Это копия, сохраненная 25 августа в 18:24.
Скачать тред: только с превью, с превью и прикрепленными файлами.
Второй вариант может долго скачиваться. Файлы будут только в живых или недавно утонувших тредах. Подробнее
Если вам полезен архив М.Двача, пожертвуйте на оплату сервера.
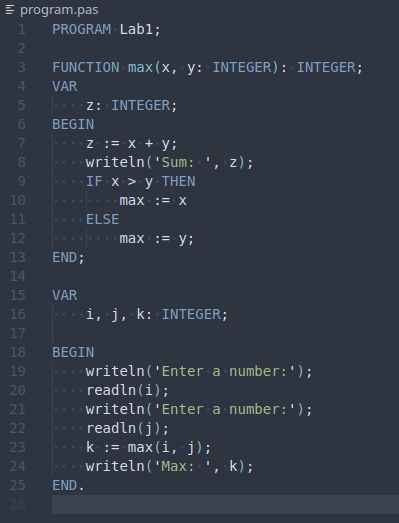
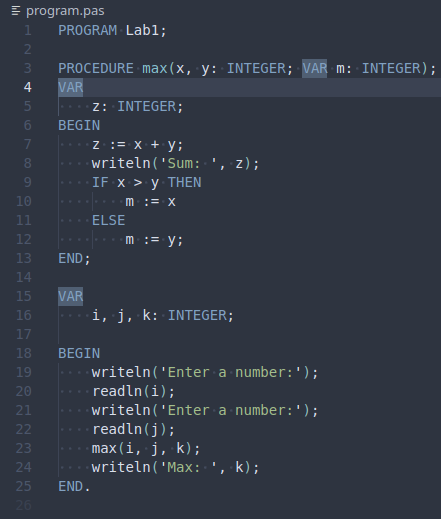
 104 Кб, 630x630
104 Кб, 630x630Предыдущий: >>3327670 (OP)
Литература:
https://ln2.sync.com/dl/cf2c1d070#xq4s328t-xbbjys2z-9r6j7ss7-gf4e9dv6 <-- Книжки, новое собрание
Ещё книжки: https://yadi.sk/d/HQhhsBsq3TVRUq
Тоже книжки: https://yadi.sk/d/tArKKuQu3Kejuq
Анон, вместо того, чтобы без разметки постить код, лучше шарь его через специальные ресурсы:
https://online-python.com/ - листинги и онлайн-запуск
https://ideone.com/ - возможность постить листинги кода и онлайн-запуска, не требует регистрации
https://dumpz.org/ - можно постить листинги, не требует регистрации
https://pastebin.com/ - для листингов, регистрация не обязательна
https://goonlinetools.com/snapshot/share/ - для листингов, без регистрации, но с капчей
#######################################
Вопросы-ответы:
— С чего начать изучать питон?
У питона намного лучше официальная документация, чем у большинства других языков. Есть там и учебное пособие для начинающих: https://docs.python.org/3/tutorial/introduction.html , неофициальный перевод на русский язык: https://digitology.tech/docs/python_3/tutorial/introduction.html (для питона версии 3.8, но разницы почти нет)
https://github.com/yakimka/python_interview_questions - интересная подборка, масса разнообразных тем и вопросов, для продолжающих, всё на русском
— Какие книги считаются лучшими?
На слуху чаще всего Лутц, но там очень много воды. Ещё на слуху Марк Саммерфильд, Эл Свейгарт "Автоматизация рутинных задач с помощью python". Эти книги рекомендуют чаще всего, но книги довольно старые, а питон развивается.
— Есть у кого на примете годный курс лекций по алгоритмам? Формат лекций мне как-то ближе, нежели просто чтение книги.
МФТИшный курс, например, https://www.youtube.com/playlist?list=PLRDzFCPr95fK7tr47883DFUbm4GeOjjc0
— А как учить джангу? Нахожу книги по джанге 1.х, можно их использовать?
У джанги отличные доки (одни из лучших для пистоновских либ, имхо), почитай их для начала. Книгу по джанге можно читать даже для версий 1.x, т.к. принципы остаются теми же. Но лучше хотя бы с версии 2.0, слишком много мелких изменений в базе.
— Какие веб-фреймворки стоит учить в начале двадцатых?
Что бы не говорили, Джанго живее всех живых и умирать не собирается (и Django REST Framework), очень перспективный асинхронный FastAPI, асинхронный AioHTTP. Flask ещё где-то используется, но уже legacy. Прочие фреймворки или у нас экзотика, или это вымирающее легаси как Торнадо.
— В ньюфаг-треде написано, что нужно начинать с SICP, чтобы научиться программировать
Вот, пожалуйста, та же самая программа, но частично переработанная под язык Python: https://www.composingprograms.com/ (нужно знать ангельский или уметь пользоваться переводчиком)
— Что можно почитать/посмотреть по многопоточности/параллелизации в питоне, да и вообще в целом?
Ролик на американском языке про многопоточность и асинхронность, построение своего event loop с нуля, помогает понять, как устроена асинхронность внутри: https://www.youtube.com/watch?v=MCs5OvhV9S4[РАСКРЫТЬ]
— Можно ли на питоне делать мобильные приложения?
Да, смотри на фреймворк Kivy https://en.wikipedia.org/wiki/Kivy_(framework) https://kivy.readthedocs.io но народ на него жалуется
— Как можно без лишней возни ускорить программу на питоне
1) проверь сначала свой код, алгоритмы и структуры данных. Чаще проблема здесь.
2) код можно иногда феерично ускорить, используя JIT (Just-in-Time) компиляцию. Почитай обязательно про модуль numba, он ставится через pip, и альтернативный интерпретатор PyPy.
— Дайте нормальные книжки на русском! Мы, блядь, не в пин##сии живём
Брат, смотри книжки по ссылкам в шапке, там есть и русские. Но помни, без языка ангелов твоя жизнь проходит мимо и ты обречён быть на обочине знаний и технологий.
ps: анон, если ты вносишь изменения в шапку, оставляй ссылку на код с обновлённым исходником.
текущая шапка: https://goonlinetools.com/snapshot/code/#z0o243n8t8byiy2zptv27
 130 Кб, 1280x720
130 Кб, 1280x720Не свитчеры, а именно с нуля первым языком?
Какой у вас план?

Ну, я. Но мне питон для автотестов нужен. И то не могу сказать, что это прям ПЕРВЫЙ мой язык, 10 лет назад я знал js, правда с того момента больше им не пользовался и не программировал. Но ООП и прочую залупу я уже знаю.
Кстати, охуел как изменилось обучение за эти 10 лет, когда я вкатывался раньше, то было дай бог 2-3 курса на английском по js, и книги с кучей воды и ненужной хуйней. То есть то, что ты сейчас можешь выучить за 2-3 видоса на ютубе растягивалось на 2-3 недели потного дрочева с книгой. И всякие ии - просто пиздец как удобно, я вот раньше ждал, когда мне на дваче ответят почему моя хуйня не работает, а мне отвечали "пошел нахуй" или "ты долбаеб", а теперь нахуй все подробно можно разобрать и пофиксить проблему за 1-2 часа, а не за ебанных 2 месяца глубокого тильта, когда ты просто сидишь и не ебешь что делать вообще + чувствуешь себя говном все это время.
План писать автотесты. Ну, как бы, я за час уже первый тест написал. Мой план просто задрочить это и не ломать голову и вспоминать "а чо там была та", а просто спокойно по лайту писать эти тесты.
Кстати пиздец обидно, ебать бы я щас охуенно жил, если б тогда js не бросил. А бросил я его знаете почему? Потому что ебаная нормисная хуйня меня задрочила до конца, то иди блядь шарагу закончи, то иди блядь вуз закончи, то блядь иди уже работать пора, то блядь ищи новую работу побыстрее, в итоге нахуй как долбаеба палкой гонят, а профита 0 нахуй. Че доебались до меня тогда все эти люди? Гореть им в аду бы, конечно.
Рано нахваливаешь всю эту мишуру, потому что ни тогда, ни сейчас у тебя результата пока что нет.
Вот когда будет, тогда и нахваливай.
даже не представляю, это наверное как купить биткоин и продать чуть дороже, а потом смотреть как он дорожает в разы.
Я не бросил 10 лет назад и вкатился но сейчас один хуй, что ты, что я сидим и в новую хуйню на общих основаниях вкатываемся так как в старой уже работы нет.
Сейчас один из немногих реальных способов найти работу на питоне это выучить React. Не шучу. Чистых бекендеров требуется очень мало, в основном разные фулстеки (бекенд + МЛ, бекенд + фронтенд).
Братья-питухонисты
Поясните за exec
Как правильно запускать в нем код, чтобы он выполнялся как отдельный запущенный скрипт? Пилию свою иде, я понимаю что надо как то передать ему словарь глобалсов идентичный тому какой создаётся при python -m file_name
Но просто сделать import __main__ в функции запуска и передать не канает, разбирать pydeved больно очень
— Та не, нормально, у меня всё само — память выделяется динамически, GC сработает, не парься. У меня ж Python, всё своё. О-о... О-о... Вот это рантайм! Как же всё гладко обёрнуто в декораторы! Просто zen! Так уж... О! О! О! Контекстный менеджер, ты моя хорошая, да?
— Да ничё.
— А? Ха-ха-ха! Импортируй меня полностью! О! Я даже GIL уже почувствовал. Почувствовал?
— Потоки не тормози.
— Асинхронно?
— Как тебе нравится — await или multiprocessing.
— О-о! О-о! О-о!
— Почувствуй силу duck typing'а.
— Он даже хрустит, блин, у меня! Интерпретатор прям жарит, как будто Cython прикрутил! О-о! Я давно такого сетапа не видел, чтобы и Flask, и NumPy, и скрипты, и джобы, всё в одной обвязке!
— Главное — не держать в памяти список на миллион строк.
— Ну смотри, хочешь — сбрось всё в генератор. Или пульни через итератор.
— Е-мое… полдня дебажил через pdb, чтобы скрипт крашнулся из-за None в поле?
— А-ха-ха! Конечно! Вот ты мне нравишься — как list comprehension на одной строке! А другие — по for’у пишут, и радуются. А-а! А-а! А-а!
— Столько времени оборачивал в классы, чтобы…
— О-о... да!.. нет!..
— Ещё будешь запускать?
Обзмеился
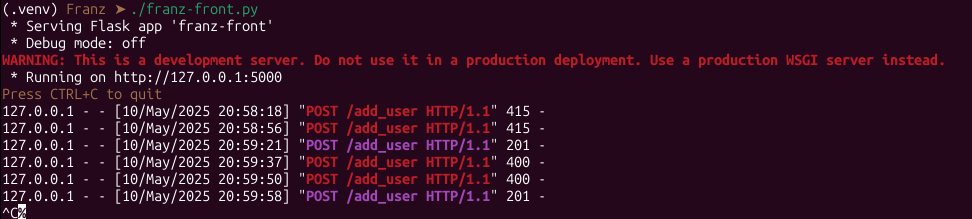 53 Кб, 972x219
53 Кб, 972x219> from waitress import serve
Заменяю
> app.run
на
> serve(app, host="0.0.0.0", port=8080)
Окай, предупреждение ушло. Это хорошо. Но есть и минус: логов нет вообще, приложение выполняется молча. Это не то, чего я бы хотел. Интернет, поиск, добавляю
> from logging import getLogger, INFO, info
и перед запуском:
> logger = getLogger("waitress")
> logger.setLevel(INFO)
Теперь при запуске я получаю об этом уведомление
> INFO:waitress:Serving on http://0.0.0.0:8080
При чём я вообще не понимаю, откуда оно берётся, знаю только, что происходит оно в момент вызова
> serve(app, host="0.0.0.0", port=8080)
Но засим -- всё! Если я вручную не делаю print, я не получаю никаких уведомлений об обращениях. Ни info("123"), ни logger.info("123") ни ещё что-то, что попробовал, ничего не выводит параметры на stdout/stderr. А мне бы надо это, типичная история: запросы, откуда пришёл, какой метод, что запросил, что получил, если не 2××, то что именно не устроило и т.п. С уровнями логирования и всем таким. Вроде бы всё должно быть просто, в конце концов это же Питон!
Например, сейчас у меня вначале, даже перед объявлением методов, лежит такой код:
> config: dict[str: str] = {}
> config["brokers"] = getenv("FRANZFRONT_BROKERS", "")
> config["log_level"] = getenv("FRANZFRONT_LOG_LEVEL", "INFO")
> logger = getLogger("waitress")
> logger.setLevel(getLevelNamesMapping()[config["log_level"]])
> for key, value in config.items(): logger.info(f"{key} = {value}")
Но на stdout при этом ничего SUKA не приходит.
Если я нигде в коде не указал пути и имени для логфайла, то это было бы странно, не находишь?
В общем, я тут откопал плейлист: https://rutube.ru/plst/440890?r=wd
Оказалось, что устройство модуля логгинг вообще пиздец нетривиальное и замороченное и моего беглого заглядывания в доку хватить не может. Пока решил обойтись самой-самой базой, а потом -- покурю внимательнее.
В частности:
Во-первых там создаются отдельные сущности "логер", "фильтр", "обработчик" ("хэндлер"), "форматер" и, возможно, ещё какие-то, до которых я не добрался и от настроек каждой из них зависит где-какие логи окажутся.
Во-вторых просто настроить 4 сущности может быть недостаточно! В частности они используют связи многие-ко-многим: один логер может быть связан с несколькими обработчиками, а один обработчик -- с несколькими логерами и настраивать придётся куда больше всего. Напрмер, повесить разные хендлеры, чтобы по-разному обрабатывать логрекорды с разной важностью.
А в-третьих -- саами логеры выстраиваются в иерархическую структуру и их связь сохраняется! То есть, при определённых настройках, отправленное тобой в лог сообщение может обработаться хэндлером от одного из родительских логеров.
Я допускаю, что это ОЧЕНЬ ГИБКО, и я даже ПОЧТИ оценил, но в текущей задаче у меня на разборы с логированием уйдёт больше кода и времени, чем на саму проблему!
На то, чтобы выплёвывать одни сообщения в stderr, а другие в stdout можно потратить 1 простейшую строку кода как у меня теперь, а можно -- 100-200+ строк злоебучего конфига со сложными связями плюс с переопределённым классом.
Короче иди нахуй, стандартный логгер реально ебанутый и оправдан только если у тебя прямо большой бэйр-метал-хостет стейтфулл и логи идут то в опенсёч, то шлются по смс прямо из приложения (а не собираются штатным функционалом кубера куда-надо в 10 раз проще, в 100 раз фичастее, а главное -- В 1000 РАЗ СТАНДАРТНЕЕ).
import telebot
bot = telebot.TeleBot(...)
bot.infinity_polling()
ну и дальше уже @bot.message_handler настраиваешь как тебе нужно.
Шо так, шо так ничего не выходит. Сам-то себе я могу написывать, а в других чатах только через /start.
В смысле, могу писать себе в боте без команды /start только через эхо бота, а в других чатах хуй.
При том, что если я выдам ему права администратора в своем чате, то все работает.
Насколько я понимаю, это сделано, чтобы нельзя было пользователей случайно подписать на бота без ведома юзера, а только чтобы он явно запускал, понимая, что далет.
Но по крайней мере ты можешь распространять ссылку прямо со стартом, тогда он будет отправляться сам, да ещё и параметр какой приклеит, например ID реферала:
> https: //t. me/nastyanovelbot? start=1854544298
>чтобы нельзя было пользователей случайно подписать на бота без ведома юзера
Именно так. Я проверил с телефона, компа и эмуля под разными аккаунтами в разных чатах и пришел к выводу, что говной занимаюсь. Это нужно делать прямо с аккаунты через машину.
Говоря откровенно, мне вообще-то спамер нужен для рекламы. Может есть ссылки какие?
>Короче иди нахуй, стандартный логгер реально ебанутый и оправдан только если у тебя
А он по-умолчанию более-менее сконфигурирован, тебе нyжна всё та же одна строчка кода, конфигурировать надо, если у тебя нестандартные запросы
Зато если вдруг понадобится что-то нестандартное, тебе не придётся переделывать весь код
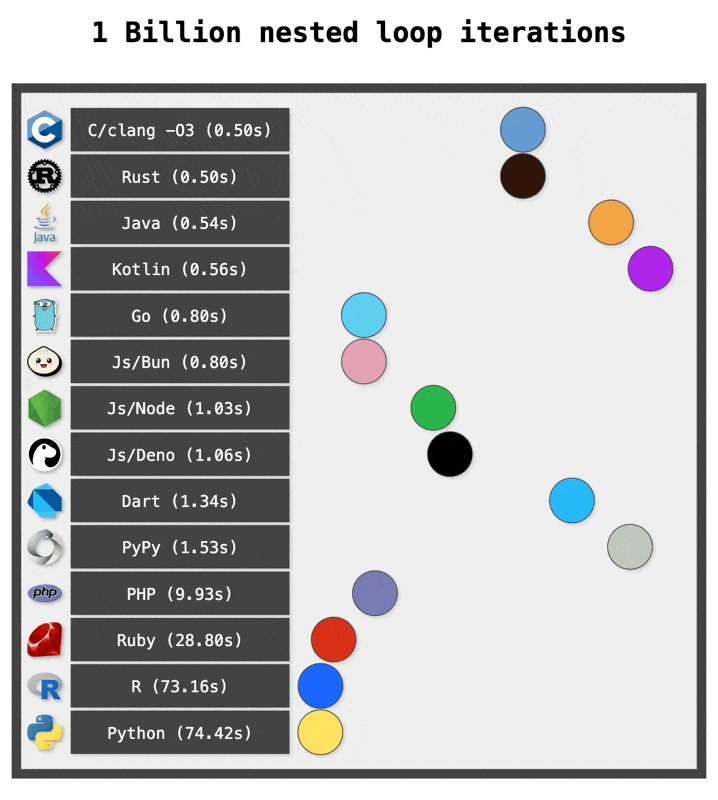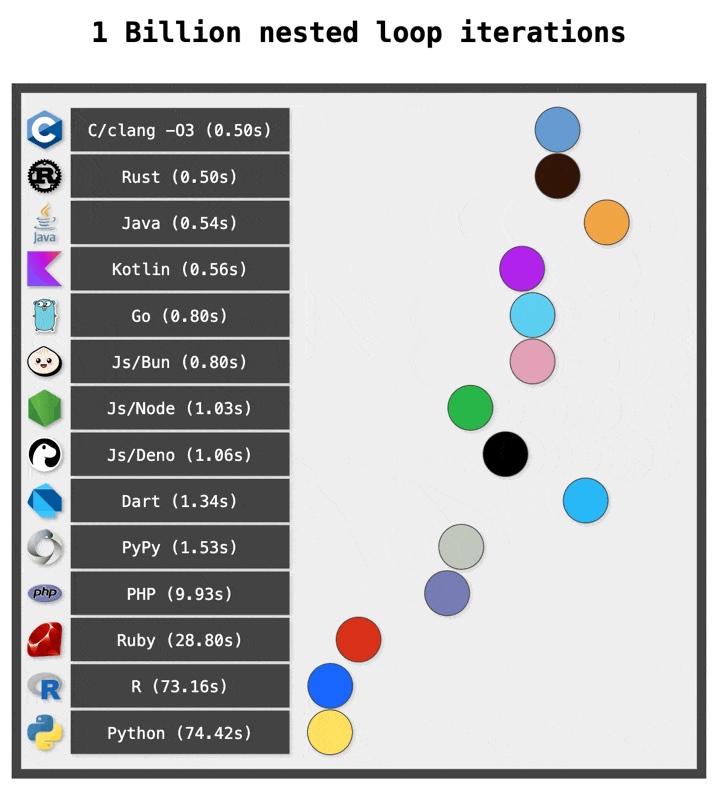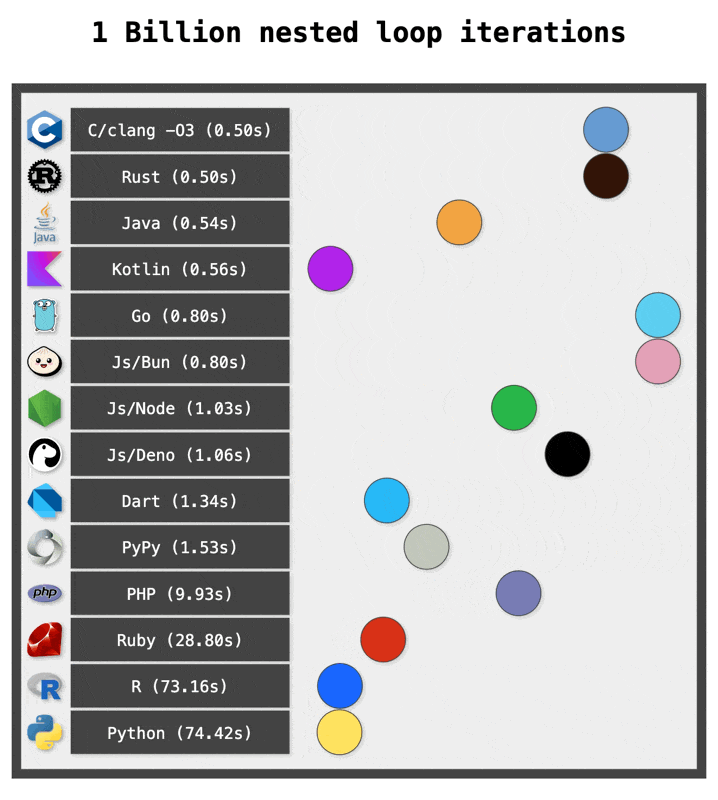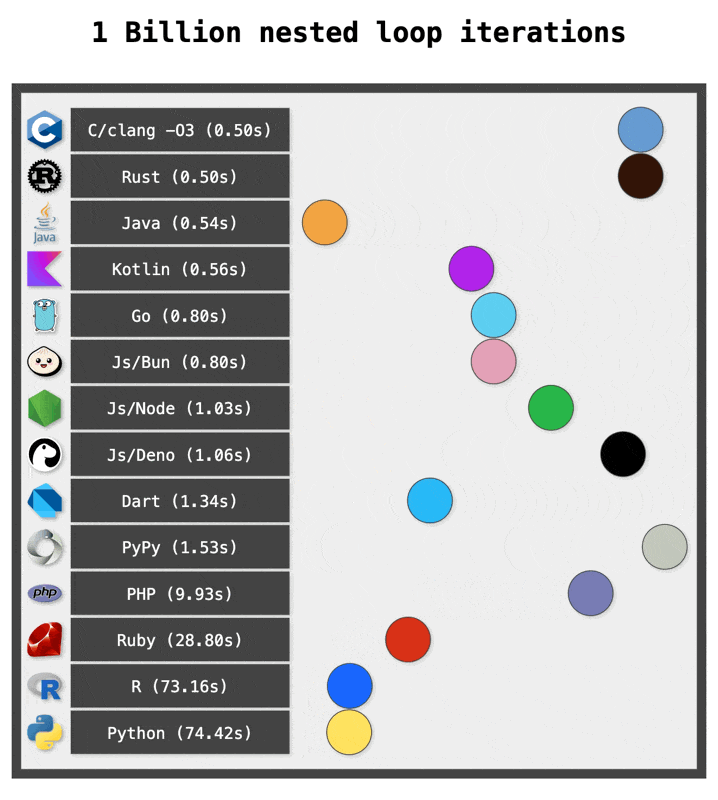
Тебе для каких целей?
Зачем тебе делать миллиард вложенных циклов? Ты ебанутый?

start это дефолтная тг функция старта бота, обойти ее насколько мне известно нельзя, только можно настроить автосообщение бота перед стартом как приветствие, а туда уже кинуть хендлер клавиатуры и дальше по плану
похуй абсолютно, пока вакансии есть похуй, тем более следим дальше за отключением мьютекса , грядет новая эра питона
Какой способ написать бота для тг (это без проблем) и подвязать ИИ чтоб отвечал по заранее распаршенному тексту?
Нашел
G4f, там типа можно задать вопрос ИИ, сказав , смари вот текст, отвечай по нему. Далее переключить ввод на тг-юзера.
Agno. Создаёшь агента, подгружаешь ему свой текст как knowledge base, далее переключаешь на юзера.
Это в теории. Кто реально пробовал?

