению с Паскалем:
Не знаю что там с паскалем, но в делфи (которая delphi XE и моложе) добавили же в некоторой степени обобщённые методы, генеретики какие-то. Я не помню, не писал 15 лет. Перегрузки тоже там есть, их я очень люблю и писал на делфи везде и в си пишу.
Так не используй RAII.
Ну, то есть в некоторой степени придётся использовать для взаимодействия с чужими либами - но это можно обернуть в классе (более того, задача достаточно шаблонная, ты можешь с удобным тебе синтаксисом сделать это для одного класса - а нейросеть по твоему шаблону сделать для всех остальных структур и функций либы).
Я примерно так делаю (RAII я не игнорирую, но использую очень ограничено):
У каждой структуре есть метод init. То есть после создания объект невалидный, и надо сделать init - и из-за того что это не конструктор, мне не надо использовать уродливые конструкции вида
class t_class{
A a;
B b;
tud_descriptor_string_cb usb_musor;
t_class(int x, int y):a{123,"s12313"},b(12312,643345), usb_musor{calculate_param_for_usb_musro()}{
... код конструктора.
}
}, я такое постоянно вижу в примерах, особенно в коде игр, и там таких вложенных штук просто на десять строк, больше чем конструктора.
Мне очень не нравится что в таком синтаксисе параметры для конструкторов я не могу в теле конструктора вычислить, а мне нужны вспомогательные функции вида calculate_param_for_usb_musro, чтобы прямо в скобках вычислить параметры - что не всегда эффективно (какая-то функция может высчитывать параметры сразу для двух вложенных классов), и выглядит отвратительно. Это та часть синтаксиса в с++, которая топ-1 по уродливости с моей точки зрения. Топ-2 это умные указатели, кстати.. Ну и ещё это странно, для примера я создаю структуру мира, в которую вложена, например, локация и объект. И получается, что несмотря на то что было бы логично сгенерировать мир, а потом туда в зависимости от свойств мира добавлять локацию и объекты - с raii выходит, что я сначала создаю объект, а уже потом локацию и мир. И так как объекту нужно что-то знать про мир, хотя бы просто иметь указатель на владельца, то всё-равно придётся что-то вроде ниже-описанной функции init делать.
С функцией init я могу в теле конструктора делать что хочу, удобным образом и в нужной мне последовательности, примерно так:
class t_class{
A a;
B b;
tud_descriptor_string_cb usb_musor;
void init(int x, int y){
a.init(123,"s12313");
auto r=calculate_param_for_();
b.init(r.first);
usb_musor.init(r.second);
... код конструктора.
}
}
Итого в конструкторе/деструкторе или ничего нет, или что-то супер простое типа выделения 20 мб памяти для массива, которую со стека я не возьму, а из кучи возьму, и которое в RAII логично ложится.
И аналогично я могу destroy вызывать когда мне хочется.
Есть конечно проблемы, что можно два раза вызвать init/destroy - но такую ошибку допустить достаточно сложно, как мне кажется, ну и к слову виртуальный метод (не статичный, а в таблице виртуальных методов когда есть что-то) даёт наклодных расходов больше (и по памяти, и по быстродействию), чем проверка bool-переменной в вызове статичного метода. Проверка проще, чем переход по чему-то там в таблице виртуальных методов, я тестировал это на разных компьютерах. Ну да это впрочем и логично, у проверки функционал проще. Да, надо иметь ввиду, что такая фигня сразу делает не особо совместимым тип с stl-контейнерами, и если unordered_map будет расширять свой внутренний буфер - он с большой вероятностью не слишком качественно скопирует твои объекты и нужно немного понимать что где происходит.
Конечно можно все объекты хранить как указатель, и вызывать для них new для инициализации в нужный момент - но это бьёт по производительности, и это не окей, что в угоду синтаксиса вместо монолитного расположения памяти объекты лежат в куче как попало, и разыменовываю постоянно указатели, хотя это нужно только для инициализации, лол. Или сделать пустой объект и move-оператор присваивания.
Да, move-симантика и вот эти мутные схемы, когда какая перегрузка перемещения или копирования вызывает, и почему у меня конструктор копирования и конструктор перемещения это не то же самое, что оператор = копирования и перемещения (при инициализациях вида A a={1,3}; и A a{1,3}; вроде какая-то разница в вызовах есть) тоже немного напрягает, потому не считаю зазорным написать явный метод вида move_unit(unit from, unit to). Это как есть офигительное копирование строк через while (dest++ = src++) и аналогичный фокус с абузом switch/case, но ведь всегда можно написать
int i = 0;
while (src != 0) {
dest = src;
i++;
}
dest = 0;
что скорее всего после компилятора будет байт в байт тем же кодом, что и вышерасположенная нечитаемая дичь.
>Что мне нравится, по сравнению с Паскалем:
Не знаю что там с паскалем, но в делфи (которая delphi XE и моложе) добавили же в некоторой степени обобщённые методы, генеретики какие-то. Я не помню, не писал 15 лет. Перегрузки тоже там есть, их я очень люблю и писал на делфи везде и в си пишу.
Я честно не понял твоего примера: конструктор vs init. Ты код init можешь в тело конструктора засунуть, а лист инициализации оставить пустым, его не обязательно заполнять, в этом случае он вызовет дефолтный конструктор для а и б, как и в случае с .init().
> Забыл упомянуть ещё RAII
А нахуя тебе C++ тогда вообще, если тебе не нравится буквально главная его киллер фича?
> Не знаю, может и стоит ограничиться С и дальше что-то пытаться делать.
Может, стоит. Попробуй на Zig ещё посмотреть, у его автора тоже шиза — причем, весьма яркая — насчёт явности выполняемых действий. Например, перегрузки операторов нет, если к чему-то обращаются, используя синтаксис (), то это вызов функции, цирка с левыми/правыми ссылками как в плюсах нет, и тд.
Исключений нет, RAII нет, наследования нет. В общем, Си, но только с модулями, без макросов, с комптаймами и прочими радостями жизни, всё как ты хочешь. Один минус, язык в активной разработке, и всё постоянно меняется. И не факт, что в ближайшие лет 5 он выйдет в релиз. Ещё и Bun с него ушел на Rust, поэтому, возможно, он вообще загнётся и всем на него станет похуй.
Так я не знал о этой фиче, когда начинал учить. Никто, рекламируя С++ для вкатунов, о ней не рассказывает. Да и даже если бы знал, без хотя бы минимального халоу-ворлдского опыта что-то о ней сказать бы не мог.
Ну, перекат на С тогда.
