 746 Кб, 2310x2306
746 Кб, 2310x2306F.A.Q.
В: У меня горит лаба/курсач, не знаю какую тему диплома взять, хочу войти в айти.О: Задавай вопрос в этом треде. Защиту диплома желательно обсуждать в /un/, а вопросы по web желательно задавать в /web/.
В: Какую программу/ось поставить для ... ?
О: Связанные с софтом вопросы обсуждаются в /s/. Исключение - IDE и прочие инструменты программирования, которые можно обсудить в тредах соответствующих языков.
В: Ко-ко-ко не работает программа. Анон памаги.
О: Копируешь сообщение об ошибке в гугл, удаляя номер строки и название файла. Языко- и платформоспецифичные вопросы можешь задать в соответствующем треде.
В: Хочу стать программистом, какой язык учить?
О: SICP + HTDP.
В: Все на английском, нипанятна!
О: Тогда 1С.
В: Бугурт от собеседований, программировать в 30 лет, съябываем из говнокодинга, обсудить новые рецепты маминого борща.
О: Мы вам перезвоним тред - для обсуждения нетехнических околопрограммерских тем.
В: Бежать ли мне срочно в node.js, если на него сам PayPal гостевуху перенёс? Начинать ли учить Go и Rust, раз все говорят, что за ними будущее?
О: Если интерес не поиграться, а работать, то не нужно следовать за массовыми истериями. Выбирай язык с кучей библиотек, туториалов и проверенными временем фреймворками под твои нужды. Иначе будешь тратить время на велосипеды и поиск багов в чужих пакетах.
В: Взломать акк.
О: Просто съеби.
В: Тред закрыли/пропал, почему?
О: Заданные не в том месте вопросы будут утилизированы.
В: Подскажите сайтов, которые читают крутые программеры.
О: Лента из руби, джавы, скалы и ещё какой-то херни.
Литература с пика: http://goo.gl/7aUL3m
Подсветка кода для /pr/: https://github.com/ololoepepe/MakabaCode/

 9 Кб, 118x200
9 Кб, 118x200установил как теперь все трекеры туда преекинуть по быстрому?
А нахуя тебе самая-самая новая версия? Тебе от торрент клиента нужна одна опция - качать файлы. Старая с этим справляется.
 94 Кб, 1398x683
94 Кб, 1398x683>это другое
Нет, это буквально то же самое. Дегенераты с линукса, так гордятся что можно ВСЁ ОБНОВИТЬ одной командой. И в винде такие же недолинуксовые дегенераты с теми же мантрами:
>устаревшее обоссаное приложение
Обоссаный тут только ты.
в мозге миллиарды вычислений в секунду происходят, гугли нейронные колонки
мозг копирует способ обработки данных с окружающих.
при повреждениях и заболеваниях иногда эта тормозная прошивка слетает.
т.е мозг ставит более оптимальную прошивку эффективно работающую, при повреждениях
Почему аутистам ничего не нужно и ничего не интересно?
Вопрос больше к sa, но может найдутся сердобольные поделиться мнением
Сижу на позиции 2 года, вроде и грейд, и знания, и опыт есть, но не понимаю куда дальше вкатываться, думаю что так или иначе все ведёт в архитекторы бизнесовые или технические- в целом пофиг
Не понимаю какой для этого стек нужен, помимо понимания паттернов и прочего, не маловажным будет знание яп, соответственно вопрос, какой язык, харды качать чтобы дорасти до солушен архитектора?
Заранее спасибо за ответ
По яп наверное java/kotlin+go лучше всего для SA потому что весь энтерпрайз сейчас на них двух сидит.
Солюшен архитектор я хз кто это. Но если тебе прям архитектурой хочется заниматься по хардкору, то наверное знания распределенных систем, микросервисов, кафки, брокеров, транзакций распределенных - вот это все надо понимать. Но тут сложно будет потому что на такие позиции обычно берут людей с опытом в разработке. Без опыта разрабом сложно стать хорошим архитектором. Но это лично как мне видится. Может быть есть позиции где СА без опыта в разработке до солюшен архитектора хорошего может дорасти но хз.
В таблице есть два (три) типа записей: попадающих под conditionA, попадающих под conditionB (и не нужных в запросе). Разные типы нужно обработать по-разному, скажем, через funcA() и funcB(), но желательно в одном запросе.
Поэтому хочется раскидать записи на две под-таблицы tableA и tableB и дальше просто и наглядно запхать их в функции. Есть ли такая операция в общем SQL?
Что-то вроде `CASE WHEN condA THEN PUT_RECORD_IN tabA WHEN condB THEN PUT_RECORD_IN tabB END`, но ничего похожего не гуглится. Предлагают через GROUP BY c условием, но хз как потом к отдельным группам обращаться вроде никак by design. А, ну и можно SELECT внутри SELECT, как это делается сейчас, но тогда подзапросы делают двойную работу.
Ты что-то наворотил. Делаешь SELECT WHERE A, обрабатываешь с funcA. Аналогично с B.
Солюшен архитектор - это бесполезный хуй, который много пиздит ниочем и рисует никому нахуй не нужные схемы. Что-то на уровне скрам мастера и прочей менеджерской перхоти. Чтобы им стать, качай навык знакомства с главным кабаном.
Как бы да, просто я разбираюсь с тонкостями SQL и всякими `SELECT (SACRIFICE_GOAT) AS a, (SUMMON_SATAN) AS b, UNHOLY_FEAST(a,b) AS c` и верю, что можно в один запрос уложиться
Принято. Как понял, нужны знания полного цикла разработки от выбора на чем будет строиться система/анализ архитектуры->стек бека/в целом наверное знания на уровне мидла (?)- заканчивается деплоем/контейнеризацией
Спасибо за ответ
Только-только исполнилось 17, чуть около года варюсь в айти и месяца 3-4 занимаюсь МЛом.
Я мега нищий и хочу решить эту проблему, нужны любые советы по поводу карьерного роста.
Ну ты опоздал зарабатывать в айти. Работы больше нет. Надо было раньше рождаться, хуле. Сейчас даже с опытом и профильной вышкой невозможно работу получить, а тебе так вообще 0 шансов. Короче займись чем-нибудь другим для заработка денег.
сука, так и знал, что надо было раньше из яйца выплывать
айти теперь это для души, но если все таки хочешь карьеру то строй социальные связи, с ними может быть какую-то работку и выцепишь, на еду точно хватать будет и может быть раз в два года отдохнуть на море недельку
Для начала выйди с этого краб-бакета для нытиков и больше никогда не спрашивай тут советов. Это уже значительно усилит твою позицию.
 78 Кб, 620x440
78 Кб, 620x440А ты устраивайся в Алабуга политех. Нынче программисты нужны, не штурм, дроны разрабатывать, будешь ххлов мочить, и денег само собой подзаработаешь.
Это же прекрасно, пока либирашки из мусорок объедки ар доедают, нормисы делают состояние и уважение
Неприятно, инвалидина? Ну поплачь
Свою картинку подставить можно только если оформить подписку за около $10 в год. Один раз я бы заплатил, но платить ежегодно за личную пикчку в фоне это слишком.
Пытался ковыряться сам, определил что расширение тащит фоновые картинки (там есть несколько разрешенных) из сайта разрабов.
Нашел один js файл, где прописан адрес текущей пикчи. Изменил адрес на другой, с той пикчей которую загрузил на хостинг пикч самостоятельно.
Далее скопировал папку с расширением и установил его отдельно, не с магазина Хрома в смысле.
И знаете что? Там есть какая-то самопроверка. Взяло и переписало тот адрес, который я подсунул на одну из базовых пикч. Она тоже с сайта разработчиков скачивается. Но имеет немного другой адрес.
И да, переписать код надо так чтоб без скрытых таймеров и бэкдоров) Интересно сколько стоит такая работа.
Купи подписку за 20 долларов на клауд код или кодекс и он тебе все сделает.
Перед этим просто проконсультируйся в обычном чате с чатгпт или дипсиком или гемини.
Программисты такое раньше умели делать, но разучились - ИИ атрофировал наши навыки и теперь мы без ИИ еще более бесполезные чем были раньше.
>Расширение типа Speed Deal.
https://github.com/conceptualspace/yet-another-speed-dial
Плоти денюх
Отредактировать-то наверное не так сложно, но таким образом ты ответвишься от официальной версии расширения и не будешь получать дальнейшие обновления, а если и будешь, то твои изменения, возможно, откатятся.
Это не учитывая того, что, возможно, Хром накладывает ограничения на редактирование расширения. Отредактировать можно, а вот примет ли браузер? Фаерфокс примет, а вот Хром не знаю. Я знаю, что Хром слишком много решает за пользователя, поэтому всё может быть.
В проде ноду не используют для прямой работы с БД. На ноде вебмакаки пишут backend for frontend, из которого уже вызывается настоящий бэкенд на шарпе/жабе/го, где у инженеров по разработке ПО имеется квалификация и нужный уровень допуска для работы с БД хоть через SQL, хоть через ORM.
> из которого уже вызывается настоящий бэкенд на шарпе/жабе/го
Что за невероятная индусская поебота? Просто берёшь и пишешь си либу которая работает напрямую с БД прямо из V8.
> Купи подписку за 20 долларов на клауд код или кодекс и он тебе все сделает.
> Перед этим просто проконсультируйся в обычном чате с чатгпт или дипсиком или гемини.
Спасибо.
>>12133
А мне такое расширение не зашло. Жаль вот этого https://addons.mozilla.org/ru/firefox/addon/speed-dial-fast/ нету для Хрома.
>>12234
Принимает же. Достаточно в режиме разработчика выбрать загрузить распакованное расширение. При этом отредактированное расширение ставится локально с какой-либо папки. Но да, при обновлениях Хрома может и перестать работать.
Интересно, а нахуя так? Все из-за производительности ноды? Почему просто не обращаться к настоящему бекенду без "человека по середине" в виде ноды?
Чтобы создать работу для раздутого штата вебмакак. Если они не будут показывать деятельность, их сократят, и не получится вытрясти из кабана побольше деняк.
>>12453
>Че делать теперь?)
я на шлагбаум пошел за 30к сторожем работать. сижу в будке жму на кнопку поднятия шлагбаума. потом снова на нее жму чтобы опустить. смотрю в камеры. больше ничего не делаю. забавно что меня даже не нейронкой, а обычным классическим компьютерным зрением и несколькими if-else можно спокойно заменить, но пока что этого не сделали.
Команда индусов - индусские решения. Никто не мешает LMDB.js взять на ноде и жить как белый человек имея 100к rps на одном сервере.
Но индусы не люди, они будут жаву к ноде прикручивать, хуячить некст, спринг, микросервис на go, валидацию json, протобаф и ещё редиса с каким-нибудь высером вроде кафки, конечно же орм, скул, графскул, эластиксерч и офк всё это вместе будет лежать через 10к rps, кекеке
Если что-то >>12358 подобное слышишь держи в голове что общаешься с тупорылым быдлом, можно сразу игнорировать подобное.
Такие дела.
двачую >>11964
Для души хакатоны, практикумы, опенсорс, фриланс. Репутация, связи. МБ ничтожный шанс засветиться перед действующим тимлидом и с ним пройти в обход безумных кадровиков.
Для работы 1С, там всегда будут деньги. В госсекторе спрос на инфобез (т.е. полуадмин-полуюрист на разбор бюрократии), зарплаты бюджетников.
Спасибо, вселяешь силы и надежды. Буду тогда стараться вывозить на связях, эмбэ и прикрутят куда нибудь
В общем почитал, потыкал то-сё, и остановился на табличных выражениях. Чую что бред, но хотя бы наглядный.
WITH needed AS (SELECT ⋆ FROM main WHERE filter),
groupA (colA) AS (SELECT ⋆ FROM needed WHERE condA),
groupB (colB) AS (SELECT ⋆ FROM needed WHERE condB)
SELECT funcA(colA) ⋆ funcB(colB) FROM groupA, groupB;
>вселяешь надежды
Жаль, что только посты на дваче не создадут рабочие места и надобность в анальниках. Айти мертво, анон.
Больно, дворник? Ты даже не смог вкатиться толком, а программисты продолжают работать лутая ещё больше денег используя ИИ.
 66 Кб, 853x625
66 Кб, 853x625Ты не смог даже прочитать подпись под названием раздела, но считаешь себя умнее каких-то менеджеров?
 151 Кб, 486x498
151 Кб, 486x498Нет, ты либо умственно отсталый, либо способен к программированию, третьего не дано.
Конечно можно как и ко многому другому можно быть неспособным
лично я лет до 15 вообще не знал что такое программирование, потом нам в школе показали что на языке петухон можно решать задачки для егэ, ну и пошло-поехало. Если это твоё ты сам к этому придёшь, если нет то не хочешь срать не мучай жопу как грится.
я кодить лет с 11 начал еще на делфи но это не спасло меня от безработицы. сижу полгода лапу сосу никуда устроиться не могу.
Просто не будь ботохуетой которая форсит безработицу
Тред в закладках и я не сплю. Два этих фактора позволили мне прочитать твое сообщение и ответить на него
> Ого, удаленка на США 15к баксов? Как попал
Сися на рaщку за 100к рублемассы
> А со здоровьем что без жизни с солнцем
Скуфею потихоньку, по возможности занимаюсь на турничке домашнем, но редко
Дело в том, что большинству, по сути всем, ничего не нужно кроме выгоды, поэтому все хотят делать только то, что у них хорошо получается, ради выгоды. И соответственно, никто не хочет делать что у него плохо получается, даже если начинает, понимает и бросает если выгоды нет.
Поэтому хочешь == можешь, это синономы. Если не можешь, хотение пропадает.
А я уникальный, не алчный скот, живу не ради выгоды, поэтому всю жизнь занимаюсь тем что хочу, что нравится, той же радиотехникой и программированием, однако еще со школы начал подозревать что абсолютный бездарь, могу только повторять чужие схемы или писать несложное, а инженерить своё и особенно сложное абсолютно не могу, и так же очень плох в поиске неизвестного, то есть ремонте, реверсинге и так далее. По сути ничего не могу, но только этим занимаюсь, паяю что могу, кодю что могу, это никого не впечатлит, но мне и не надо. Любое быдло умнее и способнее меня, лично видел, но оно ничего такого не хочет и не занимается, потому что у быдла желание только одно - выгода.
Так что способности существуют, но без желания они не имеют смысла, человек не робот, его мотивируют желания, а не способности. Все зависит от философии, глобального мировоззрения, какие ценности у человека в башке, то он и будет делать. Важно воспитание, моральная идеология, стандарты что такое хорошо и что такое плохо установленные обществом. Если в обществе стандарты - укради, наеби, то ты и получишь, сам виноват, а визги поиском виноватых и репрессии не помогут, будет только хуже.
Мимо увидел твой пост.
Сам только что узнал про Эффект Зейгарник.
Короче, мозг лучше запоминает незавершённые дела. Поэтому надо пересилить себя, начать чтото делать в этом направлении, до того пока не станет интересно. Потом прерваться и мозг уже не отпустит задачу.
У меня такая херня - когда играю, то оттягиваю кодинг, потому что знаю что начав я уже не успокоюсь и вот прям щас сделал основную часть проекта, устал и вроде хочу поиграть, но уже не то.
В общем, нельзя закрывать гештальт))0)
Сори, бро. Но для тебя у меня вариантов нет. 🙂
Это я. Но при этом айти выгодно даже если ты конченный. У меня 8 лет опыта из которых я 5 лет был джуном, а щас мидл. В то время как люди до синьора за 5 лет апаются на изи.
Но блять, как бы кто не говорил про то что айти мертво, в моём мухосранске зарплата мидла на удаленке все равно норм.
У меня оба родителя работают + брат живущий с ними. Их общий семейный бюджет все равно меньше моей мидловилки выходит.
This. И как быть тогда?
Сейчас разницы нет, так как никто не нанимает.
Но раньше вышка была хорошим плюсом. К колледжам и пту всё-таки негативное отношение если это не рабочая профессия.
И так почти ИДЕ не открываю и кодю ИИшкой. Хз как можно меня заменить. Тимлид вместа меня будет таски ИИшкой кодить? А тимлидить когда :D
 568 Кб, 1264x577
568 Кб, 1264x577>Есть ли такое, что работодатели, когда видят, что у тебя среднее образование, выгоняют с собеседования пинками под жопу
Скорее не так. Перед тем как технические специалисты увидят твое резюме оно должно пройти через рекрутёр очку. А она просто будет бать отклики с топовой вышкой в первую очередь. А щас по 200 человек на место.