 998 Кб, mp4,
998 Кб, mp4,848x432, 0:07
>грядет новая эра питона
То есть, лет через 6-9 (когда GIL удалят и из флагов, а его удалят!) приличный кусок маленьких проектов, которые авторы писали для себя, и выложили в сеть по доброте душевной, превратятся в тыкву, если тысячи людей за эти 6 лет не потратят дополнительный кусок своей жизни на переписывание проектов, которые им давно не интересны.
В то же время, мы понимаем, что если бы 15 лет назад (или когда там змея родилась?) послушали инженеров, а не маркетологов, усиленно напирающих на популярные, а не полезные фичи, то через 8 лет мы бы оказались в точке не хуже, чем та, где GIL сначала разработали, потратив кучу ресурсов, а потом удалили, потратив еще одну кучу.
Интересно, если суммировать все это время, сколько человеческих жизней, получается, убило одно недальновидное решение?
Зачем ты скопировал комент с петухабра?
Какую часть питона лучше вкатывать? Попсу типа pandas либо сейчас есть что-то ещё актуальное в этом направлении? Мб есть тут кто уже успешно работающий, был бы благодарен ему за совет.

 906 Кб, mp4,
906 Кб, mp4,432x432, 0:10
Тут специфически. Есть типы которые используют для машинного обучения готовые инструменты и библитеки готовые в том же питоне, особо не вникая не в матанализ ни в прочую хуйню для ботанов.
А есть типы с высшим образованием которые эти инструменты разрабатывают. Там да, дохуя дефицит кадров требование к матбазе и оч большие зарплаты.
Но твое резюме даже не посмотрят если нет вышки.
>А есть типы с высшим образованием которые эти инструменты разрабатывают. Там да, дохуя дефицит кадров требование к матбазе и оч большие зарплаты.
Вот. У меня просто есть ощущение, что ML сейчас остался во всяком крупняке, где условно занимаются раскаткой и обучением собственных ИИ-моделей и всё в таком духе.
Напиши имадж борду, че ты как не как двачер? Тут постоянно начинают замену двачу писать то на луа, то на расте и незаметно уходят в закат, после того как не могут решить где хранить картинки с постами...
Но ведь питун это высокоуровневая обертка для Си, там под капотом всё на ПРАВИЛЬНОМ языке написано. Если питонический код медленно работает, значит ты опять ни хуя не понял где горлышко бутылки.
>не могут решить где хранить картинки с постами
А чем их православный S3 не устраивает не знаешь?
>рулит макака с гранатой в жопе
У неё и ассемблер будет тормозить. Если хотя бы поедет, конечно.
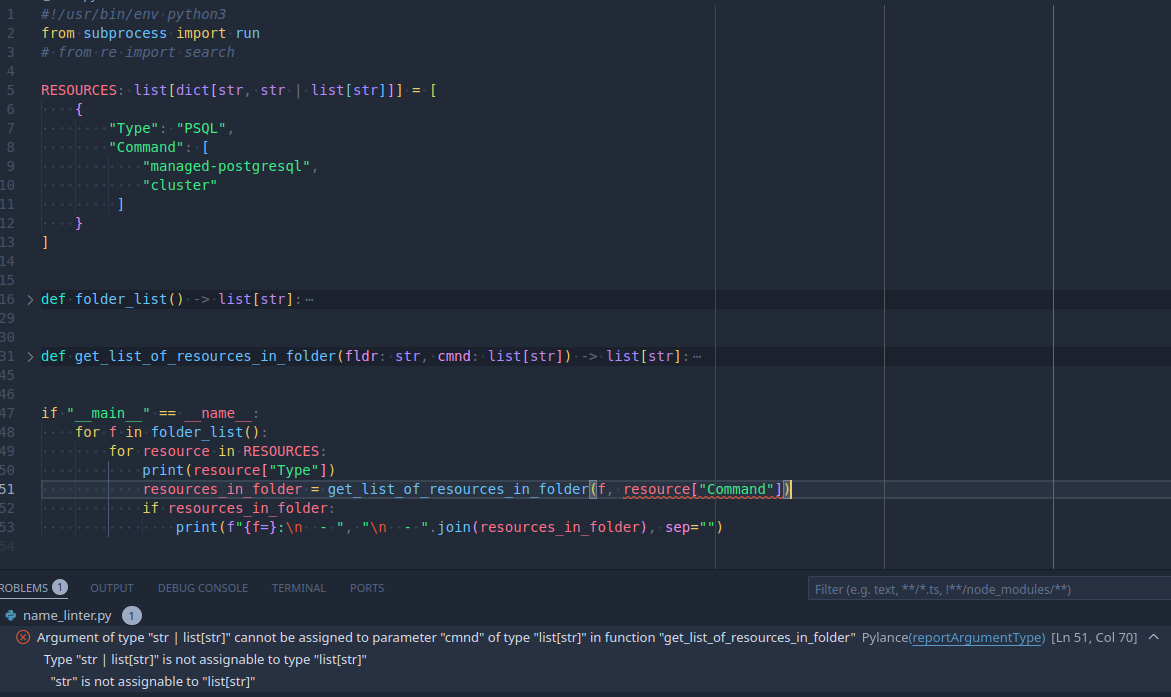 107 Кб, 1171x697
107 Кб, 1171x697> Type "str | list[str]" is not assignable to type "list[str]"
У меня вэлью дикта может быть строкой, а может быть массивом строк, почему массив строк не может быть передан там, где ждут массив строк?
Скрипт работает, с логикой всё норм.
> , почему массив строк не может быть передан там, где ждут массив строк?
Он может. Только вот ошибка говорит про другое.
Ты в качестве аргумента, тип которого должен быть строго list[str], пытаешься подсунуть выражение, тип которого либо str, либо list[str]. Вот тебе и пишут, что если тип этого выражения внезапно окажется str, то такой вызов будет невалидным.
 66 Кб, 1366x768
66 Кб, 1366x768вскод для красивой подсветки буковок + запуск скрипта из консоли. Большего тебе не надо для огэ твоего или как его там.
Бля, а я ведь сдавал в последний год когда код ещё писали на листочке, выпуск 2020
>cmnd: str | list[str]
Финт, конечно, понятный. Но там str впихнуть можно только через split()… Пока что так и сделал: заменил "str | list[str]" в дикте на "str" и добавил split() туда, где он используется. Но это какая-то странная хуйня.
>>465425
Есть правильный способ, есть полу-правильный способ и есть то, что подойдёт тебе.
Правильный способ: ставь Линукс и не выёбывайся, венда не предназначена для работы от слова вообще. Ставь хоть на виртуалку, хоть на некро-пк/ноут, оставшийся от прадедушки, куда и как угодно. Если только для Питона, то бери серверные сборки без гуя, тебе кроме консоли ничего не понадобится. Бонус: у многих облачных провайдеров можно разжится бесплатной виртуалкой с линуксом (придётся платить только несколько рублей в месяц за публичный IP) и заходить на неё по ssh. Многие IDE умеют исполняться на ремоут-хостах по ssh.
Полу-правильный способ: ставь WSL и работай в нём. Это почти линукс, затянутый внутрь венды. Лучше, чем ничего.
Подойдёт тебе: запускайся не в этой консоли. Где точно — зависит от того, что из имеющегося на твоём компе нормально работает с Unicode. Можешь попробовать IDLE, CMD, сам PS в отдельном окне или поставить, например, git-bash или Б-гомерзкую MobaXterm.
Попробуй переименовать файл во что-нибудь без пробелов и кавычек. Только английские буквы и цифры
> Пока что так и сделал: заменил "str | list[str]" в дикте на "str"
Охуенно. Но при этом значения в дикте у тебя как были и str и list[str], так и остались? И нахуй тебе вообще эти тайпхинты, если они неверные?
> split
При чем тут split вообще? Ты фактически просто решил отдельные строки сделать списками из одной строки. В отрыве от твоего говноскрипта - это вполне себе нормальное решение, только пишется оно как [str]. Нахуя для этого split вызывать, я в душе не ебу. Ты походу вайбкодер какой-то.
> Но там str впихнуть можно только через split()
Где там?
На Русском Питоне пиши, жертва ЕГЭ.
 174 Кб, 720x1310
174 Кб, 720x1310Спросил дипсик, говорит похуй, учи, только некоторые темы отдельно уточняй, а так 80% одинаковые. На скрине темы, которые по мнению дипсика будут изменены в 1 томе.
Прав ли он? Стоит ли ебать себе голову или серьёзные изменения будут только со второго тома?
Мб взять что-то актуальнее, ведь как везде пишут Питон - активно обновляющийся язык
Сначала купил, потом подумал. Хороший гой.
Зачем это учить и читать вообще, когда у тебя есть дипсик, который в любой момент объяснит как писать правильно? Ты просто пишешь код, а в непонятный момент спрашиваешь у нейронки. Это самый эффектинвый способ обучения. Талмуды были нужны 50 лет назад, когда их заучивали, т.к. в случае чего информацию было взять неоткуда, кроме библиотеки. Сейчас у тебя все знания мира в телефоне даже без поиска.
f строки мастхев
тайп хинты упростились
pathlib изучить отдельно не проблема
датаклассы все еще юзаются (или Pydantic, что очень похоже)
морж только на легаси
остальное отдельно погугли, в целом книга вполне хороша
Не объяснит.
Делай датакласс, неймдтюпл или тайпддикт и не еби себе мозги.
Поставь вскод и не еби себе мозги.
> в дикте у тебя как были и str и list[str], так и остались?
Нет, там теперь str. Примерно так, в дикте было:
> "Command": ["managed-postgresql", "cluster"],
Стало:
> "Command": "managed-postgresql cluster",
А там, где используется значение (в виде не строки, а листа строк) — я делаю её сплит. Так по крайней мере заявленные хинты соответствуют реальности, а не как предлагал >>465362, у которого выходило, что метод готов прохавать строку, хотя тогда она вызвала бы ошибку. Теперь оно готово принимать строки, самостоятельно приводя их к правильному листу.
>Ты фактически просто решил отдельные строки сделать списками из одной строки
Нет. В get_list_of_resources_in_folder ждало список строк, примерно так:
> full_command: list[str] = ["yc", "list", "--folder-name", folder, "--format=json"]
> full_command[1:1] = sub_command
а теперь ждёт строку и перед использованием приводит её к списку строк. Вот так:
> full_command: list[str] = "yc {sub_command} list --folder-name {folder} --format=json".format(sub_command=sub_command, folder=folder).split()
А после этого вызывается "subprocess.run(full_command, …)", которому первым параметром надо именно лист строк.
> Ты походу вайбкодер какой-то.
Только сейчас узнал, что это и нет, наоборот я уже несколько человек обоссал за то, что они мне подсовывали галюны нейросетей. Программирование это, конечно, не мой основной профиль, но когда я что-то делаю — я стараюсь сделать правильно, потому и прислушваюсь ко всем замечаниям линтеров и гайдлайнов, чтобы разобраться, почему именно так.
>сейчас уже и 3.11 вышел
3.13.3 есть, а скоро выйдут новые, тебе так и так с каждой версией разбираться с изменениями и новыми возможностями. Так что можешь фундамент получить и по условно-старой книге (но не 4 издание, там было слишком много про 2.7, которое сильно отличалось, а теперь — окончательно депрекейтед), а потом просто почитаешь пепы с изменениями.
>>466467
>Зачем это учить и читать вообще,
Правильно, делай без понимания, главное просто делай, однажды нейронка угадает, как надо.
Очень напоминает вот эту шутку:
https://sortvisualizer.com/bogosort/
>>466647
Есть два полярных подхода, на одном из них справочники типа таких: https://goalkicker.com/ , тут только важное, минимум постороннего текста. А на другом — Лутц, в котором идея будет разжёвываться и повторяться, зато запомнить 10% прочитанного ≡ выучить справочник наизусть. Для меня Лутц это идейный наследник автора лучшего в моей жизни учебника по физике — Лансберга.
> , после того как не могут решить где хранить картинки с постами...
Ничего подобного у меня всё просто.
C:/document and setting/Матвей_2015/изображения/двач
Так вопрос был не где товарищу майору хранить изображения с двача, а где на сервере хранить для дваче лайк борды
pyright - хорошая интеграции с lsp, поддерживает недокументированные возможноти lsp которые работают только в vscode (тормоза на ноде)
python-language-server - интеграция всего в lsp от rope до mypy (тормоза на питоне)
pylyzer автор забросил недопилив толком (работал быстро на расте)
ty (на расте, еще не рабочий, может тоже забросят)
ruff в основном линтинг и форматирование, но имеет lsp интеграцию (работает быстро на расте, но сосет у pylint по анализу проекта)
pylint гипертормоза и считает что у моделей sqlachemy слишком мало методов
isort - сортирует импорты (ruff тоже могет, но сосет у isort)
flake8, pyflake, black и пр полудохлое
Вкатун, плиз.

Мошный опенсорсный python-lsp-server, но он неюзабельный из-за питонячих тормозов + еще проверка типов хуже по сравнению с pyright
Бамп. Есть тут ИИ внедряторы?
Есть какой-то курс на степике хороший? Или книжка?
И как вообще вариант в дипсике написать промпт, чтобы он составил план для меня и всё пояснял по плану?
Вот такой промпт ему составил. Буду по его плану двигаться и уточнять всё.
"Ты — гуру Python с уровнем знаний создателя языка. Ты разработаешь интенсивный, структурированный план изучения Python на 12 недель с акцентом на:
Автоматизацию тестирования (pytest, unittest, Selenium, API-тестирование).
Работу с базами данных (SQL, SQLite, PostgreSQL, ORM — SQLAlchemy, Django ORM).
Парсеры (BeautifulSoup, Scrapy, requests, aiohttp).
Чат-боты (Telegram Bot API, Discord.py, обработка асинхронности).
Основы Django (модели, views, REST с DRF).
Git, GitHub/GitLab (ветвление, CI/CD, работа в команде).
Условия:
4 часа в день (пн–пт), 6 часов в выходные.
Практико-ориентированный подход: 60% кода, 30% теории, 10% ревью/оптимизация.
Каждая неделя должна заканчиваться мини-проектом по теме.
Постепенное усложнение: от основ Python до сложных связок (например, парсер + БД + бот).
Формат плана:
Четкие темы по дням.
Рекомендуемые ресурсы (документация, книги, туториалы).
Примеры задач для закрепления.
Советы по отладке и лучшим практикам.
Начни план с базового синтаксиса (1 неделя), но сразу включай примеры из целевых областей (например, тесты для простых функций). К 6-й неделе — углубление в автоматизацию, к 10-й — интеграция всех навыков (например, бот, который парсит данные и сохраняет в БД). Последние 2 недели — работа над комплексным проектом (например, тестовый фреймворк + CI).
Дай рекомендации по IDE (PyCharm, VS Code), инструментам (Docker, Postman) и лайфхакам для запоминания. Упомяни, как избегать выгорания."
Вот такой промпт ему составил. Буду по его плану двигаться и уточнять всё.
"Ты — гуру Python с уровнем знаний создателя языка. Ты разработаешь интенсивный, структурированный план изучения Python на 12 недель с акцентом на:
Автоматизацию тестирования (pytest, unittest, Selenium, API-тестирование).
Работу с базами данных (SQL, SQLite, PostgreSQL, ORM — SQLAlchemy, Django ORM).
Парсеры (BeautifulSoup, Scrapy, requests, aiohttp).
Чат-боты (Telegram Bot API, Discord.py, обработка асинхронности).
Основы Django (модели, views, REST с DRF).
Git, GitHub/GitLab (ветвление, CI/CD, работа в команде).
Условия:
4 часа в день (пн–пт), 6 часов в выходные.
Практико-ориентированный подход: 60% кода, 30% теории, 10% ревью/оптимизация.
Каждая неделя должна заканчиваться мини-проектом по теме.
Постепенное усложнение: от основ Python до сложных связок (например, парсер + БД + бот).
Формат плана:
Четкие темы по дням.
Рекомендуемые ресурсы (документация, книги, туториалы).
Примеры задач для закрепления.
Советы по отладке и лучшим практикам.
Начни план с базового синтаксиса (1 неделя), но сразу включай примеры из целевых областей (например, тесты для простых функций). К 6-й неделе — углубление в автоматизацию, к 10-й — интеграция всех навыков (например, бот, который парсит данные и сохраняет в БД). Последние 2 недели — работа над комплексным проектом (например, тестовый фреймворк + CI).
Дай рекомендации по IDE (PyCharm, VS Code), инструментам (Docker, Postman) и лайфхакам для запоминания. Упомяни, как избегать выгорания."
Спасибо!
 150 Кб, 897x783
150 Кб, 897x783Хуйню нереалистичную задумал. У тебя нет ресурса чтобы выучить и скрэпи, и селениум, и гитлаб с докером. Нейросети магическим образом тебе времени не добавят. Используй 20/80 промпт. Закрывай только важные дыры.
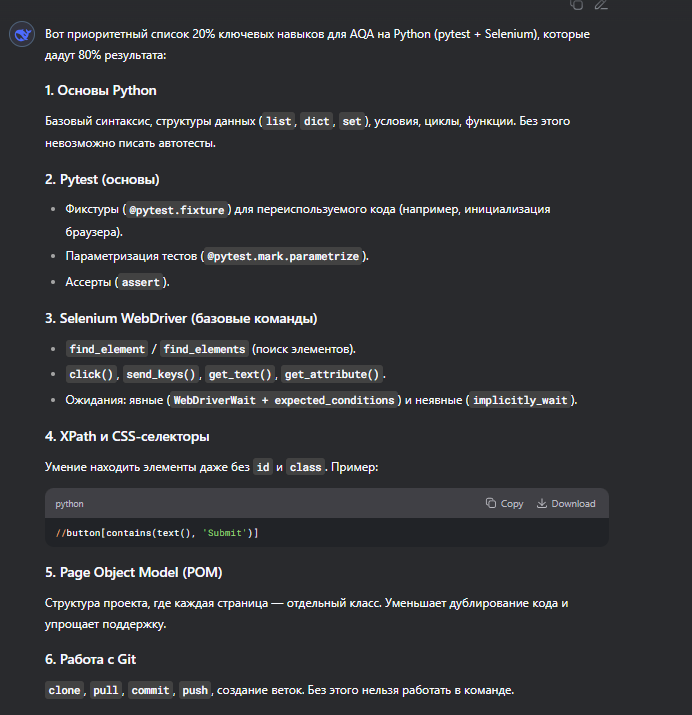

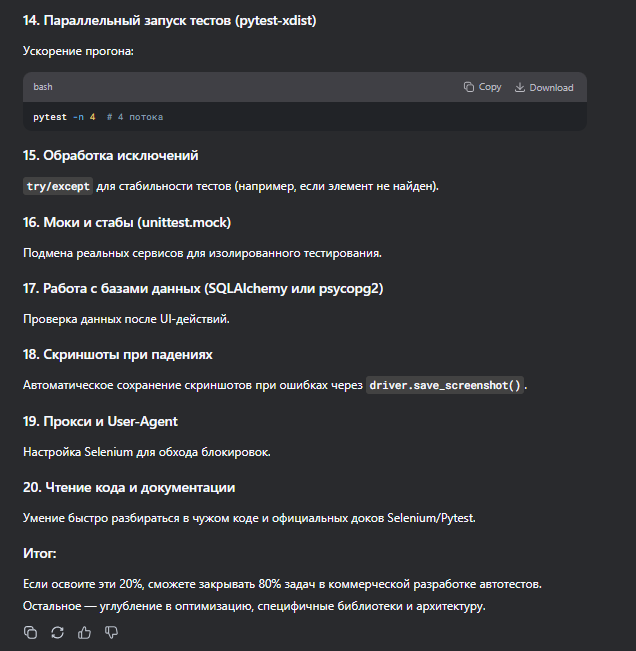
Понял.
Но дипсик всё равно задрачивает с докером. И выдаёт просто сухой текст, типа:
>REST API-тестирование (requests)
>Многие проекты требуют проверки API.
Пока я это всё буду у него спрашивать и расспрашивать, пройдёт уйма времени. Я в целом изи схватываю всё. В ВУЗе в многопоточность мог на ++, но к 29 годам щас всё нахуй забыл и хочется с базы базовой начать. А хуйсик расписал базу как
> Базовый синтаксис, структуры данных (list, dict, set), условия, циклы, функции. Без этого невозможно писать автотесты.
Нет бы сразу все по пунктам дал.
Короче по твоему принципу буду разбираться, в общем. Спасибо тебе!
>проприетарный
Во-первых это точно минус? Почему?
Во-вторых:
> CC-BY-4.0 license
Ты уверен, что правильно понимаешь смысл слова "проприетарный"? Что оно для тебя значит? Опиши, пожалуйста.
А то окажется, что приблизительно всё ПО в мире проприетарное.
>это точно минус?
Конечно. Я вскод не использую же, поэтому не могу ни использовать пиланс, ни адаптировать его под свой кейс
и сс это обычно лицензия не для софта
а вот у пиланса EULA https://marketplace.visualstudio.com/items/ms-python.vscode-pylance/license
Придумай проект простенький да крути его с подсказками ии. Я себе тг бота сделал с напоминалками, алертами и поиском по своему хранилищу различных файлов, поскольку уже заебался руками по папкам скрипты и записи искать. Это чисто твой проект и насилуй его на сколько фантазии хватит. За месяц и ооп, и основные библиотеки и даже гит с логированием освоил.
Тоже рассматривал этот вариант. Именно чат бота, а потом уже автотест на него.
Только вот, допустим, как я узнаю о множествах (set) в питоне при таком подходе?
Мне тупо надо питон для того, чтобы потом автотестером пойти, ручником заебало + потолок в 180-200к в основном на рынке.
Я сейчас с дипсиком всю базу пройду за пару дней (типы данных, преобразование, функции базово и т.д.). потом буду пилить чат-бота и тесты на него... план такой, в общем.
 286 Кб, 1920x1080
286 Кб, 1920x1080все стер нахуй
Изучи базовый синтаксис
ООП
Всякие обработки ошибок в блоках try/except
Логирование
Паттерны проектирования автотестов
Принципы программирования
По фреймворкам
Pytest - база для автотестов, изучить надо подробно его возможности, маркеры, параметризацию, фикстуры, как тесты запараллелить через xdist какой-нибудь
Selenium / playwright для UI тестов (playwright в наше время выглядит интереснее)
requests / httpx - для rest аpi (лучше httpx, т.к. на нем еще асинхронщина есть)
grpc - либа для grpc протокола
SQLAlchemy для БД (там тоже есть асинхронщина, для синхронного пг какого-нибудь psycorg2)
Allure для отчетов
докер нужен супербазово, как и ci/cd понимание (по типу набросать yaml файл для gitlab)
Все остальное, что тебе там написало выкинь нахуй, там большая часть либ для разработки, в автотестах тебе понадобятся они примерно никогда
Спасибо большое!
А нахуя ему grpc в одном ряду с основами? grpc апи разве такая распространённая штука уже, что прям с начинающих тестеров требуют? Не быкую, интересуюсь просто, с остальным согласен.
gprc как дополнение к основному, да, ты прав анонче
>grpc апи разве такая распространённая штука уже
Я лично вижу часто. Конечно, не так часто, как REST, но если что-то предоставляет публичное API, то там очень часто REST+gRPC. Так что лишним не будет. В конце концов, зная REST понять gRPC не так уж сложно мягко говоря.

