


Обсуждаем чужие гитхабы, коды, программирование микроконтроллеров.
сам учился на степике, всем советую прочитать книгу Брайана Кернигана и Денниса Ритчи «Язык программирования Си»
ЗАДАВАЙТЕ ВОПРОСЫ И ПОЛУЧАЙТЕ ОТВЕТЫ!
ахахах да прикольно , ржу нимагу)))) давайте,встречу айтишников сделаем ,пивка по пьем ёпт)))))
для начала схема подключения:
gnd (rcwl-0510) - gnd (esp32)
vin - 5v
out - любой свободный gpio
суть в том, что при обнаружении движения, датчик выдает напряжение на контакт OUT, программно мы опрашиваем наш gpio pin, и при возникновении там логической единицы понимаем, что китайцы прислали рабочий датчик.
вот так максимально просто это реализовано на си:
```
#include <stdio.h>
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "esp_log.h"
#include "driver/gpio.h"
#include "log.h"
#define MOTION_SENSOR_GPIO 22
static const char TAG = "GOVN0_SL0NA_main";
void app_main(void)
{
gpio_config_t io_conf = {
.intr_type = GPIO_INTR_DISABLE,
.mode = GPIO_MODE_INPUT,
.pin_bit_mask = (1ULL << MOTION_SENSOR_GPIO),
.pull_down_en = GPIO_PULLDOWN_ENABLE,
.pull_up_en = GPIO_PULLUP_DISABLE,
};
gpio_config(&io_conf);
int motion_sensor_state = 0;
int previous_state = 0;
while (1) {
motion_sensor_state = gpio_get_level(MOTION_SENSOR_GPIO);
/ регистрируем движение только при переходе с 0 на 1 /
if (motion_sensor_state == 1)
{
TickType_t current_time = xTaskGetTickCount();
uint32_t time_ms = current_time portTICK_PERIOD_MS;
ESP_LOGI(" -- ", "Motion sensor detected motion! Time: %lu ms (%.2f seconds)\n",
(unsigned long)time_ms, time_ms / 1000.0f);
}
ESP_LOGI(" -- ", "Motion sensor state: %d\n", motion_sensor_state);
vTaskDelay(1000 / portTICK_PERIOD_MS);
}
}
```
из логов видно, что все работает:
```
I (283) main_task: Calling app_main()
I (283) -- : Motion sensor state: 0
I (4283) -- : Motion sensor state: 0
I (5283) -- : Motion sensor state: 0
I (6283) -- : Motion sensor state: 0
I (11283) -- : Motion sensor detected motion! Time: 11010 ms (11.01 seconds)
I (11283) -- : Motion sensor state: 1
I (12283) -- : Motion sensor detected motion! Time: 12010 ms (12.01 seconds)
```
всё лучшее - на СИ!
для начала схема подключения:
gnd (rcwl-0510) - gnd (esp32)
vin - 5v
out - любой свободный gpio
суть в том, что при обнаружении движения, датчик выдает напряжение на контакт OUT, программно мы опрашиваем наш gpio pin, и при возникновении там логической единицы понимаем, что китайцы прислали рабочий датчик.
вот так максимально просто это реализовано на си:
```
#include <stdio.h>
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "esp_log.h"
#include "driver/gpio.h"
#include "log.h"
#define MOTION_SENSOR_GPIO 22
static const char TAG = "GOVN0_SL0NA_main";
void app_main(void)
{
gpio_config_t io_conf = {
.intr_type = GPIO_INTR_DISABLE,
.mode = GPIO_MODE_INPUT,
.pin_bit_mask = (1ULL << MOTION_SENSOR_GPIO),
.pull_down_en = GPIO_PULLDOWN_ENABLE,
.pull_up_en = GPIO_PULLUP_DISABLE,
};
gpio_config(&io_conf);
int motion_sensor_state = 0;
int previous_state = 0;
while (1) {
motion_sensor_state = gpio_get_level(MOTION_SENSOR_GPIO);
/ регистрируем движение только при переходе с 0 на 1 /
if (motion_sensor_state == 1)
{
TickType_t current_time = xTaskGetTickCount();
uint32_t time_ms = current_time portTICK_PERIOD_MS;
ESP_LOGI(" -- ", "Motion sensor detected motion! Time: %lu ms (%.2f seconds)\n",
(unsigned long)time_ms, time_ms / 1000.0f);
}
ESP_LOGI(" -- ", "Motion sensor state: %d\n", motion_sensor_state);
vTaskDelay(1000 / portTICK_PERIOD_MS);
}
}
```
из логов видно, что все работает:
```
I (283) main_task: Calling app_main()
I (283) -- : Motion sensor state: 0
I (4283) -- : Motion sensor state: 0
I (5283) -- : Motion sensor state: 0
I (6283) -- : Motion sensor state: 0
I (11283) -- : Motion sensor detected motion! Time: 11010 ms (11.01 seconds)
I (11283) -- : Motion sensor state: 1
I (12283) -- : Motion sensor detected motion! Time: 12010 ms (12.01 seconds)
```
всё лучшее - на СИ!
ASM или Си?
это так, простенький пример, лучше конечно создавать отдельную задачу для опрашивания gpio и очередь для передачи событий из прерывания в задачу
сиси
У строк в Паскале есть один минус. Они ограниченны, не больше 255 символов. В С строки в этом смысле лучше, ты войну и мир вместить в одну строку можешь. В Паскале придется мастерить что-то динамическое, типа связного списка.
>но строковые константы
Писать наверное какой-нибудь конвертор для них, хз.
>Как поменять формат строковых констант на свой?
Скорее всего никак. Только компилятор переписывать.
Хотя в С тоже придется динамический массив делать для войны и мира. Но ты понял, это просто массив, а не какая-то нетривиальная структура.
Но в новом паскале наверное это как-то решили. Последний раз программировал ещё на турбо.
Наверно только генерировать массив из отдельных символов, типа
const char str[] = { 'H', 'e', 'l', 'l', 'o' };
 86 Кб, 881x572
86 Кб, 881x572для примера возьмём такую программку с явной проблемой:
int main(void)
{
int arr[5];
for (int i = 0; i <= 5; i++) {
arr = i;
}
return 0;
}
имеется выход за пределы массива
компилируем с необходимыми флагами:
gcc test_file.c -fsanitize=address -g -O0 -o test_file
запускаем и видим ошибку времени исполнения:
==352074==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7f2e77c00034 at pc 0x5563dcbb222e bp 0x7ffc0c6fa970 sp 0x7ffc0c6fa968
...
...
именно так это и должно работать, но при попытке собрать эту программу нашим компилятором:
/opt/mipsel-unknown-linux-gnu/bin/mipsel-unknown-linux-gnu-gcc nsm/test_file.c -fsanitize=address -g -O0 -o test_file
/opt/mipsel-unknown-linux-gnu/bin/../lib/gcc/mipsel-unknown-linux-gnu/12.2.0/../../../../mipsel-unknown-linux-gnu/bin/ld: cannot find libasan_preinit.o: Нет такого файла или каталога
/opt/mipsel-unknown-linux-gnu/bin/../lib/gcc/mipsel-unknown-linux-gnu/12.2.0/../../../../mipsel-unknown-linux-gnu/bin/ld: cannot find -lasan: Нет такого файла или каталога
collect2: error: ld returned 1 exit status
на фотке переписка с тимлидом. че делать
86 Кб, 881x572для примера возьмём такую программку с явной проблемой:
int main(void)
{
int arr[5];
for (int i = 0; i <= 5; i++) {
arr = i;
}
return 0;
}
имеется выход за пределы массива
компилируем с необходимыми флагами:
gcc test_file.c -fsanitize=address -g -O0 -o test_file
запускаем и видим ошибку времени исполнения:
==352074==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7f2e77c00034 at pc 0x5563dcbb222e bp 0x7ffc0c6fa970 sp 0x7ffc0c6fa968
...
...
именно так это и должно работать, но при попытке собрать эту программу нашим компилятором:
/opt/mipsel-unknown-linux-gnu/bin/mipsel-unknown-linux-gnu-gcc nsm/test_file.c -fsanitize=address -g -O0 -o test_file
/opt/mipsel-unknown-linux-gnu/bin/../lib/gcc/mipsel-unknown-linux-gnu/12.2.0/../../../../mipsel-unknown-linux-gnu/bin/ld: cannot find libasan_preinit.o: Нет такого файла или каталога
/opt/mipsel-unknown-linux-gnu/bin/../lib/gcc/mipsel-unknown-linux-gnu/12.2.0/../../../../mipsel-unknown-linux-gnu/bin/ld: cannot find -lasan: Нет такого файла или каталога
collect2: error: ld returned 1 exit status
на фотке переписка с тимлидом. че делать
>Белые люди изобрели божественный абсолютно безопасный Раст
>Продолжать пользоваться дырявыми С/С++
Вы заслуживаете все ваши беды.
Раст успел уже обосраться и в ядре линупса и в сетевой инфраструктуре амазона. Ни какой безопасностью там и не пахнет, если программист накосячил, то раст не спасает. А вот мозги, при написании программ, выносит изрядно.
>Белые люди
Ты не охуел там? Тебя пидорасты за такой хейтспич закэнселят, рэйсист неинклюзивный.
А есть что-то более сложное? Там вроде довольно много инфы написано. Пожалуй, даже больше, чем в типовых книгах по си.
![484-0[1]](https://2ch.life//pr/src/3619616/17684758470980.webp)
Существует ли книга, после прочтения обложки которой вы не сказали "нуу и хуйня ебаная"?
Книга дракона.
Странно. Вот тип строки как в паскале, ограничение на длину строки - 4 гига.
struct strptr
{
char *begin;
uint32_t len;
};
осталось написать функции для сравнения, разбивки на токены, поика символов и всё - класс готов.
Можно будет взять кусок текста и пройтись по нему кодом, растащить на токены, и при том ничего никуда не копировать.
Да и от сегфолта с переполнением буфера оно помогает
Всё верно, речь больше про строковые константы.
@monkey обосри язык программирования СИ
Убирать 0 из внутреннего буфера = стрелять себе в ногу, если твои строки не собираются жить в песочнице, а логика с оплатой размера строки, но экономии 1 байта...
Там нет экономии в 1 байт, потому что он используется для хранения размера строки, а на деле 1 байта мало, поэтому используют 2 или 4. Так что напротив расход по памяти выше.
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/epoll.h>
#include <linux/input.h>
void main () {
struct input_event kbev;
struct epoll_event epev;
int kbfd = open("/dev/input/event0", O_RDONLY | O_NONBLOCK);
if(kbfd < 0) {
printf("Failed open event0\n");
return;
}
int epfd = epoll_create(1);
if(epfd < 0) {
printf("Failed to create epoll\n");
return;
}
epev.data.fd = kbfd;
epev.events = EPOLLIN;
if(epoll_ctl(epfd, EPOLL_CTL_ADD, kbfd, &epev) != 0) {
printf("Failed to configure epoll\n");
return;
}
int evn;
for(;;) {
evn = epoll_wait(epfd, &epev, 1, 0);
if(evn) {
if(evn == -1) {
printf("epoll_wait error");
return;
} else if(evn > 0) {
read(kbfd, &kbev, sizeof(struct input_event));
printf("%d\n", kbev.time.tv_sec);
}
}
}
close(epfd);
}
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/epoll.h>
#include <linux/input.h>
void main () {
struct input_event kbev;
struct epoll_event epev;
int kbfd = open("/dev/input/event0", O_RDONLY | O_NONBLOCK);
if(kbfd < 0) {
printf("Failed open event0\n");
return;
}
int epfd = epoll_create(1);
if(epfd < 0) {
printf("Failed to create epoll\n");
return;
}
epev.data.fd = kbfd;
epev.events = EPOLLIN;
if(epoll_ctl(epfd, EPOLL_CTL_ADD, kbfd, &epev) != 0) {
printf("Failed to configure epoll\n");
return;
}
int evn;
for(;;) {
evn = epoll_wait(epfd, &epev, 1, 0);
if(evn) {
if(evn == -1) {
printf("epoll_wait error");
return;
} else if(evn > 0) {
read(kbfd, &kbev, sizeof(struct input_event));
printf("%d\n", kbev.time.tv_sec);
}
}
}
close(epfd);
}
Ну и тем не менее он выстрелил так, что большинство базового ПО написано на нем и произошедшем от него С++.