математик веб-макака
Можно если писать лабы студентам 24/7. На обычной работе эти знания нахуй не всрались конечно же
Если ты не делаешь высокоуровневую архитектуру и если ты (по твоим же словам) обычный мидл разработчик, то тебя можно легко уволить. Потому что вероятнее всего ты просто тикеты из джиры в ИИ копируешь и производишь нейрослоп. Тебя можно заменить ИИ агентом который сам будет из жиры задачи брать и делать.
Заранее спасибо за ответ.
Исторически сложилось, что в СПО идут люди отрицательно одаренные. Так что даже гнать не будут, просто посмеются с глубинария.
анон - помоги нищеброду с поиском нейронки, а то у меня опять то что было сломалось.
я не совсем понимаю во всех этих терминах, но сейчас у меня было opencode cli (который запускался из консольки). для которого в visual studio code я юзал расширение opencode vs code extension которое хоть пиздец кривое но позволяло работать с проектом.
у меня толи лимиты закончились, толи еще какая поебень... но я так понимаю там можно свою модель выбрать.
хотел выбрать deepseek - но мне на любую эту модель пишет что недостаточно средств (а где блядь бесплатно? в интернете написано что бесплатно)
или может какой-то другой плагин посоветуйте сразу (opencode в vs code кривой шо пиздец).
раньше пользовался kilo code- но сейчас он не работает (толи бан, толи хуй знаю - после крупного обновления).
квн у меня есть если что. денех нет. я нищий. и я просто ковыряю свой проект игры мечты. поэтому мне и надо нейронка чтобы она была встроена в visual studio code и могла с моим кодом работать.
можно наверное и локальную но я хуй знаю как это встроить в visual studio code. когда-то ставил ollama но она работала только в консольке.
Ну, у меня 85 IQ, но я же смог вкатиться в бэк и получаю 350к. Вкатывался долго, конечно, около 8 лет ушло но зубрёжку книг.
У меня разговорный английский и я смотрю сериалы с 15 лет и в дискордах англоязычных много тусуюсь. Есть англо друзья онлайн с которыми в войс чате много сидим. Так вот, за 8 лет карьеры английский на работе пригодился 0 раз. То что программистам нужен англ распространяет отдел продаж skyeng
> Потому что вероятнее всего ты просто тикеты из джиры в ИИ копируешь и производишь нейрослоп. Тебя можно заменить ИИ агентом который сам будет из жиры задачи брать и делать.
Ну почти так но у меня контекст шире. Я помню что писалось в чатах и что говорилось на митингах и дейли. Плюс решаю тикеты саппорта где наши менеджеры называют баг "не работает" и прикладывают скриншот(или фоту моника с мобилы).
Это пока ИИшка не умеет
НЕ МОЖЕШЬ ВЫУЧИТЬ АНГЛИЙСКИЙ УЖЕ 10 ЛЕТ
@
САМООЦЕНКА НИЖЕ ПЛИНТУСА
@
РЕШАЕШЬ ВЫЙТИ В ИНТЕРНЕТ
@
КАКОЙ-ТО АНОН С АНИМЕ ФОРУМА ХВАСТАЕТСЯ ТЕМ, ЧТО У НЕГО ХОРОШИЙ АНГЛИЙСКИЙ С 15 ЛЕТ
@
ПОЗЖЕ 2 ДИГГЕРА НАХОДЯТ ТВОЮ САМООЦЕНКУ В ЗАБРОШЕННОЙ ВЕТКЕ МЕТРО
я просто глупый и за более чем 10 лет не смог выучить английский. родился в глухой провинции в семье запойного алкаша и деревенской дуры, окружение было соответствующим. какое-то время в универе и уже после пытался в грамматику, прорешивал мерфи красно-синего, но по итогу ничего не вышло - просто слишком глупый с рождения. я плохо учился в школе и вузе. так бывает..
>>14869
Буквально языки - мое хобби. Нравится смотреть фильмы на других языках, понимать как в оригинале и чем от перевода отличается. Ну вот к работе в айти эти навыки ваще никак не применимы. Только делают мння душнилой. Бомблю когда вижу названия переменных leafs и тд. Или там persons. Потому что множественное число от person это people.
Не понимаю зачем джунам рассказывают что надо англ учить. Буквально вся команда будет на русском. Даже те кол работают на западный рынок часто работают через ру тимлида. Возможно если начать работать на аутсорс и потом напрямую с заказчиками вписаться в обход посредника полезно. Но это ниша залупа
Где з/пшки пожирнее?
>Не понимаю зачем джунам рассказывают что надо англ учить
еще смешнее что нейронкам похуй на каком ты языке, хоть на бурятском пиши.
раньше был аргумент что джуны без англюсика не смогут правильно переменные называть (хотя гугльперевод всем доступен). а сейчас переменные за тебя нейронка назовет
как фиксить?
чел, я вообще англ не учил, просто смотрел ролики на ютубе на английском, постепенно понимать начал. Немного плавую, но смотрю без переводчиков.
В чем проблема у тебя вообще?
Зачем тебе? Ты хочешь tcp-протокол переделать?
Просто, мне кажется что ты явно что-то недопонимаешь и усложняешь себе жизнь.
Смотри. Приложение не знает что оно отправляет/принимает данные по сети. Образно, есть область памяти откуда драйвер забирает данные и вместе с tcp пуляет в сеть, это я досконально не разбирал потому что не нужно. И нет нужности про это делать книгу. Почитай как работает протокол tcp мэйби...
В wireshark есть инструкция как расшифровывать https, но я не осилил. Вот эта инфа мне бы очень помогла. Ну вдруг...
>Ты хочешь tcp-протокол переделать?
Нет.
Ине интересно как ядро фильтрует пакеты, какое у этого всего API, какой цикл жизни сокетов и пакетов, как система "скармливает" пакеты сокетам и т.д.
Делаешь два сокета - отправка/получение, у них указываешь в параметрах ttl. Ставишь эти два сокета в цикл и все. Если ченить прилетело в цикле, записываешь в файл к примеру. Драйвер возьмёт из памяти твои данные, tcp порубит их на части, прицепит свои заголовки, и отправит по ip адресу.
Я хз че ты хочешь на самом деле. Может кто-то поможет тебе.
Ядро тупо взаимодействует с сетевыми адаптерами по более низкоуровневым протоколам (Ethernet, к примеру). Сокеты - это тупо одно из внешних API ядра для вызова из прикладного софта.
>Но раньше вышка была хорошим плюсом
Плюсом была пара вышек типа СПбГУ/ИТМО и то лет 15 назад, когда это что-то значило. Рандомная вышка Пердятинского Государственного университета никогда не имела значения.
Но в обратную сторону это не работает. То есть если пчел смог ходить в уник, то это не гарантия, что он не дурачок и не буйный, просто повезло до конца дойти.
То есть если вышки нет - это значит пчел дурачок или буйный.
А если вышка есть это значит, что 50 на 50, может дурачок может нет х.з.
Ты буйный епту бля
>То есть если вышки нет - это значит пчел дурачок или буйный.
значит ценит своё время и не любит лизать жопы маразматичным преподам
Есть, 7 лет опыта. Учить программирование ещё раз смысла не вижу. На пет-проекты нет времени.
У человека может быть СДВГ, и он не имеет возможности сидеть и учить ненужные предметы в копрорасеянских вузах + в свинорусии запрещены лекарства первой линии для СДВГ. Поэтому убей себя.
Любая связь с социумом = проблемы. Кроме двачей, тут максимум меня могут послать нахуй, но и я тоже могу. Все справедливо.
Оправдывайся, неуч
Ща начались каникулы и буду поступать в магу , если поступлю то попробую вкатиться в айти кароч с чего начать или уже поздно лучше к петровичам на завод? школьниц не ебал зп 40к но в школа распиздяйская так что я там нихуя почти не делаю
айти умерло. Я сам не иронично думаю как бы пойти работать училкой информатики в пту какое-нибудь потому что сижу без работы уже полгода. Айти мертво.
>сть варик вкатиться в айтинейм школьному учителю математики ща оканчиваю 5 курс
1) в какую магистратуру идёшь?
2) шанс есть всегда.
3) постпрашивай про учебу в той или иной магистратуре у тех, кто там учился или учится сейчас.
4) успежво тебе!
1(чёто айти технологии вроде) но я живу в мухосрани и учусь в мухосранском педе так что мест там супер мало в маге
2
3да бля чо там спрашивать это мухосранский тир щит вуз
4спс
>>15688
ну хз заебывают иногда тотж впр проверять + поднимать баллы даунам до тройки , сидеть на егэ дежурным заставляют, есть дети дауны которые сидят обосранные на уроке и не могут отпроситься сЪебать домой
Но всё равно есть свой вайб в шкиле старшеклассницы в колготках и кайф когда дети по имени и отчеству обращаются , ну и ебланить кайф скачал презентацию почитал её и дал даунам задания потом скролишь двач
Сиди в школе и не рыпайся, лутай стаж, хавай льготы по максимому которые есть.
Мути кружок по олимпиадному программированию и прокачивай школьную команду.
Если ты мухосранский то удалёнку согласуешь с школьной нагрузкой, для респекта крупные конторы согласятся.
Дрочи базу, пиши петпроекты, буть готов к собесам.
К 2027 должен быть ветер перемен и ласковый хаир.
Посмотри код направления магистратуры. Если там начинается на 01 или 02(к примеру, 02.04.01 математика и компьютерные науки), то это точно не it, а скрытый мехмат, где ты будешь просто учится численные методы и работать с теми преподавателями, которых вам накинули, чтобы у этих преподов просто были часы.
хуй знает анончик смогу ли я сдержаться от принятия внимания старшеклассниц , они уже мою страничку в вк задеанонили и всякую хуйню написывают что шишка колом , но я их игнорю как могу и то я ещё девственник
я матешу веду за программирование ваще не шарю лучше по матеше подтянуться я считаю
 595 Кб, mp4,
595 Кб, mp4,640x272, 0:17
если бы завтра отрубали инет, какой контент скачали бы на жесткий? думаю, каких интересных лекций, туториалов по самым разным темам скачать, чтобы прямо сотни часов. наверняка есть у вас любимый образовательный контент. с фильмами и сериалами проблем нет
Перед смертью не надышишься.
Тут вопрос уже в том куда вообще можно вкатится 2026 хотя бы за еду.
Есть комп. класс там проводят тесты на спец. сайте.
Т.е. загоняют группу-две, каждый за свой стол. Тлф отбирают. Кто смог пронести-быстро палят.
Видел списывают с микронаушником (шепотом в микро говорят там чел на другом конце ответы говорит).
У меня другой вопрос.
На компе кроме этого сайта вуза НИЧЕГО НЕ ОТКРЫВАЕТСЯ В БРАУЗЕРЕ. Ни яндекс ничего.
Можно ли как-то убрать эту блокировку чтоб заработал яндекс и я смог искать ответы на каждый вопрос?
Желательно быстро и чтоб потом опять вернуть.
Если нельзя, можно и не возвращать наверно. Речь об 1 компе, моем куда сяду.
Влететь можно или это на уровне фантастики?
В 21-24 годах нанимали активно гошников всякие маркетплейсы, сейчас хайп го прошел и в целом найма в россии сейчас нигде как такового нет.
 17 Кб, 584x266
17 Кб, 584x266Не особо слежу за вакансиями, но даже в своей дыре (Пермь) натыкался на вакансию джуна https://perm.hh.ru/vacancy/130070167. Если нравится язык, то учи. Если не нравится, то лучше выбрать python (220р/час hh.ru/vacancy/133614763)/js, наверное. Вакансии все равно будут появляться, если даже на условно мертвые руби/эликсир/эрланг иногда мелькают вакансии для джунов. Только вот как ты будешь конкурировать с выпускниками/задротами/другими вкатунами.
Системные аналитики это как раз про много общения с разными людьми. Не советую если хикка.
 64 Кб, 731x688
64 Кб, 731x688>У меня ценность любой работы заключается в том, чтобы не было общения с людьми
В it общения с людьми много больше, чем работая курьером.
> Это нормально что нейронка ошибки в коде делает
Да, но это хуйня, с топ нейрокалом случается нечасто. Но представь что будет когда она сделала ошибку в архитектуре. У тебя пролапс ануса будет с такой хуйни, гарантирую это.
Нейронка которая в чатботе - лажа. Нейронка которая в claude code и тд делает намного меньше таких ошибок потому что она может ещё и запустить код, тесты, проверки синтаксиса и тд
>claude code
заебешься доставать.
по факту подойдет любая нейронка с CLI режимом, и любой плагин на VS code делающий что-то типа курсора.
я сейчас сижу на opencode (недавно нашел еще плагин, который ставит опенклод замест копилота, только не знаю - автоподстановки там работают или как).
до этого на kilo code. еще цеплял свои локальные через плагин Continue.
Но я не совсем представляю типичный день 90% кибербезопасников в отличии от других айти-специальностей, хоть и есть полгода опыта разрабом в рога и копыта. И соответственно заменит ли их ИИ? И впринципе суть их работы, какое мышление там нужно и так далее в отличии от дизайна/аналитиков/разрабов
Пять лет назад когда листал айти форумы и треды, то кибербезопасников засирали, так как все деньги лутали разработчики, а этим доставались крошки
Это шутка такая? Среднее специальное в айти котируется даже хуже, чем просто окончить 11 классов. "Отучился в колледже 4 года" звучит для работодателей примерно как "4 раза оставался на второй год".
Для начала хотя бы в российские взяли... Потом уже уладим проблемы на местах, если надо то за нужного человека всегда обкашляют вопрос хоть он из Сомали
Давно бы вкатился, раз все так просто.
>Пять лет назад когда листал айти форумы и треды, то кибербезопасников засирали, так как все деньги лутали разработчики, а этим доставались крошки
Хуета. У меня знакомый работает и его работа это сидеть на винде, настраивать групповые политики, битлокер, кастрировать браузеры, разбирать инцеденты и тд. Короче, на 30% бумажный даун, на 30% компьютерный мастер который отчитывается что поставил обновления.
Компании боятся не хакеров, в ФСТЭК\Регуляторов\Мусоров и задача перед ними показать что вы блюдёте, храните персональные данные в соответствии с ФЗ.
>>17925
>Потом уже уладим проблемы на местах, если надо то за нужного человека всегда обкашляют вопрос хоть он из Сомали
А гений не нужен. Нужен тот кто перед ревизорро компанию не посрамит
И правда Почему бы тебе не сказать ему что мы хотим чтобы их стало больше согласился о
н расплываясь в детской улыбке
Хабаровчан выщёлкиванием соучаствовавшую
> Что лучше: бесплатно отучиться на информационную безопасность 10.02.05 в колледже 3 года 10 месяцев или за 450 000 рублей на программного инженера 09.03.04 в университете 4 года 6 месяцев? И то и то заочно.
Вышка котируется только если топовая. Она же и даёт связи и направляет на стажировки в лучшие конторы. Если нет то хуй забей.
Херню поришь, школу ты практически 100% закончишь 11 классов, а вот в колледже тебя выпрут и не поморщаться если совсем отбитый. А в некоторых так вообще ближе к инсту по запросам. Но в плане работников люди с колледжа хуже, чуть более инициативные и "знают себе цену", сложно ездить на них и пороть им херню про опыт, семью и надо подождать все будет. Заметил что люди которые 11 классов окончили и чем ближе к золотой медали (если не куплено, с этим вообще беда), тем проще им по ушам ездить.
>>17909
>И то и то заочно.
Ты фактически покупаешь корочу об образовании которая по факту ничего не дает, за заочкой идут только когда по докам у тебя образование должно быть и ты за ним идешь.
>бесплатно отучиться на информационную безопасность
Узкая сфера со связями, без них платят копейки и в основном бумажки тупейшие перебираешь.
За бесплатно только в топ вузе можно выцепить связи, за ними туда и идут, без них ИБ никому не всралось.
>на программного инженера
>за 450 000 рублей
Если тебе там не дадут оборудование которое сложно самому добыть и ты сможешь его тыкать, то опять таки тупизм.
Время проведенное там в плане обучения имеет низкую ценность, так что опять же только связи, если ты не идешь за ними и не дают что-то что ты сам потрогать не можешь, то херня.
Вышка сейчас только для создания связей нужна, либо когда нужен доступ к примеру к супер компу и ты точно его получить не можешь без образования. В остальном на нее смотрят еще как на фильтр "ездового" животного, лучше всего использовать людей с красными дипломами и максимальной посещаемостью, это обычно люди без жизни и опыта в ней, поэтому им можно любую херню пороть и они будут работать за низ вилки, даже спасибо скажут за переработки.
>Она же и даёт связи и направляет на стажировки в лучшие конторы
Более того, это вообще единственная причина идти в вуз. Сам по себе диплом никому не нужен.