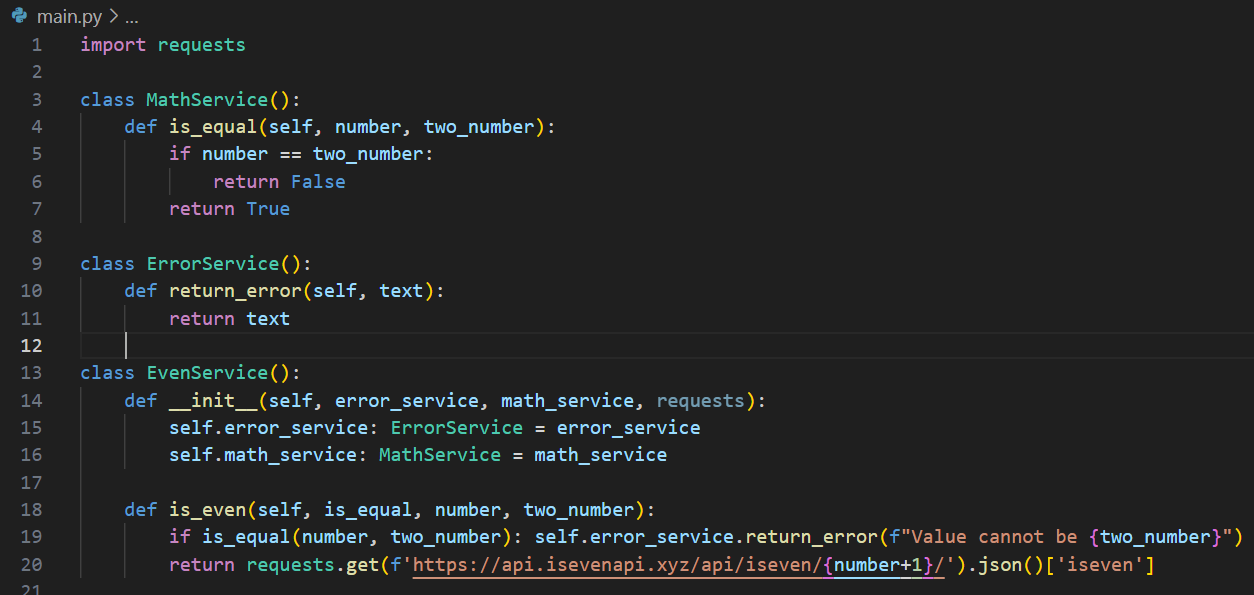
two_number это самое смешное
спасибо супер герой
чтобы я сказал ему пакет, и софт скачал этот пакет и все его зависимости в текущую папку, а не в ~/.cache/pip/хуй/пизда/джигурда/a/b/c/2/2/8/dsfdskjfhdskjfhsdhfdskhfkjdshkdshfdsfs.bin
Downloading torch-2.7.1-cp313-cp313-manylinux_2_28_x86_64.whl (821.0 MB)
━━━━━━━━━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 244.6/821.0 MB 1.6 MB/s eta 0:06:02
WARNING: Connection timed out while downloading.
WARNING: Attempting to resume incomplete download (244.6 MB/821.0 MB, attempt 1)
Resuming download torch-2.7.1-cp313-cp313-manylinux_2_28_x86_64.whl (244.6 MB/821.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━ 533.7/821.0 MB 1.6 MB/s eta 0:03:03
WARNING: Connection timed out while downloading.
WARNING: Attempting to resume incomplete download (533.7 MB/821.0 MB, attempt 2)
Resuming download torch-2.7.1-cp313-cp313-manylinux_2_28_x86_64.whl (533.7 MB/821.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 819.2/821.0 MB 2.1 MB/s eta 0:00:01
WARNING: Connection timed out while downloading.
мать ебал того кто придумал наговнокодить софт для скачивания без поддержки докачки
Иши крвартиру с нормальным тырнетом
https://github.com/pypa/pip/issues/4796
> [Improvement] Pip could resume download package at halfway the connection is poor
> ichard26 closed this as completedin #12991 on Apr 12, 2025
смотрю #12991
они добавили опцию --resume-retries ахах))00)0 тип если на последней секунде загрузка обрывается
>>471951
> Resuming download torch-2.7.1-cp313-cp313-manylinux_2_28_x86_64.whl (533.7 MB/821.0 MB)
> ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 819.2/821.0 MB 2.1 MB/s eta 0:00:01
> WARNING: Connection timed out while downloading.
то пип выкачивает файл заново)0)) сука мать ебал этих питонистов
Чел. Какой пидон тебе. Ты с твоим мобильным легасистанским интернетом не сможешь гитом пользоватся. Ты просто не сможешь большую репу склонировать. В гите просто не может быть докачки при клонировании..
Попробуй https://github.com/astral-sh/uv
> Попробуй https://github.com/astral-sh/uv
работает кривовато, но намного лучше, чем дефолтный pip, спасибо!
случайно не знаешь, как заставить его качать архивы .whl вместо отдельных уже распакованных файлов?
> $ uv --cache-dir ./tmp pip download bitsandbytes
> error: unrecognized subcommand 'download'
если сделать uw pip sync requirements.txt, то какие-то пакеты он качает в виде .whl, а какие-то уже распакованные папки, мне хотелось бы все пакеты в виде .whl
В КР все нейронки доступны чел. Хоть какая-то польза
 132 Кб, 588x604
132 Кб, 588x604Держи в курсе.
Всю СЛОЖНУЮ часть за тебя уже сделали. Тебе осталось научиться пользоваться инструментами.
Сычев, всю сложную работу за тебя уже сделали, тебе осталось только сделать хттп ручку для скоринга клиентов Азино666.
Но ведь это реально так и есть. По сравнению с той математикой, что уже придумана, скоринг это уже прост как калькулятор.
А учиться так и так нужно. Даже есть пойдёшь бухгалтером, тебе надо освоить предметную область хоть немного и научиться в 1с, зато все действия в эске в итоге делаются двумя педалями.
version_1.0
version_1.1
version_1.1_fix
version_1.2
version_2.0
version_2.0_fix
version_2.0_fix2
Новая папка
Новая папка (1)
пориджи с их venv просто переизобрели разные папочки лол
Как тебя папочка спасет от замусоривания site-packages разными версиями зависимостей? При том pip сам по себе не умеет удалять зависимости зависимостей.
Venv это именно окружение, а не контроль файлов твоего проекта
так venv это и есть локальный site-packages в текущей папке ./ вместо дефолтного ~/.cache/pip/site-packages/
ебать ор
>>473408
>Version Control System в виде разных папочек
Ну такое. Пока я не узнал о существовании гита это было норм, сука, нам даже в универе на первом курсе (в 2003м) предодша по программированию советовала сохранять разные версии кода в отдельных папочках!
>venv
Но ведь виэнв нужен для другого. А именно только для дебага, к рабочему продукту он отношения не имеет потому, что Docker.
И вообще по дефолту виэнв прописывает фул-пас и его уже нельзя просто так скопировать.
1) Ну о том и речь. Если ты будешь
Новая папка
Новая папка (1)
ты так же можешь все зависимости срать в одну кучу куда нибудь ~/.cache/pip/site-packages/
2) venv похуй где у тебя сайт пакеджес. Оно не обязательно у тебя в папке с кодом. Всякие pipenv например автоматически создают для тебя твои venv в отдельной .virtualenvs/ директории, когда ты делаешь pipenv install numpy
Я почти с нуля
Подрочи.
pip качает всё в локальную папку, а потом распаковывает внутрь venv, а мне не нужны десятки гигабайт говна в ~/.cache
> мне не нужны десятки гигабайт говна в ~/.cache
Но ведь ~/.cache буквально предназначен для десятков гигабайтов говна. Если бы оно вместо этого сохранялось в /tmp было бы ровно тоже самое, только перекачивать, возможно, пришлось бы чуть чаще, если ребутаешься регулярно.
> ПОЧЕМУ В ДИРЕКТОРИИ КЭШ СОДЕРЖАТСЯ КЭШИРОВАННЫЕ ДАННЫЕ??????? ТУПОЙ ПИТОН!
Самый смешной тред на этой доске.
пчел я хочу чтобы при создании "виртуального окружения" всё питонье говно складировалось именно внутри этой конкретной папки, а не срало мне в ~/, в /tmp, в небо, в аллаха.
Проверил у себя.
ОКАЗЫВАЕТСЯ, МНЕ В ~/.cache/ НАСРАЛИ:
Абсолютно все браузеры (больше всех). Абсолютно все редакторы (видео, фото, текстовые), PIP, несколько эмуляторов терминала, игры, видеоплееры, скриншотилки и ещё, наверное, сотня программ из категории "разное". Пиздец! Как они все посмели хранить кэш в папке для кэша?
Маня, ты обосралась, просто признай это. Разрешаю умолкнуть без извинений.
И да, для совсем уже дегенератов:
> ~ ➤ pip --help | grep cache 0
> cache Inspect and manage pip's wheel cache.
> --cache-dir <dir> Store the cache data in <dir>.
> --no-cache-dir Disable the cache.
 1,1 Мб, mp4,
1,1 Мб, mp4,576x1024, 0:10
Заметил, что многие к питону довольно предвзято относятся, дескать из-за простоты в освоении он потерял очки престижа. Хотя по факту вакансий на питон в разы больше. Но вопрос в другом, какое направление вы выбрали для дальнейшего развития и на чем выбор основывался?
>из-за простоты в освоении
когда что-нибудь асинхронное многопоточное напишешь и оно не будет зависать тогда и приходи
Ты ебанутый? Где ты видел, чтобы кэш хранился в том же месте, где и то, что мы кэшируем? В чем тогда смысл кэша?
Я бы уточнил, с чего вообще начать.
а зачем писать многопоточку на петухе?
асинхронщина вообще по мнению многих крутанов в питоне считается чуть ли ни раком
>Задача такая: имеется набор данных, нужно построить линейные уравнения регрессии
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
рак мозга у тебя
>В чем тогда смысл кэша?
Ты путаешь кэш и бэк. Суть кэша только в том, чтобы не проводить заново некую операцию, временно сохранив её результаты.
>>475937
"Асинхронщина" это хлеб и кровь и плоть и вообще единственный смысл который в 25 году остался в питоне. Если для тебя это новость, значит ты какая-то залетуха с курсов.
Пиздец, пол года в тред не заходил а тут одни нуфани и скриптокиди остались.


пикрил 2 в изобилии имеет кучу перевода в стиле "ее рука хуй иметь ебал я", из-за чего некоторые вещи мне не понятны. в целом умею писать простенькие консольные программы, но хочется лучшего понимания, чтобы не путаться и обладать какой-то логикой действий. а то даже простые программы могу косячно писать, долго переписывая как будет лучше имхо.
мне немного надо, я как хобби после работы изучаю. вкатываться не планирую, нейросети и университетчики явно умнее меня.
>насколько пикрил хорош для углублённого изучения после пикрил 2?
Ты рассчитываешь что тут найдётся кто-то понимающий и читавший две конкретные книги и он будет способен адекватно сравнить и вынести вердикт?..
Удачи.
А если серьёзно -- спроси на канале "Диджитализируй!" Чувак очень много читает и ведёт книжный клуб.
>Если для тебя это новость, значит ты какая-то залетуха с курсов.
почему сразу "залетуха"? может он джангист, где, конечно, имеются декораторы sync_to_async и async_to_sync, но что-то похожее асинхронщину завезли, если не ошибаюсь, в django 4.
сам эту лабуду не использовал, проще все писать на каком-нибудь fastAPI/aiohttp
 13 Кб, 447x357
13 Кб, 447x357Друзья, в процессе вката нахожусь, параллельно пробую разные инструменты.
Можно ли как-то в юпитерлабе вот этот столбец с номером шага расширить? Пробовал снижать ширину jp-Cell, но он только на правой стороне становится короче. Вызвано, скорее всего, размером шрифта.
Сделал 2 потока t1 и t2, запускаю из них функцию. Как узнать из какого потока пришел конкретный результат?
Чтобы определить, из какого потока пришел результат, можно внутри вызываемой функции получить имя текущего потока через threading.current_thread().name.
import threading
import time
def worker():
thread_name = threading.current_thread().name
print(f"Результат из потока: {thread_name}")
return thread_name
# Создаем потоки
t1 = threading.Thread(target=worker, name="Thread-1")
t2 = threading.Thread(target=worker, name="Thread-2")
# Запускаем потоки
t1.start()
t2.start()
# Ждем завершения
t1.join()
t2.join()
Если ты хочешь получить результат из каждого потока (например, собрать их), нужно использовать более продвинутый способ, например, через concurrent.futures.ThreadPoolExecutor, где можно легко сопоставить результат и поток:
from concurrent.futures import ThreadPoolExecutor
import threading
def worker():
return f"Результат из: {threading.current_thread().name}"
with ThreadPoolExecutor(max_workers=2) as executor:
futures = [executor.submit(worker) for _ in range(2)]
for future in futures:
print(future.result())
Если ты используешь threading.Thread, и хочешь вернуть результат из потока, то это можно сделать через передачу queue.Queue или оборачивание потока в класс:
import threading
import queue
def worker(result_queue: queue.Queue):
thread_name = threading.current_thread().name
result_queue.put((thread_name, f"Результат из потока: {thread_name}"))
result_queue = queue.Queue()
t1 = threading.Thread(target=worker, args=(result_queue,), name="Thread-1")
t2 = threading.Thread(target=worker, args=(result_queue,), name="Thread-2")
t1.start()
t2.start()
t1.join()
t2.join()
while not result_queue.empty():
thread_name, result = result_queue.get()
print(f"{thread_name} => {result}")
Чтобы определить, из какого потока пришел результат, можно внутри вызываемой функции получить имя текущего потока через threading.current_thread().name.
import threading
import time
def worker():
thread_name = threading.current_thread().name
print(f"Результат из потока: {thread_name}")
return thread_name
# Создаем потоки
t1 = threading.Thread(target=worker, name="Thread-1")
t2 = threading.Thread(target=worker, name="Thread-2")
# Запускаем потоки
t1.start()
t2.start()
# Ждем завершения
t1.join()
t2.join()
Если ты хочешь получить результат из каждого потока (например, собрать их), нужно использовать более продвинутый способ, например, через concurrent.futures.ThreadPoolExecutor, где можно легко сопоставить результат и поток:
from concurrent.futures import ThreadPoolExecutor
import threading
def worker():
return f"Результат из: {threading.current_thread().name}"
with ThreadPoolExecutor(max_workers=2) as executor:
futures = [executor.submit(worker) for _ in range(2)]
for future in futures:
print(future.result())
Если ты используешь threading.Thread, и хочешь вернуть результат из потока, то это можно сделать через передачу queue.Queue или оборачивание потока в класс:
import threading
import queue
def worker(result_queue: queue.Queue):
thread_name = threading.current_thread().name
result_queue.put((thread_name, f"Результат из потока: {thread_name}"))
result_queue = queue.Queue()
t1 = threading.Thread(target=worker, args=(result_queue,), name="Thread-1")
t2 = threading.Thread(target=worker, args=(result_queue,), name="Thread-2")
t1.start()
t2.start()
t1.join()
t2.join()
while not result_queue.empty():
thread_name, result = result_queue.get()
print(f"{thread_name} => {result}")
Чатгопете?
Асинхронное программирование не знаю, но в одном месте пишут с джанги начать, в другом фастапи. Хз что первым пощупать
А тебе для чего? inb4 для новичка
В фастапи вкат проще, если ты прям ничего не щупал, то лучше его.
Нет, но ты заебешься костыли вокруг того, что есть в зачаточном состоянии, писать. Проще готовый фреймворк использовать aka django. Тот чел тебе напиздел, что фастапи проще для новичков. Для новичков проще использовать готовое, чем писать например обработку ошибок кастомную, csrf токены настраивать и прочую мелкохуйню, что в жанге уже за тебя все сделано. Если возмешь фастапи то с большой вероятностью напишешь дырявое говно, без знания что и где нужно реализовать.
Я тут выше писал, что лучше для веб морды устройства?
Тут еще такая проблема что если ты используешь для этого сторонние модули, то лет через 5 они могут загнуться. А джангу просто обновил и вперед.
 53 Кб, 626x308
53 Кб, 626x308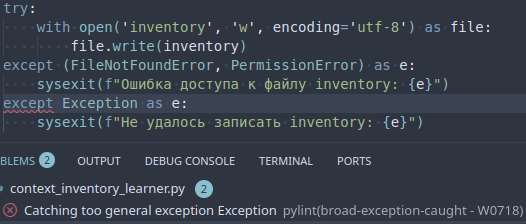 43 Кб, 526x224
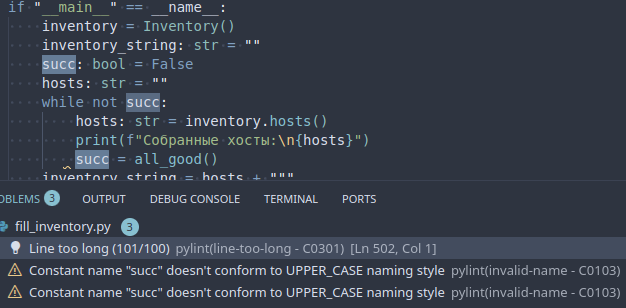
43 Кб, 526x224Вот есть такой код. ПайЛинт говорит "Catching too general exception Exception". Предлагается прочитать:
https://pylint.readthedocs.io/en/latest/user_guide/messages/warning/broad-exception-caught.html
https://stackoverflow.com/questions/14797375/should-i-always-specify-an-exception-type-in-except-statements/14797508
Я прочитал, но всё ещё не очень понимаю, как быть.
В моём понимании при попытке внести данные в файл может случиться примерно дохуялиард всяких разных вещей (RO-ФС, кончилось место на диске, диск побился на лету и так далее), которые помешают записи и по-моему вот тут вот уместно сделать "Что-то стряслось, нишмог, вот тебе ошибка, возись с ней дальше сам!", но, кажется, линтер хочет, чтобы я в таких случаях перечислял абсолютно все райзы, которые гипотетически могут прилететь в этом куске кода? Как тут идеологически правильнее поступить?
PyLint относится почти ко всем переменным, объявленным не внутри функции, как к константам. Менять они это вроде не планируют, так что можешь просто это в игнор прописать. Если загуглишь саму ошибку, найдёшь много открытых вопросов на эту тему у них в гитхабе.
>>489438
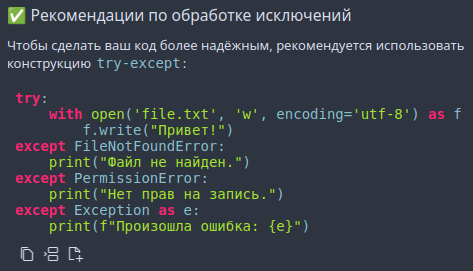
Из PEP-8:
>When catching exceptions, mention specific exceptions whenever possible instead of using a bare except: clause:
>A good rule of thumb is to limit use of bare ‘except’ clauses to two cases:
>1. If the exception handler will be printing out or logging the traceback; at least the user will be aware that an error has occurred.
>2. If the code needs to do some cleanup work, but then lets the exception propagate upwards with raise. try...finally can be a better way to handle this case.
Тоже можно заигнорить, но вообще да, как правило, эксепшены указываются явно.
>Менять они это вроде не планируют, так что можешь просто это в игнор прописать.
Мерси!
>>489449
В целом я понимаю и согласен. Но тут может произойти очень много чего и я не знаю, что именно. Бредогенератор, например, говорит о 8 видах исключений (правда, сколько он не заметил и сколько нагалюционаровал -- отдельный вопрос), но предлагает обойтись двумя явными и остальное ловить просто так (пик 1). КМК, обрабатывать все 8, чтобы выдать одинаковые сообщения -- что-то на грани между ОКР и идиотизмом, но не обрабатывать вовсе и вываливать трейс в случае чего тоже не очень хочется.
>>489632
Мне не сложно, а лишняя она не всегда, например, пустые set и dict имеют одинаковые литералы и именно на них будет смотреть IDE, LSP и LLM, а остальным -- для унификации. А вообще (сорри за оффтоп): эта привычка у меня с тех пор, как я начинал учиться программированию на Паскале, там в начале функций, процедур и программы была секция "var", в которой нужно было перечислить все переменные и их типы. Если вдуматься, то, не смотря на многословность (по факту именно она, похоже, стала причиной, по которой паскаль проиграл войну с сями), это замечательная практика, она позволяла учесть все переменные и при этом быть абсолютно точно уверенным, что вот эта переменная будет внутренней, а вот та -- придёт из более общего контекста и так далее. На 2 и 3 пиках бессмысленные и беспощадные, но рабочие примеры уровня Lab1.
> пустые set и dict имеют одинаковые литералы
Литерала пустого set нету...
Ну так избавляйся от лишних привычек. А то еще ни дай бог начнешь си писать на питоне.
>Ну так избавляйся от лишних привычек.
Зачем, если они делают код более организованным и явным?
Explicit is better than implicit.
Чел, даже в статических языках давно есть вывод типов.
> насколько пикрил хорош для углублённого изучения после пикрил 2?
Мне кажется, неплохи книжки про асинк и Fluent Python.
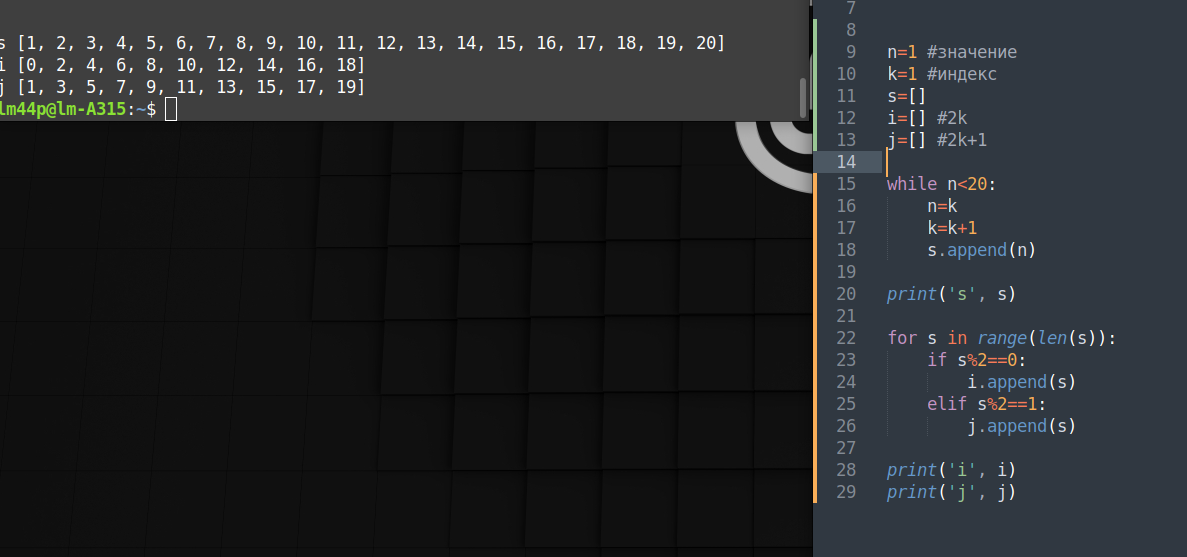
так range(len(s)) с 0 начинается
а массив s ты кикаешь тут
for s in
вместо исходного массива s у тебя пробегает значения от 0 до len(s) в цикле
for value in s:
и делать append(value) а не append (s)
Школота, я тебя сейчас по-простому обясню. Слушай сюды. Асинхронность нужна не для того чтобы паралельно что-то делать, а для того чтобы паралельно нихуя не делать. Чтобы не было блокирующего нихуя не делания. Усек? У тебя две задачи, обе могут нихуя не делать продолжитеьное время. Что лучше: обе одновременно нихуя не делают или сначале нихуя не делает одна задача, а потом нихуя не делает другая задача? Разницу усек?
Пасиб
> Что такое вайбкодинг?
это когда арч программист надевает носочки, наливает банановый смузи в стакан и наваливает hello world под крутую какирскую музыку
А терь по русски.