>нашли уязвимость
Т.е. если появляется уязвимость, то это вина языка, на котором написано по?
да. юних же писали сами создатели языка и обосрались. и тогда уже были лиспы, паскаль, форт, фортран, апл, алгол, симула, пролог, смолтолк даже мл хоть и вышли примерно в одно время, они все безопасные и си в 72м это не си в 78м, когда все эти языки уже были, те уже тогда си был отсталым калом.
но си уже так сильно всё засрал, что похуй, это уже не исправить для этого надо убить все сиподобные языки, уничтожить весь софт на них, убить всех программистов, уничтожить всё железо и начать заново. хотя новые сиподобные языки норм типа шарпа
>типа шарпа
Более каловый язык ещё поискать. Это буквально синтаксическая помойка, куда тащат абсолютно бесполезный сахарок, ломая изначальную задумку.
Давно в тематике такого бреда не видал.
Какие ОС написаны на этих "безопасных" языках? Си создавался под конкретные нужды - писать ОС на языке высокого уровня, а не на ассемблере. Также удалось добиться определенной степени кроссплатформенности.
Очень много жира с экрана потекло. Очень много
на чём угодно можно писать ос. надо портировать виртуальную машину, в си конретной нет, но есть модель пдп11 и надо портировать библиотеки например стандартную библиотеку. как это сделать? на ассемблере в любом случае для любого языка.
>на чём угодно можно писать ос.
>надо портировать виртуальную машину
Мне кажется тебе стоит подтянуть знания в этой области прежде, чем писать подобные утверждения.
шиз как ты портируешь языкнейм на платформунейм? все языки построены по принципу, что они выполняются на абстрактной машине в этом и суть абстратных машин они работают с языком и код пишется для них. на жабе под жвм, на си под пдп-11 это модель во что транслируется похуй. поэтому для порта надо чтобы платформа соотвествовала этой модели.
сделать компилятор/препроцессор/постпроцессор/чтоугодно
Посмотри на котлин, он умеет компилироваться под джвм, джс и ллвм, потому что компилятор имеет разные бэкенды.
мимо
Си транслируется в машинный код конкретной машины. Что gcc, что clang, что msvc. Ни в какую pdp-11 никто ничего не транслируется, если ты не пользуешься древним си, который писали под pdp-11.
Причём под каждую платформу пишут свой компилятор си. Например, под ZX Spectrum тоже есть си, но из-за ограничений машины он там даже стандарт не поддерживает и очень урезанный по возможностям.
А джава с джв - это совсем другой мир. Это языки под виртуальные машины для которых нужна работающая ОС, которая будет выполнять код этой вм. Ни какую ОС ты не напишешь, потому что без ОС твоя жвм даже не запустится. Это сугубо прикладная программа. А си - это системный язык, на котором можно написать практически что угодно.
Линкер отрабатывает, ошибок не выкидывает.
При исполнении бинаря падает ошибка, что библиотека не найдена, хотя она в папке с бинарём лежит.
> error while loading shared libraries: libmylib.so: cannot open shared object file: No such file or directory
Кто объяснит поч так происходит? При исполнении поиск
Возможно дело в переменных окружения. Попробуй добавить директорию с библиотекой в LD_LIBRARY_PATH
Спс, разобрался, добавил локальную диру через rpath.
>советую прочитать книгу Брайана Кернигана и Денниса Ритчи «Язык программирования Си»
Мы игнорируем тот факт что ее можно прочитать только если ты уже знаешь Си потому что там задачки +- фулл бесполезные?
Как бы не хотелось согласиться, попробуем восстановить реальную ситуацию, которая имела место в то время.
>лиспы
Тормозной скрипт, для которого только-только научились писать вменяемый GC. Требует передового железа, иначе пригоден лишь как DSL для экспертных систем без строгих требований к производительности.
>паскаль
Учебный язык. За пределами учебных задач такая же байтопараша, как си.
>форт
DSL для написания встраиваемых систем. В некоторых задачах тормозит, сцука.
>фортран
Хорош только библиотеками. В остальном кривая параша, которая с самого начала разрабатывалась бессистемно. В нём даже рекурсии не было, блеать.
>апл
DSL для математических расчётов. Да ещё с GOTO.
>алгол
Алгол 60 - неюзабелен из-за call by name, который очень тяжело оптимизировать. Алгол 68 - слишком сложный, был потеснён Паскалем.
>Симула
См. Алгол 68.
>пролог
Подмножество Лиспа, расширенное недетерминизмом и тормозной унификацией. Юз кейсы ещё уже, чем у Лиспа.
>смоллтолк
Экзотичен как Симула и тормознут как Лисп.
>мл
DSL для доказательств теорем, о котором за пределами Эдинбурга вообще никто не знает. Если не ошибаюсь, в первых версиях даже мутабельных переменных не было. Тормозит как Лисп (в который, собственно говоря, и транслируется).
Если не стесняться гуглить сложные моменты, то там нет ничего такого чего нельзя было бы освоить с нуля. Ну разве что пара алгоритмов, которые можно либо скипнуть либо тоже погуглить. Задачки можно решать с отладчиком если что-то непонятно. А вообще процентов 70 книги это очень простые упражнения. Самый главный плюс КиР в том что она короткая - 150-200 страниц. Тот же Прата уже в 5 раз длинее на все 1000 страниц.
Как ты удобно всё перечислил, но забыл про Ada который как раз и разрабатывался как безопасный в отличие от паскаля.
И это бомба. Я забыл про все языки на которых писал до. Зачем, когда можно обращаться указателями на указатели и быть по настоящему счастливым, а не вот это вот все.
SML был очень годным языком, первый и единственный юзабельный со статической типизацией. У Аппеля он компилировался в машкод для мипса и спарка.
Хуесос малолетний, ты даже в глаза не видел раст.
Чмохенс, ты даже не понимаешь, что там написано. Нейросеть хуева .
Насколько тяжело войти в 2026 в низкоуровневое программирование,есть базовое знание си ,и булевой алгебры и понимание архитектуры фон Неймана но нет коммерческой практики ,и есть ли ейджизм при трудоустройстве?
27 лет
>Вкат в низкоуровневое программирование
Достаточно базового знания бурне егейн шелла https://habr.com/ru/articles/1004854/
>>672045
Си - довольно сложный язык на самом деле.
Ты по масти программист или вкатунец? Вкатунца сходу попалят, а программист на 99-й фене петики покажет с гитхабовскими звездами.
На звёзды в гитхабе никто не смотрит, их можно за копейки купить
Модификация кода известных программ, например десктоп клиента Телеграма написан на С++, некоторые создают кастомные клиенты, модифицируя разные моменты в телеграмме: пример Котатограм, некограм и тд.
Или тот же браузер Мозилла, на С++, кто-то модифицирует его код, чтобытна базе его создать свой браузер, например с целью большей приватности, например Tor или Camoufox.
Разработка VPN приложений, всяческие средства обзода блокировкой все пишутся на Си или Си++, там где нужно натнизком уровне изменять настройки сети.
Разработка Игр для Андроид. Сам код игры может быть написан на Си++, собран в бинарный файл типа lib.so, другая часть, сам интерфейс написан на Java, и через бридж JNI вызываются функции уже из бинарного файла.
И в общем и целом где нужна работа с графикой, звуком, сетью, все пишется на Си/Си++.
Примеры: PhotoShop, Gimp, VLC player и тд.
Если прям хочется, то можно создать что-то свое, конкурировать с Фотошопом условным вряд ли сможете, скорее как учебный проект, который может перерасти в хороший Опенсорс.
Черные хакеры используют Си/Си++, чтобы писать вредоносное ПО. Хотя тут имхо, любой язык подойдет, тот же питон или джаваскрипт, на любом можно сделать малварь.
Вот это основные наверное направления, ради в которых можно вписаться в изучение Си/Си++.
Я его использую, когда к примеру мне нужно продать какую-то программу, но при этом сохранить контроль над интеллектуальной собственностью.
Чтобы покупатель не нашел какого-то другого программиста, не модифицировал код, не "дал другу погонять", не перепродал.
Поэтому да отличная тема, всем советую, кто на Python пишет, но тред не про него конечно.
А по Си, ну честно сказать, тяжело на нем писать, даже те, кто на нем много лет пишет, говорят, что иногда лучше сделать на php, python, js, c# если это сайт/бот/десктоп. Но области применения по прежнему есть, выше расписал.
SML появился только в начале 80х, а современный стандарт вообще только в 90е. До него был только просто ML, на котором ничего, кроме расширений для пруверов, не писали.
>первый и единственный юзабельный со статической типизацией
В некоторых задачах сабтайпинга не хватает, а так согласен.
Ну такая себе шутейка.
Какая нахуй разница?
>микроконтроллерах и всякой дедовской хйне:
Ну как дедовской, вся индустрия это си и плюсы по-сути: промышленные роботы всякие, тачки, самолёты.
Всё что ты расписал это какая-то хуета для школьников.
перезвоним
Си - это чистое сияние разума, очищенное созерцанием истинной пустоты войда от привязанностей к паттернам и типам, от страстей исключений и суеты функциональной ереси. По мере просветления ты ощутишь, как последние оковы стандартной библиотеки спадают с тебя и ты обретаешь истинную бинарность.
Как язык работает с железом? Может ли он в целом делать это напрямую? Например с сетевой картой
ООП - это когда абсолютно бессмысленная хуйня придуманная только для того чтобы одного недопрограммиста можно было легко заменить на другого.
Вообще орал когда читал СтраусТРАПА и он такой пишет - ну Си короче сложный, я придумал си с классами чтобы проще было нахуй.
>железом
Что такое железо?
>Может ли он в целом делать это напрямую?
В мире погроммистов напрямую - это работа с регистрами устройств, у тебя, допустим, есть устройство с регистрами доступное по такому то адресу, на деле ты будешь долбиться через интерконект (или шину).
>Например с сетевой картой
Да, вот читни исходник для примера https://github.com/torvalds/linux/tree/master/drivers/net/ethernet/intel/e1000
В Си тоже можно vtbl напихать, это будет та же ООП хуйня.
 66 Кб, 1024x480
66 Кб, 1024x480Предлагаю тебе парсер мат. выражений написать на чистом Си. Особенно AST весело на Си писать. Тебе либо придется делать костыльный аналог полиморфизма, делая свою vtable, либо почувствовать себя магом и кастовать типы, молясь нигде не проебаться.
У тебя от джаваскрипта мозг вытек нахуй. Берешь и пишешь свич по int nodeType, у тебя их всего три.
Окей, у тебя есть struct Node { int num, type; Node* lhs, rhs }. Ты оформил 5 кейсов, 4 операции арифметические и взятия числа.
Потом ты подумал. Какой же калькулятор без 1) мат. констант 2) встроенных дефолтных функций вроде корней, синусов и пр.
Как выкручиваться будешь?
У меня будет, скажем, штук 20 свичей по инту вместо полиморфизма. Я добавляю новую операцию, надо поправить все свичи. Без правок программа должна упасть на тестах. Если не падает, пишу тесты, которые уронят. И так пока все не заработает.
Необходимость ООП сильно преувеличена. В процедурном коде у тебя весь алгоритм перед глазами, хоть там и простыня ифов. С ООП логика размазана по сотням визиторов в сотнях файлов, пара строк на каждый, охуеешь собирать этот пазл.
Всё правильно. Единственный случай, где нужен динамик диспатч - это если количество кейсов заранее неизвестно и они подгружаются динамически (плагины), так что схожий код в одном месте принципиально не поместить. Иначе просто пиши свитч.