 298 Кб, 1200x1800
298 Кб, 1200x1800Исключения и RAII — это самое гениальное изобретение в программировании, отказывающиеся от них вынуждены переизобретать их в уродской форме.
Исключения придуманы, чтобы не возвращать из каждой нетривиальной функции признак ошибки, который каждый вызывающий должен проверять. Если он этого не сделает, ошибка будет проигнорирована. Игнорирование ошибки — почти никогда не то, что ты хочешь с ней сделать, поэтому очень плохо как поведение по умолчанию. С исключениями поведение по умолчанию — прерывание текущей работы и пробрасывание ошибки до уровня, который знает, что с ней делать.
Представь иерархию вызовов вроде
>сохранить проект → записать файл → записать секцию → записать массив чисел → записать одно число → записать uint32 → сбросить заполненный буфер на диск → системная функция записи в файл
в которой «системная функция записи в файл» проваливается, и теперь эту ошибку нужно пробросить наверх через все промежуточные звенья, то есть каждое звено должно сделать if err != nil { return err; }. Такое пробрасывание ошибки наверх через явные (а даже если и не очень) return’ы — по сути ручная эмуляция раскрутки стека при исключении, и она уродует всю цепочку, заставляя добавлять мусор в код и сигнатуры функций.
Но это мелочи.
Подобно тому, как великая цель сборки мусора — это не собирать мусор, а эмулировать компьютер с бесконечной памятью, великая цель исключений в сочетании с RAII — обеспечить транзакционность твоих операций. Транзакция — это последовательность действий, которая исполняется как одно целое, то есть либо исполняется полностью, либо не выполняется вообще. Идеальная реализация try ... catch — это создать бэкап Вселенной перед try, при успешном достижении catch уничтожить бэкап, а при ошибке откатить Вселенную к бэкапу и перейти на обработчик catch с информацией о случившемся. И вот, деструкторы должны обеспечивать откат состояния, и это плюс-минус тот же откат, что ты делаешь при штатном завершении работы с объектом, при котором вызовется тот же деструктор.
В этой аналогии должно быть интуитивно понятно, что try ... catch — «тяжёлая» и в некотором роде «высокоуровневая» операция, которая должна исполняться «на самом верху», принимая решение, что делать с ошибкой: показать пользователю, записать в лог, прервать часть работы или всю работу; на остальных уровнях тебе ПРОСТО нужно правильно проектировать свои сущности и писать правильные деструкторы, и всё будет САМО работать при любых ошибочных сценариях.
Пример. Представь, что у тебя есть программа-редактор чего-нибудь, и при выделении частей чего-нибудь она входит в режим, в котором вокруг выделенной части появляются кнопочки ←, ↑, →, ↓. У тебя будет объект, хранящий состояние этого режима, в том числе список добавленных кнопочек, и в своём деструкторе он будет уничтожать всё, связанное с режимом, в том числе убирать с окна кнопочки. Так что если ты начал добавлять кнопочки ← и ↑, а на добавлении кнопочки → загрузка её пиктограммы провалилась, будет выброшено исключение, деструктор этого полуготового состояния уберёт с окна все уже добавленные кнопочки (как и при штатном выходе из ←↑→↓-режима), и вообще всё магически откатится к состоянию перед try, и уже кто-то наверху примет решение, что делать с ошибкой. Какие бы неведомые ошибки ни происходили, твоя программа не придёт в несогласованное состояние, в котором в окне остались плавать ни с чем не связанные ← и ↑.
Другой пример. Представим, что ты сохраняешь вот этот проект из своего редактора в файл, но в процессе возникла ошибка. Оставлять недописанный (по сути повреждённый) файл не стоит, поэтому типично сделать try { записать файл } catch (...) { удалить файл; throw; } — это будет явным усилием по откату изменений, если тебе лень писать деструктор. Более чистым решением (в свете аналогии с клонированием Вселенной при try ... catch) будет сделать объект, представляющий файл, с булевским полем ok, после записи файла выставлять ok = true, а в деструкторе объекта удалять файл, если не ok — тогда откат будет полностью автоматическим, но try ... catch ... throw КОРОЧЕ, по крайней мере пока это не понадобилось в более чем одном месте.
Ещё пример. Представь, что у тебя есть объект, который иногда ОБНОВЛЯЕТСЯ и на чьи обновления можно ПОДПИСАТЬСЯ. Ты можешь добавить объекту методы subscribe(on_update_callback) → int id и unsubscribe(int id), где subscribe обещает вызывать on_update_callback при обновлениях и возвращает ID этой подписки, а unsubscribe(id) отменяет подписку по id. Но это напрашивается на бесконечные проблемы, связанные с забыванием вызвать unsubscribe, unsubscribe’ом не того id, и чёрт знает чем ещё. Если вместо int id ты будешь возвращать из subscribe() объект Subscription, который вызывает unsubscribe в своём деструкторе и который явно хранят внутри себя те, кто ещё желает получать уведомления об обновлениях, то автоматически станет невозможно забыть отписаться. Такая подписка — такой же ресурс, требующий управления и идеально ложащийся на концепцию RAII, как пресловутые открытые файлы или выделенная память.
Я не представляю, как люди живут без исключений и RAII, чем занимаются. Дебажат целыми днями? Обнаруживают и явно обрабатывают сотый сценарий, в котором повисают бесхозные ← ↑ / остаётся призрачная подписка, автора которой доедают двоичные опарыши?
298 Кб, 1200x1800Исключения и RAII — это самое гениальное изобретение в программировании, отказывающиеся от них вынуждены переизобретать их в уродской форме.
Исключения придуманы, чтобы не возвращать из каждой нетривиальной функции признак ошибки, который каждый вызывающий должен проверять. Если он этого не сделает, ошибка будет проигнорирована. Игнорирование ошибки — почти никогда не то, что ты хочешь с ней сделать, поэтому очень плохо как поведение по умолчанию. С исключениями поведение по умолчанию — прерывание текущей работы и пробрасывание ошибки до уровня, который знает, что с ней делать.
Представь иерархию вызовов вроде
>сохранить проект → записать файл → записать секцию → записать массив чисел → записать одно число → записать uint32 → сбросить заполненный буфер на диск → системная функция записи в файл
в которой «системная функция записи в файл» проваливается, и теперь эту ошибку нужно пробросить наверх через все промежуточные звенья, то есть каждое звено должно сделать if err != nil { return err; }. Такое пробрасывание ошибки наверх через явные (а даже если и не очень) return’ы — по сути ручная эмуляция раскрутки стека при исключении, и она уродует всю цепочку, заставляя добавлять мусор в код и сигнатуры функций.
Но это мелочи.