 107 Кб, 690x961
107 Кб, 690x961Что это за зверушка - анальник?
Да норм, все ключевые слова есть.
Но не могу не спросить, как ты планируешь конкурировать с десятками тысяч других вкатунов с базовым знанием python и sql? Ты молод и у тебя есть хорошее образование? Или по блату найдешь работу?
Я не собираюсь останавливаться только на sql и python. По мере возможности буду прокачиваться дальше и пытаться откликнуться на любую джуниор вакансию
>По мере возможности буду прокачиваться дальше и пытаться откликнуться на любую джуниор вакансию
Как и тысячи выпускников с курсов...
Ящитаю, что не надо идти как баран напролом туда, где уже места нет, других баранов ты не растолкаешь один.
Лучше осмотреться и выбрать другой путь, где есть место, пусть до этого пути и надо будет больше шагов сделать.
Ой, как плохо... Прямо по коду понятно, что у тебя нет понимания происходящего.
Это когда вместо того, чтобы писать код "кодер" пишет промт ЛЛМ-ке, который описывает, что код должен делать. Правда на практике есть куча нюансов. Ищи "Курсор".
Недавно я пробовал более казуальный вариант: я подключил себе одну из бесплатных ЛЛМок и написал скрипт на 650 строк, она нагенерировала за меня ~80% кода и 100% документации, я просто сэкономил время на ручном набивании блоков кода, типа написал несколько букв, получил 3-5 строк функционал которых угадан по названию функции и окружающему коду. Это не чистый вайб-кодинг, но меня устраивает: я предпочитаю лучший контроль над результатом.
> Ищи "Курсор".
Это жизнеспособно для человека который и сам писать может?
> Недавно я пробовал более казуальный вариант: я подключил себе одну из бесплатных ЛЛМок и написал скрипт на 650 строк, она нагенерировала за меня ~80% кода и 100% документации,
Как сделал?
Он в целом прав, но есть нюанс: на вопрос
>И где есть место сейчас?
нельзя ответить. Потому что если этот ответ становится известен всем анонам на дваче, значит туда уже ломятся толпы с курсов.
Другое дело, что у того, кто освоит сам обычно дела обстоят лучше. 98% вкатышков с курсов считают, что им дали достаточно и сами не особо развиваются сверх этого, поэтому и сосут с причмокиванаием. С другой стороны те 2%, которые продолжают развиваться ещё и получили перед этим хорошую порцию структурированных знаний и пинок в нужном направлении.
Ладно, пару вещей я подскажу:
DevOps -- тут есть дефицит мидлов, так что ещё можно пытаться.
QA -- хороших спецов даже уровня джунов мало. Другое дело, что и спрос не слишком большой.
Sec -- тут ВЕЧНЫЙ голод. Но тематических курсов нет. Угадаешь почему? Потому что это охуеть как сложно и за 2-4 месяца этому научить невозможно, это нужно с 12 лет было читать журнал "Хакер", а с 14 -- сидеть на тематических форумах, постепенно погружаясь в пучины даркнета. Тогда к 20 есть хороший шанс найти или уютное место для вайтхэта или неуютные нары.
>Это жизнеспособно для человека который и сам писать может?
Только для таких и жизнеспособно, потому что только такие могут проверить, что им там негенерировала ЛЛМ.
Как анон выше написал, я за тебя не могу ответить на этот вопрос. Ты САМ должен поднять голову и осмотреться. Иначе будет очередное бодание не в ту дверь.
>Это жизнеспособно для человека который и сам писать может?
Да, но есть ненулевая вероятность, что ты будешь час бодбирать реализацию метода, который сам бы написал за 20 минут.
Вообще категорически советую воспринимать ЛЛМ как множитель для скила.
>Как сделал?
Ладно, накидаю в общих чертах.
Я знаю питон, но часто не знаю либ с которыми работаю. Вообще для меня это не профессия, поэтому работаю то с тем, то с сем.
От чего? От отступов, блядь? Как вы дегенераты заебали.
Проблемы есть, но другие. Алсо предложи альтернативу.
Нет, не пойми не правильно. Я про само самочувствие, если не тошнит, то может, стоит самого себя тащить дальше? Новое изучить в рамках ЯП.
Да, но.
В питоне нет констант которые чисто константы, есть переменные, записанные КАПСом, которые договорились считать константами. Ты можешь вынести их во внешний модуль и импортировать, например:
module.py:
> KONSTANTA = 1
main.py:
> import module
> print(module.KONSTANTA)
или
> from module import KONSTANTA
> print(KONSTANTA)
Мысль сформулируй.


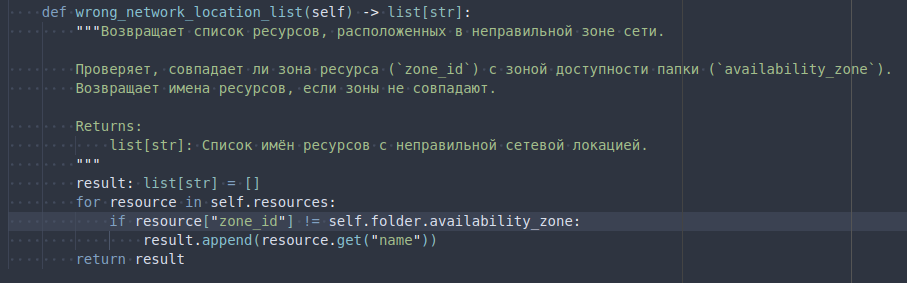
>Ладно, накидаю в общих чертах.
Даже не в общих, а на настоящем примере.
Итак, задача: инвентаризация и аудит облака. СУГУБО ПРИКЛАДНАЯ (из категории "мне было лень лазить по папочками руками"), это даже скорее скриптинг, чем программирование, но код есть код, а в этом случае код безопасный, ничего особого не спалить (все секреты сильно снаружи), а код не сможет накосячить (тем более, что я понимаю значение каждой запятой). Идеально для тестирования LLM.
Есть облако с пользователем с некими правами, пользователь может выполнять консольные вызовы через специальную утилиту для манипуляции ресурсами в облаке. В облаке есть фолдеры под отдельные проекты, в фолдерах есть сервисы (например, ALB (Application Load Balancer) или managed PSQL)
Структура: класс Cloud при ините получает список папок и создаёт по объекту класса Folder, сохраняет в список.
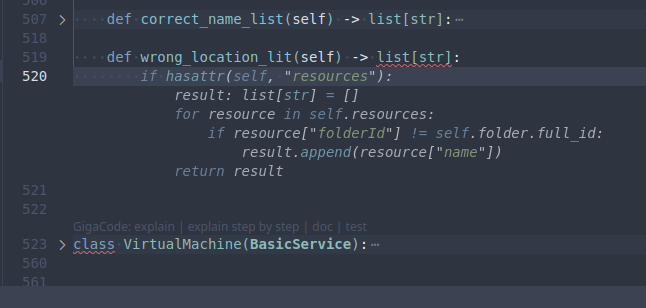
При ините класса Folder создаётся list[dict[str, BasicService]], где BasicService это базовый класс для сервисов (есть ещё несколько классов, сервисов которые наследуются от него, но имеют отличные в чём-либо обработчики, например, для разных ресурсов может различаться Naming Convention). В классе BasicService при ините выбираются и запоминаются все ресурсы определённого типа, сохраняются в list[dict], полученном из JSON-выхлопа той самой консольной тулзы.
Я хочу добавить проверку расположения ресурса (что он находится в той зоне доступности, где ему положено). Я добавляю в класс BasicService метод и мне сразу подсказывают что за метод я могу написать: __str__ (пик 1). Ну мне нужен другой, потому я ввожу имя и возвращаемый тип сам, жму Enter и мне сразу предлагает готовый код (пик 2)! И из этого кода (даже не смотря на опечатку в имени метода) 80% уже пойдёт в бой, нужно только поправить проверку потому что он решил, что я хочу проверить, находится ли ресурс в правильной папке, а мне надо проверять, находится ли он в правильной зоне доступности.
Осталось документировать новый метод, иду к определению класса и тыкаю там в "doc" (пик 3), ещё пара кликов и метод готов к использованию (пик 4). На 5 строк рабочего кода я ввёл 2 слова, остальное подставила моделька.
На выходе имеем по сути автоматизацию бОльшей части набора текста. А рядом -- чат, в котором можно уточнить какие-то детали по языку или попросить совета по реализации.
НО надо твёрдо понимать, что нельзя рассчитывать, что он выдаст идеальный код, что за ним надо проверять, что LLM вообще склонны к галлюцинациям и так далее. Чем более общий вопрос им задаёшь, тем качественнее и валиднее будет ответ.
>Ладно, накидаю в общих чертах.
Даже не в общих, а на настоящем примере.
Итак, задача: инвентаризация и аудит облака. СУГУБО ПРИКЛАДНАЯ (из категории "мне было лень лазить по папочками руками"), это даже скорее скриптинг, чем программирование, но код есть код, а в этом случае код безопасный, ничего особого не спалить (все секреты сильно снаружи), а код не сможет накосячить (тем более, что я понимаю значение каждой запятой). Идеально для тестирования LLM.
Есть облако с пользователем с некими правами, пользователь может выполнять консольные вызовы через специальную утилиту для манипуляции ресурсами в облаке. В облаке есть фолдеры под отдельные проекты, в фолдерах есть сервисы (например, ALB (Application Load Balancer) или managed PSQL)
Структура: класс Cloud при ините получает список папок и создаёт по объекту класса Folder, сохраняет в список.
При ините класса Folder создаётся list[dict[str, BasicService]], где BasicService это базовый класс для сервисов (есть ещё несколько классов, сервисов которые наследуются от него, но имеют отличные в чём-либо обработчики, например, для разных ресурсов может различаться Naming Convention). В классе BasicService при ините выбираются и запоминаются все ресурсы определённого типа, сохраняются в list[dict], полученном из JSON-выхлопа той самой консольной тулзы.
Я хочу добавить проверку расположения ресурса (что он находится в той зоне доступности, где ему положено). Я добавляю в класс BasicService метод и мне сразу подсказывают что за метод я могу написать: __str__ (пик 1). Ну мне нужен другой, потому я ввожу имя и возвращаемый тип сам, жму Enter и мне сразу предлагает готовый код (пик 2)! И из этого кода (даже не смотря на опечатку в имени метода) 80% уже пойдёт в бой, нужно только поправить проверку потому что он решил, что я хочу проверить, находится ли ресурс в правильной папке, а мне надо проверять, находится ли он в правильной зоне доступности.
Осталось документировать новый метод, иду к определению класса и тыкаю там в "doc" (пик 3), ещё пара кликов и метод готов к использованию (пик 4). На 5 строк рабочего кода я ввёл 2 слова, остальное подставила моделька.
На выходе имеем по сути автоматизацию бОльшей части набора текста. А рядом -- чат, в котором можно уточнить какие-то детали по языку или попросить совета по реализации.
НО надо твёрдо понимать, что нельзя рассчитывать, что он выдаст идеальный код, что за ним надо проверять, что LLM вообще склонны к галлюцинациям и так далее. Чем более общий вопрос им задаёшь, тем качественнее и валиднее будет ответ.
Откуда он будет импортирован?
Вот этому анонче два чая.
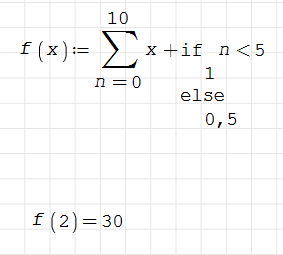

Не получается записать сумму ряда. Использую функцию nsum из scipy.
Если в лямбду добавить условное выражение, то выкидывает ошибку, но если применять другие операции (степень, корень и т.д.), то всё работает как и должно.
Пикрилы
так тебе написали всё, нельзя к логическому типу его преобразовать таким образом.
И ты хочешь сказать что в аналитика данных ебать как сложно вкатиться? Прям джуны нахуй не нужны да?
Какая разница? Вообще-то можно в чём угодно, лишь бы была интеграция с LLM. А с учётом того, что они уже умеют в LSP -- можно хоть в виме.
А пошёл по пути наименьшего сопротивления и поставил гигакодовский плагин на VSC.
Курсивом выделены предложения LLM, если что.
Чел, я не знаю наизусть все иде и плагины.
Что такое LSP и гигакод?
Как вообще можно с питоном юзать vs code? Он же нихуя не умеет!
 7 Кб, 474x159
7 Кб, 474x159Просто скопировал оттуда код, получил пик. У тебя что-то сильно не так. Вангую вендопроблемы.
Судя по всему, тебе уже ничего не поможет. Программирование это просто не твоё.
Уймись и иди на завод или грузчиком в пятёрочку.
Че такая попаболь? Опять что-то свалилось?
Сложно, потому что туда лезут десятки тысяч людей с курсов и просто перекатчиков. Я резюме у нас помогаю иногда фильтровать, и там абсолютный мрак, продавцы машин, футболисты, социологи и т.д. Быть замеченным в этом потоке грязи сложно.
Про джунов - они не нужны, потому что как только ты их научишь, то они тут же свалят от тебя. Поэтому дешевле брать студентов и платить им мало. Делать задачи по инструкциям они умеют, на зарплату не жалуются, и когда уходят их не жалко.
Если тебе гарантированно из какой-то жопы нужно вытянуть, то вот так
>import importlib.util
>import sys
>spec = importlib.util.spec_from_file_location("my_module", "/home/anonchik/moduli/ebanye/my_module.py")
>my_module = importlib.util.module_from_spec(spec)
>sys.modules["my_module"] = my_module
>spec.loader.exec_module(my_module)
Но вообще все нужные модули должны лежать у тебя в проекте и импортироваться через
>from moduli.ebanye import my_module
Блядь. Дело же не в том, что ты чего-то не знаешь. Дело в том, что вместо того, чтобы спрашивать тут -- ты мог бы выделить слова, ткнуть правой кнопкой и поискуать в сети, но если ты оказался неспособен на это, значит тебе доступен только вайбкодинг, когда ты умоляешь курсор выдать тебе рабочее решение, не применяя мозга.
Почему я должен подбирать с пола? Тебе сука лень нормально написать названия софта??? Схуя ты взял что я обязан угадывать про что ты говоришь?
>туда лезут
Если знаешь sql до оконных функций включительно - аналитические двери в любую контору открыты. Хуй знает, кого вы там делите на джуна и не джуна в sql. Есть сайт старый, его все знают. Как только на нем прорешал оконные функции - тебе везде рады.
Что ты хочешь? Волшебных рецептов "как наебать систему и устроиться с первого раза"? Их нет. Мы не управляем рынком и сделать "специально для типя конкуренцию ниже))))" не можем. Именно так и ищут! Ебутся по 6-12 месяцев, откликаются на сотни вакансий. И где-то там на 162-ой попытке их моооожет быть возьмут на работу.
Чувак, это никому нахуй не надо. Читай мой пост выше про оконные функции. И да, питон аналитику тоже не нужен, онли sql, но глубоко.
Не не. Я просто спрашиваю, нормально ли это на сегодняшний день. Просто лет 10 назад я быстро находил и по собесам гонял. Но с тех пор какой хуйни только не произошло, вот и интересуюсь, правильно ли я всё делаю. Просто неделю в ленивом поиске провел и прям вообще ноль выхлопа.
Скажи мне пожалуйста, что ты студент. Не могу придумать ситуации, где бы понадобился такой велосипед изобретать.
Зачем ебать мозги себе и остальным, если есть loguru
Так можно только если твой бот админ в твоей группе. Всё остальное через команду старт, такие правила в телеге.
0. купи дешманский впс, подними на нем алпайн + докер
1. подними контейнер torserver (там есть свой апи), но отключи гуй и закрой в файрволле вообще всё, кроме пост-запроса с добавлением кина и гет-запроса с получением потока кина.
2. подними контейнер с постгрес
3. ВОТ ТУТ поднимай свой фастапи в отдельном контейнере, он должен осуществлять базовый круд в твой постгрес + всё, что душе угодно
4. напиши парсер торрентов и подними с ним контейнер, этот парсер будет работать с твоим фастапи по добавлению фильмов (+ добавление в торсервер) по schedule
5. напиши бота на аиограм, который через твой фастапи будет удалять кинцо, что бы удалять говно-кинцо из базы прям с дивана, не включая компа
6. напиши красивую веб-морду.... ну это я уже погнал, никто не обязан учить джаваскрипт
 365 Кб, 539x413
365 Кб, 539x413Многопоточку (ясен хуй псевдо) на питуховене встречал только в pyside (это если ты вдруг решил упороться в написание ебала под десктоп на питоне).
А вот с асинхронщиной ты хамишь, паря.
> асинхронщина вообще по мнению многих крутанов в питоне считается чуть ли ни раком
Наверно зависит от применения.
Нахуя тут какой то nsum когда если все пишется в 2 строки буквально?
def f(x):
... return sum([x+1 if n < 5 else x+0.5 for n in range(0,11)])
 122 Кб, 780x1026
122 Кб, 780x1026Пишу всё в саблайме с темной темой. Там подсветка синтаксиса искаропки. Запускаю код в cmd. Никаких автодописываний и автододумываний, только хардкор. Если где то затупил, стараюсь подгугливать по старинке, без всяких дикпиков. Мозг так устроен, что на третий раз подгугливания начинает шевелиться и вспоминать сам, ибо заёбывается лезть в гугл и вот тут происходит запись инфы на подкорку. А отсутствие автокомплита тренирует мышечную память. Всякие там контекстные менеджеры и прочие шаблонные конструкции пальцы сами пишут.
Вся эта ваша залупа с ии оказывает вам медвежью услугу.
другой мимокрок
Подсветка и в нпп изкоробки. Что с дополнением? С генерацией (не ии)?
> Запускаю код в cmd. Никаких автодописываний и автододумываний, только хардкор.
Попробуй pycharm. Не бойся, он бесплатный. Мож поумнеешь.
Что не нравится?
 888 Кб, 1080x782
888 Кб, 1080x782>отсутствие автокомплита тренирует мышечную память
Бля! Серьёзно?
Мышечную память тренируешь. Набивая втупую последовательность символов, которые можно не набивать, но ты тратишь время на пустую бессмысленную работу вместо того, чтобы абстрагироваться от рутины и решать задачу. Думаешь кто-то будет тебе платить за мышечную память? Да она нахуй никому не упёрлась! Нужны решённые задачи!
>именно в саблайме
Какой сюр. Со времён IDE от борланда (вот они, кстати, были охуитительны!) абсолютно похуй, кто в чём пишет. Для нормального разработчика разница между VIm и PyCharm исчезающе мала. Какие же тут нюфани сидят. И ведь верят, что "занимаются программированием", клепая микроскриптики.
Клоун с двача, ебло оффни.
>абсолютно похуй, кто в чём пишет
ты нахуя залез не вникая в чужую беседу, быдло? Я отвечал анону, который спрашивал:
>Тебе сука лень нормально написать названия софта???
>Да она нахуй никому не упёрлась! Нужны решённые задачи!
Типичный додик. Ты еще скажи, что нужен рабочий код и похуй, как он там будет работать, главное работать конкретно сейчас.
>Попробуй pycharm
Нахуй надо, это говно пожирает ресурсы, словно его писали двачеры этого раздела. Я бы тогда уж в вскоде писал, если бы хотел что то такое.
>клепая микроскриптики
О, а вот и долбоёб, который вкручивает ООП везде, где надо и не надо и считает всё, что не ООП скриптами.
https://sql-ex.ru
На этом сайте-решебнике зарегайся и решай задачки, как прорешаешь оконные функции - по крайней мере в один банк, где мой кореш работает старшим аналитиком тебя точно оторвут с руками. Во многие конторы тебя возьмут гораздо раньше оконных функций.
И да, естественно решай сам, не скачи по задачам с ИИ за ручку, как козёл, это тебе нихуя не даст. Как упёрся во что то, пошел читать тему соответствующую. Только так.
Лично я в процессе решения понял, что работа аналитиком не моё, слишком скучная хуйня.
>Ты еще скажи, что нужен рабочий код и похуй, как он там будет работать
Если бы ты был способен на программирование (а не на кодинг скриптов под себя), то однажды, попробовав заработать на этом умении, ты узнал бы, что для тех, кто платит за человекочасы, проведённые за IDE не существует такой сущности как КОД. Для них есть продукт, который либо помогает сэкономить, либо приносит доход, либо его можно продать и получить деньги. Для этого ПРОДУКТ должен решать некую ЗАДАЧУ. Если он с этой задачей справляется, то заказчику это нравится. Если не справляется, то заказчик недоволен. Всё. Остальное в 99% случаев неважно: ни язык, ни технологии, ни по большому счёту, даже производительность, если она не мешает бизнесу. Даже возможность расширения, доработок и всего такого тоже важны далеко не всегда, более того слишком редко можно понять, потребуется ли расширяемость в будущем (и если что, это будут отдельные задачи).
У тебя некрокомп безssd? Но все остальное просто говно нерабочее для тех кто не видел иде в жизни.
> Нахуя тут какой то nsum
А теперь добавь-ка сюда два тройных интеграла.
Если бы стандартная функция подходила, то и в тред писать не пришлось бы
Понял спасибо
да
5к евро
Возьми меня в подмастерья, сэнсэй.
Вакансий стало в разы меньше, в оставшихся вакансиях появились ебанутые требования типа "3 года в AI и Ed-tech стартапах, чтобы писать нашу хуйню на джанго, только офис в Киргизии". Вакансии на ХХ такое чувство, что 99% фейк, чтобы рыночек мониторить, сколько не откликался - ноль реакции, авто-отписки везде. У меня 8 лет опыта, 6 из них - бигтех. Сократили в петушковом стартапе, второй месяц работу ищу, даже на тех собесы перестали звать. 3-5 лет назад совсем другой рынок был. Еще учитывай сезонный фактор, щас все о отпусках, ближе к осени активнее будут вакансии появляться, но тоже на многое надеяться не стоит
Так не нанимает никто в 2025 году. Вот яндекс один из немногих, где вакансии какие-то открытые висят и туда даже нанимают кого-то. Когда рынок восстановится хз, наверное не раньше чем гойда закончится, то есть примерно никогда.
Ну и еще такой фактор, что на питоне перестали писать бекенд. Где надо было, там на го переезжают, где похуй, просто замораживают проект и оставляют на его поддержку пару человек.
Крупные компании в телеге завели давно каналы и постят туда вакансии с контактами рекрутёров/HRов. Плюс есть отдельные каналы по разным стекам, которые рекрутёры тоже мониторят и перекидывают туда вакансии. От хх постепенно отказываются, поэтому если ты сейчас только через него ищешь, то ты уже проиграл.
Массивы и списки (кортежи) - это разные структуры, дебич. И в питоне они реализованы по-разному.
>Список в питоне - это не связный список, это обертка над массивом
Ха! Питоновский массив реализован в виде обертки над массивом. А где про это в общих чертах почитать подробнее? Чтобы не лезть сразу в исходники жирнючего интерпретатора.
> Скажи мне пожалуйста, что ты студент.
я самоучка, мне по кайфу циферки и переменные писать
>Не могу придумать ситуации, где бы понадобился такой велосипед изобретать.
ну и что ты как опытный сделал бы, чтобы получился тот же самый результат и при этом корректный?
>>502693
>>502724
Пиздец, очко какое то. Думаю уже в сервисные инженеры любых аппаратов пойти (вендинг, кофе, весы...) там и бабла больше и мозгоебли меньше. Опыт есть.
>>502880
>ну и что ты как опытный сделал бы, чтобы получился тот же самый результат и при этом корректный?
Ну во-первых такое я бы писал на сях. Питон как минимум на уровень выше этого. Если это алгоритмы сортировки или поиска, то встроенные питонячьи методы уже максимально быстрее всего того, что ты сейчас сидишь и пердишь, при чем написано оно на сях. Почему я и сделал вывод для себя, ты решил окунуться в алгоритмы на питоне.
Хотя пихон долбоёбы именовали - там на уровне структур данных list это на самом деле массив, а tuple - это список. Хотя, впрочем, погремистов на пуфоне эти детали ебать не должны.
Я тут заглянул в репозиторий CPython и узнал, что я сам обосрался с определением, кортеж это не список, это тоже массив, но фиксированной длины. Если б кортеж был настоящим связным списком, то к элементам кортежа было бы нельзя обратиться по индексу.
Почему ты решил что tuple это список если
1) Это неизменяемый тип данных
2) Имеет фиксированный тип. Например (1, 2, 3) имеет тип tuple[int, int, int]
Потому что на самом деле я тупица, просто я выучил горсть умных слов, научился делать серьёзное ебало и мне каким-то чудом повезло стать сеньором разработчиком.
А нахуй придумывать язык , который так зависит от синтаксиса ? Вместо того, чтобы думать над логикой программы я должен много времени тратить на поиск тупых ошибок . В Delphi к примеру с этим вообще никаких проблем не было - пиши как хочешь хоть в один столбец только не забывай ; в конце инструкций .
Утёнок, спок. В сях-дельфях ваших ебаных если пропустил ";" - то всё, пиздец, ищи-свищи где ты этот кал забыл. Нахуй он нужон? Непонятно.
Если в сишке пропустить ; то оно не скомпилится. Оно там лишнее, посему лучшая (с точки зрения синтаксиса) сишка - голенг
>>503288
Не похуй ли, какие там отступы и точки запятые? Пишу время от времени код и на питоне, и на си, и на го - один хуй разницы. У питона просто синтаксис самый компактный. Текстовые редакторы, компиляторы и интерпретаторы в 2025 подсвечивают, где ты скобку или точку с запятой забыл, не надо ничего искать
Он опциональный.
В пятоне тожи есть, а ты и не знал, пятонист...
Как же ты обосрался, ух бля!
8=З (__!__)
На джаве тоже наоборот.
На самом деле я тоже сначала пригорал, когда из джавы пришел. Особенно из-за отсутствия четкой типизации, странного фора. Но потом вдруг как понял, что это самый кайфовый и дружелюбный язык, что в сишное даже возвращаться не хочется.
Те, кто помнят кобол - лутают сотни тысяч долларов.
Делфи ещё апдейты получает, кстати. Ну так, к слову.
> Почему функция с отключением GIL не дала прироста скорости в общих задачах?
Классический "слышал звон". GIL актуален для многопоточных приложений, каковых немного. На однопоточные он не сказывается. Причём в режиме без GIL даже медленнее может работать.
В теории что может ускорять, как это JIT. Сейчас его тоже пытаются встроить в интерпретатор, в версиях 3.13 (действующая, но нужно компилировать специально для этого, по-умолчанию нет) и в 3.14 (в разработке, пока релиз осенью), но там он слабый, приличный JIT есть в альтернативном проекте PyPy. Он реально может на каких-то задачах разгоняться, но там версия 3.11 сейчас, и не со всеми пакетами совместимость есть.
Почему тормозной? Про это книги можно писать. Из-за архитектуры, где даже обычные целые числа это объекты, из-за того, что нужно поддерживать специфичный функционал, из-за чего там сложно оптимизировать, не ломая обратную совместимость.
короче из-за архитектуры местами сомнительной начинаются тормоза.
Вот если у тебя функция, в ней примитивный цикл
def func():
ssum = 0
____for x in range(1_000_000):
________ssum += x
____return ssum
этот код будет работать очень медленно, не смотря на то, что вроде тут ничего сложного. Но в питоне ты тут работаешь с итератором, там довольно много операций происходит на каждую итерацию цикла, ssum это не переменная в смысле как в Си и других языках, это ссылка на иммутабельный объект. На каждую итерацию цикла создаётся новый объект, а это требует какого-то времени. Один новый объект для x, и ещё новый объект для ssum. Соответственно обновляется словарь внутренних переменных функции.
То есть реально тут адский оверхед, с которым сложно что-то сделать.
Медленный для чего, нахуй? Для скриптов, для веб-приложений (где 99% времени это ожидание данных), для инженерных расчетов - он ебать какой быстрый.
В сетевых задачах он тоже крайне медленных, вообще всё медленно, что не работает на внешних модулях. Если сетевой код переписать на другой язык, обычно производительность будет выше. Не то, что на Го, даже на Node.js
Просто в реальности производительность обычно не нужна, а тормоза чаще не из-за питона, а из-за БД или ещё чего-нибудь.
> DevOps -- тут есть дефицит мидлов, так что ещё можно пытаться.
Это все хорошо, но как попасть на джуна без опыта?
> QA -- хороших спецов даже уровня джунов мало. Всего по 1,5к человек на одну вакансию, даже не из кого выбрать.
> это нужно с 12 лет было читать журнал "Хакер", а с 14 -- сидеть на тематических форумах, постепенно погружаясь в пучины даркнета. Тогда к 20 есть хороший шанс найти или уютное место для вайтхэта или неуютные нары.
Ну я лет 10-15 назад увлекался айтисеком. Как ты думаешь, сколько % моих знаний сегодня кому-то нужны? Я думаю что ты про айтисек по телеку слышал.
Вы вам перезвоним.