ни для кого не секрет, что все мы периодически слушаем музяку. кто то по патпиське, кто то качает с зайцевнет. для тех кто качает - некоторые музыкальные коллективы/альбомы/отдельные треки звучат тише/громче остальных
предлагаю вам подумать над проблемой автогромкости (на базе карманного аудиоплеера с гулькиным хуем мощностей)
Так не рвись, говно
В православном ocaml так и пишут парсеры, но там это называется паттерн матчинг на типах.
>предлагаю вам подумать над проблемой автогромкости
Громкость в атомобиле?
Была статейка на хабре https://habr.com/ru/articles/1022424/
Это для разговоров по телефону, а не музыки. Музыка по дизайну не одной громкости, выравнивая громкость ты испортишь музыку, всё равно что слушать нейрокал вместо музыки, свинское говноедство.
>выравнивая громкость ты испортишь музыку
вот тут поподробнее пжалста
тоесть выходит по вашим словам, что ежели я к примеру слушаю элджея на волуме 20 и потом играет агата кристи на тех же волумях но тихо, то прибавив волумя я прорываю пространственно временной континуум и получаю нейрокал?
таблетки
Это значит ты не можешь слушать стримы, сначала надо закешировать треки полностью и их проанализировать целиком, и только потом слушать. Так и делают музыкальные плееры, сначала сканируют всю фонотеку, а потом только слушаешь. А в реальном времени регулировать громкость, это для разговоров по телефону, чтобы речь было нормально слышно, а музыку это всирает, тупая свинья.
>Так и делают музыкальные плееры
ни один плеер так не делает, не надо вводить анона в заблуждение
вот играет элджей с айфона по яндекспатпиське и вот агата кристи еле слышно. запускаем тот же самый тест на плеере хуй-сунь-в-чай: результат тот же. и в очередной раз я спрошу, каким образом прибавка волумев на той же тихой агате кристи всирает ее, ответь уж нам, шизло?
программирывовай, говно инцельское
Чтоб потом когда кто-то будет читать вложенные друг в друга указатели нельзя ничего было понять?
Дыа🤡 у них были телетайпы🖕🖕🔥иногда даже без звездочек✨
Так это тогда будет не переменная-указатель где хранится адрес, а разыменованный указатель.
char c;
char c;
С точки зрения компилятора одно и то же, но какая версия все-таки лучше?
Короче, разметка не дает написать.
Но смысл такой что в одном варианте звездочка рядом с типом, а в другом рядом с именем переменной.
Есть 2 стула
ХЗ как правильно, я предпочитаю рядом с переменной,
плюс возможны конструкции
char c1, * c2, c3.
А если нарисуешь рядом с char, то указателем будет только первая переменная.
Звездочка относится к идентификатору, поэтому должна быть к нему ближе.
int i, @p, @@pp;
typedef int @ip_t, @@ipp_t;
полагаю тут дело в кривой нотации
звездочка при объявлении указателя относится к типу, а не к имени указателя тип_звезда указатеельнейм
вот такой должны была быть трушная нотация, но пендосы все проебали
дело закрыто
char\ psymbol, psomeshit; //поидее должно быть так, ведь мы создаем две переменные типа указатель на char, но компилер спотыкается об оператор запятая в этом месте и нам приходится явно протягивать объявление типа дальше
char \psymbol, \psomeshit; //тут вы скажете что звездочка относится к имени переменной, но тогда конструкция \psymbol = &strarr[3] должна корректно работать, однако этого не происходит, отсюда мы и делаем вывод, что звездочка относится к типу, а не к имени переменной
ваще эт древний холивар
 234 Кб, 1000x625
234 Кб, 1000x625Мне нравилось рядом с типом ставить, это же логично. Особенно когда const используешь
const char✰ p = нельзя менять туда куда указывает p
char✰ const p = нельзя менять поинтер
но если ставить рядом с именем
const char ✰p
char const ✰p
то получается не очень, особенно вторая строчка, как по мне.
Но олды-перды ''так принято,, писать ✰ рядом с именем. Потому делаю так же.
Да кто спорит, просто сказал, как это работает и можно обдристаться написав звезду со стороны типа.
Даже не сторогы типа, а сделав дефайн на тип укащателя вместо тайпдефа.
 28 Кб, 758x346
28 Кб, 758x346Он же никак не связан с количеством переменных параметров.
Спросил АИ, он сначала сказал что этот параметр должен быть равен количеству переменных параметров, но когда я спросил что он должен значит всегда быть int быстро пошел на попятную лол.
 43 Кб, 838x369
43 Кб, 838x369 77 Кб, 887x727
77 Кб, 887x727Что мешает однозначно писать char c1; char c2; char c3; ?
Всегда угорал с этих "оптимизаций", шизоидные скобочки от КР туда же. Зачем жертвовать читабельностью кода? Чтобы места на дискетке хватило или монитор 13 дюймов как у пра-дидов?
Бл, звездочки в макабе пролюбливаются.
Да, ты прав. Как тогда написать char* const p, ставя звёздочку около p?
int ✰f(double);
это обычная функция, возвращающая указатель на инт, т.е. звездочка как бы относится к инт возвращаемому значению
Вот что я не понимаю, почему определение функции signal идет без указания возвращаемого значения пусть даже она и возвращает указатель
Лиспоед, где решения на твоём языке? Где операционки, компиляторы, базы? Цыгане украли? Враги сделать помешали?
Чем меньше строк, тем больше видно на екране.
Ты себе монитор побольше купи чтобы видеть больше 1 поста.
Я ответил уже, что делать так не надо.
 22 Кб, 1311x357
22 Кб, 1311x357Разве можно при описании структуры сразу ей присвоить указатель.
Тут все верно. Просто у структуры нет имени. И создаются(объявляются) два указателя.
Всё правильно.
Во время компиляции создаются два объекта структуры на которые ссылаются указатели p1 и p2.
Так делать можно, но не нужно. Велика вероятность, что прилетит по ебалу лопатой, если работаешь в команде.
Нормискот не способен поня, что struct {...} обозначает тип ровно так же, как int.
 29 Кб, 803x317
29 Кб, 803x317>Разве можно при описании структуры сразу ей присвоить указатель.
Нельзя. Если не ошибаюсь, тут мы объявляем переменную p. Тип у этой переменной - указатель. Указатель это просто 8 байт адрес, ему в общем-то насрать что там будет, это просто адрес. Но для компилятора мы говорим что это указатель именно на структуру struct { int val; }
То есть
struct { int val } ⚹p;
Всё равно что
int ⚹p
Ты обьявляешь указатель. Инициализировать ты его можешь адресом, как там и показано &kate
Это всё чисто для компилятора. Так то можно сделать и
void ⚹p
И уже ему присваивать всё что угодно. Я так делаю, например когда нужно произвольные данные передать в обработчик
 63 Кб, 736x736
63 Кб, 736x736>Нельзя.
>можна
мдамс
вся хуйня в том, што поинтеры на структуры в таком виде нужны лишь для дробности типоразмеров
например поинтер на структуру в котором массив из 7 чаров будет 7байт типоразмера (сдвиг по адресу на 7 байт для самых маленьких)
практическое применение такой хуйни - за шаг перебрасывать нужное количество байт из одной хуеты в другую, например копирование строк заданного размера, чтение и замена байтпоследовательностей в конвейерных хуйнях по типу буса, етц
>>703492
у тебя цыгане интернет украли. в соседнем треде все разжевано.
пикчу штоли приклеить, а то какой то скучный тредик
как бы вы там не старались создавать супербыстрые алгоритмы, изучать биг оу и прочую хуйню, у вас абсолютно всегда останутся ограничения по железу. так уж вышло, что типикал шина данных интовая и железо попросту физически не может сделать то, что вы хотите, чтобы оно сделало. вы хотите за 1 шаг цикла пробросить неровный размер байт, да еще и что то длинное? круто классно. вас наверняка похвалит ментор, или все скажут вау на ваше решение по литкоду. но при этом шина данных хлопнет не 1 раз, а проц еще будет туда сюда гонять данные отрезая лишний байт, который вы не хотели получать. очень мало действий по коду и очень много по железу. крч, не забивайте себе голову, пишите по классике, не экономьте память, юзайте интовые размеры и все будет гуд.
Современный C++ - коллективная разработка. Датчанин там чисто затравку сделал.
>Мне нейронка говорит что эти указатели будут указывать на мусор, а не на структуры, потому что нет переменной структуры и значит память не выделена под нее.
Или ты не так понял, или нейронка троллит тебя.
Сначала объявляется неименнованный тип структуры, а потом в этом же статементе инициализируются два указателя с выделением памяти для двух структур во время конпеляции. В рантайме ты можешь работать с этими двумя указателями и они будут указывать на структуры, но там будет мусор т.к. сами структуры не инициализированы никакими значениями.
Не слушай этого волка. Выделяются два указателя, два слова. В них мусор. Ты можешь вместо мусора записать адрес структуры. Но структуры еще нет, ее надо выделить.
Это высокоуровневая макака, макака не понимает код, она пишет магические заклинания. Поэтому они так любят нейросети и считают, что нейросети заменят человека, нейросеть как магический джинн, ты ему пук, тот в ответ среньк.
определитесь уже происходит аллокация с выравниванием по структуре или не происходит? всем похуй на мусор
не понял, сам-то указатель займет 7 байт вместо 8 если структура на которую он указывает будет 7 байт?
 317 Кб, 1054x1456
317 Кб, 1054x1456экземпляры не аллоцируются
>будут ли алоцированы экземпляры
Нахуя, если только указатели данного типа объявлены. Их и имеешь в итоге.
Если напишешь
struct
{
int age;
int name[20];
} ⚹p1, ⚹p2, t1, t2;
то будут тебе экземпляры t1 и t2, при этом p1==p2==NULL.
не забудьте впендюрить звезду в шапку переката
test
test
test
 429 Кб, 1524x1754
429 Кб, 1524x1754теперь я чот не понял, а схуяли между адресами интов 1 байт, если инты 4байтные? чота туплю наверн, абиснити
надо было кастануть в ансигнед лонг лонг перед арифметикой
вот если я из адреса вычитаю инт - тогда выходит я из адреса вычитаю интчислосдвигов типоразмера данного адреса
для примера если это поинтер на инт - интчислораз по 4 байта вверх (влево) кому как удобнее
а если я из адреса вычитаю адрес? приходится поебаться почему не ансигнед лонг инт число сдвигов типаоразмера, например? тогда бы ренж был в нуле наверное? ну типа возми любой адрес в памяти и сдвинь квадрилионы раз влево - упрешься в нулл. разве нет? схуяли ОДИН?????
загадка жаки фрески прям
>ну типа возми любой адрес в памяти и сдвинь квадрилионы раз влево - упрешься в нулл
Или в 738, или в 921324, а может вообще на месте останешься.
>схуяли между адресами интов 1 байт
anyptr + 1 == (unsigned long)anyptr + sizeof(any)
Попробуй сначала адреса привести к типу void "две звезды", а уже потом делать арифметику с вычитанием и прочим.
Устанавливаешь IDE и двумя кликами открываешь дебагер, смотришь память, читаешь ассемблер.
в треде спрошу
>Устанавливаешь приложение
И тут "программист" уже слился, слишком много требуешь от будущего короля Си.
Зачем себе жизнь усложнять ненужными мелочами? Цель программирования это писать программы для людей. Зачем тратить время на ёблю с флагами и прочую чушь? Это не влияет на твой скилл писать программы.
Ты юзаешь ОС, юзаешь терминал, юзаешь компилятор, а не программируешь на голом железе, но тут внезапно ЭТО ДРУГОЕ, а вот ИДЕ это не тру и плохо-плохо.