Подобно тому, как великая цель сборки мусора — это не собирать мусор, а эмулировать компьютер с бесконечной памятью, великая цель исключений в сочетании с RAII — обеспечить транзакционность твоих операций. Транзакция — это последовательность действий, которая исполняется как одно целое, то есть либо исполняется полностью, либо не выполняется вообще. Идеальная реализация try ... catch — это создать бэкап Вселенной перед try, при успешном достижении catch уничтожить бэкап, а при ошибке откатить Вселенную к бэкапу и перейти на обработчик catch с информацией о случившемся. И вот, деструкторы должны обеспечивать откат состояния, и это плюс-минус тот же откат, что ты делаешь при штатном завершении работы с объектом, при котором вызовется тот же деструктор.
В этой аналогии должно быть интуитивно понятно, что try ... catch — «тяжёлая» и в некотором роде «высокоуровневая» операция, которая должна исполняться «на самом верху», принимая решение, что делать с ошибкой: показать пользователю, записать в лог, прервать часть работы или всю работу; на остальных уровнях тебе ПРОСТО нужно правильно проектировать свои сущности и писать правильные деструкторы, и всё будет САМО работать при любых ошибочных сценариях.
Пример. Представь, что у тебя есть программа-редактор чего-нибудь, и при выделении частей чего-нибудь она входит в режим, в котором вокруг выделенной части появляются кнопочки ←, ↑, →, ↓. У тебя будет объект, хранящий состояние этого режима, в том числе список добавленных кнопочек, и в своём деструкторе он будет уничтожать всё, связанное с режимом, в том числе убирать с окна кнопочки. Так что если ты начал добавлять кнопочки ← и ↑, а на добавлении кнопочки → загрузка её пиктограммы провалилась, будет выброшено исключение, деструктор этого полуготового состояния уберёт с окна все уже добавленные кнопочки (как и при штатном выходе из ←↑→↓-режима), и вообще всё магически откатится к состоянию перед try, и уже кто-то наверху примет решение, что делать с ошибкой. Какие бы неведомые ошибки ни происходили, твоя программа не придёт в несогласованное состояние, в котором в окне остались плавать ни с чем не связанные ← и ↑.
Другой пример. Представим, что ты сохраняешь вот этот проект из своего редактора в файл, но в процессе возникла ошибка. Оставлять недописанный (по сути повреждённый) файл не стоит, поэтому типично сделать try { записать файл } catch (...) { удалить файл; throw; } — это будет явным усилием по откату изменений, если тебе лень писать деструктор. Более чистым решением (в свете аналогии с клонированием Вселенной при try ... catch) будет сделать объект, представляющий файл, с булевским полем ok, после записи файла выставлять ok = true, а в деструкторе объекта удалять файл, если не ok — тогда откат будет полностью автоматическим, но try ... catch ... throw КОРОЧЕ, по крайней мере пока это не понадобилось в более чем одном месте.
Ещё пример. Представь, что у тебя есть объект, который иногда ОБНОВЛЯЕТСЯ и на чьи обновления можно ПОДПИСАТЬСЯ. Ты можешь добавить объекту методы subscribe(on_update_callback) → int id и unsubscribe(int id), где subscribe обещает вызывать on_update_callback при обновлениях и возвращает ID этой подписки, а unsubscribe(id) отменяет подписку по id. Но это напрашивается на бесконечные проблемы, связанные с забыванием вызвать unsubscribe, unsubscribe’ом не того id, и чёрт знает чем ещё. Если вместо int id ты будешь возвращать из subscribe() объект Subscription, который вызывает unsubscribe в своём деструкторе и который явно хранят внутри себя те, кто ещё желает получать уведомления об обновлениях, то автоматически станет невозможно забыть отписаться. Такая подписка — такой же ресурс, требующий управления и идеально ложащийся на концепцию RAII, как пресловутые открытые файлы или выделенная память.
Я не представляю, как люди живут без исключений и RAII, чем занимаются. Дебажат целыми днями? Обнаруживают и явно обрабатывают сотый сценарий, в котором повисают бесхозные ← ↑ / остаётся призрачная подписка, автора которой доедают двоичные опарыши?
Мяу, я конечно считаю, что ты перечислил большое количество искусственно возникающих проблем, которые невероятно хорошо решаются исключениями и RAII, и даже некоторое количество реальных проблем + помимо прочего я не могу не признать что твой подход верный с точки зрения здравомыслящего и направленного на результат человека: в 99.9% случаев оптимальнее и разумнее, дешевле и проще докупить второй сервер, вместо найма х3 программистов, которые смогли бы сделать то же самое без исключений и RAII.
Но речь идёт уже не про результат, а про процесс. То есть изначально претензия была не к тому, что через RAII программы не пишутся, а к тому, что это "фу, бяка, не хочу исключения", что я полностью поддерживаю. Мне оно не нравится дополнительными накладными расходами, и я понимаю что это в мире 16-ядерных ноутов с 16/32/64 гигами это шиза лютая, это как если бы я начал экономить электричество у себя дома, выключал бы свет на работе сберегая электричество на уровне как этим стоило бы заниматься на марсоходе. Что ещё абсурднее в мире, где у нас популярная операционная система - это виндоус, который после запуска сразу 4+ гб ест, и браузеры... ой, сам знаешь что я мог бы тут написать про браузеры и веб-языки. Ты прав во всём, если задача получить работающую программу, и нет задачи получать удовольствие от процесса.
Ещё чуть-чуть лирики, которая вряд ли стоит пикселей, на которых написана.
Типа да, это удобно; работает, что подтверждается практикой; очень сильно прикрывает задницу кожаным, которые да, могут пожертвовать 20% быстродействия и 40% потребления памяти, но зато получить возможно не решать фундаментальные проблемы кожаных (вроде невнимательности), а заниматься решением настоящих проблем. 40% производительности и памяти - это затраты, а не проблемы. Понятные, предсказуемые и с известным оптимальным (по времени и финансам) решением. А вот то что 30 лет назад не было удобного CAD-редактора вроде Solidworks или другого софта с таким - вот это было настоящей проблемой, несопоставимо более сложно, и даже если бы создание такой программы потребовало бы использовать просто худшие языки с х100 потреблением памяти и х0.01 производительностью, это бы всё-равно было оправдано.
А сейчас ещё нейронки плюс-минус в эту же сторону оптимизации ведут человечество. Я сейчас, сегодня, вот я сам - у которого любимый язык си, и который даже на питоне пишет почти без использования исключений, вот я тыкал нейронку, чтобы оно мне переформатировало csv, xlsx файлы и вывело какие-то графики, и оно мне это сделало за 10 минут, тогда как я бы сам гуглил функции всяких openpyxl и matplotlib день, а если бы писан на си, а в идеале ещё и без либ писать свой код для открытия и распаковки xlsx, где не будет исключений, это бы был уже не день, а месяц, если не год.