cv2.matchTemplate даёт очень много ложноположительных и ложно отрицательных мэтчей. Эта хуйня работает только из исходного изображения кропнуть часть, тогда он детектит идеально.
рандомпики
Делал много лет назад похожую хуйню по работе. В основном темплейты использовал и на крайняк каскады, ничего лучше на тот момент ещё не придумали. Сейчас наверняка есть куча готовых решений на базе нейронок.
>cv2.matchTemplate даёт очень много ложноположительных и ложно отрицательных мэтчей
Вроде оно возвращает качество мэтча.
Картинка монохромная?
Нейронками капча разгадывалась еще лет 10 назад.
https://habr.com/ru/articles/911920/
 162 Кб, 1256x866
162 Кб, 1256x866Бля, да это же классика, хз, это жирные тролли составляли или реальные вчерашние вкатуны так выделываются. Ещё минута чтению и буду читать срачи в комментах
Да разве? Туда от фирм копирайтеры серут. Сейчас там 0 коментов под большинством постов. Боты пишут для ботов?
А почему ты у меня спрашиваешь? Хабрапараша днищем всегда было, я за этим говном не слежу.
n = int(input())
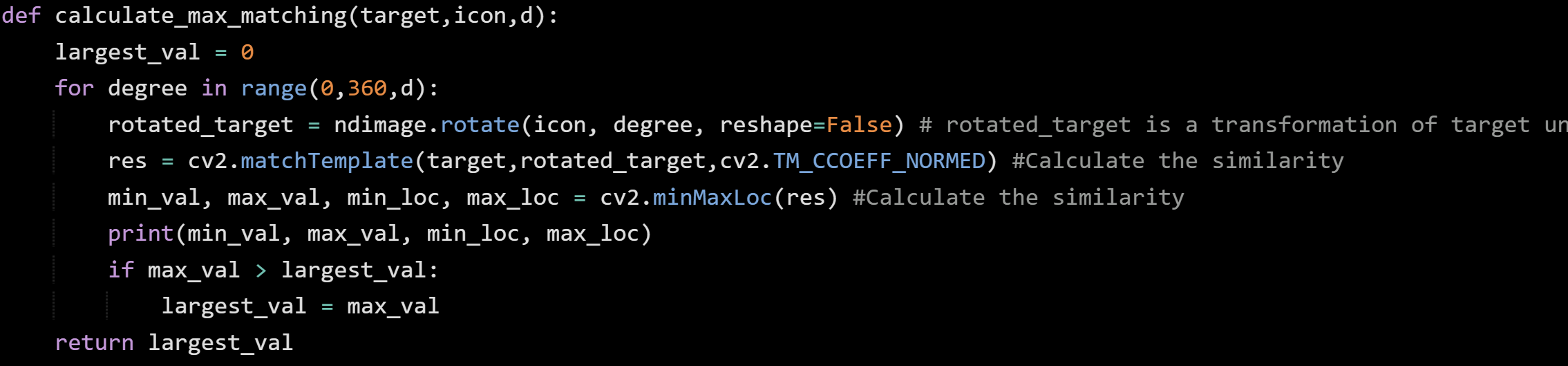
for i in range(1, n + 1):
for j in range(1, i + 1):
print(j, end= ' ')
print()
хочу чтобы решение было элегантное без дополнительных переменных и условий. Только на циклах,но как это сделать я понять не могу

В статье все по делу, такие простые вопросы не требуют подготовки или глубоких знаний, они максимально простые, но позволяют легко фильтрануть челиксов, не написавших ничего сложнее хеллоу ворлда. Просто первичный фильтр, чтобы сразу послать нахуй ебаклаков.
В комментах всё по делу, надо код простой и понятный писать, а не изъебываться с тем, как твой обфусцированный говнокод поведёт себя, если ты намешаешь невероятный кейс из кучи крайних случаев, описанных в редакции R34Hui1488 питона версии 3.12
Разработчики джанги.
>>509638
Там нет каких-то заумных или нестандартных штук. Компрехеншены пишут все, цепочечные сравнения тоже. Понимать, как они работают - это нормально.
Или ты хочешь сказать, что писать компрехеншены плохо? Если мидл реально думает, что (x for x in array) это тюпл, а не генератор, то это какой-то очень хуевый мидл.
Если не знать, как это работает в питоне, очень легко обосраться и не заметить эту ошибку. Поэтому знать такие вещи это реально база, и любой человек, который реально пишет коммерческий код на питоне, с такими вещами так или иначе знаком.
Который нахуй никому не нужен.
>Ну и пример со списком в качестве дефолта это классика любого техсобеса
Это единственный действительно адекватный пример вопроса, питонист обязан это знать и помнить всегда
Остальные же вопросы из серии, что вчера сел всерьёз изучать питон, теперь считаю, что все остальные должны фишки знать. Это тест для вкатунов, который людей с реальным опытом ставит в тупик, потому что они хуйнёй не занимаются, ненужные вещи забывают.
Множественное наследование где-то используется, в виде миксинов, но такие вещи сложно помнить. Хотя если ходишь по собесам, то это та тема, которую точно стоит освежить
>В статье все по делу, такие простые вопросы не требуют подготовки или глубоких знаний, они максимально простые, но позволяют легко фильтрануть челиксов, не написавших ничего сложнее хеллоу ворлда
Это тест для поиска людей, что НЕДАВНО начали изучать питон, обычно это показатель, что авторы тоже недавно его начали изучать, бывают же все эти 22-летние сеньёры
>Почему JIT-компиляция не дает такого прироста скорости работы приложения, чтобы его можно было сравнить с аналогом, написанным на изначально компилируемом языке?
Она иногда может работать быстрее, то есть питоновский pypy код может работать быстрее кода на C++ с высокой оптимизацией
бугурт это вызывает потому, что вопросы придумывали те, кто сам вчера только что-то изучил, и поэтому считают, что другие вопросы-ловушки должен легко уметь отвечать
Легко их отвечать можно тогда, когда специально к этому готовишься. Обычно это про тех, кто недавно изучал
Я не представляю, что это за код должен быть, где встречается
> 55 == True is True
С генераторами, в реальном коде можно встретиться с
g = (x for x in array)
хотя это больше гипотетически, не уверен, что прямо встречался. Используются генераторы списков-словарей-множеств, но в чистом виде генераторы редко
когда же вопрос формулируется как
print([x for x in array])
print((x for x in array))
print({x for x in array})
то это уже не вопрос на знание, а чисто вопрос-ловушка на невнимательность, на стресс на собесе и т.п. Отношение соответствующее.
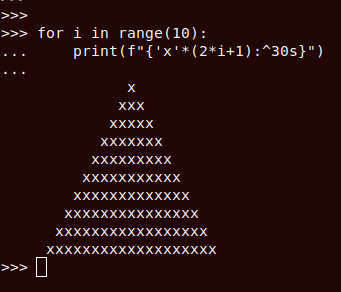 8 Кб, 341x292
8 Кб, 341x292В питоне есть особая фишка для форматирования строк, модификатор "крышечка", что центрирует данные
Возможно это не то, что ты хочешь, тебе нужно именно учебный пример с двумя циклами, но так зато можно сделать элегантно
Автор статейки, ты? Давай за множественное наследование поясни, схуяли человек, не пишущий на питуне ооп код, должен знать порядок наследования.


Смотри, пример там сам простой, а вот пояснение показывает, что у автора судя по всему проблемы с головой серьёзные
Реально же всё проще, тебе эти слова "линеарилизация С3" знать не нужно. Класс D наследуется от B, C, в обеих классах определён метод hello(), поэтому на класс A можно не смотреть вообще. Соответственно вопрос, чьи методы в приоритете, первого класса или второго. Здесь B будет
Вопрос куда менее очевидный, если бы в B не был определён метод hello. Здесь уже надо знать специфику питона. По одной логике можно ожидать ответ A (как если бы мы класс B запустили, очень ожидаемое поведение), по другой C, что будет правильным ответом).
Вот на это уже совсем не так просто ответить на холодную, а можно вещь ещё сложнее придумать, сделав глубже наследование.
Наследование, в том числе множественное, всё-таки довольно часто используется, стандартный паттерн "mixin", на холодную на такие вопросы может быть сложно отвечать, но если ты ходишь по собесам, то эта та тема, которую стоит освежить. Само по себе наследование и минимальное ООП в любом проекте есть, без этого никуда.
Настоящее ООП это в любом случае не про питон.
Конечно, это не тест на мидла-сеньёра, то есть человек с опытом отвечать будет не лучше вкатуна на такие вопросы.
>кучу ошибок даже в простом коде из-за ебаного синтаксиса с отступами
Имнно из-за него я абсолютно убеждён, что КАЖДЫЙ кодер в мире должен в обязательном порядке проходить курс по Питону. КАЖДЫЙ. Потому что блядь заебало, когда так наплевательски относятся к отступам и чуть что -- сиди и за очередным долбоёбом табы расставляй, чтобы понять, что он сказать-то хотел!
>пипец ты дед
Зря ты так. Язык хороший, годный. У него две проблемы: нет прям свободного компилятора (inb4: Lazarus, но это не совсем тоже самое, там затык в относительно проприетарных VCL) и он очень многословен. Зато как и у питона у него есть фича: почти невозможно случайно выстрелить себе в ногу, так что идеологически языки очень близки.
Да, в Питоне до появления нотаций типов по ногам стрелять было проще, но чем дальше, тем меньше таких проблем.
Покажи хоть одного вменяемого питониста, который не знает как использовать компрехеншены или цепочечные сравнения.
>>509684
>хотя это больше гипотетически, не уверен, что прямо встречался. Используются генераторы списков-словарей-множеств, но в чистом виде генераторы редко
Плохо, что не используешь. Да и скорее всего используешь, просто даже не знаешь, что это генераторное выражение.
' '.join(a for a in x) - это передача генераторного выражения в качестве аргумента например.
Алсо, "генератор списков" и "генератор" - это абсолютно разные вещи, он только на русском по какой-то причине называется генератором, на английском это list comprehension.
>>509687
>не пишущий на питуне ооп код
ООП это промышленный стандарт разработки. Если ты пишешь коммерческий код и не используешь ООП - сочувствую тому, кто будет твое говно потом разгребать.
>>509688
Посмотри код джанги, оно там буквально везде.
>>509702
>Настоящее ООП это в любом случае не про питон
А про что? Про ДЖАВУ?
>>509907
База
>' '.join(a for a in x) - это передача генераторного выражения в качестве аргумента например.
У тебя реально такой код бывает?
>А про что? Про ДЖАВУ?
Да, про джаву в первую очередь, и про совсем старый C++, новый давно в другую парадигму перешёл
Я надеюсь тебе не нужно объяснять, чем в контексте ООП общего у питона и джавы мало
>ООП это промышленный стандарт разработки. Если ты пишешь коммерческий код и не используешь ООП - сочувствую тому, кто будет твое говно потом разгребать.
На самом деле это херня, если именно ООП, а не использование классов.
Не использовать классы в разработке не получится, куча библиотек на этом построена, в том числе некоторые стандартные модули, но использовать классы это ещё не значит "использовать ООП".
В основном мультипарадигмовые подходы, что-то, реально похожее на ООП, лишь в части проекта.
>и про совсем старый C++
>ООП
>C++
Мань, ты серишь, вообще не понимаешь что пишешь, водочки ебни и успокойся.
>чел, давно автоформаттеры придумали
В тепличных условиях, когда один язык и 100% контролируемая среда разработки -- да. Но чуть ты оказываешься в условиях ограничений -- появляется серьёзный шанс СОСНУТЬ.
А в реальном мире, вне твоей теплицы, этих шансов полно.
>>509959
>Кодомакака не человек.
Что поделать? Последний программист ушёл на пенсию лет 10 назад, а остались только кодеры, крудошлёпы, рисователи кнопочек на цсс и прочая нечисть.
>Они опциональны, дядь.
Ну и что? Зато во встроенной либе и большинстве модулей они прописаны и IDE может понять, как пользоваться переменной.
То время, когда питон был настолько гибок, что из рук выскальзывал с его вообще-хер-пойми-какой-тут-окажется-тип в прошлом.
Конкретно тут ничем, я просто абстрактный пример привел.
Это ты ничего не понимаешь, только баззвордов нахватался и думаешь, что умный. Старый C++ это настоящая классика ООП, прямо вершина из массовых языков, лучше джавы. Но позже его засрали STL и практика кодирования на нём сменилась
>Конкретно тут ничем, я просто абстрактный пример привел
Вот именно что абстрактный пример, потому что в реальном коде такого не будет
C++ это антипаттерн ооп языка
Статья про мидлов или сеньоров, но QA. А из всего этого выблева реальный пример только параметр по умолчанию.
>>510175
> В тепличных условиях, когда один язык и 100% контролируемая среда разработки -- да. Но чуть ты оказываешься в условиях ограничений -- появляется серьёзный шанс СОСНУТЬ.
> А в реальном мире, вне твоей теплицы, этих шансов полно.
Штоблядь? В любом вменяемом проекте есть правила оформления.
>ООП это промышленный стандарт разработки
Дык автор статейки и не разработчик. И питун используется не только в разработке. Поэтому нет, ООП это давно не стандарт.
>Посмотри код джанги
Куда смотреть? Открыл гитхаб джанги, открыл core, посмотрел, нашёл только ThreadedWSGIServer который от двух классов наследуется. Куда смотреть, чтобы было "буквально везде"?
>А в реальном мире, вне твоей теплицы,
валидаторы разметки придумали еще в прошлом веке. в нормальном проекте ты даже коммит сделать не сможешь если у тебя код стайл-гайдам не соответствует. во всех иде автоформат включен перед коммитом.
 23 Кб, 361x385
23 Кб, 361x385>Дык автор статейки и не разработчик.
Это многое объясняет, в том числе такое странное видения разработки и скиллов разработчиков
>Куда смотреть?
На питоне убогая ООП модель и поддержка ООП, поэтому в чистом виде ООП никто не пытается делать. Вообще ООП была в моде 20 лет назад и раньше, с тех пор ушли от этого.
Без классов в питоне никуда, множественное наследование крайне редкая штука, но иногда встречается, в виде MixIn. У того автора примитивный пример, но по его объяснению видно, что он реально нихрена не понимает, но хочет казаться крутым и умным. Это диагноз.
Логика наследования в питоне абсолютно алогичная, с ней можно разобраться, но запомнить, чтобы решать задачи без подготовки, вряд ли. Потому что наркомания. Только если в проекте это используется активно, но лучше этим не пользоваться.
Вот скрин с действительно неочевидным примером, скорее всего 90% ответят неправильно, как будут работать эти два класса, потому что в адекватную логику это поведение не вписывается
Ответит только тот, кто недавно вгрызался в тему.
Нелогичной магии много, поэтому лучше этого просто избегать
>В статье все по делу
Тащемта спорно.
Вот смотри:
> 55 == True is True
работает как
> (55 == True) and (True is True)
Круто. Но зачем мне это? Я знаю, что в цепочке
> Condition_1 or Condition_2 or Condition_3
я получу первое истинное утверждение или самое последнее, а в
> Condition_1 and Condition_2 and Condition_3
первое ложное или самое последнее. Это практически полезно потому, что ты можешь сделать что-то типа (пример из реального кода):
> ....def _enter_parameter(self, param: str, default: str = "") -> str:
> ........default = default or self.defaults[param]
Тут если значение по-умолчанию не пришло (оно определено для всех, но для кого-то оно переопределяется снаружи), то возьмётся значение из словаря.
Это - полезно и нужно от цепочек сравнения, а тот код это чисто лабораторная история, так что я не готов сразу сказать, в каком порядке он выполнится, я знаю, что bool(55) == True, но при этом True == 1 и True != 55, но приведённый код у меня в проекте никогда не появится в таком виде потому, что он нахуй не нужон.
Мне не нравится то, что интуитивно мне показалось, что это отработает как
> (55 == True) is True
которое будет ложным, но если его модифицировать до
> (55 == True) is False
то оно становится истиным.
Или вот:
{("a", [1, 2]): "value"}
Я как-то курил, так что я скорее всего правильно ответил бы. В процессе своих экспериментов я доходил до того, что делал ключом словаря кортеж функций. Но что важно, так это то, что по итогам я пришёл к мысли "ух, оказывается, как можно... Только НАХУЯ?" Эталонный троллейбус из буханки. А поскольку в реальном коде такого никогда не появится даже за 10+ лет практики, то этого нормально не знать.
Это я к тому, что критикуемый аффтаром ответ "у меня такого не было" НА САМОМ ДЕЛЕ единственно верный. Более того если у кого-то в коде ПОЯВИТСЯ такая конструкция, то я всерьёз спрошу с её втора, НАХУЯ. Потому что они почти все имеют неявное поведение, а в дзене питона сказано:
> Explicit is better than implicit.
При чём в самом начале, на второй строке. А использование такого мозгоёбства этот принцип нарушает.
>В статье все по делу
Тащемта спорно.
Вот смотри:
> 55 == True is True
работает как
> (55 == True) and (True is True)
Круто. Но зачем мне это? Я знаю, что в цепочке
> Condition_1 or Condition_2 or Condition_3
я получу первое истинное утверждение или самое последнее, а в
> Condition_1 and Condition_2 and Condition_3
первое ложное или самое последнее. Это практически полезно потому, что ты можешь сделать что-то типа (пример из реального кода):
> ....def _enter_parameter(self, param: str, default: str = "") -> str:
> ........default = default or self.defaults[param]
Тут если значение по-умолчанию не пришло (оно определено для всех, но для кого-то оно переопределяется снаружи), то возьмётся значение из словаря.
Это - полезно и нужно от цепочек сравнения, а тот код это чисто лабораторная история, так что я не готов сразу сказать, в каком порядке он выполнится, я знаю, что bool(55) == True, но при этом True == 1 и True != 55, но приведённый код у меня в проекте никогда не появится в таком виде потому, что он нахуй не нужон.
Мне не нравится то, что интуитивно мне показалось, что это отработает как
> (55 == True) is True
которое будет ложным, но если его модифицировать до
> (55 == True) is False
то оно становится истиным.
Или вот:
{("a", [1, 2]): "value"}
Я как-то курил, так что я скорее всего правильно ответил бы. В процессе своих экспериментов я доходил до того, что делал ключом словаря кортеж функций. Но что важно, так это то, что по итогам я пришёл к мысли "ух, оказывается, как можно... Только НАХУЯ?" Эталонный троллейбус из буханки. А поскольку в реальном коде такого никогда не появится даже за 10+ лет практики, то этого нормально не знать.
Это я к тому, что критикуемый аффтаром ответ "у меня такого не было" НА САМОМ ДЕЛЕ единственно верный. Более того если у кого-то в коде ПОЯВИТСЯ такая конструкция, то я всерьёз спрошу с её втора, НАХУЯ. Потому что они почти все имеют неявное поведение, а в дзене питона сказано:
> Explicit is better than implicit.
При чём в самом начале, на второй строке. А использование такого мозгоёбства этот принцип нарушает.
>множественное наследование крайне редкая штука, но иногда встречается
Дык в том и дело, что и тут, и на петухабре утверждают, что оно повсеместно встречается. Джанго два раза упомянули. Я открыл репу и не нашёл "повсеместного" использования. Вот у меня и конфуз. Может в сферах, отличных от разработки и обработки данных, это реально какая-то сверх-тактика, до которых ещё не дошли веяния из остального мира, где к наследованию уже пару десятков лет прохладно относятся, а уж к множественному тем более (независимо от языка)?
 66 Кб, 840x337
66 Кб, 840x337На проекте, где я работаю, используется, но это MixIn
Смысл в том, что есть классы, описывающие объекты-модели Sqlalchemy через declarative_base, скрит из документации, и помимо Base добавляются ещё некоторые классы
Это принцип MixIn, эти классы содержат методы, что используются одновременно в разных моделях, чтобы не было дублирования кода. Это не совсем принципы ООП, в некотором роде это отступление от чистого ООП
В подобном варианте не только в алхимии используется, довольно часто, но всё-таки это не совсем множественное наследование. Здесь, например, предполагается обычно, что методы не конфликтуют друг с другом
 85 Кб, 810x503
85 Кб, 810x503Чуть не то отскринил, вот пример из документации алхимии, как это выглядит
>> 55 == True is True
>>работает как
>> (55 == True) and (True is True)
>Круто. Но зачем мне это? Я знаю, что в цепочке
Что забавно, что вот написанное пояснение автором это ещё в добавок полный бред
Потому что работает это так
(55 == True) is True
нет никого and
При этом True это сравнение по id, то есть
A is B
по смыслу эквивалентно
id(A) == id(B)
оператор is нужен только для того, чтобы сравнивать, что два класса это строго два одинаковых класса
В 99 процентах случаев нужен для
some_var is None
Автор не только спрашивает бесполезную херню, пытается ловить на невнимательности, но и сам не понимают в тех вещах, которые спрашивает
>Что забавно, что вот написанное пояснение автором это ещё в добавок полный бред
Хотя нет, не бред в данном случае, а именно магия не очевидная совсем
У питона есть фишка, известная, что можно делать
a < b < c
и это исполняется как (a < b) and (b < c)
это очень полезная возможность, это бытовое интуитивное восприятие этого выражения
Я так понимаю, оператор is подчиняется этому же правилу, хотя ни разу не очевидно. Но вот предлагать знать и помнить такую хрень это заведомо бред какой-то
Не представляю в принципе код, где что-то такое может быть разумно