>>18734
Сука каждый раз лолирую с этих "связей" в вузах. Какие связи, ни 1 знакомого нахуй не знаю из разных вузов, кто бы обзавелся этими связями полезными, разве что законтачил с васей пупкиным который играет в контр страйк. Ладно б сказали умение учиться и системное мышление, в топ вузах это как раз и есть. И бумажка все равно самое важное - аппрув ботом резюме, переезд заграницу и так далее
>Сука каждый раз лолирую с этих "связей" в вузах.
Потому что ты не понял смысла институтов в стране.
>Какие связи, ни 1 знакомого нахуй не знаю из разных вузов, кто бы обзавелся этими связями полезными
Значит вы просто все донные были и поступили в дно институт, именно поэтому есть "престиж" и именно из-за этого туда рвутся. Это буквально билет в жизнь, потому что после института шансы установить социальные связи с каждым годом снижаются, а они в нашей стране ключевой фактор в любом вопросе.
>Ладно б сказали умение учиться и системное мышление, в топ вузах это как раз и есть.
Это все вторично. Главный вопрос кто твои родители и кого ты знаешь, все остальное уже рассматривают после.
>И бумажка все равно самое важное - аппрув ботом резюме, переезд заграницу и так далее
Вот...вооот...ты не понимаешь что нет никаких резюме при связях, тебе просто говорят "нужен человек на работу, платят 600к, приходи к нам".
Опять же я говорю про хорошие места, а не обслуживающий персонал за 100к. Туда как раз и идут когда социальных связей нет.
Этот >>19062 прав. ты как маленькая тупая соска обсмотревшаяся пиздежа про американчкий успех. В России этого нет, тут только блат. Блат это социальная сеть для "своих" зарекомендовавших себя, в которую принимают только по инвайтам, приглашениям от уже действующих членов блата - блатных. Как правило это сын/зять/кум/сват, потому что кровные связи сильнее всего, дальше уже идут остальные. А посторонних по резюме в принципе не принимают, даже не рассматривают, ты никто без связей, нахуй не нужен. В блат тебе хода нет, если тебя и возьмут, то только как расходный материал, попользовать и выбросить как рваную половую тряпку.
>Сука каждый раз лолирую с этих "связей" в вузах
>Какие связи, ни 1 знакомого нахуй не знаю из разных вузов, кто бы обзавелся этими связями полезными, разве что законтачил с васей пупкиным который играет в контр страйк
В СПбГУ у тебя преподаватель может работать в Яндексе\Авите\Банках и т.д. Люди летнюю практику в яндексах прохдят. Конечно потом скорее их наймут чем вкатунов с курсов
По блату рил много че делается. Например если умеешь социализироваться то можешь по блату устроиться в озон.
Приглосят на собес и могут дать слив для подготовки
Нет, диплом колледжа - это волчий билет для айтишника. Даже если ты потом каким-то чудом по блату попадёшь в айти и дорастёшь до сеньора, на тебя всё равно будут косо смотреть: "Смотрите, этот учился в колледже))0".
Я увидел слово "реально". Реально? Нет, конечно же. Какой бы ты смысл в это ни вкладывал.
Ты исходишь из неверной предпосылки, что для каждой попытки подбора пароля надо обязательно отправлять запрос к некому чужому серверу. Вот подбор закрытого ключа для подписи в TLS-сертификате можно проводить полностью оффлайн.
Проект представляет собой инструмент для организации прямой P2P-передачи аудиосигнала между устройствами с использованием технологии WebRTC. Разработка обеспечивает минимальную задержку звука и ориентирована на создание приватных каналов связи без посредничества промежуточных серверов.
Захер мне твой рейтлимит, если я тебе просто в dns кеш насру свой ip и ты мне сам свой пароль и введёшь
> В остальном на нее смотрят еще как на фильтр "ездового" животного, лучше всего использовать людей с красными дипломами и максимальной посещаемостью, это обычно люди без жизни и опыта в ней
Откуда такая информация?
>>1008826 (OP)
>>19198
>WebRTC
Можно ли через это связать в одну сеть 2 устройства за NAT с мобильным IP при минимальном участии сервера посредника с ipv4?
Потому что троттлинг это программный слой защиты и его всегда можно обойти так или иначе.
Зашифровал SSD и следлал троттлинг чтобы если больше 5 попыток иди гуляй? Снял SSD с твоего компа, поставил на твой, твой скрипт с троттлингом остался на твоем компе.
Сделал не больше 6 попыток логина на сайт в час + капча? Это работает, но если я как-то получил слив слепка базы я у себя на сервере богу брутфорсить без твоего троттлинга.
Сделал так что к вайфаю было 5 шансов подключиться в час с защитой от подбора? Перехвачу твой хэндшейк и буду его у себя брутфорсить.
Есть разные алгоритмы типа Argon2 где можно настроить чтобы подбор хэша занимал секунду, что делает логин долгим(1 секунду) но не критичным, потому что брутфорсить 1000 комбинаций он уже будет 1000 секунд даже на топовом железе. Но опять же тут матана дохуя, а не меньше
Чел, айтишка все, вкат закрыт, хоть ты MIT закончи.
В пту осваивают рабочие профессии, собственно это сейчас и актуально.
а то мне это направление пиздец как интересно, хочу работать в айти но из образования ток 11 классов
>мне это направление пиздец как интересно
Вот тут пережирнил. Айтиговно никому никогда не было интересно, кроме пары шизиков. Все шли сюда только ради денег. Сейчас айтипараша сдохла и денег тут никаких нет.
Ну суди всех по себе.
>Откуда такая информация?
Проф наработка. Работаю в СБ и половина времени это сбор инфы о кандидатах, считай OSINT. Чем живут, чем дышут.
Эта информация в 1000 раз ценнее всяких резюме и дипломов потому что позволяет однозначно судить о человеке, определять вилку оплаты и главное степень езды.
Ньюфаги как и раньше не умели гуглить, просто они переползли в чатики и там спрашивают как писать цикл.
не, чатики ньюфагов мертвы. лично состою в таком и лично вижу как еще в 23-24 годах чатики были живые, а сейчас там буквально одно сообщение в неделю, да и то как правило какой-то спам
в целом айти чаты русскоязычные в телеге подохли почти полностью
Следовательно, и сеньоры на своих позициях будут жить вечно, не освобождая место для молодёжи. Тем более надо торопиться.
Теперь думаю о возврате в курьеры и волосы дыбом, там я говно и обслуживающий персонал. Везу если в офис завтрак из дорогого ресторана, то когда туда захожу чувствую себя грязной псиной которой нужно поскорее свалить и не мешать белым людям работать
>чатики ньюфагов мертвы
Тоже верно, демографическая яма такая что уже залётных почти нет. Все кто хотел уже вкатился, и теперь школоту в школе учат программированию.
> Теперь думаю о возврате в курьеры и волосы дыбом, там я говно и обслуживающий персонал.
Тогда работа на складе ВБ или озона тебе подойдёт лучше.
Как айтимакаки будут оправдываться, что сайт каждого сетевого магазина и не только сходу с первой страницы требует установить ПрИлАжЕнИЕ весом 50+ МБ, с доступом к камере, гироскопу, файлам, телефонной книге, при этом это лишь оболочка для страницы соответствующего сайта. Еще и QR/BAR-code для накопления скидки по карте лояльности работает меньше полгода, у некоторых он одноразовый, т.е. нельзя ПРОСТО зарегистрироваться, сделать скрин QR для получения скидок и забыть про сайт до конца жизни.
мимо селюк дремучий
>>20080
Правда ли что ни в банки кассиром, ни на завод охранником не берут человека, если у него полностью пустые страницы в соцсетях или отсутствуют, нет семьи, нет ипотеки.
> Как айтимакаки будут оправдываться, что сайт каждого сетевого магазина и не только сходу с первой страницы требует установить ПрИлАжЕнИЕ весом 50+ МБ, с доступом к камере, гироскопу, файлам, телефонной книге, при этом это лишь оболочка для страницы соответствующего сайта. Еще и QR/BAR-code для накопления скидки по карте лояльности работает меньше полгода, у некоторых он одноразовый, т.е. нельзя ПРОСТО зарегистрироваться, сделать скрин QR для получения скидок и забыть про сайт до конца жизни.
Приказ маркетолухов. Так по их мнению работает удержание и вовлечённость клиента
Всё сделано по ТЗ, оплата получена, остальное не ебёт.
>Как айтимакаки будут оправдываться, что сайт каждого сетевого магазина и не только сходу с первой страницы требует установить ПрИлАжЕнИЕ весом 50+ МБ, с доступом...
Никак. Это ИИ сделал. Мы теперь операторы ИИ агентов. ИИ решил что надо так сделать - он сделал. Мы тут не при чем.
ПрИлАжЕнИЕ нужно чтобы постоянно собирать данные о тебе. Потом их можно продавать. А ещё через ПрИлАжЕнИЕ удобно показывать тебе рекламу, потому что в интерфейс ПрИлАжЕнИЯ гораздо сложнее вмешаться чем в страницу в браузере. Доступ к контактам позволяет повышать продажи кумыса среди твоих знакомых надписями "Иван Гавнов купил этот кумыс уже 4 раза". Доступ к гироскопу позволяет отличать честного пешехода от рисерчера с эмулятором и показывать им разную рекламу. А тот факт, что ты видишь вебвью внутри, не значит, что приложение пустое, он лишь значит, что UI не приоритетная функция.
Если бы только данные, эта дристанина выжирает аккумулятор, т.к. ебашит в фоне даже когда пользователю нахуй не нужна. Телефон давно не устройство пользователя, а протрояненная помойка кишащая гадами живущими своей жизнью, занимается в основном майнингом данных для хозяев всех этих троянских ПрИлАжЕнИЙ, то есть банальной слежкой и воровством.
Почему так много стажировок на QA ручное и автомат? относительно, а не абсолютно кек Я думал они вымерли. Неужели это востребовано? Еще думаю либо над ml либо над дата инженером, хуй знает куда вкат оформлять после вуза. Все остальное 100% дохлое, так что если не выгорит пойду курьером. А точнее уже
 450 Кб, 512x512
450 Кб, 512x512Хотел бы вкатиться, но не надожу
И правда, нашел!


Через дебаггер, а что?
Пошагово прохожу отладчиком по всем написанным строкам. Смотрю, как программа себя ведёт в действии. Слежу за переменными. Какие значения они принимают. Всё проверяю.
 112 Кб, 566x805
112 Кб, 566x805Мой двоюродный брат учится в шараге на прогера, завтра сдает демэкзамен и я чет прихуел с требований. Там за 2 с половиной часа нужны наебашить ER-диаграмм, базу данных, приложение и документацию. Так вот, за час нужно сделать: Приложение с авторизацией и капчей + разными функциями. Они там совсем ебанулись? Одно дело это сделать через условный делфи или PyQt, но нет, они это будут делать при помощи ткинтера или кастомткинтера. Бедная студентота шараг. Сейчас просит помочь ему.
Я когда МЭИ заканчивал на 01.03.02 диплом проще было защитить чем эту шляпу сдать, зачем их так ябут?
И это экзамен? Там что, особо одаренных выпускают?
Это максимум на лабу первокуров тянет и то когда препод хочет чтобы максимально большое количество людей сдало.
Больше похоже на недопонимание, чем на еблю. Когда я учился, слухи о подобных заданиях на экзе у многих вызывали панику, но в итоге выяснялось, что на самом деле надо принести заранее сделанный проект на флешке, ещё раз защитить курсач или что-то вроде такого.
Что, никогда не писал экзамены на бумажке перед преподом? ПК использовать нельзя, телефон положить в коробку у входа. Думать только своим моском.
Так это нереально, да и смысл от написания кода по памяти на бумажке, если в реальной работе у тебя как минимум IDE будет и документация в инете
Дело в том что это нужно сделать за 2.30 часа, конкретно на приложение выдается 1 час. Одно дело навайбкодить можно было бы, так у них только иде будет и все, без доступов в тырынеты и прочих шпор. Покормил тролля тащем-то бгг.
>>21547
Доступов в тырынеты у них не будет.
>>21539
Хз, завтра спрошу как пройдет, мб помогут им, хз.
Чем пытаться донести смысл до 80-летнего деда, заставшего перфокарты, проще уж писать код на бумажке.
По времени без документации и прочего согласен что хуйня.
Я вообще без документации или IDE подсказок слепой как крот, а сейчас наверное даже без нейроподсказок сложно писать будет так как приучился писать таким образом чтобы правильно подсказывало.
Но в целом зная процесс обучения зазубрить команды и методы основные можно, хоть и глупо.
Там все максимальное простое и не требует "реальных" проверок и сложностей, таблица это тупо CREATE TABLE в какой-то mysql или что там у них на обучении было, никаких транзакций, никакой конкурентности, плюс это ебучий питон, там пиши насрав на все, это тебе не rust где правильно писать надо.
Задание максимально простое для того кто хотя бы пару раз на этом ткинтере писал и знает принцип работы с ним.
А вот диаграммы это да, хуита, их еще и на листочке попросят нарисовать что еще большая хуита, потому что когда что-то подобное делаешь то всегда получается десяток версий где постоянно что-то расширяешь или удаляешь, все предусмотреть сразу невозможно.
>Доступов в тырынеты у них не будет.
Как минимум нормальный препод должен дать доступ к devdocs.io или документацию адекватную, так как нет ничего тупее заучивания методов.
Правда ты говорил что это шарага, поэтому там скорее всего мои адекватные ожидания должны быть максимально разрушены.
Я слышал что образование у нас сильно просело и стало максимально ебанутым, где ты буквально зубришь правильные ответы и не думаешь вообще.
Так что возможно правильный путь это написать программу дома и "зазубрить" ее.
Глупо, бесполезно, но ситуацию решит на ОТЛИЧНО.
С тем же пазлом это максимально простая задачка, тупо картинку на Х частей порезать, положить массив, сделать клон массива, шафл, далее думаю ясно что пользователю второй показываешь и надо чтобы он собрал условно первый.
>Телефон давно не устройство пользователя
Айфон да, а на ведре ты можешь разблокировать загрузчик и установить дистрибутив какой хочешь. В идеале для приватности нужно покупать пиксель и ставить графен. Конечно после этого некоторые трояны откажутся работать, но ты сам понимаешь, или крестик, или трусики.
нормально всё придумано
Если ты не в состоянии запомнить 2 метода, садись и учи. Если и так понимаешь, занимайся своими вещами. Вин-вин.
 56 Кб, 300x100
56 Кб, 300x100Проблема не в том, шоб запомнить, а в том, шоб написать несколько тысяч строк кода за 2.5 часа без нейронок и Интернета как такового. Ты сам-то сможешь в таких условиях хоть капчу реализовать?
бля, братюнь. Какие несколько тысяч строк кода? Это буквально криейт тейбол и силект пассворд фром юзер.
Не очень понимаю бугурт про капчу. Тебя не просят сделать готовое к релизу приложение, просто нужно реализовать какую-то капчу. Не знаю, на чем там пишется, но можно сделать очень простую реализацию, которая будет подходить под критерии (которые, я уверен, выглядят как "покажи, что ты что-нибудь можешь сделать сам блядь").
И всё это не то же самое, что получить такой билетик рандомно на экзамене.
Учусь на гражданке, первый курсе иб связанный с телекомом.
Вуз с военным уклоном, но контракт подписывать не надо. В будущем хочу войти в коммерческий ИБ, а конкретней в реверс-инжиниринг, low-level security и exploit dev. По стеку сейчас ковыряю C/C++, асм, устройство виндоувса/линукса, пишу на пайтоне.
Собственно, вопрос к лидам и ИБшникам, которые работают в коммерции:
1. Насколько работодателей в РФ пугает/смущает диплом вуза с военным профилем? Нет ли какой-то предвзятости при найме?
2.Насколько в реверсе и фаззинге вообще смотрят на корочку, если на гитхабе будут нормальные пет-проекты?
Неужто это какой-то мем?
>войти в коммерческий ИБ,
Там нужны бумажки и брать на себе ответственность, без связей зп ниже среднего, с связями намного выше, но есть риски присесть.
>а конкретней в реверс-инжиниринг, low-level security и exploit dev.
в РФ ничего этого нет, может пара мест возьмут тебя за 100к, но ебашить только в добрый путь надо будет
>По стеку сейчас ковыряю C/C++, асм, устройство виндоувса/линукса, пишу на пайтоне.
что ты там ковыряешь то? те кто хотят как ты реверсом заниматься первым делом игры хакают и разбирают их, потому что практическая польза есть и хорошее обучение, затем крякают продукты не особо популярные и на которых нет кряков, без всего этого ты фактически ничего и не умеешь
>1. Насколько работодателей в РФ пугает/смущает диплом вуза с военным профилем? Нет ли какой-то предвзятости при найме?
если у тебя не должность где надо иметь этот диплом, то всем на него глубоко насрать, диплом только в отделе кадров нужен, в остальном всех интересует кто твоя семья и близкие, это куда важнее любых дипломов
>2.Насколько в реверсе и фаззинге вообще смотрят на корочку, если на гитхабе будут нормальные пет-проекты?