можно еще программировать дроны и прочую технику, а также какую-нибудь симуляцию накодировать
не все любят когда их водят за ручку
да и вот давеча мне надо было пробросить байтослоп прикинувшись будто бы я кидаю объект класса из обжектив си в какаву, уверен и дэ е слилась бы и посоветовал просто выучить обжектив си
Тогда и не программируй, дворнику куда проще, там тебе и место. Зачем лезть туда где тебе не место и гадить? В любой работе требуется тщательность, даже ботинки полировать надо как следует, а не как попало "зачем себе усложнять жизнь". Неусложнятель значит тунеядец, таких надо пиздить и гнать нахуй.
И если что, это касается любой профессии, и начальников, если начальник тоже неусложнятель у которого всегда виноваты подчиненные, такого надо точно так же пиздить и гнать нахуй. Вы все одинаковое бесполезное говно которое только гадит. Ни одна ленивая погань не делает и не сделает никаких полезных программ для людей, только говно наносящее людям вред чтобы на этом нажиться самому.
да не пизди
я думаю считается что тебе незачем вычитать из адреса просто число - ты просто получишь какой-то рандомный или мусорный адрес, а вот когда вычитаешь размер типа то можешь двигаться массиву
Указвтель+число помогает двигаться по массиву. На целое число элементов. Укащатель-указатель показывает пройденное расстояние. В элементах. Надо было сделать хуже?
![17790041313330171672[1].png](https://2ch.life//pr/src/3619616/17790043589240152832.png) 49 Кб, 181x179
49 Кб, 181x179
 563 Кб, 1280x720
563 Кб, 1280x720
вебмакака
 2,1 Мб, 1478x1310
2,1 Мб, 1478x1310вот сегфолт
>проц еще будет туда сюда гонять данные отрезая лишний байт
хм но в структурах для решения проблемы data misaligment по умолчанию вставляются паддинги, а запрещаешь принудительное выравнивание ты для того чтобы в бинарный протокол например упаковать, ну и надо делать упаковку/распаковку, и обрабатывать далее уже с выровненными данными
или речь о том что якобы в архитектуре x86 работа с "короткими" интами short int (16 бит) неэффективна тк к инструциям обрабатывающим такие числа приходится компилеру добавлять специальный префикс 0x66 и инструкция становится длиннее на байт? ну дык это в более свежих поколениях процов пофиксили наебашив сверху оптимизаций..
речь вцелом про неэффективность эффективных решений
вот к примеру в бородатые времена придумали б-три как эффективную модель данных с быстрым поиском, в текущих реалиях она неэффективна и простой массив (или хэштейбл) сработает куда быстрее из за аппаратных особенностей
поэтму фраза не забивай себе голову хуйней и пиши по классике в интах емко и красноречиво подитоживает все будущие диалоги на эту тему, тут нехуй обсуждать
>б-три как эффективную модель данных с быстрым поиском, в текущих реалиях она неэффективна и простой массив (или хэштейбл) сработает куда быстрее
конечно нож острее кувалды
б-три для дисковых накопителей оптимизирован, его узлы в страничку памяти помещаются, для индексов реляционных субд это король
хештейблы для того что в оперативу умещается, их любят in-memory dm
>другие архитектуры
тык в той же arm тоже есть свой simd движок, и работа с короткими интами и char еще более оптимизирована по сравнению с x86
хуй знает с чего ты решил что отрезать лишний байт это инт -> шорт инт
как вообще в твоей башке сложилась такая математика? хотя похуй я не хочу этого знать, это какой то бредик
кэш-линии современного x64 проца размером 512 бит, с меньшими данными они не умеют работать
да структуры неэффективно лежат в памяти, чо сказать то хотел?
давай помогу осознать буквы которые ты прочитал и на которые ответил
тебе прилетело 8 байт данных, программист заказывал 7.
твои действия как проца?
>>707867
классическая шина данных 32 битной машины например
>>707869
при чем тут шорты и чары сука мразь бесишь
>классическая шина данных 32 битной машины
тык че за "шина данных", о чем речь?
nvme ssd через pcie 5.0, причем контроллер прямо в проце
озу тоже напрямую в проц, шина памяти, контроллер в проце, это прям физика, проводочки идущие в проц и часть кристалла на проце отвечающая за io
шина по которой приходят данные на процык
проводочки по которым текут электрончики и щекотят регистры
может тут я неточен в терминах и это шина памяти, тут сорян
убшиз ета ти?
>оперативно поработай с пзу теперь, опитимизатор
да пожалуйста, давай
на каком уровне хочешь говорить?
физическом уровне? дык там pcie 5.0, многоканальная передача хоть и протокол последовательный, те же 512 бит кеш линии разделятся на 4 канала и прилетят за такт по 128 бит на канал
ос и дб могут работать с минимальным размером данных это размер дисковой страницы, в винде 4кб, итого за 64 такта прилетает страничка из диска в озу
естественно через dma те выч блоки проца не задействованы, задействовано только io: контроллер pcie, контроллер памяти, внутренняя шина
>приходят данные на процык
тык данные на выч блоки цпу приходят через кеши, в кешах минимальный размер это кеш линия, в совр проце будет 512 бит
пердоль давай свою оптимизированную б-три и долби диск, нехуй в озу грузить ты же отказался от этой идеи и скозал што б-три пзу бейзед алгоритм
и што же я вижу
грузишь в озу свою хуйню академическую из пердольного века
массив в кеш линиях в сотни раз быстрее перебрать чем твоей хуетой заниматься
перечитай пост на который ответил
все иди нахуй
алсо алгоритм отрезания лишнего байта не описал
дважды нахуй
решение на основе б-три оптимизированное под дисковое хранение более универсальное получается, и поэтому оно до сих пор основа для индексов реляционных субд, да, для oltp базы данных ты можешь добавить столько озу чтобы весь кеш дисковой структуры лежал в озу, но для хранилищ данных такое уже может не прокатить
хеши рулят в in-memory db
> возникла гипотеза что поинтеры смотрять в нулл
> гипотеза
> явно описанная в документации
> что глобальные переменные инициализируются нулем
Объясните нюфагу, почему когда я использую malloc, и компилирую через msvc, то независимо от того, сколько байтов я указал в аргументе, я все равно могу поместить в память нихуя не столько? Например, даже если char* c = malloc(1), то я туда могу засунуть строку не из одного, а аж из 80 символов? При том что _msize возвращает именно то значение, которое я указал в качеству аргумента malloc.
Приложению выдают целую страницу и внутри него она что хочет, то воротит.
А вот если выйти за пределы, то уже смотритель памяти (не помню как называется) выдаст по ебалу сегфолт.
А как тогда вообще пользоваться этим вашим мемори алокейшном? Я сейчас даже попробовал прогнать
int i;
int* a = malloc(1);
for (i = 0; i < 6; i++) a = i;
И оно реально полностью записало мне в память числа от 0 до 9, хотя я выделил даже меньше памяти, чем на одно число нужно, а for (i = 0; i < 10; i++) printf("%i ", a) благополучно мне их выводит, даже если я сразу после a выделил другую область памяти и что-то туда записал, хотя по-идее они должны в памяти по соседству находиться. Это в компиляторе такая защита от индусов сделана или, что вероятнее, я не понимаю, как мемори аллокейшн работет? Если второе, то что именно я не понимаю?
Сука, ебаная разметка.
int j;
int* a = malloc(10);
for (j = 0; j < 10; j++) a[j] = j;
и
for (j = 0; j < 10; j++) printf("%i ", a[j]);
Написали же UB. Хоть вселенная всхлопнется - тебе ничего не гарантировали.
>я написал программу записывающую числа в память
>И ОНИ СУКА ЗАПИСАЛИСЬ! не понимаю, что за хуйня?
Это называется программирование, как пишешь, так и работает.
Если же не можешь программировать, для таких есть нейросети, ты ей говоришь одно, а она определяет что ты дебил и делает совсем другое. Ура, как удобно, я несу хуйню, а система исправляет как надо.
Да, это очень удобно, только без тебя, ведь если ты тупее системы, значит ты не нужен.
>я несу хуйню, а система исправляет как надо
Так ты буквально только работу компилятора в моем примере описал
Ты числа записал? Записал.
Числа записались? Записались.
Что не так сделал компилятор? Ты дебил? Не нравится когда программа работает как ты написал, то есть тебе не нравится собственная тупость? Так при чем тут компилятор? К психиатру сходи, дебил.
Лол, нет. Компилятор C и плюсов уверен, что программист царь и бог и если хочет отстрелить себе ногу значит он так и задумал. Есть конечно предупреждения, но это совсем от долбоебов.
А чтобы дерьмо за тобой подтирали - это к статическим анализаторам кода.
Ладно, ты прав, какую-то я хуйню написал, если честно.
тык в беркли дб были другие хэши чем в современных in-memory db, те структуры данных наоборот под дефицит озу были заточены
>>707980
Успокойся шизофреник. Конпилятар тут не при чем. У тебя память вообще ОС выделяет, а не компилятор. У библиотеки просто есть функция, условно "обеспечить столько то памяти". Вот она тебе и обеспечила. А то что её реально выделилось больше - иди и билу гейтсу ной. Алокация памяти это вообще не часть языка С. Это просто прослойка над сисколами.
не всегда можешь
ты просишь у оси столько то байт
ось грит ну типа ок вот адрес начала блока куда можешь насрать
сколько там реально свободной памяти знает только ось, но если дала адрес значит точно не меньше запрошенного объема
если н дала значит нет цельного фрагмента искомого объема
Збс синтаксис. Ты просто не шаришь.
>звездочка при объявлении указателя относится к типу, а не к имени указателя
Почему тогда int* a, b создает не два указателя, а один указатель и одну переменную?
Не совсем так. К твоей программе прилипает c-heap-manager. При запуске программы он у ОС просит большой кусок памяти. Дальше он эту память нарезает на блоки и хранит список свободных блоков. Когда ты просишь память, ты не всегда обращаешься к ОС, ты обращаешься к менеджеру, и он тебе дает указатель на блок, способный вместить как минимум сколько ты запросил. Когда память освобождаешь, то так же освобождается блок и он возвращается в список доступных блоков.
Вот если блоков нет, только тогда уже программа идет на поклон к ОС.
Почему бы и нет. Поржем вместе над пасквилянтами ))).
for (int i = 0; i < rows; i++) {
m = malloc(cols sizeof(m));
}
а как здесь указатель на указатель m стал массивом?
Да там и так понятно где звездочки
Наоборот, и то будут нюанцы
> телеграм бота, бэкенд вебсайту, десктопное приложение вы на нем писать не будете.
Почему не буду? Буду. Я же контрол-фрик.
Доброе утро! Неужели это для тебя открытие. Это же самое первое о чём пишут в си. Строго говоря в си нет "массивов" вообще. Имеется ввиду что нет такого же вот обьекта как в Паскале, там, которому можно было диапазон задать, например. Квадратные скобочки в си это грубо говоря шорткат, то есть i[N] это тоже самое что *(i+N) . Различия всё-таки есть. Например sizeof скобочек выдаёт именно длину массива, а sizeof указателя выдаст 8. То есть что-то типо массива есть, но это не совсем массив.
 33 Кб, 894x457
33 Кб, 894x457>Например sizeof скобочек выдаёт именно длину массива, а sizeof указателя выдаст 8. То есть что-то типо массива есть, но это не совсем массив.
Только следует помнить, что sizeof скобочек будет работать только в скоупа и сабскоупах, где массив определен. Передай указатель на массив в функцию, и он забудет размер.
>массивы существуют
Назвать этот огрызок от указателя "массивом" не совсем правильно.
Массивы существуют только условно. Но по факту это скорее указатель с дополнительными свойствами.
Начнём с того что массивы можно присваивать. А то что то в С называют "массивом" присвоить нельзя:
int *a;
int c[3];
int b[3];
b = c //syntax error
Зато можно
a = b
И теперь, ВНЕЗАПНО мы можем индексировать a:
a[2];
Это по твоему нормально называть массивном? Массивы в Pascal или других высокоуровневых языках по твоему так себя ведут? Он конечно назван как array, но фактически это не то что подразумевают под массивом.