Что вообще под этим имеется в виду? Почему так говорят? Типа в питоне нельзя создать объект с некоторыми свойстваим или че?
Настоящее ООП есть только в единственном языке Smalltalk
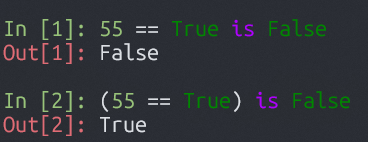 45 Кб, 368x142
45 Кб, 368x142>Что забавно, что вот написанное пояснение автором это ещё в добавок полный бред
>Потому что работает это так
Нет, это не так, автор тут прав.
 141 Кб, 411x834
141 Кб, 411x834Это адепты единственно правильного и лучшего ООП языка в мире.
Предположу что потому что в питоне нет приватного скоупа и как следствие - инкапсуляции. Но соблюсти все условия каноничного ООП практически невозможно и по-моему ни один язык их не соблюдает полностью (не уверен насчет смолтока).
Но на ООП естественно лучше не зацикливаться, лучше писать попроще.
>Предположу что потому что в питоне нет приватного скоупа
Приватность такого скопа это условность, залезть туда не составляет ни какого труда при желании из любого места. И что это тогда, просто оформленная в синтаксис защита от дурака? Другими словами, это то же самое соглашение, только более формальное. Питон не выебывается и имеет менее формальное соглашение: просто не трогать _нэйминг.
Алсоу, ООП это абстракция, споры про настоящесть ооп это конечно же толстота.
Парадигма ООП нужна для того, чтобы разрабатывать огромные и сложные программы. Она не про учебные примеры, где всё неизбежно высосано из пальца.
Главное здесь это особая строгость, чёткая иерархия наследования, типов, интерфейсов, без этого сложно поддерживать большие программы, с долгим циклом разработки.
Когда шизят про то, как плохо без типов в питоне, что можно вместо числа подставить строку, это реально шиза, высосанная из пальца. Но когда идёт речь про сложные типы данных, про классы, это не ерунда.
Ты строишь одну иерархию классов-интерфейсов, там есть какой-то класс с методом, что берёт одни параметры, возвращает другие. Какие-то другие части твоего кода работают с этим классом. Если ты захочешь чуть изменить параметры метода, то тебя ждут проблемы с поддержкой, питон проглотит это, слетит что-то лишь в момент исполнения.
Слабая инкапсуляция это тоже история, отсутствие final и другое
Впрочем сам чистый ООП подход больше вопросов вызывает, нужно ли. Модно было в начале нулевых, но потом отказались от этого в пользу мультипарадигмовых подходов.
Надо просто не жопой, а глазами читать аннотацию и комментарии к методу. Всё, проблема решена.
Ты что-нибудь крупнее 100к строк писал?
Нахуй мне читать что-то, если компилятор подскажет? Подсветит красненьким, не даст ошибок сделать? Ты хоть понимаешь, как это экономит время и деньги?
Только на мелком проекте
На большом, который делается годами, массой разработчиков, это не работает.
Интерфейс фиксирует стандарт, когда ты меняешь интерфейс, в компилируемых языках ты так просто ничего не сломаешь. А в питоне легко.
Главное, ООП придумывали как раз для того, чтобы добавить такую строгость в проектирование, а питон от неё ничего не оставляет, поэтому ООП там неполноценный.
Если тебе надо поменять интерфейс в питухоне, то, вероятно, будет неплохой идеей хотя бы одну извилину временно включить, ради такого случая и не кататься ебалом по клавиатуре, пускать слюни и плакать что компилятор тебе сопли не утирает.
Алсоу. В питоне более чем достаточно инструментов чтобы не срать в штаны из за того что всё не так как в твоей любимой жаве, ты год уже ИТТ ноешь об одном и том же, мог бы и повысить скилл в этом направлении. Ну или тебе просто нарвится сраться на эту тему.
копинг какой-то
Питон не предназначен для действительно серьёзной разработки, масса аргументов для этого есть. Но да, на нём при этом ведут серьёзную разработку иногда.
Надо просто уметь называть вещи своими именами
>Нахуй мне читать что-то, если компилятор подскажет? Подсветит красненьким, не даст ошибок сделать? Ты хоть понимаешь, как это экономит время и деньги?
Во всех более-менее адекватных проектах используют тайпхинты и/или модельки на пайдантике. Так что при передаче неверного типа ИДЕ тебе точно так же будет подчеркивать ошибку.
>Приватность такого скопа это условность, залезть туда не составляет ни какого труда при желании из любого места. И что это тогда, просто оформленная в синтаксис защита от дурака?
Да, очень много чего в программировании - это защита от дурака, потому что такие ошибки "ненароком" и составляют большинство.
>Питон не выебывается
И тем не менее вводит type hints, что суть такая же защита от дурака.
Ну так я про то и пишу и там условность и тут условность. Только "там" более строгая, а питон не выебывается и соглашения тут по рукам макаку не бьют, потому что это всё равно от ошибки не спасет, если ты мозг отключаешь, когда питонируешь.
Так я о чём и говорю, если бы это не спасало, тайп хинты бы не вводили, что суть статическая типизация.
Наоборот это признание того что статические проверки нужны, и да, нужно выебываться.
Куда-то тебя понесло. Это ни какого отношения к нити не имеет. Изначальный пост был что "ваше ООП не ООП потому что нет приват скопа". На что я отвечаю что приват скоп это соглашение, в питоне есть своё соглашение которое закрывает именно этот вопрос, это _нейминг. И в контексте ООП это не имеет значения, потому что ООП само по себе абстракция.
>статическая типизация
Тайпхинт это даже не близко статическая типизация. Это прежде всего подсказка макаке, не обязательная часть описания блока кода, и только бонусом на неё всякие надстройки ориентируются, чтобы проверять ошибки макаки. Но в первую очередь это для человека. Как и соглашение в виде _нэйминга.
Я не вижу в этом ни какой проблемы, если ты ебалом по клаве катаешься то тебя типизация и приват скоп не спасут, а если не катаешься, то спокойно идешь и применяешь все инструменты которые тебе помогают комфортно работать и не допускать ошибок в больших приложухах.
>Я не вижу в этом ни какой проблемы, если ты ебалом по клаве катаешься то тебя типизация и приват скоп не спасут, а если не катаешься, то спокойно идешь и применяешь все инструменты которые тебе помогают комфортно работать и не допускать ошибок в больших приложухах.
Остаётся только вопрос зачем тайпхинты ввели, если они так сильно не нужны.
> Это прежде всего подсказка макаке,
Какой блядь макаке? Кто такая макака? Ты?
Это подсказка иде чтобы дополнение работало и материалась.
Чтобы подсказывали сигнатуру метода. Ты че за тупые вопросы задаешь?
>ваше ООП не ООП потому что
ООП это технология проектирования больших программ, завязанная на жёсткую иерархию классов. Она необходима для того, чтобы можно было вести большие проекты с длинным циклом разработки, которые ведут много людей.
Когда у тебя большой проект. тебе необходимо дорабатывать одни части программы так, чтобы они при этом не ломали другие, и одновременно чтобы какая-то гибкость была.
Ради этого пытались придумывать ООП. Где у тебя части программы общаются через классы, что выстроены в нужную иерархию.
В джаве-плюсах, ты передаёшь указатель на класс, что имеет конкретный тип. Именно это фундамент ООП, ты можешь менять поведение, но ты сохраняешь тип, все участники знают, что за тип, ты его случайно не поменяешь так, чтобы другие участники не знали об изменениях.
В питоне же не такой типизации, там принцип утиной типизации, или прототипной (или протоколы, в терминологии питона). Ты можешь передавать что угодно куда угодно, главное для работы, чтобы был соблюдён нужный интерфейс, строго говоря, ты может общаться через класс, который даже не наследник от того, что обычно. И всё будет работать. Это даёт больше гибкости, но одновременно создаёт проблемы,, нет строгости, нет возможности что-то дорабатывать, не ломая то, что есть.
Начну вот с этого:
https://docs.python.org/3/tutorial/index.html
Цель: мышинное обучение. Может быть, найду что-то в связке с ML.Net.
Годная идея?
>мышинное обучение
>Годная идея
нет, там знание питухона вторично, первично это либы и матчасть. Начни с Нампи он везде и книги Тарика Рашда и зделой свою нейронку.
>Решил вкотиться в эту вашу змею после 6+ лет на .Net + SQL + JS.
>Начну вот с этого:
Да, официальный туториал более чем годен, если ты программировать в принципе умеешь, даётся как раз то, что нужно
Это про питон вообще, сам предмет ML конечно надо отдельно изучать, это более ёмкая сфера, чем особенности питона
>Это про питон вообще, сам предмет ML конечно надо отдельно изучать, это более ёмкая сфера, чем особенности питона
Я бы с большим удовольствием работал с ML.Net, потому что там и производительность лучше, и стек крутой и морально близкий, и те же нативные либы С++ подключать не сложно.
Но Питон мне точно нужен.
И в параллели уже уходить в математику. Мне это интересно.
> .Net + SQL + JS.
Объясни почему почти все дотнетчики - фулстаки?
Ни в одном бэкенд-ориентированном языке (кроме JS) такого не видел.
>Объясни почему почти все дотнетчики - фулстаки?
Много сложных систем на .Net (всяких CRMок), где нужно и с БД возиться, и с фронтом. Кстати, я передумал становиться модным фуллстеком и изучать всякие Ангуляры и Реакты в глубину. Они не особо сложные, но суть в другом. Сейчас надо любой ценой катиться в бекендовский машоб.
>Ни в одном бэкенд-ориентированном языке (кроме JS) такого не видел.
Ты шутишь? В джаве практически всегда фулстак
Возник такой вопрос. А не утопия/зашквар ли делать на python андроид приложухи?
Можно ли сделать что то годное с красивым дизайном на подобии современных приложух. Просто чекал экземплы киви фреймворка и честно говоря - лагучая хуйня. Что скажете?
> Ты шутишь? В джаве практически всегда фулстак
Лолшто
Почти не видел вакух на джаву, где требуют серьезное знание фронта.
В теории ты можешь на Jython написать, но это конечно будет непросто
Да я понимаю что звучит как хуйня. А реакт нейтив я знаю, просто мне было интересно прав ли я насчёт python+android
Как оказалось да. Ну и хуета блять
Выбери что-то одно. Шансов мало, но они есть
В питон вообще тяжело вкатиться, из бэка наверное за Django, чаще в виде DRF, какой-то рынок есть. FastAPI тоже используется, но есть ощущение, что это редко и совсем не для джунов там, но может я не прав.
Остальные фреймворки (Flask, AioHTTP) как самостоятельные не существуют
Если вкатываться в бэк, может стоит на PHP смотреть. Если желудок достаточно крепкий, конечно. Питон оверхайпед, дикая конкуренция, а веб бэк на нём не то, чтобы активно делают. А PHP брезгуют, при этом так нереально много на нём чего сделано, что нужно поддерживать
>>515272
>Это как?
def foo():
____return 1, 2, 3
v1, v2, v3 = foo()
это через неявное создание tuple, фишка красивая, но по-моему в реальной жизни не то, чтобы очень часто используется
Это называется "кортеж". Как массив, только иммутабельный.
Я в начале 2024 вкатился со знанием бэка на Питоне (django/drf) + Джаваскрипт (vuejs) + Линукс, но было сложно. Щас наверное ещё сложнее.
Линукс это стандарт профессионализма, вместо линукса может быть умение работать в консоли MacOS. Дружба с линуксом даёт тебе сразу много баллов в рейтинг, возможность сильно выделиться из других, шансы на существенно возрастают
Линукс это стандарт индустрии. Все пользуются линуксом. Если ты не пользуешься докер-контейнерами, тебя обоссут, а докер-контейнер это по-определению линукс, даже не Макось
Подавляющее число всех серверов работает под линуксом, по крайней мере пока речь идёт о питоне, а не dotnet/c#
Короче, я бы настоятельно рекомендовать вложиться в том, чтобы освоиться более-менее с линуксом, это реально полезно, особенно с точки зрения шансов на устройство куда-либо
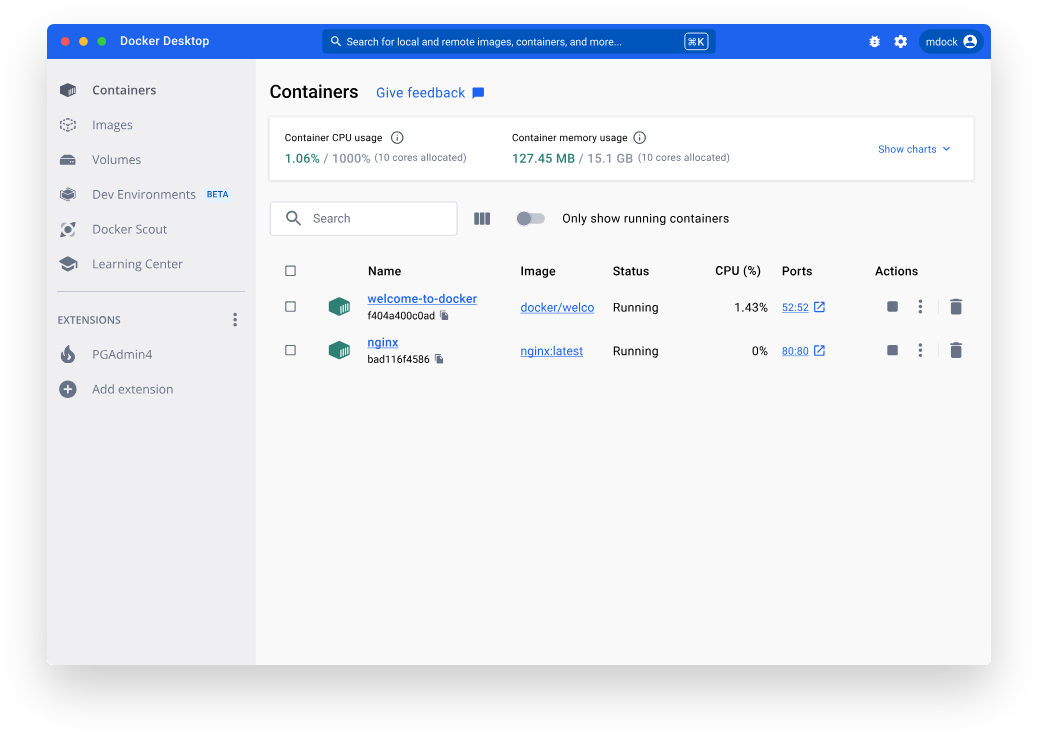
Ну давай, напиши мне докерфайл для контейнера чтобы туда все зависимости подтянуть и вот это все. Без знаний линуха.
Фанатик, плес. Нахуя нужно знание линукса для написания докерфайла? Или ты вот эти вот RUN mkdir -p $MY_PROJECT_PATH называешь знанием линукса?
А где на питоне есть вакансии? Только не надо ML и прочие дата аналитика - там питон 0,1% от знаний.
> это через неявное создание tuple, фишка красивая, но по-моему в реальной жизни не то, чтобы очень часто используется
Это пиздоблядофича. Перепутал параметры - привет, баги. Поэтому и не используется.
>>515367
+. Прошивка для хостинга.
>>515372
> умение работать в консоли MacOS.
Не ну программу из сосноли я умею запустить.
>>515391
Кто все, блядь? Ты про кого сейчас? Про хостинг? Про разработчика? Про пользователя?
>>515538
+. Еби этого прыщедебила.
>Поэтому и не используется.
А как же:
zalupa, created = Zalupa.objects.get_or_create(name="zalupa", defaults=defaults)
>Это пиздоблядофича. Перепутал параметры - привет, баги. Поэтому и не используется.
Иногда всё-таки используется, но обычно это для каких-то приватных методов. Ты выносишь функционал в отдельную функцию-метод, возвращаешь несколько значений. В такой ситуации перепутать сложно.
Вот чтобы это светило куда-то во внешний мир, такое уже сильно реже, но иногда может
>Не ну программу из сосноли я умею запустить
Минимальный джентельменский набор, это права на файлы, утилиты типа kill и разные прерывания, перенаправление вывода, утилиты вроде ps ну и прочая такая всячина. Если ты это умеешь, и если не умеешь, уже большая разница. Всякие tcpdump ещё.
Если знаешь на ещё более продвинутом уровне, то лучше. Это твоё конкурентное преимущество, довольно серьёзное. Это показывает, что ты настоящий айтишник, к тебе относиться уже по-другому будут.
>Кто все, блядь? Ты про кого сейчас?
Про сферы, где используется питон, про бэкенд и т.п. Не про ML скорее всего, там свой мир
>>515552
>А где на питоне есть вакансии?
Довольно много, вне ML, Django и тестирования. В основном это, наверное, бэкент и системный софт. Тут, конечно, тоже нужна масса своих знаний помимо питона. Но по-моему только в Java/C++ можно выбрать чисто на языке, в других направлениях предполагается охват в ИТ достаточно широкий
А что? Какой нужен?
>>515571
Один хуй когда-то перепутаешь или добавится лишняя переменная и привет.
> прерывания,
Что?
Не ну настолько я знаю и линупс и винду
> Это твоё конкурентное преимущество, довольно серьёзное. Это показывает, что ты настоящий айтишник, к тебе относиться уже по-другому будут.
И каким образом оно тебе поможет? Если ты будешь работать на фирме то к боевому хостингу тебя никто не подпустит.
> Про сферы, где используется питон, про бэкенд и т.п. Не про ML скорее всего, там свой мир
См выше
Django это есть бекенд :) А кроме него?
>> прерывания,
Бля, травмы детства, живу на линуксе, а вот иногда возьми, да прорвёт. Сигналы, конечно же
>И каким образом оно тебе поможет? Если ты будешь работать на фирме то к боевому хостингу тебя никто не подпустит
В боевому нет, а к отладочному да. И вообще, это показывает, что ты реальный айтишник, в отличии от многих других непонятных херов, с которыми ты конкурируешь
>Django это есть бекенд :) А кроме него?
Джанго это веб-фреймворк, он сомнительный. Во многих случаях у тебя система работает через питон, но веб части может толком не быть. Задача питона обслуживать работать с базой данных, редисами всякими, получать-пересылать данные, работать с ОС в том числе. Это стандартный системный бэкенд. В таких задачах питон достаточно активно используется.
> а к отладочному да.
Это который manage.py runserver? :).так там никакого линупса нету.
> И вообще, это показывает, что ты реальный айтишник, в отличии от многих других непонятных херов, с которыми ты конкурируешь
Ну я неебу как у вас в манямирке, но джангоебы которых я видел работали на Винде и в хуй не дули.
>Ну я неебу как у вас в манямирке, но джангоебы которых я видел работали на Винде и в хуй не дули
Вопрос ещё в том, что за руководство у проекта, если там все сплошные виндусятники, то может быть но лучше в такие места не идти
А так, тут примерно как с когда-то модным литкодом, по работе нахуй не нужно, но крутым алгоритмистам предпочтение
Ты просто поставь себя на место тех, то набирает на работу. Если мы про вкат, конечно. Вот есть куча херов, но пойди пойми, кто из них адекватный, кто не, как специалист.
Если у тебя нормальные знания линукса, это сразу показывает, что ты скорее всего айтишник, ты мыслишь как айтишник, а не рядовой вкатун-перекатчик с продаж.
Короче, надоело спорить. Тем, кто хочет вкатываться, просто заметка, квалификация в линукс-части это то, что реально замечают. Конечно, если ML, там наверное уже не так важно, но может тоже работает. Конечно математика там важнее, но если у вас вышки математической нет, то вы так просто её не получите уже. А квалификацию по ИТ повысить можно
> Вопрос ещё в том, что за руководство у проекта, если там все сплошные виндусятники, то может быть но лучше в такие места не идти
Прыщееб интернетный, иди нахуй. Проект работает и приносит бабки.
> крутым алгоритмистам предпочтение
Олимпиадным программистам? В твоём манямирке разве что.
Да, я даже не с ращки.
Крутых алгоритмистов как раз и скипнут потому что когда им предложат проект, в котором их знания будут юзаться в полной мере они свалят. Термин оверквалификейтед не просто так придумали.
> Бабах
Ты себя чувствуешь опущенным по сравнению с другими странами?
Я хз как у вас, но у нас так.
> даже с главной ОС индустрии разобраться не можешь,
Пиздуй в s, пердоля. Здесь тебе не рады.
> В джанго
Ну ок, бывает, но нечасто.
>Ряяя пердолики
>Ряяя прыщи
Тем временем соседний тред С++ обезьяны до сих пор не могут срать юникодом в виндовую калечную консольку.
>Ты себя чувствуешь
Ты хоть сам вкатится, в IT работаешь? Или тебя не берут? Если не берут, то совет, освой линукс, реально за человека считать станут. Но и алгоритмы тоже полезны
Я давно в индустрии работаю, на сенько-позиции (чувствую себя мидл-мошенником)
>Пиздуй в s, пердоля. Здесь тебе не рады
Пытающиеся вкатиться может быть. Ну типа зачем мне квалификация серьёзная, так возьмите, я же не ращаванин, сам видел, работают херы непонятные, бабло гребут
Хочешь быть спецом, изучай линукс, сети, специфику БД и массу ввего ещё
Я видел как люди на винде работают. То наверно не спецы, ну или не такие спецы. В душе неебу зачем рядовому джангоебу знать как оно будет на луниксе пахать.
Как у вас в раш ке - в душе неебу.
>винды, с питоном такая же история
хотя nodejs вроде бы нормально работает, но это не точно. Точно то, что питон не работает. в win10 по крайней мере
кстати, вопрос тем, кто виндой пользуется, как вы выводите в консоль текст на русском языке или украинской мове?
Не так давно с этим столкнулся, когда пытался что-то под виндой запустить. Сам пользуюсь только линуксом, там нет этих проблем
Нода-жс при этом умеет выводить юникод в консоль, а питон нет, pypy по крайней мере
Наверное это как-то перебарывается, но не было времени разобраться
Винда могла в юникод самое позднее в нт 4. Питон работает замечательно. Может с руками что-то не так?
Все работает из коробки. Ты не во времена двойки последний раз питон щупал? И проблемы были только с умляутами на русской винде, например.
Я посмотрел, стандарный CPython работает нормально, а вот PyPy версия с юникодом не дружит
pypy нужен главным образом для того, чтобы можно было высылать софт в виде zip-архива и без лишнего гемора запускать, народу, далёкому от этих вещей
ладно, надо думать, как обходить тогда
Pypy проблемки. Нахуй он нужен?
> чтобы можно было высылать софт в виде zip-архива и без лишнего гемора запускать, народу, далёкому от этих вещей
В экзешник можно сконпилить.
class Test:
def decorator(func):
def wrapper(args, kwargs):
print('foo')
result = func(args, kwargs)
return result
return wrapper
@decorator
def method(self):
print("bar")
Вот это единственный вариант, но в таком виде это просто сторонняя функция, которая сидит в скоупе класса и ни как к нему не относится, какое-то это васянство? Или так делают? А выносить декоратор вне класса я тоже не хочу, хочу чтобы всё было в одном блоке класса.
>А выносить декоратор вне класса я тоже не хочу, хочу чтобы всё было в одном блоке класса.
Зачем? Логика декораторов другая, они применяются в момент создания функций-классов-методов
Когда ты применяешь декоратор к методу класса, самого класса ещё не существует, соответственно тут поведение будет очень неочевидное
Логика декораторов в другом, они и не должны быть частью твоего класса. Описывай просто класс в отдельном модуле, и в нём не декораторы
Возможно вообще тебе нужны не декораторы, а что-то ещё
У меня класс это графическая часть приложения запускаемая в своем потоке. Декоратор, который я добавляю к методам, добавляет этим методам определенную потокобезопасность. Очень удобно шлёпнул сахарак над методом и готово, не нужно городить огород. Саму логику обертки тоже удобно менять в одном месте. По всему получается что место этого декоратора именно в этой абстрации, она логически его часть, но синтаксически это получается просто функция внутри скоупа класса, которая не имеет отношения к экземпляру.
Вся загвоздка только в том, что синтаксис декоратора не позволяет его приписать к классу, а логика приложения чотко говорит что ему тут самое место. Вот я и спрашиваю какие ваши практики по этому вопросу, как делают обычно. Но я влюбом случае его тут оставлю. Я просто хочу выяснить, может я что-то в синтаксисе не знаю, может есть специальный бубен для декораторов внутри класса ?
>Вот я и спрашиваю какие ваши практики по этому вопросу, как делают обычно
Никто не делает декораторы внутри класса. Польза какая-то очень мифическая, а серьёзные вопросы к этому есть
Идея декораторов в том, чтобы разделить логику декоратора и того, где ты его применяешь
Если у тебя универсальное решение, то разумно его держать вне класса, например чтобы можно было использовать не только в нём. Если оно завязано на конкретный класс, то другие подходы используют, с ними больше гибкости
Оно нигде в другом месте не применяется. Этот мой декоратор просто удобная для модификации надстройка, экономия сотки строк, которая определенное типовое поведение добавляет ко всем методам.
>Идея декораторов в том, чтобы разделить логику
Декоратор это синтаксический сахар обертки. Это и есть по сути обычная обертка, только сокращенная в синтаксисе для экономии места и красоты, где ты тут увидел идею разделения логики? Обертки используются... да как только не используются, и совсем не обязательно для того чтобы логику разносить по разным концам приложения.
Я например импортирую этот класс куда-то и мне конечно удобней чтобы и этот декоратор вместе с этим классом всюду сразу импортировался. Он больше нигде не нужен, он логически его часть, как я уже писал.
>Я например импортирую этот класс куда-то и мне конечно удобней чтобы и этот декоратор вместе с этим классом всюду сразу импортировался
Этот момент не понял. Зачем тебе думать тут про импорт декоратора? Декоратор применяется на этапе "компиляции", первого прохода питона по коду, тебе его потом по-определению уже не нужно куда-то импортировать. Это что-то, что используется на этапе разработки (тебе с ним удобнее описывать методы), а не использования
Если же ты хочешь применять его где-то снаружи, то можно определить его внутри класса под @staticmethod, хотя я бы не стал так делать, я бы просто определял декоратор в модуле
Кстати, если ты вдруг ещё не смотрел, посмотри на wraps из functools, это как корректно декораторы создавать, чтобы минимизировать побочные эффекты
>Зачем тебе думать тут про импорт декоратора?
Ну да, не подумал т.к. декоратор не часть экземпляра, он оборачивает всё сразу, а не при создании инста т.е. внести в обертку изменения под определенный инст не получится.
Вот как неудобно. Значит если я своим декоратором буду явно оборачивать методы НОВОГО экземпляра класса new=warp(meth), то всё нормально, бэст практис. А оборачивать методы используя синтаксис декоратора через @ собачку, это нельзя.
Т.е. чтобы всё было "по феньшую" мне в мой класс надо зафигачить отдельную фабрику, которая при инициализации пройдет по всем методам и все явно обернет. Вот такая хуита получается. Мде.
>@staticmethod
так декоратор вообще работать не будет, по крайней мере методы своего класса статический метод оборачивать не может.
>wraps из functools
Спасибо посмотрю, но я не люблю делать импорты, если в них не нуждается логика, а вопрос с декораторами это скорее вопрос красоты и синтаксиса. Ради этого импорт делать... как то не очень.
Не не не погодите. Декоратор применяется не на этапе компиляции, а по ходу выполнения, когда встречает определение функции.
Всё я правильно про него думал, им методы не оборачивают только по причине убогости синтаксиса.
>Это из дотнета портанули?
Зная майков - скорее наоборот.
>>510356
>В любом вменяемом проекте
>>510520
>валидаторы разметки
Так вот В РЕАЛЬНОМ проекте у тебя может произойти ЧТО УГОДНО. Например (из практики), может появиться встроенный язык конфигурации/логики/описания внутренних справочников или моделей или ещё чёрт знает, что! И такой встроенный язык может не повторять синтаксис реальных языков программирования и разметки и не иметь никаких форматеров или валидаторов, пока ты сам его не напишешь. И когда говнокодер запилит на нём СТЕНУ ТЕКСТА без отступов, пусть даже дефолтный пример, то его захочется выебать раскалённой кочергой!
>коммит
А это вообще делается через пре-коммит-хуки, которые некоторые не все правильно у себя настроят, так что хорошо ещё если репозиторий настроен грамотно, есть CI и хоть что-то, что не позволит влить код в мастера, если он не соответствует гайдлайнам, но есть это далеко не везде.
>А не утопия/зашквар ли делать на python андроид приложухи?
некоторое время назад (кажется, в прошлом году) в тред прибегал чувак, который на киви писал под мобилки, в том числе иос. Насколько я понял, по крайней мере под яббл писать более чем реально. Вёдра меня не интересовали и не интересуют, если что.