если у тебя пет проект это по факту реальный проект, то тебя сами позовут у кого есть такая нужда, как минимум на проект, но люди в основном читы разрабатывают в реверс направлении, конкуренция сейчас дикая в этой области, а главное нейронки с этим отлично справляются, да денуво они не ломанут потому что там некоторая смекалка нужна, но все остальное находят и ломают на ура
Аи это ярко показал и мне неприятно.
Похуй. Кодомакак изначально никто за илитариев не считал, был период хайпа в 10 лет, когда им стали платить чуть больше остальных батраков, теперь это поправили
Сейчас станет ещё неприятнее.
Ты мог бы стать великим писателем, чьи книги читали бы по всему миру, но ты сам выбрал копирайтинг, и твои тексты читают только поисковые боты. Так чего же ты хотел? Неча на ИИ пенять.
И кстати, всякие java и c++ есть смысл учить или уже совсем допотопно? Кстати, я по фрилансу в основном хочу работать. Англ на слух не пойму, так что СНГшному.
Решал булеву и реляционную алгебру на бумажке. Имплементил структуры данных на лабах. Делал поиск пути по A звездочка.
И шобы шо. Щас зумерки тупо за полгодика с нуля до джуна с ЛЛМкой вкатываются и вайбают.
Years of academy training wasted.jpg
У нас щас наняли джуна, 18 лвл. Поучился полгода в вузике, сказал залупа, перевелся на заочку. Пошёл на рыночег. Щас сидит вайбает джун задачки. Хотят апать до мидла(я голоснул за). У меня этот путь занял.
3 года само учебы
4 года уника.
1 год на первой работе где ливнул ибо легаси ад.
1 год на второй.
Очень тяжело...
>>22880
>я такой же как и ты, но безработный с февраля.
Какой стэк?
>Какой стэк
бекенд, в основном java/kotlin + go + python по мелочи
есть бак и магистратура из топ-5 вузов рф кстати, я 6 лет учился, ебать я лох
 101 Кб, 500x139
101 Кб, 500x139> дата аналитику
Человек-excel, задача которого статистики надоев и посевов для собраний собирать. Залупа.
> но понимаю что там нужна статистика, матан какой-то базовый.
Очень базовое понимание мат статистики. Распределения, отклонение, и тд. Психологини из гумвузов осиливают.
Нейронка не выручила
Имеется msys2 поставленная на win10
Если просто запустить ucrt46.exe всё ок, но по умолчанию открывается домашняя папка ~
Пытаюсь запустить ucrt через командную строку, так чтобы открылась текущая папка: C:\\msys64\\ucrt64.exe -cur_dir=%cd%
В этом случае ucrt запускается на секунду и закрывается. Никаких ошибок не возвращает.
То есть, если бы у него было достаточно памяти, я была бы всегда одна сессия, то я бы не отличил его от окружающих меня людей.
Зато /s/ выручит.
Понял одну вещь - когда начинает казаться что ии общается как личность, это значит что ты настроился с ии на одну волну и теперь будешь получать инфу от него эффективнее. Круто

>понять
Нейрокал не может понимать, это очевидно вот прямо сразу, так что никакого общения с генератором словесного поноса быть не может. Если ты даже этого не замечаешь, значит ты такой же дефективный урод уровня нейрокала который понимать не в состоянии. Только нейрокал не урод, он так сделан, а ты нет.
Он и не утверждает что может понять. Наоборот, говорит что он неодушевлен.
Я говорю лишь о том, что он подстраивается под пользователя в текущей сессии, и маркером того что он подстроился является то, когда пользователю кажется что он общается с личностью.
Этот же приём используют репетиторы.
Этот же приём пытаются использовать авторы сложных книг, понимая что не смогу получить фидбэк от каждого читателя и среагировать на него (тем самым увеличив популярность своей книги). Они изначально пытаются подавать материал простыми словами или даже играючи.
А ии может подстроится онлайн, в этом вижу огромный плюс для развития человечества.
Вы нейросектанты все ебанутые. Есть сраный чатбот, который собирает ответ из кусков как та китайская комната - обожемой оно меня понимает!!!11 Нет, не понимает, это просто набор коэффициентов.
Даунёнок, кто тебе говорит что оно что-то понимает. Ты читать умеешь? Перевожу на твой даунский язык - если кажется что ты общаешься как-будто бы с личностью, это значит ии правильно подобрал эти твои коэффициенты под тебя. Вот и всё.
Значит он будет предоставлять информацию именно так, как тебе нужно. Это и будет казаться как общение с живым человеком.
И если кто-то вдруг опасается что он псих и общается с неодушевлённым предметом, то он наоборот всё делает правильно, в этот момент канал доступа к информации собранной человечеством максимально открыт. Пользователь не свихнется, его мозг наоборот находится в привычной атмосфере общения, так как раньше небыло таких прецедентов.
Кринж же, там почти сразу привкус говна во рту.
Ее надо стегать кнутом. Строгие гайдлайны, постоянная валидация результата, минимум доступных инструментов, все что детерминированно может быть вскриптках сделать в них. Она должна сидеть и выбирать из нескольких строго ограниченных вариантов или автоматизировать такие действие где нельзя написать просто скрипт.
Отличный помощник + не скучно писать код + изучаю возможности чтобы понимать плюсы и минусы, чтобы быть в теме.
>Кринж
>2ch
Как-нибудь переживу)
Нахожу странным, что у тебя там есть привкус говна, а тут нет.
 261 Кб, 1100x819
261 Кб, 1100x819Шта блять? Экзамен для обучения?
Хз, но я проходил на стажировку, причем в 1С. Задачи ебаный в рот, я так понял они там для всех айтишников одинаковы на первом этапе. Я когда их увидел даже не пытался решить, что то по типу пикрила но сложнее. За нищенскую зп как на обычной галере пусть сами решают это, я не школьник заниматься ненужной хуйней

>Q: How does 2-Step Verification work?
>Logging in with an SMS code is an industry standard in messaging, but if you're looking for more security or have reasons to doubt your mobile carrier or government, we recommend protecting your cloud chats with an additional password.
:(
Т.е. по умолчанию там не пароля. :((





Нихуя нет
Раст здесь не при чём, это общая болезнь автоматического управления зависимостями, не обязательно даже в программировании. В том же линупсе стандартно явление, когда при установке мелкой утилиты выкачивается половина гнома и другой блоатвари.




Ты умеешь транскрипцию читать?
Ничего хорошего в этом всём нет, пидораст на расте видит хуйню и тащит её в проектик, в сишке это были бы пару файлов .c и .h, какая-нибудь жирная зависимость шла бы вместе с твоим дистрибутивом.
>какая-нибудь жирная зависимость шла бы вместе с твоим дистрибутивом
Которую конечный пользователь должен будет установить
Сайт запрашивает номер телефона для отправки СМС для регистрации, а сайты с номерами платные.
Раньше было приложение, которое регистрировали американской номер телефона. После 2022 года оно не работает.
Есть альтернатива?
Так я писал про бесплатные сайты.
На какой бирже завести кошелёк битка?
 40 Кб, 960x470
40 Кб, 960x470Так-с, посоны. Этот план перебьëт такую наносек-зарплату? Как вкатиться?


Конпелирую с -mcpu=cortex-m3 -mthumb
Когда пишу SVC handler на ассемблере (первый пикрил), на первой его инструкции кидает в hard fault, CFSR.UNDEFINSTR == 1
Если пишу на C (второй пикрил - листинг), всё нормально
Почему так?
О, круто, я тоже эту бурду ебу. Как стать таким же охуенным, как ты, и пердолить её на ассемблере? Оставишь тележку?
К примеру стек такой
pc
ebp
buff[2]
buff[1]
buff[0]
и мы можем относительно легко переписать pc
pc (buff[4])
ebp (buff[3])
buff[2]
buff[1]
buff[0]
а почему не делают на пк так?
pc
ebp
buff[0]
buff[1]
buff[2]
и про оверфлоу мы не перепишем pc и не будет shell скрипт и тд исполняться
Даже не знаю, какой язык хочу, но точно знаю, что не хочу программировать сайты и игры.
>Заканчиваю 3-й курс
>в шараге в мухосрани
>Как выкатиться в программирование?
>Ничего не умею и ничего не знаю
>Даже не знаю, какой язык хочу, но точно знаю, что не хочу программировать сайты и игры
Тебе в пвз или доставку. Без шуток.
Почему? Я не хочу всю оставшуюся жизнь корячиться на дноработе.
Я зашёл на сайт Media Player Classic https://mpc-hc.org
v1.7.13 выпущен July 16, 2017 с депрессивным комментарием "is released and farewell" от XhmikosR
при этом v1.7.9 выпущен June 01, 2015 XhmikosR
Что за некомпетентность? На самом деле версия 1.7.9 по нумерации новее чем 1.7.13, потому что девять десятых больше одной десятой. Это была грубая ошибка в нумерации версий.
И вообще что за депрессивность "выпущен и прощайте" это же отрытые исходники, к их написанию любой программист присоединиться может, а донаты существуют, я сам донаты делал.
Вообще нормальные люди-программисты после версии 1.7.9 выпускают 1.7.9.1, потом например 1.7.9.3 а потом 1.8.0
Десятичная у нас система, а не как у майя двадцатичетырёхричная, или какая она там? не помню точно. после 9 мы не ставим 13.
Послушай песню Летова "Суицид", всё поймёшь.
Вот тебе не по хуй? Все эти плееры это гуидятина над кодеками, уровень лаба1. Хотя педики из VLC все еще паузу по клику мышей не осилили.
> Но я хотел сисколл реализовать, а на чистом С это невозможно
А там нет возможности сделать типа
void foo(void) {
asm {
push yba
pop yba
srenk
}
}
?
 24 Кб, 450x600
24 Кб, 450x600Есть очень древняя программа, исходники потеряны.
В программе есть одна dll, внутри которой хранится текст sql запроса, execute block и беда в том, что длина одного поля ограничена varchar(64) и теперь этого мало, на новых данных возникают ошибка переполнения.
Есть ли средства поменять 64 хотя бы на 99 прямо в этой dll ?
Я очень давно касался всего этого, но... куда ты вставлял этот код? Ты можешь просто в strartup.s попробовать дописать вместо weak заглушки.
>Да хз, вроде всегда в thumb, негде ему переключиться
У тебя в начале .s файла должно быть вот это:
.syntax unified
.cpu cortex-m3
.thumb
>>24973
Так конечно можно, но это сложнее, нюанс в том в каких регистрах окажутся сишные переменные. Если же будешь писать код отдельных функций целиком на ассемблере, то достаточно просто соблюдать соглашения о вызовах.
В /s/ тебе расскажут о редакторах бинарных файлов.
 7 Кб, 224x224
7 Кб, 224x224>Пока подзабил; писать на асме под STM32 это вообще дурацкая идея, походу
Норм идея, под рукой нету затестить, открыл свой исходничек, вот обычный reset корректно работал:
[code]
.cpu cortex-m4
.thumb
.syntax unified
.global reset_handler
.type reset_handler, %function
reset_handler:
...
...
[/code]
Алсо, посмотри что там в isr, стоит ли thumb бит в адресе svc обработчика.
>но это сложнее
Ну разобраться в подобном не помешает, вангую у опа прост функцайка не помечена как thumb, поэтому переход на неё вызывает hard fault, в дизасме ты не увидишь thumb бит, надо на адрес смотреть в бранч инструкции или в значение isr векторе, выше уже озвучил, вангую там 0 в младшем бите, а твой проц не thumb инструкции не поддерживает, поетому и ошибка соответствующая. Ну ты там держи в курсе, самому интересно стало.
 418 Кб, 220x180
418 Кб, 220x180>Ну разобраться в подобном не помешает
Смотря кому. Мне так нафиг не нужно.
>вангую у опа прост функцайка не помечена как thumb
Так и я о том же. Но можно еще проще сделать. У анона по любому используется готовый startup.s с заглушками на все прерывания. И самое простое что можно сделать это дописать свой код в эту заглушку. Для пробы пусть хоть nop добавит.
Создай, только сделай норм шапку, без провокацией и без шитпоста
Зачем тебе два МВП-треда?
>паузу по клику мышей не осилили
Пиздец я тебя по всей борде вижу, шиза.
Ну нахуя тебе пауза по клику? По клику надо таскать.
Не ссы никто ниче не умел после шараги.
Подлизывайся к преподам, забей на протыклассников. Ближе к диплому еще к куратору подлизывайся. И так невзначай попроси рекомендацию для трудоустройства или хотя бы стажеровку. У них пиздец связи, и хоть обычно 99% челепупсов идут на кассу, 1% все таки устраиваются, и некоторые даже связь держат.
Закатывайся в поступашки и подавайся со всеми на стажки
Или есть другие опции (штурм не в счет) ?
>найти РАБотку
>без опыта
тут только крутить опыт или идти на неоплачиваемую многомесячную стажировку (если они еще остались)
Реально всё так плохо или эт только в смежных с вебом областях?
Вроде как год назад ещё реально было?
>только в смежных с вебом областях
нет, это везде
>Вроде как год назад ещё реально было?
зависит от локации, в моем городе все сдохло уже в середине 2к24 года
Ты нахуя отвечаешь на такую очевидную толстоту?
>Насколько пиздец по поиску работы
Полный пиздец
>>25820
>Заканчиваю колягу, нужно искать работу
Без шансов. Иди переучивайся на электрика/сантехника пока молодой.
>>25844
>Реально всё так плохо или эт только в смежных с вебом областях?
>Вроде как год назад ещё реально было?
В любом айти полный пиздец сейчас. Год назад было лучше чем сейчас, ситуация на рынке труда стремительно ухудшается.
>В любом айти полный пиздец сейчас. Год назад было лучше чем сейчас, ситуация на рынке труда стремительно ухудшается.
Когда будет нормализация?
Вряд ли в ближайшие 10 лет. Если про российский рынок труда говорить, то нормализация случится когда
1) закончится экономический кризис
2) снизятся процентные ставки
3) закончится гойда
4) со страны снимут санкции и снова придут западные работодатели
При этом всем нет гарантии что ИИ окончательно не уничтожит профессию целиком и есть вероятность даже при выполнении условий выше мы уже никогда не увидим адекватного рынка труда.
Лучше меняй профессию полностью.
Оператор бульдозера
>>26030
Да щас пиздец полный аноны правы, у меня конечно год опыта с профильной вышкой (бак+мага), да мало вводных, но блять даже такое есть не у всех. И все равно везде везде отказы, подаюсь на любой график, любую зп даже бесплатно, офис/удаленка не важно тоже, и везде отказы! Я делаю тестовые в каждой вакансии, пишу сопроводительные и хуй там плавал. Если про выкат думать то есть вариант в автосервисе, но пока опускаться на уровень профессиональности 9 класса школы не хочу. Очко горит что я буду работать не то что с птушниками, а с теми кто просто школу закончил...Ебаное айти, подаюсь даже заграницу где релокацию просят после оффера и тоже нихуя
Профессия гейткипер.
Нууу, слушай, тут я бы поспорил. Что зрачит опускаться до уровня пту? Я знаю что такое программирование, это не та профессия где требуется сверхвысокий интеллект. Ты буквально просто учишься правилам какого-то языка, как конструктору, а потом из этих деталей собираешь что-либо. Так что не переоценивай себя, ты не физик, не математик и не врач. То что у айтишников такие высокие зарплаты, так по моему мнению это плата за тотальное ноулайферство, за просиживанием штанов за компом 24/7, плата за одичалость и вечную зубрежку.
Тут анон наверное имел в виду, что в путяге одна быдлятина и гопники учатся.
Если в сервак хочешь пойти, то вкатывайся во что-нибудь связанное с электрикой. ПТУшники в основном всякой грязной работой занимаются.
Тут скорее общественное восприятие и зарплаты конечно же, мобильность по миру и т. д. Но в принципе мне жаль 6 лет которые я проебал на учебу чтобы остаться там где начинал будучи пиздюком 16 лет. Это самое обидное, пока писал пришел очередной отказ на работу в офисе за 40к на позиции джуна, с выполненным тестовым которое идеально функциональность делает и в принципе сложность была мидловая. Ну я не только на джуна подаюсь а ваще везде где могу. Видимо придеться забыть про гойти
>>26134
Да я думал, просто там надо начать с чего то чтобы в электрику податься, откуда с нуля буду знать почему пропуск зажигания например. Или в АКПП, но там как будто жеское пространственное мышление надо
>>26151
мяу, я тоже бак+магу окончил в околотоповом российском вузике + в бигтехе 4 года отработал. И вот уже 7 месяцев без работы сижу и ничего найти не могу. Всю мою команду сократили из бигтеха. Было 8 человек. Работу смогли найти только двое, и то, одного из них потом снова уволили. Остальные шестеро включая меня сидят дома без работы уже больше полугода. Пиздец.