массив это массив не зависимо от того что ты там себе нафантазировал
твои выпады напрямую связаны с непониманием лаконичности и компактности си. ты не туда воюешь. си это язык велосипедов. хочешь присваивать массивы - пиши свой хук для присваивания. хочешь какие то другие массивы - пиши свои массивы. это си, детка, туда ли ты забрел?

В си нет массивов, это указатели, как нет математических чисел, это ячейки памяти определенного размера, и тем более в си нет строк. Си обманчив тем, что выглядит как язык высокого уровня, хотя на самом деле си это ассемблер. Мимо-макаки этого не понимают и ищут свои абстракции которых в си нет. Си это машинный язык, а не скриптовый. Нельзя писать на машинном языке не представляя как работает машина, то есть как твой код работает на машине.
Самый простой пример. Ты объявляешь переменную, это имя и привязанное к нему значение. В си ты должен понимать, что это лишь блок памяти, знать размер этих данных в байтах, а так же место в котором они находятся, стек или куча. Это не какие-то лишние знания, а минимальная необходимость без которой нельзя ничего программировать, получается гадание наугад, бред, нелепость как не зная арифметики заниматься тригонометрией, так не бывает.
Застрелись нахуй и больше сюда не сри этим говном, дебил ебаный.
Си у него ассемблером стал, блять. Откуда вы лезет?
vararg в сях это костыль по большей части. В теории ты можешь вместо int count поставить любой аргумент, при вызове подавать ему любые значения и как-нибудь угадывать, сколько пришло аргументов. На практике ты либо идёшь по простому и понятному шаблону, либо ловишь баги и леща от других прогеров, которым придётся копаться в нешаблонном коде.
ИМХО в сях лучше наплодить похожих функций с разными наборами аргументов, в 95% случаев это прокатывает. А vararg оставить всяким питонам и языкам с полноценной рефлексией

Алгоритмы и сруктуры данных, многопоточка, как работает mmu, как работает шедулер, хуй86 архитектура (можно arm), основы криптографии, tcp/ip, устройство efs/ntfs, чуток баз данных
Эмбеддед разработчиками, программистами, инженерами электроники, учеными. В общем Си у них это не основная специальность. Часто они совмещают его с другой компетенцией или языком. Чистых СИ вакансий почти нет
>Эмбеддед разработчиками
Много ли там вакансий, НЕ связанных с разработкой чего-либо используемого в междоусобицах восточных славян? (религия не позволяет)
привет, для чисти изучение для себя, а про работы даже не знаю, час хочу системный прогграмирвние и системный админстарция, то есть чисти энтузиазм
даже хз, не чекул, вроде как и все снг мало как я знаю
Электрика/электроника, схемотехника, микроконтроллеры, SPI/UART, парочка ассемблеров. Часто радиофизика, обработка сигналов, сетевые протоколы вплоть до побитового разбора пакетов/кадров.
1. Введение в тему из любого источника: хоть сайты, хоть ютуб, хоть книги (для начинающих)
2. Тренировка основ простыми задачами на leetcode/codeforces
3. Хитрости и приёмы именно Си: книга Кернигана и Ритчи. Пет-проекты (гугли темы для проектов начинающих программистов, бери что по силам)
3.5 Для системного программирования - Таненбаум, Реймонд, исходники и комментарии FreeBSD
P.S. Системное администрирование это абсолютно другое направление. Там программировать толком не нужно, максимум скриптовать
>3.5 Для системного программирования - Таненбаум
Вот из тех кто его советует, хоть раз открывал его? Это же тупое говно на уровне научпопа. Есть намного лучше курсы/книги: nan2tetris, книга с кометой, xinu project, mmurtl...
>3. Хитрости и приёмы именно Си: книга Кернигана и Ритчи.
Я бы тебе с ноги уебал, если бы увидел что ты пишешь как они. Effective C берешь и читаешь, а не изучаешь окаменелости.
Не окаменелость а фундамент.
В твоём проекте буду писать по твоим стилям/гайдам. В своих буду устраивать филиал IOCCC, и никакой двачер мне не указ. K&R стоит читать, чтобы знать на что Си вообще способен, а уже потом перебирать, что подходит конкретному проекту, а что нет.
 21 Кб, 540x568
21 Кб, 540x568>Таненбаум
Общеизвестный факт, ни один из посоветовавших книги Таненбаума сами их не читал.
Ведь если бы он попытался их прочитать, ему бы стало стыдно советовать это графоманское дерьмо ни о чём
В его времена не было кэшей. Математический надроч там неплохой, но вешь в себе.
 10 Кб, 498x279
10 Кб, 498x279Быку - кнут. А кто по натуре своей свободу любит, тому и за забором свобода.
Думаю если ты школьник с кучей свободного времени, можно порешать. Но если студент и старше, то это сродни учить геометрию по Началам Евклида, когда тебе нужно учить анализ и линейку.
Для cs-чепушков.
Чем?
А зря, книжка норм обзор современного Си с проблемами и с тулами.
Можешь попробовать, но он на своем выдуманном ассемблере все разбирает. Если осилишь с упражнениями, то очень круто, но я бы не советовал, если ты не умеешь программировать уже хорошо довольно.
>но он на своем выдуманном ассемблере все разбирает
Классно же. Можно с умным видом нести бред и всё равно никто ничего не поймёт.
обычная переменная:
-имеет какой-то адрес в в памяти
-имеет какой-то размер (например 4 байта для инт)
-по этому адресу лежат данные - содержание переменной
указатель:
-имеет какой-то адрес
-имеет размер ( 8 байт обычно)
-по этому адресу лежат данные - содержание указателя
Разница лишь в том что содержание указателя - это адрес другой переменной.
Но что мешает мне в обычную переменную тоже положить адрес?
Адрес - это всего лишь число.
Ты можешь сходить по любому адресу, если захочешь. Но адреса у компилятора и ОС определённые, поэтому промажешь. А раньше указатель состоял из двух адресов - смещения и сегмента. Формат и размер указателя - вещь платформозависимая, и делать с ней что-то стоит с некоторой оглядкой хотя бы на чистоту и корректность кода.
 368 Кб, 850x1234
368 Кб, 850x1234>а чем обычная переменная отличается от указателя?
Ничем. Указатель - это переменная.
>Но что мешает мне в обычную переменную тоже положить адрес?
Статическая типизация, блядь, тебе мешает. Вы что траллите? Вы читали вообще синтаксис перед тем как что-то писать на С? Представь себе, и int, и char - это всё числа. Но ты не сможешь в char положить int! Ты наверное можешь сказать, но в int то char я могу положить. НЕ МОЖЕШЬ! У тебя просто происходит неявное преобразование char в int. В обратную сторону нужно явно прописать преобразование, типо
int a;
char b;
b = (char)a;
То же самое и с адресами. Ты МОЖЕШЬ преобразовать указатель в long int.
long long a;
void ⚹b;
a = (long long)b;
Например ты можешь распечатать адрес через printf.
Более того, в низкоуровневом программировнии это вполне обычная штука, только в обратную сторону, long long переводить в указатель, обычный пример memory mapped io
#define UART0_BASE 0x4000C000
volatile long long ⚹uart = (volatile long long ⚹)UART0_BASE;
> Но ты не сможешь в char положить int!
нет никаких типов на самом дела, есть байты с нулями и единицами.
тип - это то как ты выбираешь интерпретировать данные.
ничто не мешает получить адрес и потом хранить его как инт, например

Есть питон, там есть переменные инты.
Покажи как работаешь с памятью.
Тебе же
>ничто не мешает


>есть байты с нулями и единицами.
Эти нули и единицы с тобой в одной комнате, жид? Всем славяно-ариям известно, что нет никаких "битов", есть устойчивые состояния асинхронного RS-триггера, которые характеризуются электрическими напряжениями на выводах. "Биты" это вам дуракам в школе мозги пудрят. Если человек использует такие слова как "бит" или "указатель", и уж тем более "метод класса" - то это всё, с ним всё потеряно, он глубочайшие промытый идиот, который пользуется жидовскими ТЕР-Минами (террориистическими минами) для веб-макак.
Да, это правда. Понимаю, после 10 лет в вебмакакинге это шокирует.
Надо заметить, что это не только относится к компьютерным наукам, но и вообще к самой реальности. Все что ты воспринимаешь это интерпретация.
>>715165
Бит это прежде всего абстрактная единица информации, не привязанная к конкретной реализации.
Орнул с этого руса. В чем он неправ? Прав во всём
 6 Кб, 230x173
6 Кб, 230x173>Понимаю, после 10 лет в вебмакакинге это шокирует
Ты провёл 10 лет в вебе, не понимая модель памяти? Допустим.
>Бит это прежде всего абстрактная единица информации
А "переменная" это какая единица? Абстрактная или конкретная? А электрическое напряжение что, конкретное? Почему тогда электрическое напряжение это буквально разница между двумя числами - потенциалами поля в точках. А потенциал поля это конкретная величина? А потенциальная энергия? Если энергия такая конкретная то почему мы её пощупать не можем а просто циферки считаем?
>>715169
>Что тебе не понятно в хранении информации?
А тебе что непонятно? Не я же про "байты" рассуждать начал. Стало быть тебе видимо что-то непонятно в этой теме, раз пришел в тред си о байтах вопрошать. Что-то не видел синтаксисе си тип "байт". Есть int, есть char, но байтов никаких нет.
Тут либо реально столяров обитает, либо какой-то шиз пытается копировать его стиль общения
>ы провёл 10 лет в вебе, не понимая модель памяти?
Хуль ты очком крутишь, макака? Совсем от петона мозги высохли?
>А "переменная" это какая единица? Абстрактная или конкретная?
Переменная это не единица.
Тебе бы логику подтянуть.
>Что-то не видел синтаксисе си тип "байт"
Ну ещё бы, куда тебе знать что можно получить значение по указателю на байт.
А ботохуетач будет работать без js? Для Столярова жопаскрипт в браузере не по понятиям
На Ютуб же он ролики выкладывает. Это тебе нельзя js, а ему можно.
>Хуль ты очком крутишь, макака? Совсем от петона мозги высохли?
Никогда не умел программировать на python. А язык весьма неплохой между прочим. На нём можно заняться чем-то интеллектуальным, а не копипастить код по байтам.
>Переменная это не единица. Тебе бы логику подтянуть.
А утверждение "переменная не единица" это не логика.
>указателю на байт
А мог бы ты показать этот твой "указатель на байт"? Что-то ни в одной книге такого нет.
а char?
а чар может быть любым, но вот де-факто это 1 байт, а послезавтра это будет что-то 3-байтовое, и наступит каюк всему си
>А мог бы ты показать этот твой "указатель на байт"? Что-то ни в одной книге такого нет.
чел, любой указатель указывает на байт (хранит адрес байта)
>А может у тебя байт 7 бит?
Байт это сегда 8 бит по определению.
Другое дело что ты можешь один бит использовать для хранения знака, например, а 7 других для числа от 0 до 127
Любой указатель и есть байт. Получается никакого указателя нет, есть только байты. Никакого си тоже нет, есть только байты. Которые всегда 8 бит, даже на PDP-10 для которого между прочим си и создан 🤡
>Что блядь?
Ну, если никаких переменных и чисел не существует, а есть только "байты" (или как там это себе в бошке нафантазировал), то стало быть и значение адреса это тоже байты, а стало быть и никаких указателей нет, есть только байты. Ну и функции кстати тоже нет, есть только jmp, ret
 6 Кб, 230x173
6 Кб, 230x173А да? Да ну нахуй. А я и не заметил, что тот анон с самого начала несёт хуйню (см. >>715077 ), либо жиденько троллит.