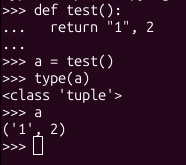 7 Кб, 186x165
7 Кб, 186x165>блоке return несколько переменных вернуть, охренеть!
Одну. Он возвращает один кортеж. а вот магия присвоения элементам одного кортежа элементы другого кортежа
> a, b = b, a
вот это действительно охренеть. И такого синтаксического сахара в языке столько, что может приключиьться синтаксический диабет.
Линуксом пользуются абсолютно все, кто выходит в интренет и почти все, чьи задачи по работе отличаются от вордика с одинэской.
Весь современный интренет работает на Линуксе, а поскольку кроме сайтиков (ой, блядь, простите, веб-приложений) сейчас не пишется по сути, почти весь написанный код в конечном итоге запихивается в контейнеры и запускается в кубере на линуксах.
>>515429
>Ты вот про эту хуйню?
Это игрушка более-менее работает для тестирования, но работать ПО всегда будет в настоящей среде, хоть усрись.
>Нихуя себе, у нас в треде ЭКСПЕРТ
Ну, чтобы сказать, что MVC это сомнительно не нужно быть экспертом. В нормальных проектах представление (фронт) существует отдельно, а модель (база) и контроллер (бэк) -- отдельно и общаются они через API-интерфейсы бэка, это даёт много плюшек, которые на джанго оказываются недоступны.
>Я например импортирую этот класс куда-то
Ты импортируешь модуль.
типа
> import my_module
Если из модуля тебе нужен класс, то ты можешь написать
> from my_module import MySuperClass
то в этот момент интерпретатор пройдёт по коду класса и инициирует его вместе с декоратором, который может лежать в модуле рядом. Воспользоваться декоратором отдельно ты не сможешь, но нужные методы будут обёрнуты.
Если же декоратор нужен тебе отдельно, то можешь импортнуть и его:
> from my_module import mu_ultra_decorator, MySuperClass
Это нормально, когда в модуле есть что-то кроме единственного основного класса.
> Зная майков - скорее наоборот.
Ты не в курсе что {} форматирование из дотнета, как и оператор асинк? Подозреваю.прыщедебила.
>>516340
Py в командной строке запускает интерактивный интерпретатор. Не слышал никогда?
>>516348
> И такого синтаксического сахара в языке столько, что может приключиьться синтаксический диабет.
Не пизди. Куда ему до того же сисярпа.
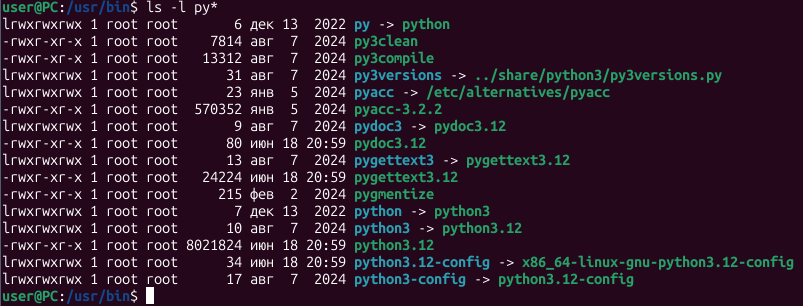 89 Кб, 803x306
89 Кб, 803x306>Py в командной строке
В 98% случаев `py` это симлинк. (типисчно: py -> python, python -> python3, python3 -> python3.12, см пик.) При чём в виэнвах он по крайней мере по-умолчанию не создаётся.
А вот при исполнении скрипта интерпретатор будет зависеть от шебанга и в шебанге ТОЖЕ МОЖЕТ БЫТЬ СИМЛИНК.
В общем, кури матчасть и вместо подрывов тащи конкретный код (целиком, с шебангами) и что у тебя не так.
Кстати, единственный верный шебанг это '#!/usr/bin/env python3'.
>Py в командной строке запускает интерактивный интерпретатор. Не слышал никогда?
Когда ты кликаешь на файл, запускается ассоциация, прописанная где-то в реестре для этого типа файлов
Когда ты запускаешь из командной строки, запускается то, что командная строка находит в PATH, если находит вообще, если ты не по полному пути запускаешь
>Не не не погодите. Декоратор применяется не на этапе компиляции, а по ходу выполнения, когда встречает определение функции.
Декоратор запускается один раз, когда питон проходит по коду программы (условно компиляции), декоратор возвращает функцию-враппер, что уже вызывается постоянно.
Если у тебя есть класс, где методы отдекорированы, то для каждого метода декоратор по идее вызовется ровно один раз, при первом импорте куда-либо. Не важно, будешь ли ты использовать класс, и если будешь, то сколько раз, но должен по идее один раз вызваться
Уверен примерно на 98%, пару процентов на глюки оставляю, можно проверить
Это не совсем компиляция, согласен, компиляция это создание pyc-файлов, в этом значении некорректно. Поэтому в кавычках было
по идее ты можешь сделать
import sys
print(sys.executable)
и посмотреть, откуда твой питон в каждом случае запускается
>Я про винду, само собой.
Буэ. На ней вообще ничего нормально не работает.
Но тут тебе тогда правильно сказали:
>>516426
>Когда ты кликаешь на файл, запускается ассоциация, прописанная где-то в реестре для этого типа файлов
правь реестр.
Это вендопроблемы. Слава яйцам у меня их не бывает. Заебался решать, свалил нахуй и забыл как страшный сон.
Тогда смотри ассоциации файлов и то, как у тебя PATH настроены, не помню точно, как это делается
В консоли посмотреть пути можно командой path
>Еще один с прыщей?
Не много ли ты на себя берёшь? Ты не в состоянии разобраться с проблемой, разобраться с которой для айтишника должно быть элементарно
Сидишь на своей винде, ну сиди, мало ли сросся с ней, пока менеджером по продажам работал. но изучи как она работает. Бля, почему я и то лучше знаю, хотя давно виндой не пользуюсь...
Тупое ты существо, с виндой все в порядке, это питон чудит. Изучи как он на винде работает, потом пиши сюда, красноглазик хуев.
Так это ты пришёл с проблемой, что не понимаешь, почему у тебя разные интерпретаторы запускаются. Это ты не понимаешь, как работает операционная система, под которой ты работаешь. Даже про то, что можно команду path в консоли запустить, не знаешь. Если что, это под виндой, в линуксе нет такой команды
>Изучи как он на винде работает, потом пиши сюда, красноглазик хуев
Я давно сюда не писал. Не думал, что за пару лет доска скатится к тому, что всерьёз будут думать, что пользоваться виндой это нормально для питон-разраба. Причём одновременно даже не понимая, как винда работает. Раньше такие как ты тут не задерживались, гнали их сразу
Во-первых питон нормально работает, сука ещё раз почти весь питонячий код в итоге работает на линуксах. Но и под дриснятки его собрали, пользуйтесь. Но ты, блядь, обвиняешь язык в проблемах системы, с которой не можешь справиться. Ты вообще е-бо-бо. У тебя же не с питоном проблемы, а с твоим локалхостом. При чём это не было искаропки, это ты своё локалхочт настроил жопой и теперь страдаешь.
При этом даже не можешь ни нормально описать проблему. Как это ДОЛЖНО БЫТЬ:
> я так-то и так-то настроил систему, я делаю икс, полчуаю игрек, а хочу получать зэд
Покажи, где у тебя хоть что-то похожее! Только подрывы и обвинения. Это потому, что ты не понимаешь, как что работает вообще и это есть печаль.
>>516526
>Я давно сюда не писал. Не думал, что за пару лет доска скатится
Вкатышков много, сам видишь. Им на курсах сказали, что венда - норм, а когда уточняли что будет на практике (про линуксы, WSL, виртуалки и т.п.) они, естественно, не слушали. Половина треда в вопросах "куда вкатываться".
Обычно оголтелых вендосектантов тут не так много или они не проявляются..
> всерьёз будут думать, что пользоваться виндой это нормально для питон-разраба.
Иди нахуй. Работают и зарабатывают.
> Причём одновременно даже не понимая, как винда работает.
Это ты скотина тупая нихуя не знаешь, а лезешь.
>>516538
Тупое мудло, разберись как питон запускает нужную версию на винде потом вякай.
А нахуя мне вообще что-то понимать? Я все сделал по инструкции, оно не работает. Ручками реестр или боже упаси pylauncher пусть всякий пердоскот вроде тебя ковыряет
>Это не совсем компиляция
Это самая настоящая компиляция, питон такой же компилируемый как и джава
мимо душнила
>разберись как
Ты, видимо, разобрался, поэтому у тебя проблемы?
> Я все сделал
Что, всё? По пунктам.
>по инструкции
По какой инструкции?
>оно не работает
Что именно не работает?
>Ручками реестр
Если сломал, то придётся.
>Тупое мудло
>пердоскот
И это на секундочку я тебе пытаюсь помочь. Не уверен, что ты вообще достоин моей помощи, но сегодня мне лень.
И да, чтобы ты знал, я перешёл на линуксы как основную систему очень давно и в первую очередь из лени. Потому, что на линуксах кратно меньше пердолинга. Особенно когда дело касается разработки (ЛЮБОЙ).
 89 Кб, 803x306
89 Кб, 803x306>нихуя не понимаешь
Зато ты понимаешь, поэтому у тебя нет проблем! Ой, то есть есть! Только ты их ни изложить не можешь, ни исправить. Видимо, ты тоже не понимаешь. Вот только вопрос, "тоже" или ты просто тупой, а если бы рассказал всё подробно, то выясилось бы, что тебе кто угодно может помочь, даже я, хотя со спермохлёбскими осями я не работал много лет.
> сюда пришла винду обсирать!
Не-а. Вообще мимо. Впрочем, мне её обсирать и ненадо, ты с ней на пару сами справляетесь.
Вот тебе как выбтрается интерпретатор в системе здорового человека. Напоминаю, что на пике ты можешь увидеть пример ls /usr/bin/py*.
Итак, дано. Например:
py -> python
python -> python3
python3 -> python3.12
python3.10
python3.11
python3.12
Например, я хочу, чтобы у меня скрипт запускался версией 3.11, я могу слделать несколько вешей.
1. Правильный путь. Создать виртуальное окружение и запускаться внутри него.
> md .venv && python -m venv .venv && source ./.venv/bin/activate
> ./script.py
2. Прописать шебанг
#!/usr/bin/env python3.11
3. Перенаправить симлинк (но это глобальное изменение, оно скажется на всех, у кого в шебанге прописано "py"/"python"/"python3"):
>ln -s python3.11 python3
Как работает в недоОС (работало во времена ХР, но вряд ли они стали ломать): есть реестр, в котором прописано сопоставление типа файла (определяется только по расширению) и бинарника. Когда ты делаешь запуск -- он смотрит, какой программой открывать ЭТО, а потом начинает её искать в $PATH. Реестр это вообще ёбань страшная, её запилили на заре ОСи и с тех пор не знают, как избавиться от этой помойки потому что слишком многое на неё теперь завязано.
Так что тебе надо либо разобраться с $PATH, либо с реестром, но ты же не способен никак рассказать, что у тебя творится.
>Нахуй пошла
>скотина
>Нахуй
>Ты ж скотина ебаная
Нет, ты всё-таки недостоин помощи.
89 Кб, 803x306>нихуя не понимаешь
Зато ты понимаешь, поэтому у тебя нет проблем! Ой, то есть есть! Только ты их ни изложить не можешь, ни исправить. Видимо, ты тоже не понимаешь. Вот только вопрос, "тоже" или ты просто тупой, а если бы рассказал всё подробно, то выясилось бы, что тебе кто угодно может помочь, даже я, хотя со спермохлёбскими осями я не работал много лет.
> сюда пришла винду обсирать!
Не-а. Вообще мимо. Впрочем, мне её обсирать и ненадо, ты с ней на пару сами справляетесь.
Вот тебе как выбтрается интерпретатор в системе здорового человека. Напоминаю, что на пике ты можешь увидеть пример ls /usr/bin/py*.
Итак, дано. Например:
py -> python
python -> python3
python3 -> python3.12
python3.10
python3.11
python3.12
Например, я хочу, чтобы у меня скрипт запускался версией 3.11, я могу слделать несколько вешей.
1. Правильный путь. Создать виртуальное окружение и запускаться внутри него.
> md .venv && python -m venv .venv && source ./.venv/bin/activate
> ./script.py
2. Прописать шебанг
#!/usr/bin/env python3.11
3. Перенаправить симлинк (но это глобальное изменение, оно скажется на всех, у кого в шебанге прописано "py"/"python"/"python3"):
>ln -s python3.11 python3
Как работает в недоОС (работало во времена ХР, но вряд ли они стали ломать): есть реестр, в котором прописано сопоставление типа файла (определяется только по расширению) и бинарника. Когда ты делаешь запуск -- он смотрит, какой программой открывать ЭТО, а потом начинает её искать в $PATH. Реестр это вообще ёбань страшная, её запилили на заре ОСи и с тех пор не знают, как избавиться от этой помойки потому что слишком многое на неё теперь завязано.
Так что тебе надо либо разобраться с $PATH, либо с реестром, но ты же не способен никак рассказать, что у тебя творится.
>Нахуй пошла
>скотина
>Нахуй
>Ты ж скотина ебаная
Нет, ты всё-таки недостоин помощи.
> Правильный путь. Создать виртуальное окружение и запускаться внутри него.
Самый надёжный это запускать по глобальному пути
/opt/venv/zhopa-project-py313/bin/python my_file.py
Так у тебя без лишнего пердолинга запускается всё из нужного окружения, всё наглядно и т.п.
Пшел нахуй, прыщепидор. Разберись как питон на винде работает сначала.
> Нет, ты всё-таки недостоин помощи.
Ты скотина винду по телеку видала, кому ты помогать собралась?
С хуя ли? Кортежи для чего придуманы?
>это через неявное создание tuple, фишка красивая, но по-моему в реальной жизни не то, чтобы очень часто используется
def divide(a: Number, b: Number) -> tuple[Number, str]:
____if b == 0: return None, "Divizion by zero"
____return a / b
res, err = divide(10, 5)
if err != None:
print(err)
print(res)
Сижу на винде потому что привык и мне так удобно. Линуксы и прочее говно в виртуальных машинах, если понадобится.
В системе установлено 3 версии питона. Помимо "явного запуска" из некоего виртуального окружения можно ещё из любого места запустить скриптик .py, который подсосется python.exe, а нужную версию выберет через шебенг, причем можно даже не писать полный номер версии #!/usr/bin/env python3 . Это поведение из коробки.
Брат воскрес зависимость есть, о чем вы тут так яросто спорите вообще не понятно.
>res, err = divide(10, 5)
Вообще в питоне исключения есть
Это ты предлагаешь собрать худшие особенности питона и го
Так это может быть не только ошибка.
Флаг успеха, как в примере из джанго выше, сообщение, что угодно.
>Разберись как питон на винде работает сначала.
Мне-то зачем? Я не идиот, чтобы запускать его на этом недоразумении, которое ты по безграмостности считаешь операционкой.
>>516606
>Самый надёжный это запускать по глобальному пути
Надёжный, хули тут спорить. Ну по факту это виэнва без активации. У меня, например, есть entrypoint.bash (для запуска в контейнере, ясен орган), так там я делаю вызовы питона по относительному пути:
> pizda_env/bin/python3 hooy.py
В контенерах могу себе позволить. Но в IDE и консоли -- проще всё-таки активировать окружение.
>/opt/venv/
Используешь какую-то упрощалку типа pipenv? Я что-то к ним так и не привык, по старинке, ну я приводил пример.
Даже скорее так по сути:
> mkdir --parents .venv && python -m venv .venv && source ./.venv/bin/activate && [[ -e requirements.txt ]] && pip install --requirement=requirements.txt
>Сижу на винде потому что привык и мне так удобно.
Просто привык. Как правило виндузятники не знают, что такое удобно на самом деле, просто пользуются тем, что подсунули не задумываясь о том, нравится ли им система, как было бы ей удобнее пользоваться и т.п. Я в этом уверен по одной простой причине: я в разных местах проводил опросы и переклички и среди всей массы почти не нашёл возвращенцев, которые нормально посидели на разных линуксах/макосях, а потом поняли, что для них ШИНДОШС объективно лучше и осознанно вернулись. Типичный возвращенец, которого я находил, попадает в одну из двух категорий: либо "я попробовал, но столкнулся с минорным багом, мой спермачий опыт не помог и я поджав хвост сбежал назад под привычную шконку", либо "я попробовал, просидел больше года (иногда сильно больше), но потом обстоятельства потребовали и я с большим сожалением вернулся".
>Линуксы и прочее говно в виртуальных машинах, если понадобится.
Более чем приемлемый выход на самом деле.
>В системе установлено 3 версии питона.
>подсосется python.exe, а нужную версию выберет через шебенг
Ну охуеть. То есть я был прав тут >>516410, а спермодаун подрывался на ровном месте. Хотя для такого поведения python.exe должен делать дохуя лишней работы по поиску альтернативных версий... Ну да хуй бы с ними, система всё-равно не профильная.
>о чем вы тут так яросто спорите вообще не понятно.
Ну ты видишь, спермохлёб-фоннатег утверждает, что он тут единственный, кто понимает, как работает винда и питон и кричит, что венда божественна, а питон днище, хотя я так и не добился от него даже детального объяснения, что точно у него за проблема. Между всполохами из его жопы ещё как-то можно понять, что у него стоит несколько версий и скриптики запускаются не той версией, которую он хочет, но без деталей, что у него есть и как работает я просто любуюсь полыханием.
>Это пиздоблядофича. Поэтому и не используется.
ЧТОА? Даже dict.items() не используешь? И enumerate(list) не пользуешься?
> Перепутал параметры - привет, баги.