Сейчас вернулся обратно в мухосрань из ДС жить с мамкой. И вероятно скоро на курсы электриков попиздую при местном ПТУ.
Надо было матан учить сейчас бы дата саентистом за 300к/месяц работал.
 333 Кб, 640x458
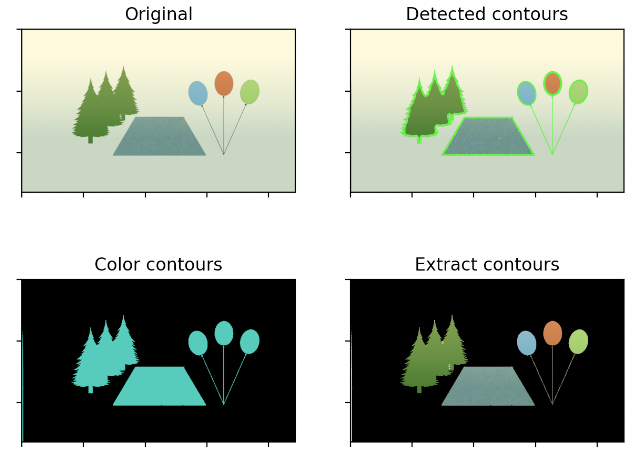
333 Кб, 640x458Анончики, подскажите пожалуйста как на плюсах оформить обход от 0 до N с разностью. Не помню как этот метод правильно называется, поэтому не могу найти гайды.
Задача такая:
1. Разложить картинку на RGB.
2. Выделить контуры объекта, по контрасту.
3. Сравнить его положение на кадре 1 и кадре 2.
то есть у нас есть 3 массива. R[x][y], G[x][y],B[x][y].
x_res = 1920
y_res = 1080
for (r[x]=0; r[x]=x_res; r[x]++)
r[x] = r[x] - r[x-1]
Тоже самое для Y, а потом по двум другим цветам.
Как правильно называется этот метод выделения контура? Помню что там по сути нужно было строить векторы за счёт разности соседних ячеек, но это правильно гуглить и как правильно оформить в коде - не пойму. Плюс. как задать маску по объекту, чтоб она была выше и шире на M пикселей?
Вообще. как это правильно называется. Никак не могу вспомнить.
>Да я думал, просто там надо начать с чего то чтобы в электрику податься, откуда с нуля буду знать почему пропуск зажигания например.
Мне с госуслуг приходило письмо о том, что можно за 5к пройти двухмесячные курсы при колледже летом. Я уже неиронично думаю туда пойти. Электриком можно стать, сантехником. Опять же полезные для жизни навыки.
Тебе хотя бы отвечают. Представь, когда ты много лет проработал и внезапно у хрюш в голове сработал скрипт и они перестали отвечать на сеньку. Ты типа стал слишком дохуя опытным и оверквалифаед. Отвечают на просто лида где-то 50% хрюш, на техлида 100%, но таких вакансий полторы на весь рынок.
Короче, беги отсюда, пока не поздно. Айти на ближайшие лет пять сдохло, пока пузырь не лопнет и кабаны не перестанут проебывать бабло в нейронки. Сейчас все ебанулись и сливают бабло в токены, хотя нанять живых людей дешевле.
Пузырь не лопнет, модели будут становиться лучше. Анальник теперь - дно работа за еду типа технолога на заводе. Смиритесь, прогресс вас порешал раньше, чем таксистов.
Работает через внешний пека? Ты уверен что это принесёт тебе профит? Не лучше ли взять опенсорс решения, чем ебаться с этим самому? Там подводных камней чуть больше чем дохуя.
Алсо, гарантирую что основная проблема будет не в контурах а в том чтобы продать, не на том сосредотачиваешься.
Я уже видел такую штуку для КС и батлы, но они работали на том же железе. А если через дублирование HDMI вывести на малинку или старый пека, то будет через виртуальный HID ебашить как MER1T. И попробуй докажи что не йоба-флик от гения OSU.
Так такое уже продаётся и в опенсорсе лежит, об этом и речь. Смысл делать своё, притом ты с конкретном алгоритмом можешь неделю ебаться. Погугли сначала, попробуй интегрировать свои идеи, если они есть, в существующий софт, можно ещё переписать через нейрокалыч.
Лол. Тут вся работа - это нештурм за 50к гривен или бесплатно через бусик. Дроны приезжают готовые из-за границы, задача хiхла донести дрон до точки и поставить на землю, дальше дрон улетает, а хiхла накрывает арта.



Это вакансии от тцк. Надо будет прийти на собеседование в офис, дальше сам понимаешь. Я на джини подавался несколько раз ради интереса в скаетон и прочие, никто даже мое резюме не скачал, но продолжают репостить неделя за неделей.
Сисяниг
Ну да, на передке будешь сидеть и программировать скотчем дрон. Да, так и будет. Да, военной тайны не существует, всё так, туда всех берут.
АРЯЯЯЯ НАХУЙ РАБОТЫ НЕТ 200 лет уже сижу пиржу на одну ваку сходил
АРЯЯЯ ДАЛБАЕБЫ АЙТИ ВСЁ
АРЯЯ БЛЯЯЯТЬ АРЯЯЯЯЯЯЯ АРЯЯЯЯ СУКААА АРЯЯЯЯЯ
>Нихуууя по делу в этих ебучих тредах, тока срач срач срач
Дебилы одни.
Сейчас идеальное время для проработки базы и самообучения.
Можно углубить знания, сделать все пед проекты которые хотел, сменить стек и т.д.
У степашек и тарасов один путь - на передок. Сколько бы лошков не промывали что есть программирование контроллеров - всё это пиздёж военкома.
Выглядит как бклто сделано на делфи, но проги из делфи без проблем можно портануть.
.net + winforms/wpf скорее всего.
можно при помощи вайбкодинга портировать на c++/pyton+qt либо на java+swing либо на electrone и тогда можно будет на линухе запускать
Кроссплатформенность дотнета очень условная и в основном касается только серверов, да и то не всех.
Если же кто-то напишет GUI на винформах/впф/увп/мауи, на линупс ты такую программу портанёшь только через Wine.
не бойся малютка, 100% терминов это хуйня по типу ЭЭЭ НУ У МЕНЯ ФУНКЦИИ ПОСТЕПЕННО ВЫПОЛНЯЮТСЯ А ЕСЛИ ЧОТО УПАДЕТ ТО Я НАПИСАЛ ФУНКЦИЮ ЧТОБЫ БДШКА ВСЕ ОТКАТЫВАЛА, вот это буквально описание саги например
и так со всем, ты как только поймешь что анальникам просто нравятся сложные и непонятные слова, то все станет намного проще и как-то даже забавнее
А некоторые вообще на валютную удалёнку попадают и делают х2-3 от того что ты получаешь, просто зазубрив собесы
Стоит ли из-за этого расстраиваться? Всегда были пробивные и уникумы, винить разве что можно себя, что ты комфортно дрочил писю на парах.
>портанёшь только через Wine
Пытался запустить через wine, он даже окно с ошибкой не высветил.
Если что прогу он делает уже лет 15, и я сомневаюсь что он переписывал её с нуля хоть раз.
>без проблем можно портануть
Охуеешь выпиливать работу с реестром.
Второй раз охуеешь когда будешь фиксить работу с файлами и кодировками.
И это пока чисто уметь сохранять состояние проги.
повтори и не делай ошибок
Сурс-то есть? Если есть, скажи Искуственному Интеллекту чтобы портанул её под ДжаваСвинг и всё пойдет
>на чом он там мог её написать?
она может быть завязана на WinAPI почему-то или на каком-нибудь COM / OLE, знависит от того что она там делает на самом деле.
тогда нюхай UDP пакеты и показывай ИИшке что на табло выводится и скажи "сделай так же, только без ошибок"
на Java/Swing/FlatLaf
Очевидно же, что к анону с двача больше доверия, чем к дотнет-разрабу IRL.
>Ну да, на передке будешь сидеть и программировать скотчем дрон. Да, так и будет. Да, военной тайны не существует, всё так, туда всех берут.
>>27317
>Лол. Тут вся работа - это нештурм за 50к гривен или бесплатно через бусик. Дроны приезжают готовые из-за границы, задача хiхла донести дрон до точки и поставить на землю, дальше дрон улетает, а хiхла накрывает арта.
Вот это у вас некопиум... Занося дяде военкому энную сумму денег в месяц можно быть перманентно неприкасаемым, по крайней мере с его стороны.
Про $7000+ зепку — это пиздеж, конечно, но $3-4k можно иметь спокойно. Вот этот прикол про "зарплата от ... до ..." — старая история. Конечно же тебе будут платить зарплату "от".
По поводу "а что если меня засунут в бусик и выкинут с пулемётом на переводой" — опасность есть, но это дело намного менее хаотично, чем некоторым кажется. Да, есть совершенно отмороженные челы, но если у тебя документы в порядке, то тебя вернут с учебки, а отморозков из ТЦК посадят на бутылку. Сильнее всего ебут тех, кто пытался за сало купить белый билет.
>>27432
>Я на джини подавался несколько раз ради интереса в скаетон и прочие, никто даже мое резюме не скачал, но продолжают репостить неделя за неделей.
Я недавно начала работать, тоже имел проблеы с тем, что никто не откликался на мои резюме. Но нужно понимать, что сейчас в целом в IT работников меньше, чем рабочих мест — твоё резюме могут выкинуть в мусорник, даже не отвечая.
Меня так в одно место не взяли, и я от своего знакомого-инсайдера оттуда узнал, почему. Просто прочитали резюме, сказали "хуйня, не подойдёт" — и пошли дальше. Добро пожаловать в айти в 2026 году.
>если у тебя документы в порядке
Ты как пятилетний ребенок. Да им поебать на твои документы, посидишь неделю на подвале и поедешь в скэлю. В тцк наглухо отбитое зверье, их надо сжигать заживо нахуй. У кого доки в порядке, те давно съебали из этой параши мрий.
>Я недавно начала работать
А, так ты поридж. Вопросов нет.
>Да им поебать на твои документы, посидишь неделю на подвале и поедешь в скэлю.
Ты в курсе, что рандомного дядю с улицы не могут послать сразу в окоп? ТЦК не может никого послать в окоп, потому что не ТЦК людей в окоп отправляет. Сначала всегда учебка — а это нихуя не окоп.
(хотя, я не исключаю, что за последний год практика поменялась)
>У кого доки в порядке, те давно съебали из этой параши мрий.
Лол, так я и съебал.
>А, так ты поридж. Вопросов нет.
Я седой скуф.
>Лол, так я и съебал.
Мое увожение. Нехуй тут делать.
>Ты в курсе, что рандомного дядю с улицы не могут послать сразу в окоп?
В курсе. Сперва ты за 2 минуты проходишь медкомиссию. Потом пиздуешь в учебку, где тебя конвоируют под автоматом даже в туалет и где можно внезапно умереть "от пневмонии". Не смог съебать из учебки - пиздуешь в окоп без оружия, будешь сидеть там приманкой для дронов. Попытаешься съебать или сдаться - замочат ублюдки мадяра. В итоге мотивация отрицательная. Если бы на российской стороне у генералов был интеллект выше комнатной температуры и вместо пуляния орешниками по сараям они бы сосредоточились на ебке дрономразей, хихлоармия давно бы уже разбежалась, все ебали воевать на зеленое говно.
>Сперва ты за 2 минуты проходишь медкомиссию.
Опять же, у меня старые данные, может быть что-то поменялось. Ты реально проходишь медкомиссию под конвоем, и не за 2 минуты. Раньше просто факт того, что тебя забрали с нарушениями, мог быть поводом для твоего возврата — при условии, что ты сам ничего не нарушал. Недавно я видел, что эту малину отменили и возвращать людей стало сложнее. Ну то есть в 2024 мне гарантировали, что если меня заберут, то 100% вернут обратно — сейчас не знаю.
Никакой проблемы со средствами связи в учебке не было в том плане, что они разрешены в отведённых местах и часах. Учебка уже не находится в юрисдикции ТЦК, если чо.
>Не смог съебать из учебки - пиздуешь в окоп без оружия, будешь сидеть там приманкой для дронов. Попытаешься съебать или сдаться - замочат ублюдки мадяра. В итоге мотивация отрицательная.
Если бы мотивация была настолько отрицательной, то все бы либо тушкой, либо чучелком посъебывали бы. Но по факту люди выполняют служебные обязанности. У меня бывший одноклассник чуть не умер, пытаясь прорваться из окружения. Нахуя он это сделал? Ты уже в окружении, тебе никакие мадяры не помогут. Но нет, "я хочу домой, к маме-папе, я просто тут отслужу, как все, честно-порядочно, надо значит надо". В его отбитую сапогами голову не приходит мысль, что у него намного выше шанс вернуться домой из плена (а ещё лучше вообще не возвращаться).
При нынешней архихуёвой и бесперспективной ситуации мотивация там как раз очень хорошая.
>Если бы на российской стороне у генералов был интеллект выше комнатной температуры и вместо пуляния орешниками по сараям
Подстанции и ОРУ, нефтебазы, мосты через Днепр (там некоторые мосты своей смертью умирают от ржавчины) — всё, дохуя ты навоюешь без электричества, топлива, и логистики? По Банковой ни разу не били вообще.
>Конторе приказали портировать их поделие с венды под Астру, а они просто подложили туда wine и получили огромный грант за обеспечение совместимости с отечественной ОС. На бумаге всё отлично, а вот на деле то, это как по мне чистое наебалово.
В РФ спиздили деньги... Никогда такого не было...
>На бумаге всё отлично, а вот на деле то, это как по мне чистое наебалово. Я хз как такое контрить.
В реальности все как сидели на винде так и сидят.
Старые системы не трогают, а вот новые заставляют сразу на всяких астрах и т.д.
>В РФ спиздили деньги
На это деньги как раз никто специально не даёт. Просто говорят что в этом году в закупках нужно только импортнозамещённое, нужна буквально бумажа с печатью.
Они связанны между собой, например, у этого человека хранится эта вещь в этом месте.
Программу хочу по типу интерактивных графов. Например: вкладка окна "вещи", открываешь и там сетка из картинок всех вещей. Кликаешь на картинку, картинка, остаётся на экране, а окно под ним заменяется на окно графа где появляются картинки человека и места, например, направленная связь: слева картинка-человекот него направленная связь к нашей вещи, а от вещи направленая связь к картинке-место.
Причем, в этом окне можно крикнуть на человека и откроются все связи " человек - другие вещи - другие места".
Сделать связи в виде графов я уже догадался и попробовал программку graphviz. Нашёл что она может (из файла-описания одного-единственного графа) делать svg картинку. Мысль: можно окна программы создавать как картинку svg и этот формат использует xml-формат графического описания svg картинки возможно можно анимировать, ну, типа изменяя xml-документ на лету - менять изображение, двигать и создавать, удалять узлы и связи графа - фактически это будет анимация в окне программы. И вроде XSLT-язык позволяет преобразовывать xml-файл налету.
Тоесть вроде есть вариант использовать связку из graphviz (с svg-выводом) и язык XSLT - получать анимированную интерактивную svg (далее - как-то впихнуть в окно винды или андроида.
Но определённые минусы:
- XML файлы менять нельзя вроде.
- Винда загркжает XML файлы в оперативку как DOM- обьекты, тоесть файл в 100МБ займёт 4ГБ оперативки, как пример. Хотя вроде есть реализация поэлементной загрузки xml-документа в некоторых интерпретируемых языках программирования. Тоесть не жрать память что бы отобразить граф "три картинки и связи".
- xml вроде не предназначен для такой анимации (поэтому я выделил выше несколько вроде). Типа символьный(текстовый) формат документа сам по себе не очень.
Поэтому есть ещё вариант модуль для Python от graphviz.
Или реализация интерактивной анимации через SVG.js (под Javascript).
Тоесть плюнуть на XML и учить питон или джаву. Делать свой новый свежий костыль на однлм из них. Питон маленько ковврял, писал в две строки парсерворующий инфу с одного сайта (с злым антипарсером). Иследовал пандасы как медленный не асинхронный библиотэк, быстрые асинхронки пытаюсь найти (но это тоже хобби, поэтому не спешу). Javascript ни разу не трогал, но думаю там тоже поиском/подбором JSкостылей и JSмодулей вместо 50строчного найти инклюды для замены кодом в те же 2 строки.