Тред по С. В си типизация статическая. Тут есть типы переменных, прЕкинь!1 И переменную разных типов нельзя присвоить друг другу. Это тебе не java. В некоторых случаях выполняется неявное преобразование, если оно слишком очевидно, например char a = 2, ну очевидно что оно и в int должно быть 2, смысла отдельно попиисывать это преобразования нет, но в коде его таки прописывают часто, просто для информации, чтобы человек понимал что во что превратилось. А вот 1488 int в char это что? Ну можем взять лишнюю часть, то есть 1488 % 256 = 208. А почему так? Почему не 256? По стандарту C результат такого преобразования implementation-defined. То есть язык си не требует единственного варианта поведения - это уже реализация компилятора решает что делать. Поэтому надо явно написать "вот да, я знаю что делаю, я преобразую char в int". А зачем этот шиз выдал что "всё есть байты" - в душе не ебу. Походу дошколёнок пердежа столрярова надышался на его сайте, открыл для себя умное слово "байт" и носится везде с ним как с открытием. Тред про язык С, а вот ему надо благую весть всем рассказать, что оказывается вся память из байтов состоит. Когда он для себя RS-триггеры из курса автоматики откроет, будет носиться рассказывать всес что битов нет. Вот такая-с аудитория у С. Надо внатуре было нормальные языки учить.
Байты хранят числа.
Значение адресов это тоже числа.
Когда я говорю что нет типов, речь о том что типы используются компилятором для интерпретации данных и определения количества байтов с которых будет извлекаться эти данные.
Но не что мне не мешает получить адрес байта объекта и пройти по каждому отдельному байту используя указатель на char, достать число из байта и интерпретировать его как мне нужно.
>>715559
Ты просто не дорос до уровня понимания.
Ты даже не понял что за этим стоит философская идея - вся информация с которой мы работаем это интерпретация.
Для тебя типы это что-то волшебное и железобетонное, а не технический способ интерпретировать числа из набора байтов.
> И переменную разных типов нельзя присвоить друг другу
Воед знаешь?
Короче, ты спалился когда спросил что такое указатель на байт. То есть ты не понимаешь что указатель именно на один байт и указывает.
Видимо сидишь через нейронку строчишь хуйню нихуя не соображая.
не наступит, вайдчары давно есть
>Байты хранят числа.
>Значение адресов это тоже числа.
Ахахах. Машинные инструкции, внезапно, тоже числа. Еблан. Ты перед тем как своими охуительными "знаниями" выёбываться хотя бы почитал про архитектуру фона Неймана. Ебать ты дебил, вроде ты пытаешься умничать, а нихуя не получается.
 25 Кб, 364x500
25 Кб, 364x500>> И переменную разных типов нельзя присвоить друг другу
>Воед знаешь?
Ахахах дебил, переменной void не существует в СИ. Есть только указатель на void. И его ВНЕЗАПНО нельзя присвоить ничему кроме *void. Что с ебалом. Ахахах дура, ебать.
Не плачь, дите.
Ну обосрался, ну значит обосрался. Нахуй жопой вилять?
Главное запомни что указатель указывает на байт т.е. хранит адрес байта.
>>715741
>переменной void не существует в СИ. Есть только указатель на void.
Указатель это тоже внезапно переменная.
> И его ВНЕЗАПНО нельзя присвоить ничему кроме *void.
Да что ты говоришь? Серьезно?
Естественно указатель на воид МОЖЕТ указывать на адрес абсолютно любого типа.
Это собственно и есть его главная функция.
В общем, я понял что ты вообще нихуя не соображаешь, пройди просто нахуй.
>Ну обосрался, ну значит обосрался.
>Нахуй жопой вилять?
Это ты сам с собой говоришь, я так понял. Я твоей мамке про это раскажу она тебя ведь к детскому психологу отправит.
мамку твою
https://justine.lol/blinkenlights/
Blinkenlights — это отладчик командной строки, ориентированный на визуализацию того, как программное обеспечение изменяет память. Он способен эмулировать статически скомпилированные программы i8086 и x86_64-pc-linux-gnu на платформах Linux, Mac, Windows, FreeBSD, NetBSD и OpenBSD.

Тебе надо исходить из того, что тебе обеспечено и гарантируется что всё будет ОК - только если ты будешь использовать и записывать память в пределах запрошенного аллоцированного кол-ва байт, начиная с возвращенного malloc-ом адреса.
Что язык С, что С++ - все они никак не ограждают тебя от выстрела в ногу. В смысле да - ты можешь попытаться читать или записывать память за пределами выделенного диапазона адресов. Но что из этого выйдет - хуй знает. Может прокатит, а может и нет. Причём самым непредсказуемым образом. Это так называемые баги из разряда buffer overrun.
В общем, нормальные программисты так не поступают. А вот хакеры - вполне могут поступить. Но они часто знают, что делают.
Что касается хакеров. Есть такой приём переполнения буфера. Это когда массив байтов аллоцируется на стеке. Хакер в целях взлома системы добивается, чтобы его данные оказались бы записаны в такой массив-буфер, причём произошла бы перезапись за пределами верхней границы массива. И знаешь к чему это подчас приводит? Я тебе расскажу.
Дело в том, что в x86 компьютерах, все стеки растут от верхних адресов памяти, к нижним. Т.е. когда ты вызываешь какую-то функцию, в стеке для неё создается stack frame, в котором располагаются все локальные переменные этой функции, в т.ч. наш массив. И при этом, этот stack frame (далее - стековый кадр) оказывается расположен по более низкому адресу, чем стековый кадр функции, что его вызвала. А массив в нашем кадре расположен в памяти от более низких адресов к более высоким. Это приводит к тому, что перезапись за границы массива позволяет записать память в стеке не только нашего стекового кадра, но и кадр функции, что его вызвала!
А ещё, когда процессор кидает данные в стек, они тоже кидаются сначала с более высоких адресов к более низким.
И вот когда вызывается функция, для вызываемой функции создаётся стековый кадр, где самым первым делом (по самому высокому адресу этого кадра) в стек кидается т.н. адрес возврата из функции. Это тот адрес, по которому должно продолжиться выполнение программы, когда наша вызываемая функция завершится, и должен будет произойти возврат к вызвавшей её родительской функции.
Но! Хакеру важно, чтобы он захватил контроль за ходом исполнения нашей программы. Для этого, он с помощью перезаписи буфера (сиречь массива в стеке), он добивается перезаписи адреса возврата из функции (который лежит ВЫШЕ, чем сам массив) своим собственным адресом, который ему нужен.
Т.е. ты понимаешь, к чему это приводит? Что программа уже делает то, что ей хакер указал. И это показывает, насколько надо быть внимательным при написании софта на Си и Си++, который будет взаимодействовать с чужими данными. Надо всё проверять!
Особенно в каком-нибудь сетевом коде, где тебе по сети могут прислать любое говно из любой точки мира.
Там вообще, в сетевых стеках (которые как раз пишутся на Си и Си++) нужно быть охуенно внимательным. Уже не раз история видела, как кривой код приводил к масштабным проблемам.
Те же взломы Windows NT в конце 90-х, т.н. WinNuke. Или там всякие Denial of Service атаки на сетевые стеки, где на компьютер устраивали множество TCP подключений, которые забивали память ядра (особенно, когда там был буфер подключений индивидуально для каждого порта). Это только то, о чём я слышал. По факту, вариантов поднасрать было намного-намного больше.
Ещё хочу сказать, что сам язык Си или С++ никак не запрещает тебе пытаться читать или записывать данные по произвольным адресам памяти. Использовать указатели с произвольным содержимым. Ты всегда можешь тупо взять некое число, и кастануть его у указателю.
Только что выйдет из всех этих попыток - тот ещё вопрос.
На самом деле, подчас в некотором софте. Системном или для микроконтроллеров, обращение к кое-каким конкретным адресам может быть даже желательным. Так как по этим адресам располагаются полезные для тебя вещи.
Так например в ДОС, начиная с адреса 0 (НОЛЬ), в реальном режиме процессора, лежит массив адресов перехватчиков прерываний. И если ты хочешь написать свой собственный перехватчик, тебе неизбежно придётся переписать адрес в этом массиве.
Ещё например драйвера, часто используют обмен данными с подопечными им устройствами через некоторые спроецированные в физическое адресное пространство памяти адреса ввода-вывода этого устройства. Которые известны только самим разработчикам устройства. Чтение данных по такому адресу приводит к получению определённых данных от самого устройства. И наоборот, запись данных по адресу - приводит к отправке данных на устройство.
В винде, каждый исполняемый процесс имеет своё виртуальное адресное пространство памяти (не путать с физическим адресным пространством памяти). И значит, там это пространство разбивается на диапазоны. В разных диапазонах память может иметь свои особенности. Некоторая память допускает только чтение данных. Некоторая - и чтение, и запись. Некоторая - ещё и исполнение. Возможно только чтение и исполнение, а возможно и ещё и запись впридачу. Последний вариант позволяет исполняющейся программе - программировать саму себя. Т.е. на лету генерировать и записывать машинный код, который можно будет затем исполнить процессором. Гугли функцию VirtualAlloc из WinAPI.
Далее, некоторые диапазоны памяти в программе используются, чтобы спроецировать в них исполняемый код из exe и dll файлов. Некоторые - просто содержат готовые проинициализированные данные из этих же файлов, которые запрещено исполнять. Некоторые диапазоны содержат в начале исполнения программы тупо нули. Некоторые диапазоны вообще никак не используются, и попытка обращения к ним приводит к ошибке и segfault (в винде - access violation). Также, во время исполнения программы, она может запросить у ОС дополнительную память (из т.н. кучи), и ОС как раз таки выделит эту память в некоторых диапазонах адресов.
А ещё - программа может спроецировать файлы с диска прямо в память, и читать-записывать такие файлы путем прямого чтения или записи по адресам памяти.
Не, там есть что подчерпнуть. Например, я там вычитал как делать рандомные числа с нормальным (гауссовским) распределением. И вообще там про рандомные числа много чего интересного написано.
Про сети сортировок тоже интересно. В других книжках такого нет.
>как делать рандомные числа с нормальным (гауссовским) распределением.
И как же? Просуммировать побольше чисел с равномерным распределением и по закону больших чисел получить нормальное распределение? Или есть вариант поумнее?

 26 Кб, 355x432
26 Кб, 355x432Да. Там гораздо умнее. Я прям сейчас не упомню, но нужно было сделать что-то вроде генерации пары чисел - координат в неком квадрате. Причём вводился некий критерий, что если число, вычисляющееся через эти координаты оказывается слишком большим - эти координаты надо отбросить, и сгенерировать другие. Ну и в общем, потом из координат после какого-то математического преобразования получается искомое рандомное число с нормальным распределением.
>Так например в ДОС, начиная с адреса 0 (НОЛЬ), в реальном режиме процессора, лежит массив адресов перехватчиков прерываний. И если ты хочешь написать свой собственный перехватчик,
То пиздуешь в папку arch и хуяришь на ассемблере.
Бля, промахнулся тредом, соррян

Что, студент или подался на вакансию?
Поясняю. Если у тебя 32-битная система, то тип size_t, который принимает malloc является 32-битным, и принимает максимальное возможное значение (2 в степени 32) - 1. sizeof(char звёздочка) у тебя оказывается равно 4. Всё это влечёт за собой при вычислении аргумента malloc в коде, целочисленное переполнение. Там фактически, этот аргумент оказывается равным 4 (четырём). И именно столько байт аллоцирует malloc.
А далее - ты в цикле в этот массив пытаешься записать аж 1073741825 элементов. Каждый элемент это указатель тоже из 4-х байт. А адресное пространство в 32-битной системе - у тебя тоже только 2 в 32 степени (4 гигабайта). При вычислении адресов, по которым надо класть в массив данные, там тоже неизбежно будет встречаться целочисленное переполнение, т.к. каждый индекс массива надо будет домножать на размер элемента (4 байта указатели). А сам массив, тоже не в самом начале адресного пространства находится небось. В итоге, в цикле ты дойдёшь до границы адресного пространства, а потом ещё в его начало перепрыгнешь. И если бы не защита памяти, ты вообще легко можешь перезаписать уже сам машинный код твоей программы, который сам лежит где-то у тебя в памяти. В общем, полный пиздец.