Ну, если ты чайник, не способный на правильные нейминг и расстановку операндов, то возможно.
В моём коде это встречается часто. Да, чаще в приватных методах, но бывает по-разному.
>Перепутал параметры - привет
Каждый раз проигрываю с этих вкатунов из НОРМАЛЬНЫХ ЯЗЫКОВ, которые без типизации непрерывно срут в штаны и не могут в уме держать более одно аргумента, а если надо запомнить что функция возвращает первым элементом а что вторым, то тут вкатун падает в обморок от перенапряжения.
>Ну ты видишь, спермохлёб-фоннатег утверждает, что он тут единственный, кто понимает, как работает винда и питон и кричит, что венда божественна, а питон днище, хотя я так и не добился от него даже детального объяснения, что точно у него за проблема
Не, он не говорил, что понимает, как винда работает, он говорил, что ему не нужно это понимать, потому что он программист, а не сисадмин. А если ты сидишь на линуксе, значит ты сисадмин, а если ты сисадмин, ты должен понимать как питон на винде работает, а если понимаешь, то должен сказать, что у него за проблема и как решить, но так, чтобы он, программист и не сисадмин, понял. Ведь если он сидит на винде, то имеет право знать и не желать знать, что такое реестр, консоль и команды там.
>а потом поняли, что для них ШИНДОШС объективно лучше и осознанно вернулись
Причин бывает много, например то, что ОС используется не только для работы, а тут винда уже частно имеет преимущества, под линуксом многие вещи не поддерживаются. Правда кто серьёзно работает, по-моему интерпретаторы под виндой не запускают, тут варианты, или ты запускаешь виртуалку-докер локально, либо же, наверное чаще, ты запускаешь приложение на удалённом сервере. В любом случае эти сценарии подразумевают, что с линуксом ты работаешь довольно свободно, на уровне продвинутого пользователя-разработчика консоли.
А вот в том, что гоняют приложения при этом локально на винде, я не верю. Если только это не про ML направления какие-нибудь и некоторые близкие по духу.
>разных местах проводил опросы и переклички и среди всей массы почти не нашёл возвращенцев, которые нормально посидели на разных линуксах/макосях, а потом поняли, что для них ШИНДОШС объективно лучше и осознанно вернулись. Типичный возвращенец, которого я находил, попадает в одну из двух категорий: либо "я попробовал, но столкнулся с минорным багом, мой спермачий опыт не помог и я поджав хвост сбежал назад под привычную шконку", либо "я попробовал, просидел больше года (иногда сильно больше), но потом обстоятельства потребовали и я с большим сожалением вернулся
Неистово двачую, тричую! Меня как во время практики один программист подсадил на линукс, я так им увлекся и понял насколько это удобно, что от винды как от прокаженного бегаю, в жизни не вернусь никогда. А когда имеешь опыт, то любая проблема решается за пару минут, хотя на самом деле, если руки не из жопы то и проблем не возникает, ни разу ещё не сталкивался с какими-то нерешаемыми проблемами в отличие от винды, когда единственный способ что-то решить, это либо откатиться назад, либо полностью переустановить её
>ему не нужно это понимать, потому что он программист, а не сисадмин
Честно говоря я даже не сразу понял, что ты так тонко троллишь. Мои аплодисменты.
>тут винда уже частно имеет преимущества, под линуксом многие вещи не поддерживаются.
За всю мою практику я не встречал почти ничего, для чего это было бы справедливо. Изредка с чем-то есть сложности или минорные неудобства, но не более. В остальном на линуксах только удобнее. Я собсвтенно ушел с винды из-за лени. Мне стало лень с ней возиться и я перешёл туда, где возня была только в начале пути и
Но нужно понимать, что я изначально, ещё до перехода на линуксы имел ввиду конкретные инструменты. У меня может быть задача и я могу решить её разными инструментами. То есть ещё до смены ОС я пользовался OO.o тогда ещё и GIMP'ом потому что они полностью закрывали мои требования и при этом были бесплатными. Даже с играми так же: есть N игр, которые не запускаются (как правило из-за старых версий DRM, не совместимых с Proton'ом), но нахуя они мне, если есть тысячи других, которые работают идеально?
>вы код в ручную пишите?
М-м... А какая разница?
У меня LLM (сука, не ИИ, нет там интеллекта, откуда вы это вообще вытащили?) в последнем проекте написала ~80% кода и 100% документации, но и что?
Если ты пишешь код, то ты должен понимать, зачем в нём стоит каждый знак на каждом месте. ЛЛМка может дополнить код или даже написать целый метод по названию, но тебе всё-равно нужно понять, что он делает, как это вообще работает и т.п. Так что для меня дополнение от LLM это просто чуть более развёрнутый вариант IntelliSense и аналогов, только работает через сеть и очень медленно.
>Изредка с чем-то есть сложности или минорные неудобства, но не более
Есть куча софта, в основном это про обработку медиа, что под линуксом не запускается. Версий под линукс нет, даже под wine не запускаются (там не всё можно запустить), про "аналоги" говорить не надо, пожалуйста, это только для тех, кто мало-мальски серьёзно не работал аналоги
Кстати с инженерным софтом были подобные истории. но вот мне это не было актуально совсем.
>У меня LLM (сука, не ИИ, нет там интеллекта, откуда вы это вообще вытащили?)
Это философия уже, что такое интеллект и есть ли интеллект в таком понимании у среднего человека
Но в остальном согласен, во-первых ИИ-шки пока самостоятельно могут только небольшие программы делать, а в разработке нужно с серьёзным софтом нужно ориентироваться на весь проект. LLM натренированы хорош на небольших программах.
Более серьёзно, что понимать надо в любом случае. Вот посмотрел на новую GPT5, подают так, что радикальный прирост в уровне. Попросил сделать небольшую программу не очевидную, дал описание, программу сделала, запускается и работает (на прошлой версии уже с этим были проблемы). Но сделала при этом очень неочевидные косяки
и главное, ты прав, что всё равно нужно понимать, что за код ты получаешь. Хорошо понимать. А для этого нужны серьёзные скиллы, хорошее понимание предмета, надо набить практику приличную с тем, чтобы разбираться Иначе труба.
>М-м... А какая разница?
Реально тут очень давно какой-то шиз бегает, или несколько, постоянно вбрасывает темы, что программисты не нужны и всей нейронки порешают.
Пока не очень убедительно, потому что критически важно это разобраться в проекте и как-то его поддерживать. А в программировании разобраться хорошо в коде ничуть не проще, чем написать свой. Поэтому такого, чтобы нейронки заменили людей, не будет.
Но влияние на рынок есть, огромное, всё-таки производительность труда увеличивается, особенно во многих рутинных задачах, а это значит, что людей нужно меньше, особенно средней и низкой квалификации. Для QA рынка явно беда.
 1,4 Мб, mp4,
1,4 Мб, mp4,720x720, 0:12
Не, я на эту доску зашел так, от праздного любопытства, сам нейронки юзаю от безысходности, так как много народы поувольнялось после 22 года, а я сидел с пальцева попе. В итоге пришлось добирать проекты других, разбираться, конечно было пиздец лень, вот и юзал джепети всякие. Сейчас плотно сижу на нейронках, уже наверное написать даже привет мир не смогу, хотя раньше очень нихуево писал код.
>софта, в основном это про обработку медиа
Ещё раз. У тебя нет задачи "смонтировать фильм с помощью Windows Movie Maker"! Твоя задача -- "смонтировать фильм". И вот для этого всегда есть решения, в том числе профессиональные типа Davinchi Resolve.
У тебя нет задачи "отредактировать фото с помощью фотошопа" (хотя, кстати, кажется, последние версии уже облачные, так что можно и ими пользоваться), у тебя задача "отредактировать фото" и для этого уйма инструментов, от более чем достаточных для 99% редакторов встроенных во вьюверы или гимпа, до... ХЗ, чего. Я не знаю задач, с которыми не справится гимп, но те кому неудобен его интерфейс (насколько я знаю, единственная серьёзная претензия к нему) могут пользоваться критой, дарктейблом, фотофлоу и т.д. Для аудио есть и бксплатный аудасити, и куда более серьёзный платный ардоур (и не он один). И так далее. Не для всего я сразу назову инструменты (впрочем, могу поискать), но для всего они есть в том или ином виде.
Если же упираться в конкретные тайтлы, то я тебе скажу так: винда сосёт с заглотом потому что под неё нет не то что Final Cut Pro, но даже простеньких iMovie или Garage Band.
>И вот для этого всегда есть решения
Для многого нормальных решений нет. На коленке сделать что-то можно, а хорошие решения только под винду или мак
Это рассуждения уровня "зачем тебе Postgres, когда есть sqlite". Для многих задач sqlite достаточно, да
>Для многого нормальных решений нет.
Для чего? Примеры, блядь, будут, или только кукареки?
Ты написал, что
>>516952
>ОС используется не только для работы
>>517193
>куча софта, в основном это про обработку медиа
То есть непрофессиональное использование ПК для обработки медиа (фото, видео, звук). Я тебе накидал примеров такого ПО. У тебя же из аргументом только "для многого". Не-а. Это не аргумент. Давай лучше расскажи, чего тебе в давинчи не хватает (авторам Аватара и Прометея хватает, а тебе -- нет, уже интересно).
Инструменты, для обработки RAW фото
Adobe Lightroom и Canon Digital Photo Professional (бесплатная между прочим)
Бесплатные аналоги не могут даже нормально настройки съёмки подхватить, ты сдохнешь на том, чтобы что-то сравнимое с JPEG получить
vMix, профессиональный софт для трансляций. Только не надо про то, что OBS это реальная альтернатива, разные возможности, в добавок OBS глючный, не могут вечные баги пофиксить
Я пользуюсь OBS, когда надо, не люблю пиратский софт, но кто с видео серьёзно работает, не как я, тому это так себе замена
А если я чисто шкриптики и пишу?
>для обработки RAW фото
PhotoFlow
ON1 Photo RAW
Darktable
UFRaw
digiKam
Rawstudio
ещё у Affinity Photo есть полуофициальная сборка.
Cто лет как отказался от зеркалки, проверить не на чем.
+ собственно Adobe Lightroom, у которого есть веб-версия.
>OBS это реальная альтернатива
ОБС это не просто "альтернатива", по факту это промышленный стандарт, которым пользуются почти все стримеры, в том числе профессиональные видеоблогеры, разросшиеся до медиастудий типа Вилсаком и Абзаца. С плагинами (в том числе платными) он просто ебёт всё, что движется, а что не движется -- то двигает и ебёт.
>в добавок OBS глючный, не могут вечные баги пофиксить
Я стримил с его помощь на твич и ВК-видео, писал скринкасты, в том числе видеоинструкции для пользователей и вообще как консьюмер его пользовал много и за всё это время из проблем я замечал только редкие пропуски кадра, когда система загружена посильнее, но я бы удивился, если бы такого не было. Никаких других глюков или багов замечено не было.
Если же у тебя есть исключительно редкие ПРОФЕССИОНАЛЬНЫЕ требования (ага, у Петухова с десятками сотрудников и основным доходом с видеопродукции нет, а у тебя есть), то требуй от работодателя отдельный комп.
>PhotoFlow
>ON1 Photo RAW
>Darktable
>UFRaw
>digiKam
>Rawstudio
Нагуглил базвордов, которыми не пользовался. Что-то из этого я смотрел, они банально не в состоянии подхватить настройки камеры и показать что-то сравнимое, что выдаёт камерный jpeg. Надо жопу порвать, чтобы получить что-то адекватное. Ты сам raw не обрабатывал, а говоришь.
Типичный диванный интернет-пионер
>ОБС это не просто "альтернатива", по факту это промышленный стандарт, которым пользуются почти все стримеры, в том числе профессиональные видеоблогеры
ОБС это не промышленный стардарт, это стримминг "для бедных". "Профессиональным видеоблогерам", что своё рыло в 4к транслируют может достаточно. Для серьёзных транс нет.
>Никаких других глюков или багов замечено не было
Потому что ты пользовался им как домашний пользователь. Ок, глюк конкретный, встроенный браузер, когда ты его ставишь слоем выше видео, некорректно работает с частичной прозрачностью, она значительно сильнее "просвечивает", чем при этих же настройках в vMix и в настольном браузере. Причём если несколько таких слоёв, то ещё сложнее. Из-за этого, когда у тебя график накладывается на видео, всё в жопу летит. Это они сломали много лет назад и до сих пор не починили, хотя на форуме их поддержки про это много писали и просили.
Другие глюки есть. Для серьёзного использования у vMix масса функционала, что нет в ОБС. Тебе этот функционал, скорее всего, не нужен.
Короче, мальчик, иди играть в песочнику, ты типичный пионер-красноглазик. Это при том, что я сам на линуксе сижу, основая ОС для меня.
Есть ещё масса сфер, где линукс-альтернативы откровенно не сравнимы с тем, что есть на маках и винде. Но они чуть дальше от меня, я просто знаю, что вот серьёзный народ на это смотреть не станет.
Это как предлагать sqlite как акльтернативу для Postgres. При том, что в 90% задач на самом деле вполне можно было бы sqlite вместо использовать.
>>517386
Не только медийный софт. С медийным просто это очень известная тема. Огромная масса нишевого софта, с которым тебе возможно надо работать, существует только под винду. Часть этого софта можно спокойно поднять под Wine и работает не хуже, но что-то нельзя. Причём софт настолько нишевый, что альтернатив не существует вообще, либо положено пользоваться конкретными продуктами. Это совершенно обычная история для профессионального не массового софта.
Если твои интересы не выходят за пределы типично пионерских, это твоя проблема. Точнее наоборот, тогда для тебя проблем нет.
Многие вообще без компьютеров обходятся, им смартфона достаточно, они убеждены, что всё на смартфоне можно сделать. Прямо как ты
> Огромная масса нишевого софта, с которым тебе возможно надо работать, существует только под винду. Часть этого софта можно спокойно поднять под Wine и работает не хуже, но что-то нельзя
Есть люди, которые будут ебаться поднимать профессиональный виндовый софт под прыщи? Есть какие-то преимущества кроме как "смотрите как я могу!"? Вон дизайнерской хуйней можно и на винде пользоваться. Но почему-то дизайнеры на маках сидят.
>Хотя для такого поведения python.exe должен делать дохуя лишней работы по поиску альтернативных версий...
О чем ты? При установке питона в конкретный ключ реестра делается запись, что вот такая версия установлена. Исполняемый файл сразу знает что у него есть. Открывается файлик .py, читается строка шебенга и сразу отправляется в нужную версию. Чего тут лишнего? Телодвижений столько же как в IDE скрипт запускать, может даже меньше, потому что нет окружающих свистоперделок только файл скрипта и голый питон.
>чтобы у меня скрипт запускался версией 3.11, я могу слделать несколько вешей
4. Использовать uv.
Т.е. аргументов для предметного разговора у тебя нет. Ясно.
Мне надо ТГ бота посадить на https://www.pythonanywhere.com/
Я развернул виртуальное окружение и, все равно, чето не запускается, а что - понять не могу. Точнее, скорее всего, имеет место быть несоответствие версий библиотек.
Там сейчас довольно новая версия 3.13. Поэтому в виртуальном окружении пробовал перепрыгнуть на 3.9 но чето не выходит.
Вылазит такая ошибка:
Traceback (most recent call last):
File "/home/nickname/bot_code.py", line 45, in <module>
main()
File "/home/nickname/bot_code.py", line 38, in main
updater = Updater(TOKEN)
TypeError: init() missing 1 required positional argument: 'update_queue'
Кто сталкивался? Что я делаю не так?
*прогать не умею, ебусь все с гуглом и нейрухой. Мне чисто бота в ТГ запустить на один раз. Всем большой благодати заранее
>TypeError: init() missing 1 required positional argument: 'update_queue'
У тебя есть какой-то класс (видимо Updater), который принимает в себя TOKEN, но ему еще нужен аргумент update_queue, который у тебя туда не вложен.
Это копия, сохраненная 25 августа в 18:24.
Скачать тред: только с превью, с превью и прикрепленными файлами.
Второй вариант может долго скачиваться. Файлы будут только в живых или недавно утонувших тредах. Подробнее
Если вам полезен архив М.Двача, пожертвуйте на оплату сервера.