А ещё интересный мысленный эксперимент.
Вселенная 1. Байтоёбы. Лютые. Пишут код на чистом си. За каждым действием компьютера стоит строчка кода, 0 автоматический действий. Проходит 100 лет. Они даже написали кусочек игр, браузеров и даже cad-систем.
Вселенная 2. Адепты высокоуровневых языков. Прошло 20 лет. Пишут на питоне, на js, на любом мусоре, отображения окна браузера с 4 иконками и 40 строками текста требует загрузки 40 мб из сетки и 600 мб оперативы для кеширования, а работает это на связке тяжело жужжащих системников. Прошло 40 лет. Системников произвели ещё больше чтобы это хоть как-то работало, окей, если компьютер это 10 квт тепла и 70 децибелл шума, но лютое злоупотребление высокоуровневыми языками, конструкторами всевозможных программ и прочее приводят к тому что от реализации до демки требуется неделя или меньше даже для сложных программ. Ну и сервер на 50 квт для первых версий, да.
прошло 60 лет. Люди написали все возможные программы, изобрели удобнейшие cad-программы и прочее такое, и в тоге где-то стоит мегаваттный суперкомпьютер с cad системой, на нём отдель из нескольких инженеров считают как сделать ракету, как сделать термоядерный реактор, как собрать кольца и сферы дайсона и вот это всё + более того, любая идея проверяется численными методами за несколько часов написания кода и последующую отправку на рассчёт. Последующее тиражирование разработок этих инженеров делает эти мегаваттные затраты в масштабах человечества просто нулевыми и незначительными. Через 80 лет эти люди приходят к ии намного провосходящим всё что у нас есть сейчас, и эти ии к 85 году переписываю весь софт на супер-низкоуровневые инструкции, становится доступно каждому под свои нужны, задачи или хотелки написать и скомпилировать на час, например, интернет браузер на ассемблере под конкретную архитектуру этого человека. И всё. В этой точке вселенная 2 превосходит вселенную 1 и по суммарной вычислительной мощности (подстёгивалось не воспитание программистов, а создание серверов, которые масштабируются лучше) и по омтимизации (так как индивидуальное написание программ под каждую архитектуру становится доступным из-за феноменально высокой скорости разработки).
Аналогичная ситуация с зелёной и солнечной энергетикой. Думаю, если все откажутся от углеводородов и будут сидеть на солнечных панелях, то технологический прогресс замедлиться, и будет очень неспешным, и через 500 лет будет не сильно выше текущего. А если нещадно жечь нефть, уголь и газ, то технологический прогресс через 50 лет может быть очень высоким, приедут ко всяким реакторам на быстрых нейтронах или, лол, термоядерным реакторам и как бы так не вышло, что неспешное тление в течении 500 или 5000 лет загрязнит землю сильнее, чем короткий и очень интенсивный кусок в 50 лет, за которым технологий будет достаточно, чтобы прийти к отсутствию загрязнений. Иногда препятствие лучше преодолевать с разбегу, чем медленно, долго и упорно строить к нему лестницу.
Мяу, я конечно считаю, что ты перечислил большое количество искусственно возникающих проблем, которые невероятно хорошо решаются исключениями и RAII, и даже некоторое количество реальных проблем + помимо прочего я не могу не признать что твой подход верный с точки зрения здравомыслящего и направленного на результат человека: в 99.9% случаев оптимальнее и разумнее, дешевле и проще докупить второй сервер, вместо найма х3 программистов, которые смогли бы сделать то же самое без исключений и RAII.
Но речь идёт уже не про результат, а про процесс. То есть изначально претензия была не к тому, что через RAII программы не пишутся, а к тому, что это "фу, бяка, не хочу исключения", что я полностью поддерживаю. Мне оно не нравится дополнительными накладными расходами, и я понимаю что это в мире 16-ядерных ноутов с 16/32/64 гигами это шиза лютая, это как если бы я начал экономить электричество у себя дома, выключал бы свет на работе сберегая электричество на уровне как этим стоило бы заниматься на марсоходе. Что ещё абсурднее в мире, где у нас популярная операционная система - это виндоус, который после запуска сразу 4+ гб ест, и браузеры... ой, сам знаешь что я мог бы тут написать про браузеры и веб-языки. Ты прав во всём, если задача получить работающую программу, и нет задачи получать удовольствие от процесса.
Ещё чуть-чуть лирики, которая вряд ли стоит пикселей, на которых написана.
Типа да, это удобно; работает, что подтверждается практикой; очень сильно прикрывает задницу кожаным, которые да, могут пожертвовать 20% быстродействия и 40% потребления памяти, но зато получить возможно не решать фундаментальные проблемы кожаных (вроде невнимательности), а заниматься решением настоящих проблем. 40% производительности и памяти - это затраты, а не проблемы. Понятные, предсказуемые и с известным оптимальным (по времени и финансам) решением. А вот то что 30 лет назад не было удобного CAD-редактора вроде Solidworks или другого софта с таким - вот это было настоящей проблемой, несопоставимо более сложно, и даже если бы создание такой программы потребовало бы использовать просто худшие языки с х100 потреблением памяти и х0.01 производительностью, это бы всё-равно было оправдано.
А сейчас ещё нейронки плюс-минус в эту же сторону оптимизации ведут человечество. Я сейчас, сегодня, вот я сам - у которого любимый язык си, и который даже на питоне пишет почти без использования исключений, вот я тыкал нейронку, чтобы оно мне переформатировало csv, xlsx файлы и вывело какие-то графики, и оно мне это сделало за 10 минут, тогда как я бы сам гуглил функции всяких openpyxl и matplotlib день, а если бы писан на си, а в идеале ещё и без либ писать свой код для открытия и распаковки xlsx, где не будет исключений, это бы был уже не день, а месяц, если не год.
А ещё интересный мысленный эксперимент.
Вселенная 1. Байтоёбы. Лютые. Пишут код на чистом си. За каждым действием компьютера стоит строчка кода, 0 автоматический действий. Проходит 100 лет. Они даже написали кусочек игр, браузеров и даже cad-систем.
Вселенная 2. Адепты высокоуровневых языков. Прошло 20 лет. Пишут на питоне, на js, на любом мусоре, отображения окна браузера с 4 иконками и 40 строками текста требует загрузки 40 мб из сетки и 600 мб оперативы для кеширования, а работает это на связке тяжело жужжащих системников. Прошло 40 лет. Системников произвели ещё больше чтобы это хоть как-то работало, окей, если компьютер это 10 квт тепла и 70 децибелл шума, но лютое злоупотребление высокоуровневыми языками, конструкторами всевозможных программ и прочее приводят к тому что от реализации до демки требуется неделя или меньше даже для сложных программ. Ну и сервер на 50 квт для первых версий, да.