А вот если система у тебя 64-битная, то size_t и указатели имеют размер 8 байт, при вычислении размера куска памяти для malloc никакого переполнения не случится. Размер адресного пространства тоже куда больше (2 в 64 степени байт). Malloc вполне себе нужный кусок памяти может выделить на твои 8589934600 байт. И ты вполне себе забьёшь массив своими указателями в цикле.
В общем, я не вижу особых проблем.
Размер стэка обычно чё-то типа 8 мбайт. Ты в цикле по сути кладёшь на стэк 4 байта 4 миллиона раз, то есть будет 16 мбайт. Много короче, может стэк оверфлоу случиться.
А вот и двачер-дегенерат подоспел. На стек он кладёт, через malloc. Как же. Какую только хуйню здесь не прочтёшь.
Ты не делаешь free в цикле для массива указателей, а делаешь только free для всего массива, значит всё остальное на стэке лежит и тут будет стэк оверфлоу.
Чё несёт, кретин. Си подучи, уёбок. Может, раздуплишься как-нибудь, и поймёшь наконец как оно всё-таки работает здесь. На стеке у него лежит. Жопа твоя на стеке лежит - вот что.
Долбоёб, ты не делаешь маллок в функции рид_стринг. Если ты не делаешь маллок - значит это лежит на стэке, а не на куче. Как же заебали вкатуны малолетние, боже.
>Если ты не делаешь маллок - значит это лежит на стэке, а не на куче.
Этот дегенерат ещё будет называть кого-то малолетним вкатунцом.
Твоё суждение не верно, дебил. Это не лежит ни на каком стеке. Пошёл нахуй. Говорю же - выучи Си, прежде чем рот открывать.
Наверное он просто вайбкодер, который только нейронкой командовать может. А сам ничегошеньки не понимает ни в Си, ни в программах на нем.
И 4 миллиона раз, ага ага.

Это CLion?
А плюсы, в отличии от Си - язык весьма суровый (надо понимать, в какой код преобразуется твой текст из переопределений с шаблонами). Не говорите С/С++ - это примерно как сказать JAVA/JS
 54 Кб, 1080x496
54 Кб, 1080x496Ядро выдает память блоками по 4 килобайта(см. системный вызов mmap, архитектуру виртуальной памяти)
malloc не является системным вызовом/ запросом к ядру. Это аллокатор из стандартной библиотеки(dll или so), который резервирует места в тех самых 4кб блоках под переменные(обозначает в блоках пустые места и т.д. ). Его задача - выдать адреса такие, что объекты не будут друг-на-друга наскакивать.
Да, malloc может подать запрос в ядро - если блоков не хватает, или если 'дыры' в блоках слишком узкие, что б туда уместился объект. Но он не будет по 4кб на каждый int просить:)
да, вы можете писать за пределами зарезервированной
области, но вы этим тотально попортите объекты, лежащие рядом с вашим. Поведение программы при этом меняется настолько - что при одинаковых вводных данных будет разный вывод. И вы будете надеяться, что схватите сегфолт, а не произойдет безсимптомная порча данных
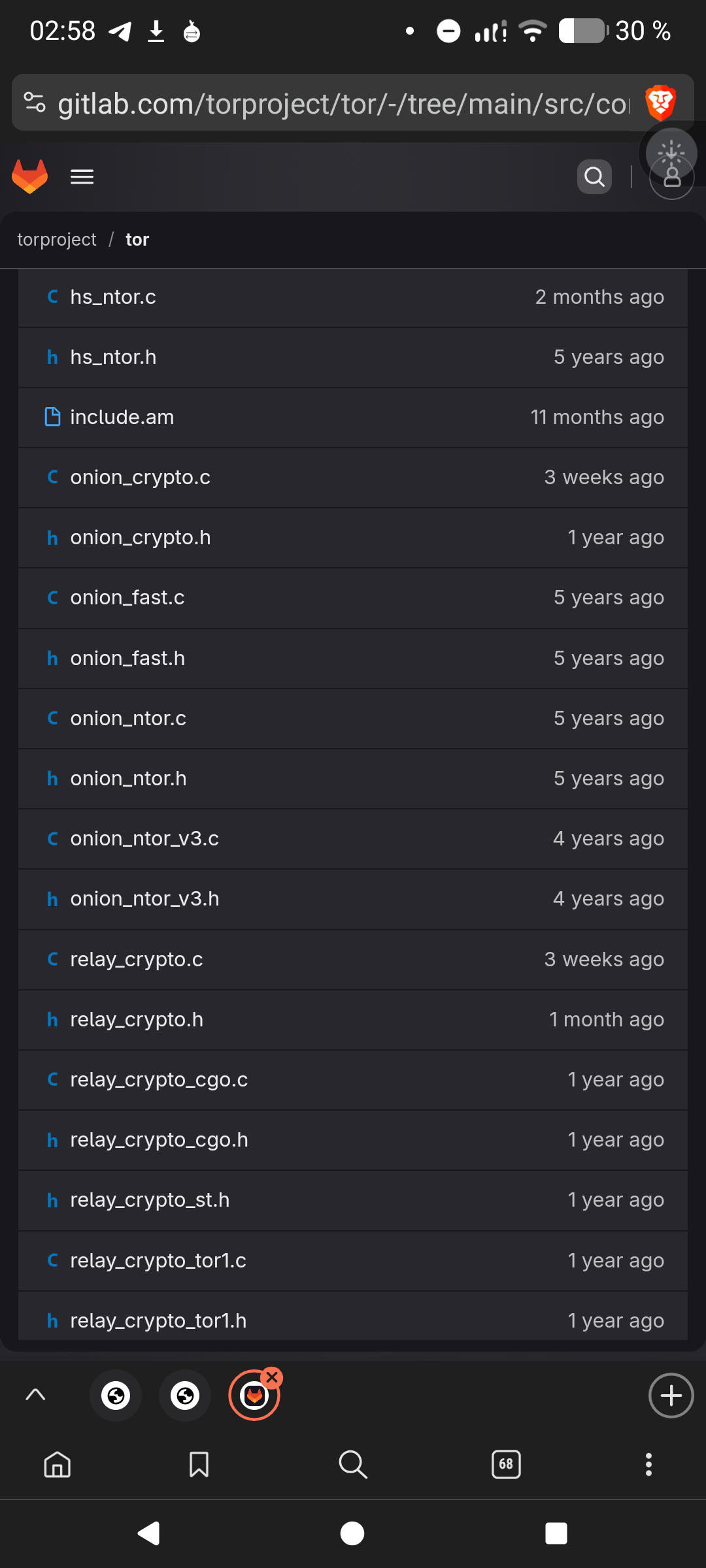
@ это звездочка
____
#include "stdlib.h"
struct client
{
int id;
int pin;
};
int main()
{
int@ a= malloc(sizeof(int));
struct client@ c= malloc(sizeof(struct client));
@a=8;
c->id=20;
c->pin=1248;
for( int i=0; i<200; i++)
{
a=1337;
}
printf("a=%d; id=%d; pin=%d\n", @a, c->id, c->pin);
return 0;
}
____
см. Скрин. Баг то вылезает то не вылезает. И ни однлго сегфолта
54 Кб, 1080x496Ядро выдает память блоками по 4 килобайта(см. системный вызов mmap, архитектуру виртуальной памяти)
malloc не является системным вызовом/ запросом к ядру. Это аллокатор из стандартной библиотеки(dll или so), который резервирует места в тех самых 4кб блоках под переменные(обозначает в блоках пустые места и т.д. ). Его задача - выдать адреса такие, что объекты не будут друг-на-друга наскакивать.
Да, malloc может подать запрос в ядро - если блоков не хватает, или если 'дыры' в блоках слишком узкие, что б туда уместился объект. Но он не будет по 4кб на каждый int просить:)
да, вы можете писать за пределами зарезервированной
области, но вы этим тотально попортите объекты, лежащие рядом с вашим. Поведение программы при этом меняется настолько - что при одинаковых вводных данных будет разный вывод. И вы будете надеяться, что схватите сегфолт, а не произойдет безсимптомная порча данных
@ это звездочка
____
#include "stdlib.h"
struct client
{
int id;
int pin;
};
int main()
{
int@ a= malloc(sizeof(int));
struct client@ c= malloc(sizeof(struct client));
@a=8;
c->id=20;
c->pin=1248;
for( int i=0; i<200; i++)
{
a=1337;
}
printf("a=%d; id=%d; pin=%d\n", @a, c->id, c->pin);
return 0;
}
____
см. Скрин. Баг то вылезает то не вылезает. И ни однлго сегфолта
быстрофикс
for( int i=0; i<200; i++)
{
*(a + i)=1337;
//было a ( i )= 1337, где ( ) квадратные
}
А что такого? Зашел чел спросить "что такое аллокатор". Во всяких книжках "си для чайников за час" детали работы аллокаторов + сбои памяти не объясняют, а тема важная. Хорошо что внимание обратил - цепляться за "странное поведение" для сишника необходимо, как и для любого другого спеца.
Насколько я помню, про аллокацию памяти подробно писал Кнут ещё в 1960-х годах.
>Во всяких книжках "си для чайников за час" детали работы аллокаторов + сбои памяти не объясняют
Диди в K&R объясняют в последней главе, на примерно 150 странице. И кто-то же всё равно гонит на бессмертную классику.
А чё ты там спросил, ткни? Алсо, с забором памяти есть один тонкий момент, который надо помнить, calloc (по стандарту) возвратит ошибку, если произошло переполнение, а вот realloc - нет.
Я-то ничего не спрашивал. Просто понимаю анона выше, аллокаторы тема весьма глубокая, а он в неё полез.
Сам сталкивался с весьма странными проблемами. Пишешь ты сетевую софтину - у тебя буферы клиентов в куче висят, дофига тасков. И в это же время в кучу прописываются результаты операций(те, что хранятся в оперативке до отключения питания). И вот кусочки буферов, временные данные ты через free убрал - и остается страница, на половину пустая, но забитая теми самыми "вечными" объектами. И память-то ты не юзаешь, и страницу вернуть ядру не можешь. И процесс твой убивают.
И что тут делать? До того дошло, что сам аллокатор вымучил, независимый от malloc. Я уверен, что половина сетевых программистов со внутренней фрагментацией сталкивалась - может у кого было решение покрасивее?)
>И что тут делать?
>у тебя буферы клиентов в куче висят, дофига тасков. И в это же время в кучу прописываются результаты операций(те, что хранятся в оперативке до отключения питания). И вот кусочки буферов
1. У тебя проблема в логике.
>страницу вернуть ядру не можешь
2. Никогда не отдавай память системе.
3. Выходит из 1, у тебя не будет проблем с фрагментацией.
4. Выделяй заранее память для пула маллока.
>И процесс твой убивают
5. Значит сервер хуйня.
>хотя по-идее они должны в памяти по соседству находиться
Не надо делать таких предположений. Твоя программа вообще не должна делать никаких предположений, где конкретно в памяти тебе выделят пространство malloc-ом. Это полностью на усмотрение аллокатора, который может руководствоваться оч. нетривиальной логикой.
Там помимо отдельных зон в памяти для объектов различного размера, могут вообще перед или после выделенного malloc-ом участка памяти, выделяться им же скрытые, служебные поля в памяти перед или после официального выделенного участка. И в этих полях размещаться какая-нибудь служебная информация.
Не любой. Указатель на void нельзя. Из-за того, что у него неизвестен размер элементов массива.
Так указатели и сами являются переменными. Просто там в них лежат не какие-то простые данные, а адреса. Адреса вполне можно представлять как числа, и в Си действительно можно числовые переменные кастовать в указатели. Как и указатели кастовать в числа. Надо только убедиться предварительно, что размеры в байтах этих числовых переменных и указателей - совпадают.
>А раньше указатель состоял из двух адресов - смещения и сегмента.