TLDR:
Что посоветуете, писать всё через хрени для xml,
или питоны, жээсы. Или же есть что-то более изящное для создания программы-гайда. Учитывпя чьл у меня высокие требования к дизайну окон/вкладок программы. Думаю, больше времент займёт оформление визуал-дизайна, быстродействие на машинах даже с 4ГБ оставшейся свободного места оперативы (хайд планирую юзать одновременно с занимаюшей операьивку открытой другой прошраммой (видеоигра).
Так же там будет вестись чекин выполненные/незавершенные задания (ветки графа).
Они связанны между собой, например, у этого человека хранится эта вещь в этом месте.
Программу хочу по типу интерактивных графов. Например: вкладка окна "вещи", открываешь и там сетка из картинок всех вещей. Кликаешь на картинку, картинка, остаётся на экране, а окно под ним заменяется на окно графа где появляются картинки человека и места, например, направленная связь: слева картинка-человекот него направленная связь к нашей вещи, а от вещи направленая связь к картинке-место.
Причем, в этом окне можно крикнуть на человека и откроются все связи " человек - другие вещи - другие места".
Сделать связи в виде графов я уже догадался и попробовал программку graphviz. Нашёл что она может (из файла-описания одного-единственного графа) делать svg картинку. Мысль: можно окна программы создавать как картинку svg и этот формат использует xml-формат графического описания svg картинки возможно можно анимировать, ну, типа изменяя xml-документ на лету - менять изображение, двигать и создавать, удалять узлы и связи графа - фактически это будет анимация в окне программы. И вроде XSLT-язык позволяет преобразовывать xml-файл налету.
Тоесть вроде есть вариант использовать связку из graphviz (с svg-выводом) и язык XSLT - получать анимированную интерактивную svg (далее - как-то впихнуть в окно винды или андроида.
Но определённые минусы:
- XML файлы менять нельзя вроде.
- Винда загркжает XML файлы в оперативку как DOM- обьекты, тоесть файл в 100МБ займёт 4ГБ оперативки, как пример. Хотя вроде есть реализация поэлементной загрузки xml-документа в некоторых интерпретируемых языках программирования. Тоесть не жрать память что бы отобразить граф "три картинки и связи".
- xml вроде не предназначен для такой анимации (поэтому я выделил выше несколько вроде). Типа символьный(текстовый) формат документа сам по себе не очень.
Поэтому есть ещё вариант модуль для Python от graphviz.
Или реализация интерактивной анимации через SVG.js (под Javascript).
Тоесть плюнуть на XML и учить питон или джаву. Делать свой новый свежий костыль на однлм из них. Питон маленько ковврял, писал в две строки парсерворующий инфу с одного сайта (с злым антипарсером). Иследовал пандасы как медленный не асинхронный библиотэк, быстрые асинхронки пытаюсь найти (но это тоже хобби, поэтому не спешу). Javascript ни разу не трогал, но думаю там тоже поиском/подбором JSкостылей и JSмодулей вместо 50строчного найти инклюды для замены кодом в те же 2 строки.
TLDR:
Что посоветуете, писать всё через хрени для xml,
или питоны, жээсы. Или же есть что-то более изящное для создания программы-гайда. Учитывпя чьл у меня высокие требования к дизайну окон/вкладок программы. Думаю, больше времент займёт оформление визуал-дизайна, быстродействие на машинах даже с 4ГБ оставшейся свободного места оперативы (хайд планирую юзать одновременно с занимаюшей операьивку открытой другой прошраммой (видеоигра).
Так же там будет вестись чекин выполненные/незавершенные задания (ветки графа).
>Просто говорят что в этом году в закупках нужно только импортнозамещённое, нужна буквально бумажа с печатью.
Ну так получи бумажку с печатью. Ты как маленький, ей богу. Там вон по бумажкам в РФ импортозамещённый автопром.
>>28571
Классная идея — всё логично и уже много продумано. Ниже — аккуратно сгруппированные рекомендации и конкретные варианты реализации, плюс практический план MVP: что быстрее прототипировать, а что лучше для финального продукта с хорошим дизайном и производительностью (особенно если на машине мало RAM).
Сначала — короткий вывод (если торопитесь):
- Для быстрого прототипа с минимумом нового языка: Python + Dash (dash-cytoscape) — интерактивный граф в браузере/окне, легко оперировать данными и изображениями. Desktop-пакетирование возможно, Android — хуже.
- Для кроссплатформы (Windows + Android) и современного UI/UX: Web-frontend (React/Vue) + библиотека графов (Cytoscape.js / Sigma.js / vis-network / React Flow) + упаковка как PWA для Android и как нативное приложение (Tauri — лёгкий) для Windows.
- Если готов учить Dart и хотите «нативный» на обоих платформах: Flutter — мощный, но экосистема визуализации графов более ограничена (придётся писать часть рендеринга самому).
- Избегайте подхода «генерировать огромный SVG/XML и крутить XSLT» — SVG полезен, но не как monolithic DOM для больших/динамичных графов: DOM-память и перерисовки быстро убьют производительность.
Дальше — подробности по вариантам, плюсы/минусы и рекомендации по архитектуре.
1) Почему не хранить/анимировать один большой SVG/XML
- Большой XML/SVG = огромный DOM в памяти; браузеры/движки загружают узлы в DOM, это затратнее, чем динамическая отрисовка. Для графа с сотнями узлов DOM быстро растёт и тормозит.
- XSLT можно применять, но трансформации XML в реальном времени — дорого и не дают гибкой UI-логики (жесты, плавность, виртуализация).
- SVG хорош для отдельных элементов и для векторной графики, но интерактивные/масштабируемые графы лучше рисовать динамически (canvas / WebGL / целенаправленное SVG с контролируемым количеством DOM-элементов).
2) Что лучше по рендерингу: SVG vs Canvas vs WebGL
- SVG — удобно для небольших графов (< ~200 узлов), лёгкая обработка событий и стилизация через CSS.
- Canvas — быстрее для среднего/крупного количества примитивов, но требует ручной обработки кликов/хитов (hit-testing) и управления сценой.
- WebGL — лучший выбор для больших графов (1000+ узлов), обеспечивает GPU-ускорение; библиотеки типа sigma.js используют WebGL и дают хорошую интерактивность.
Рекомендация: для начала используйте SVG (Cytoscape.js или vis.js), если профиль пользователей — немного узлов и важен внешний вид. Если ожидаете много узлов/виртуальное отображение — WebGL (sigma.js) или гибрид.
3) Конкретные библиотеки и стеки (с указанием, зачем каждая)
- JS (рекомендую для UI/дизайна и кроссплатформенности)
- Cytoscape.js — мощная, хорошая для связных сетей, расширяемая, удобная интерактивность (поддерживает графы направленные, стили, расширения).
- sigma.js — WebGL-рендеринг, быстрый на больших графах.
- vis-network — прост в освоении, но стало реже поддерживаем.
- D3.js — для кастомной визуализации (больше контроля, больше работы).
- React + React Flow — если хотите node-based UI (drag/drop), но для чистых сетей лучше cytoscape/sigma.
- UI: React + MUI / Tailwind — быстро сделать красивые вкладки/галереи/панели.
- Для анимаций и управления SVG: SVG.js или просто используйте функционал библиотек выше.
- Packaging: Tauri (малый вес, безопаснее) или Electron (проще, но «тяжёлый»).
- Для Android: сделать PWA (установляемое приложение через браузер) или использовать Capacitor / Cordova — но PWA проще и быстрым решением.
- Python (если хотите остаться в Python)
- Dash + dash-cytoscape — позволяет делать web-приложение на Python, быстро прототипировать графы и UI (Dash поддерживает callbacks для кликов и динамической подгрузки).
- Streamlit — быстрее прототип, но менее гибкий для интерактивных графов (есть плагины).
- PyQt / PySide (Qt) — можно сделать полноценную настольную GUI, но портирование на Android непростое (Qt for Android есть, но сложнее).
- Упаковка: PyInstaller для Windows exe; для Android — Kivy или BeeWare, но это сложнее.
- Если Python — рекомендую Dash (веб-интерфейс локально), потом оборачивать во фронт-обёртку для Desktop.
- Flutter (Dart)
- Отличный UI, кроссплатформенность (Windows + Android + iOS).
- Экосистема графовых библиотек поменьше; придётся писать кастомный рендеринг на Canvas.
- Рекомендовано, если готовы учить Dart и хотите «нативный» интерфейс с отличным UX.
4) Архитектура данных и хранения изображений (важно для памяти/скорости)
- База: SQLite (локально) — идеально для настольных / мобайл приложений, ACID, простой.
- Таблицы: nodes(id, type ['thing'/'person'/'place'], title, image_path, thumbnail_path, metadata/json), edges(id, source_node_id, target_node_id, relation_type, metadata).
- Таблица tasks/checkins(id, node_id, status, note, timestamp).
- Изображения: не храните большие оригиналы в базе. Храните файлы на диске, в записи — путь и небольшие превью (размеры: thumbnail 128px, grid 256px, full 1024px).
- Генерируйте thumbnails заранее (или при первом запросе) и кэшируйте.
- Lazy loading: подгружайте только миниатюры для сетки и подгружайте большие изображения при открытии/фокусе.
- Сервер/локальный API: небольшая локальная служба (FastAPI/Flask для Python, либо встроенный static-файловый сервер у фронтенда) -> фронтенд запрашивает JSON/пагинацию/графы.
5) Производительность и экономия памяти (очень важна для 4GB RAM)
- Не загружать весь граф в память/DOM сразу — используйте «lazy expand»: показывайте только соседей выбранной ноды; при клике на узел загружайте соседей с сервера/БД.
- В галереях/сетках используйте виртуализацию списков (react-window / virtualization) — DOM держит только видимые элементы.
- Кэширование на диске и в памяти ограниченного размера (LRU).
- Для больших сетей — использовать WebGL-рендерер (sigma.js).
- Выполняйте тяжёлую обработку (поиск, layout) в воркерах / отдельном процессе, чтобы UI не «подвисал».
6) UX / интерфейс — как вы описали, и что добавить
- Вкладки: «Вещи», «Люди», «Места», «Поиск / Фильтры», «Задачи/Чекины».
- Основной экран: сетка миниатюр (виртуализированная) — при клике миниатюра «приклеивается» (pin) в левом/верхнем углу, справа/под ней — pane с графом (где отображаются связанные люди/места).
- Граф: направленные связи, стрелки, подписи типа «хранится», «принадлежит», «находится в».
- Навигация: клики по узлам — динамическая экспансия соседей; кнопки «развернуть на уровень», «показать всё», «свернуть».
- Breadcrumbs/history для возврата и истории навигации.
- Панель задач/чеков: отмечать node как «выполнено», «в процессе» и отображать список задач, фильтры по статусу.
- Сохранение layout (позиции узлов) для UX: пользователю приятно, если при возврате nodes остаются в тех же местах.
- Анимации: плавные переходы при добавлении/удалении узлов (CSS/SVG transition или библиотечные анимации).
7) MVP (пошаговый план — сделать быстро и проверить концепт)
- Шаг 0: подготовка данных. Первая версия: JSON с 5–10 вещей, 5 людей, 5 мест и примерами связей + миниатюры.
- Шаг 1: прототип UI в браузере (React/Vue) или Dash:
- Слева — сетка картинок (из JSON), при клике — pin и запрос соседей.
- Справа — рендер графа соседей с библиотекой (Cytoscape.js или dash-cytoscape).
- Шаг 2: добавить lazy-loading соседей (вместо загрузки всего JSON) — имитировать API.
- Шаг 3: добавить метаданные, статусы задач и простую систему чек-ин/чек-аут (локально в JSON/SQLite).
- Шаг 4: добавить thumbnail-генерацию, pagination, виртуализацию.
- Шаг 5: упаковка: Tauri (Windows) + PWA (Android) или просто PWA (если нужно сначала только Android).
- Шаг 6: оптимизация: при необходимости перейти на sigma.js (WebGL) для больших графов.
8) Рекомендации по выбору для вашего текущего опыта
- Вы немного знакомы с Python и не трогали JS. Самый быстрый способ получить интерактивный прототип — Dash + dash-cytoscape:
- Плюсы: писать почти всё на Python, быстрый proto, много примеров, удобные callbacks.
- Минусы: интерфейс — «веб», упаковка под Android сложнее (лучше ориентировать на Desktop/Browser).
- Если хотите действительно красивый интерфейс и кросплатформу (Windows + Android) — учить JS/React и использовать Cytoscape.js + Tauri/PWA. Learning curve выше, но результат — гибче и «побольше control» над UX.
- Если хотите «нативный» и готовы учить Dart — Flutter — хорошая опция, но придётся реализовать/адаптировать графовую визуализацию.
9) Практические советы по tooling
- Backend (если нужен): SQLite + FastAPI (очень удобен и быстрый), либо всё делать клиент-сайд с JSON для MVP.
- Thumbnailing: Pillow (Python) или sharp (node) — генерировать 3 размера.
- Local packaging: Tauri (рекомендую) — заметно легче Electron.
- Для Desktop-native embedding Python web UI: pywebview (обёртка браузерного окна), но Tauri даёт более современный подход.
- Лэйаут графа: используйте force-directed layout для автоматической расстановки, но дайте пользователю фиксировать/перемещать узлы вручную.
Напишите ответы — и я подготовлю конкретный прототип (Python Dash) или шаблон на React+Cytoscape, + дам инструкции по упаковке в Windows/Android.
>>28571
Классная идея — всё логично и уже много продумано. Ниже — аккуратно сгруппированные рекомендации и конкретные варианты реализации, плюс практический план MVP: что быстрее прототипировать, а что лучше для финального продукта с хорошим дизайном и производительностью (особенно если на машине мало RAM).
Сначала — короткий вывод (если торопитесь):
- Для быстрого прототипа с минимумом нового языка: Python + Dash (dash-cytoscape) — интерактивный граф в браузере/окне, легко оперировать данными и изображениями. Desktop-пакетирование возможно, Android — хуже.
- Для кроссплатформы (Windows + Android) и современного UI/UX: Web-frontend (React/Vue) + библиотека графов (Cytoscape.js / Sigma.js / vis-network / React Flow) + упаковка как PWA для Android и как нативное приложение (Tauri — лёгкий) для Windows.
- Если готов учить Dart и хотите «нативный» на обоих платформах: Flutter — мощный, но экосистема визуализации графов более ограничена (придётся писать часть рендеринга самому).
- Избегайте подхода «генерировать огромный SVG/XML и крутить XSLT» — SVG полезен, но не как monolithic DOM для больших/динамичных графов: DOM-память и перерисовки быстро убьют производительность.
Дальше — подробности по вариантам, плюсы/минусы и рекомендации по архитектуре.
1) Почему не хранить/анимировать один большой SVG/XML
- Большой XML/SVG = огромный DOM в памяти; браузеры/движки загружают узлы в DOM, это затратнее, чем динамическая отрисовка. Для графа с сотнями узлов DOM быстро растёт и тормозит.
- XSLT можно применять, но трансформации XML в реальном времени — дорого и не дают гибкой UI-логики (жесты, плавность, виртуализация).
- SVG хорош для отдельных элементов и для векторной графики, но интерактивные/масштабируемые графы лучше рисовать динамически (canvas / WebGL / целенаправленное SVG с контролируемым количеством DOM-элементов).
2) Что лучше по рендерингу: SVG vs Canvas vs WebGL
- SVG — удобно для небольших графов (< ~200 узлов), лёгкая обработка событий и стилизация через CSS.
- Canvas — быстрее для среднего/крупного количества примитивов, но требует ручной обработки кликов/хитов (hit-testing) и управления сценой.
- WebGL — лучший выбор для больших графов (1000+ узлов), обеспечивает GPU-ускорение; библиотеки типа sigma.js используют WebGL и дают хорошую интерактивность.
Рекомендация: для начала используйте SVG (Cytoscape.js или vis.js), если профиль пользователей — немного узлов и важен внешний вид. Если ожидаете много узлов/виртуальное отображение — WebGL (sigma.js) или гибрид.
3) Конкретные библиотеки и стеки (с указанием, зачем каждая)
- JS (рекомендую для UI/дизайна и кроссплатформенности)
- Cytoscape.js — мощная, хорошая для связных сетей, расширяемая, удобная интерактивность (поддерживает графы направленные, стили, расширения).
- sigma.js — WebGL-рендеринг, быстрый на больших графах.
- vis-network — прост в освоении, но стало реже поддерживаем.
- D3.js — для кастомной визуализации (больше контроля, больше работы).
- React + React Flow — если хотите node-based UI (drag/drop), но для чистых сетей лучше cytoscape/sigma.
- UI: React + MUI / Tailwind — быстро сделать красивые вкладки/галереи/панели.
- Для анимаций и управления SVG: SVG.js или просто используйте функционал библиотек выше.
- Packaging: Tauri (малый вес, безопаснее) или Electron (проще, но «тяжёлый»).