прошло 60 лет. Люди написали все возможные программы, изобрели удобнейшие cad-программы и прочее такое, и в тоге где-то стоит мегаваттный суперкомпьютер с cad системой, на нём отдель из нескольких инженеров считают как сделать ракету, как сделать термоядерный реактор, как собрать кольца и сферы дайсона и вот это всё + более того, любая идея проверяется численными методами за несколько часов написания кода и последующую отправку на рассчёт. Последующее тиражирование разработок этих инженеров делает эти мегаваттные затраты в масштабах человечества просто нулевыми и незначительными. Через 80 лет эти люди приходят к ии намного провосходящим всё что у нас есть сейчас, и эти ии к 85 году переписываю весь софт на супер-низкоуровневые инструкции, становится доступно каждому под свои нужны, задачи или хотелки написать и скомпилировать на час, например, интернет браузер на ассемблере под конкретную архитектуру этого человека. И всё. В этой точке вселенная 2 превосходит вселенную 1 и по суммарной вычислительной мощности (подстёгивалось не воспитание программистов, а создание серверов, которые масштабируются лучше) и по омтимизации (так как индивидуальное написание программ под каждую архитектуру становится доступным из-за феноменально высокой скорости разработки).
Аналогичная ситуация с зелёной и солнечной энергетикой. Думаю, если все откажутся от углеводородов и будут сидеть на солнечных панелях, то технологический прогресс замедлиться, и будет очень неспешным, и через 500 лет будет не сильно выше текущего. А если нещадно жечь нефть, уголь и газ, то технологический прогресс через 50 лет может быть очень высоким, приедут ко всяким реакторам на быстрых нейтронах или, лол, термоядерным реакторам и как бы так не вышло, что неспешное тление в течении 500 или 5000 лет загрязнит землю сильнее, чем короткий и очень интенсивный кусок в 50 лет, за которым технологий будет достаточно, чтобы прийти к отсутствию загрязнений. Иногда препятствие лучше преодолевать с разбегу, чем медленно, долго и упорно строить к нему лестницу.
 278 Кб, 1447x2048
278 Кб, 1447x2048Я тоже очень низкоуровневый чел, я некоторые функции пишу на ассемблере (вот, например, чтение n-битного числа из битового поля: >>812022 →) и постоянно фанатично анализирую инструкции, генерируемые моим высокоуровневым кодом, проверяя, нет ли там каких-то откровенных неоптимальностей.
Не факт, что эти накладные расходы вообще есть. Поинтересуйся, как работают zero-cost exceptions; TL;DR: в исполняемом файле вместе с кодом хранится его карта с размеченными границами блоков try-finally, и для броска исключения стек раскручивается начиная с указателя на выполняемую инструкцию, с поиском по этой карте, под защитой каких блоков try-finally находится очередной адрес из стека вызовов и что с этим делать. Это очень медленно, но когда исключений не бросается, прямых накладных расходов на сами try-finally нет. Косвенные всё же могут быть, т. к. то, что почти каждый вызов функции может бросить исключение, ставит больше препятствий для оптимизаций, но ведь и коды ошибок не бесплатны: эти проверки if err != nil { return err; } выполняются всегда, даже если реально это условие никогда не срабатывает, а с zero-cost exceptions их тупо нет. Даже и нельзя быть уверенным, что из этого в итоге быстрее.
Касательно деструкторов, если у них есть работа, тебе же всё равно придётся её выполнять, просто в C это будет ручное
>int rollback = 0;
>if (!create_a()) goto end; rollback = 1;
>if (!create_b()) goto end; rollback = 2;
>if (!create_с()) goto end; rollback = 3;
>...
>end: switch(rollback) {
> case 3: destroy_c();
> case 2: destroy_b();
> case 1: destroy_a(); }
в каждой функции.
Я считаю, что скорость нужно искать вообще не здесь, и глупо ради скорости заранее отказываться от столь дешёвых и полезных вещей. Вот у Agner Fog в монографии Optimizing subroutines in assembly language есть такая мысль: критическое место программы — всегда цикл. Самые медленные вещи, которые только может исполнить процессор, исполняются за долю микросекунды, и чтобы это заметить, такая операция должна быть в цикле. Поэтому давайте разберёмся, как оптимизировать циклы. Если перенести эту мысль на ситуацию с объектами и их деструкторами, то по отдельности они дёшевы, а чтобы стали недёшевы, тебе нужен целый массив объектов. А раз у тебя есть целый массив объектов, стоит не оптимизировать их сраные деструкторы, а организовать сам массив получше, воспользовавшись знанием его природы, например, как SoA вместо AoS (https://en.wikipedia.org/wiki/AoS_and_SoA) или ещё что. Вот здесь: https://gitlab.com/freepascal.org/fpc/source/-/blob/main/rtl/inc/heaptrc.pp, я из этих соображений сделал хранилище для объектов типа «стектрейс», StackTracesRegistry, которое за счёт знания природы стектрейсов делает это в десятки раз эффективнее, чем в виде отдельных «array of pointer», и этим открывает дорогу совершенно новым возможностям, ранее казавшимся немыслимыми. Хотя она подразумевает ручное управление отдельными стектрейсами через вызовы Add и Release, их легко можно было бы оформить и как возвращаемые из Add RAII-объекты, вызывающие Release в своём деструкторе, это бы не изменило сути; для публичной коллекции стектрейсов я бы именно так и сделал без вариантов, но эта не публичная и у Release всего три точки вызова.
>А ещё интересный мысленный эксперимент.
Думал об этом, но это утопия. К нейросетям в этом контексте отношусь максимально скептически, я думаю, они больше поднасрут (вплоть до полной катастрофы), чем помогут, потому что они поощряют некомпетентность — как верно заметил твиттерянин https://x.com/karrisaarinen/status/2048065890760184080, когда ты не шаришь, их выхлоп волшебен, а чем лучше понимаешь, что вообще хочешь, тем сложнее, если вообще возможно, это получить; как замечал Михаил Никитин, компетентные люди берутся из некомпетентных, а когда те обучаются нейронками, их компетенция не растёт (а это я уже даже не столько у него, сколько у какого-то руководителя реальных программистов слышал: мол, мы поделили стажёров на две группы, одну из которых заставляли решать задачи ручками, а не ИИ, и те, которых не заставляли, за несколько месяцев так и не выросли).