Ну как раньше. Под ДОС, в 16-битном реальном режиме процессоров x86. Просто ещё до ДОС, были реализации Си, на других платформах типа PDP, и там никаких сегментов не было. Сегменты - это чисто Intel-овская фишка.
Типов нет в языке ассемблера, на низком машинном уровне. А вот в Си уже типы вполне себе есть.
В питоне есть функция id(), которая возвращает адрес объекта.
Если хочешь, ты можешь на Си накатать расширение интерпретатора питона, которое бы тебе позволяло читать или записывать данные по произвольным адресам в памяти. И делать это с помощью специальных функций, которые предоставляет программам на питоне сие написанное тобой расширение.
Ещё поинтересуйся в питоне модулем ctypes и типом memoryview.
Биты есть, как некая условность в виде информации, принимающей значения 1 или 0. И эта вот информация может быть заложена в самых различных формах. Как в триггере, о котором ты говоришь. А может - в виде питов на CD-диске. Или в виде дырочек на перфокарте. Вариантов масса. Но всё это по-прежнему биты.
Насколько знаю, в стандарте Си, sizeof показывает размер объекта не в байтах!! А в количестве объектов char, которые в искомом объекте могут уместиться. Т.е. тип char является основополагающим.
>И что тут делать?
Для простых сетевых хуёвин "разместил" бы всё в .bss, типо структурка на соединение с дескрипторами, данными и rx/tx буферами, n таких структур для n подключений и free list к ней.
То есть вообще без аллокаций через std lib *alloc. Вообще совет анону, если тебе на деле не очень нужна память в куче, то она тебе не нужна.
>И память-то ты не юзаешь, и страницу вернуть ядру не можешь. И процесс твой убивают.
Т.е. у тебя была нарастающая фрагментация памяти, а затем наступил момент, когда при вызове очередного маллока не нашёлся подходящий зазор, а новую память не выделить? При наличии таких рисков как раз полагается использовать языки с GC. Приличный сборщик мусора мало того, что гарантирует отсутствие фрагментации, так ещё и работает быстрее в тех случаях, когда ручное управление её вызывает (Тормоза в языках с GC вызваны их рантаймом, а не самим сборщиком).
>Приличный сборщик мусора мало того, что гарантирует отсутствие фрагментации
Гарантировать можно только копированием.
> так ещё и работает быстрее в тех случаях
Нет. Ускорение сборки покупается перерасходом памяти (отсюда промахи в кэш ака тормоза в рантайме) и откладыванием копирования (отсюда аналог фрагментации).
Тоже вымучил сам аллокатор. Lazy дерево без балансировки и thread_local массивы для маленьких объектов. Не сказал бы, что очень глубокая тема, матана в ней мало, чистое байтоебство.
>Ускорение сборки покупается перерасходом памяти (отсюда промахи в кэш ака тормоза в рантайме) и откладыванием копирования (отсюда аналог фрагментации).
Ручной аллокатор тоже много памяти тратит на собственные нужды, и при фрагментации этот расход становится очень значительным. А расход тактов на копирование stop-and-copy сборщиком сильно завышен, так как процедура копирования перемещает данные в банальный вектор (одномерный массив). И что важно, аллокация при использовании GC происходит моментально, ибо для нахождения подходящих ячеек даже искать ничего не надо, достаточно лишь проверить, не вышел ли индекс за размер кучи. Если в памяти часто выделяются и стираются короткоживущие объекты с непредсказуемыми точными сроками жизни, то ничего лучше различных вариантов и гибридов сборщика типа "stop-and-copy" пока не придумали.
>Ручной аллокатор тоже много памяти тратит на собственные нужды, и при фрагментации этот расход становится очень значительным.
Сборщик тоже много... и т.д.
Если же он тратит не много, он медленный.
> достаточно лишь проверить, не вышел ли индекс за размер кучи.
Недостаточно. Под сборку нужны четкие форматы объектов, стековых фреймов, ограничения на использование регистров - куда можно сырые данные, куда низя. Это несет свои расходы и времени, и памяти.
У микроконтроллеров, бывает что на некоторые адреса памяти на самом деле спроецированы регистры процессора этого самого микроконтроллера.
Регистры процессора (рон) не у всего, но в мк удивительно часто: авр, 8052, с166
Ты подивишься, но не обязательно. Существуют или существовали компы, где адресация шла на блоки, большие чем байт.
Вот например вот этот динозавр из 1965 г. адресует память 16-битными словами
https://en.wikipedia.org/wiki/IBM_1130
И в те же времена, были компы с десятичной системой счета, а не двоичной. Байты, меньшие 8 бит. Машины со стековой архитектурой, вроде Burroughs.
для хранения адресов юзай uintptr_t,
конвертится в void и обратно. Допустим, если в байтах нужно посчитать расстояние между объектами, самое оно.
Но, указатели штука тонкая.
Если зачем-то сделаешь указатель типа uint32_t на элемент массива uint8_t[] - познаешь боль endianness. Запишется не то что нужно, не там где нужно - и еще кучу элементов зацепит.
Есть еще offsetof и container_of для навигации по структурам(которые могут содержать дыры между элементами, если те имеют размер меньше регистра и не имеют attribute packed ). Тоже тема :-]
ХЗ при чем у тебя attribute packed, в любом случае лучше offsetof юзать, чем ручками считать смещение, полагая что packed включен.
container_of - вообще фишка линукса, когда нужно найти родительскую структуру.
Не фишка, а просто макрос конечно же, использовать можно где угодно.
поле uint32_t, и идущее за ним поле uint8_t.
Делаю функцию, в которую как аргумент передаётся по значению вот эта вот структурка. Функция должна работать как можно быстрее.
Хочу знать - будет ли данная структурка передаваться в функцию в регистрах процессора? Одно поле в 32-битном регистре, второе поле, скажем в 8-битном регистре. Такое было бы самым оптимальным вариантом.
Плохой вариант. Передавать адрес. Это уже 8 байт, вместо 5. Потом ещё косвенно обращаться по адресу.
inline не хочу, т.к. функция много где вызывается в кодовой базе, функция часто вызывается, а кода в ней слишком много.
Нужна максимальная скорость.
MSVC пишет, что в __fastcall структуры передаются только через стек. вот пидорасы! Ведь можно в регистры положить! 5-байтовую то структурку.
Вот какого хера!
>а кода в ней слишком много.
Тогда ты ничего не выгадаешь на этой ерунде. Вот хотя бы просто для начала сравни каково оно будет с inline и без. Наверняка разница будет околонулевой.
Не. Кода слишком много - значит несколько операторов.
Раскрою карты - это главная функция, которая формирует битовый поток. Ей передаётся 32 бита число-буфер, и 1 байт - кол-во актуальных бит в буфере. Всё упаковано в одну структурку.
И вот эта функция во внутренний буфер объекта потока дописывает наши вот переданные биты. Там горстка битовых операций в коде, да ещё один if. Но всё это дело должно работать как можно быстрее. Т.к. записывается много всего.
Я просто не хочу размножать всё вот это хозяйство по всему коду. Ради пущей скорости, я и исключения отключил в функции через noexcept. (хотя да, я знаю что тред про Си, а не Си++)
А вот конструктор структурки, который проверяет кол-во актуальных бит - его стоит сделать inline. Чтобы если я задаю число бит константой, можно было бы прямо на этапе компиляции отбросить ненужную проверку, и свести код прямо к заполнению нужных полей этой структуры.
В идеале, если никак больше объект структуры не используется, её можно было бы хранить в виде пары переменных. Или вообще - сразу подавать нужные данные на вход вышеобозначенной функции, и ничего не хранить лишнего.
Ну, по сути типичная процедура при энтропийном кодировании. И все же подозреваю что ты пытаешься оптимизировать не там и не то. Можно было бы хотя бы начать с того чтобы входные данные буферизировались и обрабатывались уже небольшими блоками. Наверняка это больший эффект даст.
Это оно тебя ебало, петушок.
Дана матрица 64 x 64 бит в виде непрерывного массива в памяти.
Надо ее транспонировать и положить в другой такой же массив.
 7 Кб, 576x583
7 Кб, 576x583трай хардить - поставил линукс, накатил vim с fpc и сидишь кодишь без указателей, потом осторожно пальчик в указатели опускаешь, а там уже и второй том не за горами
поменьше на дваче еще сидеть надо, побольше кодить, например: Применить знание геометрии о косинусах и синусах в crt и нарисовать там крутящуюся палочку, для такой программы указатели не нужны, а получается очень прикольно, потом можно и другие геометрические фигуры попытаться изобразить и дать им возможность двигаться
Плохи дела, если указатели - что-то очень сложное для тебя.
Это далеко не самое сложное, что бывает в комп. технологиях.
Вот для меня сложное - это дискретное косинусоидальное преобразование (DCT) в JPEG кодировании. Математика, а никак не сраный язык Си.
Я Столярова дропал. Читается для меня очень тяжело. Даже вещи что я знаю. Я начинал с Паскаля, учебник Песни о Паскале, а дальше перекат на С легко сделать, языки почти одинаковые по своей сути. Страх и непонятки перед указателями уйдут, как ты сделаешь что-нибудь динамическое. Связный список, или массив, или ещё что-то.
>Страх и непонятки перед указателями уйдут, как ты сделаешь что-нибудь динамическое
Рекомендую вообще не заниматься динамическим выделением памяти, просто объявляй композитные типы и статически выделяй под них память.
Я тебя возможно плохо понял. Что если мне нужен дин. массив, что мне делать? Объявить гигамассив? Но память на стеке она конечная и не очень большая, 20мб или примерно так.
Помнится запускал какую-то хуитку на джаве она сразу забирала пару гигов, если тебе прямо надо то почему нет, ебани соотв. символ в bss?
Как же меня раздражает необходимость читать простыни кода. Особенно говнокода.
Это нихера не лёгкая прогулка - разбирать, что там понаписали эти умники. Я вот было скачал исходники Doom 2. И что, прям вот побежал их изучать? Или может, исходники Python я много читал.
Я Python почитал немножко, да и бросил. Ибо неохота ковыряться в этих дебрях.
Ну мне в целом похуй. Платят за час работы, а что я этот час буду делать - мне похуй пока платят ставку.
Дадут задачу, подразумевающую изучать легаси кодобазу написанную говнокодером в нулевых? Почему бы и нет, просто займет больше времени чем другая задача
Ну на работе ещё куда ни шло. Хотя всё равно, приятного мало. Вся эта унылая хуйня, что прям хоть увольняйся.
Нет - есть кенты, что копошатся в чужом коде в своё личное время. И не по работе, а по зову души. Тот же Doom читают.
Меня как-то даже коллега спросил - неужели тебе не интересно, как всё устроено и работает? Это в смысле потому, что можно из интереса даже в свободное время ковыряться в чужом коде.
Нет, для меня издержки превышают профиты. Мне не настолько интересно, чтобы преодолевая себя, ковыряться во всём этом.
>Меня как-то даже коллега спросил - неужели тебе не интересно, как всё устроено и работает?
Я тоже так спрашиваю. Лично для меня это само собой разумеющееся, что человек, который профессионально заниматься написанием кода, будет заинтересован смотреть на чужой код рано или поздно. Рано или поздно должно найтись то, что тебе будет интересно изучить, по-моему это вопрос времени. Заставлять себя конечно не надо (если это не работа само собой).
>должно найтись то, что тебе будет интересно изучить, по-моему это вопрос времени
Я чукча не читатель, я чукча писатель.
Да, было интересно заглянуть, посмотреть поверхностно. Но чтобы глубоко копаться? Только может движок Unreal 2004 и ранее, я бы изучил в своё время. Хотел бы, но его исходники не опубликованы.
Забыл сказать. Муторно это для меня слишком - изучать код, разбираться. Я довольно медленно это делаю. Видел как другие куда быстрее меня соображают, читают. У них больше природной одарённости, чем у меня.
Старый движок из конца 90-х слит, unreal400.rar вроде. Но оформление кода там так себе.