- Для Android: сделать PWA (установляемое приложение через браузер) или использовать Capacitor / Cordova — но PWA проще и быстрым решением.
- Python (если хотите остаться в Python)
- Dash + dash-cytoscape — позволяет делать web-приложение на Python, быстро прототипировать графы и UI (Dash поддерживает callbacks для кликов и динамической подгрузки).
- Streamlit — быстрее прототип, но менее гибкий для интерактивных графов (есть плагины).
- PyQt / PySide (Qt) — можно сделать полноценную настольную GUI, но портирование на Android непростое (Qt for Android есть, но сложнее).
- Упаковка: PyInstaller для Windows exe; для Android — Kivy или BeeWare, но это сложнее.
- Если Python — рекомендую Dash (веб-интерфейс локально), потом оборачивать во фронт-обёртку для Desktop.
- Flutter (Dart)
- Отличный UI, кроссплатформенность (Windows + Android + iOS).
- Экосистема графовых библиотек поменьше; придётся писать кастомный рендеринг на Canvas.
- Рекомендовано, если готовы учить Dart и хотите «нативный» интерфейс с отличным UX.
4) Архитектура данных и хранения изображений (важно для памяти/скорости)
- База: SQLite (локально) — идеально для настольных / мобайл приложений, ACID, простой.
- Таблицы: nodes(id, type ['thing'/'person'/'place'], title, image_path, thumbnail_path, metadata/json), edges(id, source_node_id, target_node_id, relation_type, metadata).
- Таблица tasks/checkins(id, node_id, status, note, timestamp).
- Изображения: не храните большие оригиналы в базе. Храните файлы на диске, в записи — путь и небольшие превью (размеры: thumbnail 128px, grid 256px, full 1024px).
- Генерируйте thumbnails заранее (или при первом запросе) и кэшируйте.
- Lazy loading: подгружайте только миниатюры для сетки и подгружайте большие изображения при открытии/фокусе.
- Сервер/локальный API: небольшая локальная служба (FastAPI/Flask для Python, либо встроенный static-файловый сервер у фронтенда) -> фронтенд запрашивает JSON/пагинацию/графы.
5) Производительность и экономия памяти (очень важна для 4GB RAM)
- Не загружать весь граф в память/DOM сразу — используйте «lazy expand»: показывайте только соседей выбранной ноды; при клике на узел загружайте соседей с сервера/БД.
- В галереях/сетках используйте виртуализацию списков (react-window / virtualization) — DOM держит только видимые элементы.
- Кэширование на диске и в памяти ограниченного размера (LRU).
- Для больших сетей — использовать WebGL-рендерер (sigma.js).
- Выполняйте тяжёлую обработку (поиск, layout) в воркерах / отдельном процессе, чтобы UI не «подвисал».
6) UX / интерфейс — как вы описали, и что добавить
- Вкладки: «Вещи», «Люди», «Места», «Поиск / Фильтры», «Задачи/Чекины».
- Основной экран: сетка миниатюр (виртуализированная) — при клике миниатюра «приклеивается» (pin) в левом/верхнем углу, справа/под ней — pane с графом (где отображаются связанные люди/места).
- Граф: направленные связи, стрелки, подписи типа «хранится», «принадлежит», «находится в».
- Навигация: клики по узлам — динамическая экспансия соседей; кнопки «развернуть на уровень», «показать всё», «свернуть».
- Breadcrumbs/history для возврата и истории навигации.
- Панель задач/чеков: отмечать node как «выполнено», «в процессе» и отображать список задач, фильтры по статусу.
- Сохранение layout (позиции узлов) для UX: пользователю приятно, если при возврате nodes остаются в тех же местах.
- Анимации: плавные переходы при добавлении/удалении узлов (CSS/SVG transition или библиотечные анимации).
7) MVP (пошаговый план — сделать быстро и проверить концепт)
- Шаг 0: подготовка данных. Первая версия: JSON с 5–10 вещей, 5 людей, 5 мест и примерами связей + миниатюры.
- Шаг 1: прототип UI в браузере (React/Vue) или Dash:
- Слева — сетка картинок (из JSON), при клике — pin и запрос соседей.
- Справа — рендер графа соседей с библиотекой (Cytoscape.js или dash-cytoscape).
- Шаг 2: добавить lazy-loading соседей (вместо загрузки всего JSON) — имитировать API.
- Шаг 3: добавить метаданные, статусы задач и простую систему чек-ин/чек-аут (локально в JSON/SQLite).
- Шаг 4: добавить thumbnail-генерацию, pagination, виртуализацию.
- Шаг 5: упаковка: Tauri (Windows) + PWA (Android) или просто PWA (если нужно сначала только Android).
- Шаг 6: оптимизация: при необходимости перейти на sigma.js (WebGL) для больших графов.
8) Рекомендации по выбору для вашего текущего опыта
- Вы немного знакомы с Python и не трогали JS. Самый быстрый способ получить интерактивный прототип — Dash + dash-cytoscape:
- Плюсы: писать почти всё на Python, быстрый proto, много примеров, удобные callbacks.
- Минусы: интерфейс — «веб», упаковка под Android сложнее (лучше ориентировать на Desktop/Browser).
- Если хотите действительно красивый интерфейс и кросплатформу (Windows + Android) — учить JS/React и использовать Cytoscape.js + Tauri/PWA. Learning curve выше, но результат — гибче и «побольше control» над UX.
- Если хотите «нативный» и готовы учить Dart — Flutter — хорошая опция, но придётся реализовать/адаптировать графовую визуализацию.
9) Практические советы по tooling
- Backend (если нужен): SQLite + FastAPI (очень удобен и быстрый), либо всё делать клиент-сайд с JSON для MVP.
- Thumbnailing: Pillow (Python) или sharp (node) — генерировать 3 размера.
- Local packaging: Tauri (рекомендую) — заметно легче Electron.
- Для Desktop-native embedding Python web UI: pywebview (обёртка браузерного окна), но Tauri даёт более современный подход.
- Лэйаут графа: используйте force-directed layout для автоматической расстановки, но дайте пользователю фиксировать/перемещать узлы вручную.
Напишите ответы — и я подготовлю конкретный прототип (Python Dash) или шаблон на React+Cytoscape, + дам инструкции по упаковке в Windows/Android.
>тоесть файл в 100МБ займёт 4ГБ оперативки
Если ты ожидаешь что ты упрёшься в ресурсы, тогда точно не через ХМЛки - они для прототипов где важнее скорость и функционал.
Я бы посоветовал джаву.
А потребление оперативки будет зависеть от того, как ты всё это упакуешь в памяти. Попробуй прикинь наибольший возможный граф для себя и посмотри сколько он будет занимать. Если не будешь создавать много объектов одновременно, то занимать это много не будет.
Ну, навскидку, будет линейка квестов в штук 50, типа граф начинается с 5-10 концов веток, начальных узлов, от каждого идёт ветка по 3-7 узлов, и все сходятся в одно место, в финальный квест линейки. Можно представить как дерево графов сходящееся или звезду. Мне главное что бы в проге ставить чекины, что бы быстро напоминала какие квесты завершил, сколько и чего осталось сделать для выполнения ещё не завершенных квестов. И думаю удобнее кликать по узлам незавершенных, рядом с завершенными которые и смотреть что там надо.
А остальные графы (цепочки квестов) короткие, одна прямая цепочка без ветвлений. Но опять, чекин прогресса (напоминание) и планирование дальнейших действий.
Ща нашёл что можно (NoSQL, графовой бд) тупо быстро накидать в один файл, просто узлами (отмаркированные как перс, вещь, место). Сам список готовый. А потом долго ебаться с файлом связей графа, создавать цепочки, ветвления, направление связи, группировка связей в хард руппировку, вроде гиперграф тут поможет (это когда на выполение квеста надо сразу несколько предметов). Это самое сложное ибо будет базой для удобного визуального дизайна графа. (а не текстовый талмуд на несколько страниц, где связи между квестами разорваны, или квесты собраны в линейку связей, но уже исчезает связь "как одновременно выполнить парралельно несколько квестов (а не бегать челноком туда-сюда по два, три раза). Это и есть причина, почему родилась идея оформить это в виде графа, ради парралелизма, можно увидеть что два квеста за раз можно сделать.
Плюс всякие примочки, аналитика профита в виде коинов, экспы и ачивок. Сидеть добавлять "свойства" узла, свойства связи по типу ключ=значение".
"а потом может быть пойму что моя хрень выросла до тяжёлого неповоротливого куска говна, который не потяну и который никому нахрен не нужен".
граф в 50 узлов это ничто, можешь делать вообще как хочешь
сложно понять всю глубину мысли, но 100 мб графа тут не будет
Вкатился в этот ваш айти на верстку 5 лет назад, да схватился зубами за уходящий поезд айти и ногами еще бился километр о шпалы, ну перешел я на рыгакты, проектов не оказалось после закрытия, перешел на ангуляры и вью. Что-то там не срослось и перенесли на новый проект с некстом. Ну похуй, освоился, работал. Черт дернул работу сменить, сменил. Начал работать на вью, за полтора года зп не выросла не на копейку, ответственности и роста тоже не появилось...
Теперь рынок мертвый, где если в конторах не банкротство - то ИИ и сокращения.
А я просто хотел сидеть в какой-нибудь конторе, делать дела, становиться круче, хавать пиццу в пятницу и латте пить перед работой, вырости до уровня "Выступать перед полным залом с докладами по хуйнянейм. Купить классический айтишный авто типа шкода кадиак.. Да ёб твою мать.....
 139 Кб, 1011x1063
139 Кб, 1011x1063Теперь без 100 баксов на подписку клода, нет смысла даже.
Для петпроджектов 20 баксов хватит. Когда упрешься в лимит, ну пойди другим делом займись. А когда ты уже на работе, то работодатель проплатит либо за 200 подписку, либо за токены
Оно и сейчас бесплатное. Я же не долбоёб, чтоб оформлять платные подписки, когда есть бесплатные открытые аналоги.
Ну а что за тупой вопрос про бесплатное программирование тогда? Раз нет варианта отказаться, значит деньги найдешь. Из дома что-нибудь стащишь, закладки поделаешь, почку продашь. Вариантов денег найти-то куча.
Вкатиться есть смысл? Тема не из за бабла мне правда интересно. Еще с детства. Ну по базе проебал свою молодость. Потом и потом.
Я хочу спросить про ml инженеринг. Нормально?
 652 Кб, 974x647
652 Кб, 974x647Сейчас работаю на около-дно работе, ковыряю ЖС. Есть знакомый бухгалтер , который может устроить на 0,0001% ставки чисто для опыта, чтобы шел в стаж каким-нибудь эникеем без понятия кто это в трудовой книжке.
Подскажите, это может пригодиться в будущем?
Нынешняя дно-работа общепит
Хуевый знакомый у тебя, эникеем мог бы и на фулставку взять. Там задачи будут закрываться любым челом который пользуется компом дольше года и умеет гуглить, это же на подхвате челик который бегает старушкам программы настраивает и включает компы в сеть когда у них не включается.
Там место такое-себе, сидят скуфы за МРОТ. Да и не думаю что платить эникею будут больше чем в забегаловке в которой работаю сейчас, пиная хуи
Ну и нах оно? Общий стаж у тебя смотреть будут в таких же околобюджетных парашах.
Вайти у тебя спросят сколько лет ты пользовался конкретным инструментом и в каких проектах. Ищи лучше нормальную стажеровку где ты будешь разработчиком или хотя бы тестером.
Года два уйдет минимум еще. Насколько это актуально ещё будет плюс минус? Пока ИИ не заменит.
Актуально, ии никого не заменит. Мы уже в начале этого года должны были 90% кода писать иишкой. Коупинг выдохся.
Ну так и пишем. Все пишут с ии, кто пишет без - хлебушек. Все равно что от компилятора и ИДЕ отказаться.
Спасибо. Надеюсь. Главное порыв. А то жизнь какая то безвкусная стала. Как раз через ИИ и спрошу дорожную карту.
Нах? Все готовое и структурированное лежит просто загугли программу университета с мировым именем по теме
Все и с ИДЕ пишут, но ИДЕ еще никого не заменила.
Кармак вообще стал легендой без всяких ИИ. ДУМайте.
Так ИИ заменил только дебичей которые всю жизнь кнопки красили, сейчас все использует его в работе ибо удобно.
Че там в мезазое никого не ебет, люди коды процессора на перфокарте тыкали и че? В сравнение с твоим создателем игрелек для дебилов они боги.
Окей. Поищем, анону респект
еще раз спасибо
Глубина мысли - сделать удобный гайд. А не такой же неудобный, как текстовый. Фактически будет: чел помнит частично все квесты, а в этой проге накидывает себе набор квестов, она помогает узнать что есть параллельные квесты, что есть связь между квестами.
И я наверно соврал про 50 узлов. На самом деле тут получается куча мелких графов (два узла и одна их связь, или чуть больше), не имеющие связи с этим 50-узловым и между собой, тоесть если разбросать все эти графы на листе - то пользователю пригодится поиск по его запросу - по всем графам, по всему листу короче и как бы получается понадобится показать вместе, к примеру, 50-узловый и один или более, сколько нашлось - мелких.
я сомневаююсь что сделаю полный гайд, потому что понимаю
что там работы дохрена. Скорее моё хобби - структурировать информацию, исследовать методы структурирования и что там "ученые" придумали, пусть лет 20 назад, но это тоже "новое, ноухау".
Просто интересно узнавать новое в области информатики.
Я кстати тот ответ нейронки скопировал. Может, как-то на досуге поищу по каждому тайтлу инфу. Если зайду в тупик с Neo4j
Ну, тогда ИИ - это язык программирования. Точнее, следующий этап после ЯП. Первый - это набивание "кодов процессора" на перфокарте, прожигание транзисторов на большой транзисторной схеме (тобишь считай ПЛИС), второй - это ассемблер, третий это ЯП. ИИ выходит - четвертая степень (уровень) "создания автоматических вычислительных систем (в смысле компьютерная программа в ЭВМ))
Пока только в простых вещах вроде плагинов\скриптов\фронтенде
Там достаточно подводных которые не позволяют пока на него полностью полагаться, но в рутине он незаменим. Так что пока это следующий уровень подсказок\снипетов\автогенерации в ИДЕ которая прям функциональные блоки может хуячить но обосраться где-то если оставишь без контроля.
>Это где у тебя бесплатные аналоги клода по перфомансу есть?
Единственное отличие клоды заключается в том, что она вылизана на составленных вручную датасетах, чтобы в большинстве типовых задач с первого раза выдавать рабочее решение без дополнительной помощи. Любая другая топовая нейросеть сможет написать сравнимый код, но ей придётся помогать. То есть, например, тебе нужно будет грамотно выбрать стек для решения задач, пиздануть нейросетку линейкой по рукам, когда она будет тащить какое-то легаси, когда будет пытаться решать не ту задачу, которую ты ставил, и так далее. В клоду просто зашито какое-то количество готовых ударов линейкой по пальцам.
Чем более нестандартная у тебя задача, тем меньше эта разница касается тебя, поскольку тем больше работы будешь делать лично ты, и тем больше тебе начнуть МЕШАТЬ встроенные в клоду алгоритмы.
>Локальные лаботомиты это больше мучение чем помощь.
30B модели уже вполне промышленно применимы. Другое дело, что именно на технику для такого инференса нынче цены заоблачные (нужно никак не меньше 30 Гб VRAM для агентной работы). Люди придумывают всякие изъебы с массивами старых карточек, купленных за копейки.
>Я хочу спросить про ml инженеринг. Нормально?
Это как вкатиться в блогинг или фронтенд в 2021 году, когда ковид кончается. Уже сейчас в ML людей как мух на говне, к 2027 пузырь ёбнет и большая часть ML-щиков останутся на морозе, как фронтендеры после ковида.
>ИИ выходит - четвертая степень (уровень) "создания автоматических вычислительных систем (в смысле компьютерная программа в ЭВМ))
Нет. Когда ты пишешь на Java, то ты не вычитываешь ассемблер, который тебе сгенерировал компилятор — ты пишешь Java, читаешь Java.
Когда ты пишешь нейросетью, то ты читаешь не нейросеть, а код. Есть ебанашки, которые и пишут ,и читают код нейросеть, но это так сказать "unsustainable", по крайней мере на текущий момент, тебе рано или поздно понадобится человек, который прочитает код и скажет "вот это и это хуйня, перепиши".
Та же история уже давно произошла c IDE — код на Java очень тяжело читать без IDE, но это всё равно код на Java. Можно сказать, что мы имеем IDE-assisted Java. И, соответственно, AI-assisted java — но это всё равно Java, мы не можем полностью непрозрачно заменить Java на чат с нейросетью..