И наоборот, можно сказать, что весь мир вокруг тебя существует не благодаря Питону и ЖС, а вопреки. Мой любимый пример — видеокодеки. Именно благодаря тому, что их байтоёбят, видео получило прирост производительности, пропорциональный увеличению мощности железа, поэтому на железе одного и того же сегмента 20 лет назад мы смотрели видео в 640 × 480, а теперь смотрим в 4K 60FPS. Не байтоёбские же программы фактически ХУЖЕ делают то же самое, что их аналоги 20 лет назад, и помимо больших системных требований и для своей РАЗРАБОТКИ и поддержки легко может требовать БОЛЬШЕ людей и телодвижений. См. также мою любимую иллюстрацию, что раньше ДЕЙСТВИТЕЛЬНО было лучше: https://www.artlebedev.ru/kovodstvo/sections/151/.
В целом, про революции пиздят инвесторам (и потребителям), реальное развитие эволюционно, план делать всё больше говна в надежде, что однажды говнистый эгрегор породит волшебника, превращающего говно в конфеты, менее надёжен, чем план совершенствовать производство конфет. Конечно, если выгорит, конфет будет больше, но... Это начинает звучать подозрительно похоже на лудочку: или джекпот, или потомки сосут хуй без ресов. Второе вероятнее.
278 Кб, 1447x2048Я тоже очень низкоуровневый чел, я некоторые функции пишу на ассемблере (вот, например, чтение n-битного числа из битового поля: >>812022 →) и постоянно фанатично анализирую инструкции, генерируемые моим высокоуровневым кодом, проверяя, нет ли там каких-то откровенных неоптимальностей.
Не факт, что эти накладные расходы вообще есть. Поинтересуйся, как работают zero-cost exceptions; TL;DR: в исполняемом файле вместе с кодом хранится его карта с размеченными границами блоков try-finally, и для броска исключения стек раскручивается начиная с указателя на выполняемую инструкцию, с поиском по этой карте, под защитой каких блоков try-finally находится очередной адрес из стека вызовов и что с этим делать. Это очень медленно, но когда исключений не бросается, прямых накладных расходов на сами try-finally нет. Косвенные всё же могут быть, т. к. то, что почти каждый вызов функции может бросить исключение, ставит больше препятствий для оптимизаций, но ведь и коды ошибок не бесплатны: эти проверки if err != nil { return err; } выполняются всегда, даже если реально это условие никогда не срабатывает, а с zero-cost exceptions их тупо нет. Даже и нельзя быть уверенным, что из этого в итоге быстрее.
Касательно деструкторов, если у них есть работа, тебе же всё равно придётся её выполнять, просто в C это будет ручное
>int rollback = 0;
>if (!create_a()) goto end; rollback = 1;
>if (!create_b()) goto end; rollback = 2;
>if (!create_с()) goto end; rollback = 3;
>...
>end: switch(rollback) {
> case 3: destroy_c();
> case 2: destroy_b();
> case 1: destroy_a(); }
в каждой функции.
Я считаю, что скорость нужно искать вообще не здесь, и глупо ради скорости заранее отказываться от столь дешёвых и полезных вещей. Вот у Agner Fog в монографии Optimizing subroutines in assembly language есть такая мысль: критическое место программы — всегда цикл. Самые медленные вещи, которые только может исполнить процессор, исполняются за долю микросекунды, и чтобы это заметить, такая операция должна быть в цикле. Поэтому давайте разберёмся, как оптимизировать циклы. Если перенести эту мысль на ситуацию с объектами и их деструкторами, то по отдельности они дёшевы, а чтобы стали недёшевы, тебе нужен целый массив объектов. А раз у тебя есть целый массив объектов, стоит не оптимизировать их сраные деструкторы, а организовать сам массив получше, воспользовавшись знанием его природы, например, как SoA вместо AoS (https://en.wikipedia.org/wiki/AoS_and_SoA) или ещё что. Вот здесь: https://gitlab.com/freepascal.org/fpc/source/-/blob/main/rtl/inc/heaptrc.pp, я из этих соображений сделал хранилище для объектов типа «стектрейс», StackTracesRegistry, которое за счёт знания природы стектрейсов делает это в десятки раз эффективнее, чем в виде отдельных «array of pointer», и этим открывает дорогу совершенно новым возможностям, ранее казавшимся немыслимыми. Хотя она подразумевает ручное управление отдельными стектрейсами через вызовы Add и Release, их легко можно было бы оформить и как возвращаемые из Add RAII-объекты, вызывающие Release в своём деструкторе, это бы не изменило сути; для публичной коллекции стектрейсов я бы именно так и сделал без вариантов, но эта не публичная и у Release всего три точки вызова.
>А ещё интересный мысленный эксперимент.
Думал об этом, но это утопия. К нейросетям в этом контексте отношусь максимально скептически, я думаю, они больше поднасрут (вплоть до полной катастрофы), чем помогут, потому что они поощряют некомпетентность — как верно заметил твиттерянин https://x.com/karrisaarinen/status/2048065890760184080, когда ты не шаришь, их выхлоп волшебен, а чем лучше понимаешь, что вообще хочешь, тем сложнее, если вообще возможно, это получить; как замечал Михаил Никитин, компетентные люди берутся из некомпетентных, а когда те обучаются нейронками, их компетенция не растёт (а это я уже даже не столько у него, сколько у какого-то руководителя реальных программистов слышал: мол, мы поделили стажёров на две группы, одну из которых заставляли решать задачи ручками, а не ИИ, и те, которых не заставляли, за несколько месяцев так и не выросли).
И наоборот, можно сказать, что весь мир вокруг тебя существует не благодаря Питону и ЖС, а вопреки. Мой любимый пример — видеокодеки. Именно благодаря тому, что их байтоёбят, видео получило прирост производительности, пропорциональный увеличению мощности железа, поэтому на железе одного и того же сегмента 20 лет назад мы смотрели видео в 640 × 480, а теперь смотрим в 4K 60FPS. Не байтоёбские же программы фактически ХУЖЕ делают то же самое, что их аналоги 20 лет назад, и помимо больших системных требований и для своей РАЗРАБОТКИ и поддержки легко может требовать БОЛЬШЕ людей и телодвижений. См. также мою любимую иллюстрацию, что раньше ДЕЙСТВИТЕЛЬНО было лучше: https://www.artlebedev.ru/kovodstvo/sections/151/.
В целом, про революции пиздят инвесторам (и потребителям), реальное развитие эволюционно, план делать всё больше говна в надежде, что однажды говнистый эгрегор породит волшебника, превращающего говно в конфеты, менее надёжен, чем план совершенствовать производство конфет. Конечно, если выгорит, конфет будет больше, но... Это начинает звучать подозрительно похоже на лудочку: или джекпот, или потомки сосут хуй без ресов. Второе вероятнее.
>видеокодеки
Ну, там и осмысленность высокая. Камер очень много, я не удивлюсь, если сейчас в мире есть петабайт данных в секунду. И если бы там был не h265/h264, а h262, то, ну, было бы три петабайта в секунду. А ещё, ну, вроде только вчера я видел в av1 кодировал по 40 минут на 1 секунду 1280х720х30 , а сейчас это и на процессоре в разы быстрее, и у меня на видеокарте стоит пусть не такой идеальный, но энкодер av1 который может в реальном времени писать 1920х1080х60. А ещё говоря уже av2 то ли вышел, то ли близко к этому. Это экономит одновременно кучу байт/с сетевого трафика и кучу байт на накопителях данных. Возможно в ущерб производительности. Впрочем, ещё лет 20 назад вроде бы предсказывали, что закон Мура плюс-минус работать будет (для производительности), а вот для памяти и данных оно растёт медленнее, и в целом мы придём к сценарию, что производительность дефицитным ресурсом не является, а вот скорость памяти ой как является. На сервере с терабайтом памяти скорость нейросети ограничивается скоростью памяти, расчёты это проценты от затрачиваемого времени. Ну и цены на ddr5, ну да сам знаешь.
>раньше ДЕЙСТВИТЕЛЬНО было лучше
Да есть такое. Я в этом восхищаюсь достижениями науки и техники времён второй мировой. Там в течении 1-3 лет не имея наработок и никакого опыта в соответствующих областях сделали ракету, турбореактивный двигатель, радары микроволновые, ну и так далее по списку, и основные выработанные тогда решения стали стандартом лет на 30 вперёд. А потом ещё за 1-10 лет сделали ядерные реакторы, бомбы, термоядерные бомбы, спутники. Сейчас какую-то фигню которую сделали ещё в 80 заново проектирую и разрабатываю лет 10 до первого образца - при том, что там ничего нового и все решения уже известны, просто выбери нужные и сделай. Это капец.
В нейросети я всё же верю. Инвесторам врут; это, возможно, обвалится, и по факту окажется намного менее полезным, чем думают - но, мяу - это:
1 - избавляет от рутинного кода. Парсинг json-файла я вполне и запись значений из него в нужные поля структуры я доверю нейросети больше, чем себе. Это очень простая задача, с которой справляется qwen-3.5-9B, который летает на любой 8 гб карте. но она скучная, мозг теряет активность и внимательность, и в таком коде я вероятнее напишу -1 или +1 в каком-то месте. А так я и время сохраняю. И фокус.
2 - я могу не влезать в чужую область, и совершенствоваться в своей. Я вот сейчас устройство разрабатываю, для его управления удобно было бы использовать мобильное приложение. Я убеждён полностью, что в разработке мобильного приложения, которое выполняет лишь функцию интерфейса и не содержит никакой логики и вычислений, просто принимает данные, отсылает команды - что там есть хоть что-то, чего бы я не смог сделать сам. Сюда же попадает генерация спрайтов и анимацией картинконейросетью для прототипа игры. Предположим я демку делаю. Если я оставлю квадраты вместо текстур, а игра, например, про атмосферу и ощущения - то с квадратами будет сложно представить что выйдет. А если нарисовать криво-косо хоть что-то напоминающее реальные объекты, то будет намного проще представить как оно будет выглядеть с нормальными спрайтами и звуками.
3 - оно развивается неадекватно быстро. Картинки до диффузионных моделей, картинки sd1.0, картинки sdxl, картинки qwen-image различаются невероятно сильно, на порядки. Ещё пара таких ступеней, и даже если больше ничего непроизойдёт - это уже будет невероятной пользой. Да даже если в текущем состоянии замрёт. Это как с GPS - можно сколько угодно ругать космос и бесполезность полётов на Венеру, Сатурн и прочее - но GPS (выгода от него, экономия человеческих ресурсов) уже с запасом окупают все деньги, которые человечество потратило на все космические программы, в том числе бредовые.
4 - уже сейчас существующие модельки могут заменить очень много рабочих мест. Я сегодня подключался к карточке у себя дома и локальной сеткой смог распарсить pdf-файл, перерисовать его в файл с разметкой и поменять нужное. В сущности если не использовать pdf-файлы, а оставлять редактируемые, а ещё лучше - разработать дружелюбный для компьютеров формат документов, то все работники занимающиеся оформлением и созданием документов будут не нужны. Машины вроде как катаются. Юристы, ну, я бы предпочёл чтобы меня судила непредвзятая нейросеть, у которой будет цифровая подпись от сертифицирующего центра, что веса не были модицифированы, и чтобы можно было воспроизвести результат её работы для проверки решения. Чем человек, у которого может быть просто тьма заинтересованности, финансовой, карьерной, ещё какой + эти эксперименты где судьи с 20 лет опыта после обеда и со сладким чаем освобождаю досрочно в 3 раза чаще, и при этом на прямой вопрос влияет ли это, говорят что нет, мы не предвзяты. Не очень хочется стать жертвой такого случая (попасть до обеда или после). Если использовать сеть для обучения. У меня бы слюни текли, если бы в институте я бы мог не только спросить уставшего преподавателя между пар, который не всё знает и которому не всегда интересно ещё что-то мне объяснять, а была бы нейросеть, которая персонализированно отвечает мне. И это всё то что уже существует. Даже если дальнейшего развития не будет.
Полностью двачую твои слова про компетенции и обучение.
Если ты опытный - то если ты не можешь решить задачу, то и нейросеть тем более не может. В итоге для тебя это добро, так как решает скучные простые задачи (да ещё и быстрее тебя), и это корректное использование.
Если ты неопытный - то есть задачи, которые сложнее чем те, которые ты можешь решать, и в этот момент нейросеть становится лютым ядом. По смыслу как в тех экспериментах, что люди имеющие доступ в интернет с телефоном на парте заметно хуже запоминают информацию лекции. Тут и мысль что нейросеть может решить вредит, а если этим ещё и пользоваться, то это гроб-кладбище.
Выход либо в дисциплине и "культуре взаимодействия с нейросетями", либо если не останется достаточно сложных задач в принципе (таких, которые бы не решались нейросетью).