>Пока только в простых вещах вроде плагинов\скриптов\фронтенде
Конкретно у фронтенда самая большая проблема в том, что он в ковидные временя превратился в совершенно ебанутую раковую опухоль. НЕЛЬЗЯ ТАК ПИСАТЬ ИНТЕРФЕЙСЫ. Вкатуны, не имеющие никакого отношения к программированию, создавали себе "рабочие места" ковыряния вилкой однотипной копипасты. И тут внезапно пришло ИИ, которое может ковырять однотипную хуйню в 20 раз быстрее человека — фронтендеры, вкатившиеся в IT из курьеров, резко обломались.
Любой прирождённый программист прежде всего понимает, что его задача заключается в том, чтобы писать УНИКАЛЬНЫЕ ПЕРЕИСПОЛЬЗУЕМЫЕ функции. В таком раскладе у нейросети просто не остаётся работы, потому что ей нечего и некуда копировать — всё повторяющееся уже реализовано, его просто нужно вызвать одной строчкой с правильными параметрами, а именно на границах связи модулей у нейросеток часто возникают проблемы.
Степень переиспользования и сейчас могла бы быть больше, но, ещё раз, IT наводнено людьми. которые прирождённые токари и повары, а не айтишники, им по приколу тысячу раз повторять один и тот же алгоритм, а где есть спрос — там и предложение. Потому с проблемой никто напрямую не борется.
В том-то и дело, что нейрослоп не читают, его генерят. Если что-то не работает, меняют промпт чтобы работало, но при этом вылазят другие проблемы. В результате просто оставляют вариант наиболее приемлемый с точки зрения высирателя оставив косяки как есть, вручную код не читают и не правят. И нейрослоп далеко не только код, он генерит документацию, коммиты с описаниями изменений, короче имитирует бурную деятельность.
Нейрософт то же самое что нейрочат, лишь имитация. Нейробот имитирует чекловека-собеседника, так и нейрокод лишь видимость, показуха, как покраска травы зеленой краской.
> И нейрослоп далеко не только код, он генерит документацию, коммиты с описаниями изменений, короче имитирует бурную деятельность.
При чём тут генерация рандомной хуйни к прикладному кодописанию? Яндекс-рефераты не вчера изобрели.
>Нейрософт то же самое что нейрочат, лишь имитация. Нейробот имитирует чекловека-собеседника, так и нейрокод лишь видимость, показуха, как покраска травы зеленой краской.
Я очень интенсивно использую нейросети в разработке, но, ещё раз, у них функция как у IDE, они помогают писать код, а не заменяют собой ЯП или програмиста.
 951 Кб, mp4,
951 Кб, mp4,560x560, 0:06
Всех нас.
 293 Кб, 333x292
293 Кб, 333x292Он пиздец как не любит когда кто-то "пишет код".
Он пиздец как не любит когда кто-то "делает фичи" и "тулзы".
На любой логгер, на любую функцию говорит "а нахуя нам это логировать?"
"а нахуй нам это выносить в функцию чтобы потом прыгать к определению?"
До всех тикетов доёбывается чтобы сообщения были максимально короткими, без доли речевой избыточности.
Если в диффе коммита больше зелёных строчек чем красных - значит код добавляется а не удаляется - значит коммит хуёвый.
Чё это за хуйня?
Я такой же.
Когнитивную сложность контролирует, вам, долбоебам, дай волю, нанейрослопите вагон говна
Мужик опытный значит. Это зелень всякая или менеджеры любят хуйни накидать на несколько страниц типа много работали
 123 Кб, 860x924
123 Кб, 860x924Я пытался осилить и пхп, и с#. Пока что лучше всего получается кодить на си. По крайней мере, хоть я все ещё немного пугаюсь указателей и сложных технических терминов, на нем получается лучше, чем на более высокоуровневых языках.
>Если в диффе коммита больше зелёных строчек чем красных - значит код добавляется а не удаляется - значит коммит хуёвый.
Всё правильно. А что не так?
c# и есть высокоуровневый, то есть удобный и легкий для чтения, сюда же питон и прочие. А низкоуровневый это ассемблер какой-нибудь, ближе к машинному коду.
>Чё это за хуйня?
типичный анальный сектант.
горит своим сраным кодингом во времена бурного расцвета ИИ.
сейчас такой хуйней заниматься - это быть умалишенным.
весь ваш код скоро перепишет нейросетка.
код сегодня - мегадешевый воспроизводимый ресурс который уже ничего не стоит.
Дегенерат малолетний, в больших проектах нейронки никогда ничего не перепишут тк им тупо контекста не хватит. И именно для этого надо стараться как можно меньше код засирать, на сегодняшний день.
Пока трансформер является базой для нейронок, они нихуя делать сами не смогут.
>Дегенерат малолетний
к себе обращаешься?
>>29816
>в больших проектах нейронки никогда ничего не перепишут тк им тупо контекста не хватит
на что им контекста не хватит, чудило?
у любой задачи есть строго ограниченный контекст
шиз реально думает, что в нейронку пихают весь проект
и эти дегенераты тут об ИИ рассуждают
рот свой закрой и не позорься
весь контекст и будет когда на просьбу пересать какой-нибудь хелпер надо будет дрочить весь проект где функции этого хелпера используются
Ебучий дауненок, тебе для этого и нужен минималистичный код чтобы можно было нейронкой эффективно работать с ним, неужели это непонятно. Бля вот просто не пиши ничего и не пизди на своего руководителя, смирись что у тебя двузначный дебильный айкью и просто делай че сказали.
Я это к чему... Вообще, реально подрабатывать в bug bounty без серьезного опыта и навыков? Ну, хотя бы на 500$ в месяц. Всякие HackerOne, Intigriti, агрегаторы bug bounty программ - они для новичков подходят, или профи с автоматическими переборами всевозможного говна + ии агентами уже сметают все базовые баги подчистую? А то я, по сути, кроме анализа api эндпоинтов и подмены пакетов ничего не умею. Ну, XSS подробнее изучу, ладно, но как будто такого уровня вообще недостаточно. Что думаете?
>у меня такой же был долбоеб который тянул на новый проект старый самописный фреймворк, а то АБЫ ЧЕВО
Ты разницу видишь между "тащить непонятно какое говно в проект" и "не добавлять ничего в проект"?
>Что думаете?
На юутубе посмотри записи как профи ищут уязвимости в конкурсах для хакеров.
Это всё дроч для админов, как литкод дроч для кодеров.
Зарабатывают деньги на работе. Если ты крутой хацкер, то у тебя есть работка в крупной конторе и ты на рабочеме месте постоянно пытаешься свою же контору ломануть.
>и не пизди на своего руководителя
Я то тут при чём, это вообще какой-то левый хуй.
У нас крутится локальная llm чтобы не сливать секреты вовне, и я подтверждаю, чтобы проверить код или поправить через llm, мне приходится прятать многие лишние не относящиеся к проблеме файлы чтобы не тратить токены.
Локальная хуета не стоит внимания чел, даже дешманский диппсина в4 неиронично в сотни раз умнее.
>>29838
Дебич ну если ты не пользовался зачем влазить в разговор?
Нейронка идет грепами по коду и ищет или тем тулом которым ты ему дал. На гитхабе есть аст-греп например или можно подрубить к лсп ИДЕ. Не позорься.
за ИДЕ увеличивают зарплату кодеров?
или уменьшают?
ИДЕ нахуй не нужны. Ведь они не увеличивают зарплаты не увеличивают количество рабочих мест.
Жалко, хотел почитать тутор мб вводный пока на работке
бамп вопросу

Есть небольшая вероятность, что возьмут стажёром девопсом за 60 тысяч рублей в месяц до вычета налогов.

Я в колледже в своем селе учился, потратил 3 года жизни чтобы получить корочку Оператор ЭВМ. Возьмут программистом с такой? Как вообще программировать?
Ну тимлидом или архитектором врядли возьмут, на это я бы не расчитывал, но условный 9-5 сеньор или мидл вполне возможно, главное нормально и уверенно собеседование пройти. На хх покидай заявки.
Так я не умею программировать, начал на одном собеседовании рассказывать что вот умею Windows переустанавливать, вирусы удалять и т.д, мне сказали что это не то вообще.



Хотел бы продемонстрировать свою математику. Это ещё можно оформить в электронном виде, просто найти аналоги на клавиатуре.
Здесь я работаю с протколом SMB - тем самым, что работает в сетевых шарах Windows, нам нужно написать "отечественный аналог" так сказать.
Пик 1 - правила обработки полезной нагрузки для сжатых сообщений протокола SMB2 (v3.1.1).
Пик 2 - Ошибочная модель того же самого до появления пик 1
Пик 3- Описание параметров и свойств SMB1 Транзакций на листе справа, слева -- отображение предикатов над свойствами на состояние автомата кеширования. (Тут описано реассемблирование по сути полезной нагрузки Транзакции).
И таких подобных листов у меня копилось и выбросилось аж с 2015 года где то.
Что скажете? Полезный инструмент для кодера?
Как вы расписываете на бумаге, какая у вас "математика"?
То есть ты взял обычный конечный автомат if return и хитровыебано нарисовал разные индексы и скобки. Чтобы что? Ты у мамы Галуа дохуя?
Это вполне помогает придти к пониманию для меня скорее того как простроить алгоритм, я выделил формат, из формата достал какие то свойства, работаю уже с ними, а там дальше всё это всё равно нужно переводить в рабочий код.
Я бы не стал хвастаться, но это вполне рабочий инструмент по моему.
 223 Кб, 596x335
223 Кб, 596x335>пишу на С++ реализации сетевых протоколов
Каво? Ты кто такой нахуй. Джимми нейтрон?
>Хотел бы продемонстрировать свою математику
И чё крутого она может для пацанов?
>Здесь я работаю с протколом SMB - тем самым, что работает в сетевых шарах Windows, нам нужно написать "отечественный аналог"
NFS просто возьми да и всё
Кажется понимаю о чем ты, но UI нельзя написать как компактную умную систему, которой на вход подаются параметры под конкретную ситуацию. Потому что самих этих параметров столько много и их структура такая глубокая и ветвистая, что само их описание автоматически становится программированием. А если ты будешь пытаться городить свои супермощные статические форматы данных, то у тебя просто получится менее гибко и еще более многословно описать UI
 29 Кб, 450x682
29 Кб, 450x682>Кажется понимаю о чем ты, но UI нельзя написать как компактную умную систему, которой на вход подаются параметры под конкретную ситуацию.
И поэтому нужно писать 200 тысяч разных окошек ввода логин-пароля?
>А если ты будешь пытаться городить свои супермощные статические форматы данных, то у тебя просто получится менее гибко и еще более многословно описать UI
Какие данные? У нас три раза в неделю перекрашивают кнопки и обновляют шаблоны компонентов с https://www.shadcn.io/ . Данные UI вообще никакие не обрабатывает.
>картинка
У гугла точно такой же всратый интерфейс, когда дело касается бизнес приложений. Достаточно зайти в их каталог и убедиться. UI для гемини придумало наглухо ебнутое животное, попробуй там сделать картинку из файла.
Установил 360 total security.
Нажимая на значок корзины, в открытом окне где "удалить содержимое" и т.д., была пиктограмма 360 security. После удаления говнопрограммы вместо пиктограммы кружочек. При нажатии на него надпись: "приложение не найдено".
Как удалить спам с кружочком? Чистил реестр, системную папку корзины, все тоже самое.
Заново установить и удалить 360 total security?
Семерка потому, что старинный ноут.
1) тебе в /s
2)
>Нажимая на значок корзины, .. была пиктограмма
Изучи деепричастные обороты. В таких предложениях подразумевается один субъект действия.

Хуита. Я никогда на СО не спрашивал, только переходил по ссылкам из гугла и читал. В комментариях можно было узнать что-то новое. А сейчас железный дебил высирает +2000 пр, даже смотреть в это говно не хочется. Где-то что-то упадет - вообще похуй, проблемы кабана.
На 2к строках уже за милую душу что-то рандомно отъебывает, особенно если изначальные условия прописаны типо код компактным держать. Но ведь действительно похуй
>за полтора года зп не выросла не на копейку, ответственности и роста тоже не появилось
Перепутал причину и следствие.
Можно ли сделать псевдо-приложение из html+css+js (после упаковать в zip)?
Процесс такой:
Пользователь распаковывает zip в отдельную папку (пусть будет "test"),
открывает html в браузере, жмет "обработать файл", отчего запускается скрипт,
находит и обрабатывает mydocument.txt, рядом в ту же папку сохраняет output_mydocument.xlsx .
Смысл: кроссплатформенное "приложение".
можно
> находит и обрабатывает mydocument.txt, рядом в ту же папку сохраняет output_mydocument.xlsx .
Если без запуска локального сервера, вот здесь возникнут сложности. На стороне браузера нельзя просто взять и обратиться к файловой системе, надо сначала показать диалоговое окно загрузки файла, пользователь мышкой выбирает txt, а после обработки надо показать окно скачивания файла, где пользователь опять же выбирает, куда положить xlsx. Если для тебя это не проблема, всё остальное реализуемо.
Куда лучше вкатываться - аналитику, QA, Go или Java? Думаю подаваться на стажировку в т-банк, перед этим проходить их курсы
> Куда лучше вкатываться - аналитику, QA, Go или Java?
Вот тебе ещё варианты: Data science, геймдев, веб-разработка, системщина, разработка баз данных, разработка десктопным программ, мобильная разработка, C#, JS, TS, PHP, Kotlin, 1С, C++, Ruby, SQL, HTML, CSS, Asm.
Нет, я именно хочу выбрать себе роадмап какой-то с самого начала, направление, стек епта
ИИ всех заменит, курьеры неиронично хороший совет
Но если все таки хочешь вайти, то ориентируйся лучше по количеству отзывов и вилке зп конкретно в твоем регионе - оно может различаться
Какая разница на чем ебашить корпоративный слоп? Любые задачи программирование ебаная скукота
Что если начать качаться? Чтоб грузчиком подрабатывать? Одного часа в день хватит чтоб накачаться?
Сложно ли развернуть кубер на винде? Хочу написать пет-проектик для тренировки
Читаешь книгу\решает примеры с телефона пока едешь это 2 часа туда, 2 обратно - считай учебный день в универе.
Пока на работе наушники одел и слушаешь подкасты. Выходные тратишь не на протыклассников а на плотную учебу.
Через minikube легко.
Я когда собирался вкатываться год потратил на то, чтобы найти работу со сменным графиком 2/2 либо 3/3. Понимал, что не вывожу полноценную учебу с 5/2 работкой инженегром на заводике. Прошел где-то штук 20 собесов в разную хуйню - склад сантехники, склад медпрепаратов, склад электронных компонентов, несколько вакансий ЧПУ на заводах (там ночные смены - нахуй), слесарь на ТЭЦ. Пролетел с собесом в типографию. В итоге под нг нашел место дворником 1/3 на базе отдыха и уволился. Но кинули с работой. Дворником, да, взяли вместо меня какого-то 50лвл дядьку.
Побегал курьером в яндексе, заработав 2-3к за месяц. Через пару месяцев, в начале ковида, вышел работать инженером на заводик 5/2, отработал там год. В итоге уволился и уехал к мамке. В 23 году вкатился.
> Побегал курьером в яндексе, заработав 2-3к за месяц.
Долларов? Это в Москве столько можно заработать?
>>Побегал курьером в яндексе, заработав 2-3к за месяц.
>Долларов? Это в Москве столько можно заработать?
Да, В Моске по крайенй мере недавно можно было такое заработать, но нужно именно бегать — сидя на жопе такое не заработаешь.
 520 Кб, 712x1000
520 Кб, 712x1000Кто-нибудь знаком с этой книгой? Подскажите, какие предварительные знания необходимы для успешного ее освоения? Математику, даже школьную, знаю плохо, но хочется изучить те области, которые важны для компьютерных наук.
Ладно, мб напиздел тут. Выходил и правда мало. Тогда минималка была 100 руб./час, я за неё выйти не мог толком. Прикинул, что да если весь месяц работат 160ч как на пятидневке, ты выйдет 16к.
Книга хуевая если ты хочешь чему-то полезному научиться. Это примерно как сейчас учить геометрию по Началам Евклида. Информация сегодня от туда совершенно бесполезная, когда есть линейная алгебра и пр. вещи.
Ну то есть книга, обе, не плохая и классика, но место ей в истории, она не актуальна.
>которые важны для компьютерных наук
Я бы выучил поверхностно какой-нибудь язык, желательно где нет ебли с работой со строками, и начал с The Elements of Computing Systems. А потом уже катись куда душа лежит.
Но если хочешь РАБоту найти, то мой совет не слушай, а смотри что кабан от тебя ждёт и учи что он ждёт. Умение написать ос и компилятор тебе вообще никак не поможет в этом деле.