>видеокодеки
Ну, там и осмысленность высокая. Камер очень много, я не удивлюсь, если сейчас в мире есть петабайт данных в секунду. И если бы там был не h265/h264, а h262, то, ну, было бы три петабайта в секунду. А ещё, ну, вроде только вчера я видел в av1 кодировал по 40 минут на 1 секунду 1280х720х30 , а сейчас это и на процессоре в разы быстрее, и у меня на видеокарте стоит пусть не такой идеальный, но энкодер av1 который может в реальном времени писать 1920х1080х60. А ещё говоря уже av2 то ли вышел, то ли близко к этому. Это экономит одновременно кучу байт/с сетевого трафика и кучу байт на накопителях данных. Возможно в ущерб производительности. Впрочем, ещё лет 20 назад вроде бы предсказывали, что закон Мура плюс-минус работать будет (для производительности), а вот для памяти и данных оно растёт медленнее, и в целом мы придём к сценарию, что производительность дефицитным ресурсом не является, а вот скорость памяти ой как является. На сервере с терабайтом памяти скорость нейросети ограничивается скоростью памяти, расчёты это проценты от затрачиваемого времени. Ну и цены на ddr5, ну да сам знаешь.
>раньше ДЕЙСТВИТЕЛЬНО было лучше
Да есть такое. Я в этом восхищаюсь достижениями науки и техники времён второй мировой. Там в течении 1-3 лет не имея наработок и никакого опыта в соответствующих областях сделали ракету, турбореактивный двигатель, радары микроволновые, ну и так далее по списку, и основные выработанные тогда решения стали стандартом лет на 30 вперёд. А потом ещё за 1-10 лет сделали ядерные реакторы, бомбы, термоядерные бомбы, спутники. Сейчас какую-то фигню которую сделали ещё в 80 заново проектирую и разрабатываю лет 10 до первого образца - при том, что там ничего нового и все решения уже известны, просто выбери нужные и сделай. Это капец.
В нейросети я всё же верю. Инвесторам врут; это, возможно, обвалится, и по факту окажется намного менее полезным, чем думают - но, мяу - это:
1 - избавляет от рутинного кода. Парсинг json-файла я вполне и запись значений из него в нужные поля структуры я доверю нейросети больше, чем себе. Это очень простая задача, с которой справляется qwen-3.5-9B, который летает на любой 8 гб карте. но она скучная, мозг теряет активность и внимательность, и в таком коде я вероятнее напишу -1 или +1 в каком-то месте. А так я и время сохраняю. И фокус.
2 - я могу не влезать в чужую область, и совершенствоваться в своей. Я вот сейчас устройство разрабатываю, для его управления удобно было бы использовать мобильное приложение. Я убеждён полностью, что в разработке мобильного приложения, которое выполняет лишь функцию интерфейса и не содержит никакой логики и вычислений, просто принимает данные, отсылает команды - что там есть хоть что-то, чего бы я не смог сделать сам. Сюда же попадает генерация спрайтов и анимацией картинконейросетью для прототипа игры. Предположим я демку делаю. Если я оставлю квадраты вместо текстур, а игра, например, про атмосферу и ощущения - то с квадратами будет сложно представить что выйдет. А если нарисовать криво-косо хоть что-то напоминающее реальные объекты, то будет намного проще представить как оно будет выглядеть с нормальными спрайтами и звуками.
3 - оно развивается неадекватно быстро. Картинки до диффузионных моделей, картинки sd1.0, картинки sdxl, картинки qwen-image различаются невероятно сильно, на порядки. Ещё пара таких ступеней, и даже если больше ничего непроизойдёт - это уже будет невероятной пользой. Да даже если в текущем состоянии замрёт. Это как с GPS - можно сколько угодно ругать космос и бесполезность полётов на Венеру, Сатурн и прочее - но GPS (выгода от него, экономия человеческих ресурсов) уже с запасом окупают все деньги, которые человечество потратило на все космические программы, в том числе бредовые.
4 - уже сейчас существующие модельки могут заменить очень много рабочих мест. Я сегодня подключался к карточке у себя дома и локальной сеткой смог распарсить pdf-файл, перерисовать его в файл с разметкой и поменять нужное. В сущности если не использовать pdf-файлы, а оставлять редактируемые, а ещё лучше - разработать дружелюбный для компьютеров формат документов, то все работники занимающиеся оформлением и созданием документов будут не нужны. Машины вроде как катаются. Юристы, ну, я бы предпочёл чтобы меня судила непредвзятая нейросеть, у которой будет цифровая подпись от сертифицирующего центра, что веса не были модицифированы, и чтобы можно было воспроизвести результат её работы для проверки решения. Чем человек, у которого может быть просто тьма заинтересованности, финансовой, карьерной, ещё какой + эти эксперименты где судьи с 20 лет опыта после обеда и со сладким чаем освобождаю досрочно в 3 раза чаще, и при этом на прямой вопрос влияет ли это, говорят что нет, мы не предвзяты. Не очень хочется стать жертвой такого случая (попасть до обеда или после). Если использовать сеть для обучения. У меня бы слюни текли, если бы в институте я бы мог не только спросить уставшего преподавателя между пар, который не всё знает и которому не всегда интересно ещё что-то мне объяснять, а была бы нейросеть, которая персонализированно отвечает мне. И это всё то что уже существует. Даже если дальнейшего развития не будет.
Полностью двачую твои слова про компетенции и обучение.
Если ты опытный - то если ты не можешь решить задачу, то и нейросеть тем более не может. В итоге для тебя это добро, так как решает скучные простые задачи (да ещё и быстрее тебя), и это корректное использование.
Если ты неопытный - то есть задачи, которые сложнее чем те, которые ты можешь решать, и в этот момент нейросеть становится лютым ядом. По смыслу как в тех экспериментах, что люди имеющие доступ в интернет с телефоном на парте заметно хуже запоминают информацию лекции. Тут и мысль что нейросеть может решить вредит, а если этим ещё и пользоваться, то это гроб-кладбище.
Выход либо в дисциплине и "культуре взаимодействия с нейросетями", либо если не останется достаточно сложных задач в принципе (таких, которые бы не решались нейросетью).
Забыл пояснить важное.
>И это всё то что уже существует. Даже если дальнейшего развития не будет.
Я имел ввиду что это уже есть как прототип/демонстрация - но пока нет или почти нет как технология. С уже имеющимися сетками можно, лол, тьму полезных "ии-инструментов" сделать.
И ещё забыл важный аргумент про науку. Мне очень понравилось как в интервью Теренс Тао выразился, не помню формулировки. Но в обще в науке шизы, и скатываться до инструментализма им вредно. Будет лучше, если учёный будет придумывать концепции, а лаборанты, программисты и помощники будут их проверять или что-то такое. И вот раньше учёным чаще приходилось самими ручками работать и до инструментализма скатываться.